digdag(正確にはTreasureData Workflow)のtd_wait_table>, td_wait>を使ってみたのでそのメモです。
ジョブフロー
こんなフローで試してみました。
1. td_wait_table>で「wf_wait_target」というテーブルができるのを待つ
2. 「wf_wait_target」にクエリなげる
3. td_wait>で「wf_check」テーブルに100レコード以上のデータがストアされるのを待つ
4. 「wf_check」テーブルの内容を「export_wf_check」にエクスポート
digファイル、SQLは以下になります。
digファイル
timezone: Asia/Tokyo
schedule:
daily>: 09:00:00
_export:
td:
database: test
+task_wait_table:
td_wait_table>: wf_wait_target
+task1:
td>: queries/count_wf_wait_target.sql
+task_wait:
td_wait>: queries/check_record.sql
+task2:
td>: queries/export_wf_check.sql
create_table: export_wf_check
SQL
SELECT
count(1) as cnt
FROM
wf_wait_target
SELECT
count(1) > 100
FROM
wf_check
SELECT
*
FROM
wf_check
ジョブを実行してみる
作成したdig,SQLをTreasureData WorkflowにPushしてさっそく実行してみます。
td wf push wf_sample
td wf start wf_sample td_wait --session now
ここからはTreasureData Workflowのコンソールで確認していきます。
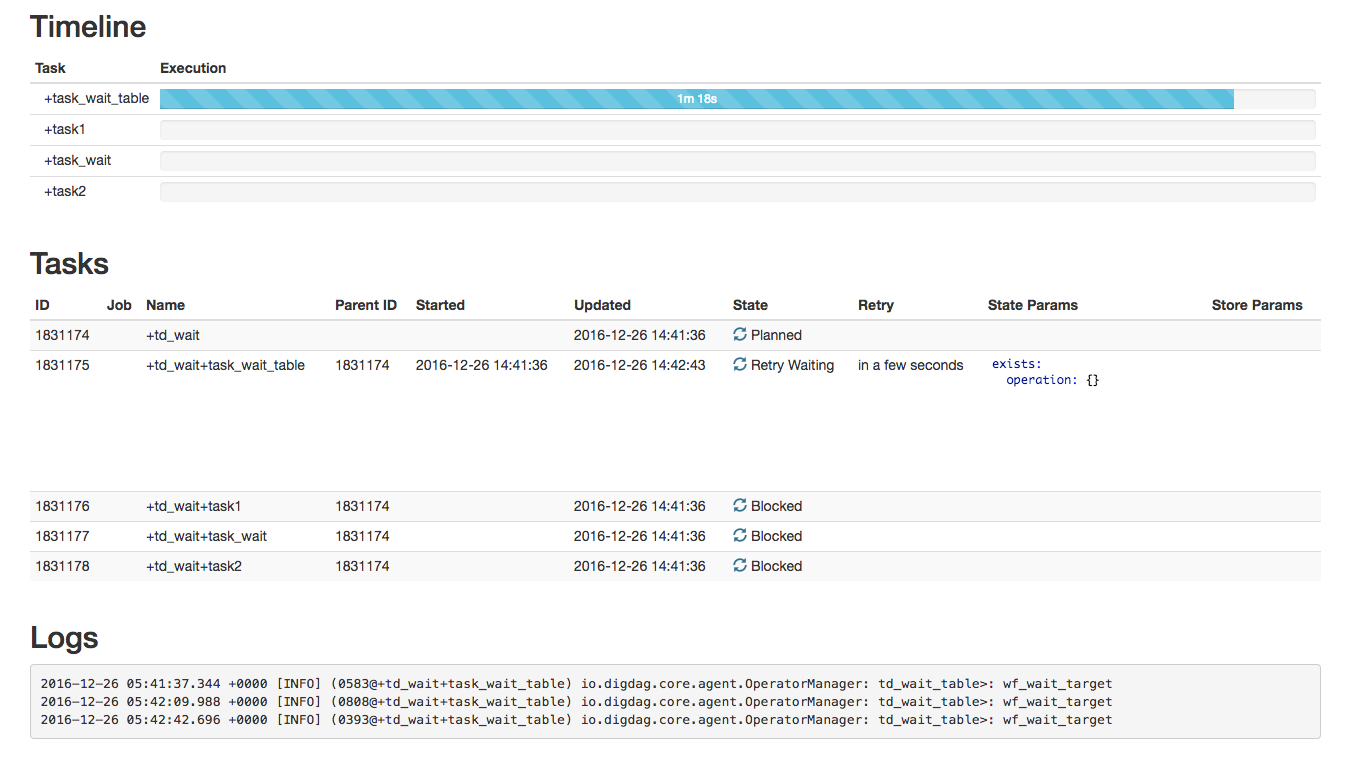
td_wait_table
「wf_wait_target」というテーブルができるのを待っています。
30秒に1度テーブルの存在をチェックしているのがわかります。
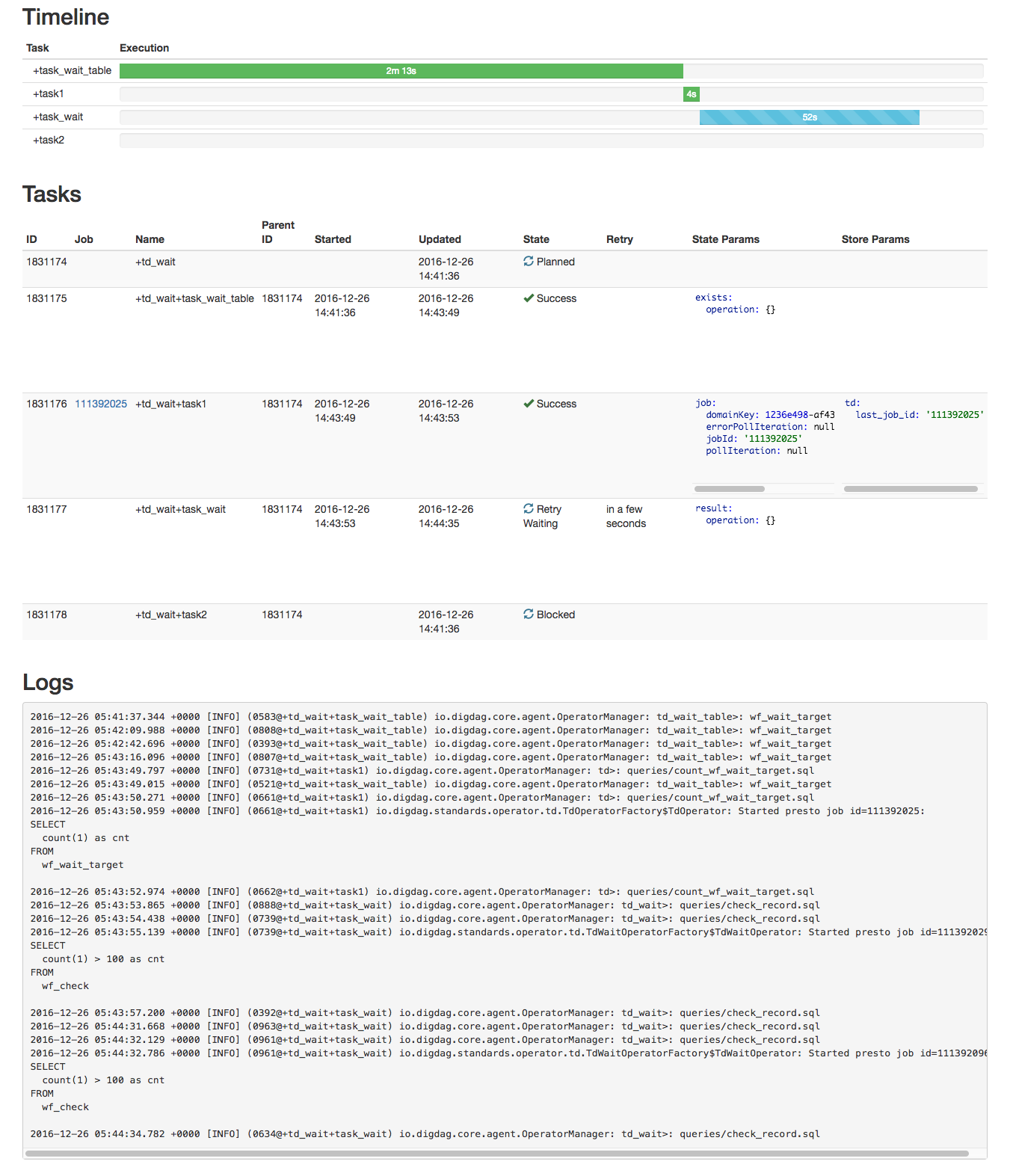
td_wait(レコード数)チェック
「wf_wait_target」テーブルを作成すると次に進んで、check_record.sqlを実行し、100行以上になっているかチェックしています。
Timelineも進んでいますね。
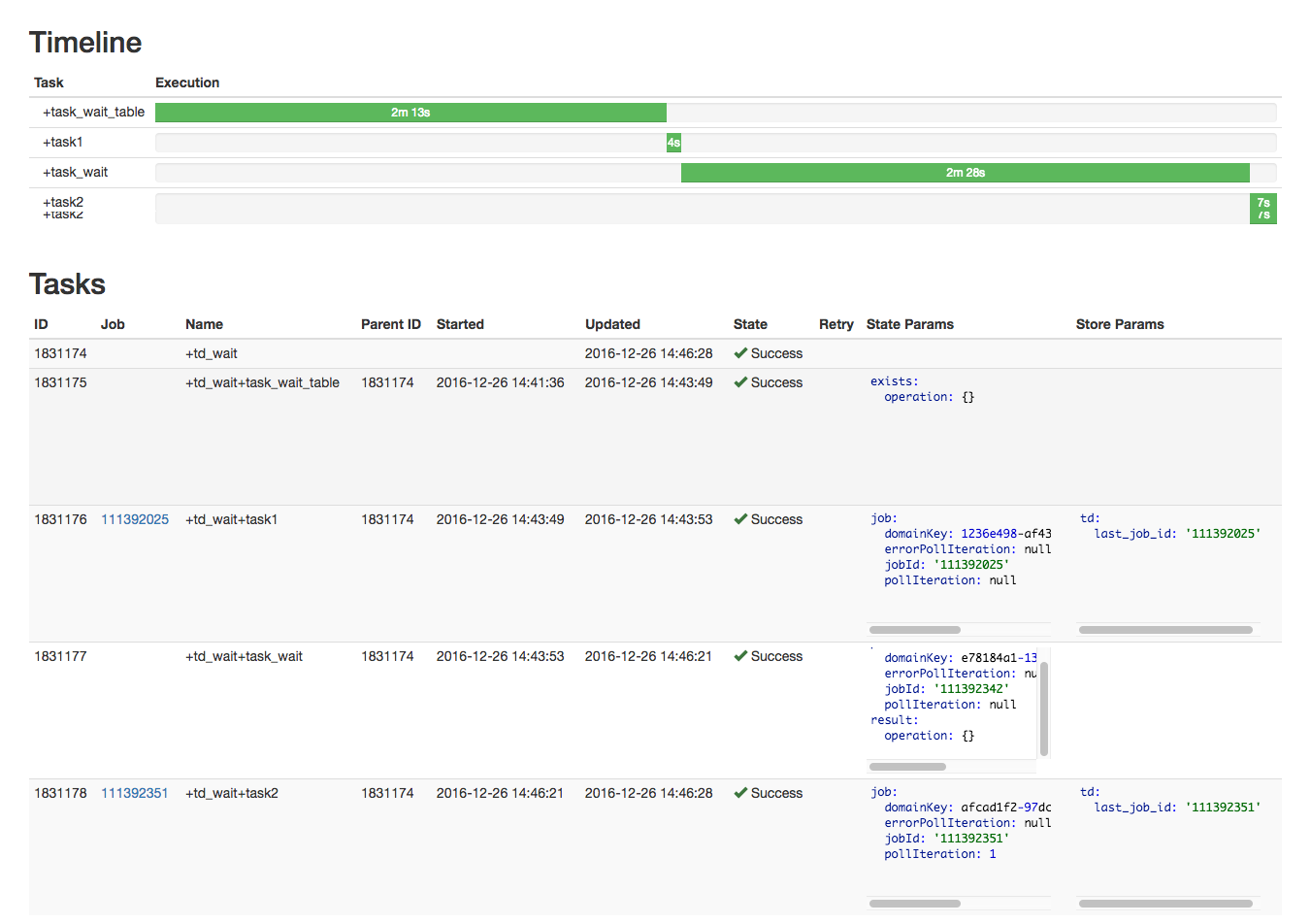
実行完了
「wf_check」テーブルに10,000行をInsertすると、最後のエクスポートまで無事完了しました。
さいごに
digdagのドキュメントにも記載されていますが、td_wait_tableは単純なテーブル有無だけではなくレコード数も条件に入れられるので非常に使い勝手がよさそうに思えます。
また、td_waitはtrueを返すまで待つので、単純な件数以外でも使えるのがいいですね。
ドキュメントには書いてないですが、このwaitにタイムアウトはあるのだろうか?
(digdagドキュメント)