はじめに
- Pythonでスクレイピングの仕方を備忘録。
- スクレイピング禁止のサイトもあるので注意が必要。
準備
- 以下の環境を構築
Google Chrome
WebDriver
- chromedriver
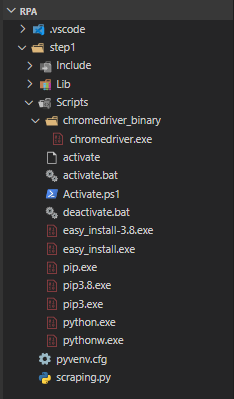
- 解凍した、chromedriver.exeを以下のフォルダ構成で保存
【フォルダ構成】
Python
selenium
selenium
pip install selenium
Beautifulsoup4
BS4
pip install beautifulsoup4
Hello Beautifulsoup4!
scraping.py
from bs4 import BeautifulSoup
html_doc = """
<!DOCTYPE html>
<html>
<head>
<title>TEST SOUP</title>
</head>
<body>
<h1>Hello BS4</h1>
<p class="font-big">python scraping</p>
<button id="start" @click="getURI">Start</button>
<ul>
<li><a href="https://www.yahoo.co.jp">Yahoo</a></li>
<li><a href="https://www.google.co.jp">Google</a></li>
<li><a href="https://www.amazon.co.jp/">Amazon</a></li>
</ul>
</body>
</html>
"""
soup = BeautifulSoup(html_doc, 'html.parser')
print(soup.prettify())
print(soup.title)
print(soup.title.name)
print(soup.title.string)
print(soup.title.parent.name)
print(soup.h1)
print(soup.p)
print(soup.p['class'])
print(soup.button)
print(soup.find(id='start'))
print(soup.a)
print(soup.find_all('a'))
for link in soup.find_all('a'):
print(link.get('href'))
print(soup.get_text())
Hello Selenium!
driver
# 要素の指定方法
# driver.find_element_by_id('ID')
# driver.find_element_by_class_name('CLASS_NAME')
# driver.find_element_by_name('NAME')
# driver.find_element_by_css_selector('CSS_SELECTOR')
# driver.find_element_by_xpath('XPath')
# driver.find_element_by_link_text('LINK_TEXT')
# driver.find_element_by_partial_link_text('LINK_TEXT')
# 要素の操作
# driver.find_element_by_id('ID').click()
# el = driver.find_element_by_id('ID')
# driver.execute_script("arguments[0].click();", el)
# driver.find_element_by_id('ID').send_keys('STRINGS')
# driver.find_element_by_id('ID').text
# driver.find_element_by_id('ID').get_attribute('ATTRI_NAME')
# driver.find_element_by_id('ID').clear()
# ページ操作
# driver.back()
# driver.forward()
# driver.refresh()
# driver.close()
# driver.quit()
selenium.py
import time
import os
os.environ['PATH'] = os.getenv('PATH') + './Scripts/chromedriver_binary;'
# WebDriver: https://sites.google.com/a/chromium.org/chromedriver/downloads
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from bs4 import BeautifulSoup
from bs4 import SoupStrainer
HEADLESS = False
URL = 'https://docs.python.org/ja/3/py-modindex.html'
SELECTOR = 'body > div.footer'
op = Options()
if HEADLESS:
op.add_argument("--headless")
driver = webdriver.Chrome(chrome_options=op)
driver.get(URL)
WebDriverWait(driver, 30).until(
EC.presence_of_element_located((By.CSS_SELECTOR, SELECTOR))
)
code_tag = SoupStrainer('code')
sp = BeautifulSoup(driver.page_source, features='html.parser', parse_only=code_tag)
for c in sp.find_all('code'):
print(c.string)
driver.quit()
おわりに
- 自動化で効率UP。