こんにちは。スキルアップAI編集部です。
前回の記事ではGenerative Adversarial Networks(GAN)について解説しました。GANは、生成モデルの一種であり、 2人のプレーヤーが敵対的に学習することによって新しい画像などを生成するという手法でした。
このGANの学習を数学的な側面から見てみると、「教師データが従う確率分布をニューラルネットワーク を用いて陰に学習している」と表現することができます。一般的に、学習された確率分布から得られる擬似的なデータは、その確率分布の標本(サンプル)と呼ばれるものに対応します。
このように、確率分布から標本を生成することをサンプリングと呼び、統計学や機械学習における非常に重要なテクニックとして重宝されています。実は、GANの内部にもこれと同じ仕組みが入っています。
本記事では、サンプリングの概念と基本的なサンプリングの方法について解説していきます。
目次
1.乱数・擬似乱数・一様乱数
2.種々の分布からのサンプリング
3.生成モデルとサンプリング
4.参考文献
1. 乱数・擬似乱数・一様乱数
乱数とは、その名の通り「ランダム」で「予測できない」数のことです。コンピュータは確定的な計算をすることでしか数を生成することができないため、完全な乱数を作ることができません。
そこで、コンピュータは代数学のトリックを使って、「乱数っぽく振る舞う数」(これを擬似乱数という)を生成することができます。
以下では、この擬似乱数のことを乱数と呼ぶことにします。
最も基本的な確率分布の1つに一様分布があり、一様分布から得られる標本を一様乱数と呼びます。「一様」とは、全ての値が等確率で現れる(同様に確からしい)という意味です。整数の一様乱数の生成には「線形合同法」「M系列法」「メルセンヌ・ツイスタ」などの有名な手法がありますが、これらの理解には高度な代数学の知識が必要です。
さらに、実装も容易ではないので、ライブラリとして用意されたものを活用するのが無難でしょう。ここで知っておくと良いことは「メルセンヌ・ツイスタが現状比較的安全な擬似乱数を生成することができる」ということです。
実際、PythonのrandomライブラリやNumPyのnumpy。randomではメルセンヌ・ツイスタが採用されています。擬似乱数については [1] や [2] が詳しいです。
また、標準一様分布(図1)とは「以上 未満の実数」が等確率で出現するような確率分布であり、あらゆる乱数の原点とも言える標準一様乱数を生成します。
標準一様乱数の生成は、「以上 未満の整数」の値をとるような整数の一様乱数を生成し、その値を で割ることで得ることができます。この標準一様乱数が、いろいろな乱数を生成するための出発点となります。

図 1. 標準一様分布の確率密度関数
2. 種々の分布からのサンプリング
サンプリングとは、統計調査において「母集団や確率分布から標本を抽出する」操作のことを言います。前節の一様乱数の(擬似的な)生成は、一様分布からのサンプリングに対応します。本節では、その他の分布からの乱数の生成について、その手法の一部である逆関数法をご紹介します。
逆関数法では、累積分布関数(図2)を用います。累積分布関数は確率密度関数の不定積分で、その値域は0から1です。確率密度関数の値が大きいところでは、累積分布関数の傾きは大きくなります。
逆関数法とは、標準一様乱数を「累積分布関数の逆関数」に入力することで、その出力として所望の乱数を得る手法のことです。累積分布関数の傾きが大きいところほど、サンプルが得やすいようにできています(図3)。逆関数法の問題点は、累積分布関数の逆関数が陽に記述できないと利用できない点です。
サンプリングの方法としては、逆関数法の他にも「棄却サンプリング」「マルコフ連鎖モンテカルロ法」など、様々な手法があります [3]。ここで重要なのは、多くのサンプリング手法は、「より簡単な乱数を利用して複雑な乱数を生成している」という点です。

図 2. 確率密度関数と累積分布関数のイメージ
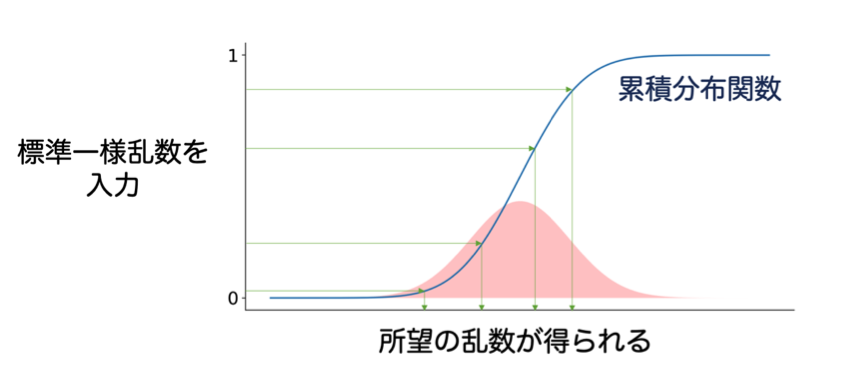 図 3. 逆関数法のイメージ
図 3. 逆関数法のイメージ
3. 生成モデルとサンプリング
GANでは具体的な分布を定めずに、データから直接構造を学習することで「簡単な乱数を擬似データに変換する」ことを可能にしていました。これは、ニューラルネットワークがデータの従う分布を陰に学習しているということです。
その結果として「簡単な乱数を擬似データに変換する」ような関数が Generatorとして得られるというわけです。モデルを陽に記述できなくても、擬似的なデータをサンプルとして得られるというのが嬉しいですね。
これは、今後解説するVariational AutoEncoder(VAE)やGenerative Moment Matching Network(GMMN)などの多くの生成モデルでも同様のことなのです。
4. 参考文献
[1] 小柴健史,『乱数生成と計算量理論』岩波書店,2018.
[2] M. Matsumoto and T. Nishimura、 Mersenne Twister: A 623-dimensionally equidistributed uniform pseudorandom number generator、 ACM TOMACS、 Vol. 8, No. 1、 pp. 3-30、 Jan. 1998.
[3] K. Murphy. Machine Learning: A Probabilistic Approach. MIT Press, 2012.
25卒向け!AIエンジニアになるための長期インターンプログラム参加者募集中!
25卒学生向けに、AIの基礎を学びながら就活も一括サポートする無料カリキュラムを提供しています。
修了するとE資格の受験資格も獲得できるプログラムとなっています!

特長①AIエンジニアやデータサイエンティストの基礎が身に付く
AIジェネラリスト基礎講座や機械学習のためのPython入門講座など、市場価値向上のための基礎を習得。
特長②AI・データ分析領域の優良求人を紹介
非公開求人や選考直結型インターンをご紹介し、早期内定の獲得をサポート。
特長③長期インターンプログラム専用の学生コミュニティ参加可
学生同士で就活情報をシェアしたり、学習を進めるうえでアドバイスをしあったりできるコミュニティに参加可能。
☆☆☆
スキルアップAIのメールマガジンでは会社のお知らせや講座に関するお得な情報を配信しています。
配信を希望される方はこちら
また、SNSでも様々なコンテンツをお届けしています。興味を持った方は是非チェックしてください♪
Twitterはこちら
Facebookはこちら
LinkedInはこちら