概要
仕事で学んだことや注意事項のまとめのAWS OpenSearch編です。
未来の自分や初心者で同じような境遇の人の参考になれば嬉しいです。
基礎知識
用語 (ざっくりの理解)
イメージの付きづらい用語が多く、難しかったです。
【おすすめしてもらったわかりやすい記事】
-
インデックス
データとデータ構造全体のこと。DBのテーブル的なイメージ。 -
ドキュメント
1行ごとのレコードのこと。 -
マッピング
型の定義。DBのカラム的なイメージ。 -
シャード
インデックスの実体で、インデックスを分割したもの。プライマリーシャードとレプリカシャードがあります。
【わかりやすい記事】
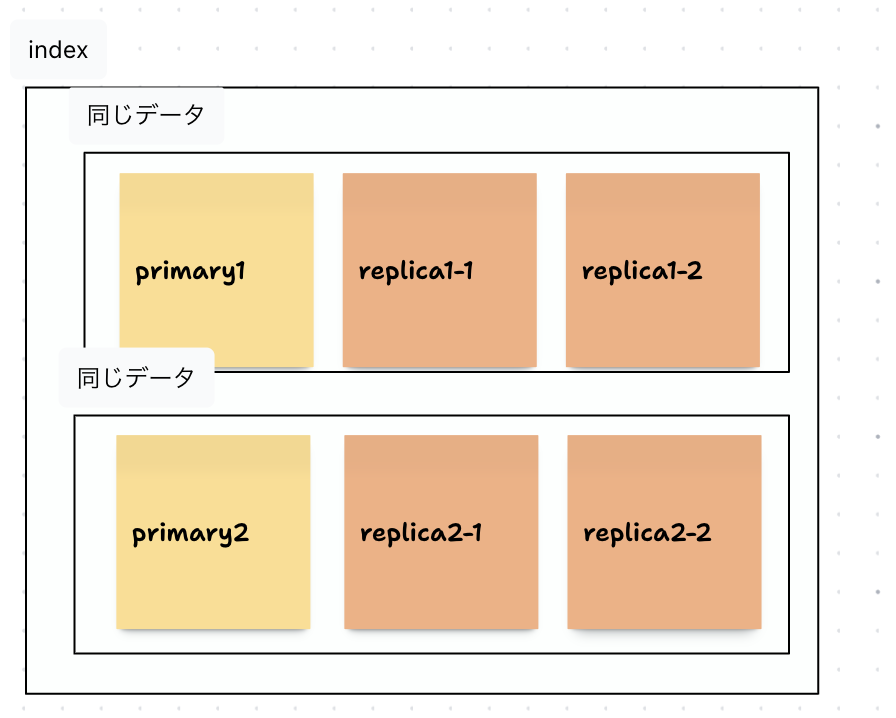
プライマリーシャードの数分インデックスが分割されます。レプリカシャードは、インデックスのコピーで、冗長性を持たせます。
全シャード数 = プライマリーシャード数 + (プライマリーシャード数 × レプリカ数)
以下のイメージでは、全シャード数 = 2 + (2 * 2) = 6 になります。
【イメージ】
-
ノード
OpenSearchのプロセスが動作する単一のサーバー。データノードやマスターノードなど色々なロールがあります。(参考)
各データノードにシャードが分散して配置されます。(参考)どのノードがデータノード/マスターノードかは、AWS管理コンソール > Amazon OpenSearch Service > ドメイン > インスタンスのヘルス から確認できます。
ダッシュボード
クエリの実行や、インデックスの状態を確認することなどができます。
-
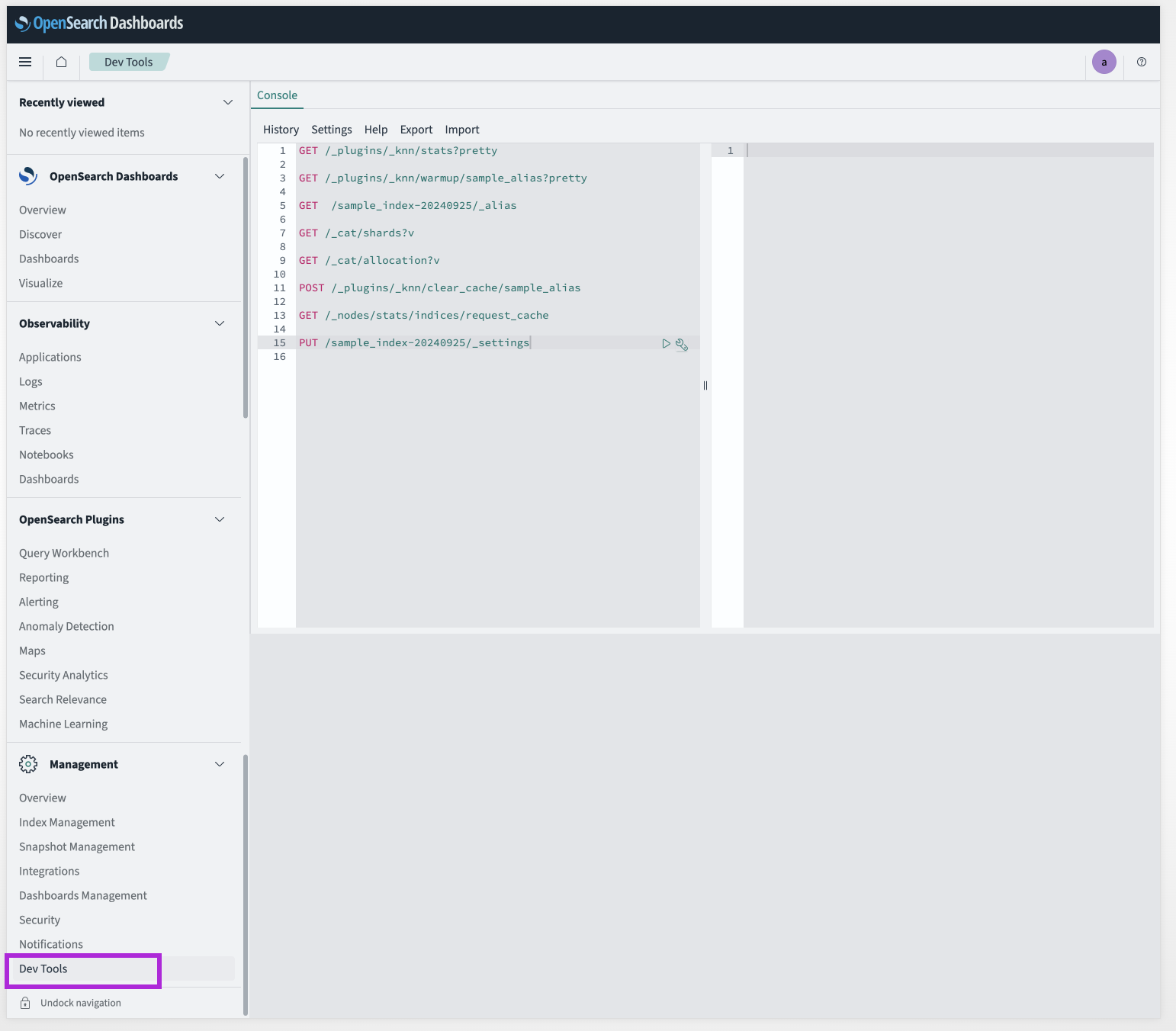
クエリの実行 (APIでもできるようですが、ダッシュボードが便利)
1行ずつ実行し、右で結果を確認することができます。
-
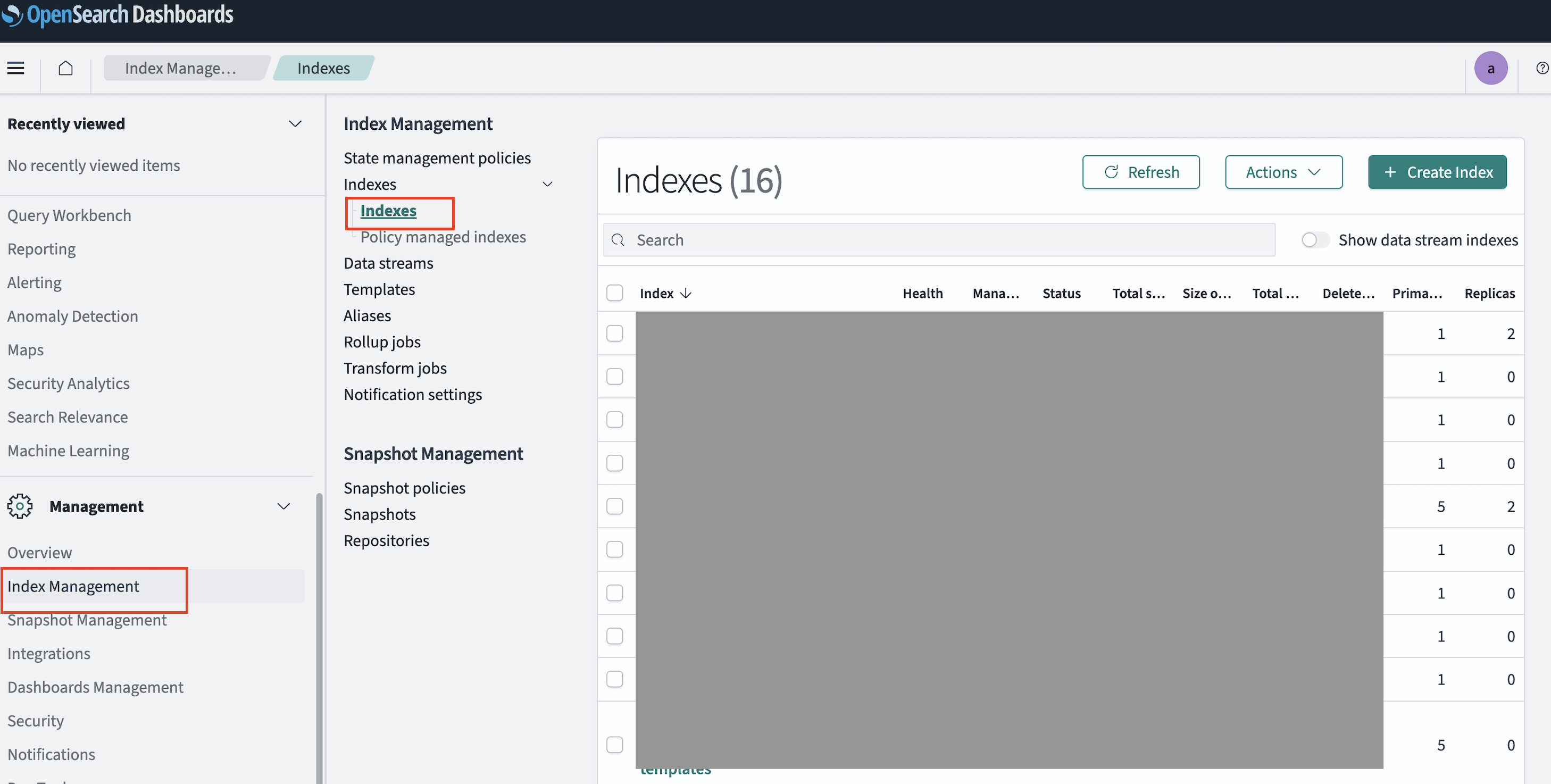
index情報の確認
Index Management > Indexes > Index からシャード数やエイリアスの確認・設定ができます。
【わかりやすい記事】
クエリ
- エイリアスを付け替える (上記Index Management画面からも可能)
使う側でエイリアス名を指定しておくことで、indexを作り直してエイリアスを付け替えれば、ダウンタイムを少なくすることができます。
例:エイリアス名を sample_alias → test_sample_alias に変更
POST /_aliases
{
"actions": [
{
"remove": {
"index": "sample_index-20240920",
"alias": "sample_alias"
}
},
{
"add": {
"index": "sample_index-20240920",
"alias": "test_sample_alias"
}
}
]
}
- エイリアスの確認 (上記Index Management画面からも可能)
GET /sample_index/_alias
- 最初の10件取得 ("size"を指定する)
GET /sample_index/_search
{
"size": 10
}
トラブル関連
k-NN検索でしばらくリクエストしないと、次のリクエスト2,3回だけレスポンスがとても遅い
通常は1秒もかからず検索が終わるのに、開発環境で朝一など、しばらくリクエストがなかった状況で、レスポンスに5秒以上かかるというトラブルが発生しました。数時間に一度しか再現せず、原因が全然わかりませんでしたが、AWSに問い合わせを行ったところ、k-NN検索で利用するネイティブライブラリインデックスがメモリ上に保持されていないと、検索レイテンシーが遅くなるという回答をいただきました。
【解決策】
warm up api を実行し、メモリにインデックスデータを事前に載せておくことで解決しました。sample_index の部分はindex名またはエイリアス名です。
GET /_plugins/_knn/warmup/sample_index?pretty
- テスト等でキャッシュをクリアしたい場合は、以下で実行できます。(ただ、クリアしても朝一で実行した時ほどは遅くならなかったです。)
POST /_plugins/_knn/clear_cache/sample_index?pretty
- キャッシュがある場合は、以下を実行した結果、データノードの
indices_in_cacheが 0でなくなっています。
GET /_plugins/_knn/stats?pretty
【補足】
ネイティブライブラリインデックスとは?
以下は公式ドキュメントの説明をChatGPTに和訳・要約してもらったものです。簡単に言うとベクトルデータをメモリに載せておく必要があるということ?
- ネイティブライブラリインデックスの作成
- インデックス作成時に、各knn-vectorフィールドとLuceneセグメントのペアごとにネイティブライブラリインデックスが作成されます。
- このインデックスは、高速に近傍探索(k-NN検索)を行うためのデータ構造です。
- キャッシュによる管理
- 検索時には、これらのインデックスがネイティブメモリ(RAM)にロードされます。
- キャッシュがこれらのインデックスを管理することで、検索速度を向上させています。
warm up apiを叩いているのにレスポンスが遅い時がある
warm up apiによりレスポンスがたまに遅くなる問題が解決し、ひと安心していましたが、別環境で今度はリクエストを続けているとだんだん遅くなっていく事象が発生しました。原因は、シャード数よりノード数が多くなっており、シャードが配置されていないノードが存在してしまったためのようでした。シャード数 > ノード数 に変更することで解決されました。
気がついたらすごく課金されていた
無料枠をデータ量と勘違いして、個人アカウントでチュートリアルとして作ったちょっとしたデータを放置していたところ、気がついた時には5万円くらい請求されていて絶望しました...。OpenSearchの無料枠は利用時間単位になっており、「 t2.small.search または t3.small.search インスタンスを月 750 時間まで」でした。
常識だと思いますが、チュートリアルで作ったものは終わったらすぐ消さなければいけないし、無料枠の条件をきちんと確認しなければいけないと思いました。
その他
k-NN検索
ベクトル化されたデータを検索し、類似度から、「最近傍」(最も類似したケース)を見つける検索です。特定の画像に似た画像を見つけたりするのに役立ちます。
- クエリ (公式のサンプルより)
GET my-knn-index-1/_search
{
"size": 2, // 上位2件をレスポンスとして返す
"query": {
"knn": {
"my_vector2": {
"vector": [2, 3, 5, 6], // 検索基準のベクトル値(これに似たものを探す)
"k": 2 //最も近いデータポイントを2件探す
}
}
}
}
検索メトリクス
上記のように、検索レイテンシーのトラブルがあったため、リクエスト〜レスポンスまでの時間をメトリクスで取得できると便利なのですが、AWSに問い合わせたところ、現状はそのようなメトリクスは存在しないそうです。
(ラウンドトリップ(リクエスト〜レスポンスまでの時間) = クエリがクエリフェーズで費やした時間 + フェッチフェーズの時間 + キューで費やした時間 + ネットワークレイテンシーですが、
CloudWatch メトリクスの SearchLatency は クエリがクエリフェーズで費やした時間 だけを表しているそうです。)
- その他参考
おわりに
OpenSearchに初めて触れて、複雑な検索もシンプルなクエリでレスポンスも早く行えるところがすごいと感じました。ただ、躓きポイントも多く、携わるにあたってもっとよく勉強するべきだったなと感じました。周りの方のサポートによりなんとかリリースに漕ぎ着け大変感謝でした。加えて、一口にOpenSearchと言っても、k-NN検索と形態素解析では全然違う知識が必要とされることもわかりました。また、今回運用周りで少し携わりはしたものの、実際の検索やデータ構成には携わっていないため、今後その辺りも勉強していければと思いました。
正直まだよくわかっていない部分も多く、間違いがありましたらお知らせいただけますと幸いです。