はじめに
先日、Tesseract を実際に試しに使って、OCRの精度がどのくらい出るのか試してみたが、PCで作成された標準フォントのプリント画像であれば、それなりの精度は出そうなことが分かった。(スキャンによるノイズや画像の傾きなどの影響を受けて認識精度が悪化しそうではある)
しかし、手書き部分に関しては壊滅的に認識できていなく、日本語の手書き文字においては、クラウドのAzureが良さそうだとのことだった。
今回は、Tesseractでは全くダメだった手書き部分を、クラウドサービスではどの程度完璧に読めそうなのか試してみようと思う。
今回試す Azure のサービス名は 【Cognitive Service / Computer Vision(Read API)】 というものになる。
※帳票や請求書読み取りに使われる Form Recognizer というサービスもあるが、それはまた違う機会に。
前提条件
【PC環境】
Windows 10 Pro
【SW or Packageのバージョン】
Python 3.9.13
Computer Vision(Read API)の使い方と結果
1.Azure アカウントを作り、Read API 利用に必要な情報をメモしておく
2.Python から【Read API】を使用するコードサンプル
3.【Read API】を使ったOCRの結果確認
1.Azure アカウントを作り、Read API 利用に必要な情報をメモしておく
・Azureコンソールにログインし、 "Computer Vision" のリソースを作成する。
※1. 本記事ではアカウント自体の作り方は省略
対応言語や、入力データの制限については以下の公式サイトを参考に。
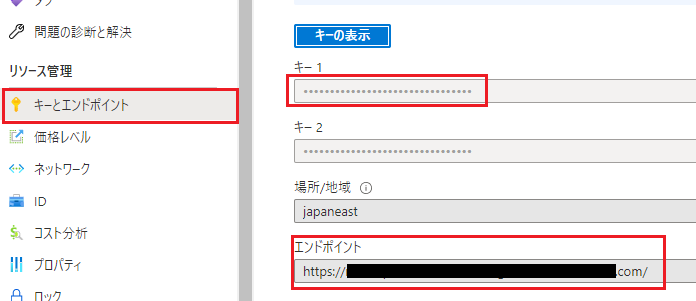
・Read API のサービスを外部から呼び出すために以下の情報をメモしておく・
・APIキー
・エンドポイントのURL
2.Python から【Read API】を使用するコードサンプル
Python から【Read API】を使用する方法は、自分が試してみた感じでは大きく2つ。
① ComputerVisionのサービスを利用するPythonライブラリを使う。
② REST-API で呼び出し JSON形式で受け取る
それぞれのサンプルコードを以下に記載。
① ComputerVisionのサービスを利用するPythonライブラリを使う。
公式ページのクイックスタート(Python)に書かれているのはこっちのやり方。
まずは必要なpythonパッケージをインストール。
pip install --upgrade azure-cognitiveservices-vision-computervision
※ Azure利用とは直接関係がないパッケージは必要に応じて追加すること。
from azure.cognitiveservices.vision.computervision import ComputerVisionClient
from azure.cognitiveservices.vision.computervision.models import OperationStatusCodes
from azure.cognitiveservices.vision.computervision.models import VisualFeatureTypes
from msrest.authentication import CognitiveServicesCredentials
from array import array
import os
from PIL import Image
import sys
import time
# APIキー と エンドポイントを設定
subscription_key = "*************************************"
endpoint = "https://*******************************.azure.com/"
# ComputerVisionを操作するクライアントのインスタンス化
computervision_client = ComputerVisionClient(endpoint, CognitiveServicesCredentials(subscription_key))
print("===== Read File - remote =====")
###############################
# Webでアクセスできる画像ファイル に OCRをする場合
###############################
# Read API に投げる部分
read_image_url = "https://raw.githubusercontent.com/MicrosoftDocs/azure-docs/master/articles/cognitive-services/Computer-vision/Images/readsample.jpg"
read_response = computervision_client.read(read_image_url, raw=True, model_version="2022-04-30" )
# 結果を受け取る部分
read_operation_location = read_response.headers["Operation-Location"]
operation_id = read_operation_location.split("/")[-1]
while True:
read_result = computervision_client.get_read_result(operation_id)
if read_result.status not in ['notStarted', 'running']:
break
time.sleep(1)
if read_result.status == OperationStatusCodes.succeeded:
for text_result in read_result.analyze_result.read_results:
for line in text_result.lines:
print(line.text)
print(line.bounding_box)
print('END - Read File - remote')
###############################
# ローカルのバイナリデータ(画像ファイル)に OCRをする場合
###############################
local_image = open('【画像ファイルのパス】', "rb") # pdfファイルではなぜかできなかった。。。
ocr_result_local = computervision_client.recognize_printed_text_in_stream(local_image, language="ja")
for region in ocr_result_local.regions:
for line in region.lines:
#print("Bounding box: {}".format(line.bounding_box))
s = ""
for word in line.words:
s += word.text + ""
print(s)
② REST-API で呼び出し JSON形式で受け取る。
import requests
import time
# APIキー と エンドポイントを設定
subscription_key = "*************************************"
endpoint = "https://*******************************.azure.com/"
read_api_url = f'{endpoint}/vision/v3.2/read/analyze'
print('リクエスト投げるURL:', read_api_url)
###############################
# リクエストのタイミングで投げるパラメータやヘッダー情報の設定
###############################
binary_data = True
# ローカルにある画像ファイルでOCRする時はこちら
if binary_data:
# ヘッダー情報、
request_headers = {
# Request headers
"Content-Type": "application/octet-stream", # バイナリデータの場合、application/octet-stream テキスト:json
"Ocp-Apim-Subscription-Key": subscription_key,
}
# 画像データそのもの
body = open('【画像ファイルパス】', "rb").read() # pdfファイルでもそのまま OCR できた。
# Web経由でアクセスできる画像ファイルの場合はこちら
else:
# ヘッダー情報、
request_headers = {
# Request headers
"Content-Type": "application/json", # バイナリデータの場合、application/octet-stream テキスト:json
"Ocp-Apim-Subscription-Key": subscription_key,
}
# 本文として送るもの ※ \ の部分が入っていないとリクエストが上手くいかなかったので注意!
body = "{\"url\":\"https://raw.githubusercontent.com/MicrosoftDocs/azure-docs/master/articles/cognitive-services/Computer-vision/Images/readsample.jpg\"}"
# モデルバージョンや、解析言語の設定
params = {
# Request parameters
"language": "ja",
#'pages': '{string}',
#'readingOrder': '{string}', basic or natural Default ⇒ basic
"model-version": "2022-04-30",
}
###############################
# OCR後の結果受け取りに必要
###############################
result_headers = {
"Ocp-Apim-Subscription-Key": subscription_key,
}
###############################
# OCR の実行と結果受け取り
###############################
# 指定した画像に対して OCR をかける。これによって operation ID が返され、画像の内容を読み取る非同期プロセスが開始されます。
response = requests.post(read_api_url, headers=request_headers, params=params, data=body)
response.raise_for_status()
print('【ヘッダー情報の出力】\n ', response.headers)
# 非同期プロセスのため、結果受け取りは少し待つ必要がある。
time.sleep(10)
Ope_LoC = response.headers['Operation-Location']
print('結果受け取り先URL: ', Ope_LoC)
result= requests.get(Ope_LoC, headers=result_headers)
result.raise_for_status()
result.json()
3.【Read API】を使ったOCRの結果確認
Read API に投げた画像は、Tesseractで全く認識できなかった手書き部分のある画像。(下図はTesseractでOCRした時)

こちらを Read API で読み取った時の結果が以下。

⇒ 日本語の OCR は強いという話は聞いていたが想定以上!!!誤認識は一文字だけ。