はじめに
定期的な情報収集をしたかったため、スクレイピングのアプリを作ったのだが、今回はクラウド上(AWS の lambda)への移植を試みた。
結局 Selenium の起動が上手くいかず完成できていないのだが、これまでの備忘としてメモを残しておく。
使ったサービス & 主要ソフト
-
s3
-
lambda (lambda layer も利用)
-
Cloud9 (lambda layer に登録するための、パッケージやドライバーの取得に使用)
-
pytho3.9系
-
seleium 4.16.0
メモ内容
⓪ まずは前提
今回は Selenium を使うアプリだったので、ブラウザ挙動を確認する必要があった。
そのため、開発はローカルPC(Python3.9系)で行っている。
ちゃんと問題なく動くコードである事ができた上で、AWS上のサービスで作り直しする方法を検討(コードは基本的にそのまま移行の予定)
① 必要パッケージやドライバーの準備
Python自体のバージョンについては、lambdaのランタイムの設定を行うときに適切なバージョンを選べば良いので、あまり気にする必要ないのだが、selenium や beautifulsoup4 などの追加パッケージや、Chromeドライバーなどを lambda layerにセットする必要があるので、いくつか準備しなければいけない。
大きくは以下の作業が必要。
- 任意の s3 バケットを作成
-
pythonフォルダを作成し、必要なパッケージをそこに集める。(この時、パッケージ一覧に含まれる各ライブラリは、lambdaのランタイムのpythonバージョンで動くものとすること。) -
pythonフォルダをzip化し、作成したバケットに入れる。 - Chromeドライバー関連のファイルを取得し、
headlessフォルダに入れてzip化する。 -
python.zipと同じく、作成したバケットに入れる。
※ 最終的には s3バケット内に必要なzipファイルが入れば動くため、zipファイルの作成手順やアップロードの仕方は好きなやり方でOKだが、lambda の実行環境はlinux系OSのため、その環境下で動くパッケージやドライバーを用意しなければいけない!
そう考えると、Cloud9 を使ってしまう方が楽かもしれない。
Cloud9 を使って必要なzipファイルを準備する
python 環境のアップデート
-
Cloud9 IDE(Integrated Development Environment)を起動する。
-
Python のバージョンを確認。

-
pyenv を使って3.9系のpython 環境に切り替えられる様にする。
# pyenv導入
git clone https://github.com/pyenv/pyenv.git ~/.pyenv
# 確認コマンド
~/.pyenv/bin/pyenv --version
# パスを通すため、~/.bashrc に設定追加
$ cat << 'EOT' >> ~/.bashrc
export PATH="$HOME/.pyenv/bin:$PATH"
eval "$(pyenv init -)"
EOT
# 設定ファイルの反映
source ~/.bashrc
- Python 3.9系のインストール
# インストール可能なバージョンを確認
pyenv install --list | grep 3.9.
# 希望のPythonバージョンをインストール
pyenv install 3.9.18
※ 以下の警告が出てきた。
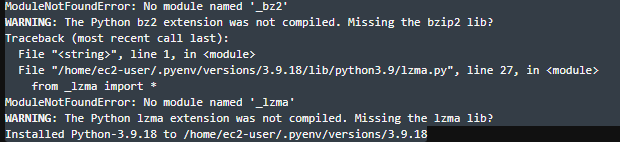
- 足りないパッゲージ
bzip2-develとxz-develをインストール
sudo yum -y update
sudo yum -y install bzip2-devel
sudo yum -y install xz-devel
# 確認
sudo yum list installed | grep bzip
sudo yum list installed | grep xz
- pythonバージョンを切り替える
pyenv global 3.9.18
# 確認
python -V
pip install --upgrade pip
スクレイピング用のpythonパッケージの準備
- pythonフォルダを作成して、その中にパッケージを取得。
mkdir python
cd python
pip install beautifulsoup4 -t .
pip install requests -t .
pip install selenium -t .
- pythonフォルダのzip化
cd ..
zip -r python python
Chrome-driver の準備
ダウンロードするドライバーのバージョンについては、こちらのサイトを参考にしながら調べてみたが、結局のところ自分は上手くいかなかった。
恐らく、今回のランタイム(Python 3.9)と Chromeドライバーのバージョンが上手く嚙み合わっていないことが原因!
- chromedriver の保存用ディレクトリを用意する。
mkdir headless
cd headless
- 任意の headless-chromium をダウンロードして、unzip、不要ファイルを削除する。
curl -SL https://github.com/adieuadieu/serverless-chrome/releases/download/v1.0.0-55/stable-headless-chromium-amazonlinux-2017-03.zip > headless-chromium.zip
unzip -o headless-chromium.zip -d .
rm headless-chromium.zip
- 同様に chromedriver をダウンロードして、unzip、不要ファイルを削除する。
curl -SL https://chromedriver.storage.googleapis.com/2.43/chromedriver_linux64.zip > chromedriver.zip
unzip -o chromedriver.zip -d .
rm chromedriver.zip
- headless フォルダのzip化
cd ..
zip -r headless headless
上記2つのzipファイルをS3にアップロード
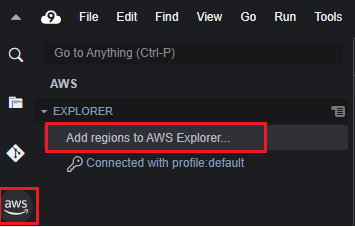
-
Cloud9 左パネルのAWSロゴマークをクリックし、
Add regions to AWS Explorer...をクリック。バケットのあるリージョンを選択する。
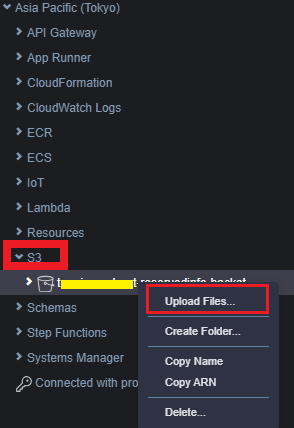
-
S3内の対象のバケットに対して、ファイルをアップロードすることができる。
S3 にzipファイルが置ければ、lambdaレイヤーへの参照は全く難しくないので割愛!
いざ試してみるが上手くいかず、、、
lambdaレイヤー自体の作成と、lambdaへのレイヤー追加をした後、以下の様なコードを実行したが動きませんでした。。。
# Selenium 4
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from bs4 import BeautifulSoup
from time import sleep
import datetime
from dateutil.relativedelta import relativedelta
import re
import json
def lambda_handler(event, context):
URL = "https://news.yahoo.co.jp/"
chromedriver_path = "/opt/headless/chromedriver"
service = Service(chromedriver_path)
options = Options()
options.add_argument("--headless")
options.add_argument("--single-process")
options.add_argument("--no-sandbox")
#ブラウザの定義
browser = webdriver.Chrome(
service=service
,options=options
)
browser.get(URL)
title = browser.title
browser.close()
print("ドライバー終了")
print("取得したタイトル ", title)
{
"errorMessage": "Message: Service /opt/headless/chromedriver unexpectedly exited. Status code was: 127\n",
"errorType": "WebDriverException",
最後に
色々とChromeバージョンの組み合わせを変えたり、エラー原因を調査してみたが、『ランタイムPython3.8系以上で、OSがAmazon Linux2』 になってしまっている事が原因の根幹になっていそう。。。
他のサイトにも助言があったのだが、docker で作った方が良いのかもしれない。
上記の解決方法、分かる方いましたらコメントいただけると嬉しいです。