What I would like to do (やりたいこと)
- Amazon Athenaを使う
- データはPythonで生成
- なるべく安く済ませる
- Parquet形式を試す
- Gzip圧縮も併用したい
Amazon Athena pricing (料金)
ここに書いてあるのですが、
ファイルを圧縮し、さらに Apache Parquet などの列形式に変換した場合
この場合、圧縮や形式変換をしない場合と比較すると、うまくいけば料金が1/9程度まで減らせるようです!!
これは見のがせないよね....?(*´﹃`*)
料金が減るということは、それだけAWS側のリソース(電気)を食わない、つまり、環境にも優しいといえるはず。多分...(゚Д゚;(゚Д゚;
How to do
1. Use Parquet formatted file (Parquet形式のファイルを使う)
1-1. Source of Python
まずは単なるParquet形式から行きましょう
import numpy as np
import pyarrow as pa
import pyarrow.parquet as pq
import pandas as pd
two_dimension_array: np.array = np.arange(12).reshape(4, 3)
df: pd.DataFrame = pd.DataFrame(two_dimension_array)
df.columns = ['one', 'two', 'three']
df.head()
one two three
0 0 1 2
1 3 4 5
2 6 7 8
3 9 10 11
今回扱うデータはこんな感じです。
これをParquet形式のファイルとして出力します。
table: pa.Table = pa.Table.from_pandas(df)
pq.write_table(table, './sample_2d_array.parquet', compression='snappy')
これで、python実行ファイルと同階層のディレクトリにsample_2d_array.parquetという名前のファイルがあるはずです。
1-2. Note: What is compression?
compressionは、圧縮形式を表すようです。
ちなみに、snappyはデフォルト値。
helpを使えばそれがわかります。
help(pq.write_table)
Help on function write_table in module pyarrow.parquet:
write_table(table, where, row_group_size=None, version='1.0', use_dictionary=True, compression='snappy', write_statistics=True, use_deprecated_int96_timestamps=None, coerce_timestamps=None, allow_truncated_timestamps=False, data_page_size=None, flavor=None, filesystem=None, compression_level=None, use_byte_stream_split=False, data_page_version='1.0', use_compliant_nested_type=False, **kwargs)
Write a Table to Parquet format.
Parameters
----------
table : pyarrow.Table
...以下略
なので、snappyという方式で圧縮するなら、実際はcompressionを指定しなくても大丈夫です。
1-3. Upload Parquet file to S3
さて、今度は、作成したParquet形式のファイルをS3にアップロードして、Athenaから読み込めるようにします。
ここからバケットを作成しますが、細かい作成方法は他の記事でご確認ください₍₍ (ง ˘ω˘ )ว ⁾⁾スヤッスヤッ
作ったバケットの画面を開き、お好みのフォルダを作成したら、Parquetファイルをアップロードします。
アップロードの方法も他の記事を見てね...(´;ω;`)
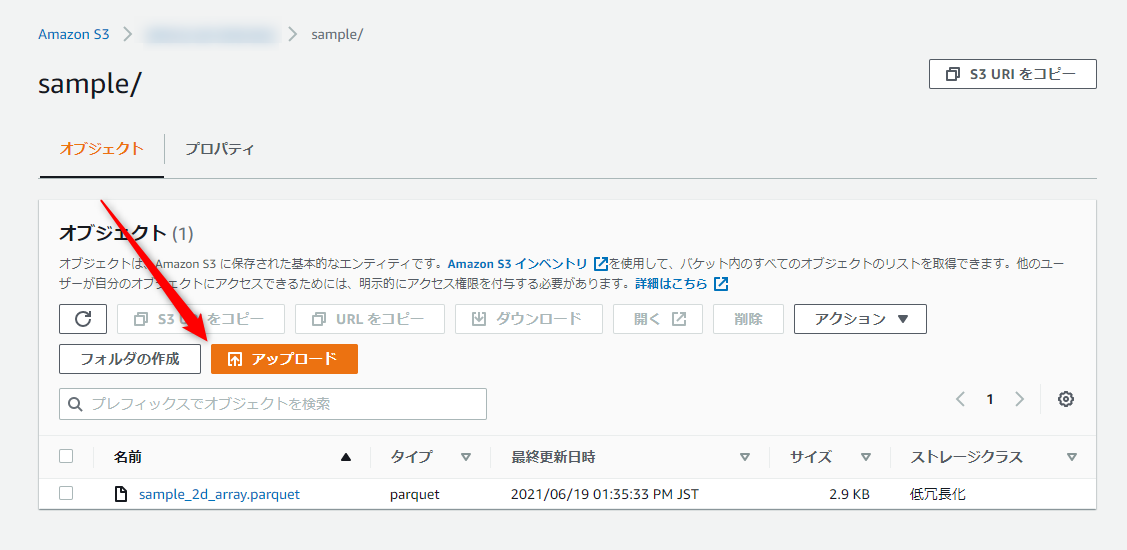
1-3 で大事なのは以下の部分ですね。
アップロードしたファイルのパスを確認すること。
- まずアップロードしたファイルの名前をクリックして...
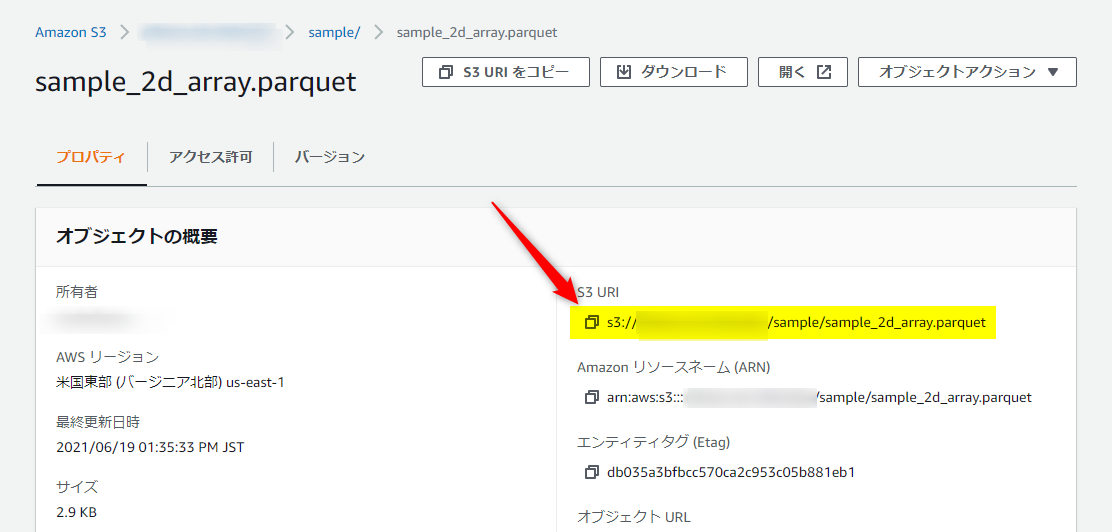
- S3 URI をコピーしておこう!
1-4. Create DB and Table on Athena
今度はS3を離れて、ついにAthenaの操作を行います。
Athenaの画面を開くと、最初はデータベースがありません。
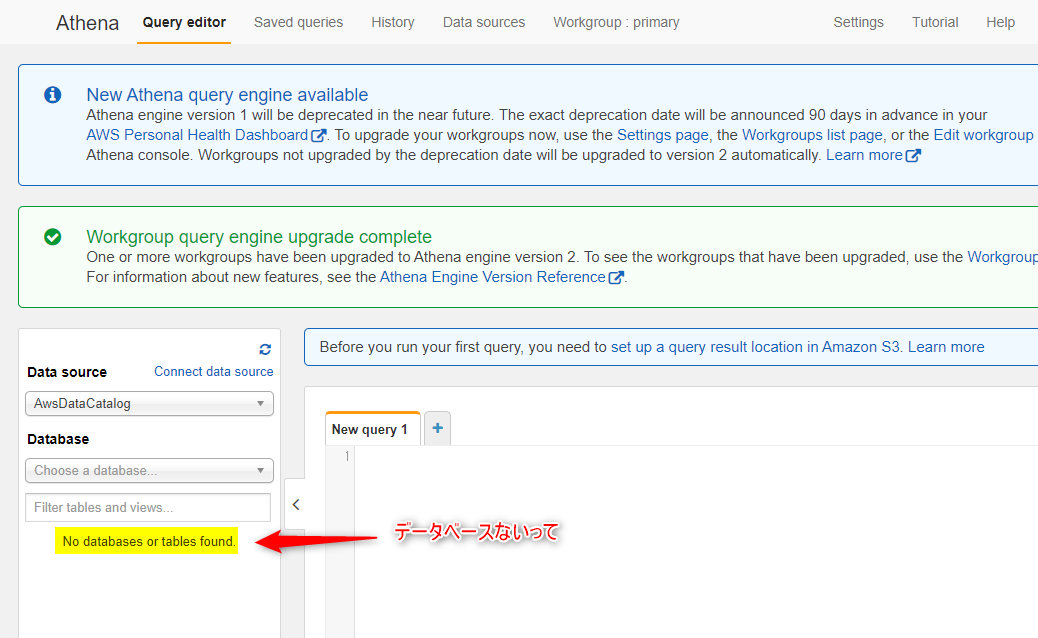
以下の公式サイトの通り、データベースをまず作ります。
CREATE DATABASE myDataBaseで作成できます。
...が、そのまま作成しようとすると、No output location provided. An output location is required either through the Workgroup result configuration setting or as an API input.というエラーが発生します。
以下のとおり。
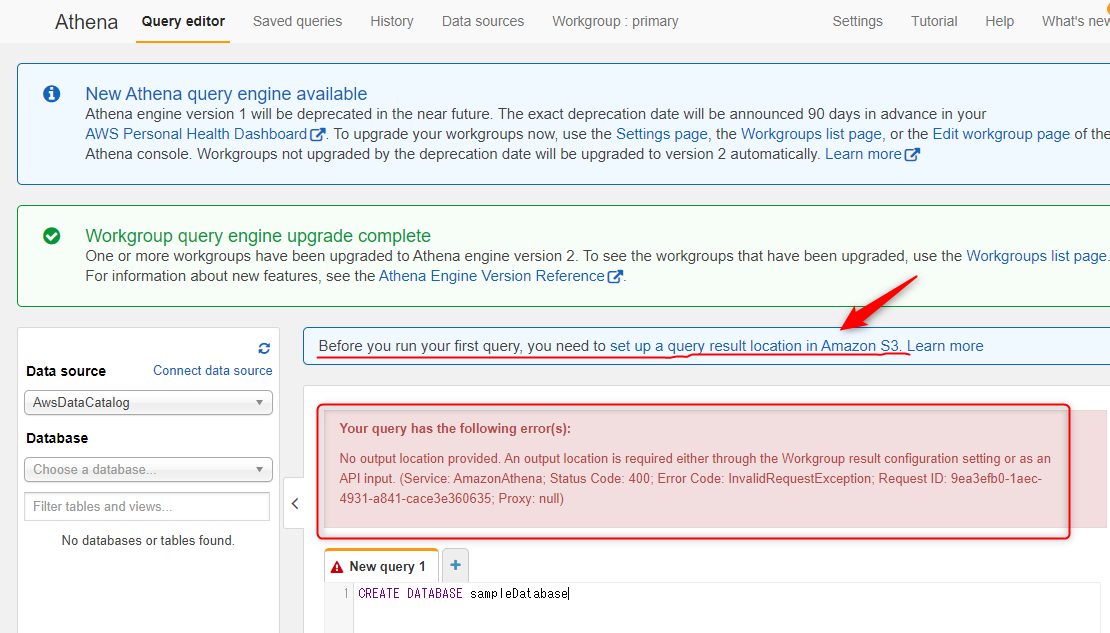
なので、その前に、赤色の下線を引いたところをクリックして、Queryの実行結果を配置するS3のフォルダを指定しましょう。
クリックするとこんなモーダルウィンドウが表示されるので入力します。
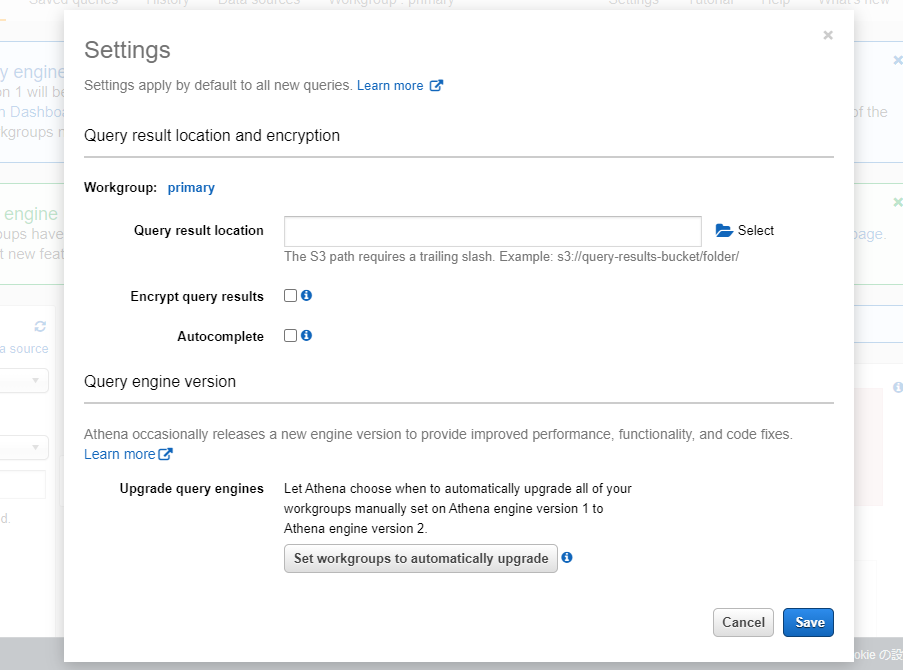
場所としては、Parquetファイルを設置したフォルダの近くで、かつ、別のフォルダがよさそう。
Query結果保存先を指定出来たら、今度こそAthena上にDBを作成します。
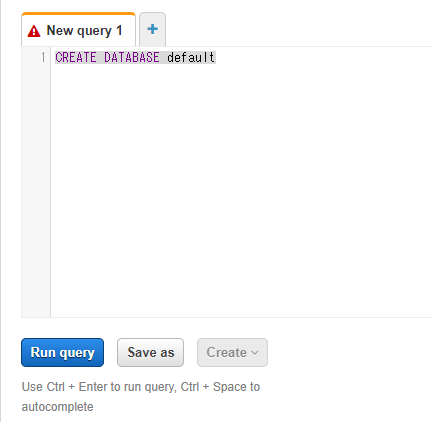
"Run query"をクリックするとデータベースができる。
今度はTableを作ります。
"Database"の下にあるセレクトボックスをクリックして、先ほど作成したデータベースを選択。(このデータベース内にTableを作成します)
後は"New query"欄にテーブル作成のクエリを書いて実行します。
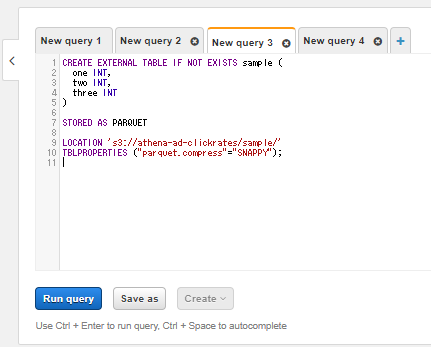
-- 今回のparquetファイル用のテーブル作成クエリ
CREATE EXTERNAL TABLE IF NOT EXISTS sample (
one INT,
two INT,
three INT
)
STORED AS PARQUET
-- 1-3 でコピーしたParquetファイルのあるS3「ディレクトリ」を指定
-- 「ファイル名」ではなく、その1階層上の「ディレクトリ」までのpathを指定する
LOCATION 's3://hoge/sample/'
TBLPROPERTIES ("parquet.compress"="SNAPPY");
もし、1-3でコピーされたS3 URIが
s3://hoge/sample/sample_2d_array.parquet
だったら、
s3://hoge/sample/
までをLOCATIONに指定すればOKです。
ここまで実行すると、Tablesのところに作成したテーブル名が表示される。
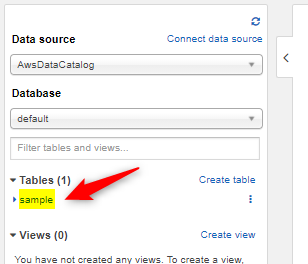
1-5. Load Parquet file into Athena
あとはTable名を指定してSQLを実行することができる。
SELECT * FROM sample;を入力して"Run query"を実行した結果がこれ。
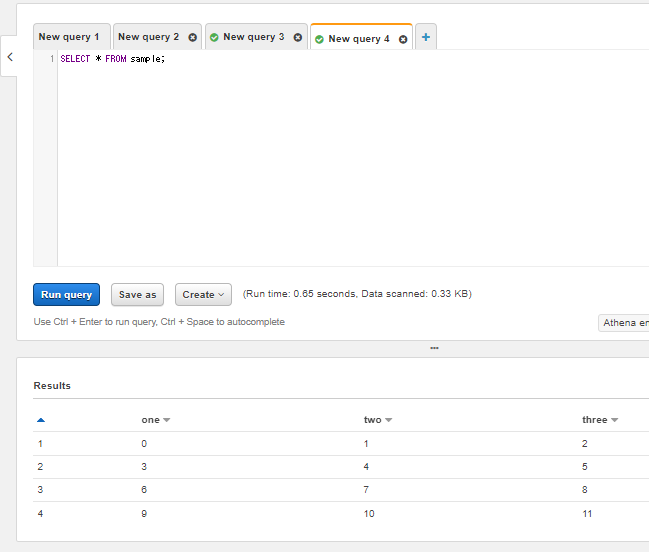
ひとまずParquet形式のデータをAthenaで読み込むところまではできた!(^ワ^*)
2. Use Parquet formatted and Gzip compressed file on Athena
2-1. Source of Python
parquet形式で、GZIP圧縮を行う方法を調べるために、もう一度helpを実行します。
compression引数のところまでスクロールすると、以下のような記述が見つかります。
help(pq.write_table)
...(略)
compression : str or dict
Specify the compression codec, either on a general basis or per-column.
Valid values: {'NONE', 'SNAPPY', 'GZIP', 'BROTLI', 'LZ4', 'ZSTD'}.
...(略)
1-1では、compression='SNAPPY'を指定しましたが、どうやらこの引数の取りうる値の一つに、GZIPがあるようです!
これを指定してみましょう!!!
two_dimension_array: np.array = np.arange(12).reshape(4, 3)
df: pd.DataFrame = pd.DataFrame(two_dimension_array)
df.columns = ['one', 'two', 'three']
table: pa.Table = pa.Table.from_pandas(df)
# compression='GZIP' に変更
pq.write_table(table, './sample_2d_array_gzip.parquet', compression='GZIP')
今度は、同じ階層に、sample_2d_array_gzip.parquetが作成されています。
2-2. Create Table on Athena
1-2~1-4の操作のうち、2においても特に変わらないところは、箇条書きでまとめておきます。
- S3上にフォルダ作成
※ 1-3とは別のフォルダを作成すること - S3へのファイルアップロード
- 1-4のデータベース作成はもうしなくてもよい
※ もちろん別のデータベースを作っても問題ないです
1~3が終わったら、2-2で新たにテーブルを作ります。
テーブルを作り直す必要がある理由ですが、以下の通り、テーブルごとに
- LOCATION:ファイルの設置箇所のパス
- TBLPROPERTIES: データの圧縮形式などのプロパティ
が異なるからです。
-- Gzip圧縮したparquetファイル用のテーブルを作成するSQL
-- テーブル名、LOCATION、TBLPROPERTIES を変更します
CREATE EXTERNAL TABLE IF NOT EXISTS sample_gzip (
one INT,
two INT,
three INT
)
STORED AS PARQUET
LOCATION 's3://hoge/sample_gzip/'
TBLPROPERTIES ("parquet.compress"="GZIP");
このSQLを実行すると、今度はsample_gzipというテーブルができているはずです。
2-3. Load Gzip compressed Parquet file into Athena
あとは、このSQLを実行するだけでデータを読み込むことができました(^ワ^*)
SELECT * FROM sample_gzip;
テーブル作成時にデータのフォーマットや圧縮形式を正しく指定しさえすれば、テーブルアクセス時は特に意識する必要がなさそうです。
これで環境負荷も減らせるならやるしかない!(`・ω・´)きりっ
とはいったものの、本当に効果があるかは調べる必要があるかもしれません!
パフォーマンスにどんな影響があるかは調べていないのですが、関連記事を見つけてあるので、末尾の記事も参考として下さい٩( 'ω' )و
References (参考資料)
基礎的な情報を上の方に、個別具体的な話はなるべく下の方に配置しました。
References about performance