End-to-End Object Detection with Transformers
物体検出をend-to-endで行うDNN。画像を入力として (class, bounding box) を出力する。(最大N個)
bonding boxは、中心座標と幅長と縦長からなり、画像のサイズに対して[0, 1]に正規化されたもの。
Transformerを用いており、個々のオブジェクトの推定の際にも全体を考慮することができる。
損失関数の計算
Ground Truthのオブジェクトの集合をyとおく。また、N個の推定結果は次のように表す。
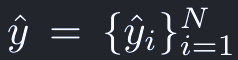
クラスがない場合はφで表す。
y^の推定結果は順不同なため、y^のオブジェクトの順によって値が変わらないような損失関数が必要になる。
そのためにまず、y^とyが最も良くマッチするような置換σ^を見つける。
この置換はHungarian algorithmを用いることで、効率的に見つけることができる。
式で表すと:
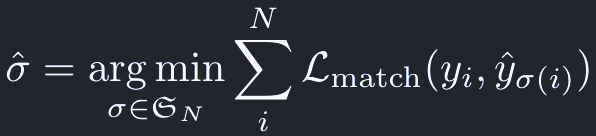
ただし、Lmatch(コスト)は:
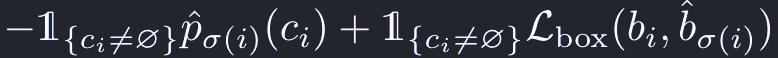
ここで、
第一項は推定結果が正しいクラスを選択する確率。
第二項はバウンディングボックスが正解と推定結果でどの程度違うかで、次のように表される:

IoUは2つの領域が完全に重っていれば1、全く重なっていなければ0となるもので、IoU損失は1 - IoU。また、実装ではGIoUを用いている。
L1損失だとオブジェクトの大きさが異なると、相対的には同じだけの誤差が異なる値になるので、Scale invariantなIoU損失も併せて導入している。
次に、見つかった置換σ^を用いて損失関数を計算する:
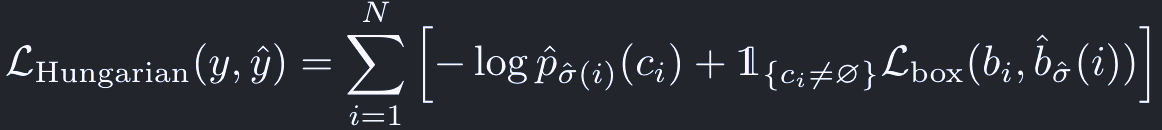
アーキテクチャ
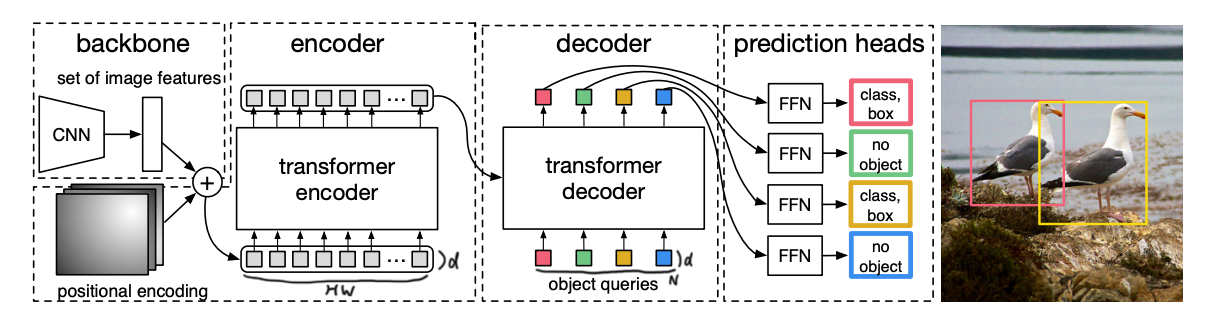
画像はCNN層(ResNetのCNN層を取り出したもの)で縦と横を1/32にスケール変換(H, W)、チャネル数(=トークンの次元数)dに変換し、encoderに入力。
decoderでは、N個の学習可能なトークン(object query)を入力として、それらの出力をclass用(softmax)とbox用(sigmoid)にそれぞれ線形変換したものを出力とする。
object queryを用いることで、逐次的にobjectを推定していくのではなく、一度に並列にobjectを推定することができる。

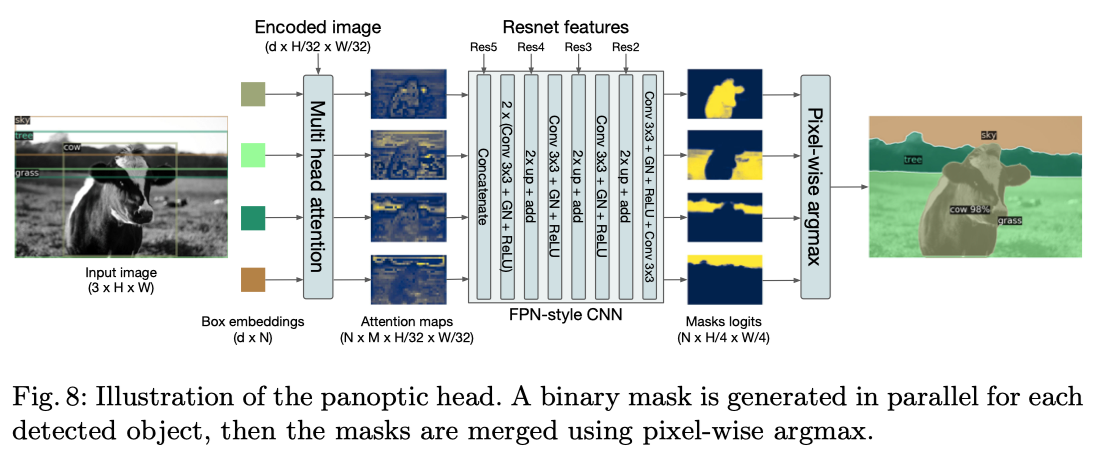
DETR for panoptic segmentation
DETRはstuffとthingsの周囲のboxを推定するように訓練する。(Hungarian matchingではboxの距離を使うため、boxの推定は必要)
decoderの出力を入力として、encoderの出力に対するattention scoreをM個のヒートマップとして出力するようなmulti-head attention (M heads)を追加。
最終的な推定には、出力されたヒートマップを入力として解像度を上げた二値マスクを出力するFPNのようなネットワークを使う。(バックボーンのResNetもlateralで繋がる)
(クラスごとに出力されたマスクを使ってセグメンテーションする)