はじめに
この記事はレイトレ Advent Calendar 2021の記事として作成されました。
はじめまして。今年はじめて参加させていただいています。sketchbooks99と申します。OptiXの導入記事書くかな〜と気楽に考えていたら、想像以上に書くことが多くて担当日を大幅に遅刻してしまいました。申し訳ありません m(_ _)m
今回は、OptiX 7.4 (最新ver) を使って Peter Shirleyによる Ray Tracing In One Weekend のサムネイル画像に三角形を散りばめたような画像の出力を目標にしたいと思います。
ただし、本家で説明されているようなレイトレーシング自体の説明ではなく、OptiXにおけるプログラム作成やAcceleration structure (AS)、Shader binding table (SBT)等の説明に重点を置いて説明していこうと思います。

解説は最初は1記事でいいかなと思ったのですが、長くなってしまったのでPart1, Part2に分けました。
また、プログラムを交えながら説明していきますが、コード全体を記事に乗せるには大きすぎるので、サンプルコードをGithub上にあげておきました。クローンしてOptiX SDKのSDKリポジトリ内に配置、CMakeLists.txtにadd_repository(optixInOneWeekend)とするだけで動作すると思います。
NVIDIA OptiXとは
NVIDIA OptiXとは、NVIDIAが提供しているCUDAベースのGPUレイトレーシングエンジンです。CUDAベースですので、動作にはNVIDIA製のGPUが搭載されている端末が必要となります。
筆者の環境
- Windows 11
- Visual Studio 2019
- RTX 2060
事前準備
本記事は最新の OptiX 7.4 を想定して書いています。ドライバのバージョン等で7.4の環境が準備できない場合はOlder versionから環境にあったバージョンをインストールしてください。7.x系であれば、変数名やマクロ名等で多少の変化はありますが、基本的には動作できると思われます。把握している限りで7.4 ~にしかないものは、本記事で記していこうと思います。
必要なもの
- CMake
- 最新のNVIDIAドライバー (R495.89 ~)
- Visual studio 2019 (Windows)
- NVIDIA OptiX 7.x 系
環境構築
自分でOptiXを書き換えてアプリを作り始めるまでの準備は、以前研究室で書いた記事があるので、そちらをご確認ください。
ここでは、PART 2 のアプリを書き換えてみるで書いたような、任意のフォルダにOptiXから提供されているサンプルコードをコピーして、アプリケーションを改変できるところまで準備してください。私はアプリケーション名を optixInOneWeekendとしました。
もしくは、サンプルコードをクローンして使ってみてください
レイトレーシング準備編
OptiXではGPU上でのレイトレーシングを起動する前に、CPU側からGPU側へのデータのコピーや、ASの構築、SBTの構築等が必要になります。
まずは、今回作る週末レイトレ用のプログラムやAS、SBT等を格納しておく構造体を準備します。
struct OneWeekendState
{
OptixDeviceContext context = 0;
// シーン全体のInstance acceleration structure
InstanceAccelData ias = {};
// GPU上におけるシーンの球体データ全てを格納している配列のポインタ
void* d_sphere_data = nullptr;
// GPU上におけるシーンの三角形データ全てを格納している配列のポインタ
void* d_mesh_data = nullptr;
OptixModule module = nullptr;
OptixPipelineCompileOptions pipeline_compile_options = {};
OptixPipeline pipeline = nullptr;
// Ray generation プログラム
OptixProgramGroup raygen_prg = nullptr;
// Miss プログラム
OptixProgramGroup miss_prg = nullptr;
// 球体用のHitGroup プログラム
OptixProgramGroup sphere_hitgroup_prg = nullptr;
// メッシュ用のHitGroupプログラム
OptixProgramGroup mesh_hitgroup_prg = nullptr;
// マテリアル用のCallableプログラム
// OptiXでは基底クラスのポインタを介した、派生クラスの関数呼び出し (ポリモーフィズム)が
// 禁止されているため、Callable関数を使って疑似的なポリモーフィズムを実現する
// ここでは、Lambertian, Dielectric, Metal の3種類を実装している
CallableProgram lambertian_prg = {};
CallableProgram dielectric_prg = {};
CallableProgram metal_prg = {};
// テクスチャ用のCallableプログラム
// Constant ... 単色、Checker ... チェッカーボード
CallableProgram constant_prg = {};
CallableProgram checker_prg = {};
// CUDA stream
CUstream stream = 0;
// Pipeline launch parameters
// CUDA内で extern "C" __constant__ Params params
// と宣言することで、全モジュールからアクセス可能である。
Params params;
Params* d_params;
// Shader binding table
OptixShaderBindingTable sbt = {};
};
OptixDeviceContextの初期化
まず、optixDeviceContextCreate() によって単一のGPUを管理するためのコンテキスト(OptixDeviceContext)を作成します。
コンテキストはModuleやPipeline、ASなどOptiX関連のクラスを生成する際に必ず必要になるので、GPUを初期化した際に同時に行うと良いと思われます。
static void contextLogCallback(uint32_t level, const char* tag, const char* msg, void* /* callback_data */)
{
std::cerr << "[" << std::setw(2) << level << "][" << std::setw(12) << tag << "]: " << msg << "\n";
}
void createContext( OneWeekendState& state )
{
// CUDAの初期化
CUDA_CHECK( cudaFree( 0 ) );
OptixDeviceContext context;
CUcontext cu_ctx = 0;
OPTIX_CHECK( optixInit() );
OptixDeviceContextOptions options = {};
options.logCallbackFunction = &contextLogCallback;
// Callbackで取得するメッセージのレベル
// 0 ... disable、メッセージを受け取らない
// 1 ... fatal、修復不可能なエラー。コンテクストやOptiXが不能状態にある
// 2 ... error、修復可能エラー。
// 3 ... warning、意図せぬ挙動や低パフォーマンスを導くような場合に警告してくれる
// 4 ... print、全メッセージを受け取る
options.logCallbackLevel = 4;
OPTIX_CHECK( optixDeviceContextCreate( cu_ctx, &options, &context ) );
state.context = context;
}
ここで、OptixDeviceContextOptionsではデバイス側からのメッセージを受け取るレベルを指定できます。レベルに応じて、メッセージの量が異なり、最大の4に設定すると以下のようなパイプラインの分析結果等を出力してくれます。メッセージの取得はcallback関数のポインタをOptixDeviceContextOptions::logCallbackFunctionに登録することで可能です。
[ 4][COMPILE FEEDBACK]: Info: Pipeline has 1 module(s), 10 entry function(s), 1 trace call(s), 0 continuation callable call(s), 4 direct callable call(s), 57 basic block(s) in entry functions, 1939 instruction(s) in entry functions, 0 non-entry function(s), 0 basic block(s) in non-entry functions, 0 instruction(s) in non-entry functions
Program Groupの準備
Program Groupの準備と書きましたが、ここでは OptixModule, OptixProgramGroup, OptixPipelineの3つを初期化していきます。関係性としては、まずCUDAコードをコンパイルしてOptixModuleが作られ、そこからOptixProgramGroupが生成されます。OptixProgramGroupはレイトレーシング起動時に最初に呼ばれる Ray generation プログラム、物体との交差判定やシェーディングに用いられる HitGroup プログラム、交差判定が認められなかった際のMissプログラム等に分類されます。
OptixPipelineはこれらのGPU上でのレイトレーシングを実現するための複数のProgram Groupから生成されます。OptixModuleとOptixPipelineはASやSBTと独立して生成することができますが、OptixProgramGroupはSBTのシェーダーレコードのヘッダーを埋めるために使用されるため、SBTを構築する前に生成されている必要があります。
Moduleの作成
CUDAコードをコンパイルして生成されたのPTX (Parallel Thread Execution)からOptixModuleを生成します。生成時にはModuleのコンパイル設定と、パイプラインのコンパイル設定を利用します。注意すべきはOptixPipelineCompileOptionsに設定する値です。Motion blurを使いたい場合にはuseMotionBlurのフラグを立てる必要があったり、交差判定時にIntersectionプログラムからClosesthitプログラムに渡したいAttributeの数を考慮しながら、Attribute数を設定する必要があります。
void createModule(OneWeekendState& state)
{
OptixModuleCompileOptions module_compile_options = {};
module_compile_options.maxRegisterCount = OPTIX_COMPILE_DEFAULT_MAX_REGISTER_COUNT;
module_compile_options.optLevel = OPTIX_COMPILE_OPTIMIZATION_DEFAULT;
// ~7.3 系では OPTIX_COMPILE_DEBUG_LEVEL_LINEINFO
module_compile_options.debugLevel = OPTIX_COMPILE_DEBUG_LEVEL_MINIMAL;
state.pipeline_compile_options.usesMotionBlur = false;
state.pipeline_compile_options.traversableGraphFlags = OPTIX_TRAVERSABLE_GRAPH_FLAG_ALLOW_ANY;
state.pipeline_compile_options.numPayloadValues = 2;
// Attributeの個数設定
// Sphereの交差判定で法線とテクスチャ座標を intersection -> closesthitに渡すので
// (x, y, z) ... 3次元、(s, t) ... 2次元 で計5つのAttributeが必要
// optixinOneWeekend.cu:347行目参照
state.pipeline_compile_options.numAttributeValues = 5;
#ifdef DEBUG
state.pipeline_compile_options.exceptionFlags = OPTIX_EXCEPTION_FLAG_DEBUG | OPTIX_EXCEPTION_FLAG_TRACE_DEPTH | OPTIX_EXCEPTION_FLAG_STACK_OVERFLOW;
#else
state.pipeline_compile_options.exceptionFlags = OPTIX_EXCEPTION_FLAG_NONE;
#endif
// Pipeline launch parameterの変数名
state.pipeline_compile_options.pipelineLaunchParamsVariableName = "params";
size_t inputSize = 0;
const char* input = sutil::getInputData(OPTIX_SAMPLE_NAME, OPTIX_SAMPLE_DIR, "optixInOneWeekend.cu", inputSize);
// PTXからModuleを作成
char log[2048];
size_t sizeof_log = sizeof(log);
OPTIX_CHECK_LOG(optixModuleCreateFromPTX(
state.context, // OptixDeviceContext
&module_compile_options,
&state.pipeline_compile_options,
input,
inputSize,
log,
&sizeof_log,
&state.module // OptixModule
));
Program Groupの生成
先ほど生成したOptixModuleを使って、OptixProgramGroupを作ります。例として球体用のHitGroupProgramを作ってみます。
OptixProgramGroupDesc の種類を OPTIX_PROGRAM_GROUP_KIND_HITGROUPに設定し、交差判定用のIntersectionプログラムと主にシェーディングに用いられるClosesthitプログラムを登録します。この時、moduleISとmoduleCHで分かれているように、同一のModuleにプログラムが登録されている必要はなく、それぞれ別のModuleからプログラムを作ることが可能です。
また、Ray generationプログラムの場合には、.kindをOPTIX_PROGRAM_GROUP_KIND_RAYGEN、module部分を .raygen.moduleとします。
void createProgramGroups(OneWeekendState& state) {
// ...
// 球体用のHitGroupProgram
OptixProgramGroupDesc hitgroup_prg_desc = {};
hitgroup_prg_desc.kind = OPTIX_PROGRAM_GROUP_KIND_HITGROUP;
hitgroup_prg_desc.hitgroup.moduleIS = state.module;
hitgroup_prg_desc.hitgroup.entryFunctionNameIS = "__intersection__sphere";
hitgroup_prg_desc.hitgroup.moduleCH = state.module;
hitgroup_prg_desc.hitgroup.entryFunctionNameCH = "__closesthit__sphere";
sizeof_log = sizeof(log);
OPTIX_CHECK_LOG(optixProgramGroupCreate(
state.context, // OptixDeviceContext
&hitgroup_prg_desc,
1,
&prg_options,
log,
&sizeof_log,
&state.sphere_hitgroup_prg // OptixProgramGroup
));
// ...
}
Callablesプログラムの場合は少々気を付ける必要があります。CallablesプログラムはDirect callableとContinuation callableの2種類があり、関数呼び出しは以下のようにShader binding table内のIDによって行われるため、何番目のSBTレコードにどのCallablesプログラムを紐づけたか、ユーザーが把握している必要があります。
// CUDAコード
extern "C" __device__ void __direct_callable__func(float, int) {
// ...
}
// Shader binding table内のID (SBT_ID) と引数型を指定して関数呼び出し
// __direct_callable__func(float, int)がSBT_ID番目のSBTレコードに
// 紐づけられている場合は関数が呼び出される
optixDirectCall<void, float, int>(SBT_ID, 12.5f, 10);
個人的にはプログラム生成の際に、Callables関数へのIDを登録しておき、Shader binding tableの構築時にはその番号のSBTレコードを埋めるように実装するのが安全だと思います。
今回の例だと、マテリアルにおける散乱方向の計算を週末レイトレシリーズで行われているような、基底クラスのポインタをインターフェースとして派生クラスの関数を呼ぶ方式ではなく、ジオメトリに紐づいているCallableプログラムのIDによって呼び出し関数を切り替える方式を採用します。詳しい話はGPU編で説明します。
今回はマテリアルにLambertian, Dielectric, Metalの3つ分、テクスチャ用にConstant, Checkerの2種類を用意します。
// Direct/Continuation callable プログラムをデバイス(GPU)側で呼ぶには、
// CallablesプログラムのSBT_IDが必要なので、生成順で番号を割り振って起き、
// その順番でCallables用のSBTを構築するようにする
struct CallableProgram
{
OptixProgramGroup program = nullptr;
uint32_t id = 0;
};
// -----------------------------------------------------------------------
// Direct callable プログラムを生成する。生成するごとにcallable_idを1増やす
// -----------------------------------------------------------------------
void createDirectCallables(const OneWeekendState& state, CallableProgram& callable, const char* dc_function_name, uint32_t& callables_id)
{
OptixProgramGroupOptions prg_options = {};
OptixProgramGroupDesc callables_prg_desc = {};
char log[2048];
size_t sizeof_log = sizeof(log);
callables_prg_desc.kind = OPTIX_PROGRAM_GROUP_KIND_CALLABLES;
callables_prg_desc.callables.moduleDC = state.module;
callables_prg_desc.callables.entryFunctionNameDC = dc_function_name;
sizeof_log = sizeof(log);
OPTIX_CHECK_LOG(optixProgramGroupCreate(
state.context,
&callables_prg_desc,
1,
&prg_options,
log,
&sizeof_log,
&callable.program
));
callable.id = callables_id;
callables_id++;
}
void createProgramGroups(OneWeekendState& state)
{
// ...
uint32_t callables_id = 0;
// マテリアル用のCallableプログラム
{
// Lambertian
createDirectCallables(state, state.lambertian_prg, "__direct_callable__lambertian", callables_id);
// Dielectric
createDirectCallables(state, state.dielectric_prg, "__direct_callable__dielectric", callables_id);
// Metal
createDirectCallables(state, state.metal_prg, "__direct_callable__metal", callables_id);
}
// テクスチャ用のCallableプログラム
{
// Constant texture
createDirectCallables(state, state.constant_prg, "__direct_callable__constant", callables_id);
// Checker texture
createDirectCallables(state, state.checker_prg, "__direct_callable__checker", callables_id);
}
// ...
}
// Shader binding tableの構築時 --------------------------------------
void createSBT(OneWeekendState& state, const std::vector<std::pair<ShapeType, HitGroupData>>& hitgroup_datas)
{
// ...
constexpr int32_t NUM_CALLABLES = 5;
EmptyRecord* callables_records = new EmptyRecord[NUM_CALLABLES];
CUdeviceptr d_callables_records;
const size_t callables_record_size = sizeof(EmptyRecord) * NUM_CALLABLES;
CUDA_CHECK(cudaMalloc(reinterpret_cast<void**>(&d_callables_records), callables_record_size));
OPTIX_CHECK(optixSbtRecordPackHeader(state.lambertian_prg.program, &callables_records[state.lambertian_prg.id]));
OPTIX_CHECK(optixSbtRecordPackHeader(state.dielectric_prg.program, &callables_records[state.dielectric_prg.id]));
OPTIX_CHECK(optixSbtRecordPackHeader(state.metal_prg.program, &callables_records[state.metal_prg.id]));
OPTIX_CHECK(optixSbtRecordPackHeader(state.constant_prg.program, &callables_records[state.constant_prg.id]));
OPTIX_CHECK(optixSbtRecordPackHeader(state.checker_prg.program, &callables_records[state.checker_prg.id]));
// ...
}
Pipelineの作成
プログラムをすべて作り終えたら、シーンを構成するプログラムからOptixPipelineを生成します。
void createPipeline(OneWeekendState& state)
{
OptixProgramGroup program_groups[] =
{
state.raygen_prg,
state.miss_prg,
state.mesh_hitgroup_prg,
state.sphere_hitgroup_prg,
state.lambertian_prg.program,
state.dielectric_prg.program,
state.metal_prg.program,
state.constant_prg.program,
state.checker_prg.program
};
OptixPipelineLinkOptions pipeline_link_options = {};
// optixTrace()の呼び出し深度の設定
pipeline_link_options.maxTraceDepth = 2;
pipeline_link_options.debugLevel = OPTIX_COMPILE_DEBUG_LEVEL_FULL;
char log[2048];
size_t sizeof_log = sizeof(log);
OPTIX_CHECK_LOG(optixPipelineCreate(
state.context,
&state.pipeline_compile_options,
&pipeline_link_options,
program_groups,
sizeof(program_groups) / sizeof(program_groups[0]),
log,
&sizeof_log,
&state.pipeline
));
// ...
}
Acceleration structureの構築
さて、レイトレーシングプログラムが作成出来たら、ここからはシーンのジオメトリデータやマテリアルデータを準備していきます。まずは、Acceleration structure (AS) の構築です。ASはInstance acceleration structure (IAS)とGeometry acceleration structure (GAS) の2種類に分けられます(DirectX/Vulkanの場合はTLAS/BLASと呼ばれます)。ASはシーンのトラバースを高速化するための階層構造で、GPUアーキテクチャによってその構造に変化はあるものの、基本的にはBVHベースで構築されます。
IASとGASの全体像は例えば以下の画像のようになります。IASは拡大縮小・回転・平行移動の変換行列やSBTのオフセットを保持するOptixInstanceや、開始時と終了時の変換行列を保持するOptixMatrixMotionTransformなどから構築されます。各InstanceやTransformにはジオメトリから構築されたGASが含まれており、1つのGASを複数のInstanceで共有することで、同一ジオメトリに対して異なるマテリアルや変換行列を適用することができます。このインスタンスは、OpenGL等のラスタライズ文脈で用いられるインスタンシングとは概念が異なるので注意が必要です。
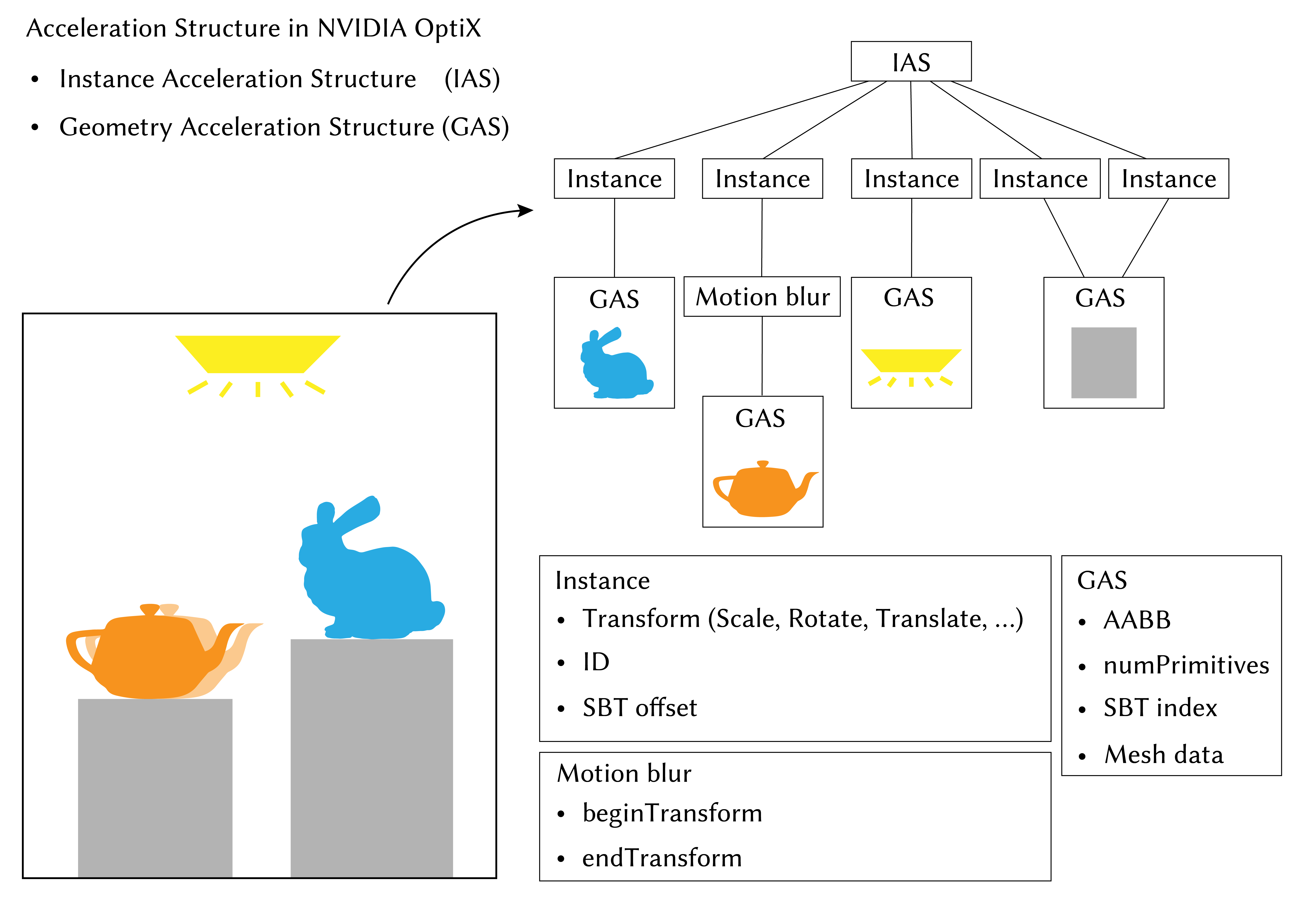
IAS、GASともにOptixBuildInputを用いて構築され、このbuild inputにはIASの場合にはOptixInstanceの配列が用いられ、GASの場合にはメッシュの場合には三角形メッシュを構成する頂点情報と頂点の結び方を定義するインデックスバッファ、ユーザー定義のプリミティブ(Custom primitives)の場合には、ジオメトリをちょうど覆うようなAxis-Aligned Bounding Box (AABB) の配列が用いられます。
この時、GASの構築時にはbuild inputのタイプが同じである必要があり、一つのGAS内に三角形メッシュとCustom primitives (例えば球体) のbuild inputを混在させることはできません。
今回の例だと、メッシュと球体によってシーンを構築するのでASの構造は以下のようになります。
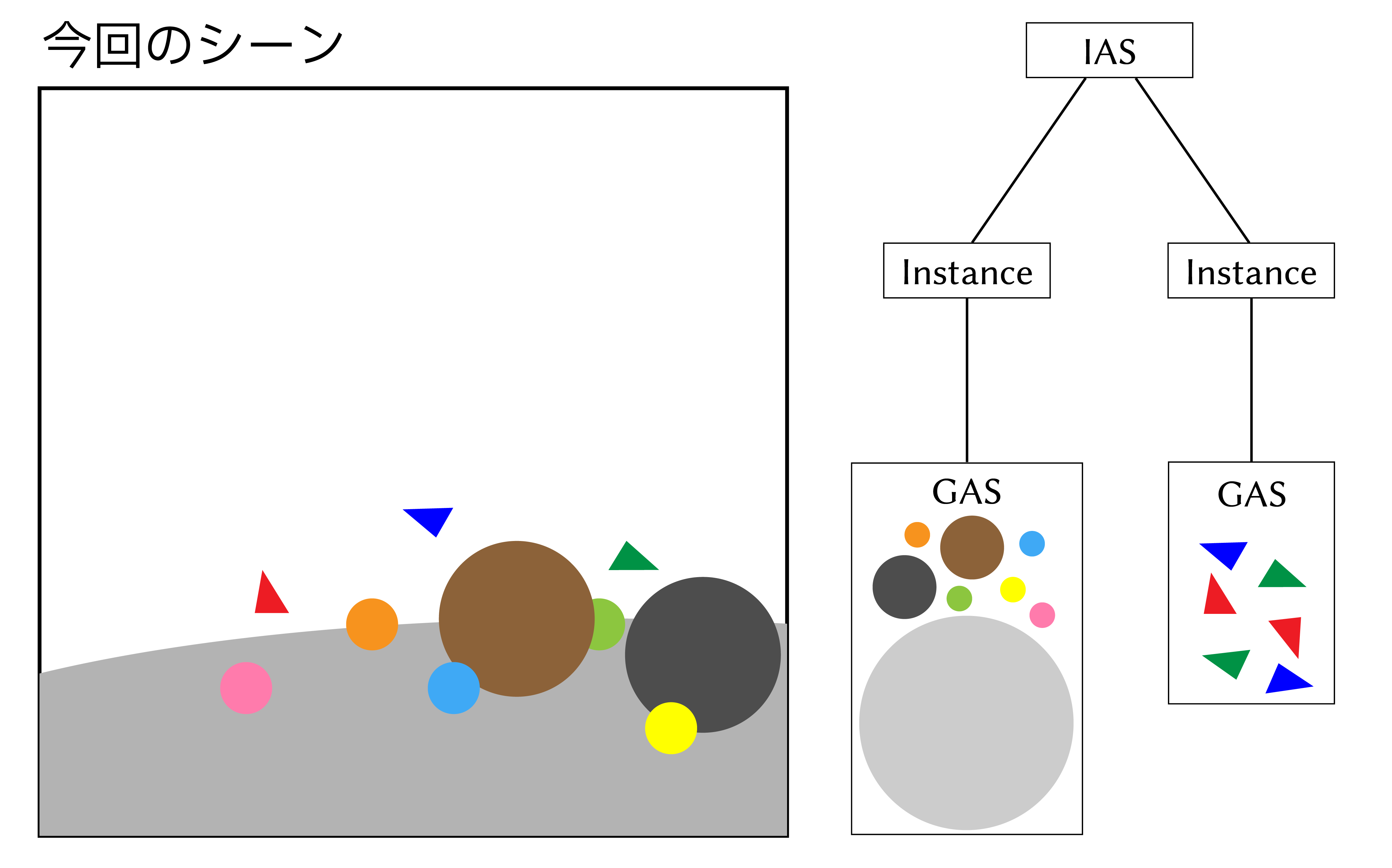
Geometry acceleration structure (GAS)
まずは、GASの構築です。球体用のデータとGASのデータを管理するための構造体を用意しておきましょう。SphereDataに関してはCUDA側でもincludeして交差判定で使用するので、ヘッダーファイル内に記述しておきます。
GAS/IASに関しては、OptixTraversableHandleが重要で、GPU上でoptixTrace関数によってレイトレースを開始する際に、このASのhandleを指定します。シーンが単一のGASで構築されている場合にはoptixTrace(gas_handle, ...)となりますが、基本的にはIASのhandleを指定するようになるかと思われます。
// .h ----------------------------------
struct SphereData
{
// 球の中心
float3 center;
// 球の半径
float radius;
};
// .cpp --------------------------------
// Geometry acceleration structure (GAS) 用
// GASのtraversable handleをOptixInstanceに紐づける際に、
// GASが保持するSBT recordの数がわかると、
// Instanceのsbt offsetを一括で構築しやすい
struct GeometryAccelData
{
OptixTraversableHandle handle;
CUdeviceptr d_output_buffer;
uint32_t num_sbt_records;
};
build inputからGASを構築する際は、GASのために確保すべきGPU上の領域を計算し、その領域だけメモリを確保します。その後、確保した領域上にASを作成します。この時、確保した領域には不必要な領域が存在する可能性があるので、メモリ領域を小さくしたい場合はCompactionを行います。
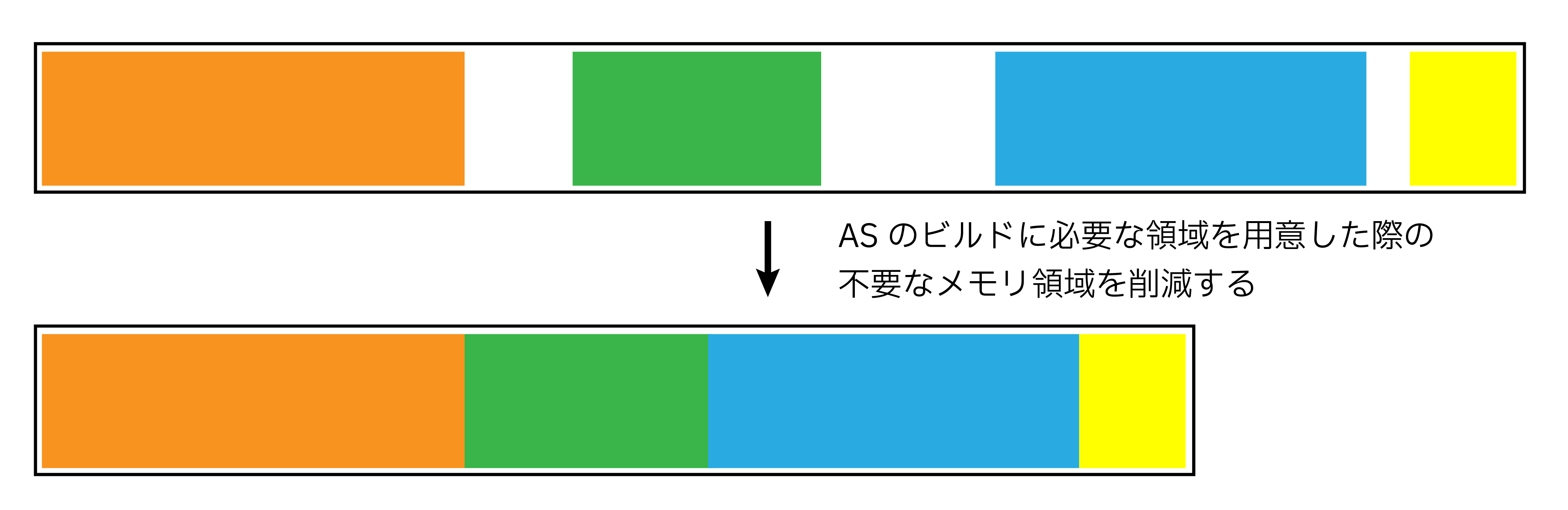
OptiX SDK のProgramming guideに記載されいている、Compaction時に注意する項目は以下の3点です。
-
OptixAccelBuildOptionsにOPTIX_BUILD_FLAG_ALLOW_COMPACTIONが設定されていること -
OptixAccelEmitDesc::typeがOPTIX_PROPERTY_TYPE_COMPACTED_SIZEに設定されている必要があります。これは、Compactionの際に新たな領域を確保する必要が出た場合に、デバイス側で確保されたresultを一度ホスト側にコピーしてくる必要があります。 - Compaction後の領域サイズがCompaction前の領域サイズを下回っている場合に限り、Compactionを行うように条件分岐する必要があります。
// -----------------------------------------------------------------------
// Geometry acceleration structureの構築
// -----------------------------------------------------------------------
void buildGAS( OneWeekendState& state, GeometryAccelData& gas, OptixBuildInput& build_input)
{
OptixAccelBuildOptions accel_options = {};
accel_options.buildFlags = OPTIX_BUILD_FLAG_ALLOW_COMPACTION; // ビルド後のCompactionを許可
accel_options.operation = OPTIX_BUILD_OPERATION_BUILD; // ASの更新の際は OPERATION_UPDATE
// ASのビルドに必要なメモリ領域を計算
OptixAccelBufferSizes gas_buffer_sizes;
OPTIX_CHECK( optixAccelComputeMemoryUsage(
state.context,
&accel_options,
&build_input,
1,
&gas_buffer_sizes
));
// ASを構築するための一時バッファを確保
CUdeviceptr d_temp_buffer;
CUDA_CHECK( cudaMalloc( reinterpret_cast<void**>( &d_temp_buffer ), gas_buffer_sizes.tempSizeInBytes ) );
CUdeviceptr d_buffer_temp_output_gas_and_compacted_size;
size_t compacted_size_offset = roundUp<size_t>( gas_buffer_sizes.outputSizeInBytes, 8ull );
CUDA_CHECK( cudaMalloc(
reinterpret_cast<void**>(&d_buffer_temp_output_gas_and_compacted_size),
compacted_size_offset + 8
));
// 新たな出力バッファを確保する必要がある場合には、OptixAccelEmitDesc::result を
// デバイス(GPU)側からホスト(CPU)側へコピーする必要がある。
OptixAccelEmitDesc emit_property = {};
emit_property.type = OPTIX_PROPERTY_TYPE_COMPACTED_SIZE;
emit_property.result = ( CUdeviceptr )( (char*)d_buffer_temp_output_gas_and_compacted_size + compacted_size_offset );
// ASのビルド
OPTIX_CHECK(optixAccelBuild(
state.context,
state.stream,
&accel_options,
&build_input,
1,
d_temp_buffer,
gas_buffer_sizes.tempSizeInBytes,
d_buffer_temp_output_gas_and_compacted_size,
gas_buffer_sizes.outputSizeInBytes,
&gas.handle,
&emit_property,
1
));
// 一時バッファは必要ないので解放
CUDA_CHECK(cudaFree(reinterpret_cast<void*>(d_temp_buffer)));
size_t compacted_gas_size;
CUDA_CHECK(cudaMemcpy(&compacted_gas_size, (void*)emit_property.result, sizeof(size_t), cudaMemcpyDeviceToHost));
// Compaction後の領域が、Compaction前の領域サイズよりも小さい場合のみ Compactionを行う
if (compacted_gas_size < gas_buffer_sizes.outputSizeInBytes)
{
CUDA_CHECK(cudaMalloc(reinterpret_cast<void**>(&gas.d_output_buffer), compacted_gas_size));
OPTIX_CHECK(optixAccelCompact(state.context, 0, gas.handle, gas.d_output_buffer, compacted_gas_size, &gas.handle));
CUDA_CHECK(cudaFree((void*)d_buffer_temp_output_gas_and_compacted_size));
}
else
{
gas.d_output_buffer = d_buffer_temp_output_gas_and_compacted_size;
}
}
では、球体データの配列を用いてGASを構築していきます。build inputには球体それぞれのAABBを格納した配列と、SBTレコードへのインデックス配列、球体の数が必要になります。それぞれまずは配列をGPU上にコピーしてから、配列の先頭ポインタをbuild inputに設定します。
// -----------------------------------------------------------------------
OptixAabb sphereBound(const SphereData& sphere)
{
// 球体のAxis-aligned bounding box (AABB)を返す
const float3 center = sphere.center;
const float radius = sphere.radius;
return OptixAabb {
/* minX = */ center.x - radius, /* minY = */ center.y - radius, /* minZ = */ center.z - radius,
/* maxX = */ center.x + radius, /* maxY = */ center.y + radius, /* maxZ = */ center.z + radius
};
}
// -----------------------------------------------------------------------
void buildSphereGAS(
OneWeekendState& state,
GeometryAccelData& gas,
const std::vector<SphereData>& spheres,
const std::vector<uint32_t>& sbt_indices
)
{
// Sphereの配列からAABBの配列を作る
std::vector<OptixAabb> aabb;
std::transform(spheres.begin(), spheres.end(), std::back_inserter(aabb),
[](const SphereData& sphere) { return sphereBound(sphere); });
// AABBの配列をGPU上にコピー
CUdeviceptr d_aabb_buffer;
const size_t aabb_size = sizeof(OptixAabb) * aabb.size();
CUDA_CHECK(cudaMalloc(reinterpret_cast<void**>(&d_aabb_buffer), aabb_size));
CUDA_CHECK(cudaMemcpy(
reinterpret_cast<void*>(d_aabb_buffer),
aabb.data(), aabb_size,
cudaMemcpyHostToDevice
));
// Instance sbt offsetを基準としたsbt indexの配列をGPUにコピー
CUdeviceptr d_sbt_indices;
CUDA_CHECK(cudaMalloc(reinterpret_cast<void**>(&d_sbt_indices), sizeof(uint32_t) * sbt_indices.size()));
CUDA_CHECK(cudaMemcpy(
reinterpret_cast<void*>(d_sbt_indices),
sbt_indices.data(), sizeof(uint32_t) * sbt_indices.size(),
cudaMemcpyHostToDevice
));
// 全球体データの配列をGPU上にコピー
// 個々の球体データへのアクセスはoptixGetPrimitiveIndex()を介して行う
CUDA_CHECK(cudaMalloc(&state.d_sphere_data, sizeof(SphereData) * spheres.size()));
CUDA_CHECK(cudaMemcpy(state.d_sphere_data, spheres.data(), sizeof(SphereData) * spheres.size(), cudaMemcpyHostToDevice));
// 重複のないsbt_indexの個数を数える
uint32_t num_sbt_records = getNumSbtRecords(sbt_indices);
gas.num_sbt_records = num_sbt_records;
// 重複のないsbt_indexの分だけflagsを設定する
// Anyhit プログラムを使用したい場合はFLAG_NONE or FLAG_REQUIRE_SINGLE_ANYHIT_CALL に設定する
uint32_t* input_flags = new uint32_t[num_sbt_records];
for (uint32_t i = 0; i < num_sbt_records; i++)
input_flags[i] = OPTIX_GEOMETRY_FLAG_DISABLE_ANYHIT;
// Custom primitives用のAABB配列やSBTレコードのインデックス配列を
// build input に設定する
// num_sbt_recordsはあくまでSBTレコードの数でプリミティブ数でないことに注意
OptixBuildInput sphere_input = {};
sphere_input.type = OPTIX_BUILD_INPUT_TYPE_CUSTOM_PRIMITIVES;
sphere_input.customPrimitiveArray.aabbBuffers = &d_aabb_buffer;
sphere_input.customPrimitiveArray.numPrimitives = static_cast<uint32_t>(spheres.size());
sphere_input.customPrimitiveArray.flags = input_flags;
sphere_input.customPrimitiveArray.numSbtRecords = num_sbt_records;
sphere_input.customPrimitiveArray.sbtIndexOffsetBuffer = d_sbt_indices;
sphere_input.customPrimitiveArray.sbtIndexOffsetSizeInBytes = sizeof(uint32_t);
sphere_input.customPrimitiveArray.sbtIndexOffsetStrideInBytes = sizeof(uint32_t);
buildGAS(state, gas, sphere_input);
}
メッシュの場合も同様にデータをGPU上にコピーしてから、build inputを構築します。注意すべきは、三角形の数(ここではインデックスバッファの配列長)とSBTレコードの数は一致しないことです。SBTレコードの数はあくまでShader binding tableに登録されているレコード数で、例えば100個の三角形に対して、3つのマテリアルしか適用しない場合は、SBTレコードの数は3つとなります。
// 重複のないsbt_indexの個数を数える
uint32_t num_sbt_records = getNumSbtRecords(sbt_indices);
gas.num_sbt_records = num_sbt_records;
// 重複のないsbt_indexの分だけflagsを設定する
// Anyhit プログラムを使用したい場合はFLAG_NONE or FLAG_REQUIRE_SINGLE_ANYHIT_CALL に設定する
uint32_t* input_flags = new uint32_t[num_sbt_records];
for (uint32_t i = 0; i < num_sbt_records; i++)
input_flags[i] = OPTIX_GEOMETRY_FLAG_DISABLE_ANYHIT;
// メッシュの頂点情報やインデックスバッファ、SBTレコードのインデックス配列をbuild inputに設定
// num_sbt_recordsはあくまでSBTレコードの数で三角形の数でないことに注意
OptixBuildInput mesh_input = {};
mesh_input.type = OPTIX_BUILD_INPUT_TYPE_TRIANGLES;
mesh_input.triangleArray.vertexFormat = OPTIX_VERTEX_FORMAT_FLOAT3;
mesh_input.triangleArray.vertexStrideInBytes = sizeof(float3);
mesh_input.triangleArray.numVertices = static_cast<uint32_t>(vertices.size());
mesh_input.triangleArray.vertexBuffers = &d_vertices; // 頂点情報
mesh_input.triangleArray.flags = input_flags;
mesh_input.triangleArray.indexFormat = OPTIX_INDICES_FORMAT_UNSIGNED_INT3;
mesh_input.triangleArray.indexStrideInBytes = sizeof(uint3);
mesh_input.triangleArray.indexBuffer = d_indices; // インデックスバッファ
mesh_input.triangleArray.numIndexTriplets = static_cast<uint32_t>(indices.size());
mesh_input.triangleArray.numSbtRecords = num_sbt_records; // SBTレコードの個数
mesh_input.triangleArray.sbtIndexOffsetBuffer = d_sbt_indices;
mesh_input.triangleArray.sbtIndexOffsetSizeInBytes = sizeof(uint32_t);
mesh_input.triangleArray.sbtIndexOffsetStrideInBytes = sizeof(uint32_t);
Instance acceleration structure (IAS)
球体とメッシュそれぞれのGASが作れたら、IASを構築します。IASの構築には、GASで得たOptixTraversableHandleとSBT offsetが設定されたOptixInstanceの配列を用います。
// IAS用のInstanceを球体用・メッシュ用それぞれ作成
std::vector<OptixInstance> instances;
uint32_t flags = OPTIX_INSTANCE_FLAG_NONE;
uint32_t sbt_offset = 0;
uint32_t instance_id = 0;
instances.emplace_back(OptixInstance{
{1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0}, instance_id, sbt_offset, 255,
flags, sphere_gas.handle, {0, 0}
});
sbt_offset += sphere_gas.num_sbt_records;
instance_id++;
// メッシュの方はY軸中心にPI/6だけ回転させる
const float c = cosf(M_PIf / 6.0f);
const float s = sinf(M_PIf / 6.0f);
instances.push_back(OptixInstance{
{c, 0, s, 0, 0, 1, 0, 0, -s, 0, c, 0}, instance_id, sbt_offset, 255,
flags, mesh_gas.handle, {0, 0}
});
// IASの作成
buildIAS(state, state.ias, instances);
注意すべきはSBT offsetです。GASを作る際に使用したSBTレコードへのインデックス配列は、複数のInstanceを使用する場合かつGASが複数のSBT indexを持っている場合には、Instanceに指定されているSBT offsetを基準としたインデックス配列となります。詳しくはShader binding tableの準備の際に説明します。
IASの構築では、build inputの種類と格納するデータが異なるだけで、ASビルド操作はGASの場合と同じです。
// OptixInstance配列をGPU上にコピー
CUdeviceptr d_instances;
const size_t instances_size = sizeof(OptixInstance) * instances.size();
CUDA_CHECK(cudaMalloc(reinterpret_cast<void**>(&d_instances), instances_size));
CUDA_CHECK(cudaMemcpy(
reinterpret_cast<void*>(d_instances),
instances.data(), instances_size,
cudaMemcpyHostToDevice
));
OptixBuildInput instance_input = {};
instance_input.type = OPTIX_BUILD_INPUT_TYPE_INSTANCES;
instance_input.instanceArray.instances = d_instances;
instance_input.instanceArray.numInstances = static_cast<uint32_t>(instances.size());
Shader binding table (SBT) の構築
さて、長々と準備してきましたがようやく準備編最後です。マテリアル情報等を管理するShader binding table (SBT)を構築します。SBTの概要は図の通りです。SBTはRay generation, Miss, HitGroup, Callables, Exception の5種類のプログラムタイプに対してそれぞれ作られますが、ここではHitGroup用のSBTに関して説明します。
OptiXではレイのトラバース中に、各ジオメトリ(正しくはGAS)に紐づけられたSBTインデックスから頂点情報やマテリアル情報などを取得し、シェーディング等を行います。SBTのレイアウトはレイトレーシングを起動する前に確定している必要があり、SBTを構成するレコードのメモリサイズはテーブル内すべてで同一である必要があります。
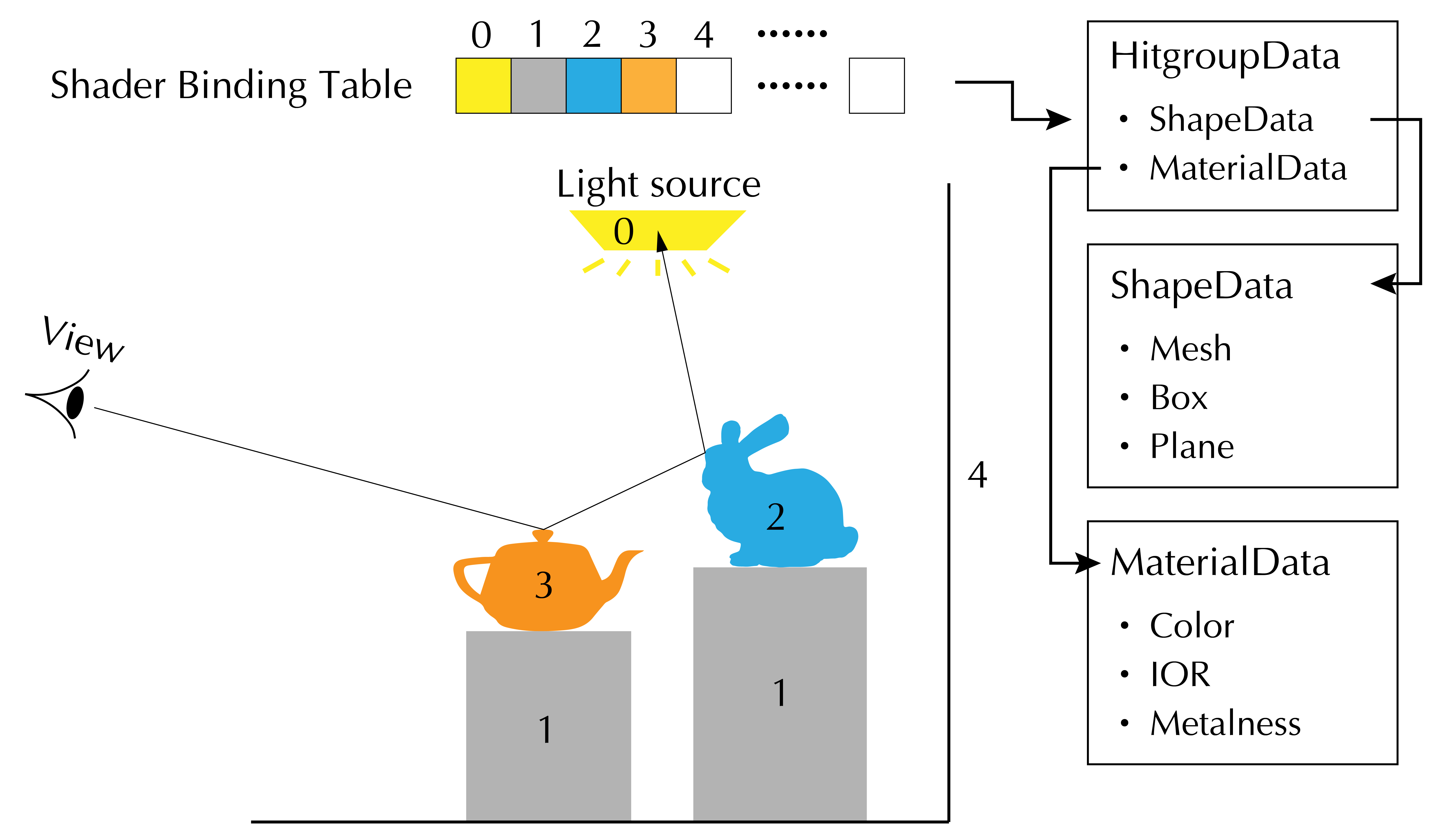
SBTは、各マテリアルやジオメトリのデータとそこに紐づくプログラムを設定するSBTレコードの配列からなります。
// Shader binding tableを構成するシェーダーレコードでヘッダーと任意のデータからなる。
// ヘッダーサイズはOptiX 7.4ではOPTIX_SBT_RECORD_HEADER_SIZE (32 bytes)で固定の値である。
// データはユーザー定義のデータ型を格納することが可能。ただし、Shader binding table内で
// 複数のレコードを保持できるHitGroup record, Miss record, Callables recordはそれぞれで
// レコードサイズが等しい必要がある。
template <typename T>
struct Record
{
__align__( OPTIX_SBT_RECORD_ALIGNMENT ) char header[OPTIX_SBT_RECORD_HEADER_SIZE];
T data;
};
各レコードのヘッダー部分は、OptixProgramGroupをoptixSbtRecordPackHeader()関数を用いて埋めることで、各SBTレコードにプログラムを割り当てます。これを忘れるとレイトレーシングを起動したのちに、メモリアクセス違反などが発生するので注意しましょう。この辺が、GPU上でエラーが起きた時にGPU上のコードの問題なのか、ホスト側における準備段階におけるの問題なのか判断するのを難しくしている気がします。
HitGroupレコード用のデータ、HitGroupDataはIntesection, Closesthit プログラムといったジオメトリ上における計算の際に使用されます。ここでは、ジオメトリ情報とマテリアル情報を紐づけておきましょう。今回は、Direct callablesプログラムを利用して疑似ポリモーフィズムを実現するので、マテリアル用のプログラムIDも紐づけておきます。
struct Material {
// マテリアル(Lambertian, Glass, Metal)のデータ
// デバイス上に確保されたポインタを紐づけておく
// 共用体(union)を使わずに汎用ポインタにすることで、
// 異なるデータ型の構造体を追加したいときに対応しやすくなる。
void* data;
// マテリアルにおける散乱方向や色を計算するためのCallablesプログラムのID
// OptiX 7.x では仮想関数が使えないので、Callablesプログラムを使って
// 疑似的なポリモーフィズムを実現する
unsigned int prg_id;
};
struct HitGroupData
{
// 物体形状に関するデータ
// デバイス上に確保されたポインタを紐づける
void* shape_data;
Material material;
};
汎用ポインタを使用しているのは、SBTレコードのサイズがSBT内で同一であるという制約を簡単に満たすためです。
汎用ポインタではなく、unionを使って以下のようにデータを管理してもよいのですが、そうすると構造体サイズが極端に大きいデータを使用する場合や、他のデータ型を追加したくなった時にいちいち定義を変える必要があって面倒なので、デバイス上の汎用ポインタを使用しています。
// unionを使用してもよいが、データ型を追加したい場合には面倒
struct Material
{
union {
LambertianData lambertian;
DielectricData glass;
MetalData metal;
} data;
unsigned int prg_id;
};
さて、今回のシーンではSBTを以下のように作りました。
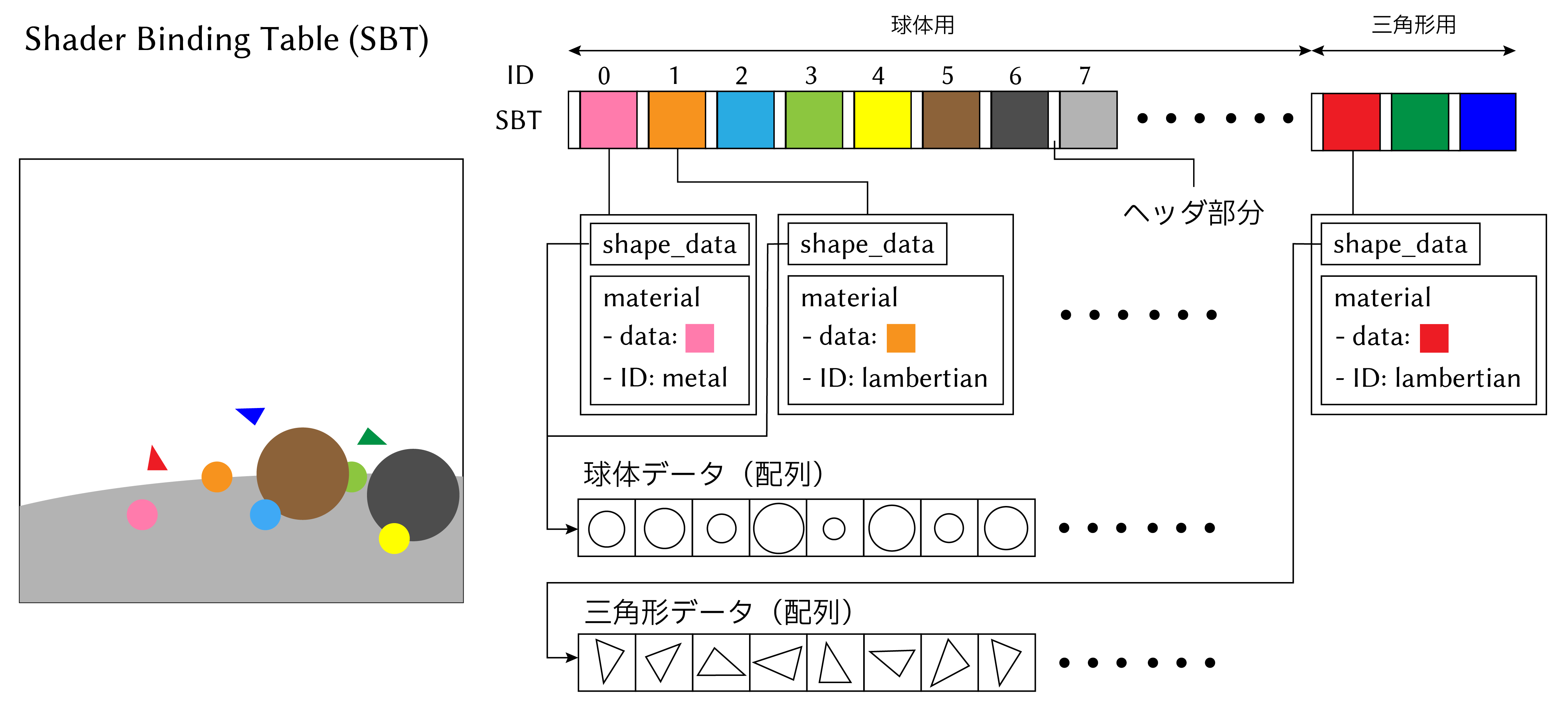
球体はすべて異なるマテリアルを適用しているので、マテリアルの数だけSBTレコードを登録します。ヘッダ部分には球体の部分では OneWeekendState::sphere_hitgroup_prgを、メッシュ部分にはOneWeekendState::mesh_hitgroup_prgを紐づけておきます。
HitGroupData::shape_dataにはそれぞれデバイス上のジオメトリ情報を格納した配列へのポインタを格納しておきます。GPU編で説明しますが、物体と交差判定を取る際には optixGetPrimitiveIndex() によってGAS内の何番目のAABB (三角形) と交差したかを取得できるため、各データにはそのインデックス情報を用いてアクセスします。
例えば球体の交差判定プログラムでは以下のようにしています。
extern "C" __global__ void __intersection__sphere()
{
// SBTからデータを取得
HitGroupData* data = (HitGroupData*)optixGetSbtDataPointer();
// ジオメトリのIDを取得
const int prim_idx = optixGetPrimitiveIndex();
// Primitive IDから球体データを取得
const SphereData sphere_data = ((SphereData*)data->shape_data)[prim_idx];
// ... 交差判定処理
}
ここで、IASの構築の際に説明したSBTとASの関係を説明します。
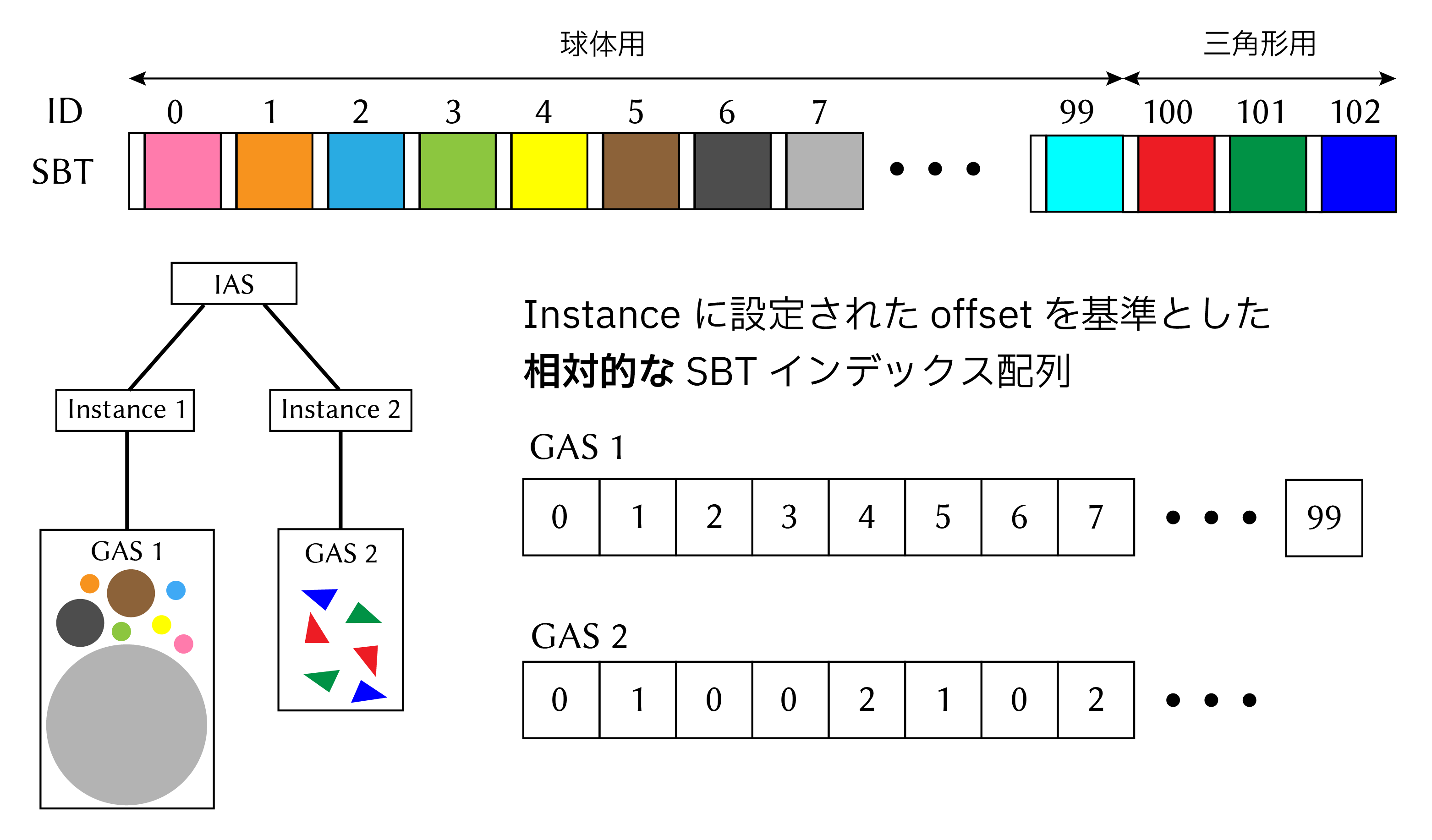
レイトレーシングのトラバース中にヒットしたジオメトリのSBT indexは以下の計算で求められます。
\begin{align}
\textrm{SBT_index} &= \textrm{SBT_Instance_Offset} \\
&+ \textrm{SBT_GAS_Index} * \textrm{SBT_Stride_from_trace_call} \tag{1} \\
&+ \textrm{SBT_Offset_from_trace_call}
\end{align}
$\textrm{SBT_Stride_from_trace_call}$と$\textrm{SBT_Offset_from_trace_call}$は使用するレイタイプの数と、現在トレースしているレイタイプのIDと考えていいと思います。例えば、カメラレイとシャドウレイで2種類のレイタイプを使用する場合は、Strideが2となり、カメラレイのOffsetが0、シャドウレイが1となる感じです。そのため、基本的にはSBTのレコード数はレイタイプ×マテリアル数となるでしょう。
さて、トラバース中にSBT indexが上式のように求まるなら、SBT Offsetの重要さがわかるかと思います。
例えば、Instance 1に紐づいている球体用のGASには100個のSBTレコードIDが使われているとします。Strideを1、レイタイプを0とすると、Instance 2のSBT Offsetに100を指定しておかないと、Instance 2内の三角形にレイがヒットした場合に誤って球体用に用意したSBTレコードにアクセスしてしまいます。
例えばわざと誤った挙動を起こすようにSBT Offsetの値を変えてみましょう。IAS構築時に設定したOffsetを3だけずらしてみます。画像の例だと、Instance 2 の SBT Offsetが100でなければならないところを97にします。
![]() このように未定義の動作をわざと引き起こすのは非常に危険で、メモリアクセス違反やブルースクリーン、GPUのハングを引き起こす可能性があります。本当に責任がある方だけ自環境でお試しください。責任は負いかねます。
このように未定義の動作をわざと引き起こすのは非常に危険で、メモリアクセス違反やブルースクリーン、GPUのハングを引き起こす可能性があります。本当に責任がある方だけ自環境でお試しください。責任は負いかねます。
// 正解
sbt_offset += sphere_gas.num_sbt_records;
// わざとオフセット値を間違える
sbt_offset += sphere_gas.num_sbt_records - 3;
結果は以下の通りです。正しい方では三角形が赤・緑・青となっていますが、offsetをずらした場合は、真ん中の3つの球体用のマテリアルが三角形に適用されているように見えます。これも三角形の交差判定はビルトイン実装なので、三角形を観察できていますが、カスタム形状の場合はジオメトリすら観察できない可能性もあります。

シェーダーテーブルの解説に関しては、@shocker-0x15さんの記事がとても分かりやすいですし、記事を書く上で参考にさせていただきました。
さてこれで準備完了です。あとはシーンのデータを準備して、レイを飛ばすだけです。準備編が長くなってしまったので、GPU編はサクっと終わらせる予定です。準備編ほど話すこともないですし。