最近ブロックチェーンが流行っており、HyperledgerやEthereumなどのブロックチェーンのプラットフォームの開発が活発です。本日は、ブロックチェーンを利用したクラウドストレージサービスの「Storj」について解説します。
Storjとは
「ストージ」と発音するようです。Storjの利用者は、P2P型のネットワークを形成したネットワーク内の他人のPCにファイルを保存し、その対価として仮想通貨(Storjcoin X: 通称SJCX)を払います。また、自分自身のPCに他人のファイルを保存すると、SJCXを受け取ることができます。
あるファイルは、断片化され暗号化された後に、複数のPCに保存されることになります。ファイルの断片の保存場所は、Storjのブロックチェーン内に保存します。従来のサーバー・クライアント型のクラウドストレージサービスと比較して、安価・安全である、というのがStorjの中の人の主張です。おそらく、従来のクラウドストレージサービスのようなデータセンタを維持するコストが必要ないため安価にサービスを提供でき、かつ各ファイルは断片化されるため安全である、と言いたいのだと思います。では、Storjがどのような仕組みになっているか見てみましょう。
断片化されたファイル
下の図(Storj Whitepaperより引用)のように、Storjに参加しているあるPCがファイルを保存しようとすると、まずそのPC上でファイルが32MB単位のShardと呼ばれる断片に分割されます。32MBに満たない断片はゼロでパディングされます。ついで、各断片が暗号化されます。最後に、ファイルがP2Pのネットワーク内に転送されます。
")
Proof-of-Storage
各ファイルは断片化され、P2Pのネットワーク内に保存されます。このP2Pのネットワーク内のPCは、基本的に信用出来ないものとして見なされます。つまり、悪意のあるPCがディスクに保存した他人のファイルの断片の内容を書き換えてしまう可能性を排除していません。そこで、Storjではあるファイルの断片が書き換えれていないかを検証する仕組みとして、Markle Tree (ハッシュ木)と呼ばれるものを利用しています。
Markle Treeとは、二分木の一種です。ビットコインのブロックチェーンでも取引の整合性を検証するために利用されています。下の図のように、あるファイルの各Shardのハッシュ値を計算し、それぞれを木構造の葉とします。さらに、二つのハッシュ値を連結して得られた値からハッシュ値を計算し、それぞれの葉の親ノードとします。最終的に、各Shardの値に依存したTop Hash(木構造の根)が得られます。例えば、下の図の例ではShard0からHash0、Shard1からHash1というハッシュ値が得られます。その親であるHash0+1は、Hash0とHash1の値を連結し、ハッシュ値を計算することで得られます。Top Hashの値はHash0+1とHash2+3の値を連結して計算したハッシュ値です。
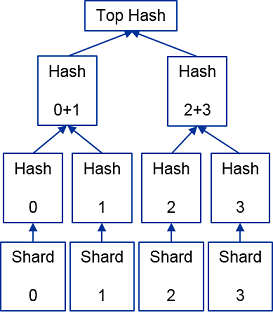
このような木構造を作っておくと、あるShardの整合性を検証するには木の中の一部のハッシュ値だけダウンロードできれば充分です。たとえば、Shard0の値が書き換わっていないかどうかを確かめるためには、Hash1、Hash2+3、およびTop Hashの値があれば可能です。Shard0の値からHash0の値が計算でき、Hash0とHash1からHash0+1の値が計算できます。さらに、Hash0+1とHash2+3から計算したハッシュ値と、ダウンロードしたTop Hashの値が等しければ、Shard0の内容は書き換わっていないと言えます。あるファイルがN個のShardに分割されたとすると、あるShardの整合性の検証にはハッシュ値をlog(N)回計算すれば良く、効率よく検証が可能です。
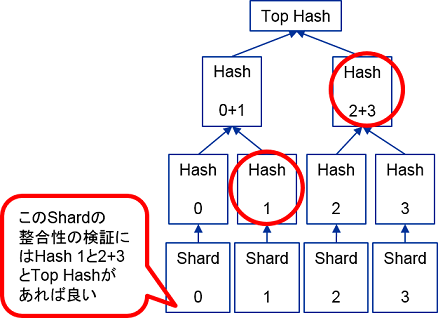
あるファイルをStorjに保存したPCは、定期的に保存先のPCに対してShardの整合性を確認します。上の仕組みを使って、Shardの内容が書き換わっていないことが確認できれば、そのPCはShardの保存先のPCに対してSJCXを送金します。Shardの内容が書き換わっている場合は、送金しません。
Storjでは、このように報酬でもってShardの書き換えを起きにくくさせ、また書き換えが起きたとしてもMerkle Treeによって効率よく検知することができます。
Proof-of-Redundancy
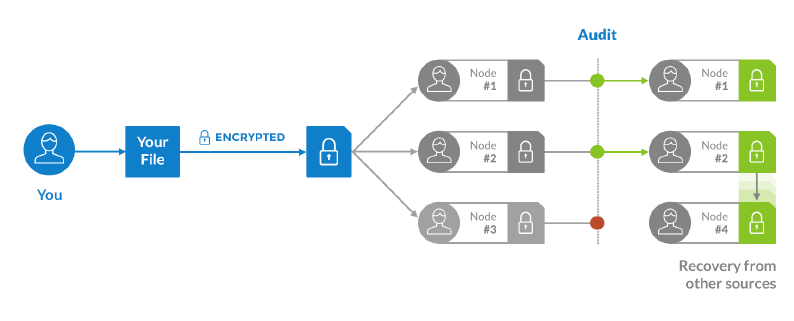
P2P型のネットワークでは、あるPCが突然シャットダウンすることもあり得ます。各Shardを1つずつしか保存していない場合、あるShardを保存したPCがシャットダウンしてしまうと、そのShardを含んだファイルを復元できないことになってしまいます。Storjでは、このような事態を避けるために、各Shardの複製をP2Pネットワーク内の異なるPCに保存しておきます。Proof-of-Storageの仕組みであるShardの整合性が確認できなかった場合、下の図(Storj Whitepaperより引用)のように、同じ内容のShardを保存した別のPCからさらに別のPCにShardをコピーすることによって、Shardの冗長性を保証します。
Storjのブロックチェーン
Storjでは、ファイルのメタデータをブロックチェーンに保存します。ファイルのメタデータとは、ファイルのハッシュ値、各Shardの保存場所、Merkle TreeのTop Hashなどです。ブロックチェーン内に保存されるファイルのメタデータはP2Pネットワーク内のPC間で合意が取れた内容です。この記事でも解説したビットコインのブロックチェーンを利用しているため、ブロックチェーンの書き換えもほぼ起きえません。
おわりに
今回は、ブロックチェーンを利用したクラウドストレージサービスである「Storj」の仕組みについて解説してみました。ファイルを断片化・暗号化して保存することにより安全性を高め、各断片の整合性を効率よくする検証する仕組みを導入し、冗長性を高めることでPCがシャットダウンしてもデータを取り出すことができる、などの工夫を凝らしたストレージサービスでした。
OpenStack SwiftやAmazon S3など、昨今のクラウドストレージサービスは、データの一貫性を捨ててサービスのスケーラビリティを拾うようなアーキテクチャになっています。一方で、IBM Spectrum Scale(旧称GPFS)などの分散ファイルシステムはデータの一貫性を保証する代わりにスケーラビリティに劣るようなアーキテクチャです。Storjの場合はどのような位置づけになるのですかね。また時間があるときに調査したいと思います。