digdag(正確にはTreasureData Workflow)の sla パラメータで若干ハマったのでメモ。
slaとは
ドキュメント の通りですが、一定の時間を過ぎた場合、あるいは指定の時間を超えた場合にアラートを飛ばすことができます。
こちらもドキュメントに記載してありますが、 fail: オプションでworkflowを失敗にすることができます。
* sla: parameter supports duration: HH:MM:SS syntax in addition to time: HH:MM:SS syntax.
* sla: parameter supports fail: BOOLEAN and alert: BOOLEAN options. Setting fail: true makes the workflow failed. Setting alert: true sends an notification using above notification mechanism.
実際にやってみる
僕がハマりポイントがわかりやすいように実際に動かしてみます
以下のようなワークフローを定義します。
内容としては td_wait_table> でテーブルを待つだけです。
SLAは10秒に設定していて、fail: false としています。
手動でワークフローを実行後、10秒経過してから対象のテーブルを作成しました。
sla:
duration: 00:00:10
fail: false
alert: false
+notice:
echo>: sla alert!!
+wait:
td_wait_table>: tdwf_wait
_error:
echo>: error!!
実行結果
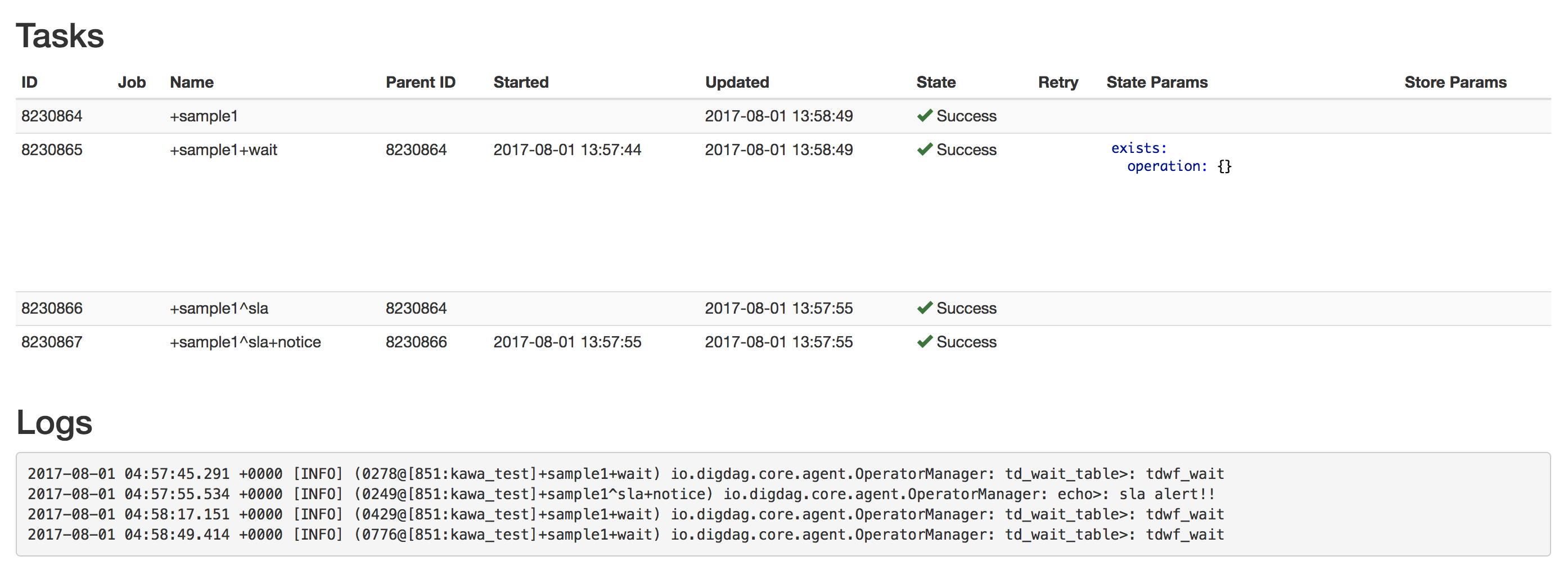
10秒以上経過したため、 +notice で定義した内容が実行されてます。
SLAは超過していますが、テーブルが作成されたので正常に終了しています。
次に、fail: trueにして同じように実行してみます。
実行結果
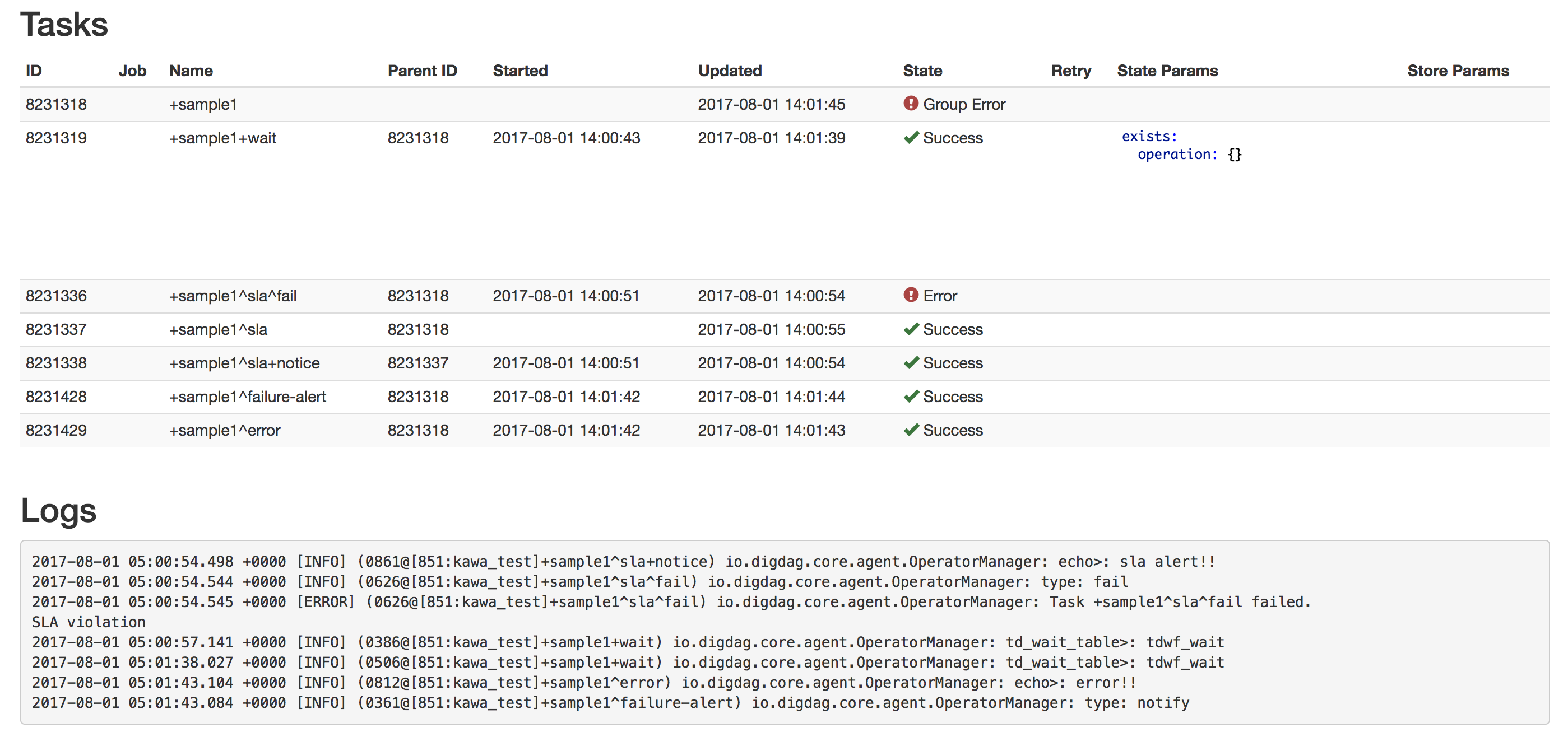
同じく、10秒以上経過したため、 +notice で定義した内容が実行されています。
SLAは超過していますが、その後もタスクは実行され続け、テーブルを作成した時点でtd_wait_tableが正常終了で終わりますが、このタスク自体のステータスは失敗となります。
そのため、 _errorで定義した内容も実行されているのがわかります。
個人的に勘違いしていた点として、 fail: true にするとSLAを超えた時点で終了すると思っていましたが、そうではありません。
次にテーブルを作成せずに、途中でキャンセル(kill)してみます。
キャンセルはtd_wait_tableやs3_waitで24時間以上待っても存在しない場合に発生してしまいます
実行結果
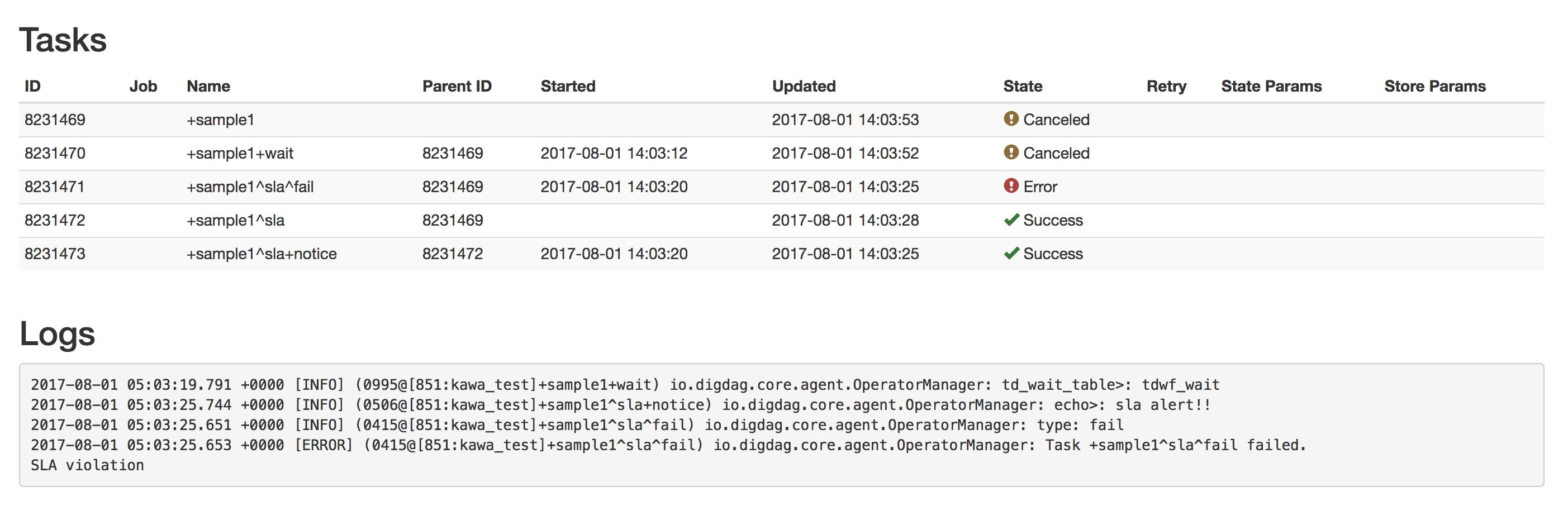
タスクのステータス自体はキャンセルしているので、失敗となります。
ここで注目してほしいのでは _errorで定義した内容が実行されない ということです。
指定したSLAを超えた場合は+noticeで定義した内容を実行できますが、waitのタスクで24時間を超えても対象が存在しない場合は要注意です。
まとめ
-
fail: trueとしてもタスクが中断されるわけではない - waitのタスクで24時間超えた場合はキャンセルとなり、error処理が実行できない
fail: trueのユースケースってあるんだろうか。。
備考
- TD workflow 0.9.13で実行