
Pandasとは
pandasとは、データ分析用ライブラリです。
pandasを使うと、Excelなどのファイルから表形式のデータを読み込み、集計、データ抽出、グラフの表示などが行えます。
Pandasのインポート
pandasを使うにはNumpyと同じようにインポートする必要があります。numpyの時と同じようにas pdとして簡単化します!
import pandas as pd
Pandasのデータ型
Pandasのデータ型は2つあります。
Series型とDataframe型と呼ばれるものです。
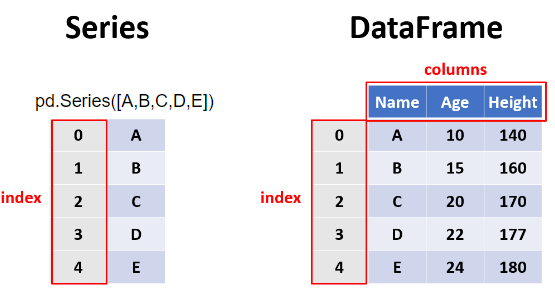
Series型
Seriesは基本一行のデータを扱います。
実際に以下のコードを実行してSeries型データを生成してみましょう。
a = pd.Series([2, 3, 4, 5])
a
実行結果
0 2
1 3
2 4
3 5
dtype: int64
##データ型
また、Numpy同様インデックス番号の指定により要素を抽出できます。
実際に、以下のコードを実行してみてください。
a[0]
実行結果
2
Series型は数値だけでなく、文字列など様々な値を格納することができること合わせて覚えておきましょう。
Dataframe型
DataFrameは、データをExcelのような表形式で表現することができます。
DataFrameの作り方
まず、Numpy配列を基にDataframeを作ります。以下のコードを実行してDataframeを作ってみましょう。
import numpy as np
col_1 = np.array(['A', 'B', 'A', 'C', 'D'])
col_2 = np.array([1, 2, 3, 4, 5])
col_3 = np.array([3, 6, 7, 8, 2])
##各行の定義
df =pd.DataFrame({'col_1':col_1, 'col_2':col_2, 'col_3':col_3})
##カラム名をつけてDataframeをつくる
<実行結果>

ファイルの読み込みによるDaraframeの作成
ファイル読み込みにはread_csvを使います。これによりcsv形式のファイルをDataframeへと読み取ることができます。
大量のデータを扱う際には、打ち込みミス等が考えられるのでデータファイルを読み込む方法が好ましいです。
まず、以下のCSVファイルをダウンロードしてグーグルドライブに移動してください。
Sample1.csv
やり方
前述のリンクをクリックした後、以下のようにドライブにショートカットを作成すればOKです!
そして次のコードをコラボ上で実行しましょう!
from google.colab import drive
drive.mount('/content/drive')
sample = pd.read_csv("/content/drive/MyDrive/sample.csv")
sample
その後次の手順でCSVファイルの中身を読み取っていきます。
1.実行すると、URLが出てくるのでそれをクリック
2. するとブラウザが開きログインする画面になるので自分のGoogleアカウントでログイン
3. ログインできるとパス(文字列)が出てくるのでそれをコピー
4. コラボに戻ってコピーしたパスを入力欄に入れる
これで準備完了です!ゼミでの演習でも行う重要な手順なのでぜひ一度やってみてください!
Dataframeの抽出
実際データ分析などをする際には、データをいじったりして加工をしたりします。そのため、データの確認のため、データ
を1行(1列)などで取り出す必要があります。
ここからは、Dataframeからデータを抽出する方法を説明します。
1行・1列抽出
行で取り出すときと列で取り出す時で書き方が違うので注意しましょう。やり方は以下のようになります。
df名.行名またはdf名[行名]と書くと行抽出できる。
df名.列名またはdf名[列名]と書くと列抽出できる。
では、以下のDataframeを作成し、データの抽出に挑戦しましょう!余力のある人はインデックス番号を英語(A~E)に変更してみましょう!

答え
##インデックス変更なし
col_1 = np.array([70, 78, 65, 87, 90])
col_2 = np.array([81, 72, 83, 94, 72])
col_3 = np.array([73, 86, 87, 68, 92])
df =pd.DataFrame({'国語':col_1, '数学':col_2, '英語':col_3})
##インデックス変更あり
df = pd.DataFrame({'国語': [70, 78, 65, 87, 90],
'数学': [81, 72, 83, 94, 72],
'英語': [73, 86, 87, 68, 92]},
index=['A', 'B', 'C','D', 'E'])
続いて、以下のコードでどの箇所が抽出されるか、予想してみてください!
df['国語']
答え
A 70
B 78
C 65
D 87
E 90
Name: 国語, dtype: int64
df.国語
答え
A 70
B 78
C 65
D 87
E 90
Name: 国語, dtype: int64
df[:1]
答え
国語 数学 英語
A 70 81 73
##0行目を抽出できる
df[1:3]
答え
国語 数学 英語
B 78 72 86
C 65 83 87
##1,2行目を抽出できる(1行目以上3行目未満を抽出)
値を変えて思い通りに抽出ができるよう練習してみましょう!
メソッドを用いた抽出
locとiloc
1行と1列以外で取り出す以外にも、ある特定の1つのデータを取り出したいときがありますよね。
そんなときにilocとlocを使う方法があります。以降、詳しく見ていきます。
iloc
ilocはindexを指定することで特定の値を抽出できます。つまり、行、列を番号で指定します。
df.iloc[2]
##行番号が2の行を抽出(番号は0スタートであることに注意)
df.iloc[: , 1]
##列番号が1の列を抽出
loc
locは名前を指定することで特定の値を抽出できます。
それではやっていきましょう。
df.loc['B']
##名前がBの行を抽出
df.loc[:, '国語']
##名前が国語の列を抽出
行に指定がない場合には代わりに:を付けます。
条件抽出(query)
query()では条件を出して抽出する事が可能です。
df.query('数学 == 72 ')
##数学の点数が72点であるデータを抽出
先頭・末尾の行の抽出
先頭の数行を抽出する際は、head()を使用します。
print(df.head())
##先頭5行分抽出
print(df.head(3))
##()内部の数だけ先頭から抽出
対して、末尾の数行を抽出するにはtail()を使用します。
print(df.tail())
##末尾5行分抽出
print(df.tail(3))
###()内部の数だけ末尾から抽出
以上で抽出の主なやり方を紹介しました。実際に自分で手を動かして理解を深めていってください!
ここからは表の並び替えや欠損値についてみていきます!
並び替え
データの並び変えなどをしたいときはsort_values()を使用します。
()内は並び替えたい列の名前、そしてascendingで構成されています。
ascendingでは、Trueで昇順、Flaseで降順でのソートができます。

上記のDataframeを定義した後、以下のコードを実行するとどうなるでしょうか。
予測してみてから答えを見て確認してください!
df.sort_values('数学', ascending=False)
答え

このように数値の降順(大きい順)に並び替えできます。
また、以下のようなコードを実行するとアルファベット順での並び変えも可能です。
こちらも予想してみてください!
df.sort_values('名前', ascending=True)
答え
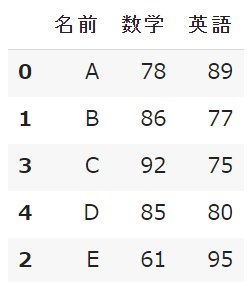
数字に限らず文字に関しても並び替えが可能なので便利ですね!!
基礎統計
describe() を使用することで、各カラムの平均値や標準誤差、四分位数といった記述統計量を求めることができます。
似たようなメソッドにinfo() がありますが、これは各カラムにnullがいくつあるか、データ型、使用メモリといったものを出力してくれます。
欠損値処理
欠損値について
欠損値とは、Dataframeにおいて空白となっている部分のことです。これがあると並び替えや統計をもとめることができなません。なので、データ分析の前処理で欠損値を外す、あるいは別の値で埋めるといった処理をよく行います。もっと詳しく知りたい人は下のリンクを見てください。
参考)欠損値とは
欠損値を外したい場合はdropna()、欠損値を置換したい場合はreplace()とfillna()を使用します。
それでは実際にコードを実行して確かめてみましょう。まず、以下のコードを実行してDataframeを定義します。
import numpy as np
import pandas as pd
col_1 = np.array(['A', 'B', 'E', 'C', 'D'])
col_2 = np.array([78, 86, 61, "不明", 85])
col_3 = np.array([89, 77, "不明", 75, 80])
df =pd.DataFrame({'名前':col_1, '数学':col_2, '英語':col_3})
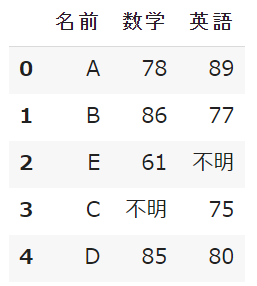
この不明という値をreplace()で欠損値に置き換えます。
実行してみましょう。
df = df.replace('不明' , np.nan)
df
##確認
これにより不明となっていた部分がNANに置き換わったはずです。
このNaNが欠損値です。欠損値はdropna()とfillna()により操作が可能です。
dropna()
dropna()では欠損値のある行を消去することができます。実行してみると、、
df.dropna()
<実行結果>
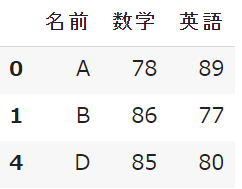
確かに、NaNを含む2,3行目が消去されてますね。
fillna()
fillna()は欠損値を()に入れた値に変えることができます。
実行してみると、、
df.fillna(100)
<実行結果>

と、欠損値を100に変換できています。
replace
replace(a,b)はaをbに置き換えることができます。
これにより、不明となる値を一気に100に変えることができます。
df = df.replace('不明' , 100)
df
dropna()とfillna()を一括で行ってると考えてもらって大丈夫です!
最後に
以上がpandasの使い方、できることの紹介でした。
前節で紹介したnumpyとセットで使われるたり、CSVファイルから読み込みでからのDataframeの作成は後の機械学習等でも使用するので実際に自分で手を動かしてみたりして慣れておいてください!
紹介したコードの実行結果をまとめたコラボがあるので是非、学習に活用してください!
pandasコラボ教材
使用の際は、必ず自分のドライブにコピーしてから使用してください!
紹介した物以外でもPandasでできることは沢山ありますので気になる人はPandasの公式ドキュメント等を確認してください!