はじめに
Spanの公開に伴い、ReadOnlySequenceというクラスがnetcoreapp2.1のリリースと同時に公開された。
このクラス、役割や使い方が分かり辛かったので、整理をしてみた。
何をするためのクラスか
短く言うと、 不連続な配列のためのデータクラス。
不連続な配列というのは、
[A][B][C]
[D][E][F]
[G][H][I]
のように、メモリ的に連続してはいないものの、大きくみて一つの配列とみなせるものという意味。
これが導入されたのは、System.IO.Pipelinesのためと言っても良く、内部でがっつり使っている。
System.IO.Pipelinesについては、ざっくりいうと非同期バイトストリーミングのためのクラスで、
詳しくは以下を参照。
- StackExchangeの人が書いた記事(英語)
- Microsoft Docs上のAPIリファレンス
クラス概要
以下の三つのクラスを主に使うことになる。
ReadOnlySequenceSegment<T>
ReadOnlySequenceで使用される、単方向リンクを備えたデータクラス。
一塊の連続データ(Memory)、全体のシーケンスにおける位置情報(RunningIndex)、次のReadOnlySequenceSegment(Next)へのリンクを持つ
abstract classなので、継承して使用する。
SequencePosition
シーケンス内部の位置を表す構造体。
ReadOnlySequenceSegmentと、その中での位置インデックスを持つ。
同一値かどうかを判定はできるものの、相対的にどちらが先に進んでいるかは判定できない。
ReadOnlySequence<T>
上記二つを利用して、不連続領域を表すための構造体。
基本的な使い方
ReadOnlySequenceSegmentの自前定義
まず、ReadOnlySequenceSegmentを自分で継承する。
class MyReadOnlySegment<T> : ReadOnlySequenceSegment<T>
{
}
abstract classだが、abstractなメソッドやプロパティは無いので、メンバーを追加しなくてもコンパイルは通る。
セグメントの準備
次に、定義したReadOnlySequenceSegmentを使用して、データ領域を作成する。
// 最初の領域の定義
var ar1 = new byte[128];
var seg1 = new MyReadOnlySegment<byte>();
// Memory<T>としてデータを保持する
seg1.Memory = ar1.AsMemory();
// データの開始点は0
seg1.RunningIndex = 0;
seg1.Next = null;
// 次の領域の定義
var ar2 = new byte[128];
var seg2 = new MyReadOnlySegment<byte>();
seg2.Memory = ar2.AsMemory();
// 全体の配列で見たときの、この領域の開始点を指定する
seg2.RunningIndex = ar1.Length;
seg2.Next = null;
// 次の領域へのリンクを付ける
seg1.Next = seg2;
ReadOnlySequenceの作成
さて、このようにしてセグメント群を設定したら、それらをつなげてシーケンスを作成する。
// 開始点の場所と、終点の場所を指定する(2,4引数は、セグメント中のインデックス番号)
var seq = new ReadOnlySequence<byte>(seg1, 0, seg2, seg2.Length);
ReadOnlySequenceの利用
ReadOnlySequenceを作成したら、後はそれを実際に利用する。
foreach(System.ReadOnlyMemory<byte> mem in seq)
{
// GetEnumeratorを実装しているので、foreachでSystem.ReadOnlyMemory<T>が取得できる
// 開始点がSegmentの途中を指していた場合、開始点から切り取られた状態で取得ができる。
}
特に後処理等は必要ない。
場所情報の取得
ReadOnlySequence全体で見たときの、N番目の位置情報を取得したい場合は、ReadOnlySequence<T>.GetPosition()を使用する。
// 末尾データを取得したい場合は、seq.GetPosition(0, seq.End)のように指定する
SequencePosition pos = seq.GetPosition(N);
// GetObjectは必ずobjectを返すため、キャストして使用すること
var segment = (ReadOnlySequenceSegment<T>)pos.GetObject();
var index = pos.GetInteger();
//
例えば、サイズ128+128+128の三つのセグメントをReadOnlySequenceが抱えている状態で、GetPosition(192)した場合、
GetObject()==二番目のセグメント、GetInteger()==64を値に持つSequencePositionが返ってくる。
なお、 SequencePosition同士の足し引き、大小比較は不可 で、同一かどうかだけが確認可能となっているため注意が必要。
ハイパフォーマンスのために
さて、ここまで基本的な使い方を書いてきたが、ここまでだといまいち存在意義がわからない人も多いと思う。
ただ使用するだけだと面倒なだけで、それならば一つの配列のみで回した方が楽というのは確かにその通り。
ここで、Pipelinesが、このクラスをどのように使用しているかを見れば、そのメリットも見えてくるかもしれない。
Streamの処理手順と問題点
Streamの処理手順については大体以下のようになる。
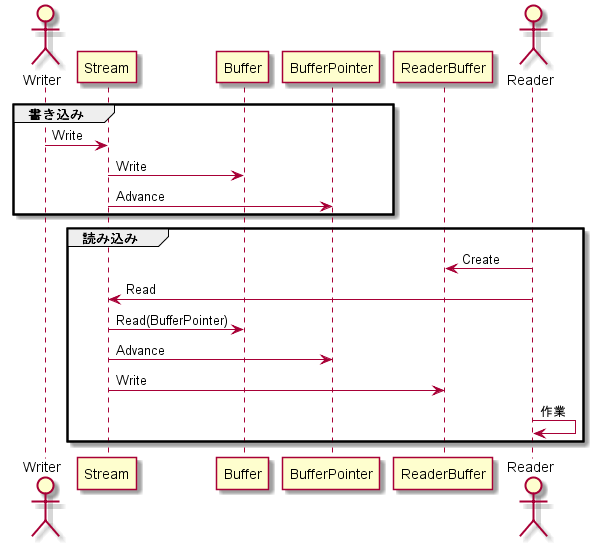
ここでの問題点は以下のようになる。
- 一つのBufferPointerを読み書きで共有しているため、同時進行したい場合はReadあるいはWriteの時に都度セットし直す必要がある
- StackExchangeの人は、これを"カセットテープのようだ"、と評している
- 最初のBufferへの書き込みと、ReaderBufferへの書き込みで、2回データコピーが発生する
- 書き込みバッファが溢れる場合、バッファの再確保→既存データのコピーが発生する(例外発生する場合もある)
Pipelinesの処理手順
大体以下のようになる。
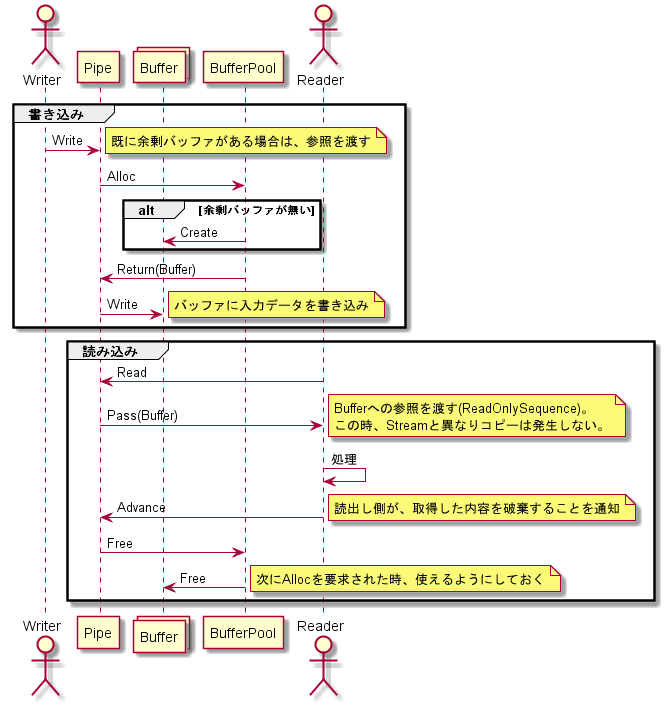
以上より、やや構造は複雑になっているものの、
- バッファの再確保とコピーが発生しない
- バッファポインタを共有していないため、並行処理が得意
という利点が発生する。特にバッファの再確保とコピーが発生しないという点については、かなりの利点と言えるのではないかと思う。
ここで問題になるのが、書き込み時点でPipe内ではバッファは細切れになって保持されているため、読出し側に渡す時に使いにくい状態になる。
そこで細切れになったバッファをまとめてくれるのがReadOnlySequence<T>というわけなのである。
使い回しの指針
ReadOnlySequenceとSequencePositionは基本的に使い回さない。
この点は、これらが構造体であるということからも間違いはないと思う。
よって、使い回すのはReadOnlySequenceSegmentと、そのバッファ領域ということになる。
使い回しの実装は、全て自作しても構わないが(実際Pipelinesはそうしている)、ArrayPoolを使えば、だいぶ楽はできると思う。
まとめ
ゼロアロケーションとゼロコピーによるパフォーマンス改善を目指してReadOnlySequenceを導入した、というのは、
ここ最近のC#の動向としてかなり面白いと思う。
ただし、ゼロアロケーションとゼロコピーすれば即ち速いかと言われると、そうでもないのがややこしいところ。
Streamに関していえば、完全に同期的に使う場合、Pipelinesの方がやることが多いため、StreamがPipelinesに比べて速い場合が多い。
ただし、比較的大きなデータを非同期で順次処理したい場合、Pipelinesというのはかなり使いでがあるクラスだと思う。
この辺りは、無条件にPipelinesに移行するのではなく、用途を確認して計測するべき、という話になってしまうのが辛いところ。
ここまで書いておいて何だけど、ストイックな事をしない限り、Pipelinesで使われているデータ構造なんだなー程度の理解で普段はいいと思う。