データベース: 統計情報の種類と役割
目次
1. 統計情報の役割
概要
データベースは、データの全体像を把握し、クエリを迅速に実行するために統計情報を利用します。統計情報は、データのサイズや分布に関するガイドとして機能し、効率的なクエリ計画を立てる際に不可欠です。
役割
統計情報は、データベースがクエリを最適に実行するために、フルスキャンやインデックススキャンを選択する際の判断材料として利用されます。
統計情報の例
- テーブルの総行数
- 各カラムにどのような値が多いか
- データの分布(平均値、最大値、最小値、分散など)
2. 統計情報の主要な種類
テーブルレベルの統計情報
- 概要: テーブル全体に関する情報です。
- 例: テーブルの総行数、NULL値の割合、重複度などが含まれます。
- 用途: テーブル全体をスキャンするか、インデックスを使うかの判断に利用されます。
-
SQL例:
SELECT * FROM PEOPLE;
カラムレベルの統計情報
- 概要: 各カラムのデータ分布に関する情報です。
- 例: カラムの値の分布(最小値、最大値、平均値)、ユニークな値の数、データの頻度(ヒストグラム)などが含まれます。
-
用途:
WHERE句の条件で、インデックスを使うかどうかを決定するために利用されます。 -
SQL例:
SELECT * FROM PEOPLE WHERE NAME = '田中太郎';
インデックスレベルの統計情報
- 概要: インデックスに関する情報です。
- 例: インデックスのユニーク度(重複がどのくらいあるか)、リーフレベルの深さ、クラスタリングファクタ(インデックスの順序通りにデータが並んでいるか)などが含まれます。
- 用途: インデックススキャンか、フルスキャンかを決定する際に利用されます。
-
SQL例:
CREATE INDEX IDX_PEOPLE_1 ON PEOPLE (NAME, ADDRESS); SELECT * FROM PEOPLE WHERE NAME = '田中太郎';
3. 統計情報がクエリに与える影響
・カラムレベルの統計情報
2の項目で挙げたカラムレベルの統計情報のうち、ヒストグラム(ユニーク度)が
どの程度実行計画に影響を及ぼすかについて検証します。
- データベース: PostgreSQL
- テーブル名: PEOPLE
- データ数: 400万件
- 統計情報: 最新の状態
-
カラム:
-
PERSON_ID: 一意なデータ -
DUPLICATION_MANY: 重複のあるデータ(0〜3の整数)- 0 :40万件
- 1 :40万件
- 2 :40万件
- 3 :280万件
-
- index
- index名:Idx_people_person_id 指定カラム: person_id
- index名:Idx_people_duplication_many 指定カラム: duplication_many
一意なデータをフィルタリングした場合
- インデックススキャンが選択され、クエリの実行が最適化されます。

重複のあるデータをフィルタリングした場合
- 取得結果が多い場合、
BitmapHeapScanが選択されることがあります。
filterがデータ量の10%程度のためBitmapHeapScanが選択されました。
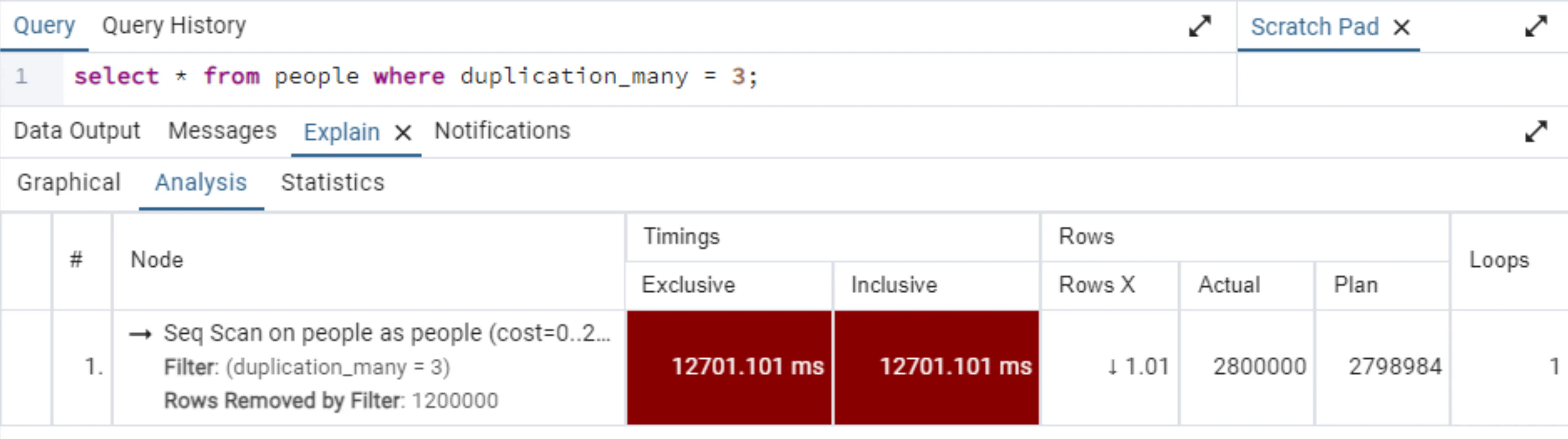
取得結果がもっと多い場合(duplication_many=3)の場合はフルスキャンが選択されます。
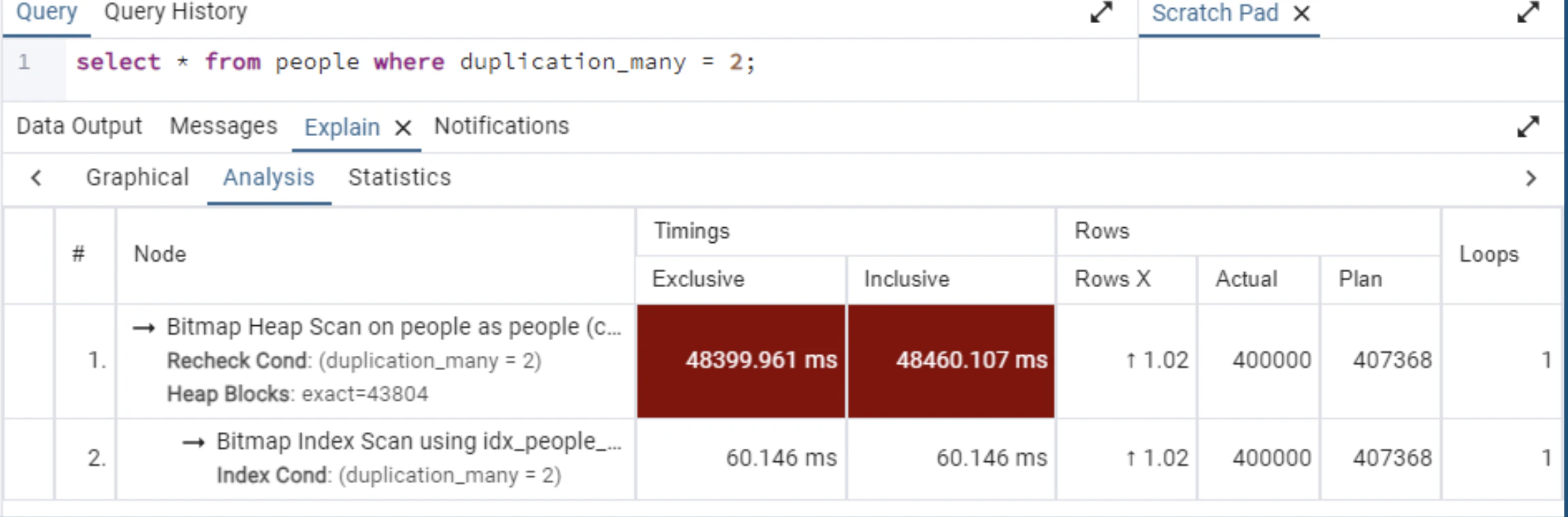
- 取得結果がさらに多い場合は、フルスキャンが選択されることがあります。
・適切なインデックスの有無
- データベース: PostgreSQL
- テーブル名: PEOPLE
-
カラム:
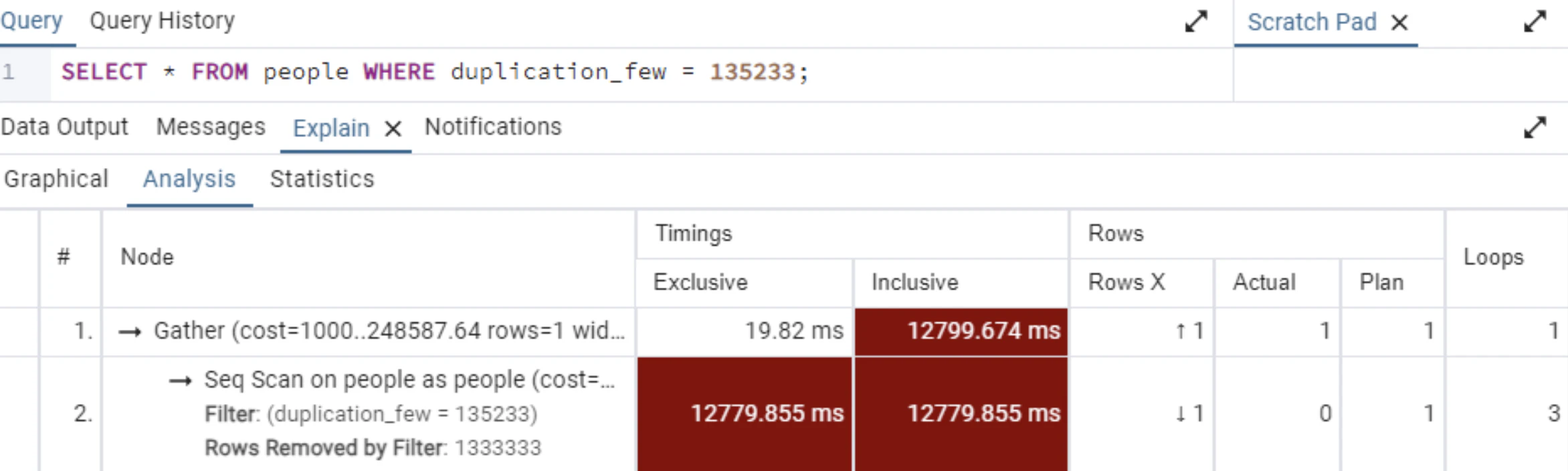
duplication_few(一意なデータ)select * frrom people where duplication_few = 135233;
適切なインデックスが存在する場合
- インデックススキャンが選択され、パフォーマンスが向上します。

適切なインデックスが存在しない場合
- フルスキャンが選択される可能性が高く、パフォーマンスに影響を及ぼします。
4. まとめ
-
FROMやWHEREなどを考慮し、ユニーク度の高いカラムからインデックスを定義しましょう。 -
ヒストグラムを意識したインデックス作成が効果的です。特にユニーク度が高いカラムにはインデックスが有効です。
-
ユニーク度が低く、インデックスを使ってもパフォーマンスが改善しない場合は、次の対策を検討しましょう:
- パーティション化
- キャッシュの利用
-
LIMIT、OFFSETの活用 - 非同期処理の利用