SPSS ModelerのCPLEXの最適化ノードでマッチング最適化を実行する

日本情報通信の森山です。
組み合わせは40320通り(8 * 7 * 6 * 5 * 4 * 3 * 2 * 1)
この記事では「CPLEXの最適化ノード」を用いるパターンを紹介します。SPSS Modelerのノードを利用する総当たりの方法は逆引き9-21を参照ください。
この記事は2023年秋のSPSSユーザーイベントで扱われたModeler詰将棋②を題材にしています。
講演内で触れたストリームの解説となります。
「CPLEXの最適化」ノードを活用すると、CPLEXという最適化ソリューションをModelerから呼び出すことができ、総当たりでは解くことが現実的でない問題に対し、より早く、最適な答えを導き出すことができます。
最適化ソリューション(CPLEX)についての詳細や本記事へのお問合せは、下記リンクをご確認ください。
1.想定される利用目的
・想定されるすべての組み合わせから最適解を求める
・総当たりや人力では計算に膨大な時間がかかってしまう問いに対して最適解を求める
2.サンプルストリームのダウンロード
3.サンプルストリームの説明
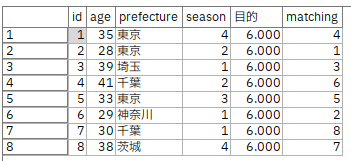
a.女性の属性データを入力します。

b.同様に、男性の属性データを入力します。
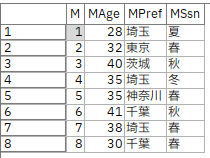
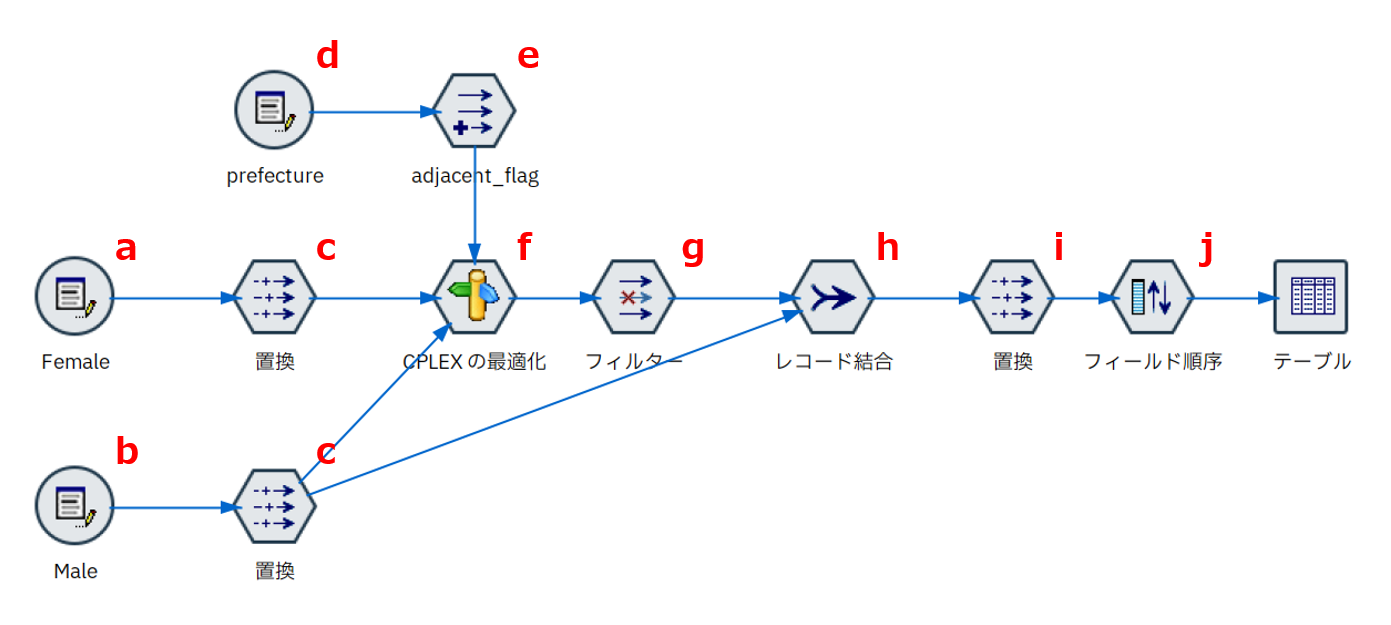
c.[置換]ノードで、後続で取り扱いやすいように季節を文字列から数字に変換します。
春が1、夏が2、秋が3、冬が4に置き換えられました。

d.隣接県の判定のための入力データとして、県の組み合わせデータを入力します。
(東京×埼玉×千葉×神奈川×茨城の25通り)

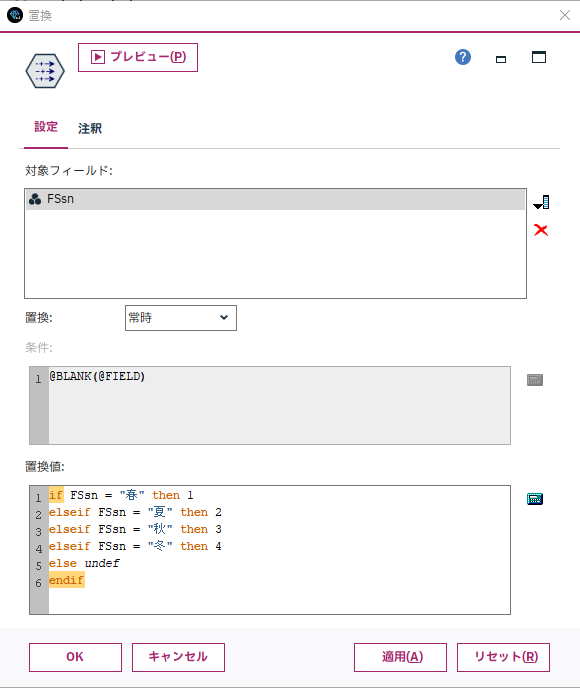
e.[フィールド作成]ノードを設定します。同一または隣接県である場合、フラグを立てるようにします。
同一または隣接県の場合は1、そうでない場合は0が付与されています。
後続のCPLEX処理内で、この表を参照して同一、隣接県の判定を行います。

f.[CPLEXの最適化]ノードを設定します。
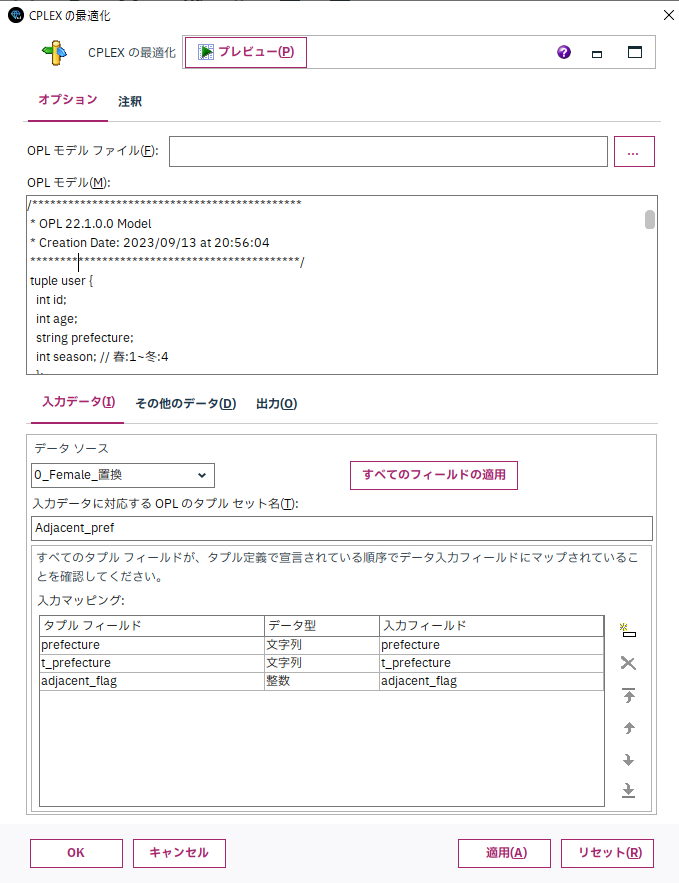
[OPLモデル]の欄に、最適化実行のためのコードを記載します。
コードについては、OPLと呼ばれるCPLEXの独自言語で記載します。
/*********************************************
* OPL 22.1.0.0 Model
* Creation Date: 2023/09/13 at 20:56:04
*********************************************/
tuple user {
int id;
int age;
string prefecture;
int season; // 春:1~冬:4
};
tuple adjacent_pref {
string prefecture;
string t_prefecture;
int adjacent_flag;
}
{adjacent_pref}Adjacent_pref=...;
{user}Male=...;
{user}Female=...;
dvar boolean matching[Female][Male];
dvar int output_matching[Female];
dvar int season_score[Female][Male];
dexpr float age_difference[f in Female][m in Male] = matching[f][m] * abs(f.age - m.age);
dexpr float total_age_difference = sum(f in Female,m in Male)age_difference[f][m];
dexpr int total_season_score = sum(f in Female,m in Male)season_score[f][m];
minimize staticLex(total_age_difference,-total_season_score);
subject to {
forall(f in Female){
forall(m in Male){
abs(f.age - m.age) * matching[f][m] <= 3;
}
}
forall(f in Female){
sum(m in Male)matching[f][m] == 1;
}
forall(m in Male){
sum(f in Female)matching[f][m] == 1;
}
forall(a in Adjacent_pref:a.adjacent_flag == 0){
forall(m in Male:a.prefecture == m.prefecture){
forall(f in Female:a.t_prefecture == f.prefecture){
matching[f][m] == 0;
}
}
}
forall(m in Male){
forall(f in Female){
if(m.season == f.season){
season_score[f][m] == 2 * matching[f][m];
} if(abs(m.season - f.season) == 2) {
season_score[f][m] == -1 * matching[f][m];
} if(abs(m.season - f.season) != 2 && m.season != f.season) {
season_score[f][m] == 0 * matching[f][m];
}
}
}
forall(f in Female){
output_matching[f] == sum(m in Male)m.id * matching[f][m];
}
}
続いて、[入力データ]タブで各入力データを、[OPLモデル]内のデータに対応させます。
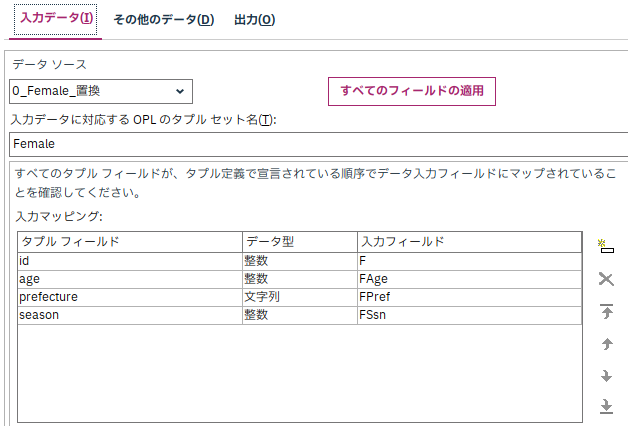
まず、[データ ソース]欄で入力となるデータを指定します。
SPSSから入力したデータをCPLEXで処理させるためには、SPSSのデータとCPLEXコード内のデータ定義を紐づけてあげる必要があります。
(SPSSで作成した「女性の属性」データを、CPLEXコード内の"Female"に紐づける等)
[0_Female_置換]は先ほどSPSSで作成した女性の属性データとなります。
[OPLモデル]内では、女性の属性データは"Female"という名前のタプルで定義されているため、
[入力データに対応するOPLのタプル セット名]欄に"Female"と記載します。
また、SPSS内での入力フィールド列名と、[OPLモデル]内でのタプルフィールド名の対応を設定します。
(どの列とどの列が同じ値なのかを定義する。SPSSのF列は、CPLEX内のid列、SPSSのFAge列は、CPLEX内のage列……等)
[入力マッピング]欄にて、"Female"のタプル列名を[タプルフィールド]欄に、データ型を[データ型]欄に入れます。
[入力フィールド]欄のリストをクリックし、SPSS Modeler上の対応する列名を指定します。
#userというタプルを作成する
tuple user {
int id; // SPSSではF
int age; // SPSSではFAge
string prefecture; // SPSSではFPref
int season; // SPSSではFSsn
};
(中略)
#userの型を継承して、Femaleを定義
#SPSSからの入力データを、以下で定義するFemaleの値として取り扱うように設定する
{user}Female=...;
同様の手順で、男性の属性データである[1_Male_置換]、同一または隣接県の対応表である[2_prefecture_adjacent_flag]についても定義します。

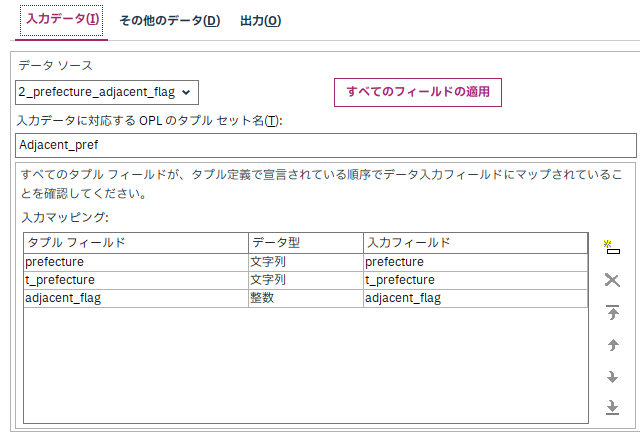
続いて、[出力]タブでアウトプットデータの設定を行います。
[出力に使用する目的関数値のフィールド名]欄では、CPLEX内の目的関数として設定した値を、SPSS上で出力するときにどのような列名にするかを設定します。
今回は年齢差の最小化が最優先のため、最適解における「年齢差の合計値」が設定した列に出力されます。
[出力タプル]には、アウトプットに含めたいCPLEX内のデータを指定します。
今回は女性の値をアウトプットに含めたいため、Femaleを設定します。
[変数の出力]には、アウトプットに含めたいCPLEXの決定変数を指定します。
[変数]列には出力後の列名を、[データ型]には出力するデータの型を、[出力フィールド]にはCPLEX内の決定変数名を指定します。
女性に対してマッチング対象とする男性の値を含めたいため、決定変数matchingを指定します。
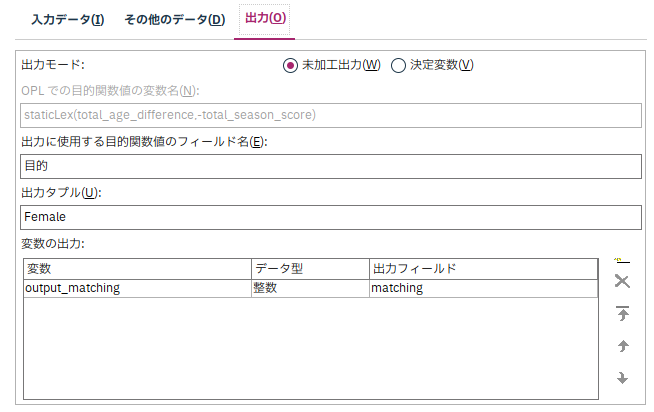
女性のIDに対して、最適化計算後のマッチング対象となる男性のIDがmatching列に出力されています。
g.[フィルター]ノードを設定します。
男性の属性データを後続で結合するため、列名をmatchingからMに変更します。
目的列は使用しないため、削除します。


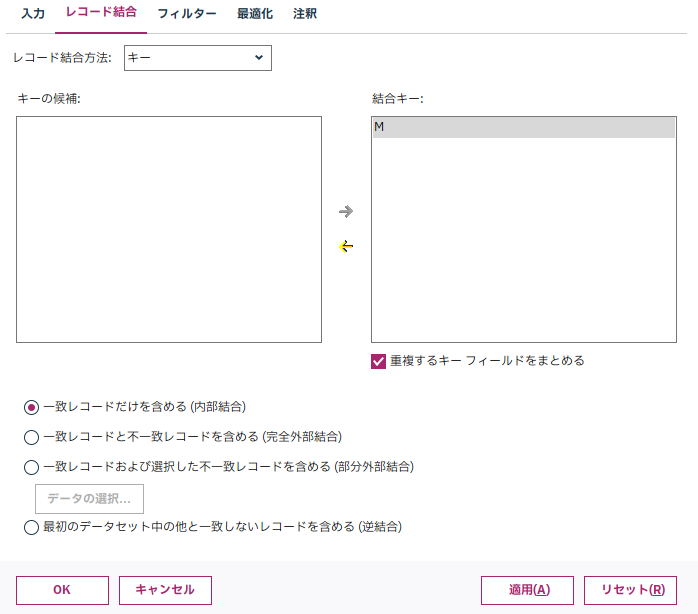
h.[レコード結合]ノードを設定します。
CPLEXのアウトプットと、男性の属性データ(Male)をM列をキーに内部結合します。
マッチング結果と属性情報がひとつのデータにまとまりました。

i.[置換]ノードを設定します。
cの処理で季節を数字に変換しているため、元の表記に戻します。

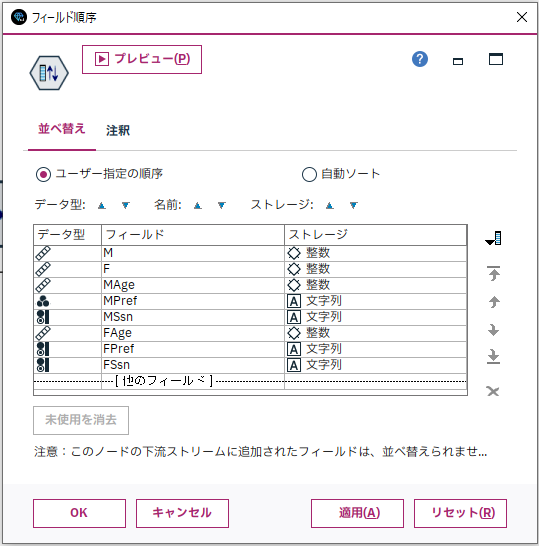
g.[フィールド順序]ノードを設定します。
列順を見やすいように置き換えます。
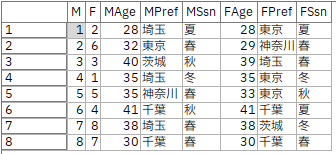
テーブルノードを実行します。
最適化結果が出力されました。
4.参考情報
【2023/12/7】最適化ソリューション(CPLEX)セミナー
最適化ソリューションで実現できること、実現方法をデモを通してご紹介します。
SPSS Modelerのノードを利用する方法
SPSS Modeler ノードリファレンス目次
SPSS Modeler 逆引きストリーム集(データ加工)