Stacked Convolution Autoencoderを使って画像からの特徴抽出を行う話です。
最後に学習におけるTipsをいくつか載せますので、やってみたい方は参考にしていただければと思います。(責任は負わないので、ご了承ください)
Mission
今回はアニメ画像から特徴抽出します。MNISTはありきたりだよねーとか思って別の題材を探していたのですが、アニメ画像もありきたりな感じしますね。
徹夜でアニメ画像を集める根性がなかったので、以下のサイトからデータセットを手に入れてきました。
泉こなたとかシャナとかフェイトとか平沢唯とか、有名なキャラクターの画像が多数あります。可愛いです。
Autoncoder とは
深層学習の一種です。入力として、例えば画像を入れると、同じ画像が出力されるように学習させるネットワークになっています。ただし、入力-出力間で様々な演算処理が行われ、次元の数が途中で減らされてしまいます。同じ画像を出力するためには、重要な特徴を選定し、次元が削減されてもできるだけ情報が落とされないようにする必要があります。そういった特徴の選定(これを特徴抽出といいます)を学習によって行うのがAutoencoderです。
ググってみると、色んな角度からAutoencoderを説明している方がいらっしゃいます。
Stacked Autoencoder とは
構造としてはDeepなAutoencoderと大差ないのですが、学習のさせ方に工夫があります。詳細はコードの説明時に述べますね。
コード
Keras(backend:tensorflow 1.0)を使用
image_dim_orderingはtfなので、(データ数、高さ、幅、チャンネル数)でデータを表現します。
from keras.layers import Input, MaxPooling2D, UpSampling2D, Convolution2D
from keras.models import Model
from keras.optimizers import Adam
from keras import regularizers
class DeepAutoEncoder(object):
def __init__(self):
input_img = Input(shape=(80, 80, 3)) # 0
conv1 = Convolution2D(16, 7, 7, activation='relu', border_mode='same', init='glorot_normal',
W_regularizer=regularizers.l2(0.0005))(input_img) # 1
pool1 = MaxPooling2D((2, 2), border_mode='same')(conv1) # 2
conv2 = Convolution2D(32, 5, 5, activation='relu', border_mode='same', init='glorot_normal',
W_regularizer=regularizers.l2(0.0005))(pool1) # 3
pool2 = MaxPooling2D((2, 2), border_mode='same')(conv2) # 4
conv3 = Convolution2D(64, 3, 3, activation='relu', border_mode='same', init='glorot_normal',
W_regularizer=regularizers.l2(0.0005))(pool2) # 5
pool3 = MaxPooling2D((2, 2), border_mode='same')(conv3) # 6
conv4 = Convolution2D(128, 3, 3, activation='relu', border_mode='same', init='glorot_normal',
W_regularizer=regularizers.l2(0.0005))(pool3) # 7
pool4 = MaxPooling2D((2, 2), border_mode='same')(conv4) # 8
encoded = pool4
unpool4 = UpSampling2D((2, 2))(pool4) # 9
deconv3 = Convolution2D(64, 3, 3, activation='relu', border_mode='same', init='glorot_normal',
W_regularizer=regularizers.l2(0.0005))(unpool4) # 10
unpool3 = UpSampling2D((2, 2))(deconv3) # 11
deconv2 = Convolution2D(32, 3, 3, activation='relu', border_mode='same', init='glorot_normal',
W_regularizer=regularizers.l2(0.0005))(unpool3) # 12
unpool2 = UpSampling2D((2, 2))(deconv2) # 13
deconv1 = Convolution2D(16, 5, 5, activation='relu', border_mode='same', init='glorot_normal',
W_regularizer=regularizers.l2(0.0005))(unpool2) # 14
unpool1 = UpSampling2D((2, 2))(deconv1) # 15
decoded = Convolution2D(3, 7, 7, activation='sigmoid', border_mode='same', init='glorot_normal',
W_regularizer=regularizers.l2(0.0005))(unpool1) # 16
self.encoder = Model(input=input_img, output=encoded)
self.autoencoder = Model(input=input_img, output=decoded)
def compile(self, optimizer='adam', loss='binary_crossentropy'):
adam = Adam(lr=0.001, decay=0.005)
self.autoencoder.compile(optimizer=adam, loss=loss)
def train(self, x_train=None, x_test=None, nb_epoch=1, batch_size=128, shuffle=True):
self.autoencoder.fit(x_train, x_train,
nb_epoch=nb_epoch,
batch_size=batch_size,
shuffle=shuffle,
validation_data=(x_test, x_test))
self.encoder.save('./save_data/full_model_encoder.h5')
self.autoencoder.save('./save_data/full_model_autoencoder.h5')
def load_weights(self, ae01, ae02, ae03, ae04):
self.autoencoder.layers[1].set_weights(ae01.layers[1].get_weights())
self.autoencoder.layers[3].set_weights(ae02.layers[1].get_weights())
self.autoencoder.layers[5].set_weights(ae03.layers[1].get_weights())
self.autoencoder.layers[7].set_weights(ae04.layers[1].get_weights())
self.autoencoder.layers[10].set_weights(ae04.layers[4].get_weights())
self.autoencoder.layers[12].set_weights(ae03.layers[4].get_weights())
self.autoencoder.layers[14].set_weights(ae02.layers[4].get_weights())
self.autoencoder.layers[16].set_weights(ae01.layers[4].get_weights())
class AutoEncoderStack01(object):
def __init__(self):
input_img = Input(shape=(80, 80, 3)) # 0
conv1 = Convolution2D(16, 7, 7, activation='relu', border_mode='same')(input_img) # 1
pool1 = MaxPooling2D((2, 2), border_mode='same')(conv1) # 2
encoded = pool1
unpool1 = UpSampling2D((2, 2))(pool1) # 3
decoded = Convolution2D(3, 7, 7, activation='sigmoid', border_mode='same')(unpool1) # 4
self.encoder = Model(input=input_img, output=encoded)
self.autoencoder = Model(input=input_img, output=decoded)
def compile(self, optimizer='adam', loss='binary_crossentropy'):
adam = Adam(lr=0.001, decay=0.005)
self.autoencoder.compile(optimizer=adam, loss=loss)
def train(self, x_train=None, x_test=None, nb_epoch=1, batch_size=128, shuffle=True):
self.autoencoder.fit(x_train, x_train,
nb_epoch=nb_epoch,
batch_size=batch_size,
shuffle=shuffle,
validation_data=(x_test, x_test))
self.encoder.save('./save_data/stack01_encoder.h5')
self.autoencoder.save('./save_data/stack01_autoencoder.h5')
class AutoEncoderStack02(object):
def __init__(self):
input_img = Input(shape=(40, 40, 16)) # 0
conv2 = Convolution2D(32, 5, 5, activation='relu', border_mode='same')(input_img) # 1
pool2 = MaxPooling2D((2, 2), border_mode='same')(conv2) # 2
encoded = pool2
unpool2 = UpSampling2D((2, 2))(pool2) # 3
decoded = Convolution2D(16, 5, 5, activation='linear', border_mode='same')(unpool2) # 4
self.encoder = Model(input=input_img, output=encoded)
self.autoencoder = Model(input=input_img, output=decoded)
def compile(self, optimizer='adam', loss='mean_squared_error'):
adam = Adam(lr=0.0005, decay=0.005)
self.autoencoder.compile(optimizer=adam, loss=loss)
def train(self, x_train=None, x_test=None, nb_epoch=1, batch_size=128, shuffle=True):
self.autoencoder.fit(x_train, x_train,
nb_epoch=nb_epoch,
batch_size=batch_size,
shuffle=shuffle,
validation_data=(x_test, x_test))
self.encoder.save('./save_data/stack02_encoder.h5')
self.autoencoder.save('./save_data/stack02_autoencoder.h5')
class AutoEncoderStack03(object):
def __init__(self):
input_img = Input(shape=(20, 20, 32)) # 0
conv3 = Convolution2D(64, 3, 3, activation='relu', border_mode='same')(input_img) # 1
pool3 = MaxPooling2D((2, 2), border_mode='same')(conv3) # 2
encoded = pool3
unpool3 = UpSampling2D((2, 2))(pool3) # 4
decoded = Convolution2D(32, 3, 3, activation='linear', border_mode='same')(unpool3) # 13
self.encoder = Model(input=input_img, output=encoded)
self.autoencoder = Model(input=input_img, output=decoded)
def compile(self, optimizer='adam', loss='mean_squared_error'):
adam = Adam(lr=0.0005, decay=0.005)
self.autoencoder.compile(optimizer=adam, loss=loss)
def train(self, x_train=None, x_test=None, nb_epoch=1, batch_size=128, shuffle=True):
self.autoencoder.fit(x_train, x_train,
nb_epoch=nb_epoch,
batch_size=batch_size,
shuffle=shuffle,
validation_data=(x_test, x_test))
self.encoder.save('./save_data/stack03_encoder.h5')
self.autoencoder.save('./save_data/stack03_autoencoder.h5')
class AutoEncoderStack04(object):
def __init__(self):
input_img = Input(shape=(10, 10, 64)) # 0
conv4 = Convolution2D(128, 3, 3, activation='relu', border_mode='same')(input_img) # 1
pool4 = MaxPooling2D((2, 2), border_mode='same')(conv4) # 2
encoded = pool4
unpool4 = UpSampling2D((2, 2))(pool4) # 3
decoded = Convolution2D(64, 3, 3, activation='linear', border_mode='same')(unpool4) # 4
self.encoder = Model(input=input_img, output=encoded)
self.autoencoder = Model(input=input_img, output=decoded)
def compile(self, optimizer='adam', loss='mean_squared_error'):
adam = Adam(lr=0.0005, decay=0.005)
self.autoencoder.compile(optimizer=adam, loss=loss)
def train(self, x_train=None, x_test=None, nb_epoch=1, batch_size=128, shuffle=True):
self.autoencoder.fit(x_train, x_train,
nb_epoch=nb_epoch,
batch_size=batch_size,
shuffle=shuffle,
validation_data=(x_test, x_test))
self.encoder.save('./save_data/stack04_encoder.h5')
self.autoencoder.save('./save_data/stack04_autoencoder.h5')
AutoencoderStack0xクラスがいくつかありますね。Stacked Autoencoder はネットワークとしてはDeepなAutoencoderなのですが、学習時には1層ずつパラメータ更新を行っています。そして、最後にそれぞれ個別に更新した層をくっつけてDeepなAutoencoderにして、finetune(学習済みパラメータを初期値とする学習)を行います。
実際に学習を行う際のコードは以下になります。
from model import DeepAutoEncoder, \
AutoEncoderStack01, AutoEncoderStack02, AutoEncoderStack03, \
AutoEncoderStack04
import numpy as np
import cv2
import sys
def main():
x_train1 = np.load('train.npy')
x_test1 = np.load('test.npy')
# データ拡張
argumented_xs = list()
for i in range(x_train1.shape[0]):
for k in range(5):
if k == 0:
x = x_train1[i, 20:, 20:, :]
elif k == 1:
x = x_train1[i, :-20, 20:, :]
elif k == 2:
x = x_train1[i, :-20, :-20, :]
elif k == 3:
x = x_train1[i, 20:, :-20, :]
else:
x = x_train1[i, 10:-10, 10:-10, :]
x2 = cv2.resize(x, (80, 80))
argumented_xs.append(x2)
x_train1_2 = np.concatenate((x_train1, np.array(argumented_xs)), axis=0)
x_train1_2 = x_train1_2.astype(np.float32) / 255.0
x_train1_2[x_train1_2 < 0.0] = 0.0
x_train1_2[x_train1_2 > 1.0] = 1.0
x_test1 = x_test1.astype(np.float32) / 255.0
x_test1[x_test1 < 0.0] = 0.0
x_test1[x_test1 > 1.0] = 1.0
del x_train1
# step1
print("***** STEP 1 *****")
ae01 = AutoEncoderStack01()
ae01.compile()
ae01.train(x_train=x_train1_2, x_test=x_test1, nb_epoch=100, batch_size=128)
enc_train1 = ae01.encoder.predict(x=x_train1_2)
enc_test1 = ae01.encoder.predict(x=x_test1)
np.save('train_stack01.npy', enc_train1)
np.save('test_stack01.npy', enc_test1)
del enc_train1, enc_test1
# step2
print("***** STEP 2 *****")
ae02 = AutoEncoderStack02()
ae02.compile()
x_train2 = np.load('train_stack01.npy')
x_test2 = np.load('test_stack01.npy')
ae02.train(x_train=x_train2, x_test=x_test2, nb_epoch=100, batch_size=128)
enc_train2 = ae02.encoder.predict(x=x_train2)
enc_test2 = ae02.encoder.predict(x=x_test2)
np.save('train_stack02.npy', enc_train2)
np.save('test_stack02.npy', enc_test2)
del x_train2, x_test2, enc_train2, enc_test2
# step3
print("***** STEP 3 *****")
ae03 = AutoEncoderStack03()
ae03.compile()
x_train3 = np.load('train_stack02.npy')
x_test3 = np.load('test_stack02.npy')
ae03.train(x_train=x_train3, x_test=x_test3, nb_epoch=100, batch_size=128)
enc_train3 = ae03.encoder.predict(x=x_train3)
enc_test3 = ae03.encoder.predict(x=x_test3)
np.save('train_stack03.npy', enc_train3)
np.save('test_stack03.npy', enc_test3)
del x_train3, x_test3, enc_train3, enc_test3
# step4
print("***** STEP 4 *****")
ae04 = AutoEncoderStack04()
ae04.compile()
x_train4 = np.load('train_stack03.npy')
x_test4 = np.load('test_stack03.npy')
ae04.train(x_train=x_train4, x_test=x_test4, nb_epoch=100, batch_size=128)
enc_train4 = ae04.encoder.predict(x=x_train4)
enc_test4 = ae04.encoder.predict(x=x_test4)
np.save('train_stack04.npy', enc_train4)
np.save('test_stack04.npy', enc_test4)
del x_train4, x_test4, enc_train4, enc_test4
# step5
print("***** STEP 5 *****")
stacked_ae = DeepAutoEncoder()
# stacked_ae.load_weights(ae01=ae01.autoencoder, ae02=ae02.autoencoder, ae03=ae03.autoencoder, ae04=ae04.autoencoder)
stacked_ae.compile()
stacked_ae.train(x_train=x_train1_2, x_test=x_test1, nb_epoch=100, batch_size=128)
if __name__ == "__main__":
main()
データを用意して、numpyを駆使してtrain.npyとtest.npyさえ作ってしまえば学習はできます。ただし、かなり時間がかかるので寝る前に実行すると良いでしょう。なお、メモリをかなり食うのでお気をつけ下さい。
学習、そして特徴抽出
朝、目覚めると学習が終わっていたので、まずは画像を入力して、そのままの画像が出力されるか、再構成ができているかを確認しました。結果は以下のとおりです。



あまりの可愛さに私の目から涙が出て、それでにじんで見えているのかなと思いましたが、どうやらそうではなかったようです。まあ、かなりの次元削減(19200 -> 3200)をしているので、完全に復元できないのは仕方ないかもですね。(再構成が目的ならDCGANとか使うべきです)
しかし、大まかな形や色は再構成できているので、特徴抽出出来てるかもしれないという感じがしてきます。
次にネットワークの中間層から値を取り出します。これを画像特徴量とします。良い特徴が得られているのか調べたいので主成分分析にかけてみます。
主成分分析については以下のサイトを見ると良いと思います。アルゴリズムのイメージを述べつつ、Pythonでのサンプルコードもあるので、非常に参考になります。
では、主成分分析にかけていくのですが、今回は泉こなた、平沢唯、フェイト・テスタロッサの3名の画像から特徴を抽出し、主成分分析にかけます。可視化するのでベクトルの次元を3200から2へ落としました。
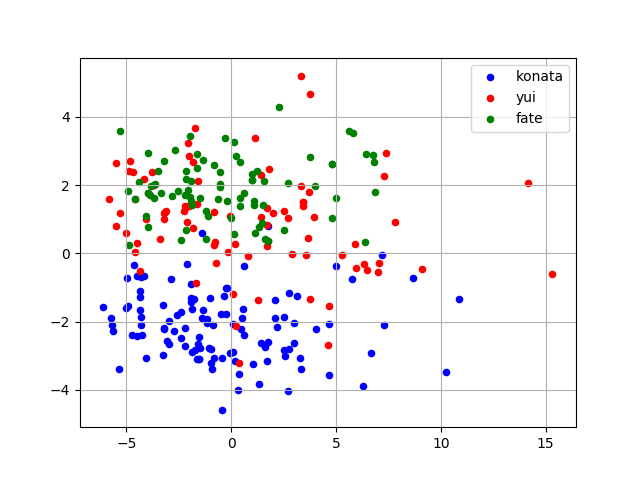
青がこなた、赤が平沢唯、緑がフェイトです。こなたの画像特徴は他の2つとは異なっているように見えますね。唯とフェイトは重複しているエリアが広いです。少しだけ、フェイトの画像特徴は上に寄っているのでしょうか。
ちなみに、主成分分析のコードは以下です。
import numpy as np
from sklearn.decomposition import PCA
from mpl_toolkits.mplot3d import Axes3D
import matplotlib.pyplot as plt
konata = np.load('features/izumi_konata.npy')
yui = np.load('features/hirasawa_yui.npy')
fate = np.load('features/fate_testarossa.npy')
# (n_data, height, width, channel) => (n_data, height * width * channel)
konata = konata.reshape(konata.shape[0], 5 * 5 * 128)
yui = yui.reshape(yui.shape[0], 5 * 5 * 128)
fate = fate.reshape(fate.shape[0], 5 * 5 * 128)
X = np.concatenate((konata, yui, fate), axis=0)
### 2-dimension
pca = PCA(n_components=2)
pca.fit(X=X)
konata_pca = pca.transform(X=konata)
yui_pca = pca.transform(X=yui)
fate_pca = pca.transform(X=fate)
plt.scatter(konata_pca[:, 0], konata_pca[:, 1], color='blue', s=20, label='konata')
plt.scatter(yui_pca[:, 0], yui_pca[:, 1], color='red', s=20, label='yui')
plt.scatter(fate_pca[:, 0], fate_pca[:, 1], color='green', s=20, label='fate')
plt.grid()
plt.legend()
###
### 3-dimension
# pca = PCA(n_components=3)
# pca.fit(X=X)
#
# konata_pca = pca.transform(X=konata)
# yui_pca = pca.transform(X=yui)
# fate_pca = pca.transform(X=fate)
#
# fig = plt.figure()
# ax = Axes3D(fig)
# ax.plot(konata_pca[:, 0], konata_pca[:, 1], konata_pca[:, 2], "o", color="blue", ms=4, mew=0.5) # <---ここでplot
# ax.plot(yui_pca[:, 0], yui_pca[:, 1], yui_pca[:, 2], "o", color="red", ms=4, mew=0.5)
# ax.plot(fate_pca[:, 0], fate_pca[:, 1], fate_pca[:, 2], "o", color="green", ms=4, mew=0.5)
###
plt.show()
コメントアウトしている部分を切り替えることで3次元に次元削減するバーションの結果も見ることができます。
こんな簡単に書けるなんて、良い時代です。
というわけで以上です。最後に、学習が上手くいかなかったときの条件などについて述べます
学習Tips
- AutoencoderにBatchnormalizationを使っても画像再構成の精度に変化がなかった
- 画像特徴のスパース化を狙って、中間層の出力に対してL1lossを適用したら、画像を再構成したときに一面の肌色の画像が出力されてしまった。L1lossに対する重みを0.0001にしても同様の現象が見られたので、現在は入れていない。
- 損失関数binary_cross_entropyは活性化関数sigmoid関数とセットで使うべきです
- 活性化関数がsigmoidでない場合(linearとか)はmean_squared_errorで良いかと思います。