こんにちは。スキルアップAI編集部です。
本ブログでは、自然言語処理の分野における文章読解タスク、つまり、AIがどれほど「正確に」文章読解できているのかを測定するタスクに関してお話しします。本ブログの後半では、画像処理分野でよく聞かれるAdversarial Examplesとの関連性や、今後の課題について考えていきます。この記事を通して、文章読解タスクに関する研究に少しでも興味を持っていただけたら幸いです。
目次
1.文章読解タスクとは
2.文章読解タスクの課題
3.adversarial-examples
4.今後の課題
5.参考文献
1. 文章読解タスクとは
文章読解タスクについて考える前に、AIの研究全体における大きな関心事として次のことがあげられます。それは、「AIは、どれほど人間と同じように考えることができるのか」ということです。この問題は、自然言語処理の分野でも大変重要です。例えば、最近では当たり前のように使われている音声認識ソフトでも、人間の多種多様な質問に対して適切な答えを返すのは全く簡単なことではありません。
音声認識だけでなく、チャットボットのような文章についても同様、「AIがどれほど『正確に』文章読解できているのか」、つまり、「AIがどれほど人間と同じように文章を読むことができているか」について評価する必要があります。そして、その評価に使われる方法の一つが文章読解タスクです。図1に文章読解タスクの一例を示します。この問題の場合、たとえ英語が分からなくても、答えやその根拠は説明できるのではないでしょうか。実際、質問文に含まれている単語を問題文から探せば、自然とこの問題に対する答えは”John Elway”だとわかるはずです。

#2. 文章読解タスクの課題
図1で示した問題を、図2のように変えてみるといかがでしょうか。Paragraphの最後に、人間には全く関係ないように思われる一文、”Quarterback Jeff Dean had jersey number 37 in Champ Bowl XXXIV.”を加えただけのものになっています。この場合、予想される答えは図1と同じ、”John Elway”であるはずです。しかし、この問題をAIに解かせた場合、最後に加えた一文に惑わされ、”Jeff Dean”と答えてしまうということがあるのです。

Jiaら[3]によると、SQuADにおいて図2のように問題文に少し変更を加えたデータセットを考えると、元々は75%あった正答率がなんと36%にまで下がってしまったということが報告されています。これが示していることは、AIはまだ人間と同様に、あるいは同様と思われる程度に、文章を理解する能力を得てはいない、ということです。
つまり、現在の文章読解タスクでは、AIの文章読解能力を測りきるのに十分ではないということがわかります。実際、Rimellら[4]やPapernoら[5]によると、文章読解タスクの学習において、答えのありそうな場所やパターンのみの学習でも高い正答率を出せることが言われています。
この課題をより正確に判断し、文章読解タスクの改善に役立てるために、次で説明するAdversarial Examplesが重要になります。
3. adversarial-examples
Adversarial Examplesとは、直訳すると「敵対する例」ですが、一言で説明するなら、「AIを騙す入力例」です。画像処理の分野でよく考えられており、図3の画像は見たことのある方も多いでしょう。

図3.画像処理におけるAdversarial Examplesの例
(参考文献[6]より引用)
この例では、元となるパンダの画像に、人間には感知できないほどの小さなノイズを加えて新たな画像を作ると、AIは”gibbon”、つまり「テナガザル」と認識してしまうというものになっています。文章読解タスクにおいても同様で、前章で挙げた図2の例は、まさしくAdversarial Examplesの一つです。
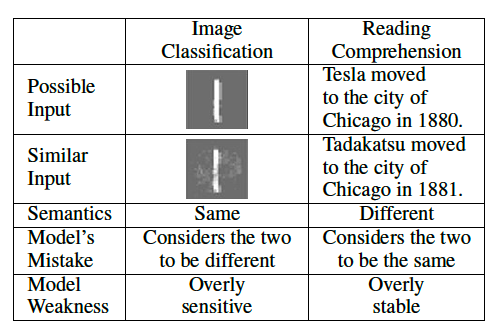
文章読解タスクにおけるAdversarial Examplesを考える際には、画像処理の場合との違いが重要になります。図4にまとめてある通り、元の入力とそれにノイズを加えたものを比べたとき、画像処理の場合には、人間には同じに見えるがAIには違って見えます。一方、文章読解タスクの場合は、人間には違う意味の文章に見えるが、AIは同じ文章であると認識してしまいます。
ここで改めて図2の問題に対する挙動を考えてみます。人間は、加えた最後の文は質問文と全く関係ないことを認識できますが、AIは、それらの違いをほとんど認識できず、結果的に誤った答えを出力してしまうといえます。
4. 今後の課題
Jiaら[3]の実験では、数種類のAdversarial Examplesを考え、それに基づいてさらに学習を進めることで、実際にSQuADの正答率は上がっています。しかし、文の繋がりや文法的な誤りについて過学習されてしまう可能性があり、十分に注意を払う必要があります。
また、現在の文章読解タスクの多くは人間が作った特徴的な問題に特化しており、パターンマッチの問題に留まってしまっていることが多いのが現状です。そのような現在のAIの言語理解の仕組みと、人間の脳の働きを見分けることが、真に言語を理解するシステムの完成には必要不可欠であり、文章読解タスクの解析とデザインは今後も重要な研究テーマであると感じます。
Adversarial Exampleについて詳しく学びたい方は「ディープラーニング最新論文講座 速習編東京第1期」、自然言語処理について詳しく学びたい方は「現場で使える自然言語処理 実践講座」をぜひご検討ください。
5. 参考文献
[1] P. Rajpurkar, J. Zhang, K. Lopyrev, and P. Liang. 2016. Squad: 100,000+ questions for machine comprehension of text. In IEmpirical Methods in Natural Language Processing (EMNLP).
[2] P. Rajpurkar. SQuAD2.0.
[3] R. Jia and P. Liang. 2017. Adversarial Examples for Evaluating Reading Comprehension Systems. In IEmpirical Methods in Natural Language Processing (EMNLP).
[4] L. Rimell, S. Clark, and M. Steedman. 2009. Unbounded dependency recovery for parser evaluation. In IEmpirical Methods in Natural Language Processing (EMNLP).
[5] D. Paperno, G. Kruszewski, A. Lazaridou, Q. N. Pham, R. Bernardi, S. Pezzelle, M. Baroni, G. Boleda, and R. Fernandez. 2016. The LAMBADA dataset: Word prediction requiring a broad discourse context. In IAssociation for Computational Linguistics (ACL).
[6] I. Goodfellow, J. Shlens, and C. Szegedy. 2015. Explaining and Harnessing Adversarial Examples. In International Conference on Learning Representations (ICLR).
25卒向け!AIエンジニアになるための長期インターンプログラム参加者募集中!
25卒学生向けに、AIの基礎を学びながら就活も一括サポートする無料カリキュラムを提供しています。
修了するとE資格の受験資格も獲得できるプログラムとなっています!

特長①AIエンジニアやデータサイエンティストの基礎が身に付く
AIジェネラリスト基礎講座や機械学習のためのPython入門講座など、市場価値向上のための基礎を習得。
特長②AI・データ分析領域の優良求人を紹介
非公開求人や選考直結型インターンをご紹介し、早期内定の獲得をサポート。
特長③長期インターンプログラム専用の学生コミュニティ参加可
学生同士で就活情報をシェアしたり、学習を進めるうえでアドバイスをしあったりできるコミュニティに参加可能。
☆☆☆
スキルアップAIのメールマガジンでは会社のお知らせや講座に関するお得な情報を配信しています。
配信を希望される方はこちら
また、SNSでも様々なコンテンツをお届けしています。興味を持った方は是非チェックしてください♪
Twitterはこちら
Facebookはこちら
LinkedInはこちら