最近、エクセルのETL依頼が初めて来ました。
エクセルのフォーマットだと色々と考えるべき面倒なことが多く、自社内のデータであれば(最低限、DBもしくはCSVなどになっている状態にしてくださいと)お引き取りいただくところではありますが、外部の会社からのファイル、且つそのデータを社内の方が分析に使えるとビジネス的に大きくプラスになる可能性があるのであれば、やらざるを得ないケースがあります。
なお、神ExcelやPDFはただの泥水なので、お引取り下さい。
マスクド・アナライズさんのtwitterより
(扱ったのは、神エクセルというほど、触りづらいエクセルではありませんでしたが・・)
ただし、手作業で日々対応する、というのは発狂する作業なので、PythonでなるべくETL作業を自動化する方向で考えてみます。
今回攻略するエクセル
仕事のエクセルファイルは公開するわけにはいかないので、お役所が公開しているエクセルファイルを対象とします。シンプルに左上から列のカラム、次の行からデータが格納されている、CSVに近い形式では面白くないのと、実際のデータは結構複雑なレイアウトに対して対応する必要があるので、込み入ったものを対象にします。
今回は総務省のサイトで公開している、「労働力調査 長期時系列データ」「表8」「4)地域,就業状態別15歳以上人口(エクセル:829KB)」のエクセルファイルを対象として進めてみます。
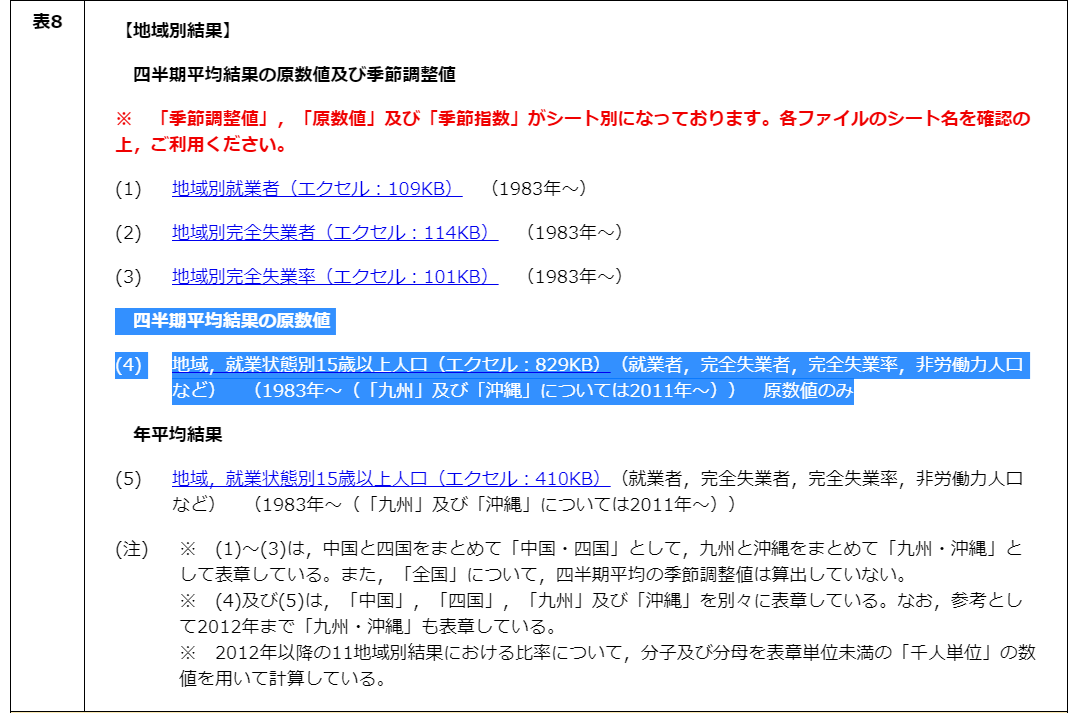
エクセルで開くとこんな感じになっています。
使うライブラリ
openpyxlというMITライセンスのPythonライブラリを中心に使っていきます。
記事で使用するバージョンはん2.5.12で進めます。
ドキュメント
また、今回の総務省のエクセルファイルが大分古いフォーマットのxlsで、openpyxlで扱おうとするとxlsxのフォーマットにしてくれと怒られるので、xlsxへの変換用にpyexcel、pyexcel-xls、pyexcel-xlsxという三つのライブラリも設定しておきます(excel2003とかのデータみたいですね・・年代ものだ・・)。
普通に、xlsxしか扱っていないよというケースであればopenpyxlだけで問題ありません。
pipによるライブラリ設定 :
$ pip install openpyxl==2.5.12
$ pip install pyexcel==0.5.10
$ pip install pyexcel-xls==0.5.8
$ pip install pyexcel-xlsx==0.5.6
エクセルファイルを見て、構造と最終的なデータの形式を決める
スクリプトを書いていく前に、まずはエクセルファイルを見て、どんな特徴があるのかを見ていきます。
- 複数シート存在する。
- 列番号や、値の開始となる行番号は各シートで統一されている。
- 数値が万人となっているので、最終的な抽出後のデータは ×10000しておく。
- 月は4半期単位で設定されている。
- 昭和や平成表記は1~3月の行、西暦は4~6月の行に設定されている。
- カラムが多次元の階層になっている。
- 性別ごと、労働・非労働人口といった具合になっている。
- 一番深いところで、「性別」「労働力人口」「就業者」「うち自営業主」といった4階層になっている。
- 最終行以降は、空欄になっていたり、補足の文字列が入っていたりする。(月の行があっても数値が入っていなかったりする)
- 後半のシートでは、【参考】や(既公表値)といったラベルが付与されているシートが存在するものの、今回は扱わなくて良さそう
上記を踏まえて、最終的なデータのカラムは以下のようにするようにします。扱いやすいように行列にするので、カラム名はものによっては長めになりますが許容します。
率を扱う、floatのカラムの値は0.0~1.0の値で統一します。
- area : int -> 地域のラベル。「全国」「北海道」など。シート名を参照する
- year : int -> 西暦
- quarter : int -> 対象の四半期。1~3月を1とし、1から4で設定
- gender : int -> 性別。1=男女合計、2=男、3=女
- population_aged_15_years_old_and_over : int -> 15歳以上の人口
- labour_force_total : int -> 労働力人口の総数
- labour_force_employed_total : int -> 労働力人口の就業者の総数
- labour_force_employed_self_employed : int -> 労働力人口の就業者の自営業主の数
- labour_force_employed_employee : int -> 労働力人口の就業者の雇用者数
- labour_force_unemployed : int -> 労働力人口の完全失業者数
- not_in_labour_force : int -> 非労働力人口
- labour_force_participation_rate : float -> 労働力人口比率。
- employment_rate : float -> 就業率
- unemployment_rate : float -> 完全失業率
実際のコード
必要に応じてご利用ください。
Github htmlpreview
必要なライブラリをimport
import os
from datetime import datetime
import openpyxl as px
import pandas as pd
import numpy as np
import pyexcel
古いフォーマットのエクセルを変換する
お役所のエクセルが古いxlsファイルで、ライブラリで開けないので事前にxlsxのフォーマットに変換しておきます。
def convert_xls_to_xlsx(xls_file_path, dest_path):
"""
古いxlsのフォーマットのファイルを、xlsxのフォーマットに変換を行う。
Notes
-----
変換の処理の都合、図や画像・フォント情報などは保持されない。ETL
などでの使用のみを想定すること。
Parameters
----------
xls_file_path : str
変換対象のxlsファイルのパス。
dest_path : str
変換後のファイルの保存先のパス。
Raises
------
ValueError
対象のファイルが存在しない場合。
"""
if not os.path.exists(xls_file_path):
err_msg = '対象のファイルが存在しません : %s' % xls_file_path
raise ValueError(err_msg)
pyexcel.save_book_as(
file_name=xls_file_path,
dest_file_name=dest_path)
convert_xls_to_xlsx(
xls_file_path='./総務省統計データ.xls',
dest_path='./総務省統計データ.xlsx')
ファイルを開く
load_workbook関数でxlsxのエクセルファイルを開くことができます。
今回はETLのみが目的なので、編集したりはしないようにread_only=Trueと指定しています。
また、data_only=Trueと指定することで、エクセルのセルの値を取得した際に値が関数の文字列ではなく、関数結果の数値やラベルなどの文字列になるように設定しています。(今回のお役所のエクセルだと、ぱっと見関数などは使われて無さそうな印象はありますが、念のため)
Workbookオブジェクトが返却され、このオブジェクトがシート関係などのデータを格納しています。
def open_as_read_only(file_path):
"""
エクセルファイルを、読み取り専用・且つ関数を無効化した状態で開く。
Notes
-----
値を取得する際に、関数の文字列ではなく表示上の数値を取得したい
ため、data_onlyにTrueを設定している。
Parameters
----------
file_path : str
対象のエクセルファイルのパス。
Returns
-------
wb : openpyxl.workbook.Workbook
開いた対象のエクセルのワークブックオブジェクト。
Raises
------
ValueError
対象のエクセルファイルが存在しない場合。
"""
if not os.path.exists(file_path):
err_msg = '対象のファイルが存在しません : %s' % file_path
raise ValueError(err_msg)
wb = px.load_workbook(
filename=file_path, read_only=True, data_only=True)
return wb
wb = open_as_read_only(file_path='./総務省統計データ.xlsx')
なお、閉じるときにはclose関数を使います。
wb.close()
必要なシート名のリストを算出する
シート名のリストは、sheetnamesという属性値で対象のリストにアクセスできます。
今回は、「参考」「既公表値」「地域区分」といった、補足用などのシートは対象外にしたいので、それらがシート名に含まれていたら対象外になるようにスキップしておきます。
sheet_name_list = []
for sheet_name in wb.sheetnames:
is_in = '参考' in sheet_name
if is_in:
continue
is_in = '既公表値' in sheet_name
if is_in:
continue
is_in = '地域区分' in sheet_name
if is_in:
continue
sheet_name_list.append(sheet_name)
以下のリストが対象となりました。
sheet_name_list
['全国', '北海道', '東北', '南関東', '北関東・甲信', '北陸', '東海', '近畿', '中国', '四国', '九州', '沖縄']
定数定義
カラム名などの定数を定義しておきます。
今回、データの開始行や列番号などは固定になっているので、それらも定数で持ってしまいます。(データによって変動する場合には、文字列で判定したりして、対象の列番号などを算出したりが必要になってきます)
カラム名
まずはカラム名の定義から。後々、データフレームなどで参照していきます。
CN_AREA = 'area'
CN_YEAR = 'year'
CN_QUARTER = 'quarter'
CN_GENDER = 'gender'
CN_POPULATION_AGED_15_YEARS_OLD_AND_OVER = \
'population_aged_15_years_old_and_over'
CN_LABOUR_FORCE_TOTAL = 'labour_force_total'
CN_LABOUR_FORCE_EMPLOYED_TOTAL = 'labour_force_employed_total'
CN_LABOUR_FORCE_EMPLOYED_SELF_EMPLOYED = 'labour_force_employed_self_employed'
CN_LABOUR_FORCE_EMPLOYED_EMPLOYEE = 'labour_force_employed_employee'
CN_LABOUR_FOECE_UNEMPLOYED = 'labour_force_unemployed'
CN_NOT_IN_LABOUR_FORCE = 'not_in_labour_force'
CN_LABOUR_FORCE_PARTICIPATION_RATE = 'labour_force_participation_rate'
CN_EMPLOYMENT_RATE = 'employment_rate'
CN_UNEMPLOYMENT_RATE = 'unemployment_rate'
COLUMN_NAME_LIST = [
CN_AREA,
CN_YEAR,
CN_QUARTER,
CN_GENDER,
CN_POPULATION_AGED_15_YEARS_OLD_AND_OVER,
CN_LABOUR_FORCE_TOTAL,
CN_LABOUR_FORCE_EMPLOYED_TOTAL,
CN_LABOUR_FORCE_EMPLOYED_SELF_EMPLOYED,
CN_LABOUR_FORCE_EMPLOYED_EMPLOYEE,
CN_LABOUR_FOECE_UNEMPLOYED,
CN_NOT_IN_LABOUR_FORCE,
CN_LABOUR_FORCE_PARTICIPATION_RATE,
CN_EMPLOYMENT_RATE,
CN_UNEMPLOYMENT_RATE,
]
列番号
続いて、列番号の定義です。注意点として、openpyxlでは列の指定はA、B、C...といった記号ではなく、1以降の番号で指定する形になります。番号も、0スタートではない点を注意してください。
COLUMN_NUM_YEAR = 1
COLUMN_NUM_QUARTER = 2
# 各性別の列の開始列番号。
COLUMN_NUM_GENDER_START_BOTH = 4
COLUMN_NUM_GENDER_START_MALE = 14
COLUMN_NUM_GENDER_START_FEMALE = 24
# 各項目の列番号加算分。性別ごとに同じ順番で設定されるため、これらの
# 定数 + 性別ごとの列番号で、対象の項目の列番号となる。
ADDITIONAL_C_NUM_POPULATION_AGED_15_YEARS_OLD_AND_OVER = 0
ADDITIONAL_C_NUM_LABOUR_FORCE_TOTAL = 1
ADDITIONAL_C_NUM_LABOUR_FORCE_EMPLOYED_TOTAL = 2
ADDITIONAL_C_NUM_LABOUR_FORCE_EMPLOYED_SELF_EMPLOYED = 3
ADDITIONAL_C_NUM_LABOUR_FORCE_EMPLOYED_EMPLOYEE = 4
ADDITIONAL_C_NUM_LABOUR_FOECE_UNEMPLOYED = 5
ADDITIONAL_C_NUM_NOT_IN_LABOUR_FORCE = 6
ADDITIONAL_C_NUM_LABOUR_FORCE_PARTICIPATION_RATE = 7
ADDITIONAL_C_NUM_EMPLOYMENT_RATE = 8
ADDITIONAL_C_NUM_UNEMPLOYMENT_RATE = 9
行番号関係
# 西暦の記載してある行番号加算分。
ADDITIONAL_R_NUM_YEAR = 1
# データの開始行番号。
START_ROW_NUM = 11
ラベルや種別値、調整値など
QUARTER_LABEL_1 = '1~3月'
QUARTER_LABEL_2 = '4~6月'
QUARTER_LABEL_3 = '7~9月'
QUARTER_LABEL_4 = '10~12月'
QUARTER_TYPE_1 = 1
QUARTER_TYPE_2 = 2
QUARTER_TYPE_3 = 3
QUARTER_TYPE_4 = 4
LABEL_KEY_QUARTER_TYPE_DICT = {
QUARTER_LABEL_1: QUARTER_TYPE_1,
QUARTER_LABEL_2: QUARTER_TYPE_2,
QUARTER_LABEL_3: QUARTER_TYPE_3,
QUARTER_LABEL_4: QUARTER_TYPE_4,
}
TYPE_KEY_QUARTER_LABEL_DICT = {
QUARTER_TYPE_1: QUARTER_LABEL_1,
QUARTER_TYPE_2: QUARTER_LABEL_2,
QUARTER_TYPE_3: QUARTER_LABEL_3,
QUARTER_TYPE_4: QUARTER_LABEL_4,
}
GENDER_TYPE_BOTH = 1
GENDER_TYPE_MALE = 2
GENDER_TYPE_FEMALE = 3
# 整数の値に乗算しておく数値設定。
INT_MULTIPLY_VAL = 10000
エクセルの内容と定数のチェック
定義した定数の値を、実際のエクセルの内容に当てはめてみてチェックしてみましょう。
全てのシートで問題がないのか(番号などがずれているシートがないかなど)のチェックなどは人の目だとしんどいので、単体テストの要領でassert文でチェックしていきます。(必要に応じてnoseなどのテストライブラリなどもご利用ください)
地味な作業ですが、凡ミスでETLの段階で列番号がずれていた・・などとなると、他の方の意思決定などに影響し、場合によっては大きな金額分影響が出てしまう恐れがあります。慎重すぎるくらいでちょうどいいくらいだと思います。(今回は仕事ではないので、がっつり厳密にといった具合まではやりませんが、仕事ではスクリプトのテストコードも含め、しっかり書いておくと安心かなと)
また、今回は単体のエクセルですが、実務では定期的にエクセルが送られて来たりするので、こういったチェックを書いておいて日次単位などで新しいファイルに対してチェックを行い、もしうまくいかない(条件や定数などを調整する必要があるなどの)場合にはSlackなどに通知するようにしておくと安心だと思います。
まずは、チェックがやりやすいように、ヘルパー関数を用意しておきます。
def get_cell_value_str(cell, strip=True):
"""
対象のCellの値を文字列で取得する。
Parameters
----------
cell : openpyxl.cell.read_only.ReadOnlyCell or
openpyxl.cell.read_only.EmptyCell
対象のセルのオブジェクト。
strip : bool, default True
文字列の先頭と末尾の余分な文字列(スペースやタブなど)を
削除するかどうかの真偽値。
Returns
-------
cell_value_str : str
取得結果のセルの値の文字列。空のセルや値がNoneの場合には
空文字が設定される。
"""
if isinstance(cell, px.cell.read_only.EmptyCell):
return ''
if cell.value is None:
return ''
cell_value_str = str(cell.value)
if strip:
cell_value_str = cell_value_str.strip()
return cell_value_str
まずは対象のセルの値を取得する関数です。エクセルファイルによってはEmptyCellになることがある(非表示設定になっているもの?)や、値がNoneになっていたり、左右にタブやらスペースやらが含まれていたりで扱いが手間なので、その辺りをシンプルにしてくれるように、文字列の型に返却値を統一し、且つ余分なスペースなどに対してstrip関数を挟んで取り除くようにしてあります。
def is_numeric_cell_value(ws, row_num, column_num):
"""
対象のセルの値が、数値のセルかどうか(float型でキャストできる
値かどうか)の真偽値を取得する。
Parameters
----------
ws : openpyxl.worksheet.read_only.ReadOnlyWorksheet
対象のシート。
row_num : int
対象のセルの行番号。
column_num : int
対象のセルの列番号。
Returns
-------
result : bool
セルの値が数値の場合にはTrueが設定される。
"""
cell = ws.cell(row=row_num, column=column_num)
cell_value_str = get_cell_value_str(cell=cell)
try:
float(cell_value_str)
except Exception:
return False
return True
また、有効な行の算出用に、対象のセルが数値のセルかどうかの判定用の関数を用意しました。
def get_data_last_row_num(ws):
"""
対象のシートの、データの最終行を算出する。数値のデータの先頭の
列で、対象の行が数値ではなくなった行で判定する。
Parameters
----------
ws : openpyxl.worksheet.read_only.ReadOnlyWorksheet
対象のシート。
Returns
-------
last_row_num : int
算出された最終行番号。
"""
column_num = COLUMN_NUM_GENDER_START_BOTH
current_target_row = START_ROW_NUM
while True:
is_numeric = is_numeric_cell_value(
ws=ws, row_num=current_target_row, column_num=column_num)
if not is_numeric:
return current_target_row - 1
current_target_row += 1
それらを使って、数値のデータが設定されている最終行を算出する関数を用意しました。
各シート(ReadOnlyWorksheet)の取得処理は、ワークブックオブジェクト(wb)のインデックスにシート名を取得することができます。
# 先頭のシートを取得する例。
ws = wb[wb.sheetnames[0]]
これで、以下のように有効なデータの最終行(今回のエクセルでは153行目)を算出できます。
get_data_last_row_num(ws=ws)
153
前述のものを使って進めます。クラウドカーネル上へのライブラリインストールが手間なのでPython自体のassert文を使いますが、必要に応じてnoseなどお使いください。
def assert_year_val(ws, column_num, row_first, row_last):
"""
対象のシートの年の内容の記述が想定した値になっているかどうかの
チェックを行う。
Parameters
----------
ws : openpyxl.worksheet.read_only.ReadOnlyWorksheet
対象のシート。
column_num : int
対象のカラム番号。
row_first : int
データの先頭の行番号。
row_last : int
データの最終行の行番号。
Raises
------
AssertionError
想定した値になっていない場合。
"""
target_row_num = row_first + 1
while target_row_num <= row_last:
assert is_numeric_cell_value(
ws=ws, row_num=target_row_num, column_num=column_num)
cell = ws.cell(row=target_row_num, column=column_num)
cell_value_str = get_cell_value_str(cell=cell)
assert len(cell_value_str) == 4
target_row_num += 4
まずは年の列の関数から。西暦の値が数値であること、桁が4桁なこと、4行ずつシフトさせていった際に、ずれがないことをチェックします。
def assert_quarter_label(ws, column_num, row_first, row_last):
"""
対象のシートの四半期のラベルの内容の記述が想定した
値になっているかどうかのチェックを行う。
Parameters
----------
ws : openpyxl.worksheet.read_only.ReadOnlyWorksheet
対象のシート。
column_num : int
対象のカラム番号。
row_first : int
データの先頭の行番号。
row_last : int
データの最終行の行番号。
Raises
------
AssertionError
想定した値になっていない場合。
"""
target_row_num = row_first
quarter_label_list = [
QUARTER_LABEL_1, QUARTER_LABEL_2, QUARTER_LABEL_3, QUARTER_LABEL_4,
]
while target_row_num <= row_last:
for i, quarter_label in enumerate(quarter_label_list):
cell = ws.cell(row=target_row_num + i, column=column_num)
assert get_cell_value_str(cell=cell) == quarter_label
target_row_num += len(quarter_label_list)
続いて四半期の列の部分の確認。ラベルが変なものになっていないか、ラベルの繰り返し具合なども問題がないことを確認します。
def assert_values_are_numeric_and_label(
ws, column_num, row_first, row_last, expected_eng_label):
"""
対象のシートの指定の列の各値が数値になっていることと、英語のラベル
表記が想定したものになっているか(ずれていないか)のチェックを
行う。
Parameters
----------
ws : openpyxl.worksheet.read_only.ReadOnlyWorksheet
対象のシート。
column_num : int
対象のカラム番号。
row_first : int
データの先頭の行番号。
row_last : int
データの最終行の行番号。
expected_eng_label : str
対象の列の英語のラベルの想定値。
Raises
------
AssertionError
想定した値になっていない場合。
"""
ENGLISH_LABEL_ROW = 10
cell = ws.cell(row=ENGLISH_LABEL_ROW, column=column_num)
english_label = get_cell_value_str(cell=cell)
assert english_label == expected_eng_label
target_row_num = row_first
while target_row_num <= row_last:
is_numeric = is_numeric_cell_value(
ws=ws, row_num=target_row_num, column_num=column_num)
assert is_numeric
target_row_num += 1
残りの値の部分の列は、共通してチェックできそうなフォーマットなので、上記のコードのように値が数値になっていることと、英語のラベルが想定したものになっているか(ずれていないか)をチェックするようにしました。
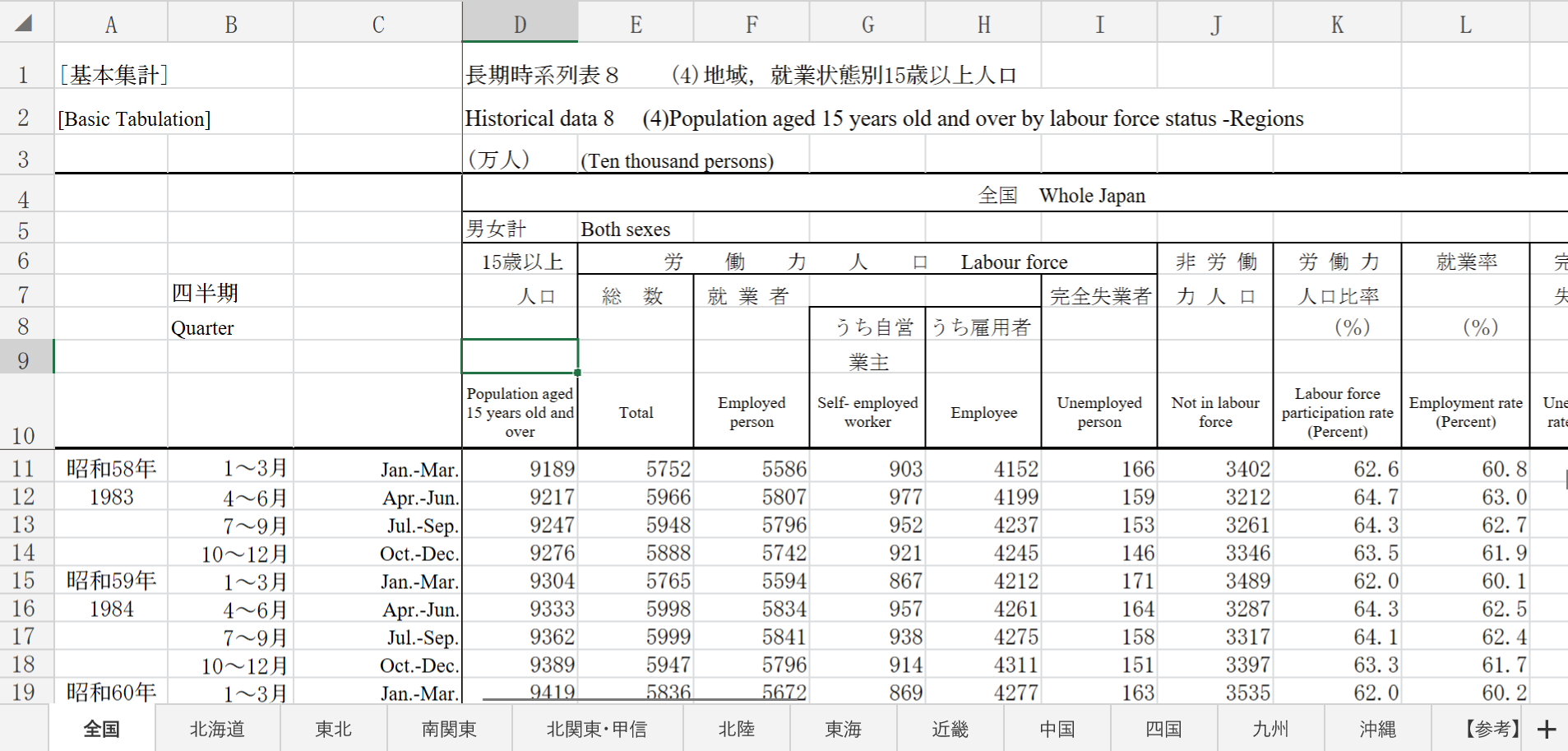
各定数のループを回すのを楽にするように、データフレームに入れておきます。
VALUE_COLUMN_INFO_DF = pd.DataFrame(
columns=['additional_column_num', 'expected_eng_label', 'column_name',
'dtype'],
data=[{
'additional_column_num': ADDITIONAL_C_NUM_POPULATION_AGED_15_YEARS_OLD_AND_OVER,
'expected_eng_label': 'Population aged 15 years old and over',
'column_name': CN_POPULATION_AGED_15_YEARS_OLD_AND_OVER,
'dtype': int,
}, {
'additional_column_num': ADDITIONAL_C_NUM_LABOUR_FORCE_TOTAL,
'expected_eng_label': 'Total',
'column_name': CN_LABOUR_FORCE_TOTAL,
'dtype': int,
}, {
'additional_column_num': ADDITIONAL_C_NUM_LABOUR_FORCE_EMPLOYED_TOTAL,
'expected_eng_label': 'Employed person',
'column_name': CN_LABOUR_FORCE_EMPLOYED_TOTAL,
'dtype': int,
}, {
'additional_column_num': ADDITIONAL_C_NUM_LABOUR_FORCE_EMPLOYED_SELF_EMPLOYED,
'expected_eng_label': 'Self- employed worker',
'column_name': CN_LABOUR_FORCE_EMPLOYED_SELF_EMPLOYED,
'dtype': int,
}, {
'additional_column_num': ADDITIONAL_C_NUM_LABOUR_FORCE_EMPLOYED_EMPLOYEE,
'expected_eng_label': 'Employee',
'column_name': CN_LABOUR_FORCE_EMPLOYED_EMPLOYEE,
'dtype': int,
}, {
'additional_column_num': ADDITIONAL_C_NUM_LABOUR_FOECE_UNEMPLOYED,
'expected_eng_label': 'Unemployed person',
'column_name': CN_LABOUR_FOECE_UNEMPLOYED,
'dtype': int,
}, {
'additional_column_num': ADDITIONAL_C_NUM_NOT_IN_LABOUR_FORCE,
'expected_eng_label': 'Not in labour force',
'column_name': CN_NOT_IN_LABOUR_FORCE,
'dtype': int,
}, {
'additional_column_num': ADDITIONAL_C_NUM_LABOUR_FORCE_PARTICIPATION_RATE,
'expected_eng_label': 'Labour force participation rate (Percent)',
'column_name': CN_LABOUR_FORCE_PARTICIPATION_RATE,
'dtype': float,
}, {
'additional_column_num': ADDITIONAL_C_NUM_EMPLOYMENT_RATE,
'expected_eng_label': 'Employment rate (Percent)',
'column_name': CN_EMPLOYMENT_RATE,
'dtype': float,
}, {
'additional_column_num': ADDITIONAL_C_NUM_UNEMPLOYMENT_RATE,
'expected_eng_label': 'Unemployment rate (Percent)',
'column_name': CN_UNEMPLOYMENT_RATE,
'dtype': float,
}])
VALUE_COLUMN_INFO_DF
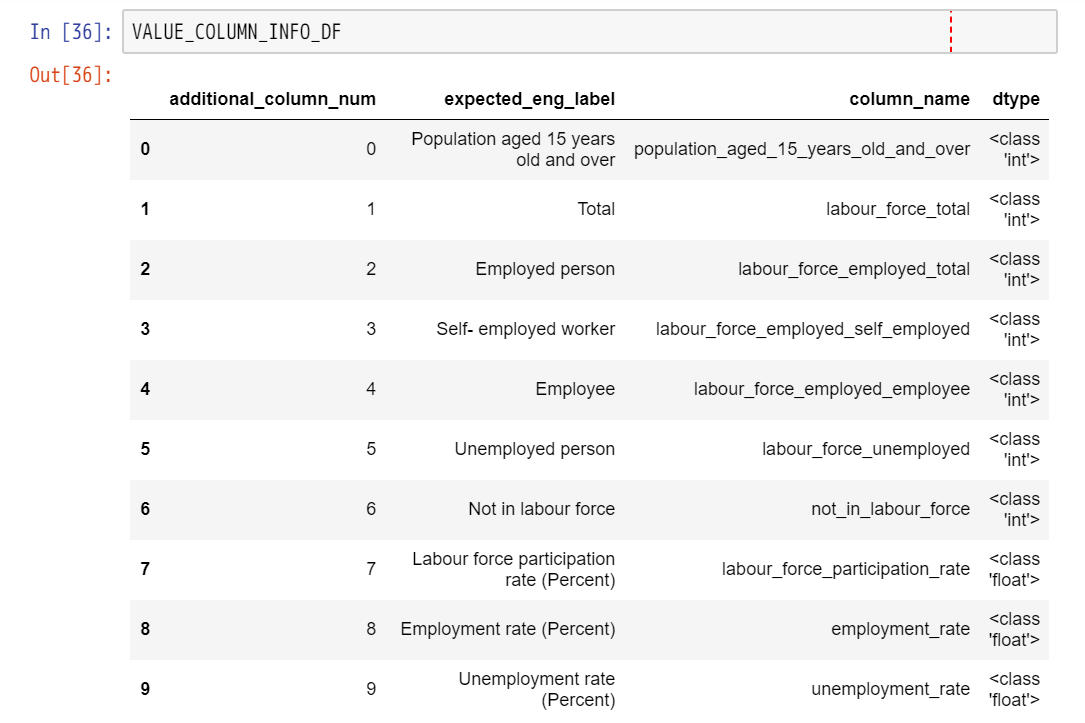
def assert_target_gender_type_value_columns(
ws, row_first, row_last, column_num_gender_start):
"""
対象の性別ごとの表に対して、各列の値や想定ラベルのチェックを行う。
Parameters
----------
ws : openpyxl.worksheet.read_only.ReadOnlyWorksheet
対象のシート。
row_first : int
データの先頭の行番号。
row_last : int
データの最終行の行番号。
column_num_gender_start : int
対象の性別種別ごとの表の開始列番号。以下の定数の値を指定する。
- COLUMN_NUM_GENDER_START_BOTH
- COLUMN_NUM_GENDER_START_MALE
- COLUMN_NUM_GENDER_START_FEMALE
Raises
------
AssertionError
想定した値になっていない場合。
"""
for index, sr in VALUE_COLUMN_INFO_DF.iterrows():
column_num = column_num_gender_start + int(sr['additional_column_num'])
expected_eng_label = sr['expected_eng_label']
assert_values_are_numeric_and_label(
ws=ws, column_num=column_num, row_first=row_first,
row_last=row_last, expected_eng_label=expected_eng_label)
さらに、ラッパー的に、男女計・男性・女性とチェックをシンプルな記述で行うための関数を用意しました。
あとは各シートに対して、ループでチェックの処理を流すだけです。
for sheet_name in sheet_name_list:
print(datetime.now(), sheet_name, 'started.')
ws = wb[sheet_name]
row_last = get_data_last_row_num(ws=ws)
kwargs = {
'ws': ws,
'row_first': START_ROW_NUM,
'row_last': row_last,
}
assert_year_val(column_num=COLUMN_NUM_YEAR, **kwargs)
assert_quarter_label(column_num=COLUMN_NUM_QUARTER, **kwargs)
assert_target_gender_type_value_columns(
column_num_gender_start=COLUMN_NUM_GENDER_START_BOTH,
**kwargs)
assert_target_gender_type_value_columns(
column_num_gender_start=COLUMN_NUM_GENDER_START_MALE,
**kwargs)
assert_target_gender_type_value_columns(
column_num_gender_start=COLUMN_NUM_GENDER_START_FEMALE,
**kwargs)
各関数で結構引数が共通のものが多いので、共通のものは記述を短くするためにアスタリスク二個によるキーワード引数の指定をしました。
ぼちぼち時間がかかるので、Notifyの拡張機能を設定しつつ、しばらく放置します。
チェックが全て通りましたが、問題ないようです。
実際にデータを抽出していく作業に移ります。
データの抽出作業
def get_year_list(ws, data_last_row):
"""
対象のシートの西暦の数値のリストを取得する。
Parameters
----------
ws : openpyxl.worksheet.read_only.ReadOnlyWorksheet
対象のシート。
data_last_row : int
データの最終行の行番号。
Returns
-------
years_list : list of int
西暦の値を格納したリスト。
"""
row_num = data_last_row - START_ROW_NUM + 1
target_row_num = START_ROW_NUM
years_list = []
while target_row_num <= data_last_row:
cell = ws.cell(row=target_row_num + 1, column=COLUMN_NUM_YEAR)
year = int(get_cell_value_str(cell=cell))
years_list.extend(
np.full(shape=(4,), fill_value=year, dtype=np.int).tolist()
)
target_row_num += 4
years_list = years_list[:row_num]
return years_list
まずは対象のシート内の西暦のリストを取得する処理です。
最終的なデータの行ごとに値は設定するものの、西暦の値は4セルのうち1つだけなので、残りの3つの行分は同じ値を埋める形で設定しています。
NumPyのfull関数で任意の値・任意のサイズでの配列の初期化ができるので、そちらを利用しています。
np.full(shape=(4,), fill_value=year, dtype=np.int).tolist()
また、最後の年は4件分値が入っていなかったりするので、そういった場合を加味して有効な値の行のみになるように最後に行数をスライスしています。
years_list = years_list[:row_num]
def get_column_val_list(ws, data_last_row, column_num, dtype):
"""
対象の列の値のリストを取得する。
Parameters
----------
ws : openpyxl.worksheet.read_only.ReadOnlyWorksheet
対象のシート。
data_last_row : int
データの最終行の行番号。
column_num : int
対象の列番号。
dtype : class
データの型。以下のいずれかを指定する。
- str
- int
- float
Returns
-------
data_list : list
対象の列の値を格納した1次元のリスト。
"""
data_list = []
target_row_num = START_ROW_NUM
while target_row_num <= data_last_row:
cell = ws.cell(row=target_row_num, column=column_num)
cell_value = get_cell_value_str(cell=cell)
cell_value = dtype(cell_value)
data_list.append(cell_value)
target_row_num += 1
return data_list
対象のシートの、対象列の有効な値の部分を上から下まで取得する関数です。特に説明不要な感じです。
def get_column_num_gender_start_by_type(gender_type):
"""
対象の性別種別の、列の開始番号を取得する。
Parameters
----------
gender_type : int
性別の種別値。以下のいずれかの定数を指定する。
- GENDER_TYPE_BOTH
- GENDER_TYPE_MALE
- GENDER_TYPE_FEMALE
Returns
-------
column_num_start : int
対象の性別種別の、列の開始番号。
Raises
------
ValueError
対応していない性別の種別値が指定された場合。
"""
if gender_type == GENDER_TYPE_BOTH:
return COLUMN_NUM_GENDER_START_BOTH
if gender_type == GENDER_TYPE_MALE:
return COLUMN_NUM_GENDER_START_MALE
if gender_type == GENDER_TYPE_FEMALE:
return COLUMN_NUM_GENDER_START_FEMALE
err_msg = '対応していない性別種別が指定されています : '
raise ValueError(err_msg)
男女計・男性・女性それぞれの表に対して処理を行う必要があるので、定義しておいた定数の種別値に応じて列の開始番号を取得する処理を用意しました。
def get_target_gender_table_df(sheet_name, gender_type):
"""
対象のシートの対象の性別の種別の表のデータを抽出した
データフレームを取得する。
Parameters
----------
sheet_name : str
対象のシート名。
gender_type : int
性別の種別値。以下のいずれかの定数を指定する。
- GENDER_TYPE_BOTH
- GENDER_TYPE_MALE
- GENDER_TYPE_FEMALE
Returns
-------
df : DataFrame
シート単体分の抽出されたデータのデータフレーム。カラムは、
CN_から始まる定数名のカラムが設定される。また、整数のカラムの
値に関しては INT_MULTIPLY_VAL の値分乗算された値が設定され、
パーセンテージのカラムに関しては100で除算され、0.0~1.0の
値に調整される。
"""
column_num_gender_start = get_column_num_gender_start_by_type(
gender_type=gender_type)
ws = wb[sheet_name]
data_last_row = get_data_last_row_num(ws=ws)
df = pd.DataFrame(
columns=COLUMN_NAME_LIST,
index=np.arange(START_ROW_NUM, data_last_row + 1))
df[CN_AREA] = sheet_name
df[CN_YEAR] = get_year_list(ws=ws, data_last_row=data_last_row)
df[CN_QUARTER] = get_column_val_list(
ws=ws, data_last_row=data_last_row,
column_num=COLUMN_NUM_QUARTER, dtype=str)
df[CN_GENDER] = gender_type
for index, sr in VALUE_COLUMN_INFO_DF.iterrows():
column_name = sr['column_name']
column_num = column_num_gender_start + sr['additional_column_num']
dtype=sr['dtype']
df[column_name] = get_column_val_list(
ws=ws, data_last_row=data_last_row, column_num=column_num,
dtype=dtype)
if dtype == int:
df[column_name] *= INT_MULTIPLY_VAL
continue
if dtype == float:
df[column_name] /= 100
continue
return df
用意した関数を参照して、対象のシートの性別の種別単位で、必要なデータフレームを生成する関数を用意しました。
エクセルの値が万人単位だったりしているので、その分を乗算したりなどの細かい調整が一部あります。
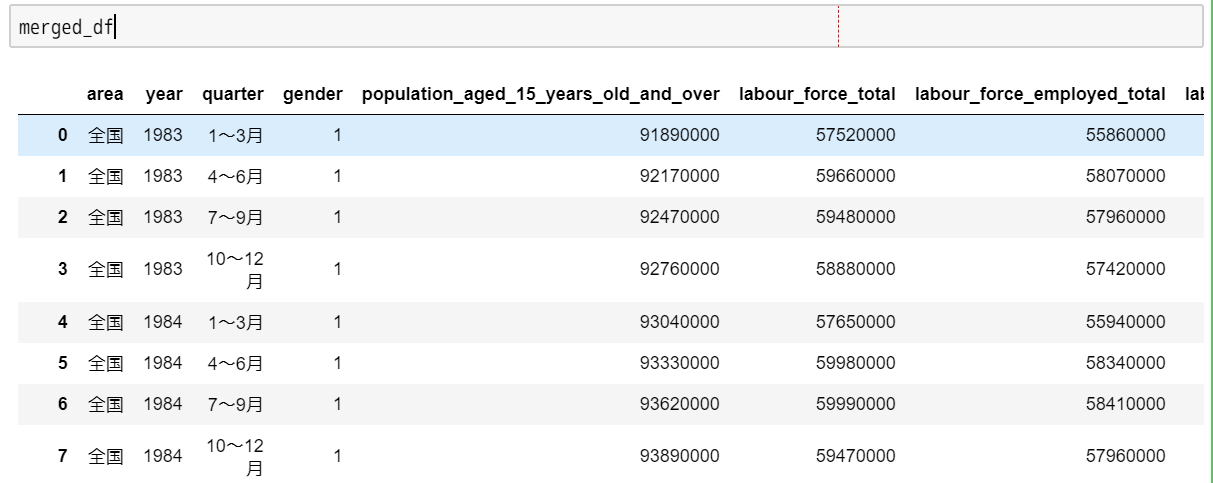
df_list = []
for sheet_name in sheet_name_list:
print(datetime.now(), sheet_name, 'started.')
df = get_target_gender_table_df(
sheet_name=sheet_name, gender_type=GENDER_TYPE_BOTH)
df_list.append(df)
df = get_target_gender_table_df(
sheet_name=sheet_name, gender_type=GENDER_TYPE_MALE)
df_list.append(df)
df = get_target_gender_table_df(
sheet_name=sheet_name, gender_type=GENDER_TYPE_FEMALE)
df_list.append(df)
merged_df = pd.concat(df_list)
merged_df.reset_index(drop=True, inplace=True)
最後にシート単位でループを回して、生成したデータフレームを統合して終わりです!
merged_df
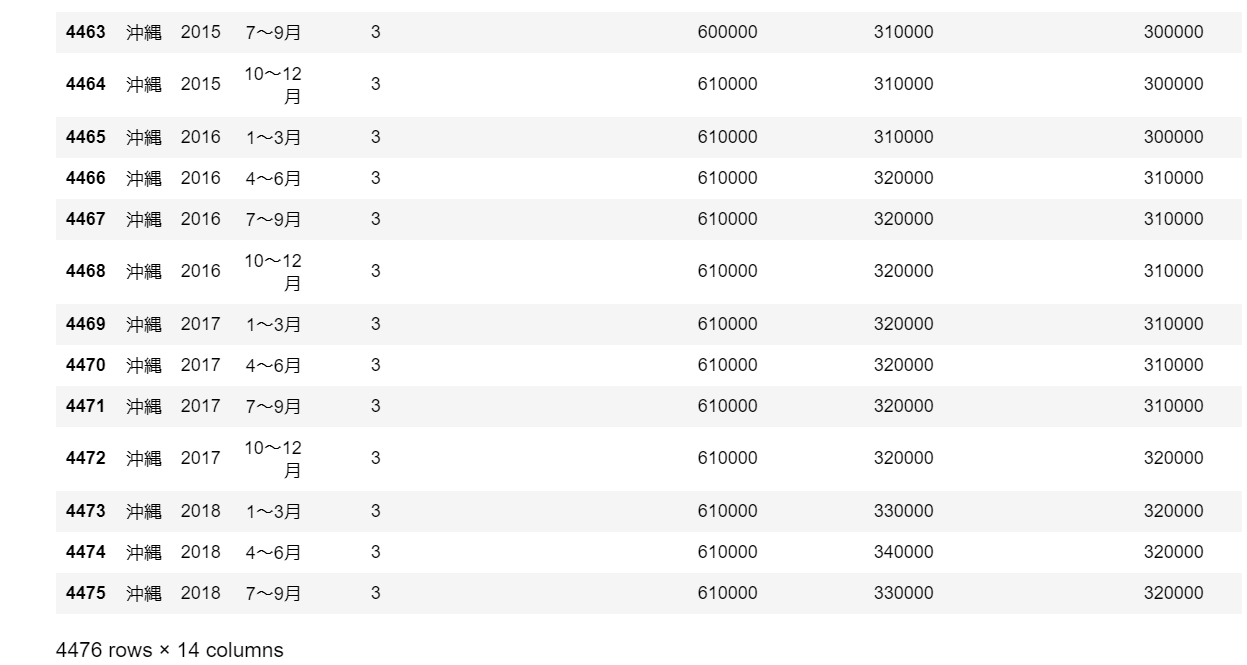
仕事だと、これに加えて単体テストを書いたり、検算したり、複雑な集計が必要な場合は各部署のデータサイエンティストさんに数値に違和感がないか確認いただいたりしますが、プライベートで記事を書いたりして遊ぶ分には省略します。
これ以上に複雑で、フォーマットもかなりばらばらでスクリプトだと厳しそうな場合はどうしよう?
エクセル方眼紙というか、神エクセルというか、そういった場合には・・お引き取り願うか、もしくは誰か綺麗に整形するライブラリとかOpenCVとか絡めた変換用の機械学習モデルとか誰か組んでくださいお願いします