*こちらはオプトテクノロジーズの社内勉強会資料になります
自己紹介
株式会社オプト シニアエンジニア @sisisin
ということで今回はScalaのCIを速くした話をします。
もはや自分が何屋さんなのか分からなくなってきた。
tl;dr
- feature 23min -> 13min、master 60min -> 24min(最短)
- CIのステップを
1コンテナでコンパイルし結果をキャッシュとして保存→コンパイル結果をリストアして複数コンテナでテストという形にした - 複数コンテナで並列テストの協調動作させる処理は複雑なのでメンテしやすいコードにして簡単にチューニング・スケール出来るようにした
- CircleCI便利!
目次
- CircleCI2.0事前知識
- 対応したプロダクトについての説明
- もともとやっていたこと
- 実施したこと
- 実施した結果
- 実際の設定の紹介
- おわりに
CircleCI2.0事前知識
- workflow
- ドキュメント: https://circleci.com/docs/2.0/workflows/
- CI上でjob同士の実行順や依存関係を定義したもので、これがCI実行の統括的な役割を担う(jobについては後述)
- job同士は直列/並列に実施が可能
- CI実行の1単位思ってもらえれば大体良い
- jobs
- ドキュメント: https://circleci.com/docs/2.0/jobs-steps/
- jobsはstepsの集合(stepについては後述)
- jobsに定義されているjobはCI実行時に1つ以上のコンテナが割り当てられる
- paralellism
- ドキュメント: https://circleci.com/docs/2.0/parallelism-faster-jobs/
- job実行の並列度を指定するパラメータ
- paralellismの値の分だけコンテナが立ち上がり、各々がjobに記述されているstepsを実行する
- それぞれのコンテナで実行されるstepsは当然同じもの
- そのため、stepsで実行されるテストコマンド側で実行するテストの振り分けを行う必要がある
- workflowとの使い分けとしては、同じことをパラメータだけ変えて実施するならこっちを利用、で良い
- 振り分けのためには環境変数
CIRCLE_NODE_INDEXを利用する
- steps
- ドキュメント: jobsのものと同じ
- 実行可能なコマンドの集合
- steps書けるコマンドの代表例
- shellのcommandが記述できる
run - キャッシュを扱う
save_cache,restore_cache
- shellのcommandが記述できる
- cache
- ドキュメント: https://circleci.com/docs/2.0/caching/
- とあるjobで他のjobの結果を扱いたいときや、依存ライブラリの取得結果をCI間で共有するために使えるキャッシュ
- save_cache
- キャッシュのキーと保存対象のディレクトリパスを指定してキャッシュを保存するコマンド
- keyにはCircleCI側で提供されているメタ変数を利用することが出来る
- 指定したキーに既にキャッシュがある場合はこのstepは飛ばされる
- キー指定の仕方が悪いと古いキャッシュを使い続けるということに
- restore_cache
- 指定したキーのキャッシュを探してきて、ヒットしたら保存したディレクトリをまるっと復元するコマンド
- キャッシュのキーは複数指定が可能で、上から順に見つからなければ次のキーのキャッシュがないかを探してくれる
対応したプロダクトについての説明
- sbtのマルチプロジェクト(プロジェクト数:28)
- BigQueryやRedshiftを使ったテストが含まれていて、これらが非常に重い
- BigQueryを使ったテスト:45分程度
- Redshiftを使ったテスト:20分程度
- 別にそれ以外のテストもまあまあ重い
- 直列に実行するとテストだけで大体25分程度
- 毎回全件テストをすると重すぎるので、featureブランチとmasterブランチでテスト対象を分けている
- BigQuery、Redshiftのテストはfeatureブランチではテストしていない
- masterブランチではCIでコンパイルした結果を
sbt assemblyして、リリース用ArtifactとしてS3へ配置している- 全パッケージに対して直列で実施すると45分弱(!)かかる
- ビルド対象プロジェクト数が20あり、バッチ系の
sbt assemblyが約100秒、webサーバ(PlayFramework使用)のsbt universal:packageBinが約400秒かかるのでしょうがないといえばしょうがない - ここでのビルド結果はそのまま本番リリースされるので、事故は起こってほしくない部分
もともとやっていたこと
- ~/.ivy2,~/.sbtのキャッシュ
- 依存ライブラリの解決はキャッシュ利用して時短していた
- jobの設定のparalellismを使った並列化
- jobをわけたりはせず、CIで実行すべき全てのステップが同時並行に走る形で実現
- フォーマットチェック,テスト,artifactの生成とアップロードという全工程を全てのコンテナが実行していた
- stepsは全部で16stepあって中々ヘビー
- CIRCLE_NODE_INDEXによって場合分けしてコンパイル対象・テスト対象・Artifactのアップロード対象を分岐
- コンパイル・テストなど全てのステップを上手く配分しようと頑張る感じ
- 基本的には各CIコンテナで
sbt [project1]/test [project2]/test ...のようなコマンドを発行- 特に重いテストは
testOnlyで対応
- 特に重いテストは
- 見るからに改善の余地がありそう(後述の図参照のこと)
- 見るからに改善の余地がありそうだけど、並列化のためのテストのランナースクリプトが長大(350行程度)なbashのスクリプトで書かれていて、中々手が入ってこなかった
- Artifact生成・featureブランチのテスト・masterブランチのテストがそれぞれあり、BigQueryやRedshiftのテスト時には前処理・後処理が必要なので意外と複雑でやむを得ない面もありつつ
- jobをわけたりはせず、CIで実行すべき全てのステップが同時並行に走る形で実現
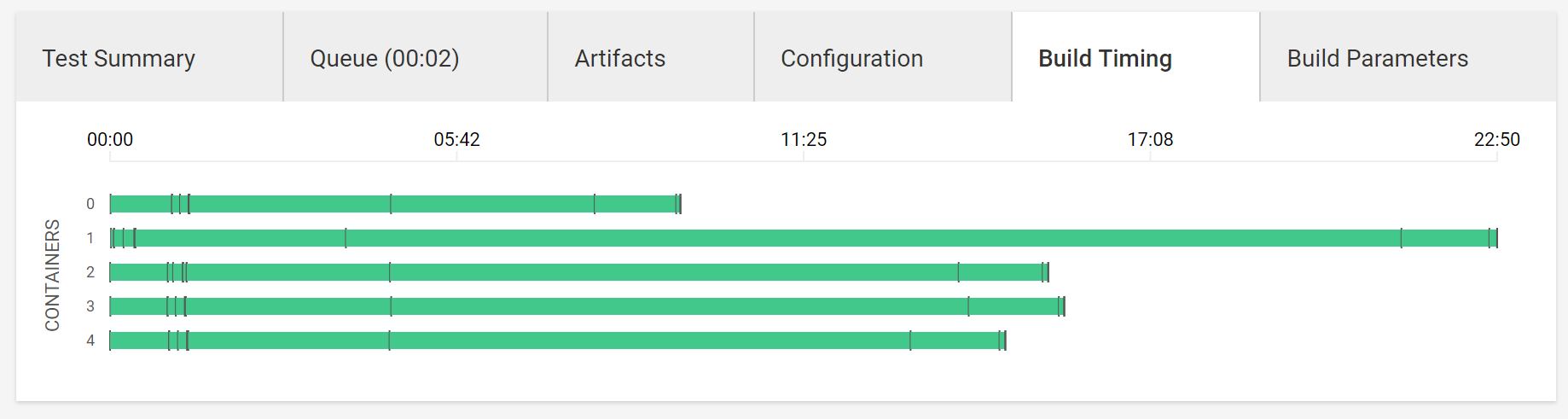
「コンパイル・テストなど全てのステップを上手く配分しようと頑張る感じ」の図(master)
全体像
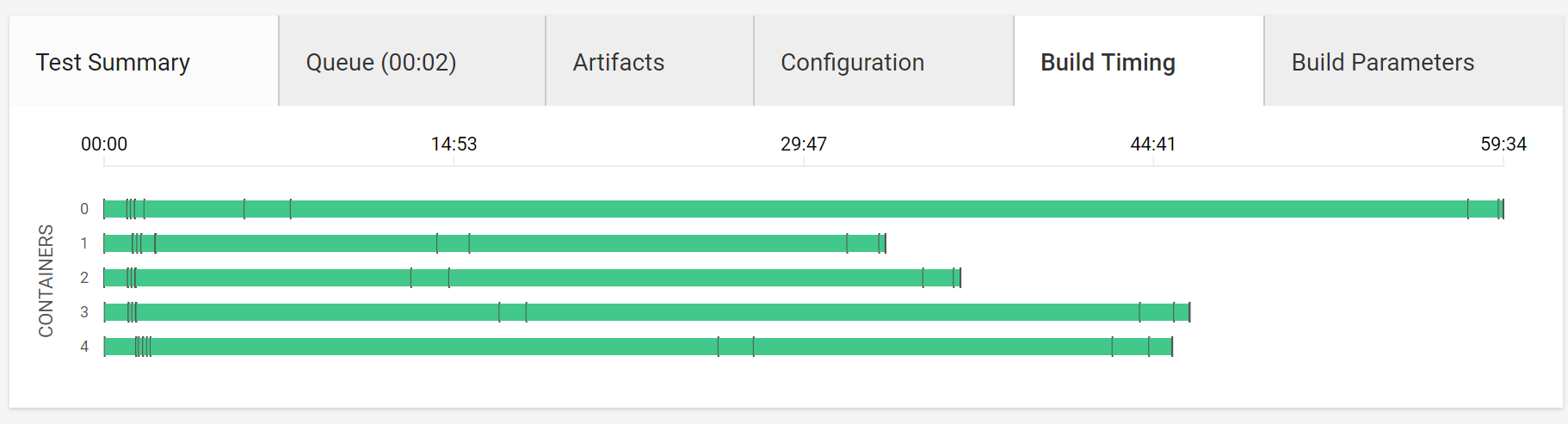
Artifactのビルド・アップロード
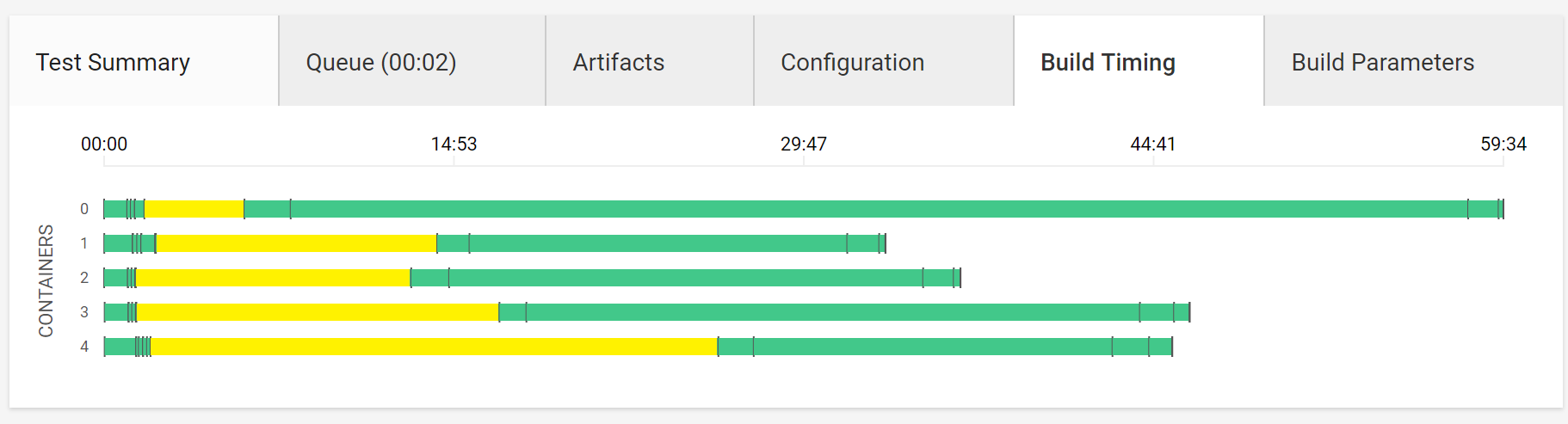
フォーマットチェック
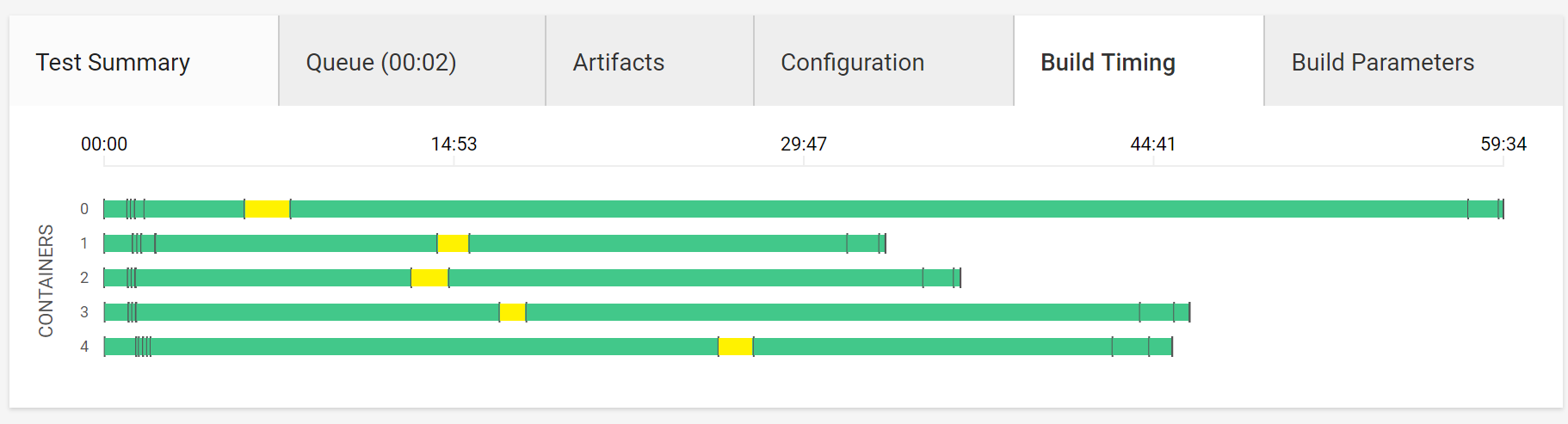
テスト
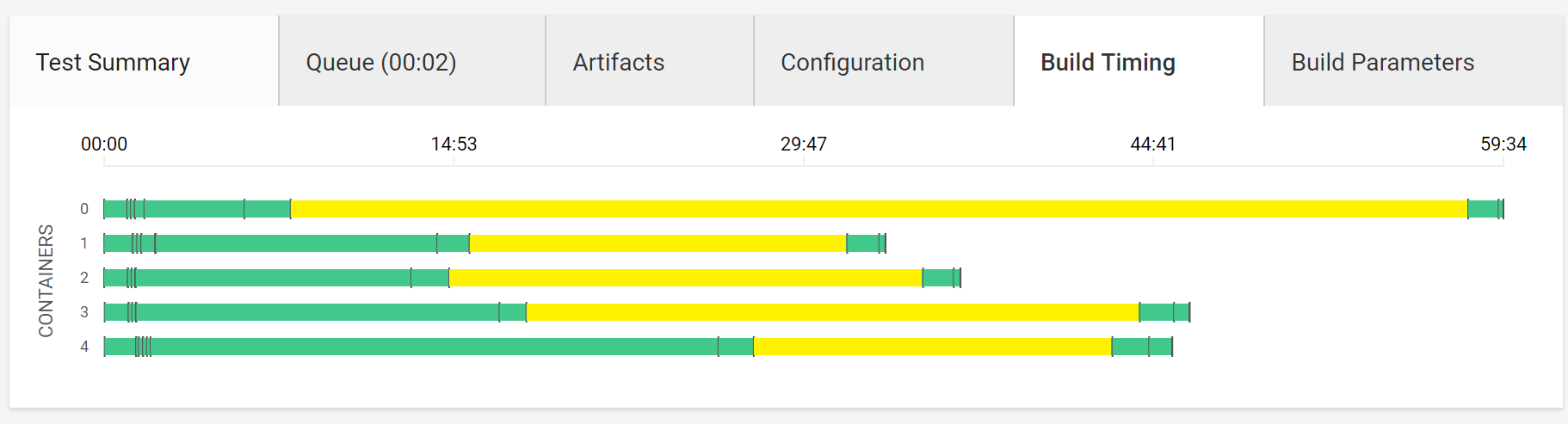
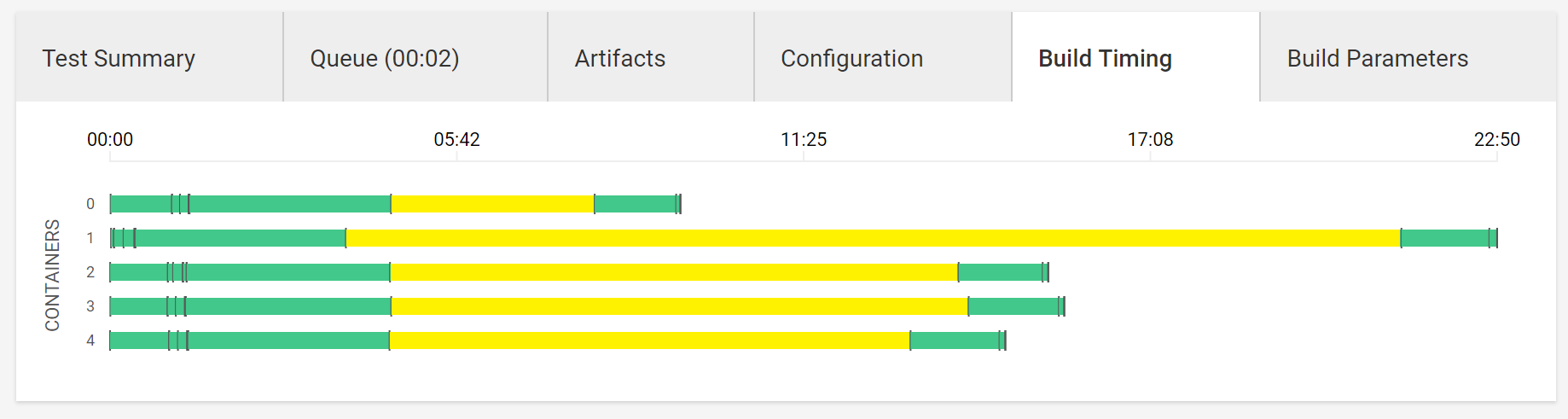
「コンパイル・テストなど全てのステップを上手く配分しようと頑張る感じ」の図(feature)
全体像
フォーマットチェック
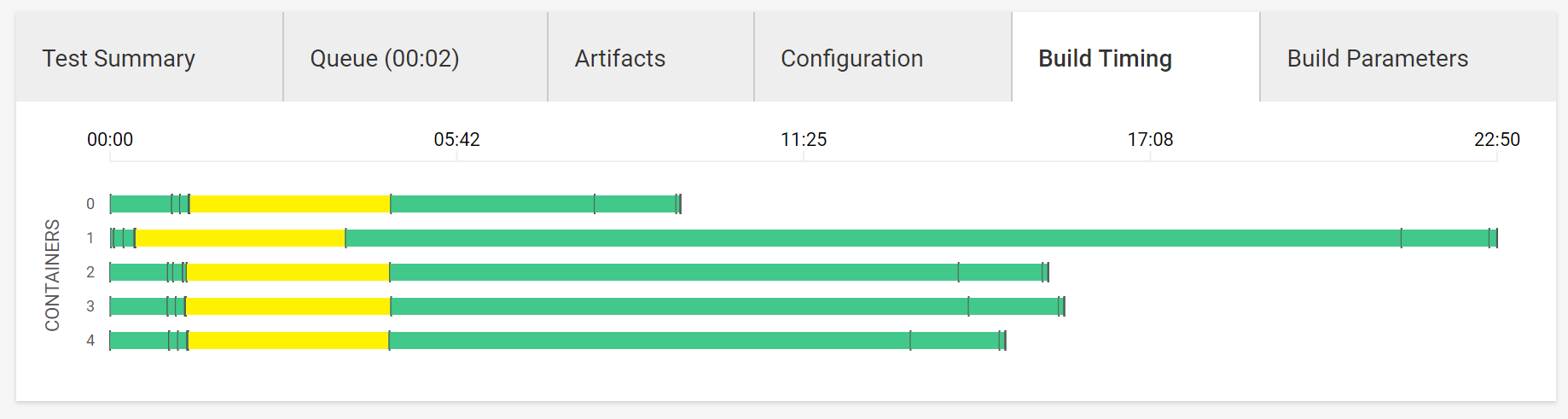
テスト
ここまでの前提条件から見えてくる実現したい(出来そうな)こと
- なんか一回やれば良さそうなことを何度もやってそうなので、必要十分なだけやるようにしたい
- jobが1つなので、各種stepが実行されるコンパイルを全てのコンテナが実施してたり、フォーマットチェックを全部のコンテナでやってたり
- テストのコンテナ割り当てをサクッと調整して最適化したい
- 現状でももっと最適化したい
- というかスケールしたいと思った時に簡単に出来るようにしたい
- (ランナースクリプトをメンタナブルにしたい)
ではやっていきまっしょい
実施したこと
- workflowによる分岐で、各stepを必要十分なだけ実施するようにした
- 「単一コンテナでコンパイル→コンパイル結果を利用して並列で後続処理」ということをArtifact生成・テストの両方で実施した
- キャッシュ対象は
projects/target,target,[project]/target
- キャッシュ対象は
- フォーマットチェックはどっかで一回やれば十分なのでコンパイルの時についでにやるようにした(別のjobにしても構わないが、コンテナ立ち上げのオーバーヘッドを鑑みると一緒で良さそうと判断)
- 「単一コンテナでコンパイル→コンパイル結果を利用して並列で後続処理」ということをArtifact生成・テストの両方で実施した
- jobの設定のparalellismを使った並列化部分のリファクタ・最適化
- コンテナ割り当てをやりやすい実装に修正した
- bashのスクリプトを500行ぐらいのJavaScriptでリプレース(!?!?)
- 微妙にチームがざわつきましたが何とかマージされました(てへぺろ(その節はお騒がせしました
- Artifact生成・テスト実施のコンテナ割り当てを最適化
- switch文の行を並び替えるだけで出来るようにしたのでちょちょいのちょいです
- コンテナ割り当てをやりやすい実装に修正した
*おまけ
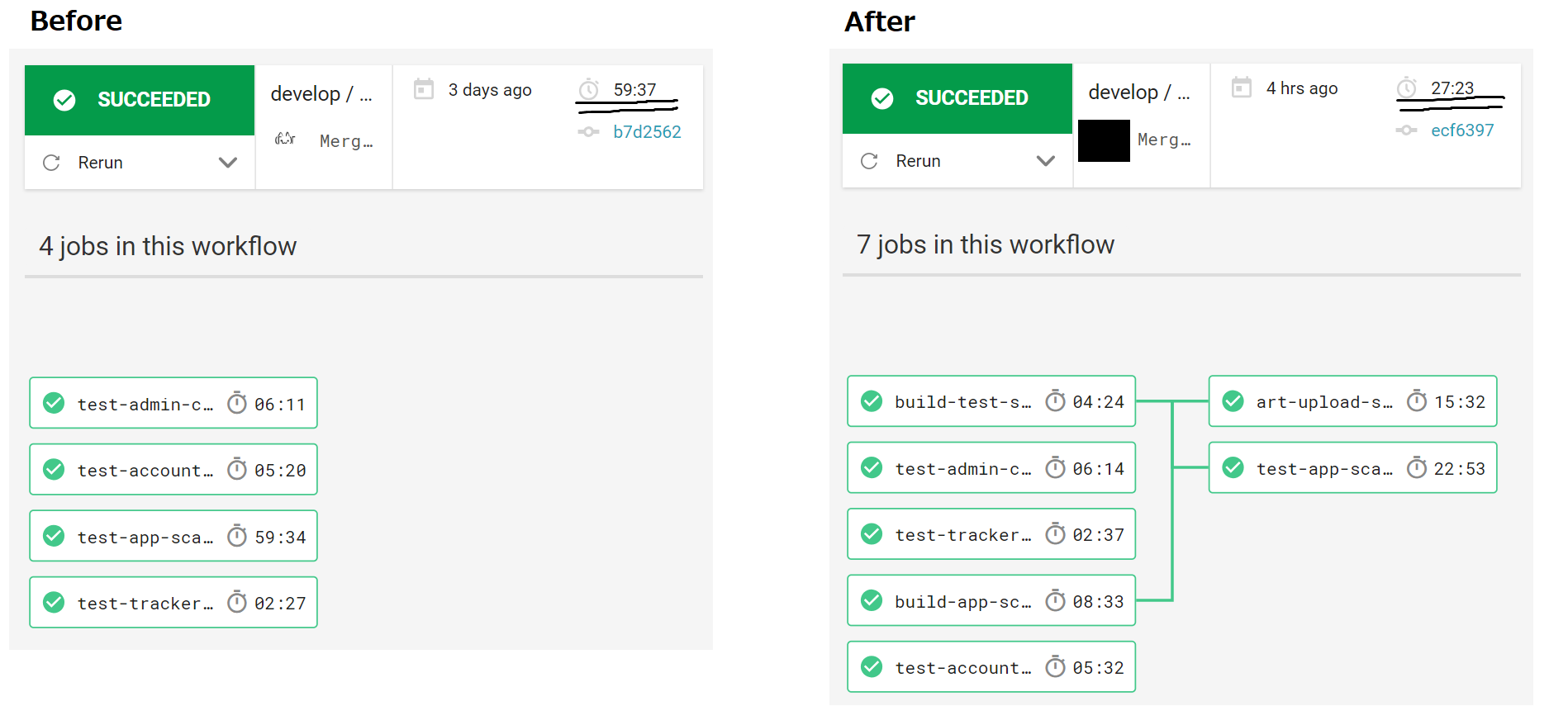
実施した結果
- CI速くなった
- feature 23min -> 13min
- master 60min -> 24min(最大)
- 図は後ほど。
- 簡単にスケールさせられるようになった
- このファイル弄ればOK、この分岐を調整すればOKが自明になったので最高
- ためしにmasterで並列度を5→8にしたら更に4分程度速くなった
- が、今はCircleCIのコンテナ数の契約的に調子乗って増やしすぎるとCI詰まるので一旦5のまま。。。
実施した結果
- CI設定の記載されているconfig.ymlが長大になった
- まあやる事増えたのでしょうがない・・・
- コンパイルjobでは10step,Artifactアップロードjobでは4step,テストjobでは10stepと当初の16stepから全体のstep数は増えたものの、各jobで何をやるかは明確になったので多分メンテはしやすくなってるはず
- ランナースクリプトがjsになった
- 設定をjsのオブジェクトで持てるようになったので表現力は増した
- 良いかどうかは諸説ある
けど、一定以上複雑な処理をbashで書いてもメンテしにくいと判断しての決断
workflow画面(masterブランチ)
テスト用コンパイル(masterブランチ)
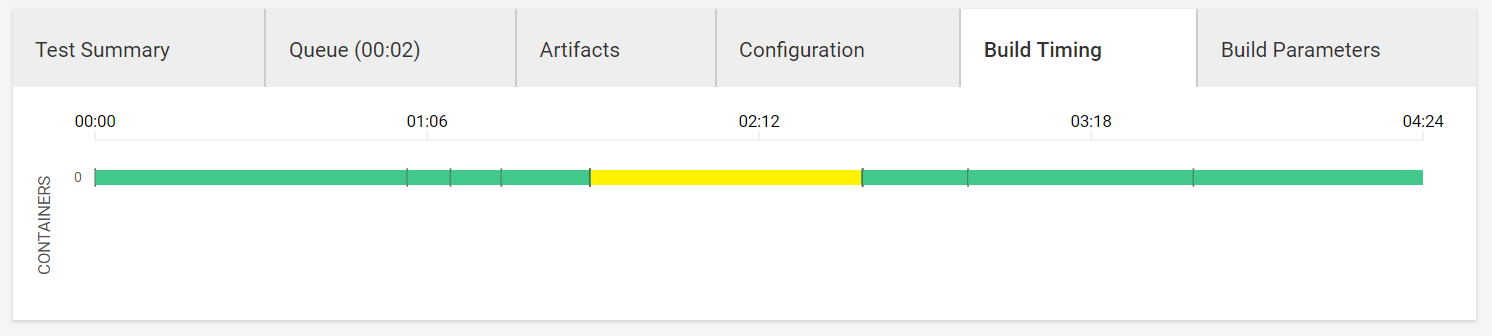
コンパイル以外はコンテナのSpin upやキャッシュ処理などです。コンパイル時間の方が短い!
コンパイル自体の時間はコンパイルキャッシュのキャッシュヒット有りで1分程度
テスト(masterブランチ)
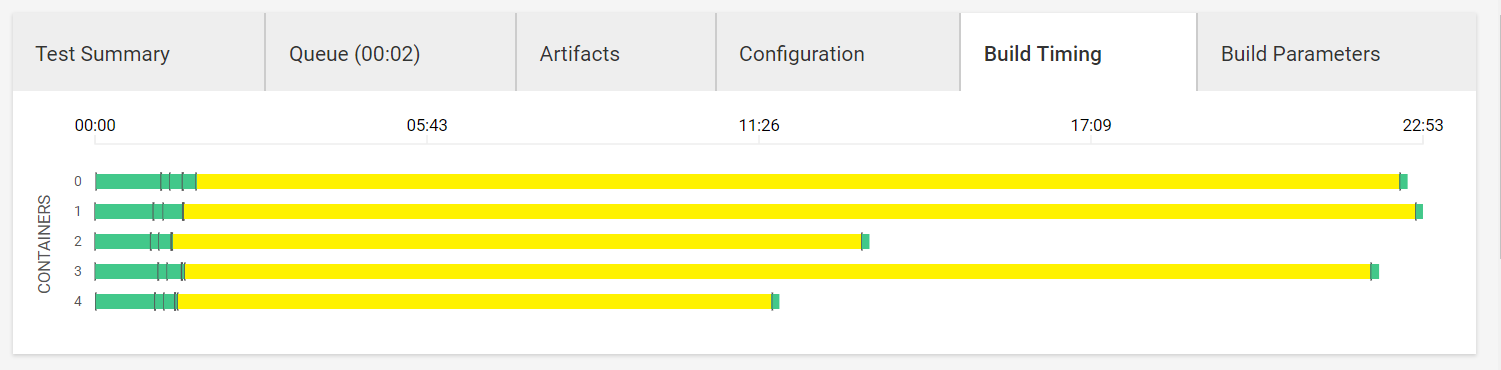
ポイント・工夫点
-
sbt compileしたあとにsbt coverage test:compileしちゃうとコンパイルキャッシュが効かない(sbt-coverageを利用している場合)-
sbt coverageをしているとカバレッジ取得のためのバイナリになるため、ただsbt compileしたものと別バイナリ扱いになる - Artifact生成とテストで分けたのはこれが理由
-
- cache周りアレコレ
- masterの場合はキャッシュのリストアは実施するが、
sbt cleanをコンパイル前に実施している- リリース用バイナリは差分コンパイルではなく綺麗な状態でコンパイルされたものにしたいため
- 指定したキャッシュヒット条件
- コンパイルjob
-
~/.ivy2,~/.sbtといった外部ライブラリについては最大限キャッシュヒットさせる -
依存ライブラリが一致しているならコンパイルキャッシュをヒットさせる- これによって、とあるfeatureブランチで作ったコンパイル結果を別のfeatureブランチで使い回せたり、同じブランチで新しいコミットでCIを回すときにも使い回せる
-
- テスト・Artifact生成job
-
同一リビジョンのコンパイルのjobで作成したキャッシュをリストアする- CIの度にコンパイルキャッシュが都度作り直しになるので、このjobではコンパイルが走ることはなくなる
-
- コンパイルjob
- masterの場合はキャッシュのリストアは実施するが、
実際の設定の紹介(一部改変したものを抜粋)
コンパイルjobのキャッシュ設定
save-app-cache-paths: &save-app-cache-paths # save_cacheの保存対象は長くなるので別定義
paths:
- ~/.ivy2/
- ~/.sbt/
- console1/target
- console2/target
- batch1/target
- batch2/target
- common/target
- project/target
- target
jobs:
build-app-scala:
# 前略
- restore_cache:
name: Restore Dependency Cache
keys: # ライブラリキャッシュのキャッシュヒットの優先度としては、ブランチ名・依存のチェックサムが一致しているものが最優先、時点でブランチ名が一致しているもの・・・と続く
- scala-app-dep-v1-{{ .Branch }}-{{ checksum "build.sbt" }}-{{ checksum "project/Dependencies.scala" }}-{{ checksum "project/Common.scala" }}-{{ checksum "project/plugins.sbt" }}
- scala-app-dep-v1-{{ .Branch }}
- scala-app-dep-v1-master
- scala-app-dep-v1-
- restore_cache:
name: Restore Compile Cache
keys: # コンパイルキャッシュは依存のチェックサムが一致かつブランチ名が一致したものか、依存のチェックサムが一致したものだけをヒットさせる
- scala-app-compile-v1-{{ checksum "build.sbt" }}-{{ checksum "project/Dependencies.scala" }}-{{ checksum "project/Common.scala" }}-{{ checksum "project/plugins.sbt" }}-{{ .Branch }}
- scala-app-compile-v1-{{ checksum "build.sbt" }}-{{ checksum "project/Dependencies.scala" }}-{{ checksum "project/Common.scala" }}-{{ checksum "project/plugins.sbt" }}
# 中略
- save_cache:
name: Save Dependency Cache # これはライブラリキャッシュ
key: scala-app-dep-v1-{{ .Branch }}-{{ checksum "build.sbt" }}-{{ checksum "project/Dependencies.scala" }}-{{ checksum "project/Common.scala" }}-{{ checksum "project/plugins.sbt" }}
paths:
- ~/.ivy2/
- ~/.sbt/
- save_cache:
name: Save Compile Cache # コンパイルキャッシュ
key: scala-app-compile-v1-{{ checksum "build.sbt" }}-{{ checksum "project/Dependencies.scala" }}-{{ checksum "project/Common.scala" }}-{{ checksum "project/plugins.sbt" }}-{{ .Branch }}
<<: *save-app-cache-paths
- save_cache: # 次のステップ(Artifact生成・テスト)で使用するためのキャッシュ
name: Save Compile Cache For Next Step
key: scala-app-compile-v1-{{ .Revision }}
<<: *save-app-cache-paths
テスト・Artifact生成jobのキャッシュ設定
jobs:
# 中略
test-app-scala:
# 中略
- restore_cache:
name: Restore Compile Cache From Before Step
keys: # リビジョンごとに新しい結果を使うので、再コンパイルは走らない!
- scala-app-compile-v1-{{ .Revision }}
# 後略
おわりに
えいやでやっちゃったけどCircleCI2.0の知見が得られたので良かったかなと思ってます
これだけでかいScalaプロダクトでもCIは頑張れば速くできるんだなあと感じられました
現状だとコンテナ数の制限がある関係で並列度を絞ってますが、もっとスケールさせてみたさがあるのでまた頑張りたい気持ちです
この記事を見た人のScalaのCI改善の一助になれればこれ幸いです