TreasureData Workflow(digdag)とは?
TreasureDataが開発したワークフローエンジンです。
詳細は以下のドキュメントを。
https://www.digdag.io/
http://docs.digdag.io/
https://docs.treasuredata.com/articles/workflows
はじめる前に
概要はもちろん読んでおくとして、projectやsession, attemptなるものが出てきて、最初はやや混乱するので、以下を読んでおくとよさそう
ここからコピペです
Projects and revisions
In Digdag, workflows are packaged together with other files used in the workflows. The files can be anything such as SQL scripts, Python/Ruby/Shell scripts, configuration files, etc. This set of the workflow definitions is called project.
なるほどなるほど。
Sessions and attempts
A session is a plan to run a workflow which should complete successfully. An attempt is an actual execution of a session. A session has multiple attempts if you retry a failed workflow.
sessionは1つのワークフローの実行単位で、sessionとattemptsは1:nの関係であると、なぜなら
The reason why sessions and attempts are separated is that an execution may fail.
失敗する可能性があるので分けていると。
なるほどなるほど。
実践
基本的にはここに書いてあるチュートリアルをもとに(というかほぼおなじこと)をやりました
workflowを定義するdigファイルを作成
こんな感じ。内容としては日次(7:00)にsum1.sqlを実行して結果をtest_wf1のテーブルに入れて、次にsum2.sqlを実行してtest_wf2に入れます。
timezone: Asia/Tokyo
schedule:
daily>: 07:00:00
_export:
td:
database: test
+task1:
td>: queries/sum1.sql
create_table: test_wf1
+task2:
td>: queries/sum2.sql
create_table: test_wf2
SQL
SQLはこんな感じです。test1とtest2というテーブルに同じSQLを投げているだけです。
SELECT
created_by,
count(distinct ip) ip,
count(distinct user) uu,
count(1) as logs
FROM
test1
WHERE
TD_TIME_RANGE(time, '2016-12-08 00:00:00','2016-12-08 01:00:00')
GROUP BY
created_by
SELECT
created_by,
count(distinct ip) ip,
count(distinct user) uu,
count(1) as logs
FROM
test2
WHERE
TD_TIME_RANGE(time, '2016-12-08 00:00:00','2016-12-08 01:00:00')
GROUP BY
created_by
ディレクトリ構成
SQLはqueries配下に置きます
wf_sample/
├── job1.dig
└── queries
├── sum1.sql
└── sum2.sql
ローカルで実行
TDのworkflowへ上げる前にローカルで実行してみましょう
$ td wf run job1
2016-12-08 20:15:49 +0900: Digdag v0.8.22
2016-12-08 20:16:02 +0900 [WARN] (main): Using a new session time 2016-12-08T00:00:00+09:00 based on schedule.
2016-12-08 20:16:02 +0900 [INFO] (main): Using session /xxx/xxx/digdag/wf_sample/.digdag/status/20161208T000000+0900.
2016-12-08 20:16:02 +0900 [INFO] (main): Starting a new session project id=1 workflow name=job1 session_time=2016-12-08T00:00:00+09:00
2016-12-08 20:16:04 +0900 [INFO] (0017@+job1+task1): td>: queries/sum1.sql
2016-12-08 20:16:05 +0900 [INFO] (0017@+job1+task1): td-client version: 0.7.26
2016-12-08 20:16:05 +0900 [INFO] (0017@+job1+task1): Logging initialized @16349ms
2016-12-08 20:16:06 +0900 [INFO] (0017@+job1+task1): td>: queries/sum1.sql
2016-12-08 20:16:07 +0900 [INFO] (0017@+job1+task1): Started presto job id=xxxxxxx:
DROP TABLE IF EXISTS "test_wf1";
CREATE TABLE "test_wf1" AS
SELECT
created_by,
count(distinct ip) ip,
count(distinct user) uu,
count(1) as logs
FROM
test1
WHERE
TD_TIME_RANGE(time, '2016-12-08 00:00:00','2016-12-08 01:00:00')
GROUP BY
created_by
2016-12-08 20:16:09 +0900 [INFO] (0017@+job1+task1): td>: queries/sum1.sql
2016-12-08 20:16:13 +0900 [INFO] (0017@+job1+task1): td>: queries/sum1.sql
2016-12-08 20:16:17 +0900 [INFO] (0017@+job1+task1): td>: queries/sum1.sql
2016-12-08 20:16:26 +0900 [INFO] (0017@+job1+task1): td>: queries/sum1.sql
2016-12-08 20:16:28 +0900 [INFO] (0017@+job1+task2): td>: queries/sum2.sql
2016-12-08 20:16:29 +0900 [INFO] (0017@+job1+task2): td>: queries/sum2.sql
2016-12-08 20:16:31 +0900 [INFO] (0017@+job1+task2): Started presto job id=xxxxxxx:
DROP TABLE IF EXISTS "test_wf2";
CREATE TABLE "test_wf2" AS
SELECT
created_by,
count(distinct ip) ip,
count(distinct user) uu,
count(1) as logs
FROM
test2
WHERE
TD_TIME_RANGE(time, '2016-12-08 00:00:00','2016-12-08 01:00:00')
GROUP BY
created_by
2016-12-08 20:16:33 +0900 [INFO] (0017@+job1+task2): td>: queries/sum2.sql
2016-12-08 20:16:36 +0900 [INFO] (0017@+job1+task2): td>: queries/sum2.sql
Success. Task state is saved at /xxx/xxx/digdag/wf_sample/.digdag/status/20161208T000000+0900 directory.
ちゃんと集計されたデータが入っています

TD workflowへpush
正常に動作することを確認できたので、定義したjobをpushします
$ td wf push wf_sample
2016-12-08 20:09:23 +0900: Digdag v0.8.22
Creating .digdag/tmp/archive-5532475972498044837.tar.gz...
Archiving job1.dig
Archiving queries/sum1.sql
Archiving queries/sum2.sql
Workflows:
job1
Uploaded:
id: xxxxxxx
name: wf_sample
revision: 36b26035-872d-419e-bed8-ab665d5996d9
archive type: db
project created at: 2016-12-08T11:09:43Z
revision updated at: 2016-12-08T11:09:43Z
アップされたようです。コマンドラインからも確認できますが、UIもあるのでそっちで確認してみましょう。
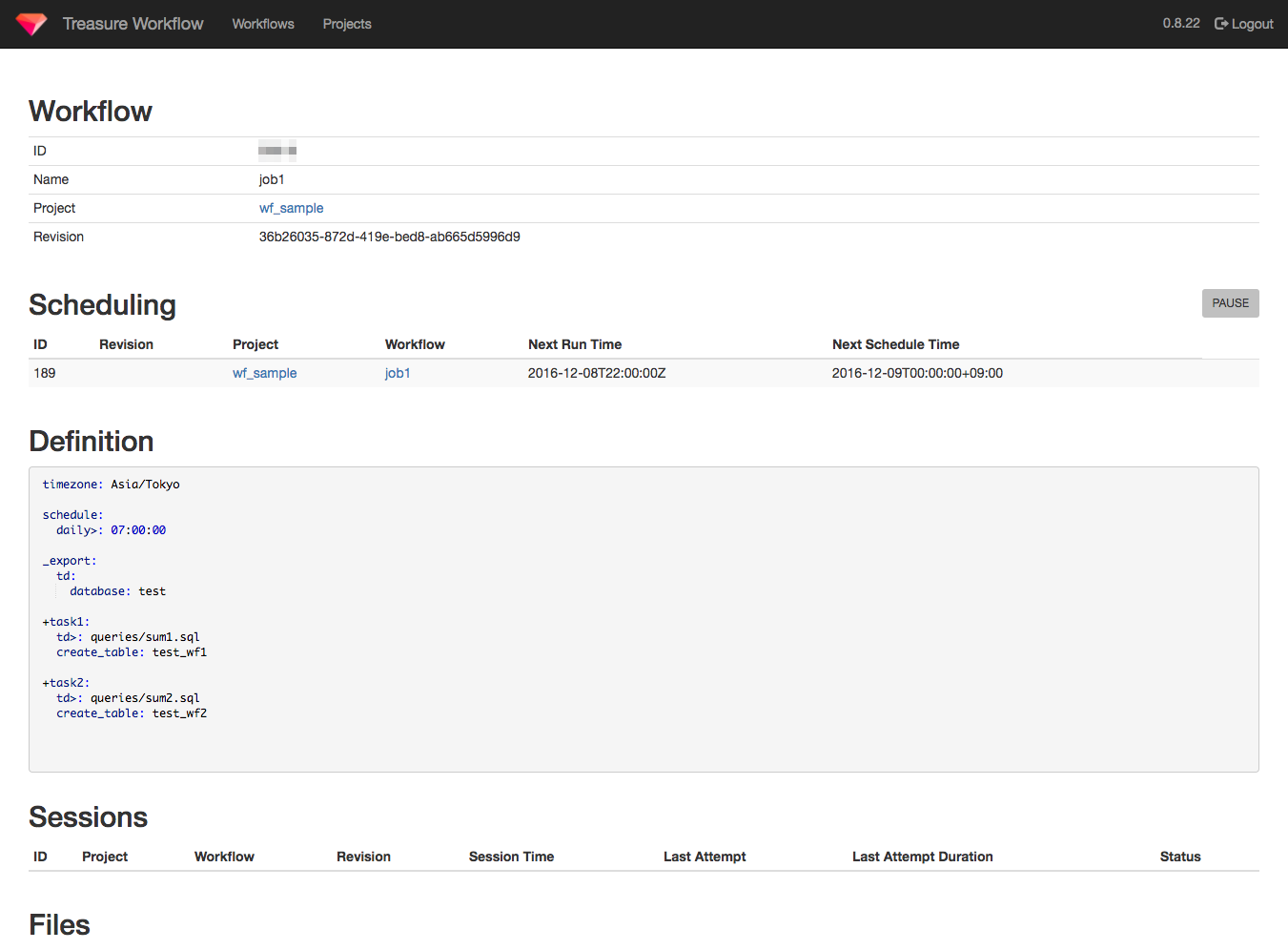
いい感じですね。次回の実行時間なんかもでてます。
TD workflowでの実行
pushに成功したのでTD workflow(サーバサイド)で実行してみます。
$ td wf start wf_sample job1 --session now
2016-12-08 20:22:03 +0900: Digdag v0.8.22
Started a session attempt:
session id: xxxxxx
attempt id: xxxxxx
uuid: 4608a620-b8c2-48f9-beb3-209f0b203d44
project: wf_sample
workflow: job1
session time: 2016-12-08 20:22:15 +0900
retry attempt name:
params: {"last_session_time":"2016-12-08T00:00:00+09:00","next_session_time":"2016-12-09T00:00:00+09:00"}
created at: 2016-12-08 20:22:26 +0900
* Use `td workflow session xxxxxx` to show session status.
* Use `td workflow task xxxxxx` and `td workflow log 613218` to show task status and logs.
こちらも管理画面で確認してみる。Sessionsに1行追加されていて、StatusがSuccessになっています。

詳細画面ではタスク1つ1つの状況も見えます
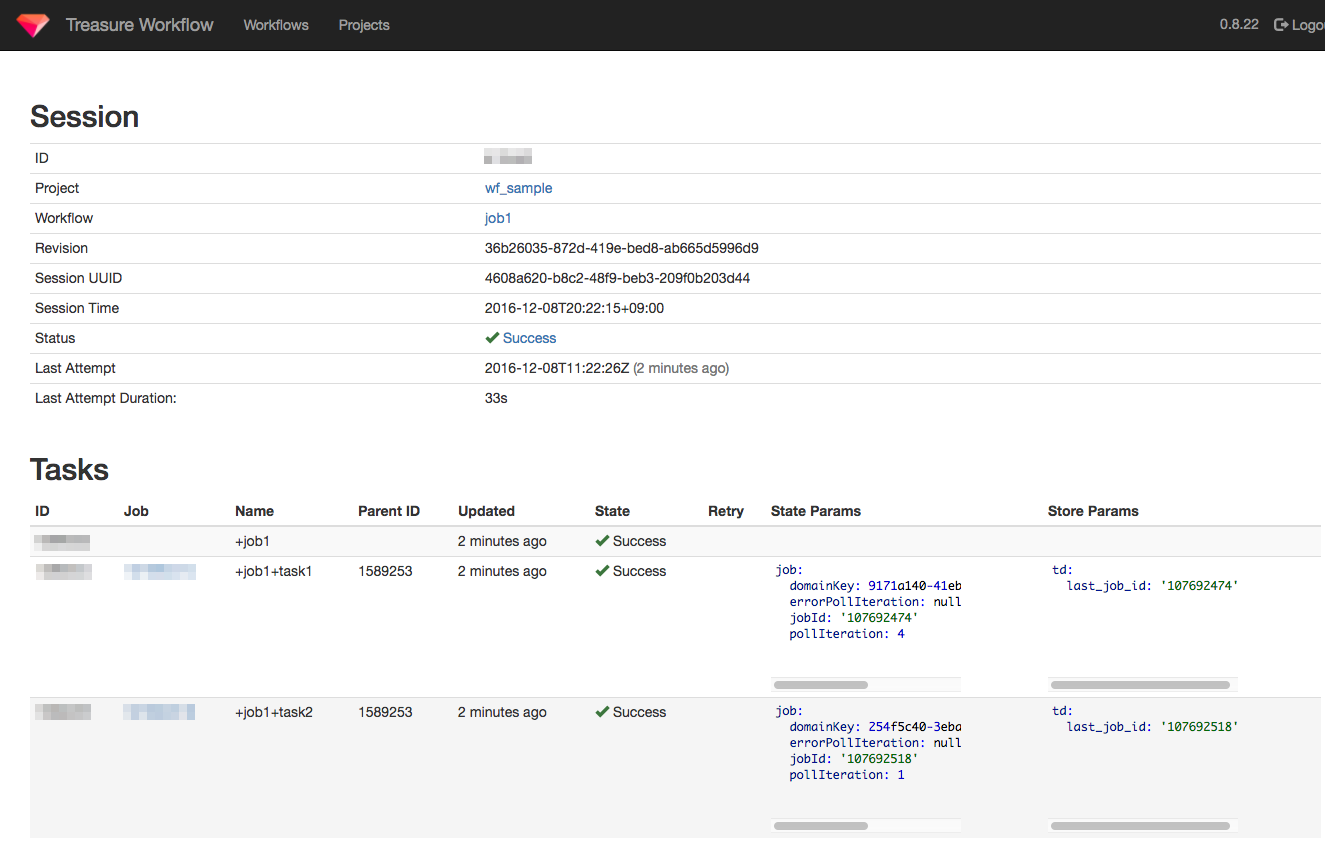
UIがなかなかいい感じです。
もうちょっと使ってみたですが書き疲れたので一旦ここで終了。
digdagとは違って、TDのworkflowの場合シェルなどのTDのクエリ以外はいまのところできないが、それでもTD内で完結するものもあるので、ちょっとしたものならこれで十分な気がします。