皆さんは、プログラミング言語を使っていて、こう思ったことはありませんか?
「日本語で書きたい!」
「もっと曖昧に書きたい!」
私は、ありません。
ですが、そういう言語を作ってみたいとは思っていました。
そしてCOTOHAという自然言語処理のプラットフォームに出会い、それを使って構文が曖昧でかつ日本語のプログラミング言語を作成できないかと思い立ち、挑戦してみました。
その名も、aimaiです。
この言語では、以下のようなプログラムが実行できます:
太郎は100を持っている。
二郎は99を持っています。
三郎は98を持っています。
花子は二郎かける三郎割る太郎を持っていました。
花子を表示しました。
今までの言語だと考えられないような書き方です。語尾すら合っていません。(日本語的にはだめですがw)
urlなど
この言語のGitHub -> https://github.com/sizumita/aimai-lang
COTOHA API -> https://api.ce-cotoha.com/contents/developers/index.html
言語仕様
この言語は曖昧な文法に対応していますが最低限のルールは設定しています。
-
変数名は人名、その後の呼び出しではわかる範囲で代名詞が使用可能
- 代入文は
[人名]は[変数の中身]を持っている(わかる範囲で曖昧に記述可能:花子は3を持たされました。`など)
- 代入文は
-
使用可能な型はint、str、list、(pythonを使用するため)
-
変数同士の四則演算
[人名 or int or str] [掛ける|わる|足す|引く] [人名 or int or str][人名 or int or str] *|/|+|- 人名 or int or str
-
他の変数の参照
[人名]
-
関数
- print
[人名] を表示。
- print
-
class なし
futures
- 条件式
-
==, <=, >=, !=※これは諦めました...
-
- if文
もし[条件式]ならば: ... \nおわり。
- list
- 要素の取り出し
[人名] のn番目
- 要素の追加・変更など
[人名] は1番目の持ち物をnに変更した
- 要素の取り出し
- 自作関数
- 複雑な数式
予約語
流石に全部読み取るのは厳しいので、少しだけ予約語を使います。
- 四則演算
掛け算,割り算,引き算,足し算,積商差和 - list
n番目の要素, nに変更 - 関数
合計する,逆にする,個数を数える,順番を揃える - if,
もし, ならば, おわり。
それぞれも曖昧にしても大丈夫なような設計にする必要があります。
作成する
APIキーを取得する
COTOHA APIでは、APIを使用するためのキーを最初に取得する必要があります。
まず、こちらから登録しクライアントIDとシークレットを取得してください。
import json
import requests
from pprint import pprint
DEVELOPER_API_BASE_URL = "https://api.ce-cotoha.com/api/dev/"
ACCESS_TOKEN_PUBLISH_URL = "https://api.ce-cotoha.com/v1/oauth/accesstokens"
CLIENT_ID = "あなたの取得したID"
CLIENT_SECRET = "あなたの取得したシークレット"
def get_access_token():
headers = {
"Content-Type": "application/json"
}
data = {
"grantType": "client_credentials",
"clientId": CLIENT_ID,
"clientSecret": CLIENT_SECRET
}
data = json.dumps(data).encode()
response = requests.post(ACCESS_TOKEN_PUBLISH_URL, data=data, headers=headers)
return response.json()['access_token']
access_token = get_access_token()
get_access_token関数を実行することでアクセストークンを入手することができます。
定形変換
代名詞を変換する
まず、この言語では構文解析する時に代名詞が一番問題になります。そのため、まずCOTOHAにある照応解析API を使用し、代名詞を全て名詞に変換します。ついでに、変数名となる人物名も入手します。
def anaphoric(text):
"""
代名詞を名詞に変えて返却
returns: トークン一覧, 変数名となる人名一覧
"""
url = DEVELOPER_API_BASE_URL + "nlp/v1/coreference"
data = {
"document": text
}
headers = {
"Authorization": "Bearer " + access_token,
"Content-Type": "application/json;charset=UTF-8",
}
users = []
data = json.dumps(data).encode()
response = requests.post(url, data=data, headers=headers)
j = response.json()
datas = j['result']['coreference']
tokens = j['result']['tokens'][0]
for content in datas:
referents = content['referents']
# 花子 と 花子さん の両方が引っかかってしまう場合がある
if referents[0]['token_id_from'] != referents[0]['token_id_to']:
continue
real_name = referents.pop(0)['form']
users.append(real_name)
for lie in referents:
tokens[lie['token_id_from']] = real_name
return tokens, users
>>> print(anaphoric("太郎は1を持っています。彼は持ち物を表示しました。"))
(['太郎', 'は', '1', 'を', '持', 'っ', 'て', 'い', 'ます', '。', '太郎', 'は', '持ち物', 'を', '表示', 'し', 'ました', '。'], ['太郎'])
予約語を変換する
例えばif, while文の:は障害になります。なので、APIが正しく認識できる形にしてやります。
条件式はもうどうしようもないので、条件式nに変換してやって、リストに保管しておきます。
def parse_sentences(tokens):
text = ''.join(tokens).replace('\n', '')
text = text.replace(':', '。') # if, while
result = ""
for s in text.split('。'):
match = re.match('もし(.+)ならば', s)
if match:
exp = match.groups()[0]
expressions.append(exp)
s = s.replace(exp, '条件式' + str(len(expressions)))
elif s == 'NHKを、ぶっ壊す。':
s = '殺す'
result += f'{s}。'
return text
字句解析
上で手に入れたtokenのリストから、文を切り出し、予約語などの適切な処理をした後、構文解析をします。
構文解析APIを読み解く
まず、COTOHAの構文解析APIについて勉強しておく必要があります。
ここで、動作動詞が一つの太郎は1を持っています。を例にしてやってみましょう。
{'message': '',
'result': [{'chunk_info': {'chunk_func': 1,
'chunk_head': 0,
'dep': 'D',
'head': 2,
'id': 0,
'links': []},
'tokens': [{'attributes': {},
'dependency_labels': [{'label': 'case',
'token_id': 1}],
'features': ['名', '固有'],
'form': '太郎',
'id': 0,
'kana': 'タロウ',
'lemma': '太郎',
'pos': '名詞'},
{'attributes': {},
'features': [],
'form': 'は',
'id': 1,
'kana': 'ハ',
'lemma': 'は',
'pos': '連用助詞'}]},
{'chunk_info': {'chunk_func': 1,
'chunk_head': 0,
'dep': 'D',
'head': 2,
'id': 1,
'links': []},
'tokens': [{'attributes': {},
'dependency_labels': [{'label': 'case',
'token_id': 3}],
'features': [],
'form': '1',
'id': 2,
'kana': 'イチ',
'lemma': '1',
'pos': 'Number'},
{'attributes': {},
'features': ['連用'],
'form': 'を',
'id': 3,
'kana': 'ヲ',
'lemma': 'を',
'pos': '格助詞'}]},
{'chunk_info': {'chunk_func': 4,
'chunk_head': 0,
'dep': 'O',
'head': -1,
'id': 2,
'links': [{'label': 'agent', 'link': 0},
{'label': 'object', 'link': 1}],
'predicate': ['progressive']},
'tokens': [{'attributes': {},
'dependency_labels': [{'label': 'nsubj',
'token_id': 0},
{'label': 'dobj', 'token_id': 2},
{'label': 'aux', 'token_id': 5},
{'label': 'aux', 'token_id': 6},
{'label': 'aux', 'token_id': 7},
{'label': 'aux', 'token_id': 8},
{'label': 'punct',
'token_id': 9}],
'features': ['T'],
'form': '持',
'id': 4,
'kana': 'モ',
'lemma': '持つ',
'pos': '動詞語幹'},
{'attributes': {},
'features': [],
'form': 'っ',
'id': 5,
'kana': 'ッ',
'lemma': 'っ',
'pos': '動詞活用語尾'},
{'attributes': {},
'features': ['接続', '連用'],
'form': 'て',
'id': 6,
'kana': 'テ',
'lemma': 'て',
'pos': '動詞接尾辞'},
{'attributes': {},
'features': ['A', 'Lて連用'],
'form': 'い',
'id': 7,
'kana': 'イ',
'lemma': 'いる',
'pos': '動詞語幹'},
{'attributes': {},
'features': ['終止'],
'form': 'ます',
'id': 8,
'kana': 'マス',
'lemma': 'ます',
'pos': '動詞接尾辞'},
{'attributes': {},
'features': [],
'form': '。',
'id': 9,
'kana': '',
'lemma': '。',
'pos': '句点'}]}],
'status': 0}
構文解析APIのレスポンスjsonの'result'はList[{'chunk_info': {...}, 'tokens': {...}}]です。これをAPIのデモページで確認してみると、
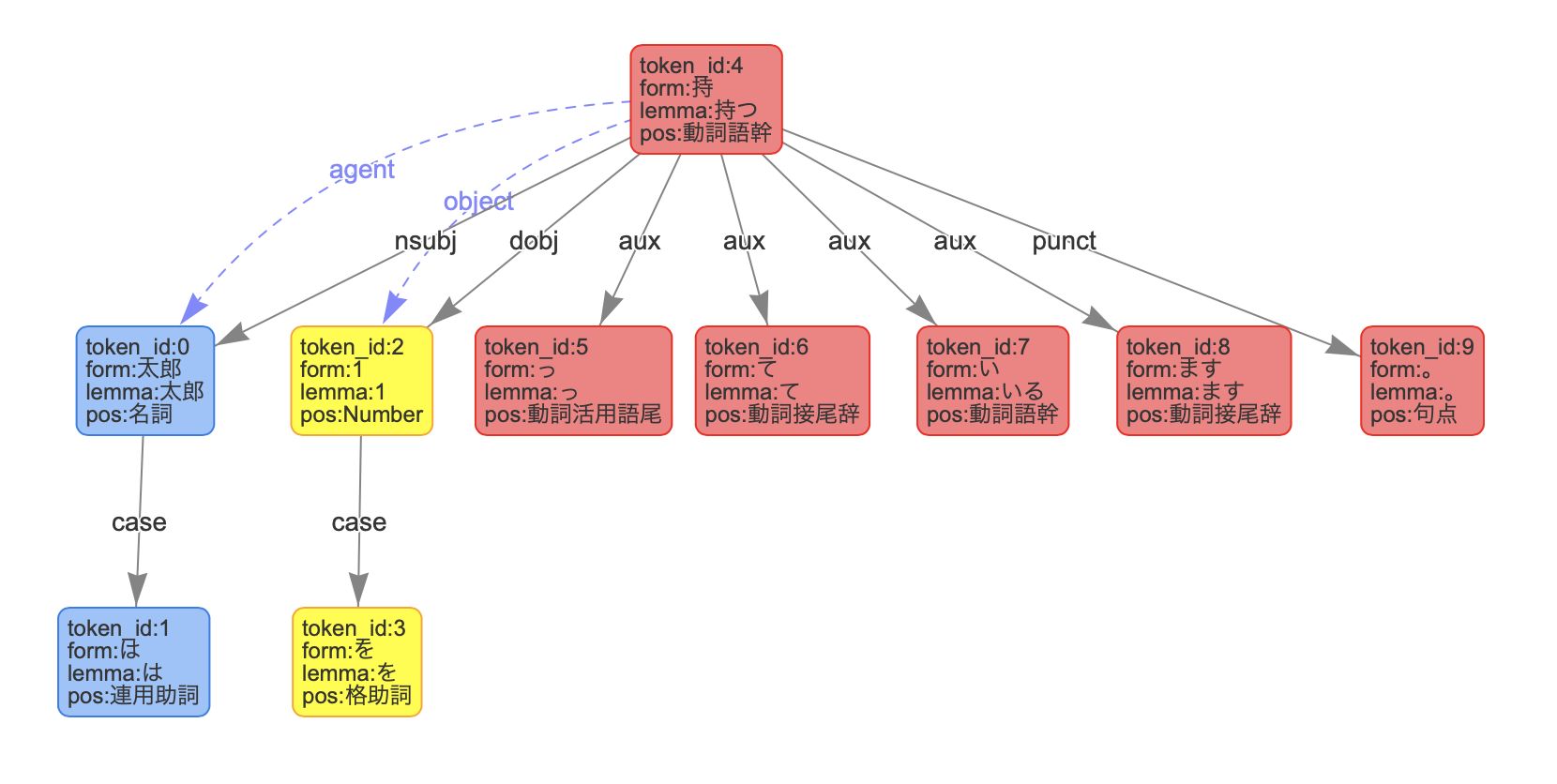
見事に色分けされているのがわかります。'tokens'に入っている情報からして色分けとチャンク情報は関係がありそうです。
dependency_labelsの繋がりが黒矢印、linksの繋がりが青点線矢印と思われます。
持つの文節は述語を表しています。よって、係りタイプが無いため0になっているようです。よって、係りタイプが0の文節が述語と判断して良さそうです。
そしてこのtokensが上位にあるものから先にあると信じます。(どなたか教えていただけると嬉しいです)
class化
このままでは扱いにくいので、classにしてしまいましょう。
class Link:
def __init__(self, info):
self.link = info['link']
self.label = info['label']
class Label:
def __init__(self, label_info):
self.label = label_info['label']
self.token_id = label_info['token_id']
class Token:
def __init__(self, token_info):
self.features = token_info['features']
self.form = token_info['form']
self.id = token_info['id']
self.pos = token_info['pos']
if 'dependency_labels' in token_info.keys():
self.dependency_labels = [Label(i) for i in token_info['dependency_labels']]
def __str__(self):
return self.form
class Phrase:
def __init__(self, chunk_info):
self.dep = chunk_info['dep']
self.id = chunk_info['id']
self.links = [Link(i) for i in chunk_info['links']]
self.main_token = None
self.sub_tokens = []
self.child_phrases = {}
def get_links(self, label):
"""リンク先の文節を返します"""
results = []
for link in self.links:
if link.label == label:
results.append(self.child_phrases[link.link])
return results
def get_link_id_list(self):
"""全てのリンク先の文節のidを返します"""
return [i.link for i in self.links]
def lexical(data):
phrases = {}
mains = []
for d in data:
chunk_info = d['chunk_info']
tokens = d['tokens']
main_token = Token(tokens.pop(0))
sub_tokens = list(map(Token, tokens))
phrase = Phrase(chunk_info)
phrase.main_token = main_token
phrase.sub_tokens = {i.id: i for i in sub_tokens}
if phrase.links:
for link in phrase.links:
linked = phrases.get(link.link, None)
if linked is None:
continue
phrase.child_phrases[link.link] = linked
if phrase.dep in ['O', 'P']:
mains.append(phrase)
phrases[phrase.id] = phrase
return mains
だいたいこんな感じで、自動で親子関係を作れるようにしました。今考えると子供を設定するのもPhrase内に書けばよかったか...
構文解析
上で字句解析した文一覧を次はなんの文なのかに分けていきます。
先ほどの処理ががLexだとするとここはYaccあたりでしょうか。
いろいろ文章を渡して実験していてわかったことは、例えば太郎くんは3を持ち4を足しました。だとうまく解析できないということです。やはり一文には1つの命令ぐらいしかおかない方が良さそうです。
構文解析について
構文解析というのは外側から当てはまるものをパターンマッチし、どんどん細かく分けていく作業です(認識が間違っていたらすみません)。
Yaccを使った時、hoge = 1のような文であれば、Assign(ID("a"), Int(1))のような感じに分けていきます。これを実装します。
class定義
まず、Yaccのようにそれぞれの意味を持たせたクラスを定義します。
class Int:
def __init__(self, value):
self.value = value
def __str__(self):
return f'{self.value}'
class Str:
def __init__(self, value):
self.value = value
def __str__(self):
return f'"{self.value}"'
class List:
def __init__(self, values):
self.values = values
def __str__(self):
return "{}".format(','.join(self.values))
class Assign:
"""代入式"""
def __init__(self, name, value):
self.name = name
self.value = value
def __str__(self):
return f'{self.name} = {self.value}'
class Parser:
def __init__(self, lexed, expressions, variables):
self.lexed = lexed
self.exp = expressions
self.var = variables
def parse(self):
pass
まず、主要な型と代入式だけで試してみます。山田くんは3を持ちました。を例に試してみましょう。
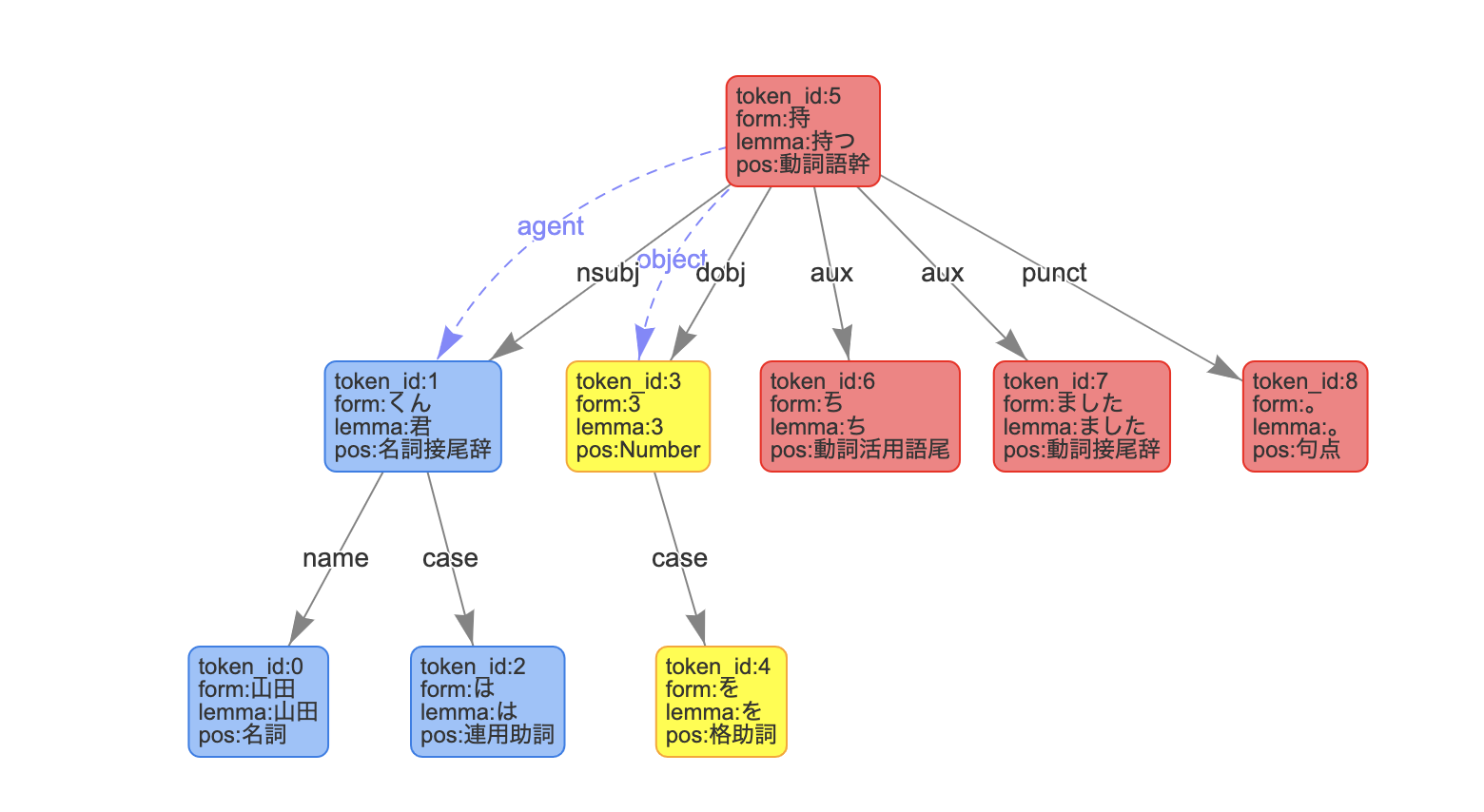
解析デモの画像から考えると、持でかつ動詞語幹であれば代入式と判断するのが良さそうです。
def stmt(self, value):
# 代入文
if value.main_token.pos == '動詞語幹':
if value.main_token.form == '持':
return self.assign(value)
def parse(self):
results = []
for l in self.lexed:
results.append(self.stmt(l))
このようにしてどんどん処理を書いていきます。
完成品がこちらです。
所々の処理がゴリ押しだったりするので、書き直したいとは思っています...
実行
完成品にある、それぞれのトークンclassにはconv関数が備わっています。この関数を実行することで、pythonの文字列が取得できる仕組みになっています。
class Int:
def __init__(self, value):
self.value = value
def conv(self):
return self.value
class Str:
def __init__(self, value):
self.value = value
def conv(self):
return f'"{self.value}"'
class List:
def __init__(self, values):
self.values = values
def conv(self):
return "[{}]".format(",".join(self.values))
class ID:
def __init__(self, value):
self.value = value
def conv(self):
return self.value
class Assign:
"""代入式"""
def __init__(self, name, value):
self.name = name
self.value = value
def conv(self):
return f'{self.name.conv()} = {self.value.conv()}'
class Function:
def __init__(self, func, value):
self.func = func
self.value = value
def conv(self):
return f"{self.func}({self.value.conv()})"
class Formula:
def __init__(self, value):
self.value = value
def conv(self):
return self.value
親のconv関数を実行することで、全てのconv関数を実行することが可能になっているので、簡単にコード生成が可能です。
def compiler(parsed):
results = []
for p in parsed:
results.append(p.conv())
return "\n".join(results)
さて、これで実行できそうです。
太郎は5を持っています。
花子は彼かける123を持っています。
花子を表示する。
$ python aimai.py test.txt
615
やりました!!!!!!!!!!!!!!一応の完成です!!!!!!
反省点
まず、数式の判別をする方法がわからず、文法に反している単語を飛ばすことぐらいしか思いつきませんでした...
また、listも判別が難しく、時間がないのもあり実装ができませんでした。if文や自作関数に関しても同じです。
目標
futuresに書いた仕様は作成したいと思います。また、一日に1000回しか実行できないのは困るので、同じコードであれば予めapiから取ってきたjsonを再利用できるようにしたいと思います。
最後に
前々から少し自然言語処理に興味がありましたが、このCOTOHA APIはすごいと思いました。
まず、代名詞の補完機能です。こんなのどうやるんだーと思っていましたが、簡単にできていて、裏に小人でもいるのかなと思いましたw。
また、構文解析の時に文節に分ける機能があって、その機能のおかげでこの言語も作成できたような物で、最近の自然言語処理は発達していると思いました。(単語に分けるものしか触ったことがなかったからかもしれませんが...)
aimaiに関して言えば、Pythonのインデントのようにです・ます口調かだ・である口調の論争が始まりそうだなあと思いましたw
まだまだ未完成で、反省すべきところもありますので、マサカリやPR、issueを立てていただけると嬉しいです🙏
GitHub -> https://github.com/sizumita/aimai-lang
最後に、この記事が面白いと思っていただけたら、いいねを押していただけると嬉しいです🙏🙏🙏