お題
GraphQLを初めて1ヶ月。そろそろ少しずつアウトプットしていく。
今回は、プチ情報。
GraphQLでは schema ファイルに Query と Mutation を定義していく。
1人で開発している時は問題ないのだけど、複数人で開発していると同じ schema ファイルを修正するので、しょっちゅう競合する。
なので、(大抵は機能ごとに担当がわかれるので)機能ごとに schema ファイルをわける。
対象読者
複数人でのGraphQLを用いた開発を現場で始めて間もない方。
前提
- GraphQL自体の説明は無し
- gqlgen自体の説明も無し
※今回、バックエンドは Golang を使っており、GraphQLのサーバーサイド実装には gqlgen というライブラリを用いている。
実践
想定事例として、何かしらの「商品(Item)」の登録・参照と「ユーザー(User)」の登録・参照をGraphQLで表現する。
schema ファイル分割前
プロダクションレベルでの検討はしていないけど、以下のような感じ。
schema {
query: Query
mutation: Mutation
}
type Query {
item(id: ID!): Item
user(id: ID!): User
}
type Mutation {
createItem(input: ItemInput!): ID!
createUser(input: UserInput!): ID!
}
type Item {
id: ID!
name: String!
}
input ItemInput {
name: String!
}
type User {
id: ID!
name: String!
}
input UserInput {
name: String!
}
これを gqlgen で golang のサーバーサイドソースを自動生成して、Playgroundで動作確認してみたのが↓
( resolver.go は適宜修正している。)
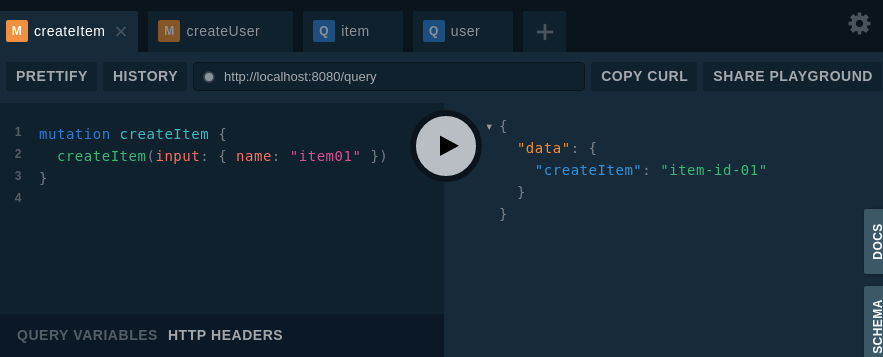
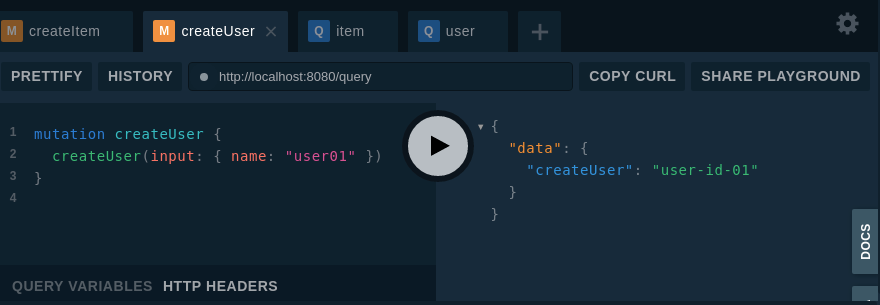
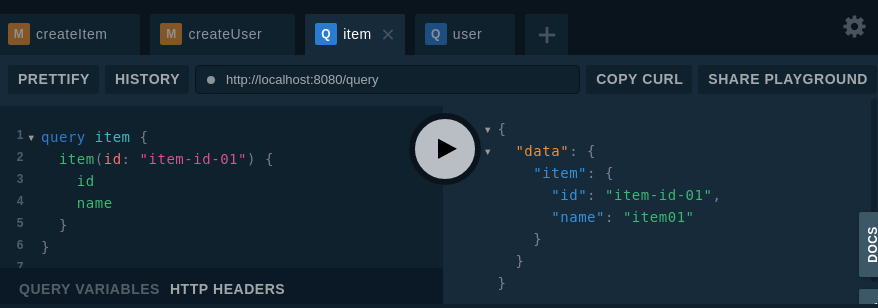
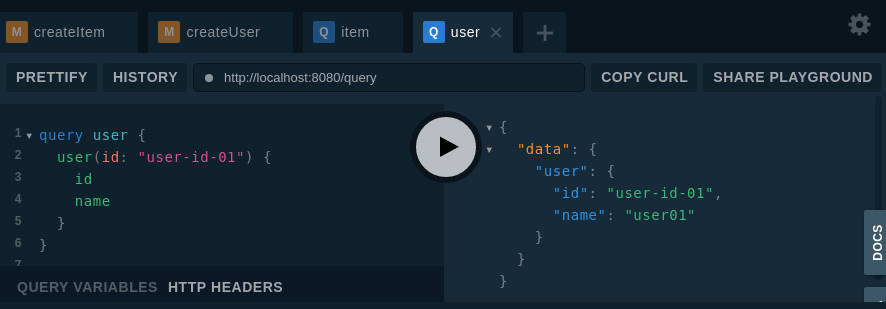
schema ファイル分割後
graphql.schema
Item と User に関する Query と Mutation を別ファイルに移動。
ただし、ベースとなる graphql.schema にも何かしら定義が必要になるため、Query の方は node 、Mutation の方は noop と適当なダミー定義を行う。
これらは、少なくとも現状は使わないので、gqlgen によって自動生成される resolver.go の中身は修正しない。
schema {
query: Query
mutation: Mutation
}
type Query {
node(id: ID!): String!
}
type Mutation {
noop(input: NoopInput): NoopPayload
}
input NoopInput {
clientMutationId: String
}
type NoopPayload {
clientMutationId: String
}
item.graphql と user.graphql
肝は、 extend というキーワード。
extend type Query {
item(id: ID!): Item
}
extend type Mutation {
createItem(input: ItemInput!): ID!
}
type Item {
id: ID!
name: String!
}
input ItemInput {
name: String!
}
extend type Query {
user(id: ID!): User
}
extend type Mutation {
createUser(input: UserInput!): ID!
}
type User {
id: ID!
name: String!
}
input UserInput {
name: String!
}
まとめ
これで、gqlgen によって自動生成されたソースは Item と User に関する部分に限って、
動作確認結果も含め、「schema ファイル分割前」と同じ内容・結果になる。
一応、今回の成果物は下記。
https://github.com/sky0621/study-gqlgen/tree/0cef7df53bee43e41e58258a9399d80cf7d2e7bd/try00
以上。