紹介論文
Are We Really Making Much Progress? A Worrying Analysis of Recent Neural Recommendation Approaches (RecSys 2019)
日本語では「本当にそんなに進捗出てるの? -或いは最近のNN推薦手法に対する警鐘-」という感じだろうか。
元論文はこちら https://arxiv.org/pdf/1907.06902.pdf
概要
- DNNが登場してから推薦分野でもDeepXXな手法が増えている
- 新手法の登場頻度が高いため、代表的なタスクであるtopN推薦に対してすらSOTAが何か追えなくなっている
- そこでトップ会議(KDD, SIGIR, WWW, RecSys)のDNN関連研究18本を追試した
- 18本のうち、現実的な努力を行った上で再現できたのが7本
- (RecSysでの発表によると、)実装が再現できない場合は、実装を原著者らに問い合わせて1ヶ月待った
- さらに6/7がkNNベース+ハイパーパラメータ最適化に負けてしまった
- 残りの1つもDNNではない線形の手法を調整したものに負ける場合もあった
- 18本のうち、現実的な努力を行った上で再現できたのが7本
- このような問題の原因として、筆者らは以下を主張している
- 再現性の低さ
- 実装, 前処理, ハイパラの再現が難しい
- 実験設定、実装が疑わしいものもある
- 正しいベースラインとの比較が行われていない
- ドメインでの調整が行われたkNNなどのシンプル(だが強力)な手法との比較がされてない
- あらゆる古典的手法に敗北している手法もある
- 再現性の低さ
評価方法
以下にこの論文で行ったすべての実験の再現のコードやデータ、ハイパラの設定などが格納されている。
評価手法は以下論文で行われたものと同様の手法を利用。
比較対象とした古典的手法
TopPopular
名前の通り、全員に同一の最も平均レーティングの高いアイテムを推薦
1 ItemKNN
KNNとアイテム間類似性をベースとした協調フィルタリング(CF)の手法。
- $r_{i}, r_{j}$は暗黙的(implicit)な評価値
- $h$はユーザからの評価回数が少ないアイテムの登場時に下駄を履かせる定数
- TF-IDFやBM25で傾斜をかけることもある
- 残りのハイパーパラメータとしてk近傍の$k$
- アイテム$i$と$j$の間のコサイン類似度$s_{ij}$を以下で定義
s_{i j}=\frac{\mathbf{r}_{i} \cdot \mathbf{r}_{j}}{\left\|\mathbf{r}_{i}\right\|\left\|\mathbf{r}_{j}\right\|+h}
2 UserKNN
ItemKNNと似た評価方法で、User間類似性をベースとした手法。ハイパーパラメータはItemKNNと同様。
3 ItemKNN-CBF
1, 2の手法が評価値ベースの手法であるのに対して、コンテンツ(特徴量)ベースの代表的手法。
- $\mathbf{f}_{i}, \mathbf{f}_{j}$ はアイテムに付与される特徴量ベクトル
- 残りの変数、ハイパーパラメータは1, 2と同様
- アイテム$i$と$j$の間のコサイン類似度$s_{ij}$を以下で定義
s_{i j}=\frac{\mathbf{f}_{i} \cdot \mathbf{f}_{j}}{\left\|\mathbf{f}_{i}\right\|\left\|\mathbf{f}_{j}\right\|+h}
4 ItemKNN-CFCBF
1, 3のハイブリッド的手法。
- 3の特徴量 $\mathbf{f}$ に評価値の次元を加える
- ただし、そのまま次元を結合するのではなく、特徴量に重み$w$をつけて $[\mathbf{r}_{i}, w\mathbf{f}_{i}]$とする
5 P3α
ユーザとアイテム間で定義されたグラフ上でランダムウォークを行うことで、アイテムのランク付けを行う手法らしい。
- ユーザ$u$からアイテム$i$にジャンプする確率は$p_{ui}=(r_{ui} / N_{u})^\alpha$で表現
- 同様にアイテム$i$からユーザ$u$にジャンプする確率は$p_{iu}=(r_{ui} / N_{i})^\alpha$で表現
- $N_{i}$, $N_{u}$はそれぞれ、アイテム、ユーザの被評価、評価の回数
- $\alpha$は減衰係数
- アイテムベースのCFと同じ様に扱うことができ、類似度 $s_{ij}$は以下で定義される
s_{i j}=\sum_{v} p_{j v} p_{v i}
- ハイパーパラメータはkNNの$k$と減衰係数$\alpha$
- コストパフォーマンスが良い、筆者推しの手法らしい
6 RP3β
5の亜種。類似度$s_{ij}$の計算の際に、$s_{ij}$を各アイテムの人気度に係数$\beta$を累乗したもので割って人気度を正規化する。$\beta=0$で5と等価。
再現できたので評価した手法
- Collaborative Memory Networks (CMN)

- Metapath based Context for RECommendation (MCRec)
- Collaborative Variational Autoencoder (CVAE)
- Collaborative Deep Learning (CDL)

- Neural Collaborative Filtering (NCF)
- Spectral Collaborative Filtering (SpectralCF)

- Variational Autoencoders for Collaborative Filtering (Mult-VAE)

各手法の評価
7 Collaborative Memory Networks (CMN)
メモリーネットワークとアテンションを潜在因子に組み合わせた手法
- 原著の実験
- 行列分解、NNベース、ItemKNN($h$なし)と比較
- Epinions、CiteULike-a、Pinterestのデータセット
- 比較手法のハイパーパラメータ最適化に関する記述なし
- 今回の実験
- ヒット率(HR@5)で比較手法のハイパーパラメータを最適化
- 結論
- 原著では比較手法に比べCMN全勝だったが、ほとんど勝てなくなってしまった
- Epinionsに至っては最も単純なTopPopularが圧勝
- このデータセットはGini指数が0.69と人気が偏ってるのが原因か

8 Metapath based Context for RECommendation (MCRec)
映画のジャンルなどの補助情報を活用するメタパスベースのモデル。優先度つきサンプリングを用いて良いパスを選択。新しいアテンション手法も提案している。
- 原著の実験
- MovieLens100k, LastFm, Yelpの比較的小さいデータセット
- 80/20の分割を10回平均で評価
- 比較手法のハイパーパラメータ最適化に関する記述が一部ない
- NDCGの評価値が怪しい
- 今回の実験
- 原著と同じく精度で比較手法のハイパーパラメータを最適化
- 結論
- すべての評価指標でItemKNNに敗北
- 原著の比較手法のハイパーパラメータは異なるデータに最適化されていて弱体化していた
- 提供された実装を調べたところ、各指標を別のバリデーションセットで一番良かった指標を記載していて、不適切

9 Collaborative Variational Autoencoder (CVAE)
教師なしでアイテム特徴から深い潜在表現を学習し、コンテンツと評価の両方からアイテムとユーザー間の暗黙的な関係を学習する手法。
- 原著の実験
- CiteULike(135k, 205k回評価)の比較的小さいデータセット
- 異なる推薦リスト長(50, 100, 300)でのリコールが評価指標
- ランダムな学習-評価のバリデーションセットが作られ5回評価
- データセットと評価方法がコードベースで共有されている
- 今回の実験
- 原著と同じくリコールで比較手法のハイパーパラメータを最適化
- 結論
- すべてのリスト長でItemKNN-CFCBFに敗北
- CVAEは提案リスト長が長くなると強くなったが、それは原著の対象としてはあまり良い状況ではない

10 Collaborative Deep Learning (CDL)
Stacked Denoising AutoEncoders(SDAE)とCollaborative Topic Regression(CTR)を同時に解くモデル。
CTRのトピック表現にSDAEを適用し、より低次元の表現をしたものでCTRを行っている気がする。
CVAEの手法でベースラインとして引用された。
- 原著の実験
- CVAEと同様の実験設定
- CTRと比べスパースなデータの状況で強いことを主張
- 今回の実験
- 原著と同じくリコールで比較手法のハイパーパラメータを最適化
- (原著は疎な状況の優位さを主張しているが)高密度の設定で評価
- 結論
- すべての推薦リスト長で複数の古典的手法に敗北
- 推薦リスト長が短いと性能がかなり悪い
- (ちなみに)9のCVAEと比較するとたしかにCVAEはCDLよりは良くなってるが、結局古典的手法には勝っていない

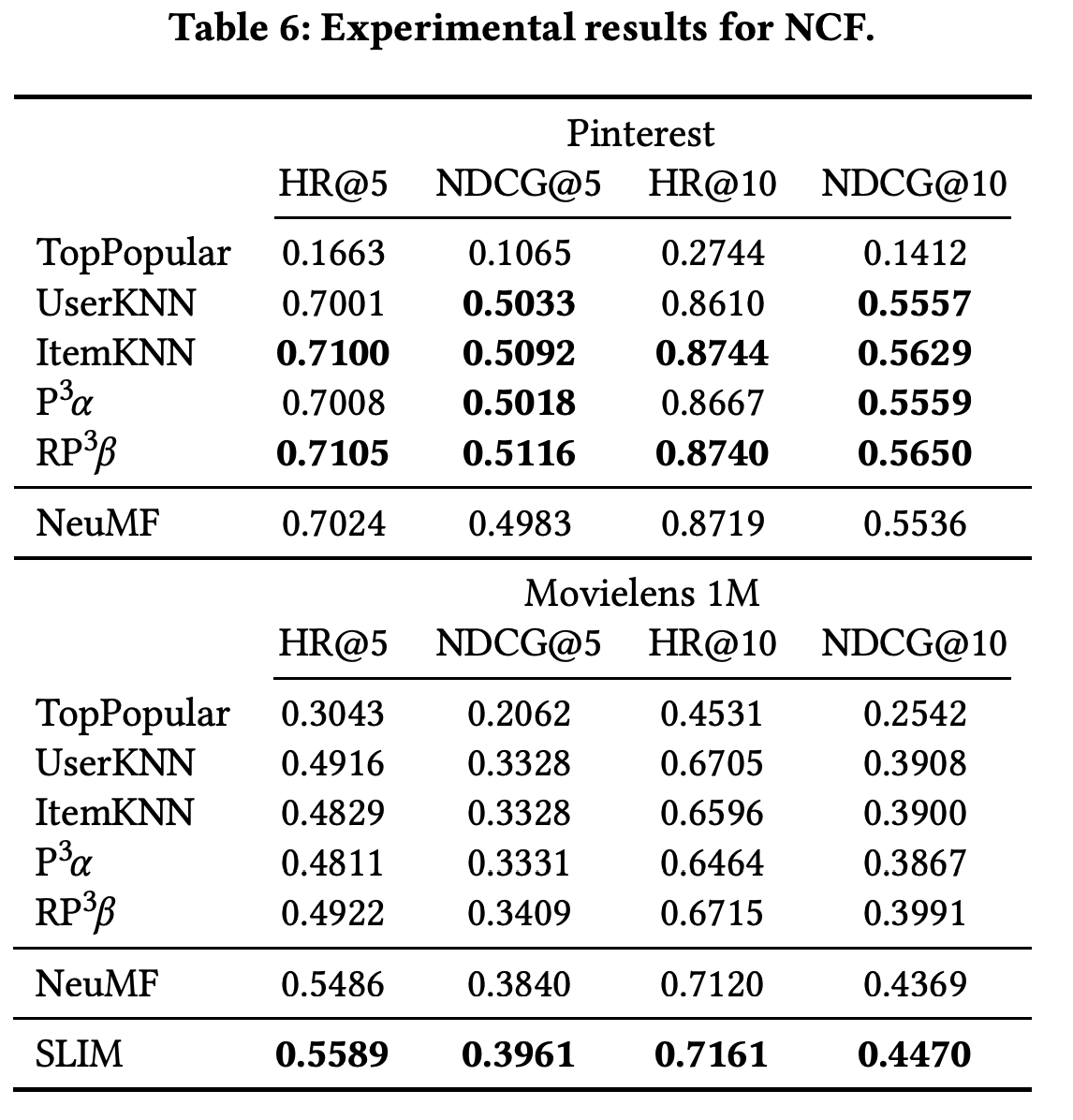
11 Neural Collaborative Filtering (NCF)
CFで使われる行列分解と、その内積表現の部分をNNベースの関数に置き換えてデータから学習するモデル。
- 原著の実験
- MovieLens1M(100万回評価)とPinterest(150万回評価)で実験
- Leave-one-outを使ってデータを分割
- ヒット率とNDCGを$@$5, $@$10で評価
- 既存の行列分解よりも優位なことを主張
- 今回の実験
- 原著実装ではテストセットを使ってエポック数を調節していたため、不適切。今回は学習セットでエポック数を最適化
- 原著ではItemKNNのハイパーパラメータを$k$のみ調節していたが、今回はすべてを最適化
- シンプルな線形手法であるSLIMを比較手法として用意
- 結論
- すべての指標で複数の古典的手法に敗北
- MovieLensでは線形手法であるSLIMにすべての指標で敗北
12 Spectral Collaborative Filtering (SpectralCF)
コールドスタート問題を解決するために、スペクトラルグラフ理論をベースに作られたモデル。ユーザーアイテム間の二部グラフをグラフフーリエ変換で畳み込むらしい。
- 原著の実験
- MovieLens1M, HetRec, Amazon Instant Videoで実験
- バリデーションは80/20で学習とテストを分割
- いくつかのカットオフでリコールとMAPを測定
- MovieLensで筆者が学習とテストに使用したデータセットが公開されている
- 原著ではあるデータセットで決定した(おそらく比較手法の)ハイパーパラメータをすべてのデータセットに適用している(!)
- 今回の実験
- 原著の設定はおかしいので、それぞれのデータセットでハイパーパラメータを最適化しなおした
- 結論
- すべての指標ですべての古典的手法に敗北(!!)
- が、原著で提供されたデータセットで実験すると何故かすべての比較手法に圧勝する…
- 筆者が調べたところ、原著データは明らかにランダムサンプリングされたものと異なる分布を示すデータ分割になっていた
- 本来は人気アイテムが偏っているが、提供されたデータのテストセットはなぜか偏りが抑制されていた…
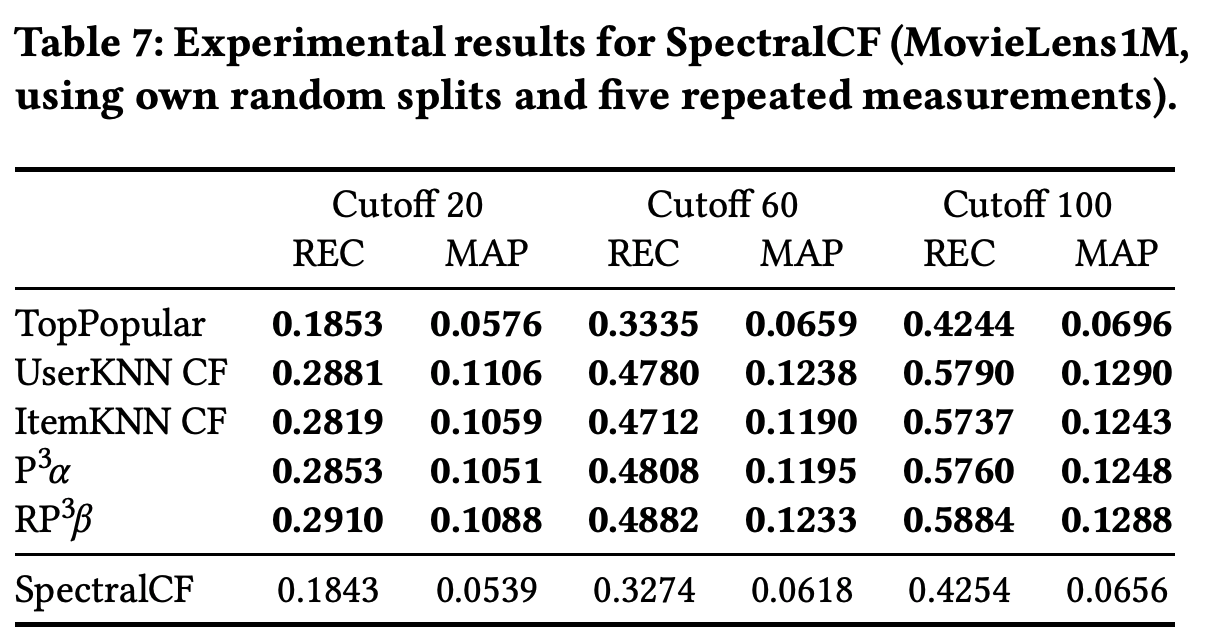
人気度分布の異常な差を示した図

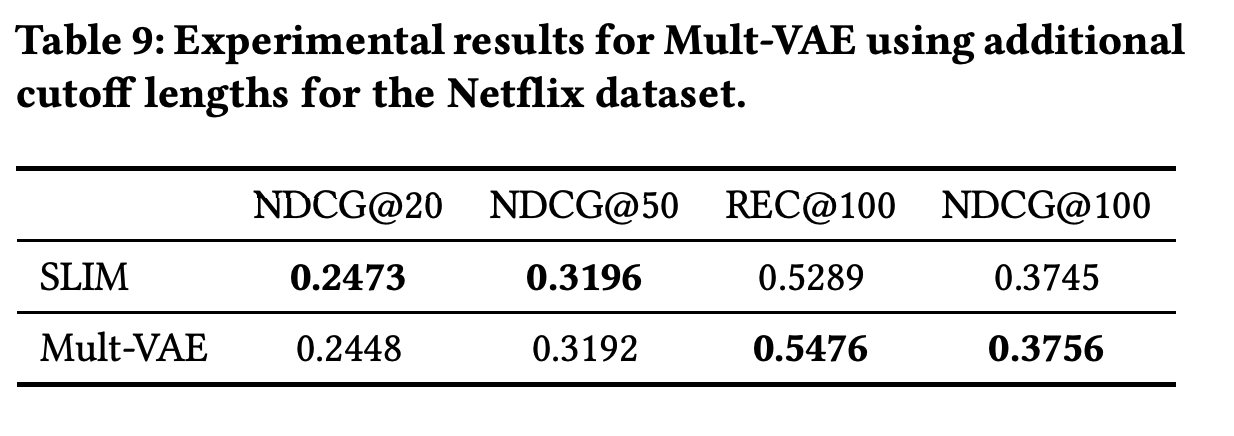
13 Variational Autoencoders for Collaborative Filtering (Mult-VAE)
変分オートエンコーダー(VAE)を使った暗黙的なフィードバックを利用するCF。多項尤度を持つ生成モデルを導入し、学習対象に対して異なる正則化項を設定して、ベイズ推論によってパラメータを推定する手法らしい。
-
原著の実験
- 映画の評価(おそらくMovieLens)や歌の再生回数を二値化して利用
- 実装とデータセットが提供され、行列分解、線形モデル、NNベースの手法と比較
- リコール(at20, at50)とNDCG(at100)を指標として、比較手法より3%ほど優れた結果になっている
-
今回の実験
- Netflixで良い性能をだしたSLIMも比較手法に追加して、非NN手法よりも優位であるという主張を検証することにした
-
結論
- 比較手法として用意したすべての古典的手法に対して各指標で10%〜20%ほど優れていた

- ただし、SLIMに対してはあまり大きな差はみられなかった
- とくにNDCG@100はほとんど差はない
- カットオフの値が一定でない(REC@(20or50), NDCG@100)ため、リコールとNDCGのカットオフの値を揃えて実験した
- すると、原著に記載されてなかったREC@100, NDCG@100ではSLIMが優位だった
- つまりNNの導入により、非NN手法より性能が向上したという主張は検証できなかった
- 比較手法として用意したすべての古典的手法に対して各指標で10%〜20%ほど優れていた

SLIMとの比較
DNN推薦における問題点
スケーラビリティと再現性
- 再現性が低すぎる
- 論文を読んで再現できた手法が7/18しかない
- 再現できたものに関しても、ハイパラやデータの前処理、評価方法などが開示されてないものがあり再現が難しい
- 計算コストが高すぎ、スケーラビリティがない
- 数年前はNetflixの100Mデータセットで検証することが業界標準だったが、いまは100Kで許される
- 100KですらGPUを使ってもハイパラの最適化に数日〜数週間かかる手法もあるためか?
- (RecSysでの発表によると、)筆者らもすべてのDNN実験を再現するために、253日もAWSを使い倒した…

- kNNもスケーラビリティ問題はあるが、適切なサンプリングにより対処できる
- 数年前はNetflixの100Mデータセットで検証することが業界標準だったが、いまは100Kで許される
改善幅の計測
- 比較したベースラインに関する詳細な情報が提供されてない
- 本当に適切な最適化や前処理を行ったのか検証できない
- ベースラインに対するデータ分割、評価手段、実装に関して間違いのある論文も発見した
- DNN手法の比較相手になりがちなNCFは本当に強いのか?
- NCFはあるデータセットではシンプルな手法に負けており、他のデータセットでも圧勝しているわけではない
- 線形回帰にさえ負けるデータセットもある
- NCFはあるデータセットではシンプルな手法に負けており、他のデータセットでも圧勝しているわけではない
- 評価データセットと評価指標が多すぎて比較できない
- 世の中には20種類以上の公開データセットがあるが、だいたい適当に1,2個を選んで実験している
- たくさんの評価指標
- Precision, Recall, MAP, NDCG, MRR
- たくさんのバリデーション方法
- random holdout 80/20, leave-last-out, leave-one-out, 100 negative items or 50 negative items for each positive
- topNといっても色々な評価方法がある
- N位までにできるだけ多くの関連アイテムを出す
- 1つのアイテムが上位に入れば入るほどよい
- MovieLensの評価値の予測指標が改善したからと言って、(他の種類の)推薦タスクの体験が改善するわけではない
今後の進展
- 行列分解をベースとしたアルゴリズム全般にも同じ実験をやっていきたい
- ( 本当にありがたいことです
 )
)
- ( 本当にありがたいことです
感想
- 最近、推薦分野もNNでどんどん進捗でてるなと、ちゃんと再現実験もせずに思っていたので衝撃を受けました…。
- この論文を執筆するための筆者らの多大な努力を感じました。素晴らしい仕事です。
- すべてが実装、データ、条件付きで公開され、こういう論文がベストペーパーに選ばれるのは当然だし素晴らしいことだと思いました。