紹介論文
概要
- Recsys2020で発表された、推薦システムの公平なベンチマークに向けた調査と提案に関する論文
- 論文の貢献
- 主要学会を中心に推薦システム論文85本を系統的にレビュー, 性能比較において重要な要素を特定した
- 実際に各要素ごとに対照実験を行い、再現可能性の高い性能比較データを提供した
- 後続の研究者に向けて、比較実験が容易かつ拡張性も高いツール (https://github.com/AmazingDD/daisyRec) を提供した
- なぜ読もうと思ったか?
- 昨年のベストペーパー (https://arxiv.org/abs/1907.06902) など、推薦システムに関する公平な評価に関心が集まっているので
- 実務において、様々なモデルや処理が実際にどんなデータに有効なのか知っておくのは重要だと思ったから
論文の背景
- 近年、推薦システムの評価のための有効なベンチマークが存在しないことが問題になっている
- 過去5年の多くの論文での手法比較が適切でないことを示した論文 (https://arxiv.org/abs/1905.01395) もある
- 適切なチューニングを行うと新規手法は負けてしまう問題
- 近年の深層学習を使った推薦の論文でとくに不可解な比較が多い指摘もあった
- 過去5年の多くの論文での手法比較が適切でないことを示した論文 (https://arxiv.org/abs/1905.01395) もある
- CV系にはImageNetのような成熟したベンチマークがある
- なぜ推薦システムでは難しいのか?
- 同じ応用ドメインでも複数のプラットフォームの、種類の異なるデータが存在するため
- 映画:MovieLens, Netflix, …
- データ量: 100K, 1M, …
- 研究者が意図的にデータセットを選んで比較することが可能になってしまう - データの前処理、分割法、評価指標、パラメタ設定方法に多種多様な選択が存在する
- 最低評価数, 分割比率など
- これらの設定が公開されてないものが多いため、後続の再現を不可能にしている
- 同じ応用ドメインでも複数のプラットフォームの、種類の異なるデータが存在するため
論文収集と分析
論文収集
- 8つの学会の過去三年分の論文リストから特定のキーワードが含まれている論文を対象とした
- "recommend", "collaborative filtering", …
- 最終的に85本が対象となった(詳細は https://github.com/AmazingDD/daisyRec/blob/dev/Additional%20Material.pdf のTable5)
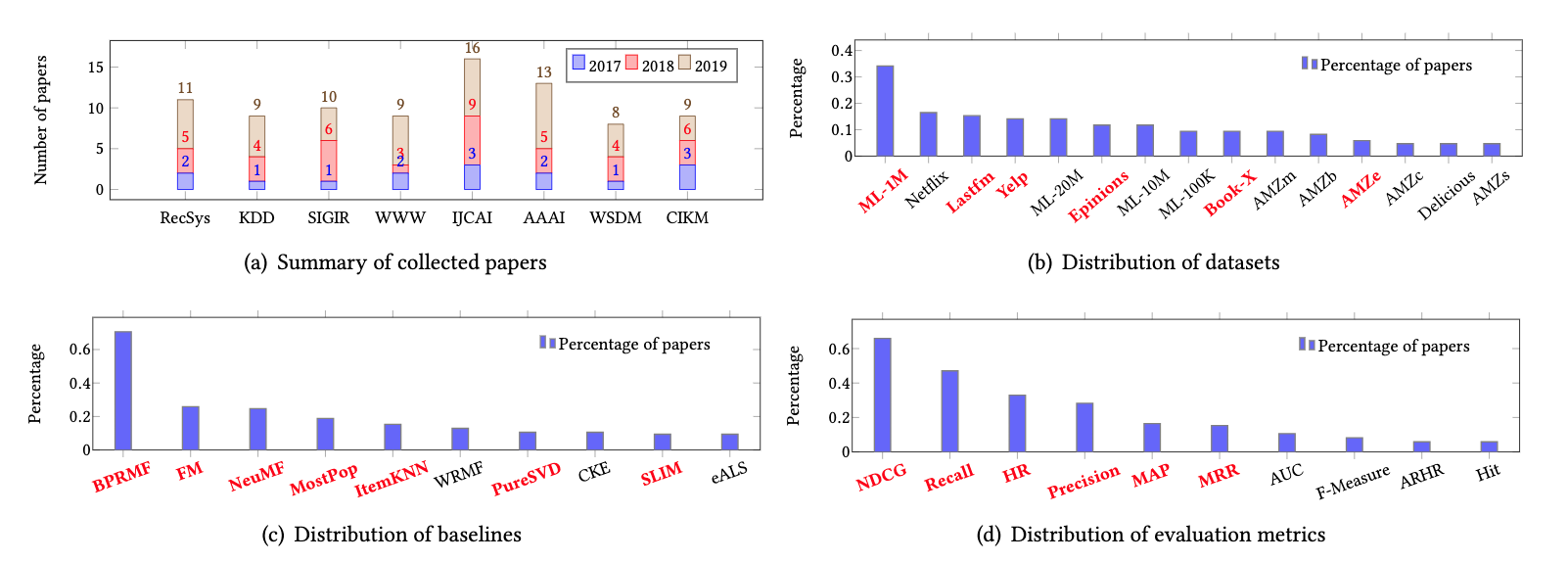
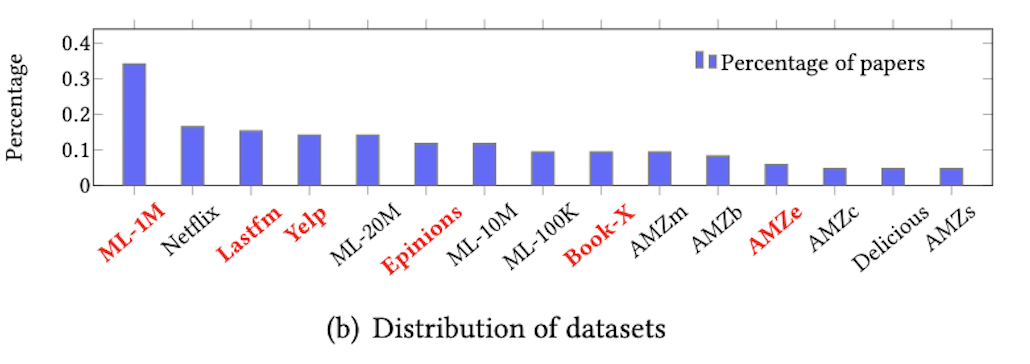
- 意外と少ない印象 - 学会、データセット、比較手法、評価関数などの分布を可視化した
- 本研究で採用した、データセット、指標、比較手法は赤字になっている
Fig1
主要な実験設定と問題点の分析
データセット
- 収集された論文からは二つの大きな問題が発見された
- 同一ドメイン(映画、音楽、EC…)内に複数の代表的なデータセットがある
- バージョンの多様性がある
- 同じ名前のデータセットでもいくつかのバージョンが存在していた
- Yelpは同一名義で3つのバージョンが存在した
- 同じ名前のデータセットでもいくつかのバージョンが存在していた
- fig1(b)は上位15件のデータセット人気度を、論文が占める割合で示した
- 85論文中90%の論文が上位15データセットの少なくとも1つを採用している
- 本研究ではデータセットの人気度とドメインカバレッジを考慮して、6つのデータセットを採用した
- ML1M(映画), Lastfm(音楽), Yelp(位置情報), Epinions(SNS), BookX(本), AMZe(EC)
- 各データセットのどのバージョンを利用するかも、権威性、情報量を考慮し選定した
 ### 前処理
### 前処理
- 明示的フィードバック(評価やカウント)を、暗黙的フィードバックに二値化しているがやり方に多様性がある
- $U, I$ をユーザ、アイテムとして、$r_{ui}$を$U$の$I$に対する二値フィードバックとする
- $r_{ui}$ は、しきい値以上の明示的フィードバックがあれば1、なければ0とした
- しきい値は論文によって設定に多様性があったが、ML-1Mでは4、それ以外は1とした
- ほとんどのユーザは5個以下のアイテムにしか評価を行っていないため、アクティブでないユーザを弾く前処理を入れることがある
- 約50%の論文でアクティブでないユーザを弾く前処理を採用していた
- このうち60%以上の論文で5,10回以上のユーザのみ扱う戦略を採用していた
- それ以外の回数にしきい値を設定した論文もあった
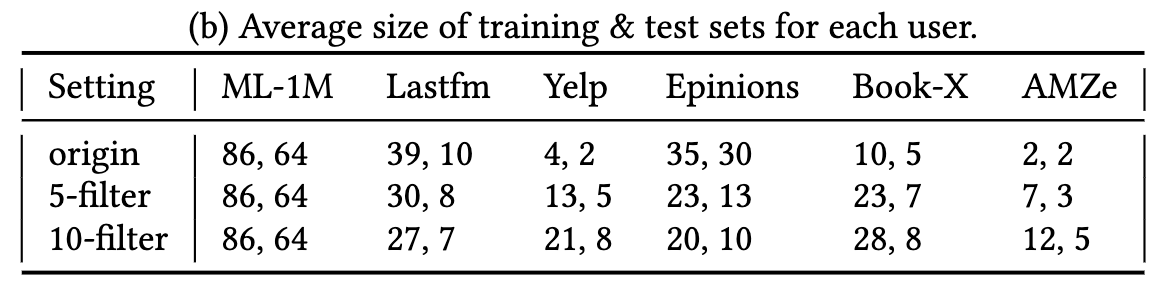
- 本研究では、オリジナル, 5-filter(5回以上評価したユーザのみ), 10-filterを採用した
- K-filterはK-coreとは異なる
- K-filter: 評価及び被評価数で一回だけ、ユーザとアイテムをフィルタリングする
- K-core: すべてのユーザ/アイテムがK回の評価を与える/受けるようになるまでフィルタリングをする
- 27%はオリジナルをそのまま、23%はどのような処理が行われたか公開されていなかった
- 約50%の論文でアクティブでないユーザを弾く前処理を採用していた
比較手法
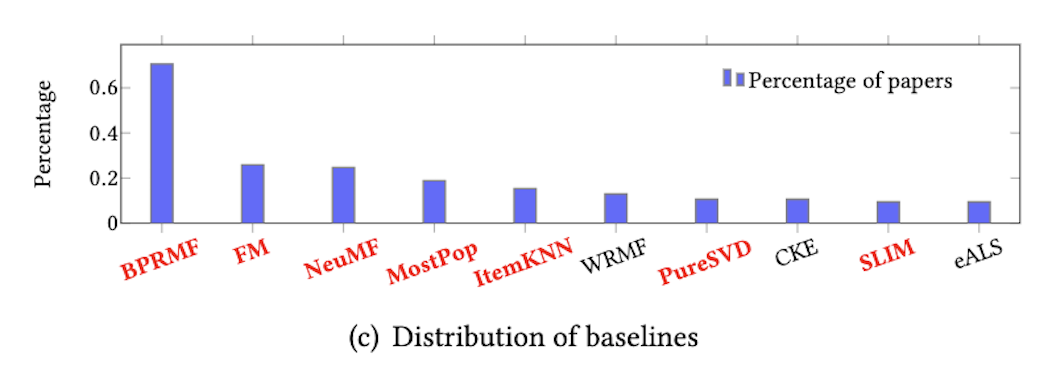
- fig1(c)は比較手法の分布
- 上位10位内の比較手法で全体の93%の論文をカバーしている
- メモリベース(MM)
- MostPop: 人気度上位のアイテムを全員に推薦
- ItemKNN: アイテム類似度(ここではcos)を定義し、K-NNベースで推薦
- 潜在因子ベース(LFM)
- BPRMF: 行列分解を用いて、BPR(Bayesian Personalized Ranking)損失を最小化する
- BPRFM: Factorization Machine系でユーザ、アイテム間の二次の特徴まで考慮
- PureSVD: ユーザアイテム行列に対して単純にSVDを適用
- SLIM: 制約項つきの二乗損失を、分解再構成した行列に対して適用
- 表現学習ベース(RLM)
- NeuMF: 行列分解の潜在ベクトル積のGMFとMLPを結合して回帰する深層推薦アルゴリズム
目的関数
- 目的関数には大きく分けて2タイプが利用されている
- point-wise (収集された論文の49%が採用)
- アイテムへの嗜好を点で数値として予測し、その精度を測る
- point-wiseの損失では、クロスエントロピーや二乗誤差がよく使われる
- 今回はTOPN推薦なので二乗誤差は評価しなかった - pair-wise (収集された論文の42%が採用)
- アイテムのペアの順序を予測し、相対的な順序を考慮することで、順位損失を近似する
- pair-wiseの損失では、対数損失やヒンジロスがよく使われる
- point-wise (収集された論文の49%が採用)
負例のサンプリング
- 観測はランダムにおきるわけではない(人気などと相関がある)ので、観察されたデータのみで評価するのはTOPN推薦には不適当
- 非観測の部分をどう評価するかが重要
- 本研究では、多くの研究を踏襲して観測されないフィードバッグを負例のフィードバッグとして扱う
- 本来、観測されないデータに関して、異なる解釈も可能なことは注意したい
- 未観測部分を適切に活用することを考える
- 実際、70%の論文で目的関数を設計するときに、未観測部分について、フィードバックとして考慮している
- 本研究で検証したサンプル戦略
- 一様サンプラー
- 収集したほとんどの論文で採用されている - アイテムの人気度ベースのサンプラー
- 低人気度サンプラー
- 欠測部のうち、人気度が低いアイテムに関して積極的に負例として採用する
- 人気の低いアイテムを好む可能性が低いという仮説に基づく
- 高人気度サンプラー
- 欠測部のうち、人気度が高いアイテムに関して積極的に負例として採用する
- 人気の高いアイテムに関して、ユーザがフィードバックしていない場合、本当に低評価の可能性が高いという仮説に基づく
- 一様サンプラー
データ分割法
主に二種類の方法が存在した。
- split-by-ratio (61%の論文が採用)
- 一定割合ρを学習、残りの1-ρを評価に使う方法。実際は以下の観点で多様性があった。
- 比率
- 学習の割合が50%-90%まで様々
- 分割粒度
- ユーザを最小単位として分割するもの
- フィードバック一つ一つを最小単位として分割するもの(同一ユーザのデータが学習と評価に分かれることもある)
- ユーザを最小単位として分割するもの
- ランダムか、時系列を考慮しているか
- 学習データはすべてテストデータ以前に発生したデータになっているかどうか
- 12%が時系列を考慮した分割をしていた
- 比率
- 一定割合ρを学習、残りの1-ρを評価に使う方法。実際は以下の観点で多様性があった。
- leave-one-out (28%の論文が採用)
- ユーザごとに一つのデータだけをテスト用に保存しておき、残りを学習に使う
- 分割粒度
- たいていユーザ単位 - ランダムか、時系列を考慮しているか
- LOOのうち54%は時系列を考慮していた
- その他、5%は特定時刻で分割, 残り6%はデータ分割について無記載
評価指標
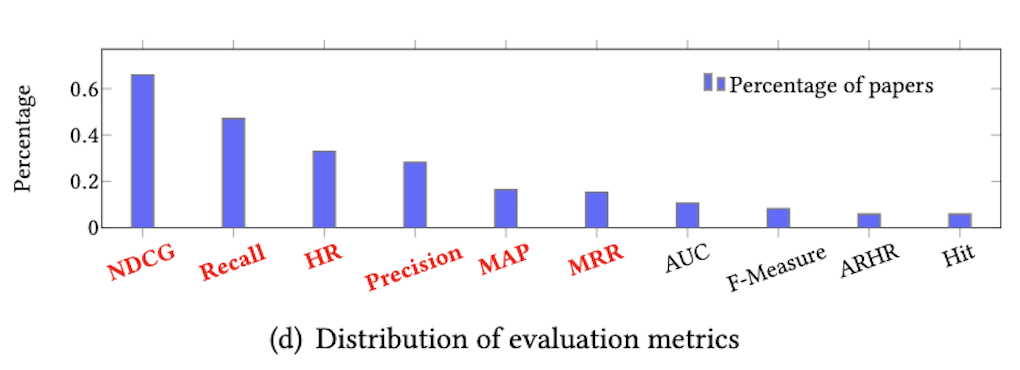
- 評価指標は収集した論文の中で、分散が大きい項目
- 94%が6つの手法のうちどれかを利用していた(Fig1 (d))
- 計測に使った指標
- 上位リスト内に含まれるか計測
- Precision
- Recall
- Mean Average Precision(MAP)
- Precision@k / sum_k の平均
- Hit Ratio(HR) - 順位を計測
- Mean Reciprocal Rank(MRR)
- 順位の逆数の平均
- Normalized Discounted Cumlative Gain (NDCG)
- スコアを順位の対数逆数で割り引く
- 上位リスト内に含まれるか計測
ハイパーパラメータ探索
ハイパーパラメータ探索は、最終的な性能に大きく影響を与える。
実験設定としては、どのようにデータセットを分割するか、どのように探索するか、という要素があった。
分割戦略
- 37%の論文がテストセットの性能を見ながら、ハイパーパラメータを調整していることがわかった
- これはテストデータの情報がモデルに漏れて、過学習を起こす可能性がある
- nested validationによって回避できる
- 学習とテストの他に、ハイパーパラメータ用の検証セットを用意する方法
- 本研究では、学習セットからさらにその10%を検証セットとしてとっておくnested validationを採用した
- ハイパーパラメータを検証セットによって設定した後、元々の学習データをすべて投入させ再学習させた
探索戦略
- ほとんどの論文でグリット探索を利用していた
- グリット探索はパラメータが少ないモデル向きで、そうでないと組合せ爆発を起こす
- パラメータ$m$個が$n$個の値をとれると、$m^n$通りの組合せが存在する
- Bayesian Hyper Optはランダムよりも賢い手法
- 本研究ではNDCGに対して、Bayesian Hyper Optを採用した
- 過去の試行を生かしてパラメータを探索するため、randomより効率的
- 特に指定がなければ、本論文では以下の設定を採用している
- ハイパーパラメータ探索時の指標
- NDCG
- 分割方法
- Nested validation
- 学習データの10%を利用
- 探索方法
- Bayesian Hyper Opt
- ハイパーパラメータ探索時の指標
比較実験
評価項目
- アルゴリズム
- データセット
- 前処理
- 損失関数
- 負例のサンプリング法
- データ分割
- 評価指標
データセット
- 比較要素
- ML1M(映画), Lastfm(音楽), Yelp(位置情報), Epinions(SNS), BookX(本), AMZe(EC)
- 結果
- アルゴリズムと合わせて後述
アルゴリズム
- 比較要素
- メモリベース(MM)
- MostPop, ItemKNN
- 潜在因子ベース(LFM)
- BPRMF, BPRFM, PureSVD, SLIM
- 表現学習ベース(RLM)
- NeuMF
- メモリベース(MM)
- 結果
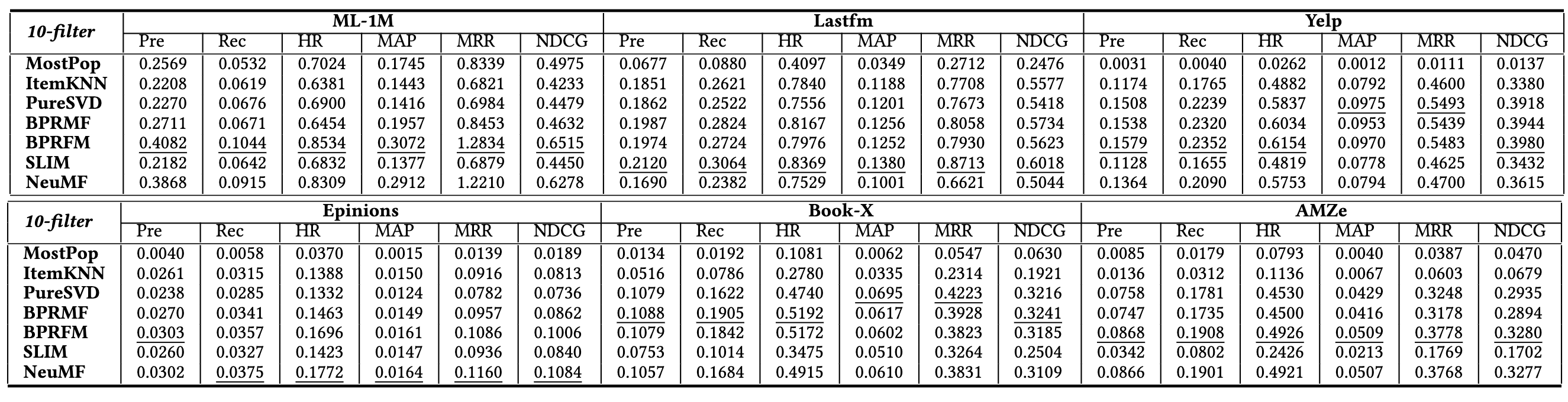
- ほとんどでMostpopが一番悪く、パーソナライズの効果を示している(Fig2)
- ML-1Mにおいては、ItemKNN, SVD, BPRMFに勝っており、データセット次第では有効
- LastFMではItemKNNは、LFM、DFMに勝っている
- 近傍ベースの考え方を取り入れることでよくなるかも?
- NeuMFはML-1M, AMZeでは健闘してるが、他は負けている
- DLMがパラメータを最適化した既存手法に勝てるわけではない
- 訓練コストが高いのもネック
- 10-filterで固定すると(Table4の設定), BPRFMが少しよさそうか?
- ほとんどでMostpopが一番悪く、パーソナライズの効果を示している(Fig2)
前処理
- 比較要素
- original
- 5-filter, 10-filter
- 評価数N以上のユーザのみ扱う
- 結果
- ユーザあたりの平均評価量の増減と相関している
- 密度があがるものは向上、減るものは減少する(密度:Table2b, 性能: Fig2)
- ML-1Mでは影響なし
- Yelp, BookX, AMZeはフィルターするほど性能向上
- Lastfm, Epinionsは性能低下
- 密度があがるものは向上、減るものは減少する(密度:Table2b, 性能: Fig2)
- ユーザあたりの平均評価量の増減と相関している

損失関数
- 比較要素
- point-wise
- クロスエントロピー(CE)
- pair-wise
- 対数損失(LL)
- ヒンジ損失(HL)
- point-wise
- 結果分析
- Pair-wise+LogLoss(赤)が総じて優れている(Fig3)
- BPRFM(中)は目的関数に対する感度が低くロバスト

負例のサンプリング法
- 比較要素
- 未評価を負例としてサンプリングして使う
- 一様サンプラー
- 低人気度サンプラー(Lpop)
- 高人気度サンプラー(Hpop)
- 未評価を負例としてサンプリングして使う
- 結果
- 一様サンプラー(灰)が最も優れている(Fig4)
- Lpop(赤)の方が不人気なアイテムを負例として扱うため良さそうだが、直感に反する結果

データ分割
- 比較要素
- split-by-ratio(学習:テスト=80:20)
- ランダム分割
- 時系列を考慮した分割
- split-by-ratio(学習:テスト=80:20)
- 結果
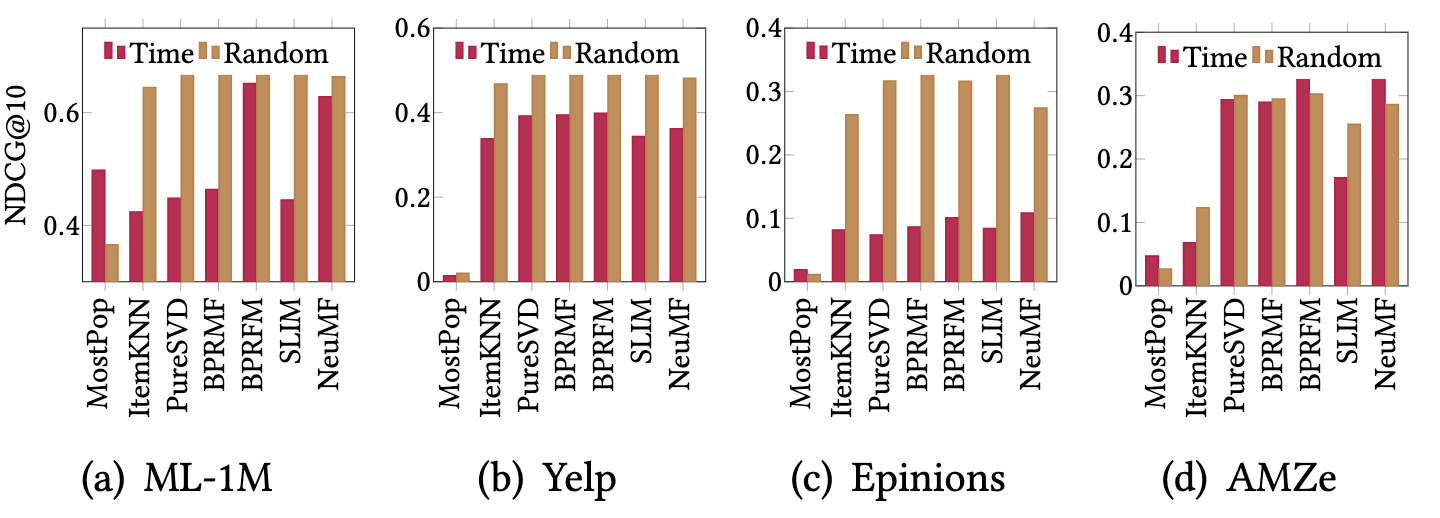
- ほとんどのデータセットでランダムが有利
- とくにEpnions(SNS)ではランダムが3倍ほど有利になった(Fig5 (c))
- 実際のシナリオに近いのは時系列分割
- ランダム分割による検証は実環境より、過大評価されている可能性がある
評価指標
- 比較要素
- ある指標を最適化するハイパーパラメータが、別の指標でも最適とは限らない
- 指標xベースラインごとに30回試行して、ある指標において最良な試行をとりだす
- それが、別の指標においても最良であれば、その指標間で得点1、相関係数は総得点を試行回数で割ったもの
- 6つの手法x6つのデータセットで全部で36で得点を割る
- 異なる指標で最適化された時の、推薦されるアイテムのKendall順序相関もみた
- 計測に使った指標
- 一定順位内に含まれるかどうかを計測
- Precision, Recall, MAP, HR
- 順位を計測
- MRR, NDCG
- 一定順位内に含まれるかどうかを計測
- ある指標を最適化するハイパーパラメータが、別の指標でも最適とは限らない
- 結果
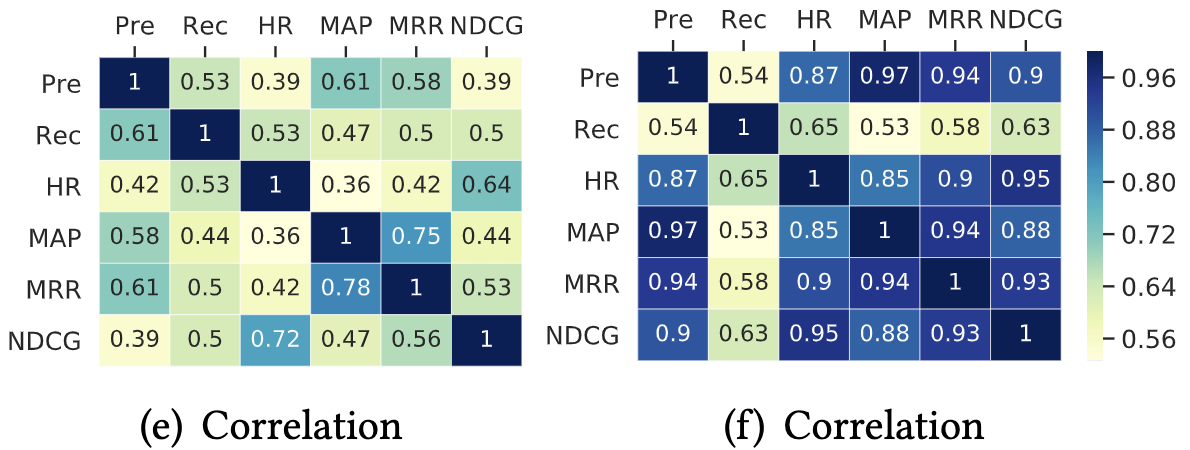
- ある指標を最適化するハイパーパラメータが、別の指標でも最適というわけではなかった(Fig:5-e)
- 相関行列は非対称
- NDCG->HRは0.72, HR->NDCGは0.64
- Kendall順序相関においては、Recallが著しく他の指標と異なることがわかった(Fig:5-f)
比較実験から得られた結論 (@smochiの解釈)
大前提、データの性質に左右されやすいが、以下のような解釈。
- アルゴリズム
- データによって異なる、BPRFMがやや強い
- 必ずしも複雑なモデルが強いわけではない(e.g. NeuMF)
- 前処理
- ユーザごとのデータ密度が上がるならやった方がよい
- 損失関数
- Pair-wise+LogLossが第一選択か
- 負例のサンプリング法
- 一様サンプラーが第一選択か
- データ分割
- グローバルで学習:テスト=80:20
- 時系列は考慮して分割すべき
- 評価指標
- 指標ごとに強いモデルが異なり、相関も低かったりするので実際の状況に近い指標を選択すべき