こんばんは、すきにーです。
huggingfaceのNLP講座の記事を見つけたので、序章の内容をまとめてみました。
https://huggingface.co/learn/nlp-course/chapter1/3
この記事では、Transformerモデルで何ができるのか、そして🤗 Transformersライブラリのpipeline()関数の使用方法について説明していきます。
HuggingFaceとは
Hugging Faceは、機械学習モデルの開発と共有、公開をするためのプラットフォームです。
Transformerを初めとする機械学習モデルの開発や普及において業界をリードしています。
🤗 Transformersライブラリ
Hugging Faceが提供する🤗 Transformersライブラリは、NLPのデファクトスタンダードとして受け入れられています。このライブラリを使えば、感情分析から文章生成まで多岐にわたるタスクが手軽に実行できます。
Github: https://github.com/huggingface/transformers
🤗 Transformersライブラリで出来るタスク
感情分析
説明:
感情分析とは、テキストに含まれる感情や態度をモデルが判定するタスクのことを指します。感情は「肯定的」、「否定的」、あるいは「中立」として分類されることが多いです。
コード:
from transformers import pipeline
classifier = pipeline('sentiment-analysis')
result = classifier('私はHuggingFaceのコースを楽しみにしていました。')
print(result)
コードの説明:
このコードは、Hugging FaceのTransformersライブラリを利用して、感情分析のためのパイプラインを設定しています。そして、指定されたテキストの感情を判定します。この例では、感情は「肯定的」と判定されます。
コードの出力:
[{'label': 'POSITIVE', 'score': 0.9598047137260437}]
この出力により、テキストは「肯定的」であるというラベルが付けられ、その確信度は約95.98%であることが示されています。
ゼロショット分類
説明:
ゼロショット分類とは、モデルが学習時に一度も見たことがないカテゴリへのテキスト分類を行う技術のことを指します。学習データには存在しなかったラベルのセットを用いて分類を行いたい場合に特に有効です。
コード:
from transformers import pipeline
classifier = pipeline("zero-shot-classification", model="MoritzLaurer/mDeBERTa-v3-base-xnli-multilingual-nli-2mil7")
classifier(
"これはTransformerの講義です",
candidate_labels=["教育", "政治", "ビジネス"],
)
コードの説明:
このコードでは、ゼロショット分類のためのパイプラインを設定しています。指定された候補ラベルを基に、テキストの内容を分類します。この例では、モデルはテキストが「教育」に最も関連していると判断するでしょう。
コードの出力:
{'sequence': 'これはTransformerの講義です',
'labels': ['教育', '政治', 'ビジネス'],
'scores': [0.9522446990013123, 0.03742500767111778, 0.010330267250537872]}

この出力により、テキストは「教育」に95.2%の確信度で関連しているとモデルが判断していることがわかります。
テキスト生成
説明:
テキスト生成とは、与えられた文やフレーズを基にして、それに続く文や段落を生成する技術のことを指します。
コード:
from transformers import pipeline
generator = pipeline("text-generation", model = "rinna/japanese-gpt2-medium")
generator("おはよう。昨日は寒かったね。")
コードの説明:
このコードは、テキスト生成のためのパイプラインを設定しています。与えられたフレーズ「おはよう。昨日は寒かったね。」を基に、モデルはテキストの続きを生成します。
コードの出力:
[{'generated_text':
'おはよう。昨日は寒かったね。私は今日も仕事だ。
早く帰りたかったな。さぁ!早く起きて仕事が終わっているかな?
まだ、私を待っている人がいるかな!? 今日は午後2時スタートだ'}]

出力が微妙ですね。モデルがgpt2のmediumなので仕方ないです。
固有表現認識 (NER)
説明:
固有表現認識とは、テキスト内の特定のエンティティや情報を識別し、人名、組織名、場所などのカテゴリに分類する技術のことを指します。
コード:
from transformers import pipeline
ner = pipeline('ner', grouped_entities=True)
ner(\"私の名前はSylvainで、ブルックリンのHugging Faceで働いています。\")
コードの説明:
このコードは、固有表現認識のためのパイプラインを設定しています。与えられたテキストから、「Sylvain」を人名として、「Hugging Face」を組織名として、「ブルックリン」を場所として識別します。
日本語のモデルが見つからなかったので、コードをそのまま使いました。
コードの出力:
[{'entity': 'I-PER', 'score': 0.999446451663971, 'word': 'Sylvain'},
{'entity': 'I-ORG', 'score': 0.9993780851364136, 'word': 'Hugging Face'},
{'entity': 'I-LOC', 'score': 0.9992868900299072, 'word': 'ブルックリン'}]
質問応答
説明:
質問応答とは、与えられた文脈の中から、指定された質問に対する答えを抽出する技術のことを指します。
コード:
from transformers import pipeline
question_answerer = pipeline("question-answering", model="KoichiYasuoka/deberta-base-japanese-aozora-ud-head")
question_answerer(
question="私の職場は?",
context="こんにちは。私は日本のIT企業で働いています。趣味は水泳と海で泳ぐことです",
)
コードの説明:
このコードは、質問応答のためのパイプラインを設定しています。文脈と質問が与えられると、モデルは文脈から答えを抽出します。
コードの出力:
{'score': 0.9833038449287415,
'start': 6,
'end': 22,
'answer': '私は日本のIT企業で働いています'}

微妙だけど、一応正解です。
要約
説明:
要約とは、長いテキストを短縮し、その主要な内容を維持した形で表現する技術のことを指します。
コード:
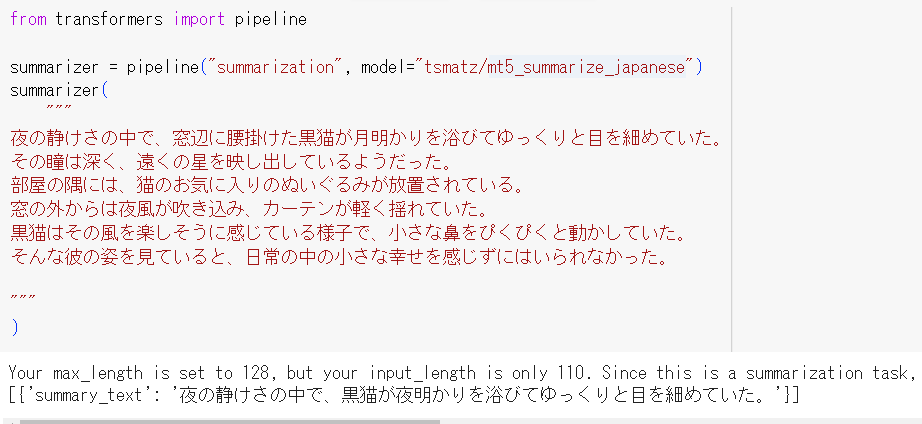
from transformers import pipeline
summarizer = pipeline("summarization", model="tsmatz/mt5_summarize_japanese")
summarizer(
"""
夜の静けさの中で、窓辺に腰掛けた黒猫が月明かりを浴びてゆっくりと目を細めていた。
その瞳は深く、遠くの星を映し出しているようだった。
部屋の隅には、猫のお気に入りのぬいぐるみが放置されている。
窓の外からは夜風が吹き込み、カーテンが軽く揺れていた。
黒猫はその風を楽しそうに感じている様子で、小さな鼻をぴくぴくと動かしていた。
そんな彼の姿を見ていると、日常の中の小さな幸せを感じずにはいられなかった。
"""
)
コードの出力:
[{'summary_text': '夜の静けさの中で、黒猫が夜明かりを浴びてゆっくりと目を細めていた。'}]
翻訳
説明:
翻訳とは、テキストを元の言語から別の言語に変換する技術のことを指します。この変換は、元のテキストの意味を維持しながら行われます。
コード:
from transformers import pipeline
translator = pipeline("translation", model="Helsinki-NLP/opus-mt-ja-en")
translator("""翻訳の場合、タスク名に言語ペアを指定すれば、デフォルトのモデルを使うことができます、
しかし、最も簡単な方法は、モデルハブで使いたいモデルを選ぶことです。"""
)
コードの出力:
[{'translation_text': 'In translation, you can use the default model if you specify a language set for the task name, but the easiest way is to choose a model you want to use in the model hub.'}]

コードの説明:
このコードは、日本語から英語に翻訳するための特定のモデルを使用して翻訳のパイプラインを設定しています。与えられた日本語のテキスト「翻訳の場合、タスク名に言語ペアを指定すれば、デフォルトのモデルを使うことができます、しかし、最も簡単な方法は、モデルハブで使いたいモデルを選ぶことです。」を基に、モデルはそのテキストを英語に翻訳します。
終わりに
Hugging FaceのNLPコースを読むと、自然言語処理の内容を基本的な部分からしっかり学べるのでおススメです。
余裕があったらモデルのファインチューニング方法なども書きたいと思います。