深層学習の表現力の高さにはいつも驚かされます。
画像認識系のタスクであれば割と何でも識別できるイメージです。
今回はMNISTのデータセットを用いて、ラベルをランダムに振り分けなおしてから学習させた場合に、訓練誤差が減少するのかを確かめてみました。
すなわち丸暗記ができるかどうかの調査です。
テストプログラム
以下のプログラムを用いて実験をしました。
ラベルをランダムに振り分けたあとに、データの数を3000に減らします。
tensorflowをバックエンドとしたkerasを用いています。
データの与え方は(データ数、チャンネル数、画像の高さ、画像の幅)です。
mnist_conv.py
# -*- coding: utf-8 -*-
from __future__ import print_function
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers.core import Dense, Dropout, Activation, Flatten
from keras.layers.convolutional import Convolution2D, MaxPooling2D
from keras.optimizers import Adam
from keras.utils import np_utils
from keras.callbacks import EarlyStopping
import sys
import numpy as np
import matplotlib.pyplot as plt
batch_size = 32
nb_classes = 10
nb_epoch = 1000
def main():
# load MNIST data
(X_train, y_train), (X_test, y_test) = mnist.load_data()
img_channels = 1
_, img_cols, img_rows = X_train.shape
X_train = X_train.reshape(60000, 1, 28, 28).astype('float32')[:3000]
X_test = X_test.reshape(10000, 1, 28, 28).astype('float32')
X_train /= 255.0
X_test /= 255.0
X_train -= 0.5
X_test -= 0.5
# 学習データのラベルをランダムに振り分ける
y_train = y_train[np.random.permutation(y_train.shape[0])][:3000]
# convert class vectors to 1-of-K format
y_train = np_utils.to_categorical(y_train, nb_classes)
y_test = np_utils.to_categorical(y_test, nb_classes)
print('train samples: ', X_train.shape)
print('test samples: ', X_test.shape)
# building the model
print('building the model ...')
# build model
model = Sequential()
model.add(Convolution2D(32, 3, 3, border_mode='same',
input_shape=(img_channels, img_rows, img_cols)))
model.add(Activation('relu'))
model.add(Convolution2D(32, 3, 3))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Convolution2D(64, 3, 3, border_mode='same'))
model.add(Activation('relu'))
model.add(Convolution2D(64, 3, 3))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(512))
model.add(Activation('relu'))
model.add(Dense(nb_classes))
model.add(Activation('softmax'))
opt = Adam()
model.compile(loss='categorical_crossentropy',
optimizer=opt,
metrics=['accuracy'])
# training
hist = model.fit(X_train, y_train,
batch_size=batch_size,
verbose=1,
nb_epoch=nb_epoch,
validation_split=0.1)
# evaluate
score = model.evaluate(X_test, y_test, verbose=1)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
# plot loss
loss = hist.history['loss']
val_loss = hist.history['val_loss']
nb_epoch = len(loss)
plt.plot(range(nb_epoch), loss, marker='.', label='loss')
plt.plot(range(nb_epoch), val_loss, marker='.', label='val_loss')
plt.legend(loc='best', fontsize=10)
plt.grid()
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()
if __name__ == '__main__':
main()
結果
丸暗記大成功です。
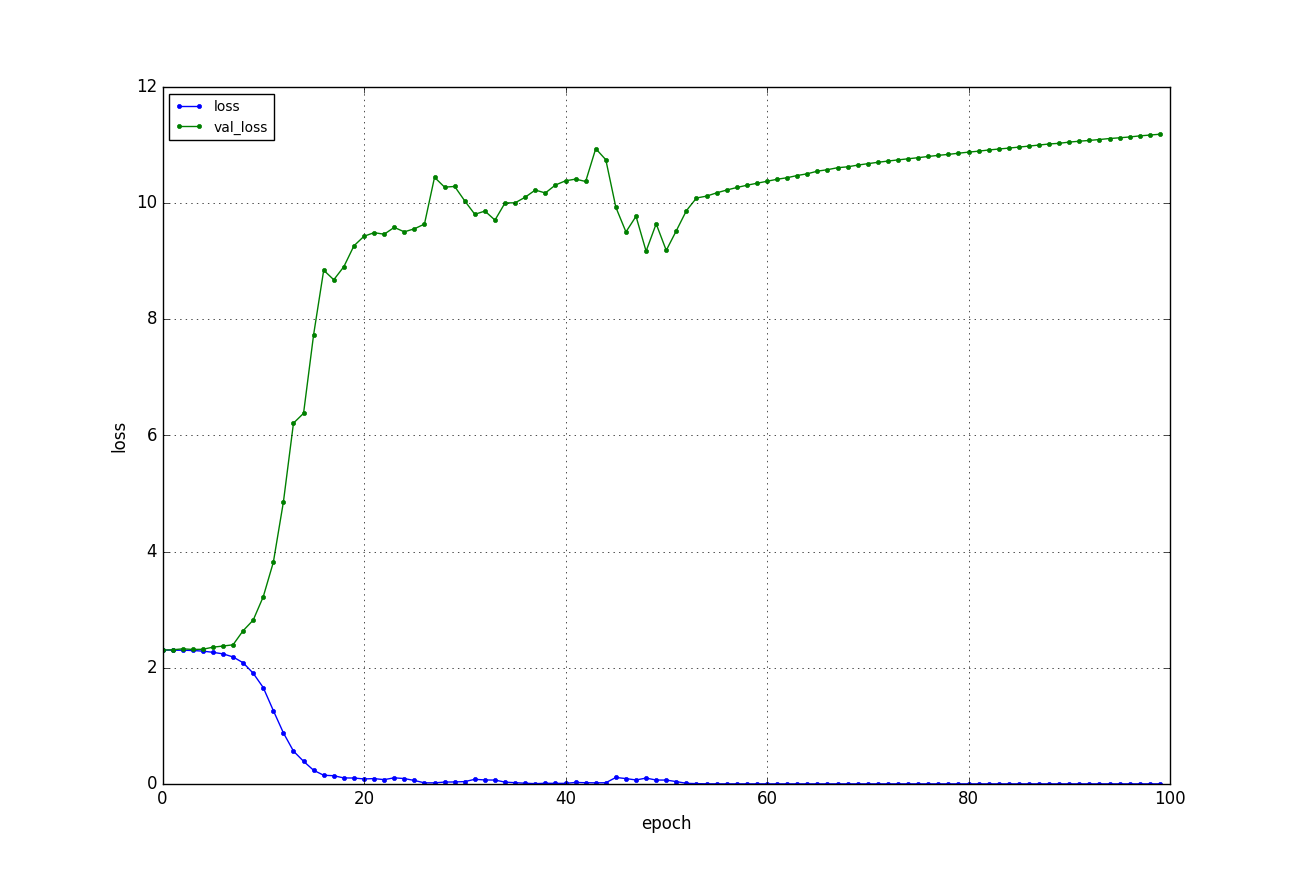
青い線が訓練誤差で、緑の線がバリデーション誤差(訓練時に使っていない画像による推定誤差)になります。
訓練誤差が0に収束し、バリデーション誤差が増加する、火を見るより明らかな美しい過学習の様相を呈しております。
訓練データに対する正答率は99.7%で、テストデータに対する正答率は8.67%でした。
ランダムに答えた場合の正答率の平均は10%になりますから、ランダムよりも雑魚い推定器の完成です。実用性皆無です。
ちなみに、訓練データの数を増やすと丸暗記ができなくなっていきます。データの数は重要ですね。