はじめに
案件が炎上するにしたがって、手入力だけだと議事録が追いつかなくなりました。
なので、音声ファイルから議事録っぽいものを生成するツールを作りました。
GCPのAPIオンリーで作りました。
ツールの使用は自己責任でお願いします。
発生する費用や問題については一切の責任を負いかねます。
実行には以下のAPIの許諾が必要です。
実行コマンドは以下になります。
$ pip install -r requirements.txt
$ python3 main.py -a {audio_path} \
-p {project_id} \
-b {bucket_id} \
-e /path/to/secret-key.json
python3.7以上で動作します。
-eオプションにはAPIを許諾しているサービスアカウントの秘密鍵を入れます。
生成例
以下の動画の音声を入れてみた例
**議事録**
**日時:**
**場所:**
**出席者:**
**議題:** コロナ禍における事業環境の変化と対応
**要旨:**
* コロナ禍は事業環境に大きな影響を与えた。
* 面会禁止や利用者の感染など、さまざまな対応が必要となった。
* デジタルトランスフォーメーションを推進し、オンライン面会や機能訓練ロボットの導入などを行った。
* 利用者向けのサービス内容も変更し、屋外活動や移動販売などを実施した。
* 感染対策を徹底し、2次被害を最小限に抑えた。
* 危機を乗り越えることで、職員の成長につながった。
**議論:**
**スピーカーA:**
「感染者が出た際の対応が難しかった。職員の動揺を抑え、統一的な対応を徹底することが重要だった。」
**スピーカーB:**
「知識不足による職員の動揺が課題だった。感染対策の教育を強化する必要がある。」
**ToDoリスト:**
* DXのさらなる推進(期日なし)
* 職員の教育と知識向上(期日なし)
料金
GCPのサービスを使いまくっているので、生成のたびに料金が発生します。
Speech-To-Text

Gemini Pro

GCSも使ってますが端折ります。
以上のようになっているので1時間の音声データ(1万文字〜1万5000文字)でおおよそ120円〜140円ほど費用が発生します。
(Speech-To-Textが高いからGeminiも端数になってる。。。)
構成
ただのCLIツールなので構成図も何もないんですが、使ってる流れはこんな感じになります。
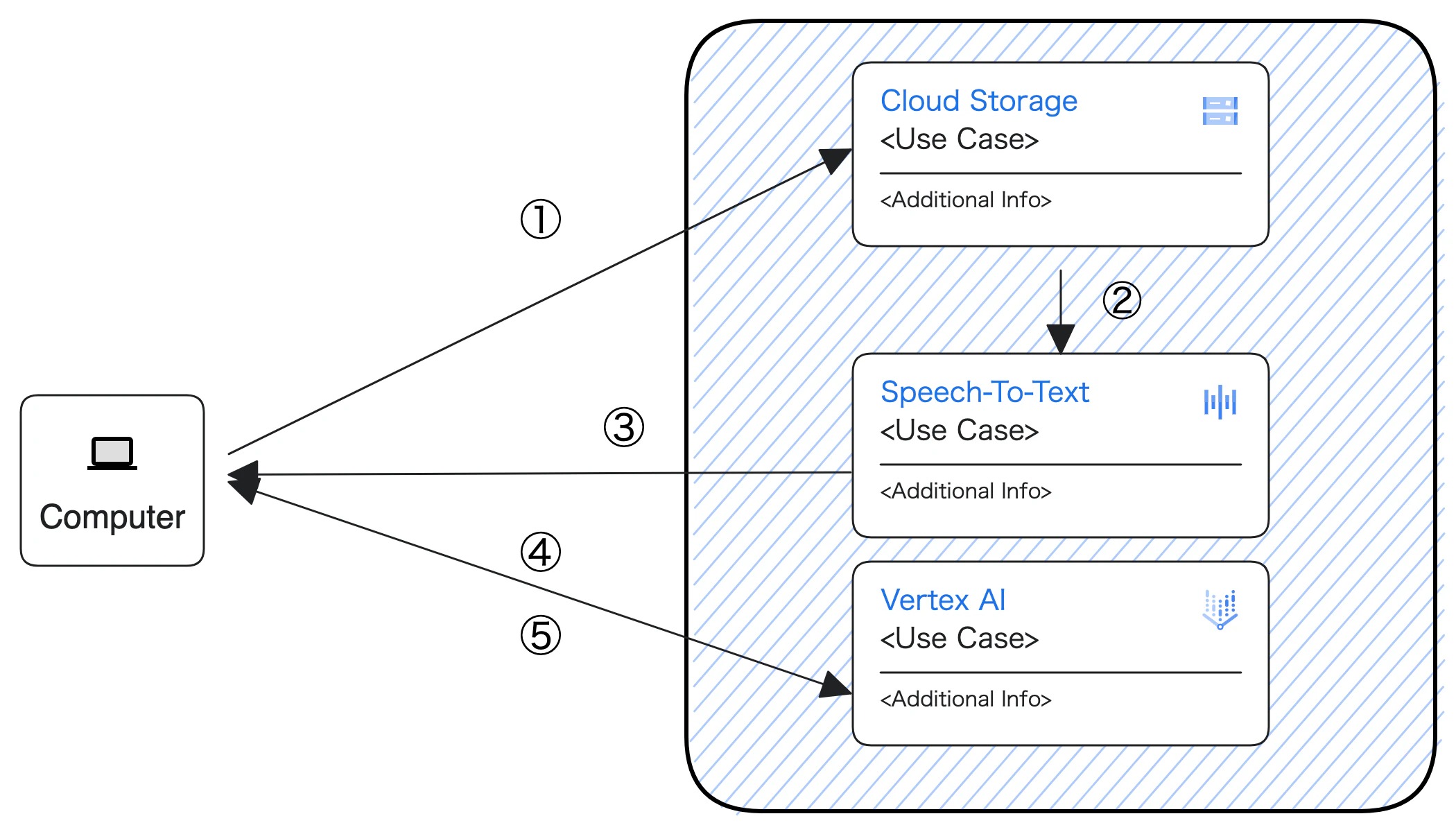
諸々一つにまとめたかったので、全てGCPのサービスにしました。
- GCSに音声データをアップロード
- Speech-To-Textで音声データから文字起こし
- 文字起こししたテキストを VertexAIのGeminiProモデルで要約
勉強になったこと
VertexAI
普段特にAIの勉強などはしていないので、Geminiは名前を知っている程度でした。
GCPのコンソールからGeminiのAPIを探しても見つからず、調べてみるとVertexAIというGoogleのAIのサービスを集約した中のモデルの一つだと。
コード上では以下のように指定しています。
model = GenerativeModel("gemini-1.0-pro")
ここで使用できるモデルの一覧
VertexAIのGUIで出力されているサンプルコードは不完全
GCPのコンソールからVertexAIのAPIを叩ける便利なページがあるのですが、ここで設定の部分にPythonで動かすようのコードが出力されています。
import base64
import vertexai
from vertexai.generative_models import GenerativeModel, Part, FinishReason
import vertexai.preview.generative_models as generative_models
def generate():
vertexai.init(project="project_id", location="us-central1")
model = GenerativeModel("gemini-1.0-pro-vision-001")
responses = model.generate_content(
["""Qiitaに投稿がしたい。"""],
generation_config=generation_config,
safety_settings=safety_settings,
stream=True,
)
for response in responses:
print(response.text, end="")
generation_config = {
"max_output_tokens": 2048,
"temperature": 0.4,
"top_p": 0.4,
"top_k": 32,
}
safety_settings = {
generative_models.HarmCategory.HARM_CATEGORY_HATE_SPEECH: generative_models.HarmBlockThreshold.BLOCK_MEDIUM_AND_ABOVE,
generative_models.HarmCategory.HARM_CATEGORY_DANGEROUS_CONTENT: generative_models.HarmBlockThreshold.BLOCK_MEDIUM_AND_ABOVE,
generative_models.HarmCategory.HARM_CATEGORY_SEXUALLY_EXPLICIT: generative_models.HarmBlockThreshold.BLOCK_MEDIUM_AND_ABOVE,
generative_models.HarmCategory.HARM_CATEGORY_HARASSMENT: generative_models.HarmBlockThreshold.BLOCK_MEDIUM_AND_ABOVE,
}
generate()
ほぼこのまま使えちゃいます。
しかもGUIで設定した諸々のパラメータも反映されるので、ドキュメントとパラメータを照らし合わせながら毎回試すのも簡単です。
しかし、このコードそのまま使うと予期せぬ文字列が入力されたときに困ります。
以下の記事にまとめています。
Googleさん的にはレスポンスが生成できなくてもエラーではないのかな?
キックプロンプトを考えるのは難しい
制約条件といったように書いたほうがいいとググったら出てきたので、以下のようなプロンプトを文章の頭につけています。
一発で議事録として使えるようなテキストを生成できるとはハナから思っていませんが、もっと改善できるなあとは思います。
prompt = """あなたは、プロの議事録作成者です。
以下の制約条件、内容を元に要点をまとめ、議事録を作成してください。
# 制約条件
・要点をまとめ、簡潔に書いて下さい。
・誤字・脱字があるため、話の内容を予測して置き換えてください。
・見やすいフォーマットにしてください。
・議論が起きている場合はその結果も書いてください。
・議論が起きている話題は別セクションで、話し手(スピーカー)が誰か分かるようなセリフ形式にして出力ください。たとえば【(スピーカーの名前)「(セリフ)」】のようにしてください
・スピーカーの名前が分からなければ「スピーカーA」「スピーカーB」のように仮の名前を入れてください。
・最後にToDoリストを期日付きでまとめて書いてください。期日がわからない場合は省略可。
# 内容"""
感想
会社のアカウントで使用することが前提だったので、生成する度発生する費用全く気にせず作りました。
しかし、60分130円はやっぱり高い気がする。
大部分がSpeech-To-Textの料金なので、音声からの文字起こしにOSSのモジュール使えば一気に費用は下げられると思う。(テキストの精度とGeminiの精度がどのくらい相関するのかがわからない)