はじめに
オライリーのスクレイピングの本を読んでいた時、Tesseract について少し説明があった。
入手可能なオープンソースOCRの中で "最良で最も正確" と書かれていたため、どのくらいの精度が出るものなのか試しに確認してみたので、その時の内容をメモとして残す。
前提条件
【PC環境】
Windows 10 Pro
【SW or Packageのバージョン】
tesseract 5.2.0
Python 3.9.13
pyocr 0.8.3
OpenCV 4.6.0.66
メモ内容
1.Tesseract・pyocr のセットアップ。
2.いくつかの画像パターンで認識精度を確認してみる。
1.Tesseract・pyocr のセットアップ
Tesseract のセットアップ
以下のサイトより、Tesseract のインストーラーをダウンロードする。
※インストールの際にコンポーネントを選択する画面が出るが、そこで日本語にチェックを入れておく。
正常にインストールができたら、ちゃんと動くか確認してみるため、コマンドプロンプトを立ち上げ以下を実行する。
C:\Users\******\Documents>"C:\Program Files\Tesseract-OCR\tesseract.exe" [テスト画像パス] [出力ファイル名] -l jpn
※自分は、以下のサイトのテスト画像を拝借した。(サイトの下の方)
pyocr のセットアップ
コマンドプロンプトで以下を実行。(自分は仮想環境をアクティブにして、そこでインストールした。)
pip install pyocr
※その他、numpy pandas matplotlib opencv あたりの標準的なパッケージは入れている。
以下のコードが動けば、セットアップは完了。
from PIL import Image
import pyocr
# tesseract コマンドのパスをセット。
pyocr.tesseract.TESSERACT_CMD = r'C:\Program Files\Tesseract-OCR\tesseract.exe'
tools = pyocr.get_available_tools()
tool = tools[0]
# 読み取りファイルのパス指定
sample_img = Image.open('[テスト画像パス]')
# 読み取り制度の設定
builder = pyocr.builders.TextBuilder(tesseract_layout=6)
# 読み取り実行
text = tool.image_to_string(sample_img, lang="jpn", builder=builder)
print(text)
※ 試しに選んだ画像は、PCで作成された標準フォントの文字認識だったため、かなり高い精度で認識できていた。
少し古い情報だが、細かいオプションはこちらのサイトを参考にした。
2.いくつかの画像パターンで認識精度を確認してみる
以下3つの画像で tesseract-OCR の精度を試してみました。
① テンプレートのpdfをそのままOCR
② テンプレートを1度プリントして、スキャンしたpdfファイルをOCR
※手書きではないが、プリント & スキャンによるノイズが混じることで認識精度がどのくらい落ちるのか確認。
③ テンプレートに手書き文字を加えたものをスキャンしてOCR
※ 検証用のテンプレートには、以下のサイトのものを使わさせていただきました。
↓ 今回のテストで使った画像
https://pdf.wondershare.jp/images/templates/pdf-templates/invoice-standard.jpg
●追加セットアップ
pdfの変換は標準モジュールではできないので、pdf2imageというモジュールを使う必要がある。
pdf2image モジュールは、変換の際にPopplerという外部ツールを呼び出すため、Poppler と pdf2image の両方をそれぞれセットアップする必要がある。
poppler のセットアップ
以下サイトよりzipファイルをダウンロードし、任意のフォルダに展開。
展開したフォルダ内の ***\Library\bin までのパスを環境変数にセットする。
セット後、コマンドプロンプトを立ち上げ、以下のコマンドが実行できればOK。
pdfinfo -listenc
pdf2image のセットアップ
pip install pdf2image
●OCRの実験結果
pdfファイルでOCRをする場合のpythonコードサンプルは以下の様な感じ。
import numpy as np
import pdf2image
import pyocr
import cv2
# tesseract コマンドのパスをセット。
pyocr.tesseract.TESSERACT_CMD = r'C:\Program Files\Tesseract-OCR\tesseract.exe'
tools = pyocr.get_available_tools()
tool = tools[0]
# pdfから画像オブジェクトに変換
images = pdf2image.convert_from_path("./invoice-standard.pdf", fmt='jpg')
######################################
# 画像を表示するために OpenCV で扱える様に変換
######################################
cvimage = np.asarray(images[0])
cvimage = cv2.cvtColor(cvimage, cv2.COLOR_BGR2GRAY)
#cvimage = cv2.cvtColor(cvimage, cv2.COLOR_RGB2BGR)
print(cvimage.shape)
cv2.imshow("image", cvimage)
cv2.waitKey(0)
cv2.destroyAllWindows()
######################################
# OCR テスト
######################################
# 読み取り精度の設定(テキスト全体)
builder = pyocr.builders.TextBuilder(tesseract_layout=3)
# 読み取り実行
for image in images:
text = tool.image_to_string(image, lang="jpn", builder=builder)
print(text)
# 読み取り(単語単位 - 画像内の位置座標付き )
print('\n■WordBoxBuilder : 単語単位(画像内の位置座標付き)--------------')
for image in images:
word_box = tool.image_to_string(image, lang="jpn" , builder=pyocr.builders.WordBoxBuilder())
for box in word_box:
print("word: {}, pos: {}".format(box.content, box.position))
# 読み取り(単語単位 - 画像内の位置座標付き )
print('\n■LineBoxBuilder : 行単位(画像内の位置座標付き)--------------')
for image in images:
word_line = tool.image_to_string(image, lang="jpn" , builder=pyocr.builders.LineBoxBuilder ())
for line in word_line:
print("word: {}, pos: {}".format(line.content, line.position))
import numpy as np
import pdf2image
import pyocr
import cv2
from PIL import Image
# tesseract コマンドのパスをセット。
pyocr.tesseract.TESSERACT_CMD = r'C:\Program Files\Tesseract-OCR\tesseract.exe'
tools = pyocr.get_available_tools()
tool = tools[0]
# pdfから画像オブジェクトに変換
images = pdf2image.convert_from_path("./invoice-standard.pdf", fmt='jpg')
######################################
# 画像を表示するために OpenCV で扱える様に変換
######################################
cvimage = np.asarray(images[0])
#cvimage = cv2.cvtColor(cvimage, cv2.COLOR_BGR2GRAY)
cvimage = cv2.cvtColor(cvimage, cv2.COLOR_RGB2BGR)
print(cvimage.shape)
#####################
#
#
# 画像処理のコードを加えて
#
#
####################
new_image = Image.fromarray(cvimage)
######################################
# OCR テスト
######################################
# 読み取り精度の設定(テキスト全体)
text = tool.image_to_string(new_image, lang="jpn", builder= pyocr.builders.TextBuilder(tesseract_layout=3))
print(text)
# 読み取り(単語単位 - 画像内の位置座標付き )
print('\n■WordBoxBuilder : 単語単位(画像内の位置座標付き)--------------')
word_box = tool.image_to_string(new_image, lang="jpn" , builder=pyocr.builders.WordBoxBuilder())
for box in word_box:
print("word: {}, pos: {}".format(box.content, box.position))
# 読み取り(単語単位 - 画像内の位置座標付き )
print('\n■LineBoxBuilder : 行単位(画像内の位置座標付き)--------------')
word_line = tool.image_to_string(new_image, lang="jpn" , builder=pyocr.builders.LineBoxBuilder ())
for line in word_line:
print("word: {}, pos: {}".format(line.content, line.position))
① テンプレートのpdfをそのままOCR
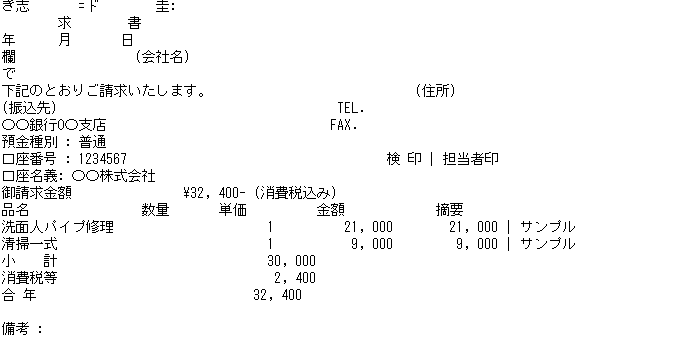
⇒ 元々がPCで作成された様なフォーマットだったため、かなり良い感じ。
② テンプレートを1度プリントして、スキャンしたpdfファイルをOCR
コンビニの複合機を使ってプリント & スキャンをしているため、家庭用のものよりは多少は性能が良いはず。。。
・少し用紙を傾けてスキャンした画像パターン
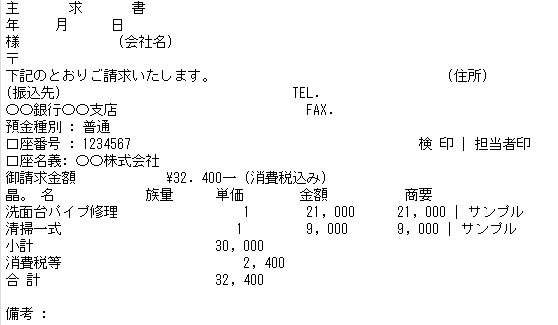
⇒ ほんの一部だけ誤認識があるが、一度プリントしてスキャンしたことによるノイズなのか、傾きによる影響なのかは不明。
・かなり用紙を傾けたパターン

⇒ 同じく誤認識があるが、それよりも文字自体が認識されていない傾向が強そう。
③ テンプレートに手書き文字を加えたものをスキャンしてOCR
用紙は傾けず、いくつか手書き文字を追加してスキャンした画像を用意。
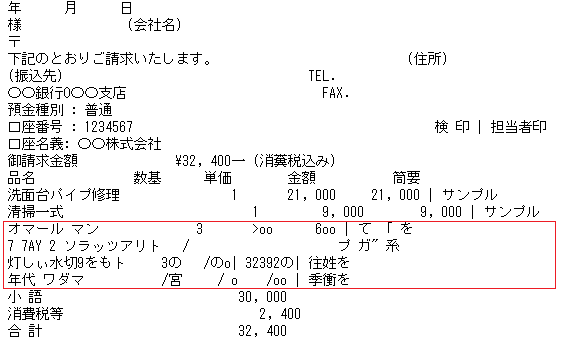
⇒ 想定以上に手書き部分は認識できていない。 ※ちなみに手書き部分のpdf画像は下図の様な感じ。
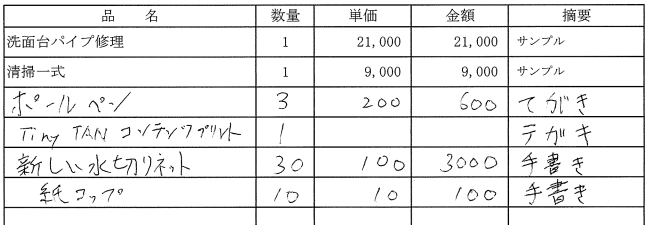
まとめ
元々PCで作成された書式であれば(フォント次第な部分もあるが)、Tesseract である程度の文字認識はできそう。
しかし、手書き文字は全然ダメっぽい。
今のところ、日本語手書き文字をOCRしたいなら、クラウドのサービスを使う方が無難かと思う。
クラウドのOCRサービスの比較については、以下の記事がとても参考になった。