はじめに
ベストプラクティスにさらっと書いてあるんですが、Spannerではクエリパラメータを使用することが推奨されています。
他のDBだとプリペアードステイトメントとか言われてるやつです。(違うかも)
SQLiの視点から言っても必ず使ったほうがいいです。
解説
以下のような適当なテーブルに適当な初期データを入れて試します。
CREATE TABLE SampleTable (
id INT64 NOT NULL,
name STRING(100),
age INT64,
email STRING(255),
) PRIMARY KEY (id);
INSERT INTO SampleTable (id, name, age, email) VALUES
(1, 'John Doe', 30, 'john@example.com')
Query Insightsでパラメータ化を使用する前後の結果を見ていきます。
クエリパラメータを使用しない場合
UPDATE
`SampleTable`
SET
`name` = 'test3',
`age` = 30,
`email` = 'test1'
WHERE
`id` = 1
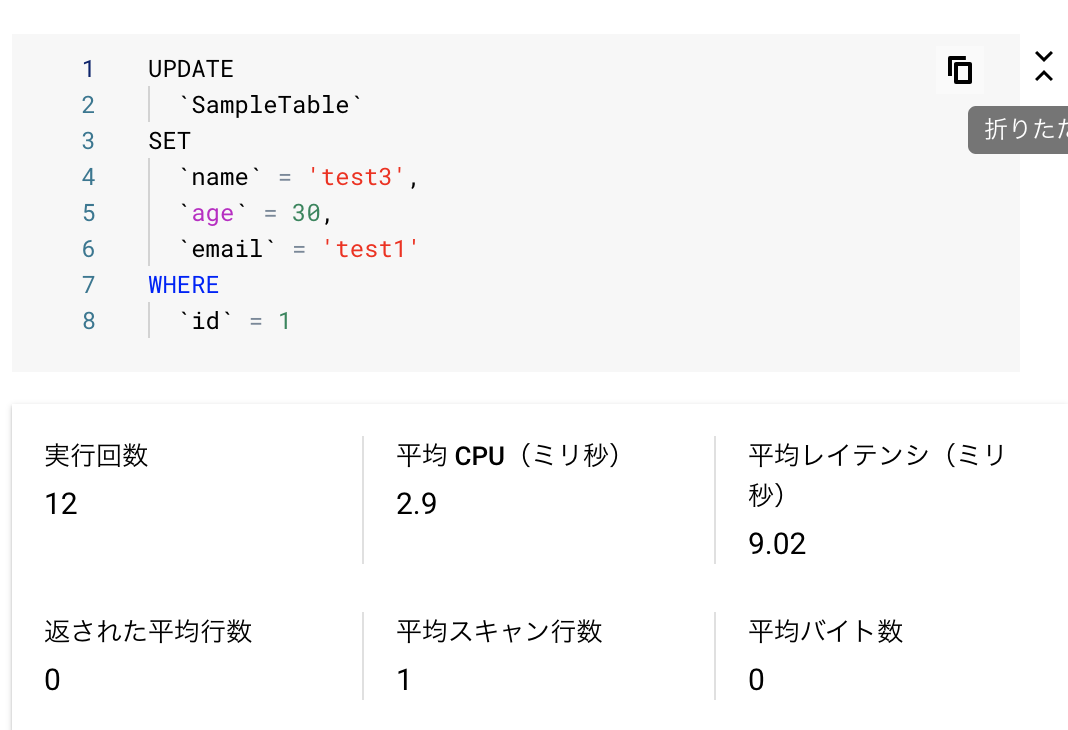
結果
| CPU(ms) | レイテンシ(ms) |
|---|---|
| 2.9 | 9.02 |
クエリパラメータを使用した場合
以下のようにパラメータ化して入れてあげます。
Spanner Studioでは試せないのでコードベースで入れてあげます。(省略)
使わなかった場合と同じ条件で試しています。
UPDATE
`SampleTable`
SET
`name` = @SampleTable_name_1,
`age` = @SampleTable_age_2,
`email` = @SampleTable_email_3
WHERE
`id` = @SampleTable_id_4
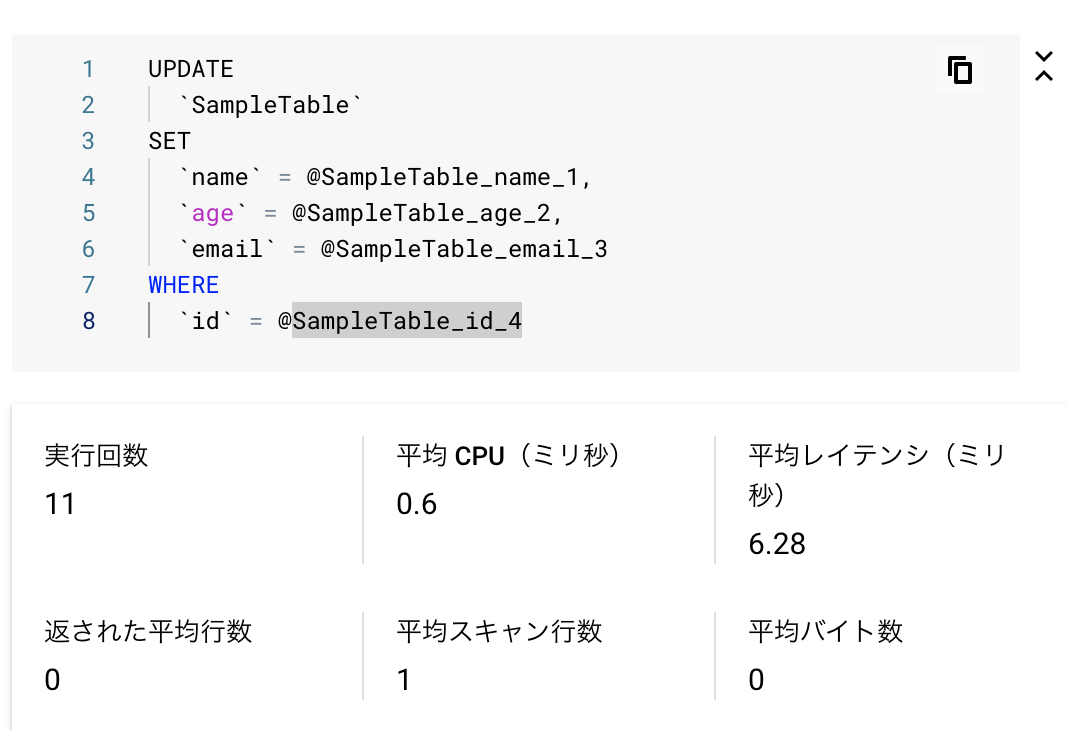
結果
| CPU(ms) | レイテンシ(ms) |
|---|---|
| 0.6 | 6.28 |
まとめ
| パラメータ化 | CPU(ms) | レイテンシ(ms) |
|---|---|---|
| 未 | 2.9 | 9.02 |
| 有 | 0.6 | 6.28 |
レイテンシは3/4ほど、CPUに至っては半分以下になっています。
たった1テーブル1レコードでこの結果なので、ユーザーデータに使われがちなSpannerならば必ず対応すべきモノだと思われます。
考察
構文解析が余計に走っている?
自分の先生曰く、Spannerは最終的にパラメータ化されたクエリで解釈しているのではないかと予想していました。
パラメータ化しないで使用すると内部でパラメータ化するための構文解析が走るということですね。
うまい感じに再利用されていない?
Query Insightsを見ているとパラメータ化したパターンとしないパターンではそれぞれ別にキャッシュされているっぽいと感じました。
例えば以下のクエリは再利用不可であり、前述の構文解析の話と合わせると毎回余計な解析が走っている(そもそもキャッシュしていないのか)
UPDATE
`SampleTable`
SET
`name` = 'test3',
`age` = 30,
`email` = 'test1'
WHERE
`id` = 1
パラメータ化するとおそらく以下のクエリがキャッシュされていて再利用されているっぽい?
UPDATE
`SampleTable`
SET
`name` = @SampleTable_name_1,
`age` = @SampleTable_age_2,
`email` = @SampleTable_email_3
WHERE
`id` = @SampleTable_id_4
ユーザーデータが毎回同じなわけないので、下の解析後のクエリをいい感じに再利用しているのかなと予想。
あくまで予想。
要望
さらっと試すためにSpanner Studioからパラメータを入力できるようにして欲しい。