はじめに
弊社では現在、レコメンドエンジンの高度化を進めています。その取組みの一貫として、強化学習を用いたレコメンドの検証を行いました。本稿ではその取り組みについて、まとめたいと思います。
強化学習とは
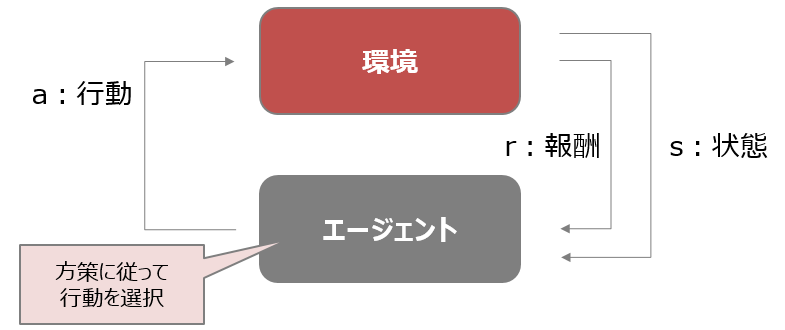
機械学習の分野の中でも強化学習は、教師あり学習や教師なし学習とは取り扱う問題の構造が異なります。
教師あり学習は入力と出力(正解ラベル)のペアデータを扱いますが、強化学習は教師なし学習と同様に正解ラベルは扱いません。一方で強化学習の特徴は、正解の代わりに報酬(もしくは罰)を扱います。
また、教師あり学習は入力から出力への変換方法を学習し、教師なし学習はデータに潜む構造や規則性を学習しますが、強化学習はエージェントが環境と相互作用しながら(行動を起こしながら)集めたデータ(環境の状態)を使って高い報酬を得る方策(いわゆるモデル)を学習します。
強化学習のレコメンドへの応用
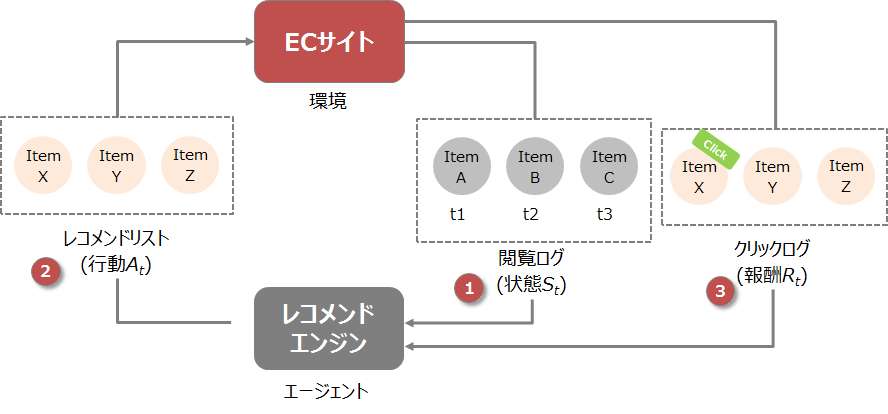
ここではECサイトにおける商品のレコメンドを想定します。
強化学習をレコメンドに応用するポイントは、「状態の定義」にあります。状態を「ある時間窓を持った閲覧履歴」と定義することで、強化学習の仕組みをレコメンドに応用することが可能となります。
例えば、ある時刻T1での閲覧履歴が「商品A→商品B→商品C」だった(上図の(1))場合、これをある時刻T1における状態$S_t$だとします。その状態$S_t$をインプットに、ある方策に基づいて行動$A_t$を起こします(上図の(2))。行動とはレコメンドリストを生成することと同義となります。そのレコメンドリストをECサイト(環境)に出してみるとその結果として、商品がクリックされたか(もしくはクリックされなかったか)のログを得ることになります。これを報酬$R_t$として次の学習に使用します(上図の(3))。
クリックされた商品はプラスに働き、逆にクリックされなかった商品はマイナスの方向に働くことになります。
強化学習を用いたレコメンドの実装
強化学習のアルゴリズムは様々存在しますが、今回はActor-Criticというアルゴリズムを検証します。Actor-Criticの詳細については今回触れませんが、既に様々な記事がありますので興味がある方はそちらをご参照いただければと思います。
また、一般的な強化学習(例えばバンディット)では実環境において方策をリアルタイムに学習しますが(これをオンライン学習と呼ぶ)、今回は実環境に適用する前にオフラインで学習を行うオフライン学習を対象に実装していきます。オフライン学習は、過去に蓄積された閲覧ログを用いて実環境適用前にある程度学習を進めることから、前述のオンライン学習に比べると実環境適用時の機会損失を緩和できるメリットがあります。
今回は学習過程や評価結果などのアウトプットについては掲載しませんが、全体的な処理の流れをイメージとして掴んでいただければと思います。
学習データ作成
まずは閲覧ログを準備します。今回の報酬はクリックがあったかどうかの0/1とするため、商品のレコメンド枠を見たかどうかのログを示すviewl_logと、商品をクリックしたかどうかのログを示すclick_logを準備します。下記のサンプルコードでは手動でデータを作成していますが、もちろんオープンデータを使ってもOKです。view_logとclick_logの紐付けには、idというキー(UUIDみたいなもの)を用いています。
# viewログの作成
view_log = pd.DataFrame(
[
['c94f376aap430jkdef9g', 1, 1],
['c965gveaap430ji1vrs0', 2, 1],
['c92sn1g6madoclsh5v8g', 3, 1],
...... # 省略
['c9djnao6madoclr43fbg', 4, 2],
['c93d8m06madocltpari0', 5, 2],
['c9kdnko6madocltno9fg', 6, 2],
...... # 省略
...... # 省略
],
columns=['id', 'user_id', 'item_id']
)
# clickログの作成
# click有無のカラム名はrewardと表現
click_log = pd.DataFrame(
[
['c94f376aap430jkdef9g', datetime(2022, 12, 1, 0, 0, 0), 1, 1, 1],
['c965gveaap430ji1vrs0', datetime(2022, 12, 1, 0, 0, 1), 2, 1, 1],
['c92sn1g6madoclsh5v8g', datetime(2022, 12, 1, 0, 0, 2), 3, 1, 1],
...... # 省略
['c9djnao6madoclr43fbg', datetime(2022, 12, 1, 0, 0, 3), 4, 2, 1],
['c93d8m06madocltpari0', datetime(2022, 12, 1, 0, 0, 4), 5, 2, 1],
['c9kdnko6madocltno9fg', datetime(2022, 12, 1, 0, 0, 5), 6, 2, 1],
...... # 省略
...... # 省略
],
columns=['id', 'timestamp', 'user_id', 'item_id', 'reward']
)
# viewログとclickログの紐付け
view_click_log = pd.merge(view_log, click_log, on=['id', 'user_id', 'item_id'], how='left').fillna({'reward': 0})
報酬関数の作成
オフライン学習を行うにあたり、事前に報酬関数を作成します。報酬関数は疑似的な環境としての役割を果たし、機械学習のモデルとして表現します。今回はこちらのバイナリフィードバックに対応したMatrixFactorizationを用いて報酬関数を作ります。オフライン学習の各ステップにおいて、ここで学習を行った事前学習済みの報酬関数(モデル)が生成する報酬の値(クリックしたかどうかのモデルの予測値)に基づいて強化学習を学習していきます。
パラメータの設定例
class args():
output_path = 'results/' + datetime.datetime.now().strftime('%y%m%d-%H%M%S') + '/'
trained_models_dir = output_path + 'trained/'
if not os.path.exists(trained_models_dir):
os.makedirs(trained_models_dir)
seed = 42
lr = 0.001
dropout = 0.2
batch_size = 512
epochs = 10
top_k = 3
factor_num = 100
layers = [200, 64, 32, 16, 8]
num_ng_test = 30
out = True
報酬関数の学習
下記サンプルコード内で出てくる各クラスの詳細については、前述したこちらのノートブックをご参照ください。
# set the num_users, items
num_users = view_click_log['user_id'].nunique()+1
num_items = view_click_log['item_id'].nunique()+1
# construct the train and test datasets
data = NCF_Data(args, view_click_log)
train_loader = data.get_train_instance()
test_loader = data.get_test_instance()
# set model and loss, optimizer
model = NeuMF(args, num_users, num_items)
model = model.to('cpu')
loss_function = nn.BCELoss()
optimizer = optim.Adam(model.parameters(), lr=args.lr)
def seed_all(cuda, seed):
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
if cuda:
torch.cuda.empty_cache()
torch.cuda.manual_seed(seed=seed)
seed_all(False, args.seed)
# train, evaluation
best_hr = 0
for epoch in range(1, args.epochs+1):
model.train()
last_time = start_time = time.time()
step = 0
for user, item, label in train_loader:
user = user.to('cpu')
item = item.to('cpu')
label = label.to('cpu')
optimizer.zero_grad()
prediction = model(user, item)
loss = loss_function(prediction, label)
loss.backward()
optimizer.step()
if (step+1) % 10 == 0:
diff_time = time.time() - last_time
elapsed_time = time.strftime('%H: %M: %S', time.gmtime(diff_time))
step_rate = (step+1) / max_iter * 100.0
print(
f'Epoch {epoch} | '
f'Elapsed time {elapsed_time} | '
f'Timestep {step+1}/{max_iter}({step_rate:.3f}%) | '
f'Loss '
f'{loss.item():.4f} | '
)
last_time = time.time()
step += 1
model.eval()
HR, NDCG = metrics(model, test_loader, args.top_k, 'cpu', test_max_iter)
elapsed_time = time.time() - start_time
print('The time elapse of epoch {:03d}'.format(epoch) + ' is: ' + time.strftime('%H: %M: %S', time.gmtime(elapsed_time)))
print('HR: {:.4f}\tNDCG: {:.4f}'.format(HR, NDCG))
if HR > best_hr:
best_hr, best_ndcg, best_epoch = HR, NDCG, epoch
if args.out:
if not os.path.exists(args.trained_models_dir):
os.makedirs(args.trained_models_dir)
torch.save(model.state_dict(), '{}{}.pth'.format(args.trained_models_dir, 'pretrained_binary_mf'))
強化学習の学習
今回はこちらに公開されているDRRを用いて強化学習の学習を行います。また、元の論文はこちらになりますので、興味がある方は詳細をご確認ください。DRR自体は明示的フィードバックを対象としたコードとなっていますが、今回の暗黙的フィードバックのデータを使用した場合でも問題なく動作します(学習時に用いる報酬が連続値から離散値になっただけ)。
方策の定義(一部コード抜粋)
強化学習の方策にあたるコードを抜粋して掲載します。下記に示す通り強化学習の方策は一般的なニューラルネットワークで表現できることが分かります。
class Actor(nn.Module):
def __init__(self, in_features=100, out_features=18):
super(Actor, self).__init__()
self.in_features = in_features
self.out_features = out_features
self.linear1 = nn.Linear(self.in_features, self.in_features)
self.linear2 = nn.Linear(self.in_features, self.in_features)
self.linear3 = nn.Linear(self.in_features, self.out_features)
def forward(self, state):
output = F.relu(self.linear1(state))
output = F.relu(self.linear2(output))
output = F.tanh(self.linear3(output))
return output
class Critic(nn.Module):
def __init__(self, action_size=20, in_features=128, out_features=18):
super(Critic, self).__init__()
self.in_features = in_features
self.out_features = out_features
self.combo_features = in_features + action_size
self.action_size = action_size
self.linear1 = nn.Linear(self.in_features, self.in_features)
self.linear2 = nn.Linear(self.combo_features, self.combo_features)
self.linear3 = nn.Linear(self.combo_features, self.combo_features)
self.output_layer = nn.Linear(self.combo_features, self.out_features)
def forward(self, state, action):
output = F.relu(self.linear1(state))
output = torch.cat((action, output), dim=1)
output = F.relu(self.linear2(output))
output = F.relu(self.linear3(output))
output = self.output_layer(output)
return output
コンフィグの設定例
class config():
output_path = 'results/' + datetime.datetime.now().strftime('%y%m%d-%H%M%S') + '/'
if not os.path.exists(output_path):
os.makedirs(output_path)
# 報酬のプロット先
plot_dir = output_path + 'rewards.pdf'
# 強化学習(方策)のロス・報酬データの保存先
train_actor_loss_data_dir = output_path + 'train_actor_loss_data.npy'
train_critic_loss_data_dir = output_path + 'train_critic_loss_data.npy'
train_mean_reward_data_dir = output_path + 'train_mean_reward_data.npy'
# 強化学習(方策)のロス・報酬のプロット先
train_actor_loss_plot_dir = output_path + 'train_actor_loss.png'
train_critic_loss_plot_dir = output_path + 'train_critic_loss.png'
train_mean_reward_plot_dir = output_path + 'train_mean_reward.png'
trained_models_dir = 'trained/'
# 強化学習(方策)のニューラルネットの重みの保存先
actor_model_trained = trained_models_dir + 'actor_net.weights'
critic_model_trained = trained_models_dir + 'critic_net.weights'
state_rep_model_trained = trained_models_dir + 'state_rep_net.weights'
csv_dir = output_path + 'log.csv'
# 報酬関数(事前学習済みのモデル)のパスを設定
path_to_trained_pmf = 'results/trained/pretrained_binary_mf.pth'
# hyperparams
batch_size = 1024
gamma = 0.9
replay_buffer_size = 100000
history_buffer_size = 5
learning_start = 5000
learning_freq = 1
lr_state_rep = 0.001
lr_actor = 0.0001
lr_critic = 0.001
eps_start = 1
eps = 0.1
eps_steps = 10000
eps_eval = 0.1
ng_buffer_push_prob = 0.01
tau = 0.01 # inital 0.001
beta = 0.4
prob_alpha = 0.9
max_timesteps_train = 260000
max_epochs_offline = 500
max_timesteps_online = 20000
embedding_feature_size = 100
episode_length = 10000
train_ratio = 0.8
weight_decay = 0.01
clip_val = 1.0
log_freq = 100
saving_freq = 1000
zero_reward = False
no_cuda = False
学習の実行
from drr.model import Actor, Critic, DRRAveStateRepresentation
from drr.learn import DRRTrainer
actor_function = Actor
critic_function = Critic
state_rep_function = DRRAveStateRepresentation
def reindex(logs):
user_list = list(logs['user_id'].drop_duplicates())
user2id = {w: i for i, w in enumerate(user_list)}
item_list = list(logs['item_id'].drop_duplicates())
item2id = {w: i for i, w in enumerate(item_list)}
logs['user_id'] = logs['user_id'].apply(lambda x: user2id[x])
logs['item_id'] = logs['item_id'].apply(lambda x: item2id[x])
return user2id, item2id, logs
# user_idとitem_idを0から採番
users, items, view_click_log = reindex(view_click_log)
# 各user_idで同一item_idを複数回閲覧していた場合、最新日のログだけを残す
view_click_log['rank_latest'] = view_click_log.groupby(['user_id', 'item_id'])['timestamp'].rank(method='first', ascending=False)
view_click_log = view_click_log.loc[view_click_log['rank_latest'] == 1][['timestamp', 'user_id', 'item_id', 'reward']]
data = np.array(view_click_log.values)
# Exchange UNIX time
data[:, 0] = data[:, 0].astype('datetime64[s]').astype(np.int64)
np.random.shuffle(data)
train_data = torch.from_numpy(data[:int(config.train_ratio * data.shape[0])].astype('float64'))
test_data = torch.from_numpy(data[int(config.train_ratio * data.shape[0]):].astype('float64'))
print("Data imported, shuffled, and split into Train/Test, ratio=", config.train_ratio)
n_users = len(users)
n_items = len(items)
# 事前学習済みの報酬関数をロード
reward_function = NeuMF(args, n_users, n_items)
reward_function.load_state_dict(torch.load(config.path_to_trained_pmf))
# Freeze all the parameters in the network
for param in reward_function.parameters():
param.requires_grad = False
# Extract embeddings
user_embeddings = reward_function.embedding_user_mf.weight.data
item_embeddings = reward_function.embedding_item_mf.weight.data
# Init trainer
print("Initializing DRRTrainer ---------------------------------")
trainer = DRRTrainer(config,
actor_function,
critic_function,
state_rep_function,
reward_function,
users,
items,
train_data,
test_data,
user_embeddings,
item_embeddings,
cuda
)
# Train
actor_losses, critic_losses, epi_avg_rewards = trainer.learn()
評価
環境変化による精度評価
強化学習レコメンドでは、閲覧履歴(環境)をインプットにして商品のレコメンド(行動)を行いクリック結果(報酬)を得る、といったことを逐次的に繰り返すことになります。下記評価においては、その環境の変化回数に応じて精度がどう変化するかを確認しています。環境がどれだけ変化したとしても、精度が劣化しないモデルが理想的な強化学習レコメンドということになります。
# 環境の変化回数が5、10、15、20のとき、それぞれの条件下での精度を評価している
T_precisions = [5, 10, 15, 20]
# DRR
for T_precision in T_precisions:
drr_Ts = []
for i in range(10):
print(f'epoch: {i+1}:')
# Evaluate
avg_precision = trainer.offline_evaluate(T_precision)
# Append to list
drr_Ts.append(avg_precision)
print(f'T = ({T_precision}): end.')
# Save data
drr_Ts = np.array(drr_Ts)
np.save(output_path + f'avg_precision@{T_precision}_offline_eval.npy', drr_Ts)
# Save
sourceFile = open(output_path + f'avg_precision@{T_precision}_offline_eval.txt', 'w')
print(f'Average Precision@{T_precision} (Eval): {np.mean(drr_Ts)}', file=sourceFile)
sourceFile.close()
最後に
- 閲覧ログを状態として扱う場合に状態の数は膨大になることから、学習がうまく進みませんでした(方策がなかなかクリック商品を当てることが難しい)。
- 学習効率を高めるためには、レコメンド対象の商品数をある程度(例えば、100商品程度に)絞った後に、強化学習にかけるべきだと思われます。
- 強化学習を実社会のレコメンドに応用した事例はあまり多くは公開されていません。そういった状況の中でもGoogleは強化学習をYoutubeのレコメンドに応用した事例を公開しています(REINFORCE)。次回はこちらについても検証を行えればと思っています。