はじめに
先日Kaggleの言語モデルのコンペに参加し、日本語の前処理の方法も少しメモを残しておこうと思った。(結構前にやったきりあまり触れていなかったので。。。)
まずは基本的な形態素解析の実装方法くらいを今回の記事にまとめる。
前提条件
【PC環境】
Windows 10 Pro
【ローカル環境のpython.Ver】
python 3.9.5
【仮想環境のpython.Ver】
python 3.9.5
仮想環境を作成することはマストではないが、一旦テストが終わったら丸っと削除するつもりなので、今回は仮想環境で作業している。
手順
1.MeCab、Janome の準備/インストール
2.各ライブラリで形態素解析
1.MeCab、Janome の準備/インストール
MeCab の準備/インストール
・WindowsにMeCabのダウンロード
32bit版:MeCabの公式サイトからダウンロードする
64bit版:有志がビルドしたもの。こちらのサイトからダウンロード。
※今回は64bit版をダウンロード。文字コードはUTF-8を選択する。
・パスを設定
Windowsの環境変数Pathに C:\Program Files\MeCab\binを追加する。
試しにコマンドプロンプトを立ち上げ、以下の様に実行して何かしらレスポンスが返ってくればOK。
> mecab
庭には二羽鶏がいます。
庭には二 險伜捷,荳闊ャ,*,*,*,*,*
H 蜷崎ゥ・蝗コ譛牙錐隧・邨・ケ・*,*,*,*
險伜捷,荳闊ャ,*,*,*,*,*
{ 蜷崎ゥ・繧オ螟画磁邯・*,*,*,*,*
がいます 險伜捷,荳闊ャ,*,*,*,*,*
B 蜷崎ゥ・蝗コ譛牙錐隧・邨・ケ・*,*,*,*
EOS
・Pythonパッケージのインストール
pip install ipykernel
pip install mecab-python3
import MeCab で問題なくインポートできれば、一旦はOK!
Janome の準備/インストール
PurePythonで書かれている形態素解析ツールのため、pip によるインストールのみで完結。
pip install janome
同じくimport janome で問題なくインポートできればOK!
仮想環境をjupyter notebookで利用するため以下を実行。
ipython kernel install --user --name=【任意の名称】
2.各ライブラリで形態素解析
そもそも形態素解析の機能についてだが、最低限以下の3つを有している事が一般的らしい。
・分かち書き(文章を形態素で分ける)
・品詞わけ(名詞や動詞などに分類する)
・原型付与(単語の基本形をだす)
今回は上記の処理を使い、以下の①~③の文章から、[名詞]、[動詞]、[形容詞] の辞書を作り、各文章のそれぞれの単語の出現度数を計算する
処理をMeCab と janome を使い実装してみる。
① 私はりんごは好きだけど、バナナは好きではない。なぜなら、バナナには水分が多く含まれていないため、果物特有の瑞々しさを感じないからだ。同じような理由で、パンもそんなに好きではない。どちらかと言えば、ご飯やうどんの方が好きだ。
② 『寒いと言うほど余計に寒くなるから、寒い時に寒いと言わない方がいい!』と主張する奴が時々いるが、何を根拠にその様な主張をしているのだろう?実際のところ、寒い寒いと連呼している方が、多少なりとも筋肉が動くため、黙ってじっとしているよりはマシなのではないか。
③ 花より団子、あなたは花と団子どちらが好きですか?花を見て楽しむのいいですが、美味しいリンゴやバナナを食べるのもまた至福のひと時ですよね。
MeCab の利用
以下のコードをnotebookにコピペすれば動く。
# ライブラリインポート
import numpy as np
import pandas as pd
import MeCab
import collections
# pandasのdisplayによる表示行を調整
pd.options.display.max_rows = 200
# MeCabpのインスタンスを作成
m = MeCab.Tagger ("-Ochasen")
# テスト文章の準備
sentence1 = '私はりんごは好きだけど、バナナは好きではない。なぜなら、バナナには水分が多く含まれていないため、果物特有の瑞々しさを感じないからだ。同じような理由で、パンもそんなに好きではない。どちらかと言えば、ご飯やうどんの方が好きだ。'
sentence2 = '『寒いと言うほど余計に寒くなるから、寒い時に寒いと言わない方がいい!』と主張する奴が時々いるが、何を根拠にその様な主張をしているのだろう?実際のところ、寒い寒いと連呼している方が、多少なりとも筋肉が動くため、黙ってじっとしているよりはマシなのではないか。'
sentence3 = '花より団子、あなたは花と団子どちらが好きですか?花を見て楽しむのいいですが、美味しいリンゴやバナナを食べるのもまた至福のひと時ですよね。'
sentence_list = [sentence1, sentence2, sentence3]
# テキストに出現した単語(名詞、形容詞、動詞)の単語リストを作成
text_parse_list = []
for text in sentence_list:
text_parse_split1 = m.parse(text).split("\n")
for text_parse in text_parse_split1:
text_parse_split2 = text_parse.split("\t")
text_parse_list.append(text_parse_split2)
# DataFrameに入れる
alltext_words_df = pd.DataFrame(text_parse_list)
alltext_words_df.columns = ['keitaiso', 'yomi', 'gokan', 'hinshi', 'col5', 'col6']
alltext_words_df["hinshi"] = alltext_words_df["hinshi"].str.split('-').str[0]
alltext_words_df = alltext_words_df[(alltext_words_df["hinshi"] == '名詞') | (alltext_words_df["hinshi"] == '形容詞') | (alltext_words_df["hinshi"] == '動詞')]
alltext_words_df = alltext_words_df[alltext_words_df["keitaiso"].duplicated() == False]
#print(len(alltext_words_df))
#display(alltext_words_df)
# 各テキストの出現単語のカウント
words = [[], [], []]
for i, text in enumerate(sentence_list):
node = m.parseToNode(text)
words[i] = []
while node:
words[i].append(node.surface)
node = node.next
c0 = collections.Counter(words[0])
print(c0, "\n")
c1 = collections.Counter(words[1])
print(c1, "\n")
c2 = collections.Counter(words[2])
print(c2, "\n")
# 各テキストの出現単語のカウント(名詞、動詞、形容詞に絞り、上位50個の単語のみ)
words = [[], [], []]
for i, text in enumerate(sentence_list):
node = m.parseToNode(text)
words[i]=[]
while node:
hinshi = node.feature.split(",")[0]
if hinshi in ["名詞","動詞","形容詞"]:
words[i].append(node.surface)
node = node.next
c0 = collections.Counter(words[0])
print(c0.most_common(50), "\n")
c1 = collections.Counter(words[1])
print(c1.most_common(50), "\n")
c2 = collections.Counter(words[2])
print(c2.most_common(50), "\n")
# 単語リストとJOINするために、dfに変換。
sentence1_df = pd.DataFrame(c0.most_common(50))
sentence1_df.columns = ['keitaiso', 'sen1_freq']
# display(sentence1_df)
sentence2_df = pd.DataFrame(c1.most_common(50))
sentence2_df.columns = ['keitaiso', 'sen2_freq']
# display(sentence1_df)
sentence3_df = pd.DataFrame(c2.most_common(50))
sentence3_df.columns = ['keitaiso', 'sen3_freq']
# display(sentence3_df)
# 各テキストの出現単語のカウントテーブルと 最初に作成した単語リストを紐づけ
temp_df = pd.merge(alltext_words_df, sentence1_df, how="left", on="keitaiso")
temp_df = pd.merge(temp_df, sentence2_df, how="left", on="keitaiso")
temp_df = pd.merge(temp_df, sentence3_df, how="left", on="keitaiso")
display(temp_df)
最後のコマンドの実行により、以下の様な表が表示される。
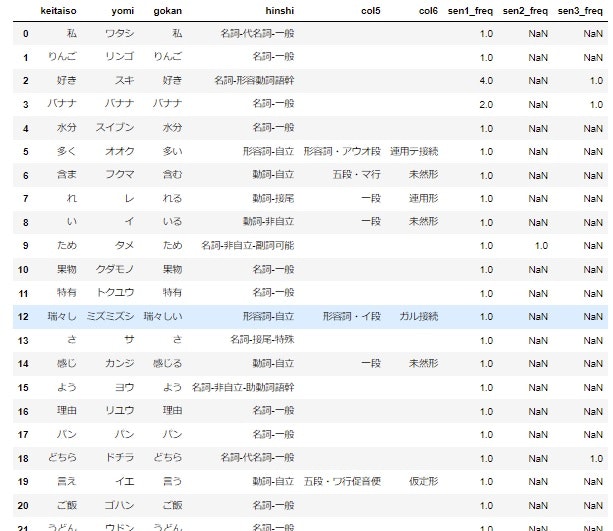
※集計したい内容によっては、この後さらに "語幹" でgroup by をかけてもいいかもしれない。
janome の利用
上記と同じ様な処理を janome でも試しに作って見た。
from janome.tokenizer import Tokenizer
t = Tokenizer()
# テスト文章の準備
sentence1 = '私はりんごは好きだけど、バナナは好きではない。なぜなら、バナナには水分が多く含まれていないため、果物特有の瑞々しさを感じないからだ。同じような理由で、パンもそんなに好きではない。どちらかと言えば、ご飯やうどんの方が好きだ。'
sentence2 = '『寒いと言うほど余計に寒くなるから、寒い時に寒いと言わない方がいい!』と主張する奴が時々いるが、何を根拠にその様な主張をしているのだろう?実際のところ、寒い寒いと連呼している方が、多少なりとも筋肉が動くため、黙ってじっとしているよりはマシなのではないか。'
sentence3 = '花より団子、あなたは花と団子どちらが好きですか?花を見て楽しむのいいですが、美味しいリンゴやバナナを食べるのもまた至福のひと時ですよね。'
sentence_list = [sentence1, sentence2, sentence3]
# 試しにどの様に取り出すのか確認
for i, token in enumerate(t.tokenize(sentence1)):
print(i, "\n")
print(token)
print('■表層形:', token.surface, ' ■品詞:', token.part_of_speech, ' ■活用形:', token.infl_type, '■基本形:', token.base_form, '■読み:', token.reading)
# テキストに出現した単語(名詞、形容詞、動詞)の単語リストを作成
text_parse_list = []
token_len = 0
for text in sentence_list:
for i, token in enumerate(t.tokenize(text)):
text_parse_list.append(token.surface)
text_parse_list.append(token.reading)
text_parse_list.append(token.base_form)
text_parse_list.append(token.part_of_speech.split(',')[0])
token_len += 1
# DataFrameに入れる
alltext_words_df = pd.DataFrame(np.array(text_parse_list).reshape(token_len, 4))
alltext_words_df.columns = ['keitaiso', 'yomi', 'gokan', 'hinshi']
alltext_words_df = alltext_words_df[(alltext_words_df["hinshi"] == '名詞') | (alltext_words_df["hinshi"] == '形容詞') | (alltext_words_df["hinshi"] == '動詞')]
alltext_words_df = alltext_words_df[alltext_words_df["keitaiso"].duplicated() == False]
#print(len(alltext_words_df))
#display(alltext_words_df)
# 各テキストの出現単語のカウント
c = [[], [], []]
for i, text in enumerate(sentence_list):
c[i] = collections.Counter(t.tokenize(text, wakati=True))
print(c[i], "\n")
print(c[i].most_common(50), "\n")
# 単語リストとJOINするために、dfに変換。
sentence1_df = pd.DataFrame(c[0].most_common(100))
sentence1_df.columns = ['keitaiso', 'sen1_freq']
# display(sentence1_df)
sentence2_df = pd.DataFrame(c[1].most_common(100))
sentence2_df.columns = ['keitaiso', 'sen2_freq']
# display(sentence1_df)
sentence3_df = pd.DataFrame(c[2].most_common(100))
sentence3_df.columns = ['keitaiso', 'sen3_freq']
# display(sentence3_df)
# 各テキストの出現単語のカウントテーブルと 最初に作成した単語リストを紐づけ
temp_df = pd.merge(alltext_words_df, sentence1_df, how="left", on="keitaiso")
temp_df = pd.merge(temp_df, sentence2_df, how="left", on="keitaiso")
temp_df = pd.merge(temp_df, sentence3_df, how="left", on="keitaiso")
display(temp_df)
最後のコマンドの実行後に表示される表。
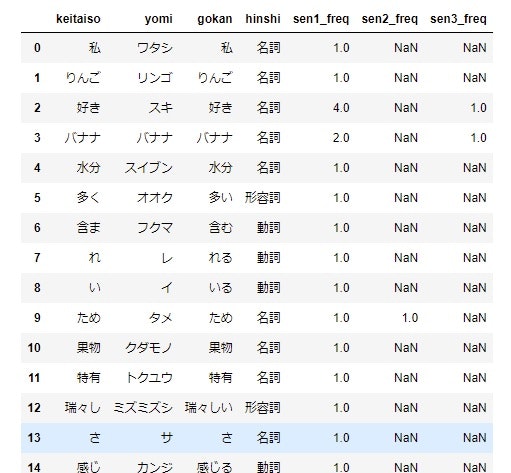
まとめ
今回は日本語の自然言語解析でまず最初に使われる形態素解析について、初歩的な実装の流れをまとめてみた。
また時間がある時に、ワードマップや、Bertなどのモデルを使った、文章分類、文章生成(要約)、感情分析なども試してみたいと思います。