Compute shaderとは
Compute Shader - OpenGL Wiki - Khronos Group
頂点を処理するVertex Shaderや色を処理するFragment/Pixel Shaderと異なり、GPUでの計算に特化したShaderになります。
これにより、GPU Particleなどを実装したいときに、わざわざFragment Shaderからテクスチャに頂点座標の計算結果を書き込まなくても良くなります。
対応環境
OpenGL4.3 以降に対応していること。
残念ながら mac はOpenGL 4.1までしか対応していないので、この記事は使えないことになります。。。
実行環境
私のマシンのスペックです。
- PC: Window 10
- GPU: Nvidia GeForce RTX 2060
- openFrameworks 0.10.1
実際にやってみる。
今回は導入的な感じとして、以下のような簡単な頂点計算を行って、それをParticleに適用するところまでをやりたいと思います。
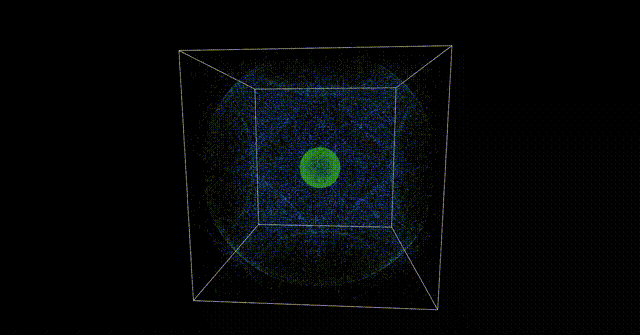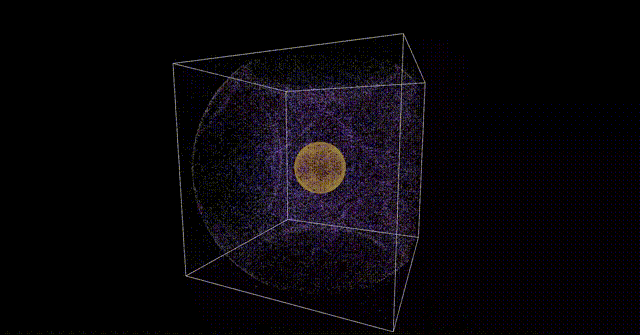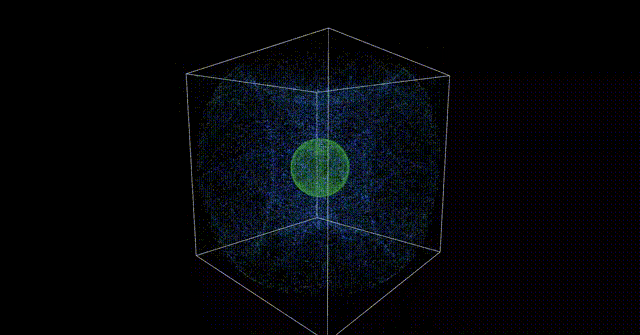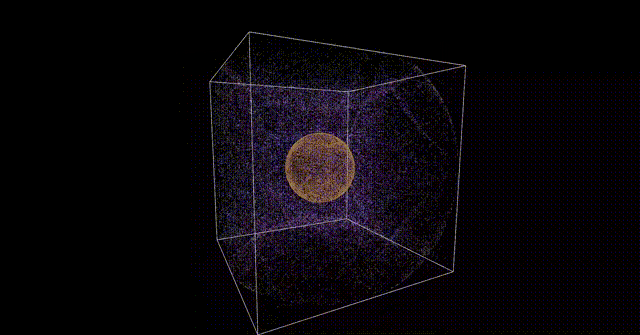
注意事項
今回はOpenGL4.3以降を用いているので、main.cppの部分で設定を忘れないようにしてください。これをやっていないと無限にCompute shaderが動きません。たまにハマります。
int main( ){
ofGLWindowSettings s;
s.setSize(1024, 768);
s.setGLVersion(4, 5);
ofCreateWindow(s);
ofRunApp(new ofApp());
}
ofApp.h/.cpp
CPU側で計算結果を使うためには、Buffer Objectが必要なので、shaderとbuffer objectを用意します。
# pragma once
# include "ofMain.h"
class ofApp : public ofBaseApp{
public:
void setup();
void update();
void draw();
void keyPressed(int key);
void keyReleased(int key);
void mouseMoved(int x, int y );
void mouseDragged(int x, int y, int button);
void mousePressed(int x, int y, int button);
void mouseReleased(int x, int y, int button);
void mouseEntered(int x, int y);
void mouseExited(int x, int y);
void windowResized(int w, int h);
void dragEvent(ofDragInfo dragInfo);
void gotMessage(ofMessage msg);
struct Particle {
ofVec4f pos; // 頂点情報とparticleの年齢を格納
ofVec4f vel; // 速度情報とparticleの寿命を格納
};
ofBufferObject dataBuffer; // particle情報を格納するためのBuffer Object
ofShader compute, renderParticle; // compute shaderとparticleを描画するshader
ofVboMesh particle; // particle
int numParticle; // particleの個数
ofEasyCam cam; // カメラ
ofVec3f wallSize;
};
次にofApp.cppのsetup()内でBuffer Object, Shader, VboMeshの初期化を行います。
Compute Shaderの読み込みは compute.loadCompute(string name) で行います。
Buffer ObjectをParticle型のvectorで初期化します。今回だと位置/速度情報と年齢/寿命を書き込みます。
GL_DYNAMIC_DRAWと書かれている部分はBuffer Objectの読み書き方法の指定です。
詳しくはこちらをご覧ください。
glBufferData - OpenGL 4 Reference Pages - Khronos Group
// シェーダー読み込み
compute.loadCompute("shader/compute.glsl"); // Compute shader
renderParticle.load("shader/render.vert", "shader/render.frag"); // particleを描画するためのshader
numParticle = 256 * 256; // particleの個数
vector<Particle> particleData; // particleの位置/速度情報を初期化するためのvector
particleData.resize(numParticle); // particleの個数に配列の要素数を合わせる
for (auto& p : particleData) {
p.pos.x = ofRandom(-1.0, 1.0);
p.pos.y = ofRandom(-1.0, 1.0);
p.pos.z = ofRandom(-1.0, 1.0);
p.pos.w = 0.0; // particleの年齢
p.vel.x = ofRandom(-5.0, 5.0);
p.vel.y = ofRandom(-5.0, 5.0);
p.vel.z = ofRandom(-5.0, 5.0);
p.vel.w = (int)ofRandom(0.0, 4.0) * 0.5; // particleの寿命
particle.addVertex(ofVec3f(p.pos));
particle.addColor(ofFloatColor(1.0, 1.0, 1.0, 1.0));
}
// Buffer Objectの初期化
dataBuffer.allocate(particleData, GL_DYNAMIC_DRAW);
初期設定ができたら、draw()関数内でCompute shaderの実行とParticleの描画を行います。
ここでShaderからBuffer Objectを読み書きできるようにbind()する必要があります。bindBase()ではshaderで読み書きするときのindex番号を設定します。
bind()できたら、Compute Shaderで計算します。計算する際に重要なのが、dispatchCompute()の部分です。これはCompute shaderの計算の並列度**(WorkGroupの数)**を設定し、計算を開始する関数です。この並列度に関してはshaderの部分で触れたいと思います。
// Buffer Objectをバインド
dataBuffer.bind(GL_SHADER_STORAGE_BUFFER);
dataBuffer.bindBase(GL_SHADER_STORAGE_BUFFER, 0);
// Compute shaderで頂点/速度を計算する
compute.begin();
compute.setUniform3f("wallSize", wallSize);
compute.setUniform3f("wallCenter", ofVec3f(0, 0, 0));
compute.dispatchCompute(64, 1, 1);
compute.end();
// 計算結果を基にParticleを描画
renderParticle.begin();
renderParticle.setUniform1f("time", time);
particle.draw(OF_MESH_POINTS);
renderParticle.end();
// Buffer Objectをアンバインド
dataBuffer.unbindBase(GL_SHADER_STORAGE_BUFFER, 0);
dataBuffer.unbind(GL_SHADER_STORAGE_BUFFER);
Shader
app側の設定が完了したので、Shaderのコードに移りたいと思います。
まずはCompute shaderです。
重要な部分だけ解説すると、layout(std430, binding=0)...の部分で、先ほどbindしたBuffer Objectに配列としてアクセスすることができます。この時、bindingの番号は、CPU側でbindBase()で設定した番号にします。
次にvoid main()の上にある。layout(local_size_x = BLOCK_SIZE, ...) in;に注目してください。これは一度にGPUで並列処理する Block数 を指定しています。このBlockごとの処理を先ほどの dispatchCompute() ではいくつずつ同時に並列で動かすかを指定しています。
例えば、dispatchCompute(64, 1, 1), layout(4, 1, 1)とすると
(64 * 4) * (1 * 1) * (1 * 1) = 256
のスレッドが同時にGPU内で計算されることになります。
dispatch...(4, 4, 1), layout(4, 4, 1)なら
(4 * 4) * (4 * 4) * (1 * 1) = 16 * 16 = 256
という感じです。
したがって、dispatchとlayoutの値をparticleや処理の数に合わせて設定することで、計算処理をより高速にすることができます。
各スレッドにはIDが割り振られており、gl_GlobalInvocationID.xがそれにあたります。これは、全実行スレッドのうち、今何番目のスレッドなのか決めるIDが一意に割り振られているものになります。
IDには他にも種類があり、今のWorkGroupの番号を取得するgl_WorkGroupID、WorkGroup内で何番目のスレッドにいるのか取得するgl_LocalInvocationIDなどがあります。
IDが取得できたら、それを基に頂点と速度の更新を行います。計算部分は特別なことはしていないので割愛します。
計算が終わったら、最後に読み込んだ時と逆に書き込みを行います。p[id] = parの部分です。
# version 440
const int BLOCK_SIZE = 1024;
uniform vec3 wallSize;
uniform vec3 wallCenter;
struct Particle {
vec4 pos;
vec4 vel;
};
layout(std430, binding=0) buffer particle{
Particle p[];
};
float random(vec2 n) {
return fract(sin(dot(n.xy, vec2(12.9898, 78.233))) * 43758.5453);
}
vec3 reflectWall(vec3 pos, vec3 vel) {
vec3 ws = wallSize;
vec3 wc = wallCenter;
if(pos.x < wc.x - ws.x * 0.5 || pos.x > wc.x + ws.x * 0.5) vel.x *= -1.0;
if(pos.y < wc.y - ws.y * 0.5 || pos.y > wc.y + ws.y * 0.5) vel.y *= -1.0;
if(pos.z < wc.z - ws.z * 0.5 || pos.z > wc.z + ws.z * 0.5) vel.z *= -1.0;
return vel;
}
layout(local_size_x = BLOCK_SIZE, local_size_y = 1, local_size_z = 1) in;
void main() {
uint id = gl_GlobalInvocationID.x;
// Buffer Objectからid番目のデータを取得
Particle par = p[id];
vec3 pos = par.pos.xyz;
vec3 vel = par.vel.xyz;
float age = par.pos.w;
float maxAge = par.vel.w;
age += 0.01;
if(age > maxAge) {
age = 0.0;
maxAge = 2.0;
pos = vec3(random(pos.xx) * 2.0 - 1.0, random(pos.yy) * 2.0 - 1.0, random(pos.zz) * 2.0 - 1.0);
vel = normalize(pos) * 5.0;
}
// 頂点に速度を足す
pos += vel;
vel = reflectWall(pos, vel);
// Buffer Objectのデータ更新
par.pos.xyz = pos;
par.vel.xyz = vel;
par.pos.w = age;
par.vel.w = maxAge;
p[id] = par;
}
さて、最後にparticleをレンダリングします。
同じようにlayout(std430...でBuffer Objectにアクセスできるようにし、particleの頂点番号gl_VertexIDでBuffer Objectにアクセスします。読み込んできた頂点情報にモデルビュープロジェクション行列をかけたら、色を出力するだけです。
注意すべきは、Compute shaderとParticleを描画するshaderの両方でBuffer Objectにアクセスしているので、Compute Shaderが終わった段階でunbind()してしまうと、vertex shaderからBuffer Objectにアクセスできなくなります。
# version 440
struct Particle {
vec4 pos;
vec4 vel;
};
layout(std430, binding=0) buffer particle {
Particle p[];
};
uniform mat4 modelViewProjectionMatrix;
uniform float time;
in vec4 position;
in vec4 color;
out vec4 vColor;
void main() {
vec3 pos = p[gl_VertexID].pos.xyz;
float age = p[gl_VertexID].pos.w;
gl_Position = modelViewProjectionMatrix * vec4(pos, 1.0);
vColor = vec4(mod(time * 0.3, 1.0), 0.5, age, 1.0);
gl_PointSize = 5.0f;
}
# version 440
precision mediump float;
in vec4 vColor;
out vec4 fragColor;
void main() {
fragColor = vColor;
}
CPU側ソースコード
Shaderコードは全て載せたので、最後にofApp.cppの全コードを載せて終わります。
void ofApp::setup(){
ofSetFrameRate(60);
ofBackground(0);
ofSetVerticalSync(true);
// シェーダー読み込み
compute.loadCompute("shader/compute.glsl"); // Compute shader
renderParticle.load("shader/render.vert", "shader/render.frag"); // particleを描画するためのshader
numParticle = 256 * 256; // particleの個数
vector<Particle> particleData; // particleの位置/速度情報を初期化するためのvector
particleData.resize(numParticle); // particleの個数に配列の要素数を合わせる
for (auto& p : particleData) {
p.pos.x = ofRandom(-1.0, 1.0);
p.pos.y = ofRandom(-1.0, 1.0);
p.pos.z = ofRandom(-1.0, 1.0);
p.pos.w = 0.0; // particleの年齢
p.vel.x = ofRandom(-5.0, 5.0);
p.vel.y = ofRandom(-5.0, 5.0);
p.vel.z = ofRandom(-5.0, 5.0);
p.vel.w = (int)ofRandom(0.0, 4.0) * 0.5; // particleの寿命
particle.addVertex(ofVec3f(p.pos));
particle.addColor(ofFloatColor(1.0, 1.0, 1.0, 1.0));
}
particle.setMode(OF_PRIMITIVE_POINTS);
// particleの情報でBuffer Objectを初期化
dataBuffer.allocate(particleData, GL_DYNAMIC_DRAW);
wallSize = ofVec3f(500, 500, 500);
}
//--------------------------------------------------------------
void ofApp::draw(){
float time = ofGetElapsedTimef();
cam.setPosition(sin(time * 0.2) * 800, 100, cos(time * 0.2) * 800);
cam.lookAt(ofVec3f(0, 0, 0));
cam.begin();
glEnable(GL_DEPTH_TEST);
// Buffer Objectをバインド
dataBuffer.bind(GL_SHADER_STORAGE_BUFFER);
dataBuffer.bindBase(GL_SHADER_STORAGE_BUFFER, 0);
// Compute shaderで頂点/速度を計算する
compute.begin();
compute.setUniform3f("wallSize", wallSize);
compute.setUniform3f("wallCenter", ofVec3f(0, 0, 0));
compute.dispatchCompute(64, 1, 1);
compute.end();
// 計算結果を基にParticleを描画
renderParticle.begin();
renderParticle.setUniform1f("time", time);
particle.draw(OF_MESH_POINTS);
renderParticle.end();
// Buffer Objectをアンバインド
dataBuffer.unbindBase(GL_SHADER_STORAGE_BUFFER, 0);
dataBuffer.unbind(GL_SHADER_STORAGE_BUFFER);
ofNoFill();
ofDrawBox(0, 0, 0, wallSize.x, wallSize.y, wallSize.z);
glDisable(GL_DEPTH_TEST);
cam.end();
}