この記事は言語実装 Advent Calendar 2022 の24日目の記事です。
はじめに
monochromeです。今回はmonorubyという名前の高速なRuby処理系の紹介をします。
ここ何年か、わたしはruruby1というRubyのインタプリタをRustで書いていて、Advent Calendarでもいくつか紹介記事を書きました。
rurubyはRubyの言語機能のかなりの部分をカバーするところまで開発が進んだのですが、CRuby2と比較するとやはり遅いのが自分としては不満でした。そこでJITコンパイル3をサポートする高速な処理系を一から作ろう、ということで開発を始めたのがmonorubyです。対応するアーキテクチャは後述の理由でポータビリティに乏しいためx86-64・linuxのみ4サポートしています。
で、各種リテラルや制御構文、クラスとメソッドの定義、メソッド呼び出しにブロック、ローカル変数・インスタンス変数・グローバル変数を実装してそこそこRuby処理系っぽいところになったところでベンチマークを取った結果が下記です。
| 3.2.0-preview3 | --yjit | monoruby | monoruby --no-jit | |
|---|---|---|---|---|
| quicksort | 124.557k | 316.856k | 346.593k | 191.412k |
| app_fib | 3.566 | 14.378 | 18.625 | 4.859 |
| tarai | 2.922 | 13.015 | 14.117 | 3.733 |
| so_mandelbrot | 0.626 | 0.978 | 16.751 | 0.737 |
| so_nbody | 0.913 | 1.507 | 5.771 | 0.749 |
| app_aobench | 0.028 | 0.045 | 0.101 | 0.026 |
CRuby(3.2.0-preview3)およびCRubyの新しいJITコンパイラ・モジュールであるYJITを有効にした場合と、monoruby(JITあり・なし)の単位時間当たりの実行回数をbenchmark-driver.gem を用いて比較しています。数字が大きい方が速いです。ベンチマークの種類によりますが、YJITと比較しても高速、特に浮動小数点演算を多数実行するso_mandelbrotやso_nbody、app_aobenchでは数倍高速となっています。インタプリタもCRuby(JITなし)と遜色ない速度になっています。
以下、設計と実装について紹介していきますが、その前に必要な基礎知識をおさらいしておきます。
基礎知識
JITコンパイラは実行時に対象言語のプログラムを機械語へコンパイルするモジュールですが、一般的な実装ではインタプリタと並存して動きます。プログラムは抽象構文木を経由してバイトコード5に翻訳され、最初はインタプリタがバイトコードを実行しつつ最適化コンパイルに必要な情報を収集し、プログラムの一部分(メソッドやループ、特定の実行パスなど)が一定回数実行されるとJITコンパイラが起動して対象のバイトコードから機械語(JITコード)を生成し、以後はJITコードを実行するようになります6。具体的な構成は実装により様々なのですが、例として下記にmonorubyの実行パイプラインを示します。実行される種々のコードが灰色の箱、オレンジの箱はコードを変換・実行する主体を表しています。
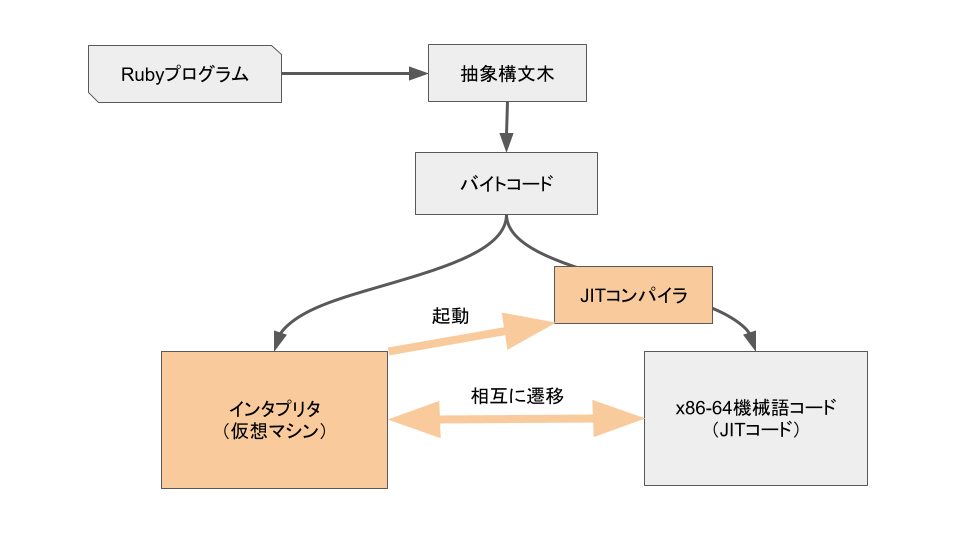
一般に動的言語で高速で小さなJITコードを生成するにはいくつかの前提条件(制約)の元でコンパイルを行う必要があります。具体的にいうと「ローカル変数xは整数である」「このa + bという加算の左辺aの型は整数で右辺bの型は浮動小数点数である」「定数Aの値は文字列"Ruby"である7」などの情報です。これらの情報は実行時にならないと分からない8ため、インタプリタがバイトコードを実行しながらオブジェクトの型やメソッドの情報、定数の値などの情報(プロファイル)を収集する必要があります。動的言語の性質上、コンパイルに用いた制約が常に満たされるとは限らない9ため、制約が崩れた場合には実行継続が不可能となり、その場でインタプリタへ戻って(deoptimization)、新たなプロファイルを元にコンパイルし直します。
このようにJITコンパイラの動作は複雑で、その性能には生成される機械語の品質やコンパイル速度の他、プロファイル情報を収集・保存するコストやdeoptimizationのコストも影響します。一般に高度な最適化を行うほどコンパイルに時間がかかり、またdeoptimizationが発生するリスクも高くなります。
下準備
処理系の話に行く前に機械語生成の具体的なやり方について説明します。Rustには既に機械語を生成する優れたライブラリがいくつかありますが、今回は自分の処理系用に使いやすいようにカスタマイズしたいので、monoasmというライブラリを自前で用意しています。これはx86-64専用で、proc macroというRustのマクロ機能を使ってアセンブリっぽい記法で実行時に機械語を吐くコードを書けます。
下記はmonoasmの使用例で、メソッド呼び出しで引き渡す引数をスタック上にセットする関数です。monoasm!マクロの内部にアセンブリ(っぽいもの)を記述しておくとコンパイル時に「機械語を生成してヒープに格納するRustコード」に変換され、実行時に実際の機械語が生成されます。
- 分岐や関数呼び出しの飛び先ラベルはあらかじめRustの変数として定義しておきます。
- 即値やレジスタ間接のオフセット指定などでは()の中にRustの式を書けます。
- JITコンパイラでは複数のコードページを切り替えて出力できると便利なので、その機能もつけてあります。
impl Codegen {
fn vm_set_arguments(&mut self, args: SlotId, len: u16, has_splat: bool) {
// set arguments
if len != 0 {
let splat = self.splat;
monoasm!(self.jit,
lea r8, [rsp - (16 + OFFSET_ARG0)];
);
for i in 0..len {
let next = self.jit.label();
let reg = args + i;
monoasm! {self.jit,
movq rax, [rbp - (conv(reg))];
}
if has_splat {
let no_splat = self.jit.label();
monoasm! {self.jit,
testq rax, 0b111;
jne no_splat;
cmpw [rax + 2], (ObjKind::SPLAT);
jne no_splat;
call splat;
jmp next;
no_splat:
}
}
monoasm! {self.jit,
movq [r8], rax;
subq r8, 8;
next:
}
}
}
}
}
なお、パーサとアロケータ(ガベージコレクタ)はrurubyのものをそのまま流用しています。
設計
monorubyの設計にあたり、いくつかの目標を立てました。
- 構造がシンプルであること
- インタプリタもそれなりに高速であること
- JITコンパイルが高速であること
- JITコード・インタプリタ間の遷移が高速に行えること
これらの目標を考慮してバイトコード、スタックのレイアウト、メソッド呼び出しのABIの設計を行なっています。
バイトコード
monorubyのインタプリタはレジスタマシンで、バイトコードは16バイト10の固定長です。特徴としては、命令コードやオペランドの他にインタプリタが収集するプロファイル情報もバイトコード内に書き込むようになっていることでしょうか11。例えばフィボナッチ関数のメソッドのバイトコードは下記のような感じになっています。%で示されているのはスタック上のスロット(レジスタと呼びます12)番号で、%0はselfです。先頭に+がついている命令は基本ブロックの開始を示します。
+:00000 init_method reg:5 arg:1 pos:1 req:1 block:0 stack_offset:5
:00001 _%2 = %1 < 3: i16
:00002 condnotbr _%2 =>:00005
:00003 %2 = 1: i32
:00004 ret %2
+:00005 %3 = %1 - 1: i16
:00006 %2 = %0.call fib(%3; 1)
:00009 %4 = %1 - 2: i16
:00010 %3 = %0.call fib(%4; 1)
:00013 %2 = %2 + %3
:00014 ret %2
この中の:00013 %2 = %2 + %3はレジスタ同士を加算してレジスタに戻す命令(ADD_RR)で、:00006 %2 = %0.call fib(%3; 1)はレシーバが%0(self)、メソッド名がfib、%3から始まって1個の引数を与えてメソッド呼び出しを行い、結果を%2へ格納するメソッド呼び出し命令(METHOD_CALL)です。下記にこれらの命令のメモリレイアウトを示します。
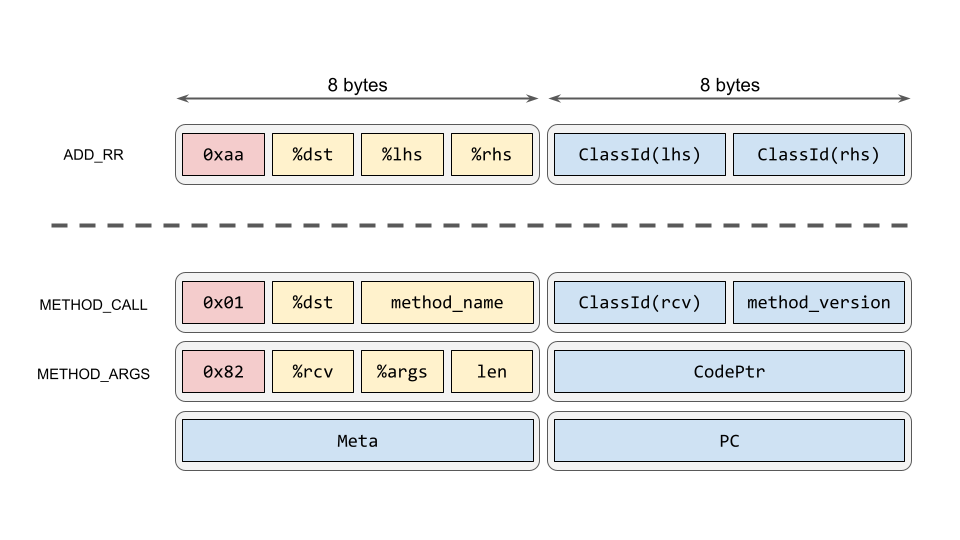
基本的には前半8バイトが命令コード(赤い部分)+オペランド(黄色)、後半8バイトがプロファイル情報(青)になっています。ADD_RR命令は命令コード(0xaa)で始まり、前半部には結果を格納するレジスタ番号(%dst)と左辺(%lhs)・右辺(%rhs)のレジスタ番号、後半は左辺・右辺の値のクラスIDが格納されます。
その下にあるMETHOD_CALLは16バイトの命令3個分を使うメソッド呼び出し命令です。メソッド名、レシーバ%rcv・引数%argsとその個数len・戻り値を返すレジスタ%dstなどのオペランドの他、プロファイル情報としてレシーバのクラスClassId(rcv)、関数ポインタCodePtrやメタ情報(関数IDなど)、バイトコードのアドレスPCがキャッシュされています。これらの情報はJITコンパイラだけでなく、インタプリタ自身もインライン・メソッドキャッシュとして使用します。
スタックフレーム構造の単一化
CRubyにはRuby上でのメソッド呼び出しに使用されるスタックがあり、メソッドを呼び出すとスタックを伸ばして制御情報やローカル変数領域を確保し(スタックフレーム)、メソッドから帰るときにはスタックを巻き戻します。一方、CRubyはC言語で書かれていますので、処理系内部の関数呼び出しや、Cで書かれたメソッドが呼ばれたときにはCのスタック(CPUが使うマシンスタック)を消費します。要はRubyスタックとマシンスタックの2つがあり、これらは基本的には別ものですが、Rubyで書かれたメソッド→Cで書かれたメソッド→Rubyで書かれたメソッドのように処理が進むと両方のスタックを消費することになり、処理が煩雑になる原因になっていました。
そこで、monorubyでは全てをマシンスタックにまとめる設計としました。これにより例外発生時などのスタックの巻き戻し処理やコルーチン(RubyではFiberクラス)の管理が単純化されます13。また、インタプリタやJITコード、Rustで書かれたメソッドも全て同一のスタックレイアウトを共有しているため、ループの途中でJITコンパイラを走らせてJITコードへ遷移したり(on stack replacement)、任意の場所でJITコードからインタプリタへ戻る(deoptimization)のも単にジャンプするだけ14で済むので低コストです。
メソッド呼び出しABIの単一化
また、CRubyもrurubyもメソッドを呼び出すときにはメソッドの実体がRubyで書かれたもの(=バイトコード)なのか、CなりRustなりで書かれた関数なのか、またはインスタンス変数のアクセサ15なのかで条件分岐して別々の処理を行っていました。monorubyのインタプリタではこれらすべてが同じABIになっている(=必要があれば処理系がラッパーを自動的に生成する)ので、呼び出し側は単に制御情報や引数をスタックにセットして指定のアドレスをcallすればよい仕組みになっています。インタプリタとJITコードも同一のABIで動きますので呼び出し側が考える必要はありません。
下記にスタックの構造を示します。詳細は省きますが、cfpを辿っていくことで呼び出し元のメソッドを、outerを辿っていくことで現在のブロックの外側のブロックを辿れます。
+-------------+
+0x08 | return addr | 戻り先アドレス
+-------------+
rbp-> | prev rbp | 前のスタックフレームの rbp
+-------------+
-0x08 | prev cfp | 前のフレームの cfp アドレス
+-------------+
-0x10 | outer | 外側のフレームへのリンク
+-------------+
-0x18 | meta | メタ情報。このメソッドの関数IDなど。
+-------------+
-0x20 | block | このメソッドに渡されたブロックの情報
+-------------+
-0x28 | self | selfの値
+-------------+
-0x30 | reg0 | 引数、ローカル変数、一時的に使用される変数など
+-------------+
| : |
+-------------+
rsp-> | reg(n-1) |
+-------------+
| : |
インタプリタ
上記のようにマシンスタックレイアウトやメソッド呼び出しABIを単一化するにはインタプリタが直接マシンスタックを触る必要があり、これをRustで書くのは困難です。また、monorubyのインタプリタは高速化のためにdirect threading16という手法を用いており、これもRustで実現するのは困難17です。このため、monorubyではインタプリタをアセンブリで記述し、処理系起動時に動的に生成することにしました。もちろん複雑な処理はRustでヘルパー関数を書いて呼び出しています。保守性・移植性を完全に犠牲にしていますが、LuaJIT18という前例があります。
その他、メソッドキャッシュや定数キャッシュなど、高速化の仕組みは一通り備えています。
JITコンパイラの実装
monorubyのJITコンパイラはメソッド単位・ループ単位の2つのモードを持ち、メソッドに関してはメソッド自身がカウンタを持っており、一定回数呼ばれるとJITコンパイラを起動して自分自身をコンパイルし、以後はJITコードへ飛ぶようにエントリを書き換えます。ループはインタプリタが回数をカウントして一定回数で同様にJITコンパイルを行い、そのままJITコードに遷移します。
以下、実装上の工夫をいくつか挙げていきます。
Floatクラスの四則演算の高速化
CRubyのインタプリタではFloatクラス(浮動小数点数クラス)の演算にあたって
- 両辺のRubyオブジェクトをスタックからロードしてf64に変換(unboxing)
- f64の演算
- 結果をRubyオブジェクトに変換してスタックへ戻す(boxing)
という操作が必要であり、本来の演算(2)よりも(1)(3)のオーバーヘッドが相対的に大きく、高速化の余地が大きいと考えました。monorubyのJITコンパイラはプロファイル情報からf64(Cのdouble)として計算に使用されるレジスタをCPUの浮動小数点数レジスタ(xmmレジスタ)に割り当て、簡易な制御フロー解析を行って不要な(1)(3)を削除するようにしました。通常コンパイラが行うレジスタ割り付けと基本的には同じですが、1つの変数をRubyオブジェクトとして使用する場合とf64として使用する場合の両方があるので、変換コストが最小限になるように工夫しています。
結果として、冒頭のベンチマークで挙げたように浮動小数点演算を繰り返し実行するso_mandelbrotやso_nbody、app_aobenchで顕著な高速化が得られています19。
インスタンス変数アクセスの最適化
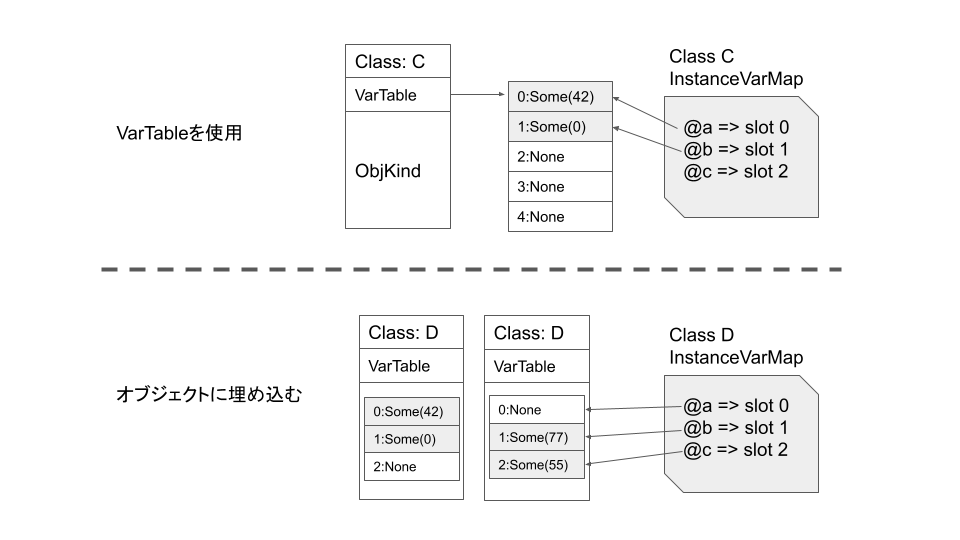
Rubyのインスタンス変数は、オブジェクトに紐づけられた名前の付いたプロパティ(値はRubyオブジェクト)です。素朴にハッシュマップなどで実装すると遅いので、monorubyではオブジェクトには可変長配列(下図のVarTable)を持たせて値を格納しています。一方、クラス情報の構造体にインスタンス変数名とインデックスの対応マップ(下図のInstanceVarMap)を持たせてあります。これだとInstanceVarMapを変数名をキーにして引いてインデックスを得て、さらにVarTableにインデックスでアクセスすることになるので二度手間ですが、インデックスをキャッシュしておくことで2回目以降は高速になります。(以上は下図の上半分、クラスCの説明)
さらに、Objectクラスの派生クラスではRubyオブジェクトのメモリ表現(8バイト)に空きがあるので、この中にインスタンス変数の値を埋め込んでしまうことができます。これを用いるとさらにアクセスが高速化する上に可変長配列をアロケートする必要がなくなるのと、JITコードではアセンブリで直書き(mov命令一発)できるので超高速になります20。(下図の下半分、クラスD)
以下、ベンチマークです。
| 3.2.0-preview3 | --yjit | monoruby | monoruby --no-jit | |
|---|---|---|---|---|
| vm_ivar_get | 11.958 | 26.649 | 67.922 | 12.395 |
| vm_ivar_set | 123.794M | 118.631M | 1.530G | 62.200M |
| vm_attr_ivar | 57.361M | 57.916M | 68.746M | 48.746M |
| vm_attr_ivar_set | 51.297M | 50.350M | 305.655M | 36.901M |
小さなメソッドのインライン化
数命令の機械語で済むような単純な計算のみを行うメソッドは直接JITコードの中に埋め込んでしまうことで高速化を図っています。メソッド呼び出し・復帰のコストを省けるのが大きいですが、特に浮動小数点数関係の単純な演算メソッド(整数から浮動小数点数への変換Integer#to_fや機械語1命令で計算できる平方根計算Math.#sqrtなど)ではRubyオブジェクトとf64の変換も削減できて大きな高速化が得られます。Math.#cosなど、正味の処理自体に一定時間かかる演算では相対的に恩恵は少なくなります。
| 3.2.0-preview3 | --yjit | monoruby | monoruby --no-jit | |
|---|---|---|---|---|
| to_f | 13.813M | 13.805M | 320.955M | 18.606M |
| math_sqrt | 9.860M | 9.670M | 51.387M | 11.530M |
| math_sin | 5.902M | 6.175M | 14.793M | 6.148M |
| math_cos | 6.068M | 6.047M | 16.028M | 6.228M |
プロファイルのない命令のJITコンパイル
インタプリタが実行時にプロファイルを収集するわけですが、JITコンパイラが起動した時点で全ての命令が実行済み(=プロファイル収集済み)とは限りません。プロファイルのない状態でコンパイルすることは一応可能ですが、最適化の程度は当然劣ります。
例えばフィボナッチ関数のスクリプト
def fib n
if n < 3
1
else
fib(n-1) + fib(n-2) # <- ココ
end
end
を考えてみると、5行目の1個目のfib()で自分自身が再帰的に呼ばれるため、n<3になるまでは2個目のfib()は実行されず、プロファイルも収集されません。この状態でコンパイルすると遅いコードが生成されます。もっと一般的なケースでは条件分岐でほとんど分岐しない枝でこういう状態が起きます。
monorubyのJITコンパイラでは、プロファイルのないバイトコードに対してはカウンタとともにインタプリタへ戻るコードを生成しておき21、一定回数以上通過した時点で(つまりプロファイルが収集された時点で)メソッドないしループ全体を再度コンパイルするようになっています。次回fib()が呼ばれる時には、より最適化された新しいJITコードが呼ばれるわけです。
今後の展望
ここまでで力尽きたので、Rubyの言語機能を充実させたい、とかフロー解析をもっとちゃんとしたものにして高度な最適化を適用できるようにしたい、とか呟きつつ、メリークリスマス。みなさま良いお年を。
-
Rubyが言語の名前でCRubyはCで書かれたRubyの処理系実装の一つにして標準実装でもある。正式名称ではない気がするが、本稿では具体的な処理系を指すときはCRubyと呼ぶ。 ↩
-
プログラム実行時に、必要に応じて必要な部分を機械語にコンパイルする形式。 ↩
-
他のアーキは永遠にサポートできる気がしない… ↩
-
ソースコードから処理系が生成する、インタプリタが解釈実行するための中間コード。雰囲気としては仮想的なCPUが実行する仮想的な機械語的なもの。「仮想的なCPU」は一般に仮想マシン、VMなどと呼ばれる。Java仮想マシン用の中間コードがバイトコードと呼ばれていたので、他の言語でも仮想マシン形式インタプリタ用の中間コードを慣用的にバイトコードと呼んでいる(ようである)。 ↩
-
あくまで一般論であり、様々な実装があるので念のため。 ↩
-
ここで「定数の値は実行しなくてもわかるんじゃないのか?」という疑問を持つのが自然であるが、Rubyの定数は実行時に書き換え可能、しかも値を取得するには名前と値のマップのリンクを探索する必要がありコストが高い。なので前回得た値とタイムスタンプをセットにしてキャッシュしておくことで高速化する。 ↩
-
抽象実行 abstract interpretation とかを使って静的に頑張って解析する方法もある。@miura1729 さんのRuby to C translator MMCとか Julia (https://github.com/JuliaLang/julia/blob/master/base/compiler/types.jl) とか。 ↩
-
例えばメソッドが再定義された、定数の値が書き換えられた、など。 ↩
-
何がバイトコードなのかよく分からなくなってくるが、ネット上の風説では本家Javaバイトコードはオペコードが1バイトなのでバイトコードと呼ばれたらしい。monorubyもオペコードは1バイトなので問題なし。 ↩
-
これは手で作った機械語コードから読み取る/書き込むのが簡単かつ高速になるので良い方法ではあるが、マルチスレッド化すると色々と問題が生じる予感がする。難しいことは考えないことにする。 ↩
-
Rubyオブジェクトを格納する8バイトのスタックフレーム内の領域、ということなのだがCPUのレジスタと一緒になってややこしい。ちなみに「スタック」という言葉もRubyのスタックとCPUが使うスタックが混ざってややこしい。 ↩
-
CRubyでは謎の黒魔術を使って実装されている。単純化される、と断言しているがmonorubyではraiseはあるがまだrescueできないし、Fiberもまだ実装していないので本当かどうかは未検証。 ↩
-
実際には後述するCPUの浮動小数点数レジスタに移動されている変数があるので、これらをスタックに書き戻す必要がある。 ↩
-
Rubyではオブジェクト
xのインスタンス変数@varへのアクセスをx.var = 42のように書ける。(クラス定義内でアクセスを許可する必要がある) ↩ -
下記の@κeenさんの記事がわかりやすいです。
https://keens.github.io/blog/2015/05/29/daiikkyuuraberuwomotanaigengoniokerudirect_threaded_vmnojissou/ ↩ -
CRubyでは(使える環境では)GCC拡張を使っている。 ↩
-
https://luajit.org/
LuaJITは様々なCPU・OS上で動くことになっているが、インタプリタは作者が一人でCPUごとにアセンブリで書き下している。頭がおかしい。 ↩ -
Rubyの浮動小数点数演算が速くなって嬉しい人がどのくらいいるかは不明。そういうことは考えない。 ↩
-
CRubyにも同様の最適化がなされており、さらに最近Shapeという仕組みが入った。 ↩
-
monorubyは一応 method JITを謳っているが、こういう所は tracing JITっぽい。YJITもまだ一度も分岐していない枝ではコンパイルを止めてスタブコードだけを仕込んでおいて、分岐した時点でプロファイルを収集しつつその先のコンパイルを行うようになっている。 ↩