はじめに
測定中の装置の様子をウェブカメラなどを使ってリモートで監視しているときに、せっかく監視してるんだからくディスプレイに表示されている数字くらい記録しておきたいと思うことがあります1。これを実現する最も簡単な方法は一定時間ごとの画像取得です。しかし、残された大量の画像から異常や特定期間の様子を探し出すのは少し骨が折れます。「うまいこと数字を抽出してログデータにできたらな…」と一度くらいは思ったことのある方が多いのではないでしょうか。固定視点の画像からたった10種類の数字を判別するだけです。数字の位置を定義して0-9までの雛形のどれに当てはまるか判定していけばできそうです。機械学習など必要ないでしょう。しかし、実際やるとなるといろいろと細かい点でつまずきそうで、なかなか手を出しにくいタスクではあります。この記事では、Pythonを使って非常に単純な仕組みで大量の固定視点画像から数字を抽出する方法を紹介します。画像から数字を抽出する方法を調べようとしてググると、でてくる情報のほとんどが紙などに印刷された数字を読み取るOCRや手書き文字の機械学習に関するものです。OCRは今回のようなにじみがあるような画像に弱そうですし2、機械学習は正直このタスクには高級すぎるでしょう。それらの隙間を埋めるような記事になると思います。画像切り出しや歪み補正、数字の位置の特定などはじめに手作業による調整は必要ですが、実装が複雑でうまくいかないとお手上げになりがちな完全自動抽出よりもコードが単純である分、個別事例への適用は容易なはずなので、うまいこと自分の事例に合わせて使ってみてください。
今回使う画像を取得した方法
説明するより下の画像を見た方が早いでしょう。

装置の前にSurfaceを置き内蔵カメラの標準撮影ソフト「カメラ」を立ち上げ、そのウィンドウをスクリーンショットソフトで一定時間ごとに撮影しただけです。自動撮影にはKIOKUを使いました。画像の保存先を手元のノートPCとクラウド同期しているフォルダにすることで、ウェブカメラの設置に必要な固定IPなしで、非常にシンプルな装置監視システムを構築できます。
ただし、Surfaceに限らずWindowsマシンを使う場合は自動アップデートが大変やっかいです。画像ファイルのサイズを減らすためアクティブウィンドウのみを撮影対象にすると、途中から再起動を促すウィンドウを撮影し続ける羽目になります。今回の例では数日の測定時間の間だけ監視したかったので、自動更新を無効化できる18時間の「アクティブ時間」をちょくちょくずらして対応しました。サイズを気にしないならば画面全体の撮影にすれば悲しい結果にならずに済むと思います。
取得した画像の例
日が暮れると照明が自動的に消えてしまう場所だったので、夜に撮影した画像は自動露出調整で対応しきれなかったのかディスプレイの数字が少し滲んでいます。左が日中、右が夜間の消灯後です。クリックすると実際に使った画像を見れます。


画像サイズは1200x700程度です。サイズ節約を優先してかなり小さいウィンドウにしましたが、これはやはり解析の難易度という点においては間違った選択でした。数字部分の解像度はもう少しあった方が判定しやすかったと思います。
デジタル数字の表示方法はいくつかありますが、今回は例からわかる通り7セグメントディスプレイと呼ばれるよく見るタイプです
このような画像から数字を抽出するタスクのポイントは以下の三点です。
- 画角の中央から外れた時の発生する歪みを補正する(perspective transformation)
- 画質の異なる画像をうまく二値化する
- 7つのセグメントのオン/オフをうまく判定する
1と2で画像処理ライブラリとして有名なOpenCVを活用します。
参考にしたコード
Recognizing digits with OpenCV and Python - PyImageSearchで公開されているコードをベースにしています。オリジナルのコードは輪郭抽出と呼ばれる手法を使って一番面倒な数字部分の抽出を自動化しているため、数字がきれいに写っている画像を与えれば全自動で数字を認識してくれます3。しかし、私の例はあまりきれいな画像ではなかったのと固定視点なので自動化にこだわる必要もないだろうと判断して、数字部分の抽出を手動で行なっています。
準備
パッケージ
手動でのパラメータ調整が必要なのでいろいろと試した結果を残しやすいJupyter notebookで実行することを推奨します。必要なパッケージとバージョンは以下の通りです。Python 3.6を使っています。
%matplotlib inline
import matplotlib.pyplot as plt
import cv2
import numpy as np
import pandas as pd
from pathlib import Path
from matplotlib import __version__ as mplv
from matplotlib.ticker import MultipleLocator, FixedLocator
from matplotlib.patches import Rectangle, Polygon
from matplotlib.collections import PatchCollection
print('numpy:', np.__version__)
print('pandas:', pd.__version__)
print('matplotlib:', mplv)
print('OpenCV:', cv2.__version__)
# numpy: 1.13.3
# pandas: 0.23.1
# matplotlib: 2.2.2
# OpenCV: 3.3.1
OpenCVはcv2という名前でインポートしていますが、バージョンは3.3.1です。
関数
切り出し範囲と歪み補正の調整のために関数を作っておきます。ポイントは以下の通りです。
- 実際は切り出しと歪み補正は一つの関数(
cv2.warpPerspective)で行なっている -
if imshowのブロックで拡大した時にピクセル座標がピクセルの中央にくるように調整 - 切り出し&歪み補正の対象範囲を半透明の
Polygonで明示
ここでピンとこなくても実際の調整結果を見るとわかると思います。
def CropTransformShowDigits(src, pnts, dstsize, decimalsub=None, imshow=False, roi=None):
'''
input
src: 元画像
roi: タプル, (xmin, xmax, ymin, ymax) 左上原点でxは水平方向、yは垂直方向
pnts: 元画像の切り出し範囲 4点(x,y)のリストかタプル , (左上, 右上, 右下, 左下)
dstsize: タプル, (height, width) 切り出し後のサイズ
decimalsub: タプル, 小数点を消すために暗いピクセルの値を代入する範囲を指定 (xmin, xmax, ymin, ymax)
imshow: 結果を表示する際にはTrue
roi: imshowがTrueのときは元画像のズームにつかう(xmin, xmax, ymin, ymax)
output
dst: 切り出して歪み補正をした画像
'''
pts1 = np.float32(pnts)
height, width = dstsize
pts2 = np.float32([[0, 0], [width,0], [width, height], [0, height]])
# 切り出しと歪み補正
M = cv2.getPerspectiveTransform(pts1, pts2)
dst = cv2.warpPerspective(src, M, (width, height))
# 小数点の位置に暗いピクセルの値を代入
if not decimalsub is None:
xmin, xmax, ymin, ymax = decimalsub
dst[ymin:ymax+1, xmin:xmax+1] = dst[0, 0]
# 結果表示
if imshow:
fig, axes = plt.subplots(1,2, figsize=(8, 3))
xmin, xmax, ymin, ymax = roi
axes[0].imshow(src[ymin:ymax+1, xmin:xmax+1], cmap=plt.get_cmap('Greys_r'),
extent=[xmin-0.5, xmax+0.5, ymax+0.5, ymin-0.5])
axes[0].add_patch(Polygon(pnts, fc='w', ec=None, alpha=0.5))
# 明るいところを白く表示するためにはGreysを反転させたGreys_rを使う
axes[1].imshow(dst, cmap=plt.get_cmap('Greys_r'),)
return dst
全画像ファイルへのパス
約3600枚の画像へのパスを用意しておきます。
imagepaths = list(Path('number_recognition/').glob('*.jpg'))
手順
必要部分の切り出しと歪み補正パラメータの調整
上に示した例を見ると、四つのディプレイの上段と下段にそれぞれ数字が表示されています。ログを取りたいのは左の二つのディスプレイの上段の数字(ヒーター付近と試料付近の温度)です。今回は固定視点の画像なので、最初の一枚を使って調整すれば全ての画像に使えるはずです。また、この段階で二値化する際に厄介な小数点も削除しておきます。
先ほど定義したCropTransformShowDigits関数を使ってroiでpntsを調整しながらいい感じになる数字を探します。以下はいい感じに調整した結果です。ちなみに、このあとの手順で二値化するので画像読み込みの時点でグレイスケールにしています4。
pathstr = str(imagepaths[0])
gray = cv2.imread(pathstr, cv2.IMREAD_GRAYSCALE) # 数字部分が暗い場合は白黒反転が必要
roi_heater = (695, 787, 282, 345)
pnts_heater = [[724, 299], [778, 297], [775, 322], [721, 323]]
decimalpoint_heater = [37, 39, 16, 19]
dstsize = (21, 52)
warped_heater = CropTransformShowDigits(gray, pnts_heater, dstsize, decimalsub=decimalpoint_heater, imshow=True, roi=roi_heater)
roi_sample = (796, 894, 280, 340)
pnts_sample = [[829, 295], [883, 294], [879, 317], [825, 318]]
decimalpoint_sample = [36, 38, 15, 18]
dstsize = (21, 52)
warped_sample = CropTransformShowDigits(gray, pnts_sample, dstsize, decimalsub=decimalpoint_sample, imshow=True, roi=roi_sample)


左側には調整に便利なようにroiで指定されたディスプレイ部分を拡大して表示して、切り出しと歪み補正の対象部分は白い半透明な図形をかぶせてあります。右側が切り出しと歪み補正の結果です。今回のように複数個所の数字を読み込む場合は、なるべく結果の見た目が同じになるようにするのがポイントです。
全データを試行錯誤しやすいDataFrameに格納
固定視点のはずですが、1枚目の画像から決めた範囲でうまいこと切り出せているか確認した方がいいでしょう。もし何らかの理由で少し視点がずれている時間帯があればそこだけ別途調整が必要です。また、このあとの二値化やセグメントのオン/オフまで進んでから微調整が必要になる可能性も高いので、試行錯誤しやすいDataFrameに補正結果を格納しておきます。
以下は試行錯誤の末、1枚目だけの調整ではうまくいかなかった点を全て調整した結果です。二回あったわずかな視点変化とちょっとしたミス5でデスクトップ全体が撮影されていた時間帯への対応が含まれています。
# make or load DataFrame
def CropTemp(path, pnts_heater, pnts_sample, dstsize, decimal_heater, decimal_sample):
img = cv2.imread(str(path), cv2.IMREAD_GRAYSCALE)
# デスクトップ全体が撮影されていた場合への対応。「カメラ」ウィンドウのみ切り取り。
if img.size > 704*1217:
w, h = 1217, 704
xmin, ymin = 1154, 564
xmax, ymax = xmin+w, ymin+h
img = img[ymin:ymax+1, xmin:xmax+1]
dst_h = CropTransformShowDigits(img, pnts_heater, dstsize, decimalsub=decimal_heater)
dst_s = CropTransformShowDigits(img, pnts_sample, dstsize, decimalsub=decimal_sample)
return pd.Series([dst_h, dst_s], index=['cropped heater', 'cropped sample'])
def PathToDatetime(path):
return pd.to_datetime(path.stem[7:], format='%Y%m%d%H%M%S')
# 以前DataFrameを作っていればHDFファイルから読み込む。dfを作り直す際はdf.h5を削除。
if Path('df.h5').exists():
df = pd.read_hdf('df.h5')
else:
# ファイル数が多いと時間がかかるかもしれない部分なのでprintで進捗確認
df = pd.DataFrame({'path':imagepaths})
dstsize = (21, 52)
pnts_heater = [[724, 299], [778, 297], [775, 322], [721, 323]]
pnts_sample = [[829, 295], [883, 294], [879, 317], [825, 318]]
decimalpoint_heater = [37, 39, 16, 19]
decimalpoint_sample = [36, 38, 15, 18]
temp1 = df['path'].iloc[:54].apply(CropTemp, args=(pnts_heater, pnts_sample, dstsize, decimalpoint_heater, decimalpoint_sample))
print('temp1 done')
pnts_heater = [[723, 299], [777, 297], [774, 321], [720, 322]]
pnts_sample = [[828, 295], [881, 294], [877, 317], [824, 318]]
decimalpoint_heater = [37, 39, 16, 19]
decimalpoint_sample = [37, 39, 15, 18]
temp2 = df['path'].iloc[54:2684].apply(CropTemp, args=(pnts_heater, pnts_sample, dstsize, decimalpoint_heater, decimalpoint_sample))
print('temp2 done')
pnts_heater = [[745, 252], [800, 252], [796, 274], [742, 274]]
pnts_sample = [[852, 251], [906, 252], [902, 273], [848, 273]]
decimalpoint_heater = [37, 39, 16, 19]
decimalpoint_sample = [36, 39, 16, 19]
temp3 = df['path'].iloc[2684:].apply(CropTemp, args=(pnts_heater, pnts_sample, dstsize, decimalpoint_heater, decimalpoint_sample))
print('temp3 done')
df = pd.concat([df, temp1.append([temp2, temp3], ignore_index=True)], axis=1)
df['time stamp'] = df.path.apply(PathToDatetime)
# 作業を再開するときのためにHDFファイルに保存
df.to_hdf('df.h5', 'df')
3600枚の画像に対してこれを実行すると1分から数分程度かかりました6。pandasの高速化テクニックにはあまり精通していないので、この方法が最適である自信はありません。こういう時に適切な方法をご存知の方はコメントいただけるとありがたいです。
ファイル名に含まれる撮影日時の数字をdatetime形式にしてDataFrameに追加しています。今回は活用していませんが、試行錯誤の際は「何番目の画像」で指定するインデックス番号よりもdatetimeのほうが範囲を特定しやすいでしょう。期間の指定は通常のboolean indexingと同じようにできます。例えば8/10の深夜0時から1時の画像を取り出すなら以下で可能です。
df[(df['time stamp'] >='2018-08-10 00:00') & (df['time stamp'] <= '2018-08-10 01:00')]

本当に固定視点か確認
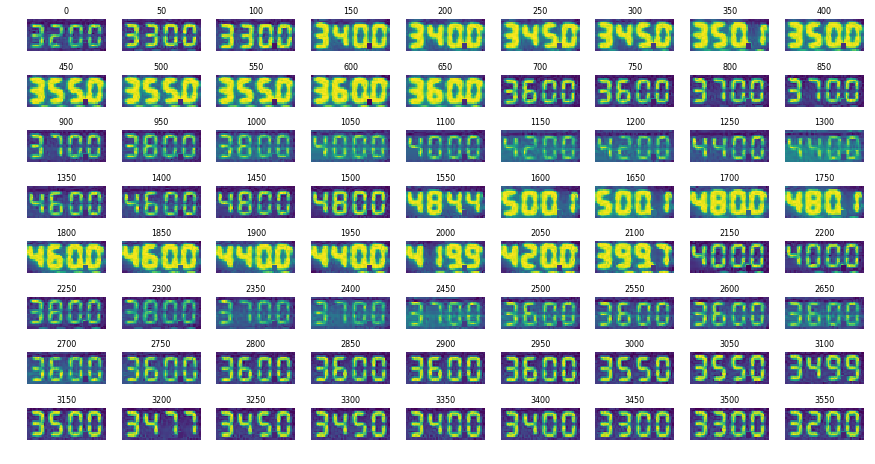
こればかりは適当な数をサンプリングして確かめるしかないでしょう。今回のケースでは以下のように約3600枚から50枚おきに歪み補正結果を一覧表示しておかしい部分を特定することで、数ピクセル程度のズレが二回発生していることを発見しました。
fig, axes = plt.subplots(8, 9, figsize=(15, 8))
for i, ax in zip(range(0, 3600, 50), axes.ravel()):
img = df['cropped heater'].iloc[i]
ax.imshow(img)
ax.set_title(i, fontsize=8)
ax.axis('off')
視点のわずかなズレを考慮して調整した結果がこちらです。このように並べると、数ピクセルというわずかな違いでも意外と「上の方の暗いピクセル部分の高さが少し違うかな…」などとわかりました。
また、操作ミスでデスクトップ画像を撮影していた時間帯は、以下のように全ピクセルの和(画像がどれだけ白いか)をプロットした時の異常値としてすぐに見つかりました。
df['cropped heater'].apply(np.sum).plot(marker='.')
df['cropped sample'].apply(np.sum).plot(marker='.')
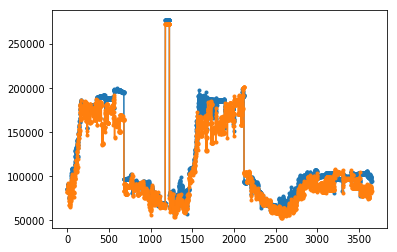
また、このプロットから、照明が消えて数字のディスプレイ部分が滲んでいる時間帯、つまりグレイスケール画像にした時に白い部分が多い時間帯もよくわかります。
なるべくきれいに二値化
実は単純に二値化と言っても、実際の画像を扱ってみると望ましい結果を得るにはいろいろと試行錯誤が必要なことがわかります。具体的には以下の三点の最適化です。
- ノイズ除去の度合い(カーネルのサイズと形状)
- 閾値の決定方法(定数かOtsu法かadaptiveに決めるアルゴリズムが必要か)
- 二値化後のノイズ除去や整形に使うモルフォロジー変換(変換の種類とカーネルの形状)
これらについて、対象とする画像の様子とやりたいタスクごとに自分で最適なレシピの組み合わせを見つける必要があるようです。私の場合は時間帯によって照明が消えているという画像処理においてやっかいな撮影条件があったので、それなりの試行錯誤が必要でした。最終的には以下のような組み合わせで満足できる結果が得られました。
# 3x3 arrayのガウスカーネルによるノイズ除去、分散は2ピクセル
blurred = cv2.GaussianBlur(img, ksize=(3, 3), sigmaX=2)
# 局所的な強度の分布により閾値を決定するadaptiveなアルゴリズムを使った二値化
binary = cv2.adaptiveThreshold(blurred, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY, 21, 0)
# 侵食と膨張と呼ばれるモルフォロジー変化を使った二値化後のノイズ除去/
kernel = np.ones((2, 2), np.uint8)
erosion = cv2.erode(binary, kernel, iterations = 1)
erodil = cv2.dilate(erosion, kernel, iterations = 1)
cv2.erodeとcv2.dilateの作用例は公式チュートリアルがわかりやすいです。
二値化の結果例をいくつか示します。ガウスぼかしによるノイズ除去の際に分散sigmaXを変えた時の変化です。
-
sigmaX=1のとき

-
sigmaX=2のとき

ご覧の通りほぼ同じに見えますが、後述する通り、数字の抽出結果を見ながら最終調整する際には差が出てきます。sigmaX=2にモルフォロジー変換を適用してみるとまた少し変わります。
-
sigmaX=2に侵食(cv2.erode)と膨張(cv2.dilate)を適用した時

適用前のsigmaX=2のデータと注意して比べるとわかりますが、同じカーネルを使った侵食と膨張を適用すると実質的にはx,y両方向に1ピクセルずつずらした結果が得られます。あとは比較的目立つ変化としては2350番あたりで「7」の左下の余白にあるノイズが消えていることがわかります。最終調整の際にはこのような細かい変化による改善が明らかになりました。
セグメント位置の定義
次はうまいこと作った二値化画像からセグメントのオン/オフを判定するために、七つのセグメントの位置を定義します。オン/オフはセグメント領域内の白ピクセル(上の画像では黄色ピクセル)の数の割合が基準値に達しているかどうかで判定します。今回の例におけるポイントは「セグメントの両端を判定対象から外し中央部分のみに注目する」という点でした。これは、実際にディスプレイ上のセグメントの領域を律儀に定義すると、滲んでる画像で誤判定が頻発したからです。位置の調整にはこれまでと同じようにサンプリングした画像一覧を使います。
# predefine seven digit segments
fig, axes = plt.subplots(8, 9, figsize=(15, 8))
kernel = np.ones((2, 2), np.uint8)
l, s = 4, 2 # セグメントの長辺、短辺のピクセル数
xh, yh = 4, 3 # topセグメントの左上の座標
xl, xr = xh-s, xh-s+s+(l+1) # top/bottom left, rightセグメントのx座標
yt, yc, yb = yh+s, yh+s+(l+1), yh+s+(l+1)+s+1 # top, center, bottomセグメントのy座標
# 7つのセグメントの左上座標
rects = [np.array((xh-0.5, yh-0.5)), # top
np.array((xl-0.5, yt-0.5)), # top left
np.array((xr-0.5, yt-0.5)), # top right
np.array((xh-0.5, yc-0.5)), # center
np.array((xl-0.5, yb-0.5)), # bottom left
np.array((xr-0.5, yb-0.5)), # bottom right
np.array((xh-0.5, yb+l-0.5)), # bottom
]
# セグメントの幅と高さ
rects_wh = [(l+1, s+1), # top
(s+1, l+1), # top left
(s+1, l+1), # top right
(l+1, s+1), # center
(s+1, l+1), # bottom left
(s+1, l+1), # bottom right
(l+1, s+1), # bottom
]
# 7つのセグメントを表す長方形を作成
patches = []
dxs = [(0, 0), (13, 0), (26, 0), (39, 0)] # 四桁の位置を定義
for dx in dxs:
for rect, wh in zip(rects, rects_wh):
patches.append(Rectangle(rect+dx, *wh, True))
for i, ax in zip(range(0, 3600, 50), axes.ravel()):
img = df['cropped sample'].iloc[i]
blurred = cv2.GaussianBlur(img, ksize=(3, 3), sigmaX=2)
binary = cv2.adaptiveThreshold(blurred, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY, 21, 0)
erosion = cv2.erode(binary, kernel, iterations = 1)
erodil = cv2.dilate(erosion, kernel, iterations = 1)
result = erodil
ax.imshow(result)
ax.xaxis.set_major_locator(FixedLocator([13, 25, 38]))
ax.grid(axis='x')
ax.set_title(i, fontsize=10)
ax.tick_params(bottom=False, left=False, labelbottom=False, labelleft=False)
p = PatchCollection(patches, color='r', alpha=0.5) # PathCollectionではない点に注意
ax.add_collection(p)
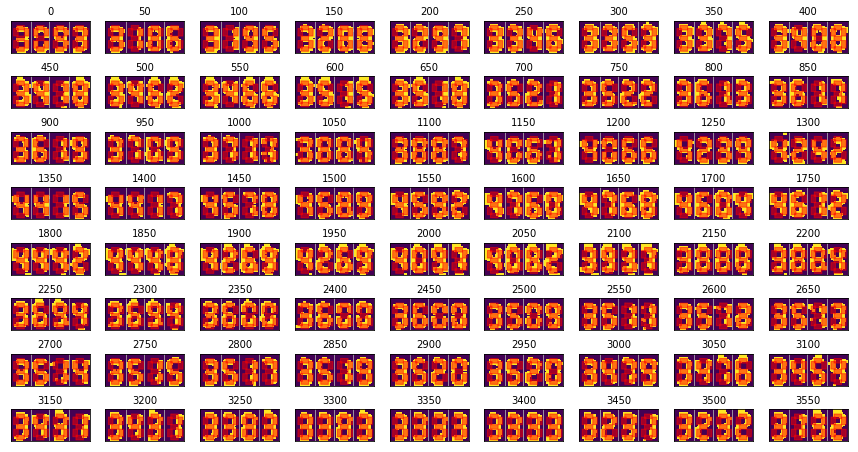
少し見にくいですが、赤い長方形で示されたセグメント領域が黄色い部分をだいたいカバーしていることがわかります。
数字抽出結果を見ながら最終調整
あとは以下の関数を使って画像から抽出した数字をDataFrameに格納してプロットしたり抽出に失敗している数を確認しながら、これまでの手順で決めてきたあれこれをいじって満足できる結果の得られる組み合わせを見つけるだけです。
def ExtractDigits(img, threshold, bounds, test=False):
# img: 切り出し&歪み補正済みグレイスケール画像
# threshold: オン/オフ判定基準
# bounds: imgにおける各桁の領域
# 二値化などの前処理
blurred = cv2.GaussianBlur(img, ksize=(3, 3), sigmaX=2)
binary = cv2.adaptiveThreshold(blurred, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY, 21, 0)
kernel = np.ones((2, 2), np.uint8)
erosion = cv2.erode(binary, kernel, iterations = 1)
erodil = cv2.dilate(erosion, kernel, iterations = 1)
processed = erodil
# 7つのセグメントのオン/オフと数字を対応させた辞書オブジェクト
# 0がオフ、1がオン
DIGITS_LOOKUP = {
# top, top left, top right, center, bottom left, bottom right, bottom
(1, 1, 1, 0, 1, 1, 1): 0,
(0, 0, 1, 0, 0, 1, 0): 1,
(1, 0, 1, 1, 1, 0, 1): 2,
(1, 0, 1, 1, 0, 1, 1): 3,
(0, 1, 1, 1, 0, 1, 0): 4,
(1, 1, 0, 1, 0, 1, 1): 5,
(1, 1, 0, 1, 1, 1, 1): 6,
(1, 0, 1, 0, 0, 1, 0): 7,
(1, 1, 1, 1, 1, 1, 1): 8,
(1, 1, 1, 1, 0, 1, 1): 9
}
# 7つのセグメント領域を定義
l, s = 4, 2
# xh, yh = 3, 2 #for binary
xh, yh = 4, 3 #for erodil
xl, xr = xh-s, xh-s+s+(l+1)
yt, yc, yb = yh+s, yh+s+(l+1), yh+s+(l+1)+s+1
segments = [np.array((xh, yh)), # top
np.array((xl, yt)), # top left
np.array((xr, yt)), # top right
np.array((xh, yc)), # center
np.array((xl, yb)), # bottom left
np.array((xr, yb)), # bottom right
np.array((xh, yb+l)), # bottom
]
segs_wh = [(l, s), # top
(s, l), # top left
(s, l), # top right
(l, s), # center
(s, l), # bottom left
(s, l), # bottom right
(l, s), # bottom
]
# オン/オフ判定結果を格納するリスト
digits = []
# 指定された桁に対してセグメントのオン/オフを判定
for i in range(len(bounds)-1):
# 指定された桁部分を取得
bound_l, bound_r = bounds[i], bounds[i+1]
roi = processed[:, bound_l:bound_r]
# 全セグメントをオフに初期化
on = [0] * len(segments)
# 7つのセグメントについて判定
for i, (xy, (w, h)) in enumerate(zip(segments, segs_wh)):
# ノンゼロピクセル数をカウント、
x, y = tuple(xy)
segROI = roi[y:y+h+1, x:x+w+1]
total = cv2.countNonZero(segROI)
area = l*s
# print('total, area:', total, area)
# ノンゼロピクセルが基準値thresholdより大きければオンと判定
if total / float(area) > threshold:
on[i]= 1
# テストモードならオン/オフ表示
if test:
print('on:', on)
# オン/オフのパターンから数字を判定
# テーブルにないパターンなら失敗
try:
digit = DIGITS_LOOKUP[tuple(on)]
except KeyError:
digit = 'Failed'
digits.append(digit)
# 失敗しなかったら文字列経由で小数点を打ち数字に変換
# 失敗したら0を代入
try:
if test:
print(digits)
plt.imshow(processed)
else:
return float('{}{}{}.{}'.format(*digits))
except ValueError: # if contains 'Failed'
return 0
まずはひとつの画像でテストしてみます。
img = df['cropped heater'].iloc[0]
ExtractDigits(img, threshold=0.85, bounds=[0, 13, 26, 38, 52], test=True)

うまく抽出できているので、全ての画像に対して実行して、結果をDataFrameに格納します。
df['heater temp'] = df['cropped heater'].apply(ExtractDigits, threshold=0.85, bounds=[0, 13, 26, 38, 52])
df['sample temp'] = df['cropped sample'].apply(ExtractDigits, threshold=0.85, bounds=[0, 13, 26, 39, 52])
df.plot(x='time stamp', y=['heater temp', 'sample temp'], marker='.', ls='none')
# 抽出失敗件数
print(len(df[df['heater temp'] == 0]), len(df[df['sample temp'] == 0]))
# 22 270

妙に大きな値や失敗は数百個ありますが、温度変化が完璧に把握できるレベルには抽出できました。
ちなみに二値化に関するパラメータを変えた際の抽出失敗件数を比べて見るとこんな感じになります。実はモルフォロジー変換なしでもセグメントの場所を合わせればそこそこよい結果になっているのがわかります。
| 二値化方法 | ヒーター温度失敗数 | 試料温度失敗数 |
|---|---|---|
sigmaX=2、侵食&膨張(最良) |
22 | 270 |
sigmaX=1、侵食&膨張 |
32 | 253 |
sigmaX=2、侵食 |
296 | 2232 |
sigmaX=2、モルフォロジー変換なし |
1115 | 2875 |
sigmaX=1、モルフォロジー変換なし |
1045 | 2951 |
sigmaX=2(セグメントをシフト) |
28 | 316 |
参考リンク
いろいろググって関連ページを探しましたが、これだけで十分でした。
- Recognizing digits with OpenCV and Python - PyImageSearch 参考にした自動抽出コード
- OpenCV: Geometric Transformations of Images perspective transformation(透視変換)について
- OpenCV: Image Thresholding 二値化について
- OpenCV: Smoothing Images ノイズ除去について
- OpenCV: Morphological Transformations モルフォロジー変換について
私は画像処理について特に詳しくない素人です。この記事で使っている方法の組み合わせやパラメータが今回のタスクに対して適切なものであるとは思っていません。むしろ詳しい方にとっては意味不明な操作が混じっている可能性は高いです。ひとまず目的を達成できたので記事にしましたが、変なところや改善可能なところがあればコメントいただけるとありがたいです。
-
もちろん、監視しているくらいなのでログファイルを取得できない状態を想定しています。例えば、ターボ分子ポンプについている真空計なんかはログ出力されていないものがおおいのではないでしょうか。 ↩
-
逆にいいディスプレイのきれいな数字ならtesseractを使ってOCRできるかもしれません。 ↩
-
しかし、コードを読んだ限り輪郭抽出部分が少し荒削りなので、そのままのコードでは1を認識できないでしょう。 ↩
-
この記事では数字部分が明るい(=グレイスケールにした時に白くなる=二値化したときに255になる)場合を扱っています。数字部分が黒いディスプレイの場合は白黒を反転させる必要があります。 ↩
-
アクティブ時間を調整した後「カメラ」ウィンドウをクリックし忘れていました。 ↩
-
原因は不明ですが、家とオフィスの環境でだいぶ実行時間が異なりました。 ↩