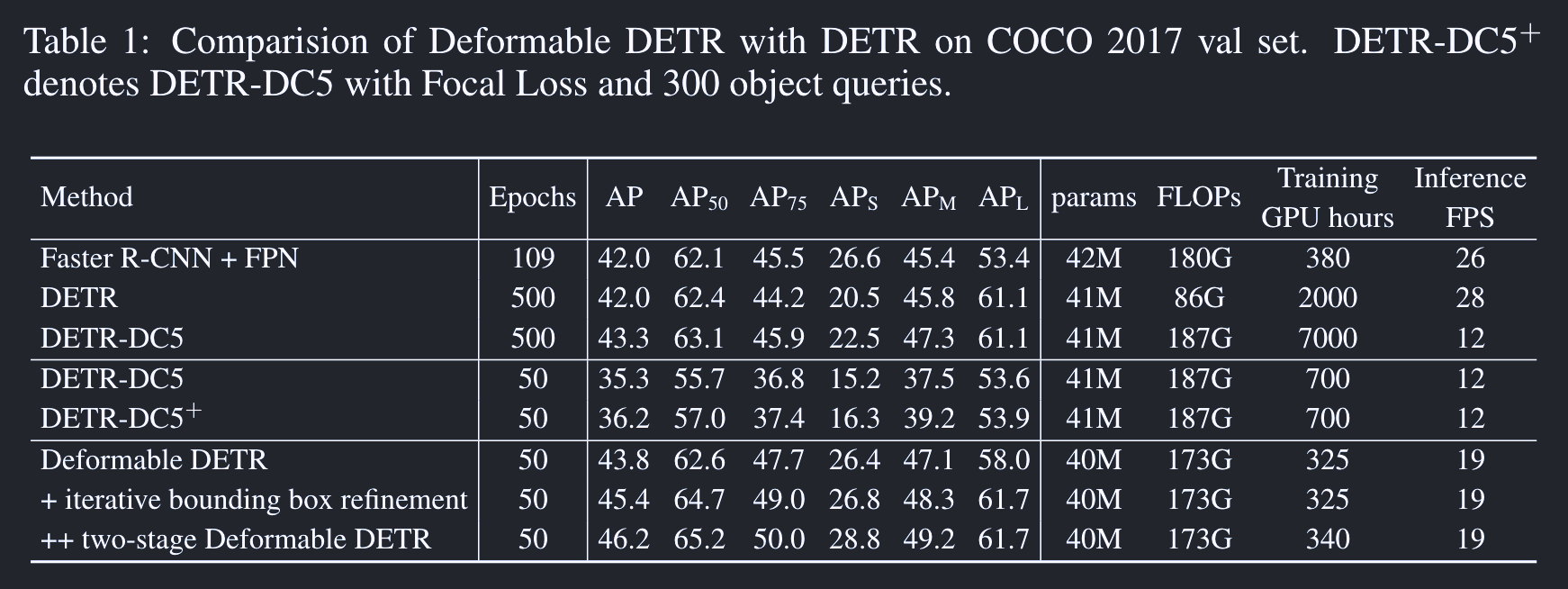
Deformable DETR: Deformable Transformers for End-to-End Object Detection
一般的なmulti head attentionは次のように表すことができる:
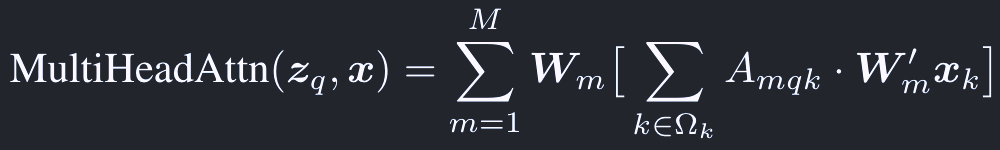
(注: Q, K, Vのうち、KとVは同じ値とみなしている。そのため上式のx_kはx_v)
ここで、
qはクエリ(Q)のインデックス
z_qはクエリの特徴ベクトル
kはキー(K)のインデックス
x_kはキーの特徴ベクトル
Mはヘッドの数


Attention weights:
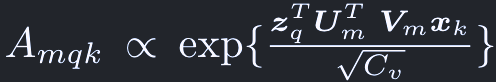
これは次のように正規化される
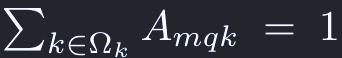
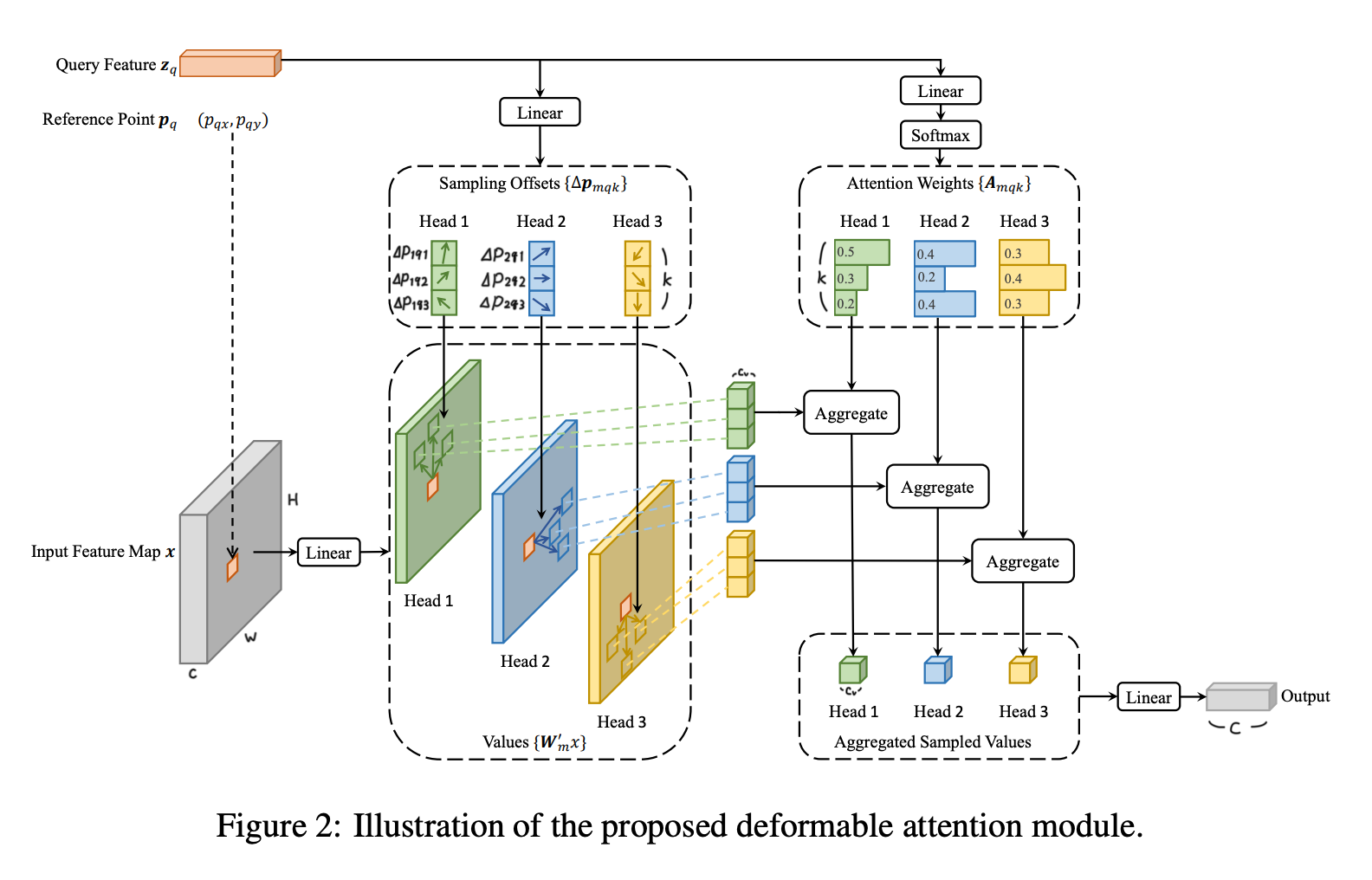
Deformable Attention Module
通常のattentionはK, Vの画像をすべて見るので、高解像度の(HWが大きい)画像を扱おうとすると計算量が大きくなりすぎる。
そこで、リファレンスポイント(p_q)周辺の少数のキーポイント(K)だけを見るようなDeformable attentionを提案する。
Deformable attentionは次のように計算する:
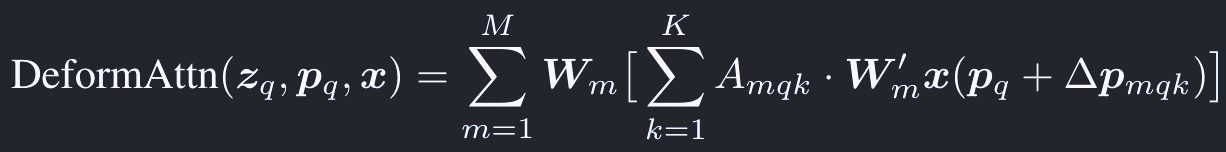
ここで、
xはVに相当する入力の特徴マップ:
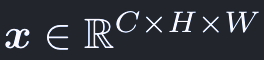
A_mqkはattention weightsに相当し、範囲は[0, 1]で、次のように正規化される:
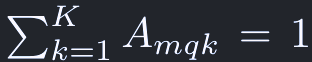
△p_mqkは二次元の実数値で、範囲に制限はない:
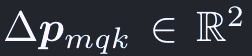
△p_mqkおよびA_mqkは、z_qをlinear projectionして得る。(チャネル数は2MKとMK)
(注: もともとのAttentionではA_mqkはQとKから計算されていたが、Deformable attentionではQからA_mqkが計算される)
Multi-scale Deformable Attention Module
Deformable attention moduleは自然にマルチスケールの特徴マップに拡張できる:
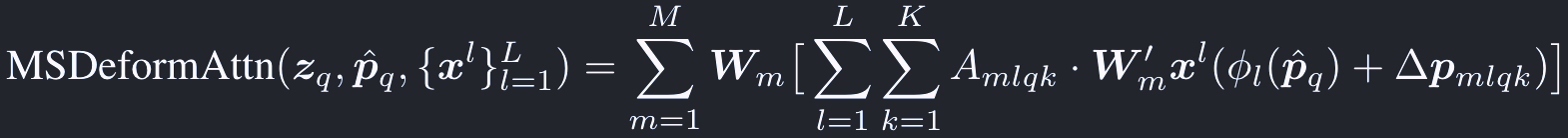
マルチスケールの特徴マップは、lを特徴階層のインデックスとして、次のように表す:
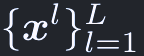
ここで、
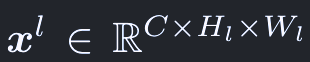
また、クエリqごとの正規化されたリファレンスポイントは:
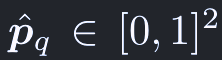
正規化されたp^_qは、次の関数でl-th levelの入力マップの座標に再スケールされる:
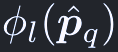
scalar attention weightは次のように正規化される:
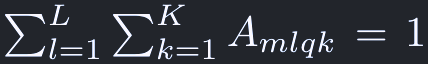
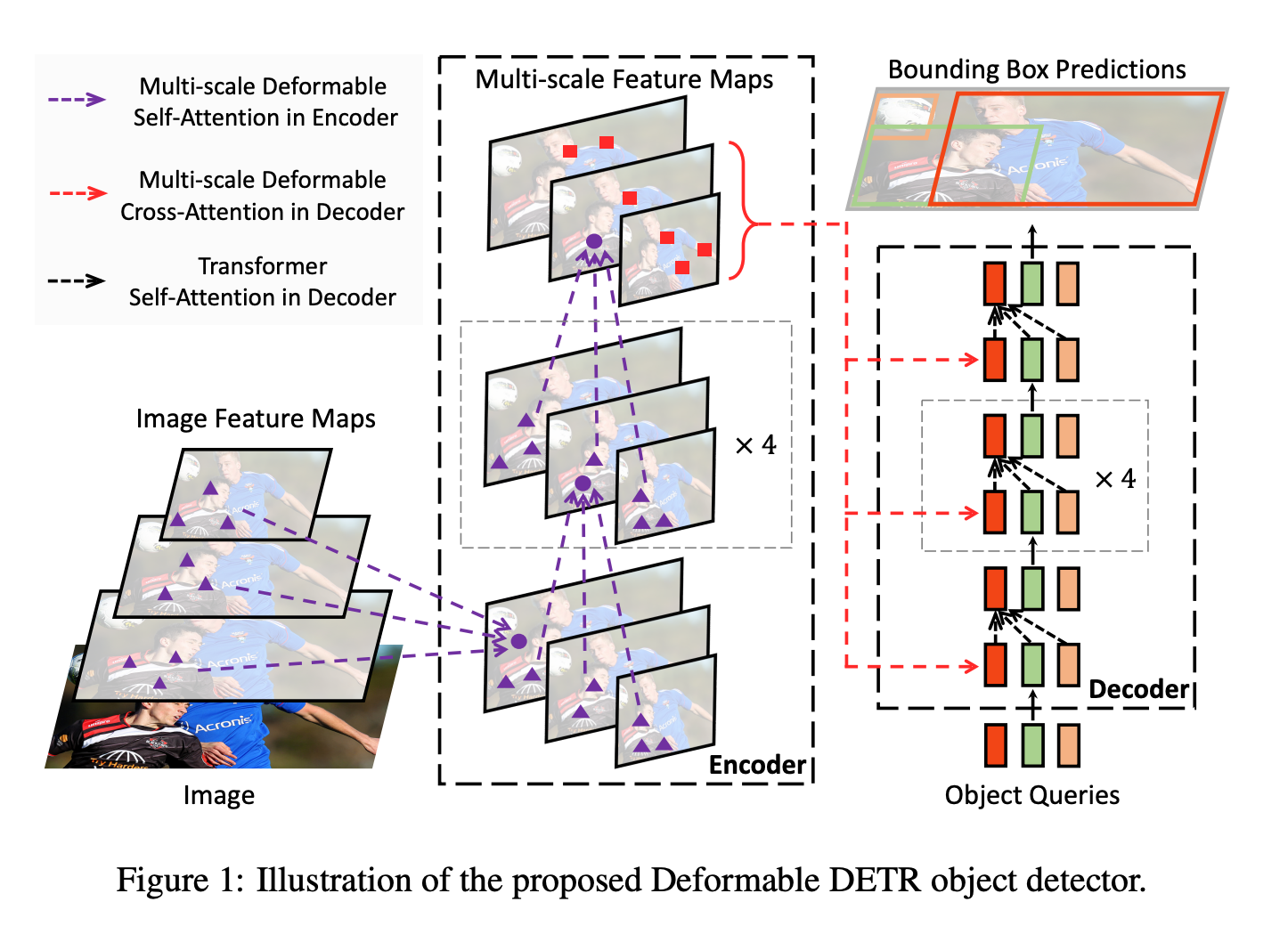
Deformable Transformer Encoder
DETRのencoderモジュールをmulti-scale deformable attentionモジュールで置き換える。
インプットとアウトプットの双方が同じ解像度でマルチスケールの特徴マップとなる。
入力のマルチスケール特徴マップは、バックボーンのResNetからC_3からC_5を1x1 convで抽出して、l=4についてはC_5に3x3 stride 2のconvを繋げて得る:
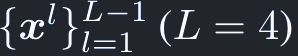
バックボーンにFPNは繋げていない。
これは、FPNがなくてもdeformable attentionが異なる解像度の情報をやり取りできるため。
クエリの各ピクセルについて、リファレンスポイントは自分自身。
ピクセルがどのスケールに属するか表すため、positional encodingに加えてscale level encodingも加える。
Deformable Transformer Decoder
self attentionについてはDETRのまま。
cross attentionはmulti-scale deformable attentionで置き換える。
各オブジェクトクエリについて、リファレンスポイントp^は、オブジェクトクエリの特徴ベクトルを学習可能な線形変換とシグモイド関数に与えて得る。
detection headが推定するバウンディングボックスの座標はリファレンスポイントからの相対的なオフセットとする。(リファレンスポイントをバウンディングボックスの中心座標のinitial guessとする)
これによって学習の難しさを下げ、収束が早くなる。