今まで複雑なデータ操作・分析などはPythonでやっており、SQLは普通のアプリ開発程度のライトなものしか触って来なかったのですが、やはり分析用の長いSQLなども書けた方がやりとり等で便利・・・という印象なので、復習も兼ねて記事にしておきます。
また、SQLに加えて検算も兼ねてPythonやPandasなどを使ったコードもSQLと併記していきます(Pythonで書くとどういった記述が該当するのかの比較用として使います)。
※長くなるのでいくつかの記事に分割します。本記事は4記事目となります。
特記事項
本記事では配列関係を良く扱っていきます。その都合、Pandasなどでapplyメソッドなどを絡めた形で触れている節もあればビルトインでの記述のみしている節もあります(本記事からPandas色が少し薄くなります)。
他のシリーズ記事
Athenaとはなんぞやという方はこちらをご確認ください:
※過去の記事で既に触れたものは本記事では触れません。
#1:
用語の説明・SELECT、WHERE、ORDER BY、LIMIT、AS、DISTINCT、基本的な集計関係(COUNTやAVGなど)、Athenaのパーティション、型、CAST、JOIN、UNION(INTERSECTなど含む)など。
#2:
GROUP BY・HAVING・サブクエリ・CASE・COALESCE・NULLIF・LEAST・GREATEST・四則演算などの基本的な計算・日付と日時の各操作など。
#3:
文字列操作全般・正規表現関係など。
この記事で触れること
- コメント関係
- 配列操作全般
- ラムダ式
環境の準備
以下の#1の記事でS3へのAthena用のデータの配置やテーブルのCREATE文などのGitHubに公開しているものに関しての情報を記載していますのでそちらをご参照ください。
SQLを読みやすくする: コメント
SQL中にコメントを残すことで、なんのSQLなのか、どういった処理なのかを各所に追加していくことができます。引き継ぎや他人との共有時などにSQLを読む負担が減ります。
Athena(Presto)では以下のようなコメントの書き方がサポートされています。
インラインコメント
--以降の文字列はインラインコメントとして扱われ、SQLには影響しません。
以下のように「ログインログを10行読み込みます。」といったような説明を入れてもそのままSQLを実行できます。
-- ログインログを10行読み込みます。
SELECT * FROM athena_workshop.login LIMIT 10;
行中にコメントを追加したい場合には、行末であれば追加することができます。
SELECT * FROM athena_workshop.login LIMIT 10 -- ログインログを10行読み込みます。
ただし、セミコロンが付いている行に関してはその後にSQL関係を入力することができなくなり、コメントなども書かれているとエラーになります。Athenaではセミコロンが無くても動くので、そういった場合はセミコロンを消してしまってもいいかもしれません。
SELECT * FROM athena_workshop.login LIMIT 10; -- ログインログを10行読み込みます。
複数行のコメントを追加したい場合には複数の--の記述を各行にするか、もしくは後の節で触れるブロックコメントを利用します。
-- ログインログを10行読み込みます。
-- 日付は2021-01-01を対象とします。
SELECT * FROM athena_workshop.login
WHERE dt = '2021-01-01'
ブロックコメント
/**/の記述のアスタリスクの間に挟んだコメントはブロックコメント(複数行に対応できるコメント)になります。例えば以下のように書きます。
/* ログインログを10行読み込みます。 */
SELECT * FROM athena_workshop.login
LIMIT 10
アスタリスクの間は自由に改行などを含めることができます。毎行--などの記述をしなくて済みますし、コメント部分のテキストのコピーなどをしたい場合などにも--などが紛れ込まないので複数行の場合にはこちらの方が快適なケースがあります。
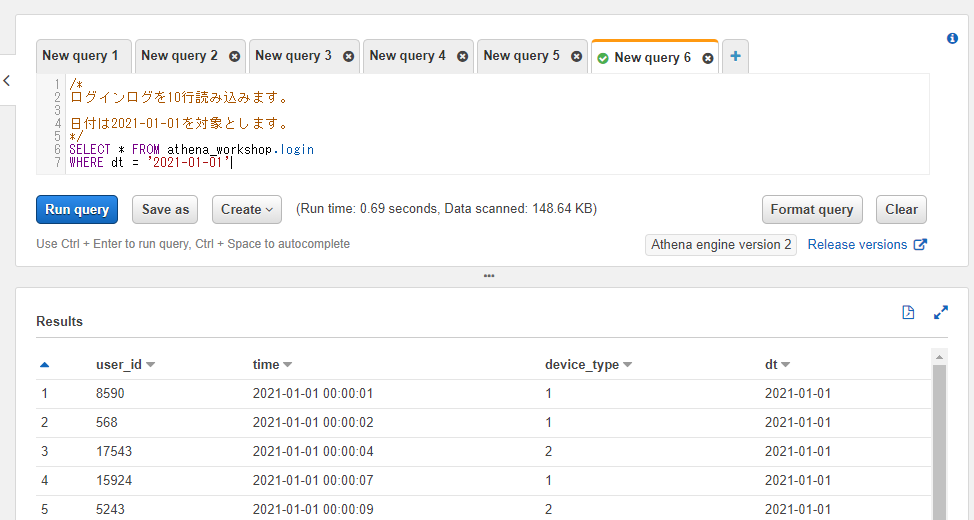
/*
ログインログを10行読み込みます。
日付は2021-01-01を対象とします。
*/
SELECT * FROM athena_workshop.login
WHERE dt = '2021-01-01'
配列の操作
この節以降では配列(Array)操作について色々触れていきます。
配列の固定値の扱い方
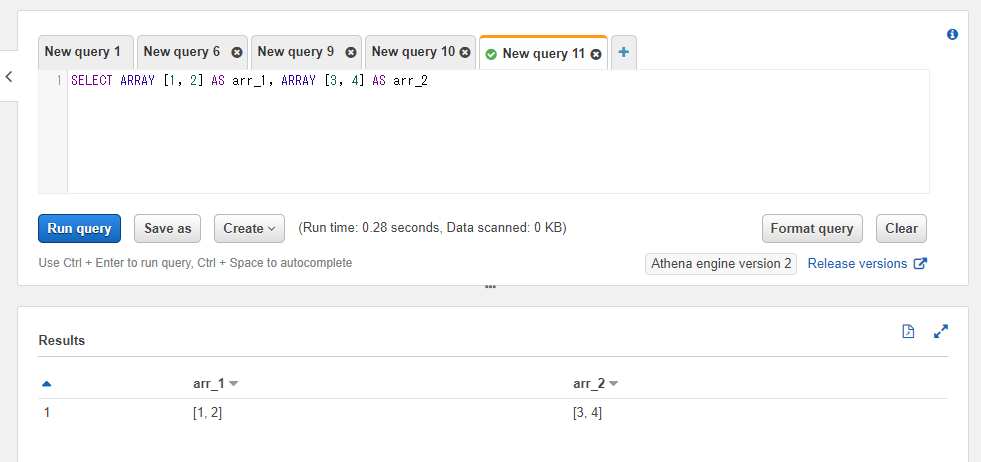
配列の固定値を作りたい場合にはARRAY [配列の値]という書き方をすることでカラムを設定することができます。例えば1, 2という値を格納した配列と3, 4という値を格納した配列の2つを得たい場合には以下のようにSQLを実行することで配列の固定値を取得することができます。
SELECT ARRAY [1, 2] AS arr_1, ARRAY [3, 4] AS arr_2
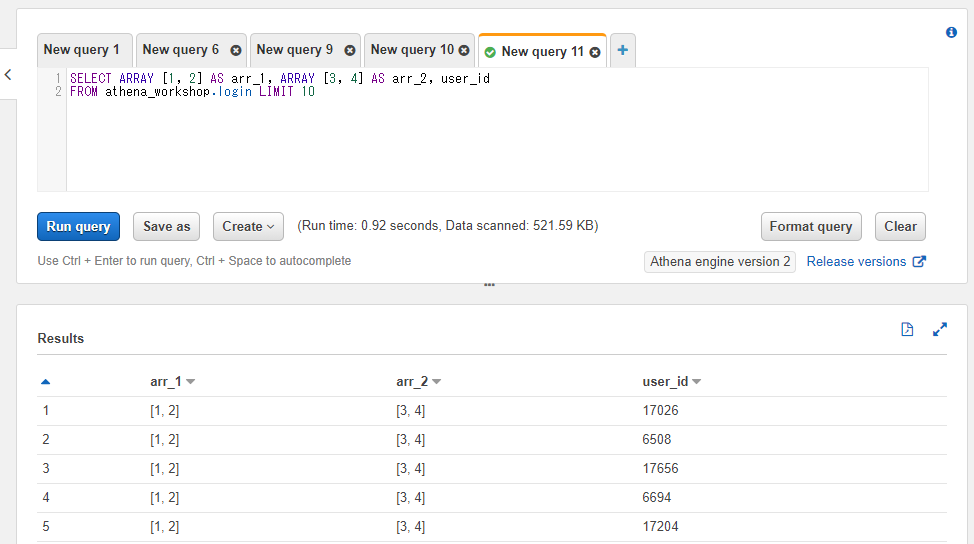
特定のテーブルと一緒に使った場合、各行に対してこの固定値が設定されます。
SELECT ARRAY [1, 2] AS arr_1, ARRAY [3, 4] AS arr_2, user_id
FROM athena_workshop.login LIMIT 10
Pythonでの書き方
Pandasを初期化する際にカラムに配列などが含まれていればそのまま配列の値を持ったデータフレームが作れるのですが、途中から配列の固定値のカラムを追加する場合、固定のスカラ値などを直接代入するケースと同じようにはストレートにいきません。配列の各値を各行に設定する・・・みたいな挙動になるため、リストなどを代入しようとするとデータフレームとリストの行数が一致していないとエラーになります。
例えば以下のように[1, 2]という配列の固定値をarr_1というカラムに設定しようとすると行数の不一致によるエラーになります。
import pandas as pd
import numpy as np
df: pd.DataFrame = pd.read_json(
'https://github.com/simon-ritchie/athena_workshop/blob/main/workshop/login/dt%3D2021-01-01/data.json.gz?raw=true',
lines=True, compression='gzip')
df['arr_1'] = [1, 2]
ValueError: Length of values (2) does not match length of index (24453)
色々対策として書き方はあると思いますが、1つの対応としてリスト内包表記などを使って行数を揃えてしまう・・・というのがシンプルかもしれません。この辺は探せばもっとシンプルなPandasのインターフェイスがあるような気がしないでもないです。
import pandas as pd
import numpy as np
df: pd.DataFrame = pd.read_json(
'https://github.com/simon-ritchie/athena_workshop/blob/main/workshop/login/dt%3D2021-01-01/data.json.gz?raw=true',
lines=True, compression='gzip')
df['arr_1'] = [[1, 2] for _ in range(len(df))]
print(df[['user_id', 'arr_1']].head())
user_id arr_1
0 8590 [1, 2]
1 568 [1, 2]
2 17543 [1, 2]
3 15924 [1, 2]
4 5243 [1, 2]
||記号による配列の連結
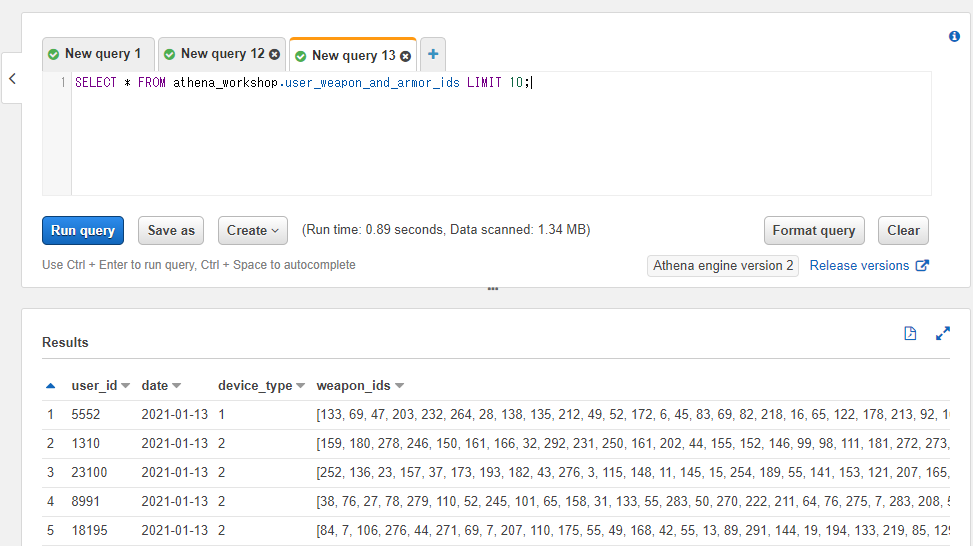
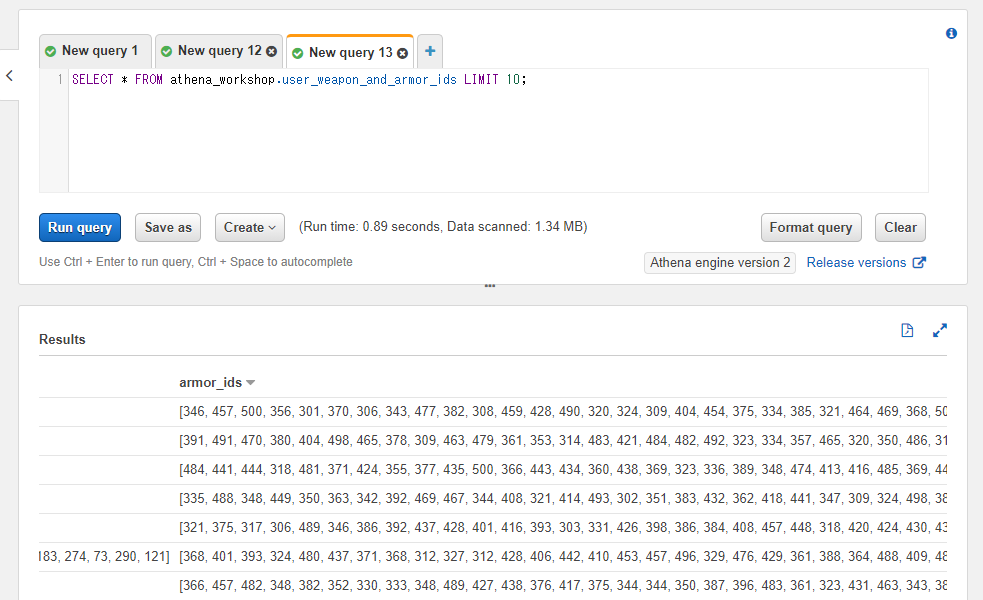
※以降の節ではuser_weapon_and_armor_idsというテーブルを扱っていきます。基本的なカラムに加えてweapon_idsとarmor_idsという2つのカラムを持っており、それぞれ所持武器と所持防具のマスタIDを想定した整数の配列を格納させています。
以下のようなデータになっています(armor_idsカラムの方がスクショ内に収まらないのでスクロールして2枚スクショを貼っています)。分かりやすいようにarmor_idsの方が大きな整数値のIDを設定しています。
SELECT * FROM athena_workshop.user_weapon_and_armor_ids LIMIT 10;
配列同士は||記号で連結することができます。
例えば2つの配列のカラムを連結したい・・・といった場合には以下のように書きます(concatenated_idsという1つのカラムに変換しています)。
SELECT weapon_ids || armor_ids AS concatenated_ids
FROM athena_workshop.user_weapon_and_armor_ids
LIMIT 10;
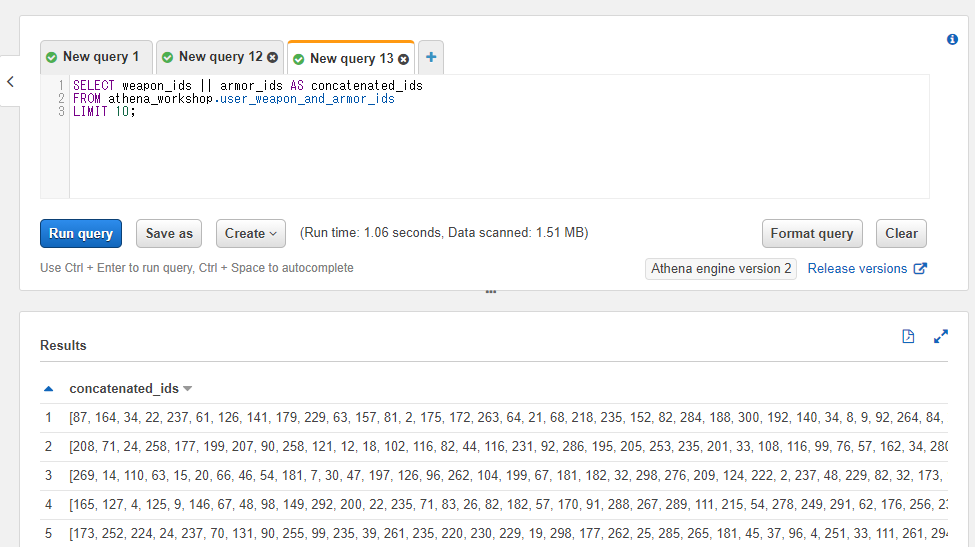
後半がarmor_idsカラムの大きな値になっていることが確認できます。
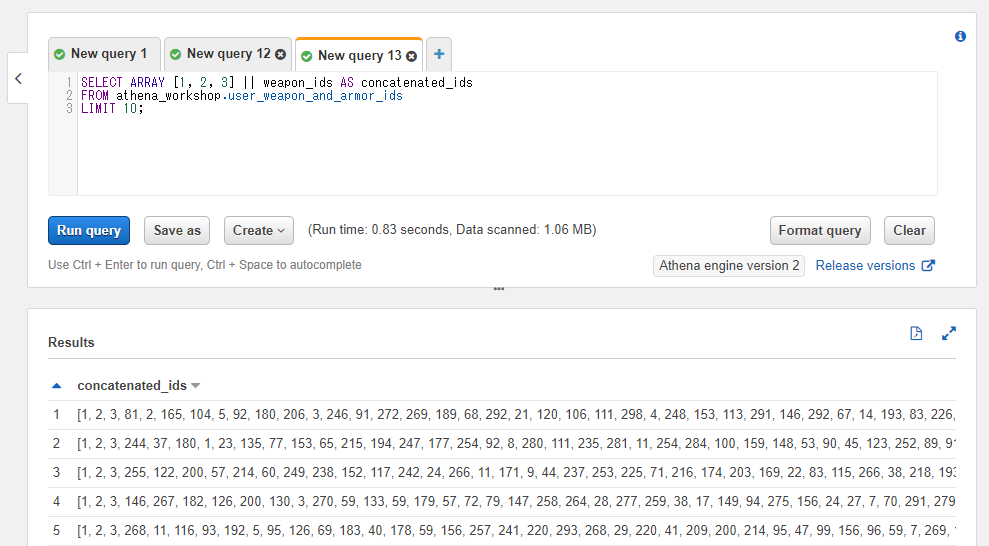
また、固定値との連結もできます。
以下のSQLでは[1, 2, 3]という配列とweapon_idsというカラムの配列を連結しています。連結されて結果の配列の先頭が1, 2, 3からスタートしていることが確認できます。
SELECT ARRAY [1, 2, 3] || weapon_ids AS concatenated_ids
FROM athena_workshop.user_weapon_and_armor_ids
LIMIT 10;
Pythonでの書き方
Pandasは基本的に各インターフェイスが行列前提のものが多く、リストの値を含んだデータフレームのための連結関係のインターフェイスは無い・・・?気がしますので、applyなりループを回したりで対応する必要があるかなという所感です(しっかり探せばその辺のインターフェイスもあるかもしれません)。
その辺は別の記事で書いたり、もしくはループで回したときのパフォーマンス関係をご共有いただいたりしているので必要に応じてそちらもご確認ください。
以下はループで回す場合の書き方例です。
from typing import List
import pandas as pd
df: pd.DataFrame = pd.read_json(
'https://github.com/simon-ritchie/athena_workshop/blob/main/workshop/user_weapon_and_armor_ids/dt%3D2021-01-01/data.json.gz?raw=true',
lines=True, compression='gzip')
weapon_ids: List[List[int]] = df['weapon_ids'].tolist()
armor_ids: List[List[int]] = df['armor_ids'].tolist()
concatenated_ids: List[List[int]] = []
for single_weapon_ids, single_armor_ids in zip(weapon_ids, armor_ids):
single_weapon_ids.extend(single_armor_ids)
concatenated_ids.append(single_weapon_ids)
df['concatenated_ids'] = concatenated_ids
print(df['concatenated_ids'].head())
print(df.at[0, 'concatenated_ids'])
Name: concatenated_ids, dtype: object
0 [240, 65, 157, 257, 51, 266, 211, 208, 257, 35...
1 [45, 123, 75, 271, 87, 298, 156, 243, 80, 57, ...
2 [85, 30, 163, 151, 142, 93, 229, 258, 101, 6, ...
3 [7, 128, 288, 157, 277, 279, 257, 202, 230, 97...
4 [20, 216, 19, 7, 189, 283, 131, 63, 48, 281, 5...
[240, 65, 157, 257, 51, 266, 211, 208, 257, 35, 187, 94, 264, 267, 18, 248, 70, 185, 156, 293, 96, 65, 143, 195, 115, 117, 107, 160, 299, 249, 85, 39, 259, 12, 207, 92, 290, 297, 152, 121, 57, 134, 182, 38, 60, 138, 244, 215, 223, 79, 208, 97, 87, 38, 160, 80, 170, 240, 206, 225, 155, 210, 245, 36, 55, 117, 14, 112, 215, 252, 236, 232, 284,
...
450, 343, 386, 425, 492, 456, 332, 475, 413, 452, 469, 477, 386, 452, 346, 444, 392, 418, 311, 466, 470, 442, 368, 319, 378, 476, 368, 491, 498, 497, 433, 337, 359, 346, 398, 446, 411, 333, 494, 500, 397, 402, 355, 317, 392, 498, 407, 499, 431, 466, 441, 458, 444, 338, 350, 440, 500, 392, 339, 447, 343, 326, 422, 345, 351]
CONCAT関数による配列の連結
CONCAT関数でも||の記号を使った場合と同じように複数の配列を連結することができます。各引数に連結したい配列を指定します。2つ以上の配列も指定することができます。
以下のSQLでは[1, 2, 3]という固定値の配列とweapon_idsカラム、armor_idsカラムと3つの配列を連結しています。
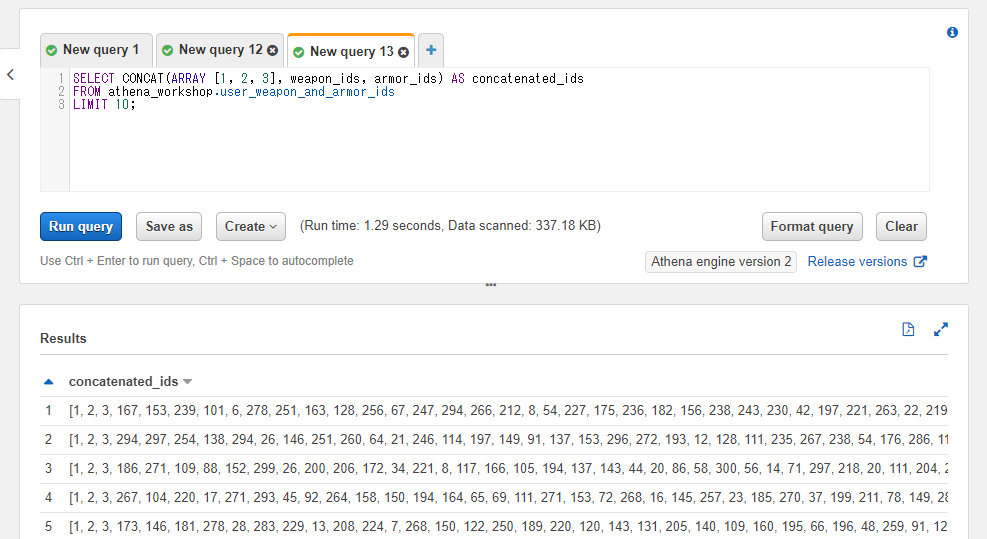
SELECT CONCAT(ARRAY [1, 2, 3], weapon_ids, armor_ids) AS concatenated_ids
FROM athena_workshop.user_weapon_and_armor_ids
LIMIT 10;
[]記号による配列の特定の位置の値へのアクセス
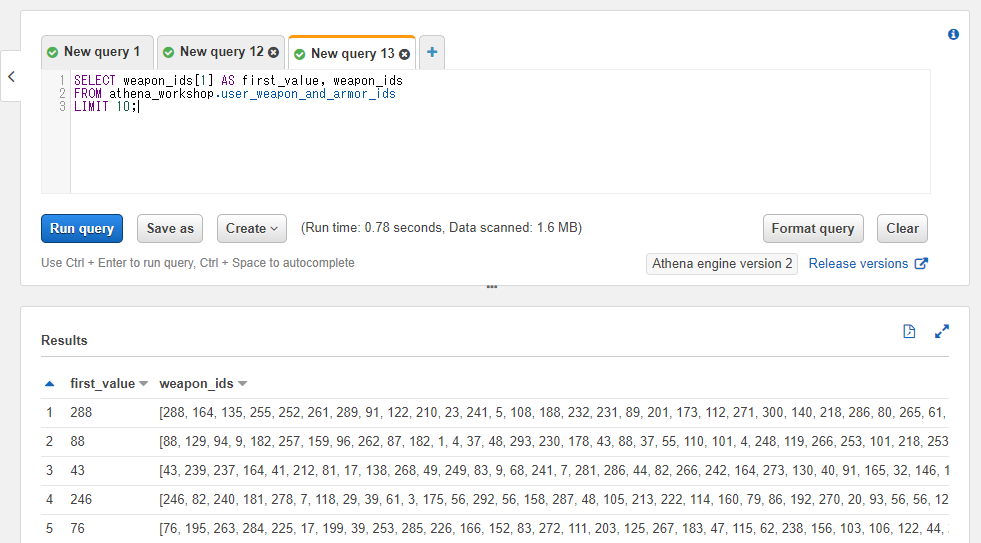
配列のカラムや固定値などに対して[]の括弧と整数を指定することで、配列の特定の位置の値にアクセスすることができます(添え字 / インデックスによるアクセス)。
なお、Athena(Presto)では配列のインデックスは1スタートとなります。jsやPythonのように0スタートではなく、Juliaなどのような挙動になるので注意が必要です。
SELECT weapon_ids[1] AS first_value, weapon_ids
FROM athena_workshop.user_weapon_and_armor_ids
LIMIT 10;
以下のSQLでは配列の先頭の値を取得しています。
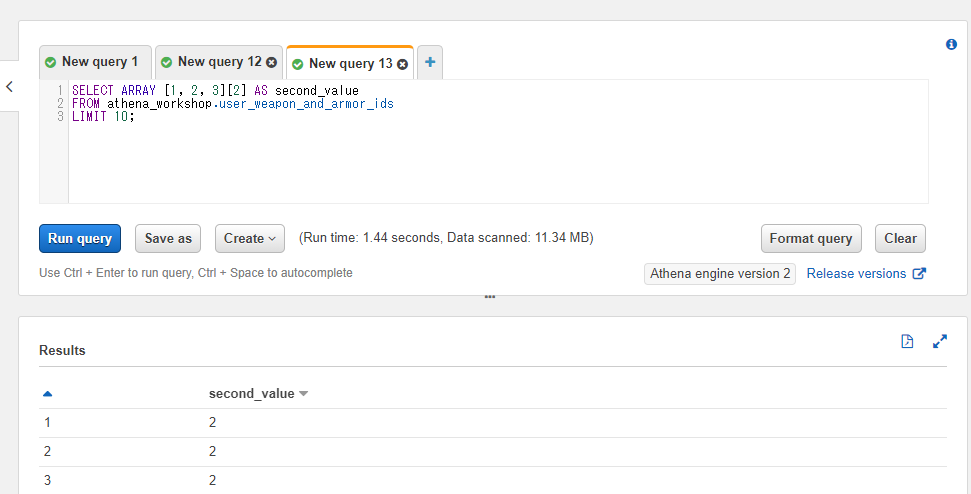
配列の固定値を使った場合にもインデックスの指定が効くようです。以下のSQLでは1, 2, 3という固定値の配列の2番目の値を取得しています。
SELECT ARRAY [1, 2, 3][2] AS second_value
FROM athena_workshop.user_weapon_and_armor_ids
LIMIT 10;
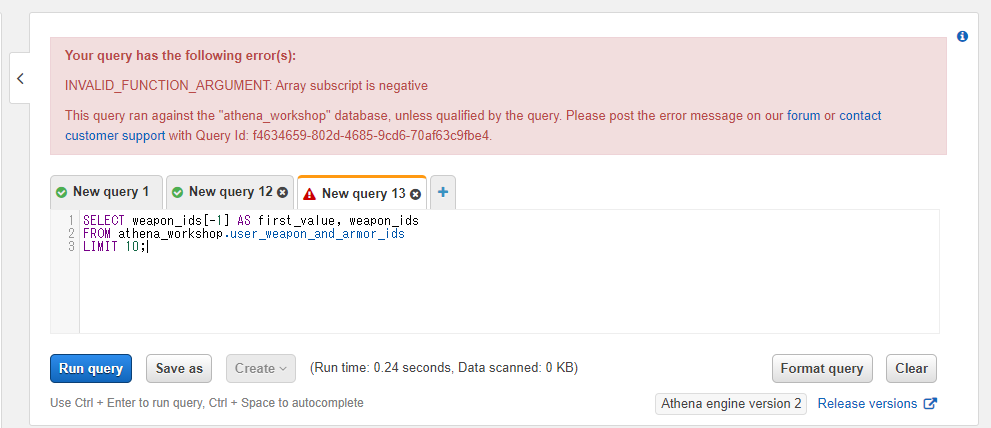
なお、Pythonなどのように負のインデックスを指定して配列の末尾からアクセスするといったことはできません。エラーになります。
SELECT weapon_ids[-1] AS first_value, weapon_ids
FROM athena_workshop.user_weapon_and_armor_ids
LIMIT 10;
ELEMENT_AT関数による配列の特定の位置の値へのアクセス
[]の括弧による特定の位置の配列の値へのアクセスと同じようなことがELEMENT_AT関数で出来ます。
第一引数に対象のカラムもしくは固定値、第二引数に値の位置のインデックスを指定します。こちらも値の位置のインデックスは1からスタートします。
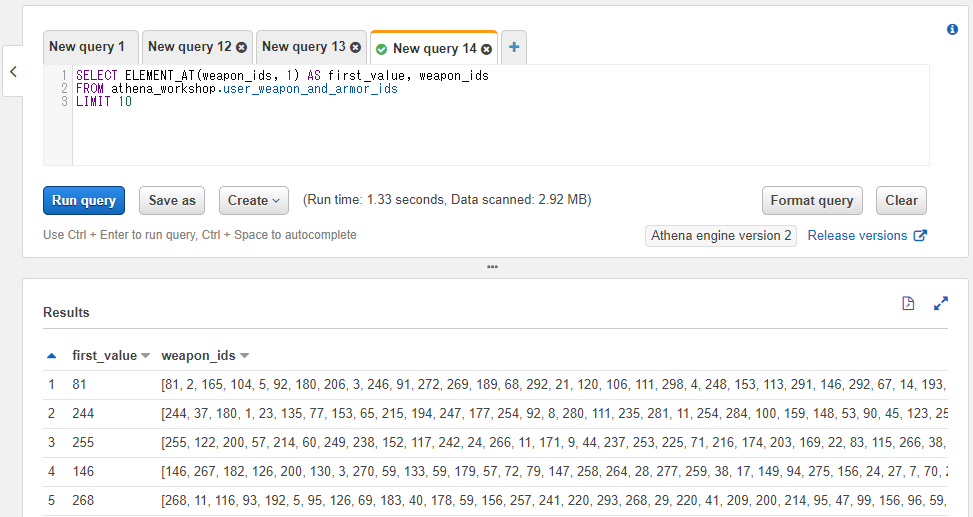
SELECT ELEMENT_AT(weapon_ids, 1) AS first_value, weapon_ids
FROM athena_workshop.user_weapon_and_armor_ids
LIMIT 10
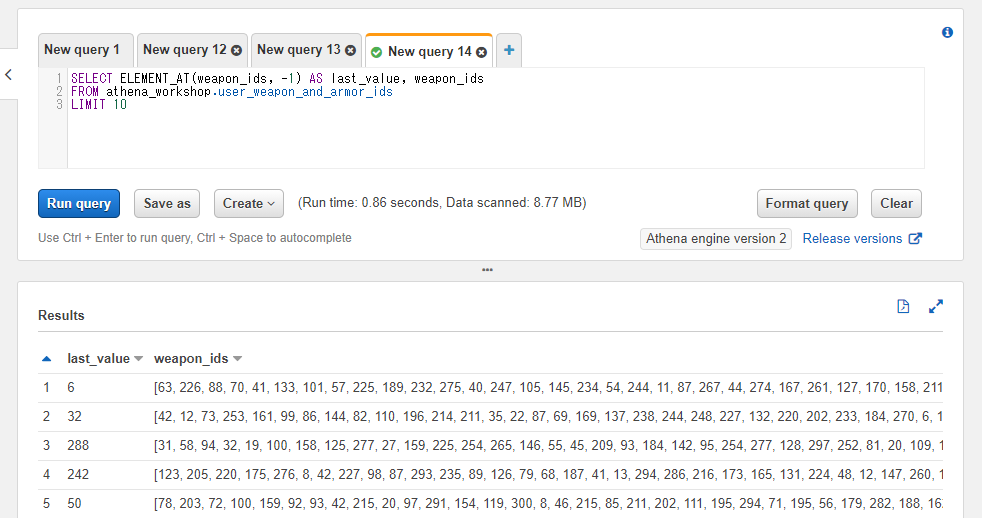
特筆すべき点として、[]の括弧では使えなかった負のインデックスの指定がPythonと同様に使えます。負の値を指定した場合は配列の末尾からカウントされます。例えば-1を指定すれば配列の最後の値が対象となり、-2を指定すれば配列の最後から二番目の値の位置となります。
SELECT ELEMENT_AT(weapon_ids, -1) AS last_value, weapon_ids
FROM athena_workshop.user_weapon_and_armor_ids
LIMIT 10
Pythonでの書き方
※Pandasが基本的に行列を扱うという性質上、ここからしばらくはデータフレーム内の配列への処理としてPythonビルトインの処理とapplyメソッドなどを絡めた書き方が多くなると思います。
特定の配列のインデックスの値を取得する関数を定義し、データフレームのapplyメソッドでそちらの関数を指定することで同じようなことができます。applyメソッドには任意のキーワード引数で固定値も渡すことができるので、今回はindexという引数を設定しています。
from typing import List, Optional
import pandas as pd
df: pd.DataFrame = pd.read_json(
'https://github.com/simon-ritchie/athena_workshop/blob/main/workshop/user_weapon_and_armor_ids/dt%3D2021-01-01/data.json.gz?raw=true',
lines=True, compression='gzip')
def element_at(list_value: List[int], index: int) -> Optional[int]:
"""
指定されたインデックス位置の値をリストから取得する。
Parameters
----------
list_value : list of int
対象のリスト。
index : int
対象のインデックス。
Returns
-------
value : int or None
指定されたインデックス位置の値。インデックス範囲外の場合には
Noneが返却される。
"""
if index >= len(list_value):
return None
value: int = list_value[index]
return value
df['first_value'] = df['weapon_ids'].apply(element_at, index=0)
print(df[['first_value', 'weapon_ids']].head())
first_value weapon_ids
0 240 [240, 65, 157, 257, 51, 266, 211, 208, 257, 35...
1 45 [45, 123, 75, 271, 87, 298, 156, 243, 80, 57, ...
2 85 [85, 30, 163, 151, 142, 93, 229, 258, 101, 6, ...
3 7 [7, 128, 288, 157, 277, 279, 257, 202, 230, 97...
4 20 [20, 216, 19, 7, 189, 283, 131, 63, 48, 281, 5...
重複を除いた形での2つの配列の連結を行う: ARRAY_UNION
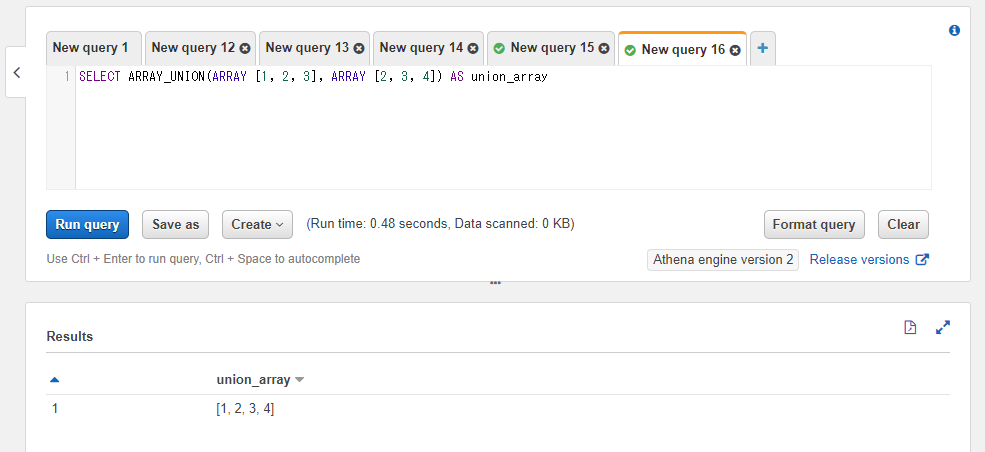
ARRAY_UNION関数を使うと2つの配列を重複を除いた形で連結した配列を取得することができます。第一引数に1つ目の配列、第二引数に2つ目の配列を指定します。
例えば以下のSQLでは1, 2, 3という値を含んだ配列と2, 3, 4という値を含んだ配列を指定しています。2と3の部分は重複していますが連結結果は1, 2, 2, 3, 3, 4といった値にはならずに1, 2, 3, 4という配列になります。
SELECT ARRAY_UNION(ARRAY [1, 2, 3], ARRAY [2, 3, 4]) AS union_array
Pythonでの書き方
処理自体はapplyもしくはループで回すとして(以下のサンプルではループで回しています)、ビルトインのset関数にリストを渡すと一意な値が取れます。型はlistではなくなるので、setで変換後に再度listに変換しています。[*a, *b]といった記述で二つ以上のリストを連結したコピーを得られるのでそちらをsetの引数に使っています。
from typing import List
import pandas as pd
df: pd.DataFrame = pd.DataFrame(
data=[{'a': [1, 2, 3], 'b': [2, 3, 4]}])
a_list: List[List[int]] = df['a'].tolist()
b_list: List[List[int]] = df['b'].tolist()
union_list: List[List[int]] = []
for a, b in zip(a_list, b_list):
union_list.append(list(set([*a, *b])))
df['union_array'] = union_list
print(df)
a b union_array
0 [1, 2, 3] [2, 3, 4] [1, 2, 3, 4]
値を繰り返した配列を取得する: REPEAT
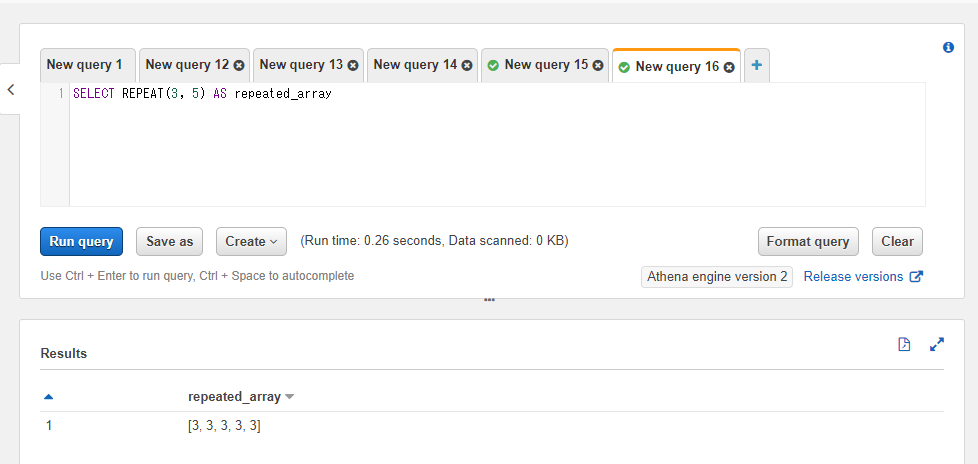
REPEAT関数は第一引数で指定された値を第二引数に指定された回数分繰り返した配列を取得します。第一引数には色々な型の値を指定できます。第二引数には整数が必要になります。
例えば以下のSQLでは整数の3という値を5回繰り返すSQLを実行しています。
SELECT REPEAT(3, 5) AS repeated_array
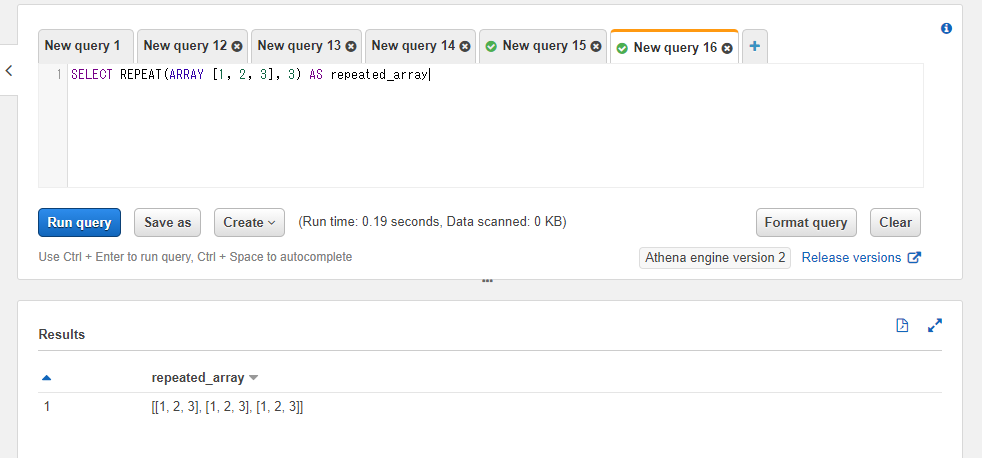
整数以外でも、例えば配列の繰り返しなどもできます。以下のSQLでは[1, 2, 3]という配列を3回繰り返しています。結果は[1, 2, 3, 1, 2, 3, 1, 2, 3]という1次元の配列ではなく[[1, 2, 3], [1, 2, 3], [1, 2, 3]]という2次元の配列になります。
SELECT REPEAT(ARRAY [1, 2, 3], 3) AS repeated_array
Pythonでの書き方
※以降の節ではデータフレームを絡めない形で触れるケースも出てきますが、前節までのapplyやループなどでデータフレームに設定することでデータフレーム側にも同じようなことができます。
リストを乗算するとリストの値を繰り返した値になります。例えば以下のようにすると3の値を5回繰り返したリストになります。
print([3] * 5)
[3, 3, 3, 3, 3]
SQLのように[[1, 2, 3], [1, 2, 3], [1, 2, 3]]といった二次元配列を得たければ与えるリストも2次元にしておくことで対応ができます。
print([[1, 2, 3]] * 3)
[[1, 2, 3], [1, 2, 3], [1, 2, 3]]
ARRAY_AVERAGE や ARRAY_SUM などの配列への要約統計量用の関数について
Prestoのドキュメントには配列の平均値を計算するARRAY_AVERAGEや合計値を計算するARRAY_SUMなどの関数があるのですが、これらはどうやらAthena上ではまだ利用できないようです。将来のアップデートで反映されるかもとは思いますが、本記事でもそれらの関数は触れずに進めます。
配列の各値の最大値を取る: ARRAY_MAX
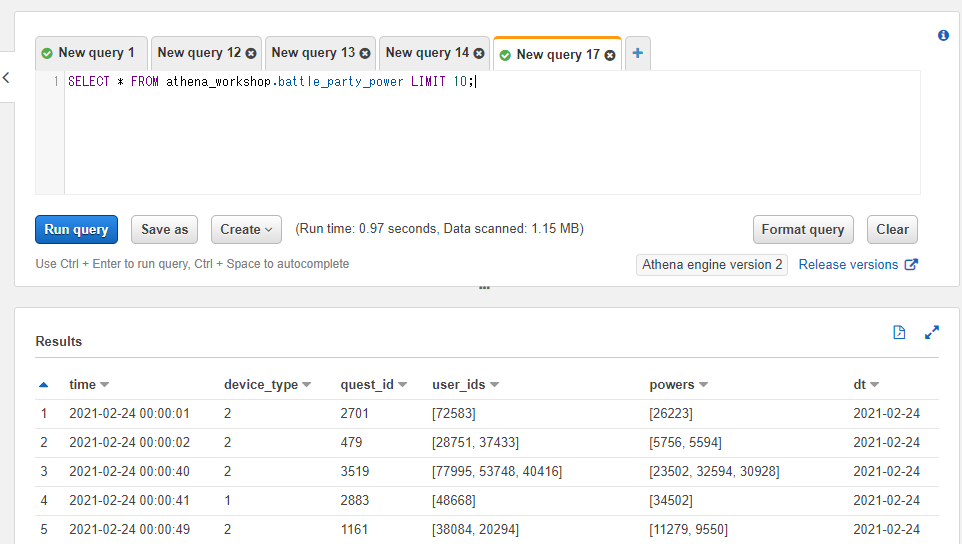
※この節以降ではbattle_party_powerというテーブルを説明のために使っていきます。クエスト(バトル)ごとのパーティーメンバーのIDと装備やレベルに応じた戦闘力を想定した値を格納しています。基本的なカラムに加えて以下のようなカラムを持っています。
- quest_id -> 対象のクエストのIDの整数。
- user_ids -> パーティーメンバーのユーザーIDの整数の配列。
- powers -> パーティーメンバーの戦闘力の整数の配列。
以下のようなデータになっています。
SELECT * FROM athena_workshop.battle_party_power LIMIT 10;
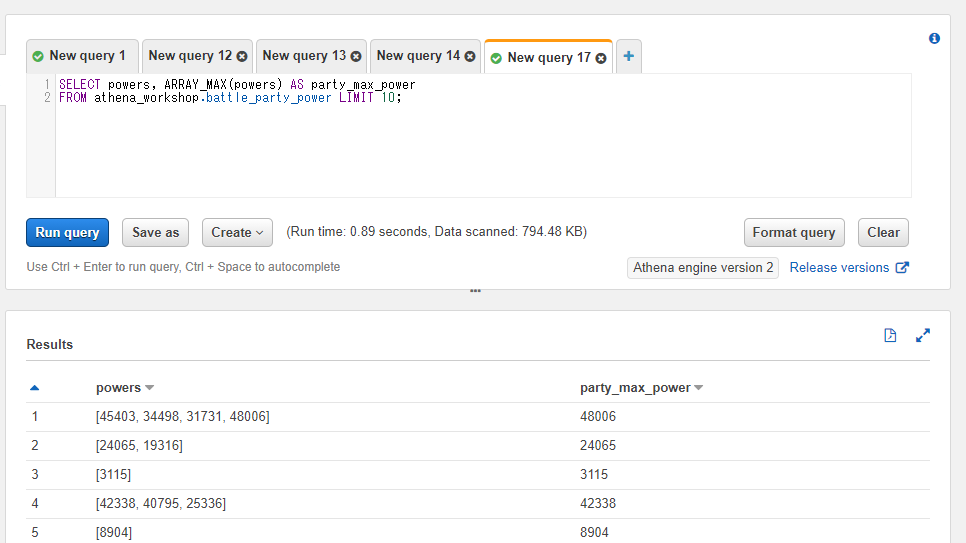
ARRAY_MAX関数を使うと配列の値の中での最大値を取得することができます。
以下のSQLではパーティーの戦闘力の中で一番戦闘力が高い値を取得しています。
SELECT powers, ARRAY_MAX(powers) AS party_max_power
FROM athena_workshop.battle_party_power LIMIT 10;
Pythonでの書き方
シンプルにビルトインのmax関数をapplyメソッドに指定するだけで対応ができます。
import pandas as pd
df: pd.DataFrame = pd.read_json(
'https://github.com/simon-ritchie/athena_workshop/blob/main/workshop/battle_party_power/dt%3D2021-01-01/data.json.gz?raw=true',
lines=True, compression='gzip')
df['max_power'] = df['powers'].apply(max)
print(df[['max_power', 'powers']].head())
max_power powers
0 41013 [41013, 34983]
1 30252 [26151, 29020, 30252]
2 10269 [10269, 8786, 8179, 6633]
3 18561 [18561]
4 50078 [34067, 50078, 37768]
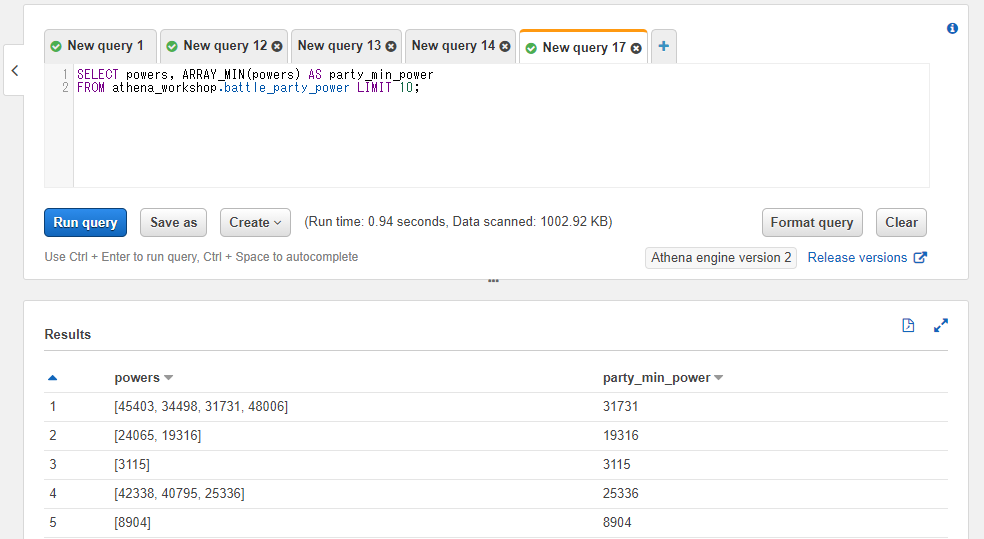
配列の各値の最小値を取る: ARRAY_MIN
ARRAY_MIN関数を使うと配列内の最小値を取得することができます。
以下のSQLではパーティーの戦闘力の中で一番戦闘力が低い値を取得しています。
SELECT powers, ARRAY_MIN(powers) AS party_min_power
FROM athena_workshop.battle_party_power LIMIT 10;
Pythonでの書き方
こちらも最大値算出の時と同じように、ビルトインのmin関数をapplyメソッドの引数に指定するだけで対応ができます。
import pandas as pd
df: pd.DataFrame = pd.read_json(
'https://github.com/simon-ritchie/athena_workshop/blob/main/workshop/battle_party_power/dt%3D2021-01-01/data.json.gz?raw=true',
lines=True, compression='gzip')
df['min_power'] = df['powers'].apply(min)
print(df[['min_power', 'powers']].head())
min_power powers
0 34983 [41013, 34983]
1 26151 [26151, 29020, 30252]
2 6633 [10269, 8786, 8179, 6633]
3 18561 [18561]
4 34067 [34067, 50078, 37768]
配列の特定範囲の値の配列を取得する: SEQUENCE
SEQUENCE関数は特定の値の範囲の配列を取得することができます。連番生成などに使います。
第一引数には開始値となる数値(後述しますが、日付や日時でも対応ができます)、第二引数に終了値となる数値を指定します。返却値は配列となります。
例えば第一引数に1、第二引数に5を指定すると[1, 2, 3, 4, 5]という配列が返ってきます。
SELECT SEQUENCE(1, 5) AS sequence_value
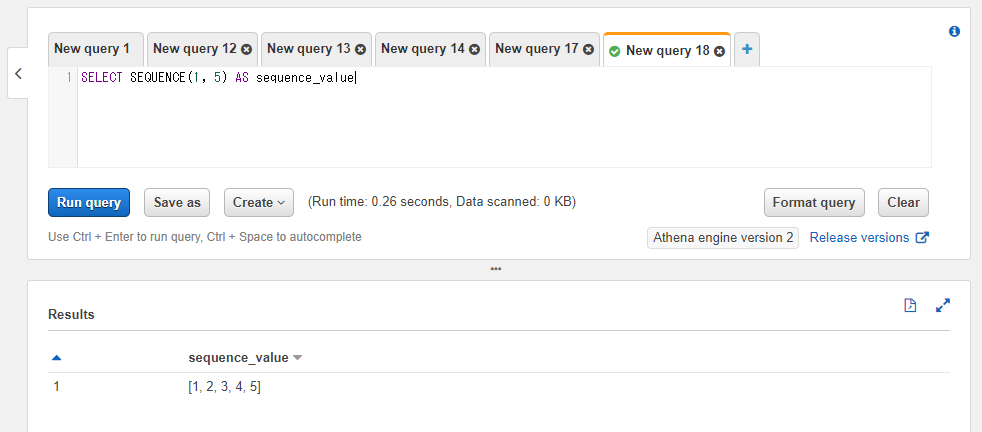
終了値が開始値よりも小さい場合は減算処理が実行される形で連番が生成されます。例えば開始値に3、終了値に-3を指定すれば[3, 2, 1, 0, -1, -2, -3]という配列結果が得られます。
SELECT SEQUENCE(3, -3) AS sequence_value
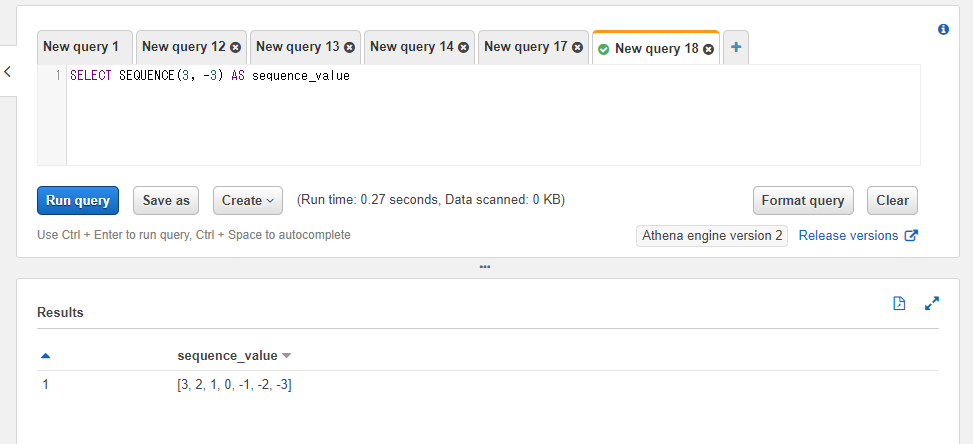
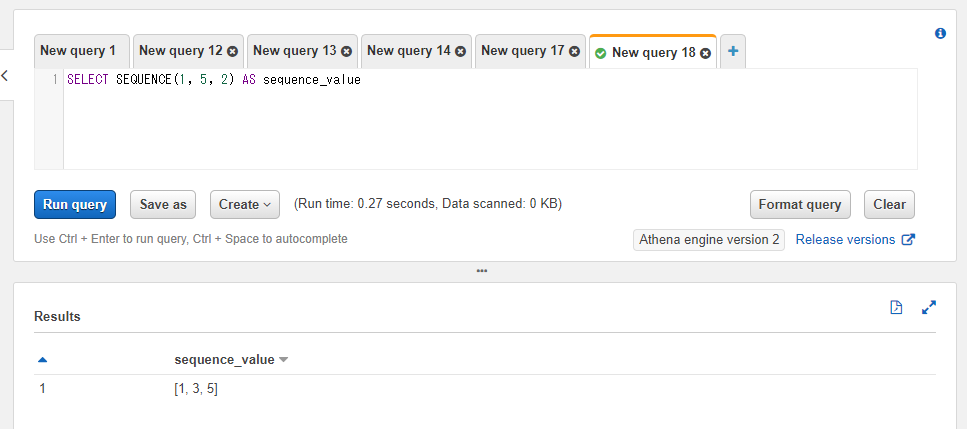
また、第三引数に整数を指定した場合連番のステップを設定することができます。例えは2ずつ増加させるといった制御になります。
SELECT SEQUENCE(1, 5, 2) AS sequence_value
Pythonでの書き方
ビルトインのrange関数を使うと連番の値を取得できます。主にループ処理などで使われますが、list関数を通してリストにキャストすれば連番の配列としても使えます。注意点として、第二引数に指定した値の1つ手前の値が最終値となるため、最終値に対して1大きい値を第二引数に指定する必要があります(Pythonだとインデックスが0からスタートするので、range(0, 5)とすれば最終値は4となり件数も5件となる・・・といった挙動になります)。
print(list(range(1, 6)))
[1, 2, 3, 4, 5]
第三引数もSQL側と同様にステップの設定となります。
print(list(range(1, 6, 2)))
[1, 3, 5]
特定の日付範囲の配列を取得する: SEQUENCE
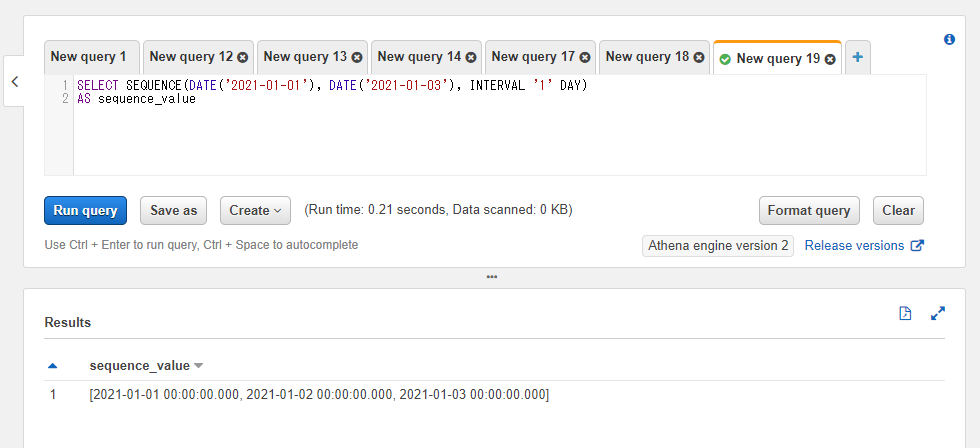
SEQUENCE関数には日付を開始値と終了値に指定することもできます。開始日~終了日の範囲の配列を得られます。ただし結果の配列の値はDATEではなくTIMESTAMPになるようです。
第三引数にはINTERVALで種類(日数や月数など)や数値(日数値など)を指定します。この辺は以前の記事で触れた日時関係の操作のものと同じなのでそちらをご確認ください。
SELECT SEQUENCE(DATE('2021-01-01'), DATE('2021-01-03'), INTERVAL '1' DAY)
AS sequence_value
なお、第三引数は整数を指定した時とは異なり省略できません(日付を指定したから1日ずつ・・・とはなりません)。省略するとエラーになります。
SELECT SEQUENCE(DATE('2021-01-01'), DATE('2021-01-03'))
AS sequence_value
Pythonでの書き方
Pandasのdate_range関数を使うと日付の範囲を取れます。
import pandas as pd
print(pd.date_range(start='2021-01-01', end='2021-01-03'))
DatetimeIndex(['2021-01-01', '2021-01-02', '2021-01-03'], dtype='datetime64[ns]', freq='D')
返却値はDatetimeIndexという特殊な値になっているので、リストの方が良ければシリーズやndarrayなどと同じようにtolistメソッドで変換できます。
import pandas as pd
print(pd.date_range(start='2021-01-01', end='2021-01-03').tolist())
[Timestamp('2021-01-01 00:00:00', freq='D'), Timestamp('2021-01-02 00:00:00', freq='D'), Timestamp('2021-01-03 00:00:00', freq='D')]
特定の日時範囲の配列を取得する: SEQUENCE
日時(TIMESTAMP)を第一引数と第二引数に指定する形でもSEQUENCE関数は使えます。使い方と挙動はほぼ日付を指定した時と同じです。
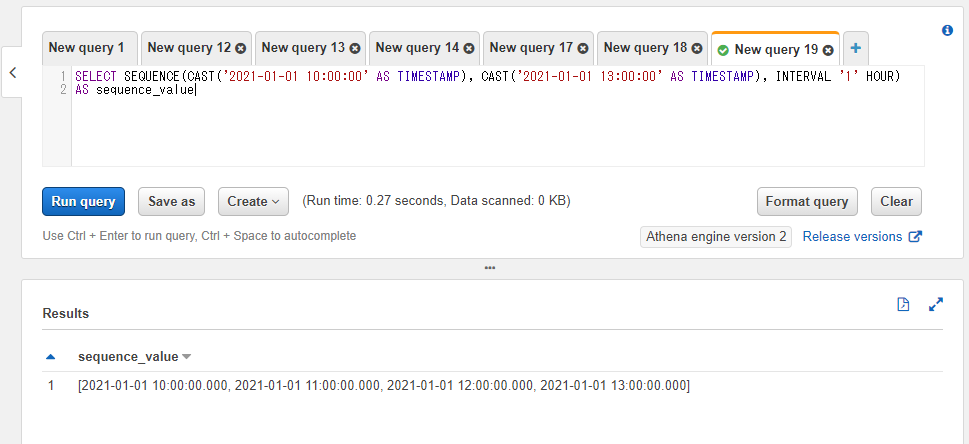
以下のSQLでは10時~13時の間で1時間ごとに4件の配列を取得しています。
SELECT SEQUENCE(CAST('2021-01-01 10:00:00' AS TIMESTAMP), CAST('2021-01-01 13:00:00' AS TIMESTAMP), INTERVAL '1' HOUR)
AS sequence_value
Pythonでの書き方
日付と同様にdate_range関数を使います。日付の時に加えてfreq引数にHを指定すると1時間単位で値が返ってきます。
import pandas as pd
date_range: pd.DatetimeIndex = pd.date_range(
start='2021-01-01 10:00:00',
end='2021-01-01 13:00:00',
freq='H')
print(date_range)
DatetimeIndex(['2021-01-01 10:00:00', '2021-01-01 11:00:00',
'2021-01-01 12:00:00', '2021-01-01 13:00:00'],
dtype='datetime64[ns]', freq='H')
配列の特定の位置から特定の件数の値を格納した配列を取得する: SLICE
SLICE関数は配列の特定の開始位置から任意の件数分の値を格納した配列を抽出することができます。第一引数には対象の配列もしくは固定値、第二引数には配列の開始位置の整数、第三引数には値の件数を指定します。
第二引数の開始位置は1からスタートします。0ではありません。
対象が存在しない場合(1件の値しかない配列で2番目以降の値を指定した場合など)には結果の行の値は空の配列となります。
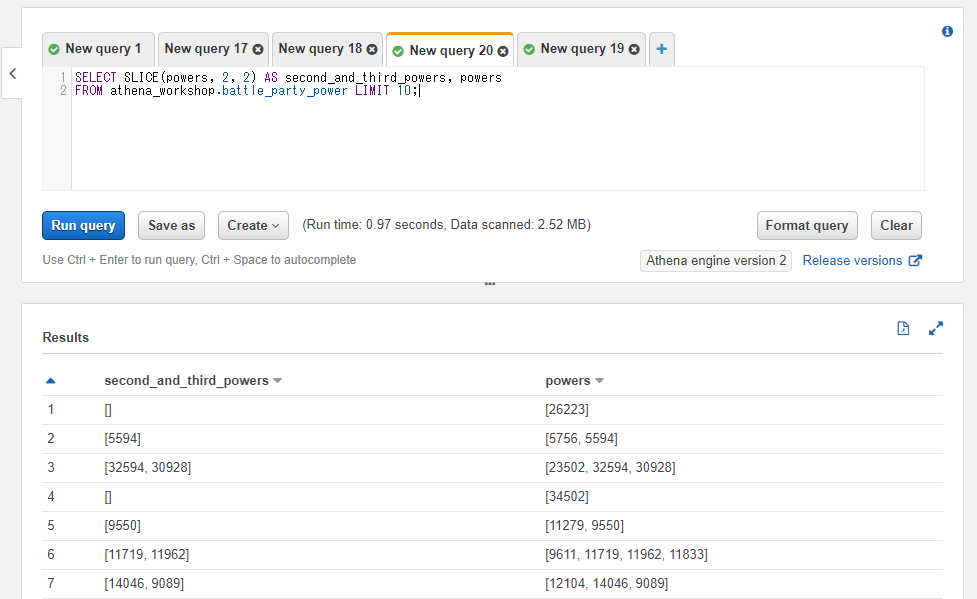
以下のSQLでは配列の2番目の位置から最大2件分の値を抽出した配列を取得しています。
SELECT SLICE(powers, 2, 2) AS second_and_third_powers, powers
FROM athena_workshop.battle_party_power LIMIT 10;
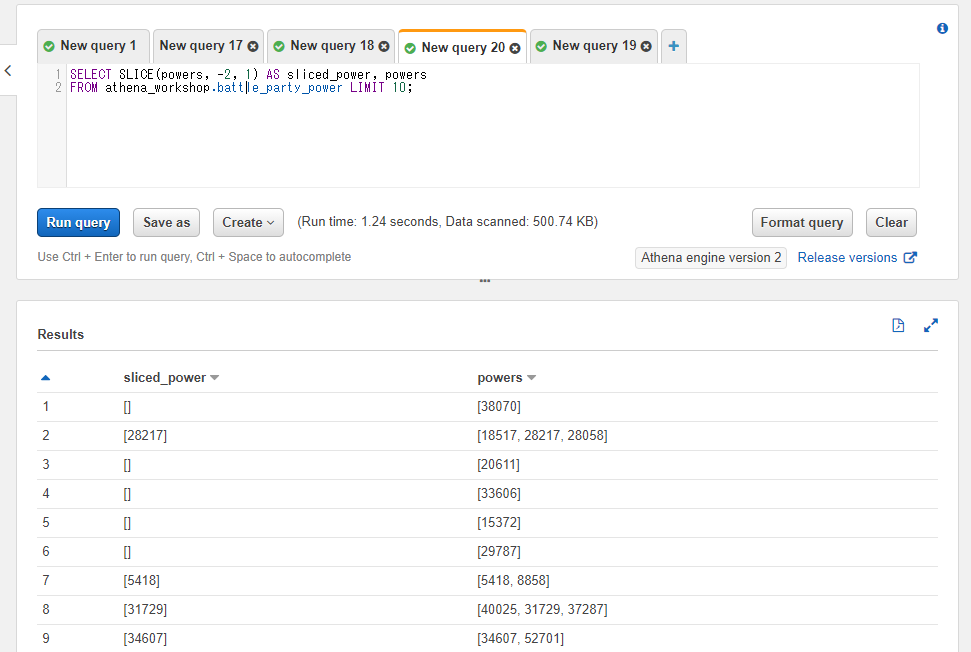
第二引数の開始位置には負の値も指定できます。Pythonと同じように-1を指定した場合は配列の最後、-2を指定した場合は最後から2番目の位置・・・といった挙動になります。
以下のSQLでは配列の最後から2番目の位置から1件分の値を抽出しています。
SELECT SLICE(powers, -2, 1) AS sliced_power, powers
FROM athena_workshop.battle_party_power LIMIT 10;
Pythonでの書き方
以下のコードのようにビルトインのリストでスライスの記法が使えるのでそちらをapplyメソッド用の関数で設定して対応しています。SQLと異なりPythonでは開始インデックスが0なのでそちらに合わせてあります。
from typing import List
import pandas as pd
def get_sliced_list(
list_val: List[int], start: int, length: int) -> List[int]:
"""
指定されたリストの特定の位置から任意の件数の値を格納したリストを
取得する。
Parameters
----------
list_val : list of int
対象のリスト。
start : int
リストの開始位置。
length : int
取得件数。
Returns
-------
list_val : list of int
スライス処理後のリスト。
"""
list_val = list_val[start:start + length]
return list_val
df: pd.DataFrame = pd.read_json(
'https://github.com/simon-ritchie/athena_workshop/blob/main/workshop/battle_party_power/dt%3D2021-01-01/data.json.gz?raw=true',
lines=True, compression='gzip')
df['second_and_third_powers'] = df['powers'].apply(
get_sliced_list, start=1, length=2)
print(df[['second_and_third_powers', 'powers']].head(10))
second_and_third_powers powers
0 [34983] [41013, 34983]
1 [29020, 30252] [26151, 29020, 30252]
2 [8786, 8179] [10269, 8786, 8179, 6633]
3 [] [18561]
4 [50078, 37768] [34067, 50078, 37768]
5 [34217, 22725] [25882, 34217, 22725, 21635]
6 [] [13968]
7 [1205, 2094] [1573, 1205, 2094, 2021]
8 [] [22217]
9 [] [19061]
一意な値のみに変換した配列を取得する: ARRAY_DISTINCT
ARRAY_DISTINCT関数を使うと指定されたカラムもしくは固定値の配列の値から、一意(重複の存在しない)配列を取得できます。
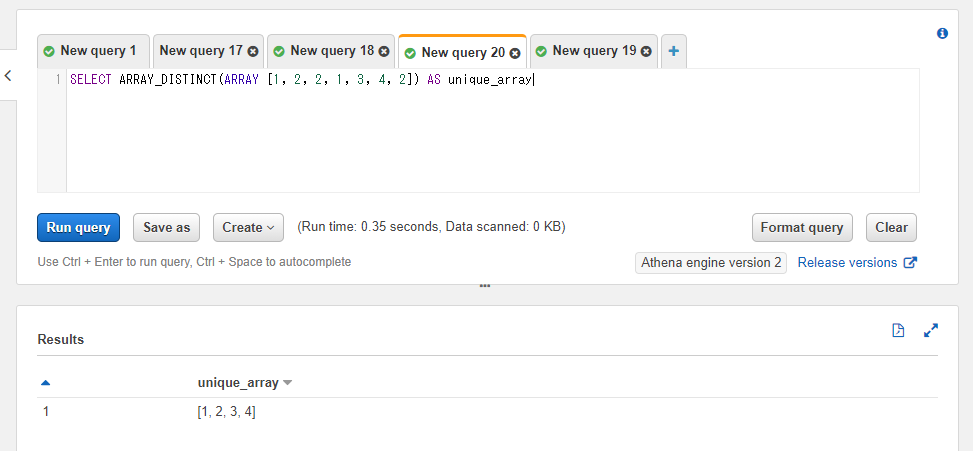
SELECT ARRAY_DISTINCT(ARRAY [1, 2, 2, 1, 3, 4, 2]) AS unique_array
Pythonでの書き方
ビルトインのリストであれば一度set関数を通すと一意な値になるので、そちらをさらにlist関数を通してリストに戻すと対応ができます。
from typing import List
unique_list: List[int] = list(set([1, 2, 2, 1, 3, 4, 2]))
print(unique_list)
[1, 2, 3, 4]
NumPyのndarrayなどであればunique関数が用意されています。
import numpy as np
arr: np.ndarray = np.array([1, 2, 2, 1, 3, 4, 2])
arr = np.unique(arr)
print(arr)
[1 2 3 4]
配列が特定の値を含むかどうかの真偽値を取得する: CONTAINS
CONTAINS関数は配列の値の中に特定の値が含まれているかどうかの真偽値を返します。
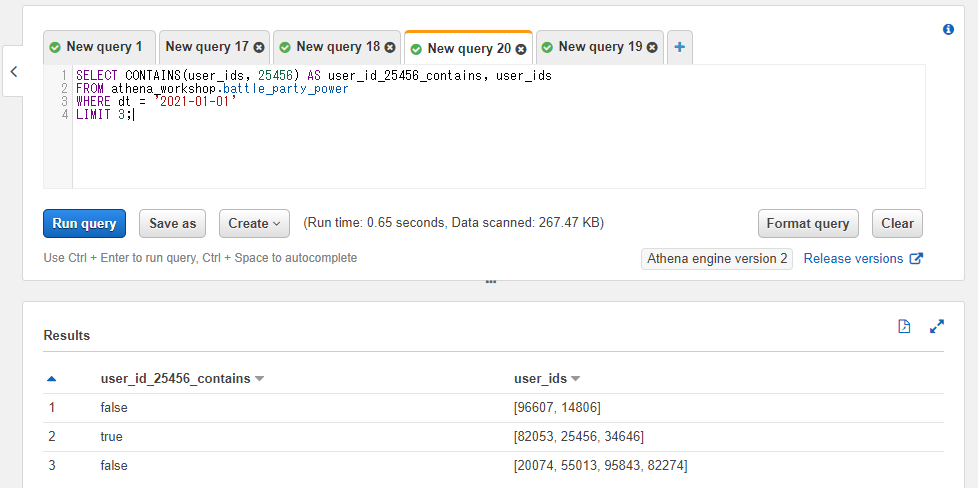
以下のSQLではパーティーのユーザーIDの配列内に25456のIDが含まれているかどうかの真偽値を取得しています。
SELECT CONTAINS(user_ids, 25456) AS user_id_25456_contains, user_ids
FROM athena_workshop.battle_party_power
WHERE dt = '2021-01-01'
LIMIT 3;
Pythonでの書き方
ビルトインのリストなどに対してinのキーワードを使うことで真偽値を取得することができます。
print(25456 in [96607, 14806])
False
print(25456 in [82053, 25456, 34646])
True
2つの配列で値の重複が存在するかの真偽値を取得する: ARRAYS_OVERLAP
ARRAYS_OVERLAP関数は2つの配列の値で重複している値が存在するかどうかの真偽値を返却します。それぞれの配列内に欠損値が含まれる場合にはtrueとはなりません。もし配列内の値が欠損値のみになっていれば返却値も欠損値(null)になります。
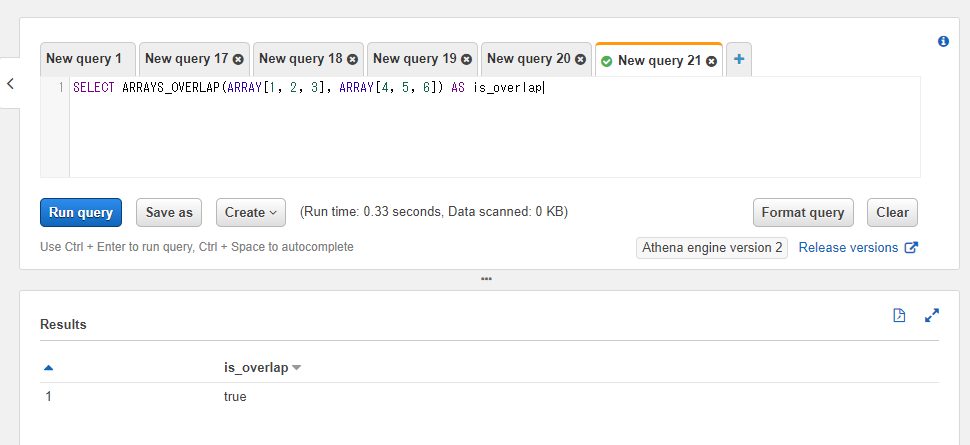
以下のSQLでは1つ目の配列の値が1, 2, 3で2つ目の配列の値が4, 5, 6であり、重複している値は存在しないのでfalseとなります。
SELECT ARRAYS_OVERLAP(ARRAY[1, 2, 3], ARRAY[4, 5, 6]) AS is_overlap
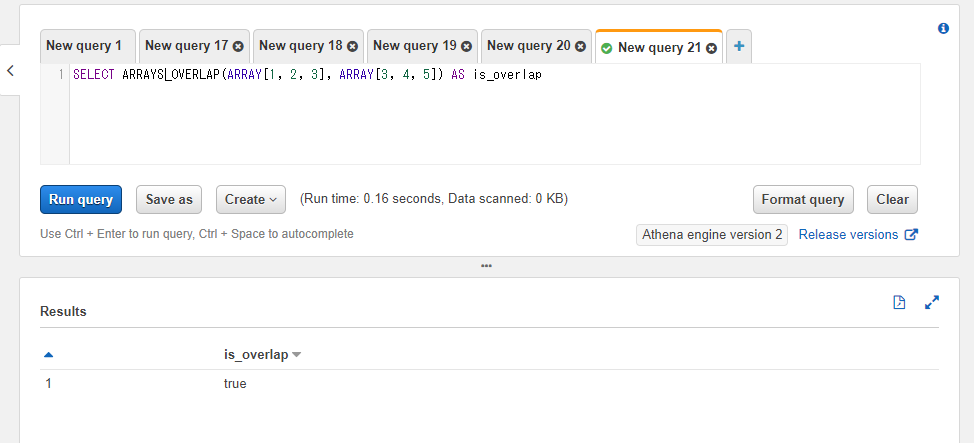
一方で以下のSQLでは1つ目の配列が1, 2, 3、2つ目の配列の値が3, 4, 5となっており3が重複しているのでtrueとなります。
SELECT ARRAYS_OVERLAP(ARRAY[1, 2, 3], ARRAY[3, 4, 5]) AS is_overlap
Pythonでの書き方
シンプルにループを使ってinで判定ができます。
from typing import List
arr_1: List[int] = [1, 2, 3]
arr_2: List[int] = [3, 4, 5]
is_overlap: bool = False
for value in arr_1:
if value in arr_2:
is_overlap = True
break
print(is_overlap)
True
が、それぞれのリストが巨大になってくると1件ずつリストに対してinを使うのは結構処理時間が気になるようになってきます。そのためもしも対象が巨大なリストの場合には2つ目のリストの方を辞書に変換しておいて、辞書のキーに存在するかどうかをinで判定するようにすると計算時間をぐぐっと抑えられます(メモリは食いますが)。
from typing import Dict, List
arr_1: List[int] = [1, 2, 3]
arr_2: List[int] = [3, 4, 5]
dict_val: Dict[int, None] = {value: None for value in arr_2}
is_overlap: bool = False
for value in arr_1:
if value in dict_val:
is_overlap = True
break
print(is_overlap)
True
配列から特定の値を取り除く: ARRAY_REMOVE
ARRAY_REMOVE関数は配列から指定された値を取り除いた配列を返却します。第一引数に対象のカラム名もしくは固定値、第二引数に任意の取り除きたい値を指定します。
以下のSQLでは配列から2の値を取り除いているため、結果は[1, 3]という配列になります。
SELECT ARRAY_REMOVE(ARRAY[1, 2, 3], 2) AS result
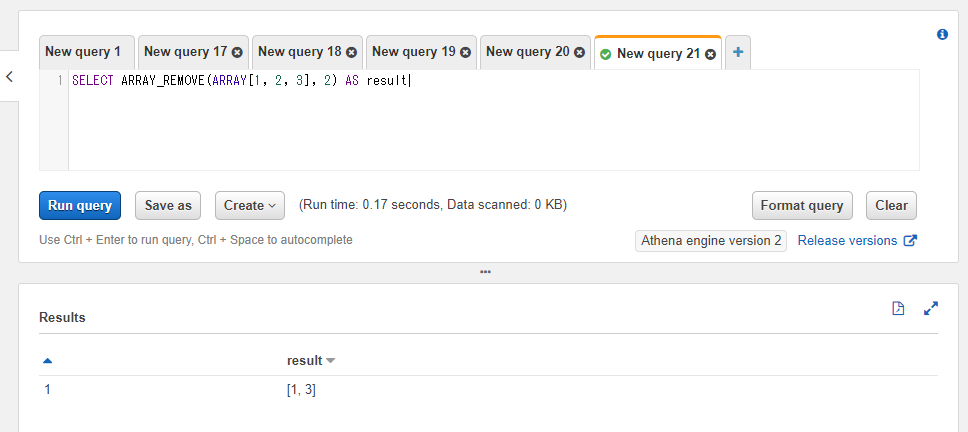
複数の削除対象の値が含まれている場合には全て削除されます。
SELECT ARRAY_REMOVE(ARRAY[1, 2, 2, 3], 2) AS result
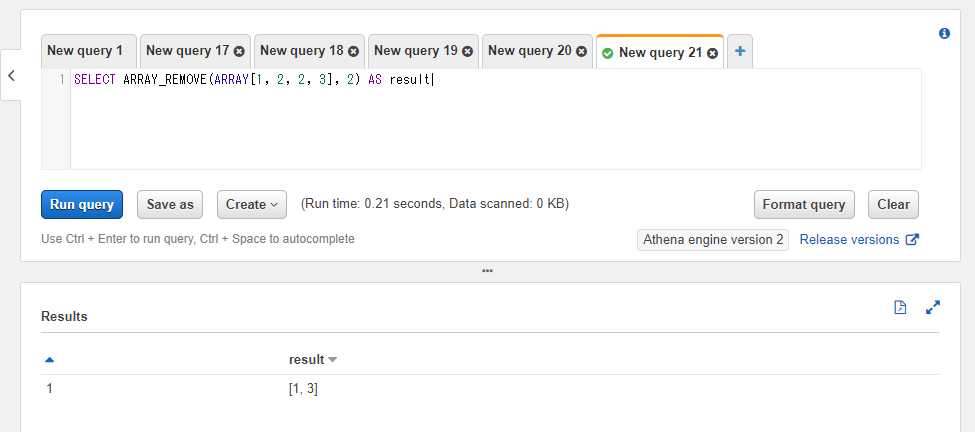
Pythonでの書き方
ビルトインのリストであれはremoveメソッドで削除が利きます。ただしリストに含まれていないとエラーになるのと1回呼んだだけでは先頭の値しか削除されないのでSQL側と同じようなことをしようとするとwhile文などで対象の値が含まれているかといった判定が必要になります。
from typing import Dict, List
arr: List[int] = [1, 2, 2, 3]
while 2 in arr:
arr.remove(2)
print(arr)
[1, 3]
配列内で指定された値の最初の出現位置を取得する: ARRAY_POSITION
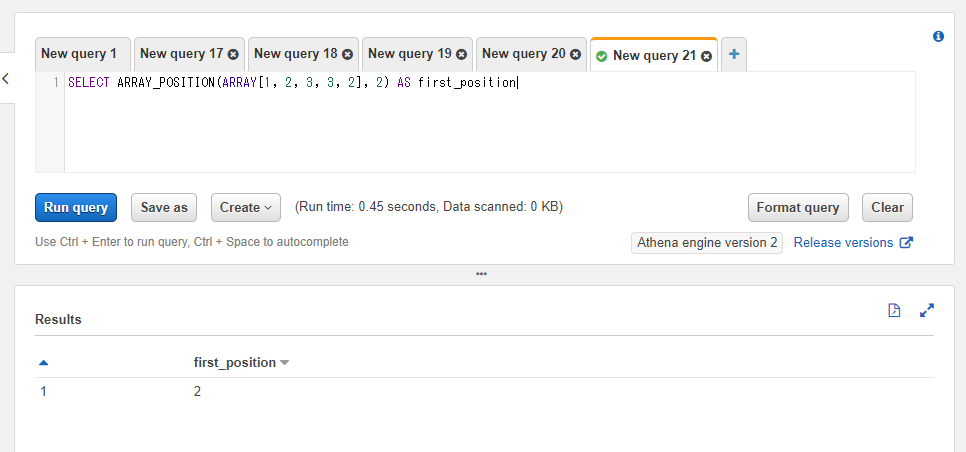
ARRAY_POSITION関数は配列内で指定された値が初めて出現する位置を返します。複数対象の値が存在する場合は最初の値の位置のみが返却されます。
例えば以下のSQLでは配列内で2の値が配列の何番目に存在するかを確認しています。2番目に存在するので結果は2となります。
SELECT ARRAY_POSITION(ARRAY[1, 2, 3, 3, 2], 2) AS first_position
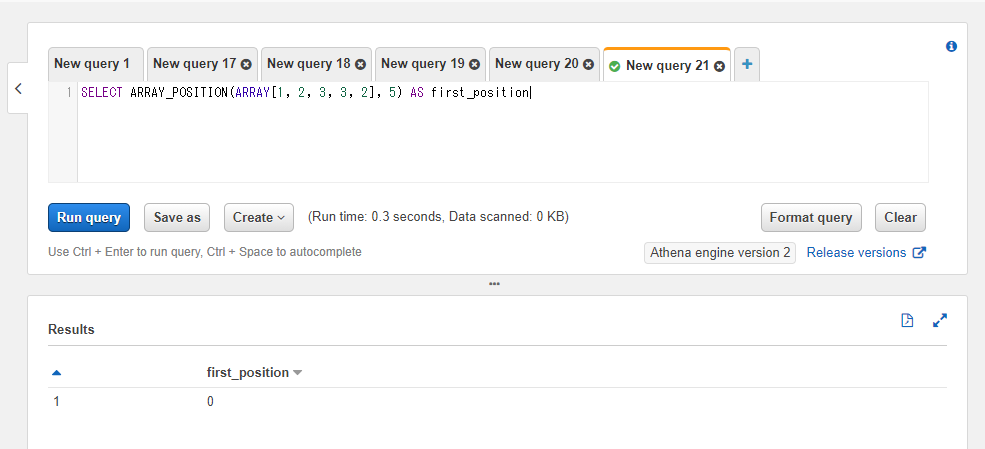
配列内に対象の値が存在しない場合返却値は0になります。
SELECT ARRAY_POSITION(ARRAY[1, 2, 3, 3, 2], 5) AS first_position
※Prestoのドキュメントでは第三引数で何番目の値かどうかが指定できるようになっていますがAthenaではまだ使えないようです。この記事を書いている時点では値が最初に出現する位置しか取れません。将来Athena側のアップデートで変わるかもしれません。
Pythonでの書き方
ビルトインのリストであればindexメソッドで同じようなことができます。他と同様Pythonではインデックスが0からスタートするのでSQLと比べて結果が-1した値になります。
from typing import List
arr: List[int] = [1, 2, 3, 3, 2]
first_position: int = arr.index(2)
print(first_position)
1
特定の値が含まれない配列を取得する: ARRAY_EXCEPT
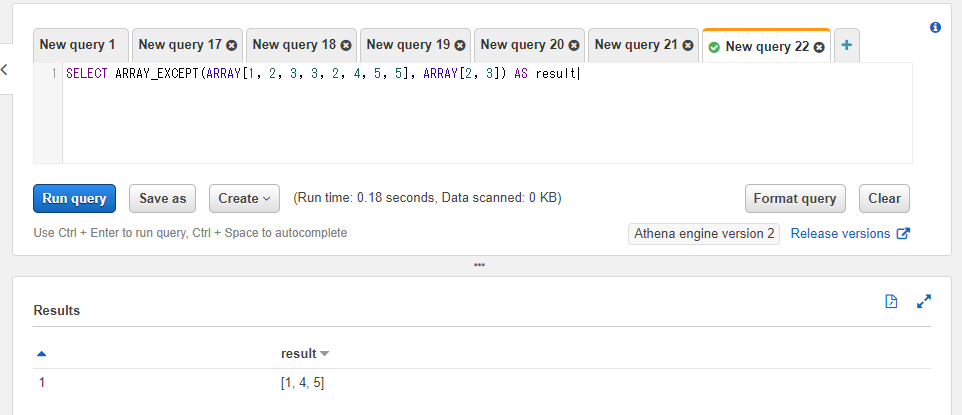
ARRAY_EXCEPT関数は2つの配列を用いて、1つ目の配列の中で2つ目の配列に含まれない値の配列を返します。
以下のSQLでは1つ目の配列の値は1, 2, 3, 3, 2, 4, 5, 5、2つ目の配列の値は2, 3としています。結果的に2と3が取り除かれた1, 4, 5の値が結果の配列に設定されます。結果に重複分は含まれません(1, 4, 5, 5といったような値は返却されません)。
SELECT ARRAY_EXCEPT(ARRAY[1, 2, 3, 3, 2, 4, 5, 5], ARRAY[2, 3]) AS result
Pythonでの書き方
ダイレクトにARRAY_EXCEPT関数に該当するビルトイン関数などは無い(?)ためループで回しています。前節と同じようにリストが巨大になった際のことを考えて2つ目の配列は一旦辞書にしています。また、ループの回数を減らすために最初の方でset関数を使って配列を一意にしています。2つ目の配列に含まれる値は結果に含めずにループ内でcontinueしています。
from typing import Dict, List
arr_1: List[int] = [1, 2, 3, 3, 2, 4, 5, 5]
arr_2: List[int] = [2, 3]
arr_1 = list(set(arr_1))
arr_2 = list(set(arr_2))
result_list: List[int] = []
dict_value: Dict[int, None] = {value: None for value in arr_2}
for value in arr_1:
if value in dict_value:
continue
result_list.append(value)
print(result_list)
[1, 4, 5]
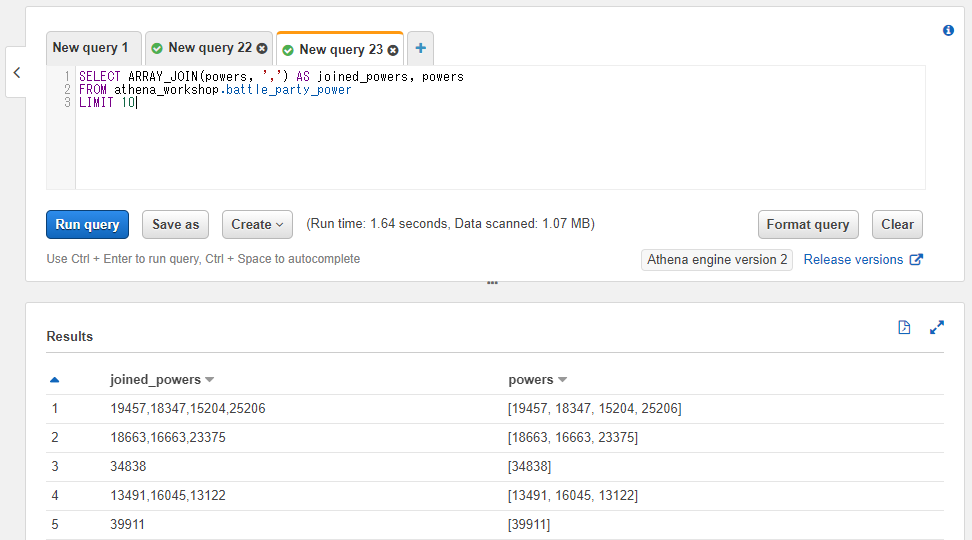
配列の値を連結して文字列を取得する: ARRAY_JOIN
ARRAY_JOIN関数は配列の値を特定の文字列で連結した文字列を取得することができます。たとえばコンマで連結すればCSV的な文字列を取得することができます。
第一引数に対象の配列のカラム名もしくは固定値、第二引数には区切り文字を指定します。
以下のSQLではコンマ区切りで配列の値を連結しています。
SELECT ARRAY_JOIN(powers, ',') AS joined_powers, powers
FROM athena_workshop.battle_party_power
LIMIT 10
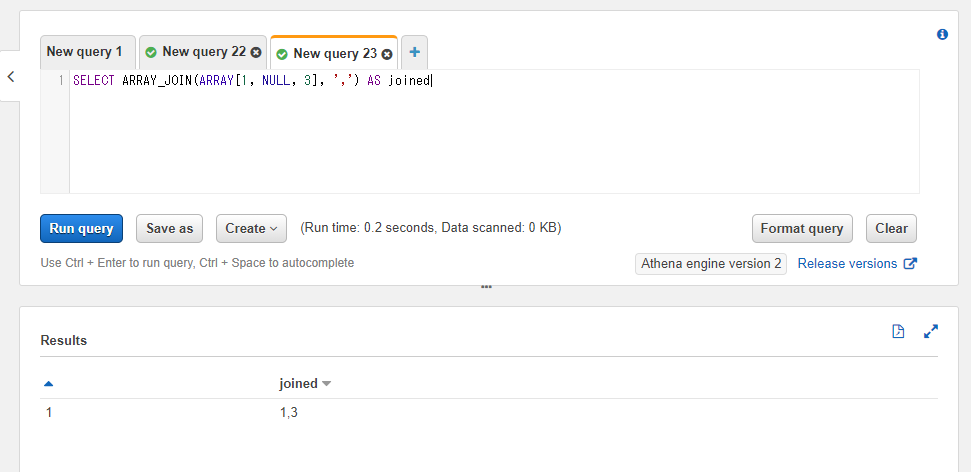
なお、配列に欠損値(NULL)が含まれている場合、その値は結果の文字列には含まれません。
以下のSQLでは1, NULL, 3という値の配列を指定していますが、結果は1,3とNULLを除いた値になっていることを確認できます。
SELECT ARRAY_JOIN(ARRAY[1, NULL, 3], ',') AS joined
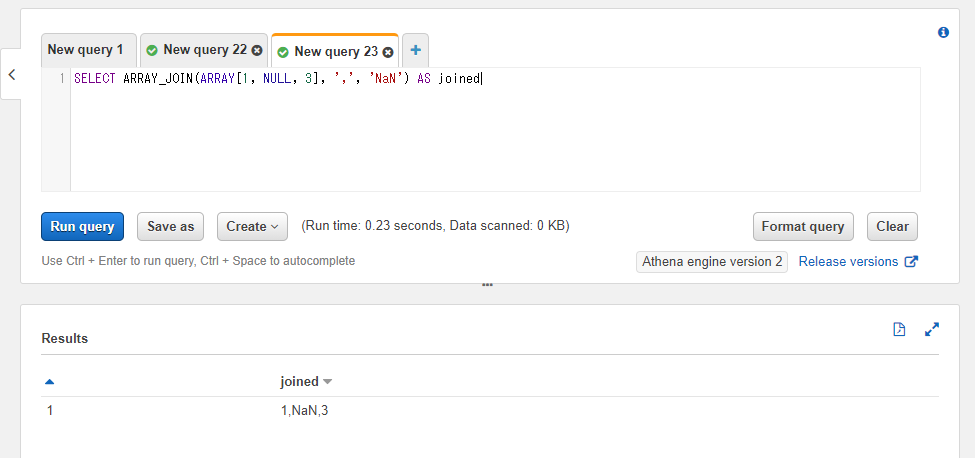
欠損値部分を別の値で埋めたい場合には第三引数を指定します。以下ではNULL部分が取り除かれてしまうのではなく、NaNという文字列で置換しています。
SELECT ARRAY_JOIN(ARRAY[1, NULL, 3], ',', 'NaN') AS joined
Pythonでの書き方
ビルトインの文字列がリストを引数に取るjoinメソッドを持っているためそちらで対応ができます。ただしリストの値を文字列に先に変換しておく必要があります。
from typing import List
int_arr: List[int] = [1, 2, 3]
str_arr: List[str] = [str(value) for value in int_arr]
joined: str = ','.join(str_arr)
print(joined)
1,2,3
配列のソートを行う: ARRAY_SORT
ARRAY_SORT関数を使うと配列の値の昇順ソートを行うことができます。
SELECT ARRAY_SORT(powers) AS sorted_powers, powers
FROM athena_workshop.battle_party_power
LIMIT 10
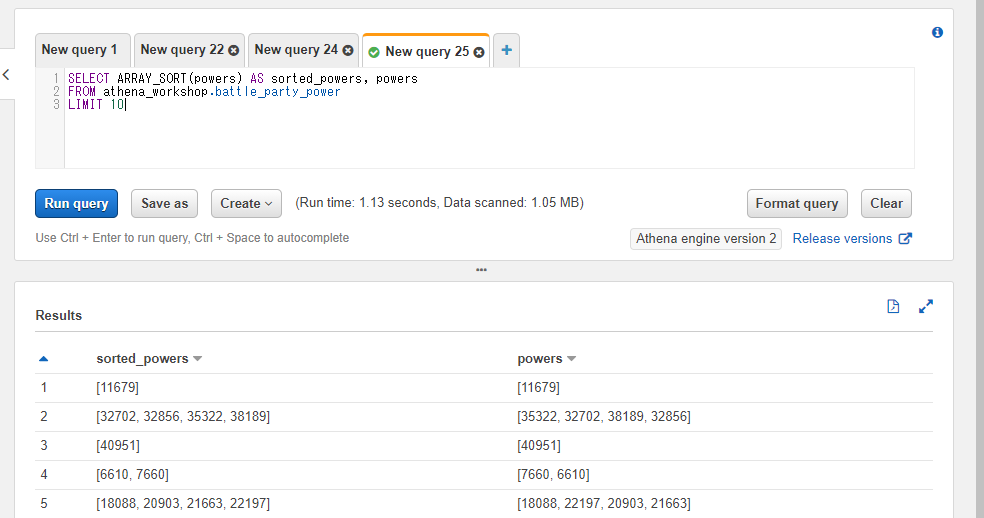
配列に欠損値(NULL)が含まれている場合にはその欠損値は配列の末尾に配置される形でソートされます。
SELECT ARRAY_SORT(ARRAY[5, 3, 6, NULL, 7, NULL, 10]) AS sorted
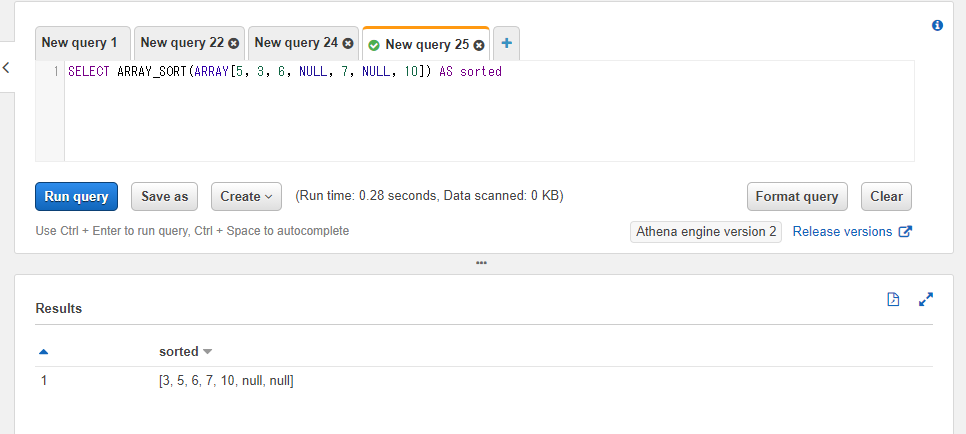
Pythonでの書き方
ビルトインのリストであればsortメソッドで昇順ソートすることができます。
from typing import List, Optional
arr: List[int] = [5, 3, 6, 10, 7]
arr.sort()
print(arr)
[3, 5, 6, 7, 10]
もしくはコピーされたリストが欲しければビルトインのsorted関数で取得することができます。
from typing import List, Optional
arr_1: List[int] = [5, 3, 6, 10, 7]
arr_2: List[int] = sorted(arr_1)
print(arr_2)
[3, 5, 6, 7, 10]
ラムダ式(Lambda Expressions)
以降の節の関数ではラムダ式が必要になってきたりするため先に軽く触れておきます。詳細は各関数で必要な分だけ説明を加えていきます。
ラムダ式は無名関数などとも呼ばれたりしますが、特定の値を受け取ってその値を使った返却値を記述することで、独自の関数定義のようなことをすることができます。
->の記号を使い、特定の値を引数として左側に記述し、右側に返却値を記述します。例えばxという値を引数で受け取って、それを1加算する形の返却値としてx + 1という表現をしたい場合にはx -> x + 1という書き方になります。複数の引数(xとy)を受け付けて1つの返却値(z)を返す場合には(x, y) -> zといったように書きます。
このラムダ式は関数内でしか使えません。ラムダ式を引数に取る関数があるためそれらの関数で使います。
ソート条件にラムダ式を使う
ARRAY_SORT関数の第三引数にはラムダ式を指定することができ、独自のソート方法を自身で組むことができます。
引数には2つの値が渡されます。ここではxとyという引数名を使っています。このxとyの2つの値での比較条件をラムダ式で書くことで比較条件を配列の各値に反映する形でソートが実行されます。ラムダ式の返却値には1つの整数が必要になり、-1, 0, 1のいずれかの値のみを受け付けます。xとyをソート用に比較した時にxの方を前にしたい条件であれば-1、xの方を後にしたい条件であれば1、xとyが同じ位置(同値条件など)になるべき条件であれば0を返すようにします。
条件文はIF関数を使って書きます。第一引数に条件式(x > yなど)、第二引数に条件を満たす場合の返却値、第三引数に条件を満たさない場合の返却値を指定します。第二引数や第三引数にはさらにIF関数もしくは他の関数などを入れ子にすることもできます。例えばA条件を満たす場合、さらにその中でB条件を満たすか満たさないか・・・といったように複数の条件を入れ子にしていくことができます。
例としてラムダ式を使わないARRAY_SORTの昇順ソートのと同じソートの計算をラムダ式を使って書いてみましょう(第三引数を省略する形で実務では問題無いのですがシンプルな説明用として使いえます)。
以下のようなSQLとなります。
SELECT ARRAY_SORT(ARRAY[5, 3, 6, 10, 7], (x, y) -> IF(x < y, -1, IF(x = y, 0, 1))) AS sorted
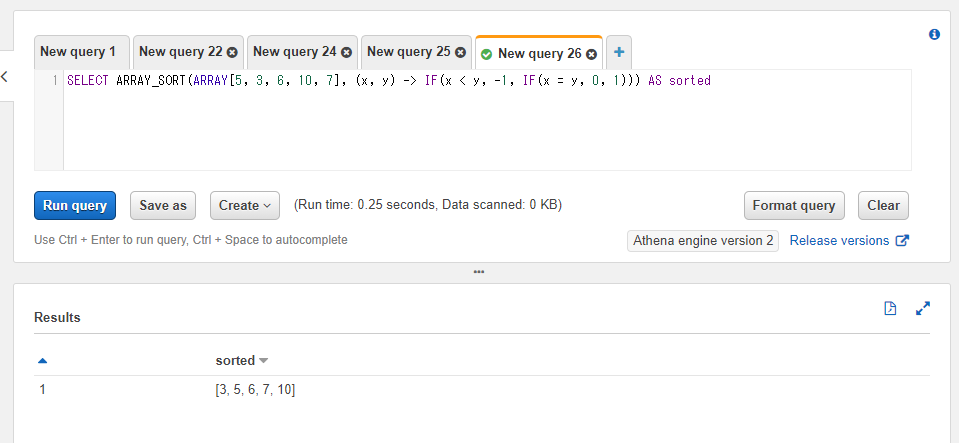
ラムダ式部分は(x, y) -> IF(x < y, -1, IF(x = y, 0, 1)))が該当します。まず引数部分ですがソートで2つの値が必要になるので(x, y)という記述にしています。
IF関数の最初の条件と条件を満たす場合の指定ですがIF(x < y, -1,としています。これはxがyよりも小さければ-1を返す(xがyよりも小さければxをyよりも前に配置する)という制御になります。
前述の条件を満たさない場合にはさらにIF関数を入れ子にしてIF(x = y, 0, 1)と分岐を書いています。これは、
-
xがyよりも小さいという条件を満たさず、且つxとyが同値(x = y)である場合には0を返す(xとyはソートで同じ位置になる)。 -
xがyよりも小さいという条件を満たさず、且つxとyが同値(x = y)でもない場合には1を返す(xがyよりも大きいのでxがyの後の位置にする)。
という条件になっています。
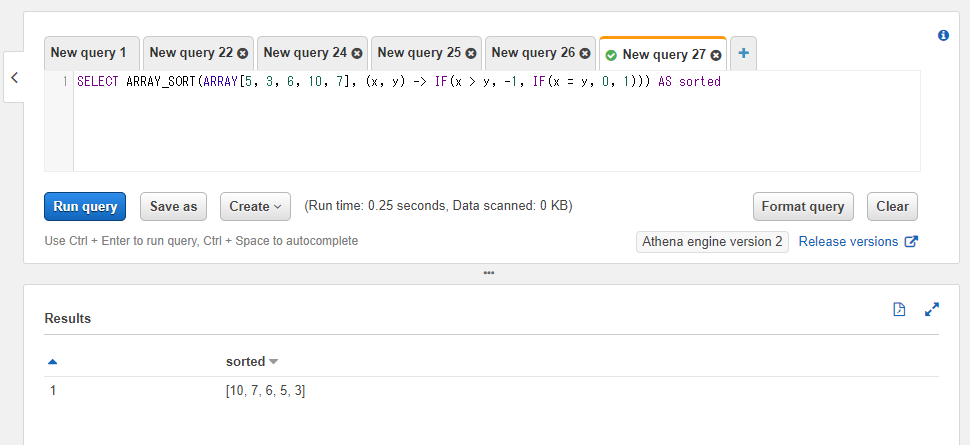
今度は降順ソートを書いてみましょう。現在Athenaでは配列を逆順にするREVERSE関数が使えない(Presto側のドキュメントには追加されているのでその内アップデートで使える形になると思われます)ため自前で書く必要があります。
やることとしてはシンプルで、x < yの箇所をx > yと比較演算子の向きを変えているだけです。これでxがyよりも大きければ前の位置に配置するという挙動になります。
SELECT ARRAY_SORT(ARRAY[5, 3, 6, 10, 7], (x, y) -> IF(x > y, -1, IF(x = y, 0, 1))) AS sorted
ラムダ式と関数などを組み合わせてソートする
ARRAY_SORT関数の第二引数のラムダ式には関数などを組み合わせて使うこともできます。例えば文字列の配列に対して文字数でソートしたい・・・というケースには以下のように書くことができます。xやyの部分を文字数を取得するLENGTH関数で囲っています。
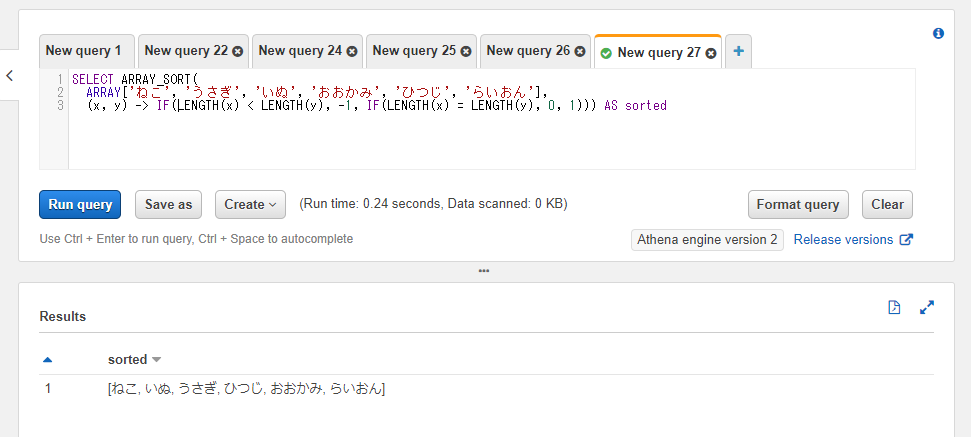
SELECT ARRAY_SORT(
ARRAY['ねこ', 'うさぎ', 'いぬ', 'おおかみ', 'ひつじ', 'らいおん'],
(x, y) -> IF(LENGTH(x) < LENGTH(y), -1, IF(LENGTH(x) = LENGTH(y), 0, 1))) AS sorted
配列をシャッフルする: SHUFFLE
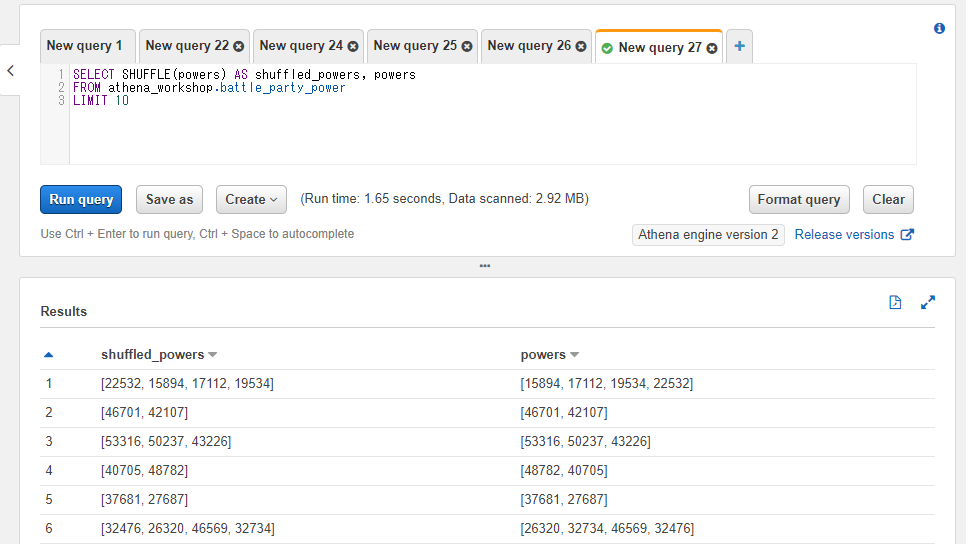
SHUFFLE関数は配列の内容をランダムにシャッフルします。結果は実行する度に変わります。
SELECT SHUFFLE(powers) AS shuffled_powers, powers
FROM athena_workshop.battle_party_power
LIMIT 10
Pythonでの書き方
ビルトインのrandomパッケージのshuffle関数でリストなどをシャッフルすることができます。
from typing import List
from random import shuffle
arr: List[int] = [5, 3, 6, 10, 7]
shuffle(x=arr)
print(arr)
[7, 6, 3, 5, 10]
2つの配列で双方に存在する値を格納した配列を取得する: ARRAY_INTERSECT
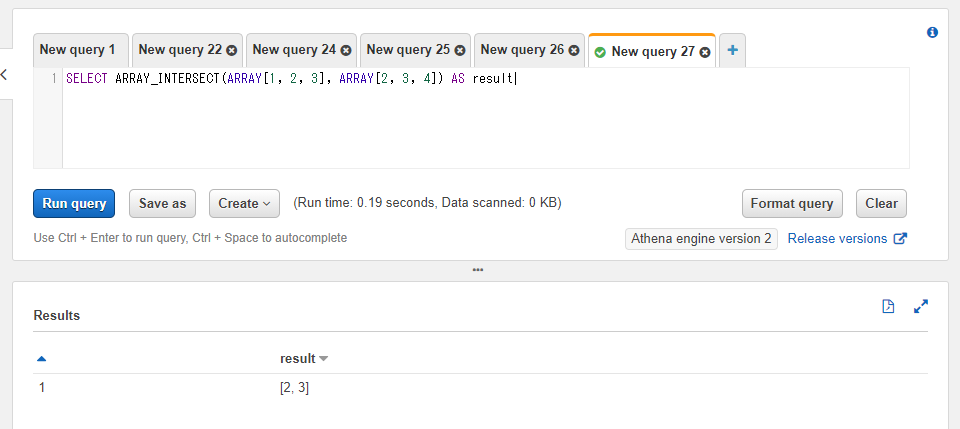
ARRAY_INTERSECT関数は第一引数と第二引数に指定された2つの配列間で、両方の配列に存在する値のみを格納した配列を返却します。返却される値は重複の無い形で設定されます。
以下のSQLでは1, 2, 3という値の配列と2, 3, 4という値の配列の2つを指定しています。2と3部分がそれぞれの配列に存在するため結果は2, 3という値の配列となります。片側にしかない値の1と4は含まれません。
SELECT ARRAY_INTERSECT(ARRAY[1, 2, 3], ARRAY[2, 3, 4]) AS result
余談ですが、Prestoのドキュメントを見ていると2次元配列を渡す形でのARRAY_INTERSECT関数の記述がありましたがまだAthenaでは使えない?ようです。
Pythonでの書き方
2つのsetを&記号で繋げばそれぞれのsetで両方に値があるもののみのsetが得られるのでそちらをリストにキャストすれば結果のリストが得られます。
以下のコードでは一度リストをset関数でsetに変換しています。
from typing import List
arr_1: List[int] = [1, 2, 3]
arr_2: List[int] = [2, 3, 4]
result: List[int] = list(set(arr_1) & set(arr_2))
print(result)
[2, 3]
任意の条件を満たした値のみを格納した配列を取得する: FILTER
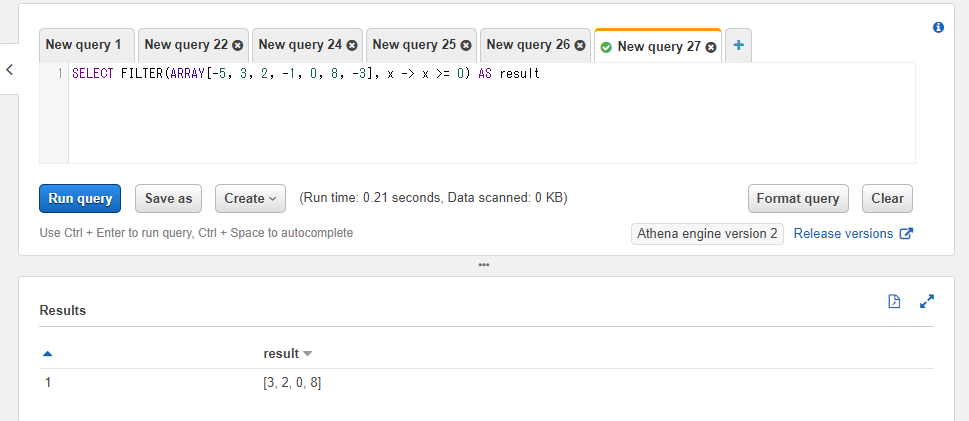
FILTER関数では特定の条件を満たす値のみを残した配列を返却します。第一引数には対象の配列のカラムもしくは配列の固定値、第二引数にはラムダ式を指定します。ラムダ式には1つの引数(サンプルではxという名前を使います)を受け付け、返却値には(等値や大なりなどの比較表現などによって)真偽値が返るようにします。返却値でtrueが返る条件の箇所のみ結果の配列に残ります。
以下のSQLではラムダ式でx >= 0という条件を指定しており、結果的に値が0以上のもののみ結果の配列に含まれるようにしています。
SELECT FILTER(ARRAY[-5, 3, 2, -1, 0, 8, -3], x -> x >= 0) AS result
Pythonでの書き方
ビルトインのfilter関数で同じようなことができます。返却値はfilterオブジェクトになるのでリストにキャストする処理を加えてあります。
from typing import List
arr: List[int] = [-5, 3, 2, -1, 0, 8, -3]
arr = list(filter(lambda x: x >= 0, arr))
print(arr)
[3, 2, 0, 8]
2次元配列を1次元の配列に変換する: FLATTEN
FLATTEN関数は以下のような行列(2次元配列)を1, 2, 3, 4, 5, 6, 7, 8, 9といったように1次元の配列に変換します。
\begin{array}{ccc}
1 & 2 & 3\\
4 & 5 & 6\\
7 & 8 & 9
\end{array}
SQL上では第一引数に2次元配列が必要になります。
SELECT FLATTEN(ARRAY[ARRAY[1, 2, 3], ARRAY[4, 5, 6], ARRAY[7, 8, 9]]) AS result
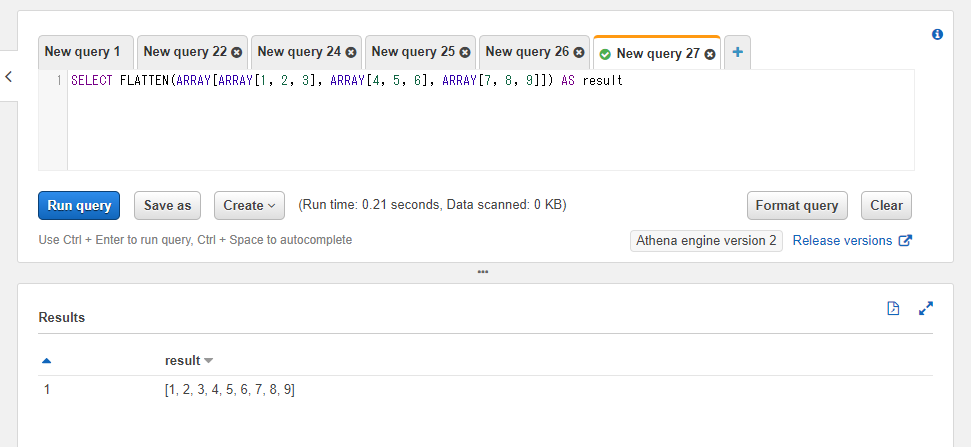
Pythonでの書き方
ビルトインのリストの場合は今まで使ったことがなかったのですがitertools.chain.from_iterableを使うとビルトインのもので完結する形でストレートにいくようです。
from typing import List
import itertools
arr: List[List[int]] = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
flattened: List[int] = list(itertools.chain.from_iterable(arr))
print(flattened)
[1, 2, 3, 4, 5, 6, 7, 8, 9]
NumPyなどであればflatternメソッドがあるのでそのままそれを呼ぶだけで対応ができます。こちらはデータ方面のお仕事などされている方々はビルトインよりも使う機会が結構あると思います。
import numpy as np
arr: np.ndarray = np.array([
[1, 2, 3],
[4, 5, 6],
[7, 8, 9],
])
arr = arr.flatten()
print(arr)
[1 2 3 4 5 6 7 8 9]
他のカラムの値を残しつつ、配列のネストされたデータを行列にする: UNNEST
ケースによっては配列のカラムではなく行列で扱った方が色々とシンプルな時があります。そういった場合にはUNNEST関数とCROSS JOINによる連結を使うと他のカラムの値を残したまま行列に変換することができます。
指定された配列の値を1行1行展開し、他のカラムの値は一通りそのまま残す(元の値を連結する)みたいな挙動になります。
例えば以下のような行列があったとします。武器のIDのカラムは配列の値を含んでいます。
\begin{array}{rr}
ユーザーID & 武器のID\\
1 & [10, 11]\\
2 & [12, 13]
\end{array}
UNNEST関数と武器のIDを指定したCROSS JOINを使うと上記の行列が以下のような行列に変換されるイメージです。
\begin{array}{rr}
ユーザーID & 武器のID\\
1 & 10\\
1 & 11\\
2 & 12\\
2 & 13
\end{array}
CROSS JOIN自体は以前の記事で触れましたが、組み合わせによる連結を行う都合元の行数よりもぐぐっと行数が多くなります。
参考 :
左側のテーブルの行数がN行、右側のテーブルの行数がM行とすると交差結合の結果の行数は$N × M$行となります。
今回のUNNEST関数の例で言うとNが元々の行数、Mが対象とする配列の値の件数となります。例えば元々の行が10万行、配列が平均して10件の値を含んでいた場合は10万 × 10で結果は100万行となります。処理に時間がかかったり扱うデータが巨大化したりするケースがあるので扱う際には少し気を付ける必要があります。
書き方としてはCROSS JOIN UNNEST(<対象の配列のカラム名>) AS <UNNESTしたテーブルに付ける名前>(配列の値に付けるカラム名)みたいな書き方になります。少々独特です。
例えばbattle_party_powerテーブルのpowersという配列を展開したい場合に、展開後のテーブル名をunnested_powersとし、配列の値のカラム名にpowerという名前を付ける場合はCROSS JOIN UNNEST(athena_workshop.battle_party_power.powers) AS unnested_powers(power)といったような書き方になります。
実際にSQLで実行してみましょう。
SELECT * FROM
athena_workshop.battle_party_power
CROSS JOIN UNNEST(athena_workshop.battle_party_power.powers) AS unnested_powers(power)
LIMIT 50
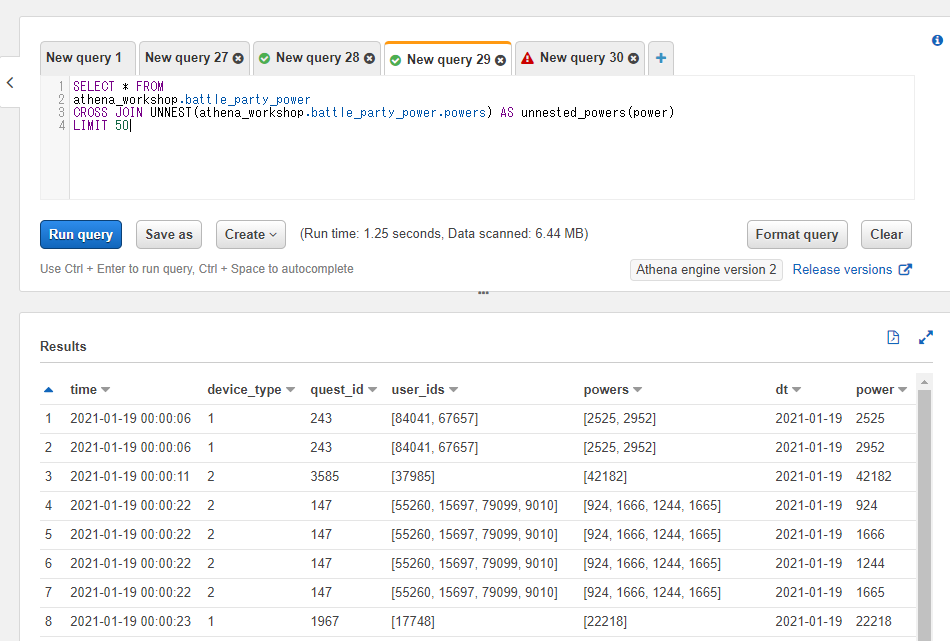
SQL実行結果では元々のカラムに加えて連結されたpowerというカラムが追加になっていることが分かります。また、powersの配列のカラムの各値が1行ずつに展開され、powerカラム以外のカラムの値はそのまま残っていることが確認できます。
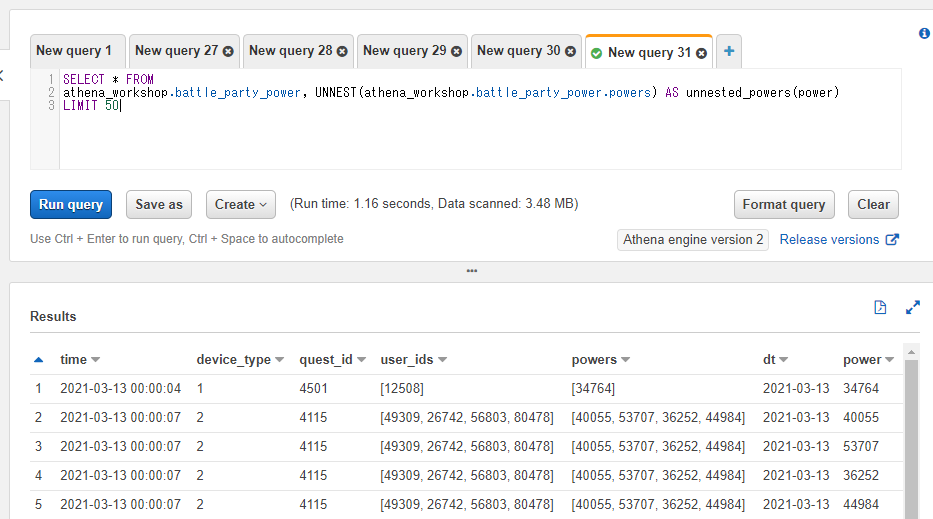
また、UNNEST関数はCROSS JOINなどと一緒に使わない書き方もあります。書き方としてはFROM句にて<対象のテーブル>, <そのテーブルの配列のカラムに対するUNNESTの指定>といったように書きます。UNNESTの前にテーブルの指定とコンマが必要になる書き方となります。例えばathena_workshop.battle_party_powerテーブルのpowersという配列のカラムに対して使う場合には以下のようになります。
SELECT * FROM
athena_workshop.battle_party_power, UNNEST(athena_workshop.battle_party_power.powers) AS unnested_powers(power)
LIMIT 50
結果はCROSS JOINしたときと似たような形になります。
ただしこちらの書き方の場合、UNNESTしたものに対して他のJOIN(LEFT JOINやINNER JOINなど)をするとエラーで弾かれるようです。そういったケースではCROSS JOINとUNNESTを使ってからその後にLEFT JOINなどを使うか、もしくはWITH句などでのサブクエリで分割する必要があるようです(将来Athena内部のPrestoのアップデートでLEFT JOINなどもできるようになるかもしれません)。
Athena is based on Presto .172 LEFT JOIN with UNNEST was added in Presto 319
...
one can rewrite the left join to a cross join with coalesce:
例えばクエストでドロップした複数の武器などがクエストのログの行に配列などで格納されていて、武器のIDと武器のマスタをJOINしたい場合が該当します。今回テーブルを追加したりはしませんが、仮にlog_db.questというクエストログのテーブルがあり、dropped_weaponsという配列のカラムが含まれており、且つmst_weaponというマスタテーブルがあると過程するとCROSS JOIN UNNESTと他のJOINを使うと(JOIN部分だけ抽出すると)以下のような書き方になります。
...
CROSS JOIN UNNEST(log_db.quest.dropped_weapons) AS unnested_weapons(weapon_id)
INNER JOIN mst_weapon
ON unnested_weapons.weapon_id = mst_weapon.id
...
辞書を格納した配列に関してはさらに色々と触れることがありますが、そちらは別の辞書について詳しく触れる記事で書いていこうと思います。
Pythonでの書き方
この辺は大分昔の記事となりますが、Pandasのjson_normalize関数などが用意されており記事にしていますのでそちらをご確認ください。
配列をn件ずつの2次元配列に変換する: NGRAMS
NGRAMS関数は1次元の配列を2次元の配列に変換します。自然言語方面で結構出てきたりします。
n-gramとはn個の連続する単位
一言で説明すると、「n-gram」とは連続するn個の単語や文字のまとまりを表します。
まとまりごとに2次元目の配列化されます。例えば[1, 2, 3, 4, 5]という配列に対してn=2でNGRAM関数を反映すると、[[1, 2], [2, 3], [3, 4], [4, 5]]といった2次元配列に変換されます。n=3で反映すると[[1, 2, 3], [2, 3, 4], [3, 4, 5]]といった値になります。
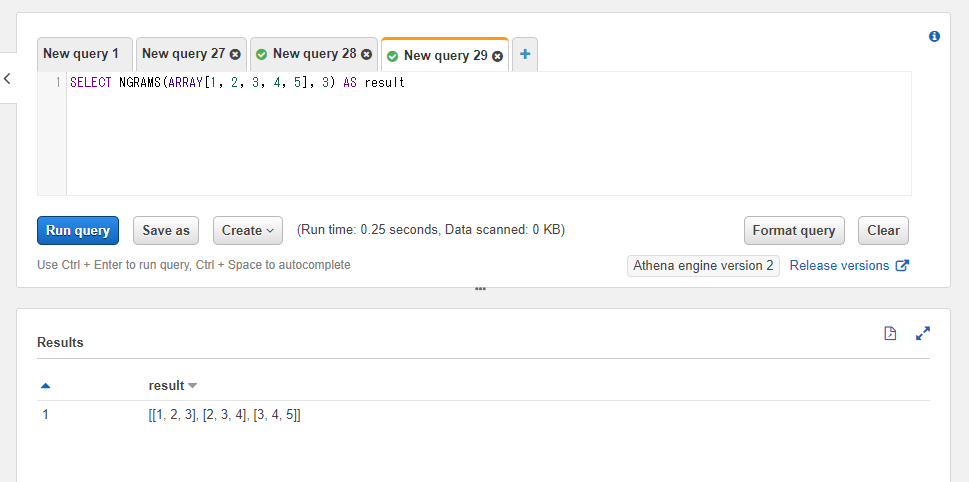
第一引数には対象の配列のカラムもしくは配列の固定値、第二引数にはnの値を指定します。
SELECT NGRAMS(ARRAY[1, 2, 3, 4, 5], 3) AS result
Pythonでの書き方
Pandas自体にはn-gram関係の機能は無さそうですが、nltkなどの別のライブラリを絡めるとシンプルにいきそうな印象です。試していないのでここではリンクのみ貼っておきます。
配列の各値で計算を行い、計算結果を取得する: REDUCE
REDUCE関数は配列の値に対して1つ1つ計算を行い、計算結果を単一の値(次元数が減った状態の値)を取得します。ラムダ式をがっつり使う形となります。
第一引数には対象とする配列のカラム名もしくは配列の固定値、第二引数には初期値、第三引数には各値ごとの入力のラムダ式、第四引数には全体の出力時のラムダ式が必要になります。引数が複雑なので順番に触れていきます。
まずは第二引数の初期値です。これは集計処理の初期値です。0を指定して0からスタートするケースが結構多くなると思います。
第三引数は各値ごとの入力のラムダ式となります。各値ごとに処理がされます。引数はその値までの計算結果(今回の記事ではsと表記します)と対象の配列の値(今回の記事ではxと表記します)の2つです。先頭の値に関してはsの値は第二引数に指定した初期値になります。
例えば[2, 3, 4]という配列に対して処理を行うとして、第二引数の初期値が1だった場合は
- 1回目の処理 -> s = 1, x = 2
- 2回目の処理 -> s = 1回目の処理の計算結果, x = 3
- 3回目の処理 -> s = 2回目の処理の計算結果, x = 4
といったように3回計算がこのラムダ式で実行されます。返却値は1つの値となる必要があります(計算結果として次の処理のsに渡されます)。
第四引数は出力用のラムダ式です。このラムダ式は第三引数とは異なり配列の各値ごとに実行されたりはしません。各値の計算結果の最後の値に対してのみ反映されます(配列の件数に関わらず1回のみ実行されます)。引数は全体の計算結果のsのみ、返却値も1つの値のみとなります。
いくつかサンプルのSQLを書いていきます。まずはシンプルに配列の値の合計値を出すという記述をREDUCE関数を使ってしてみましょう。前節までで触れた通り、配列の合計値を出す関数自体はPrestoにはARRAY_SUM関数が存在しますが、Athenaではまだこの記事を執筆時点では使えない点とサンプルとしてシンプルなので使っていきます。
まずは第二引数の初期値ですが、これは合計値を出す計算なので0を指定します。
続いて第三引数のラムダ式ですが、引数の指定は2つの値が必要になるため(s, x)といった記述になります。返却値側は配列の各値の合計を出す必要があるため、前の処理までの計算結果sに対して今回の配列の値xを加えるという形でs + xとしています。
第四引数の処理に関しては今回は制御が必要ないため、s -> sとして値をそのまま返却するようにしています。
1, 2, 3という3つの値を含んでいる配列に対して試してみます。
SELECT REDUCE(ARRAY[1, 2, 3], 0, (s, x) -> s + x, s -> s) AS result
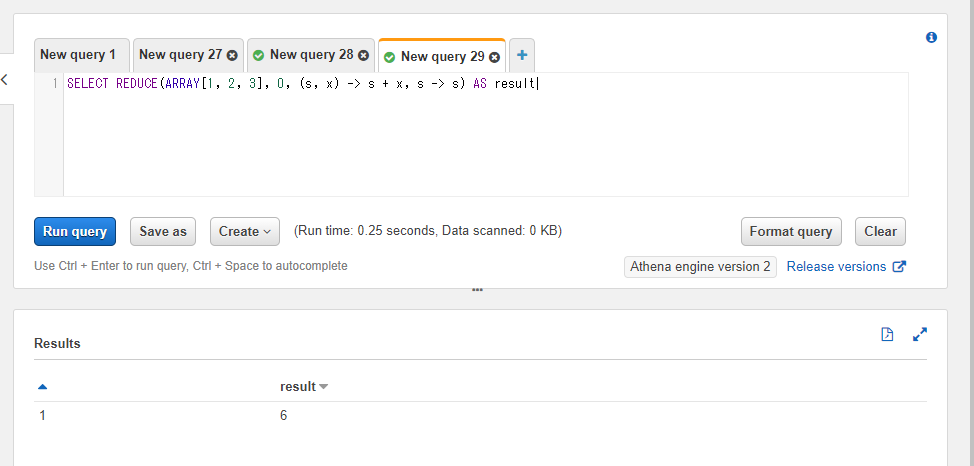
無事配列の合計値の6を得ることができました。
今度は第四引数の出力部分のラムダ式を調整していきましょう。このラムダ式は第三引数のラムダ式とは異なり配列の値1つ1つで計算はされずに最後の計算結果にのみ(最後の1回だけ)反映されます。
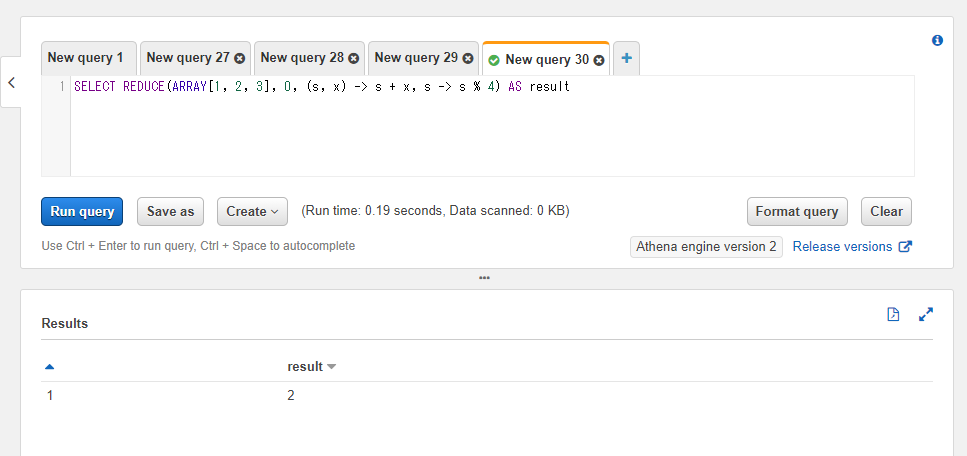
以下のSQLでは計算結果に対して4で割ったときの剰余(余り)をs % 4という記述で求めています。結果が2になることが確認できます。
SELECT REDUCE(ARRAY[1, 2, 3], 0, (s, x) -> s + x, s -> s % 4) AS result
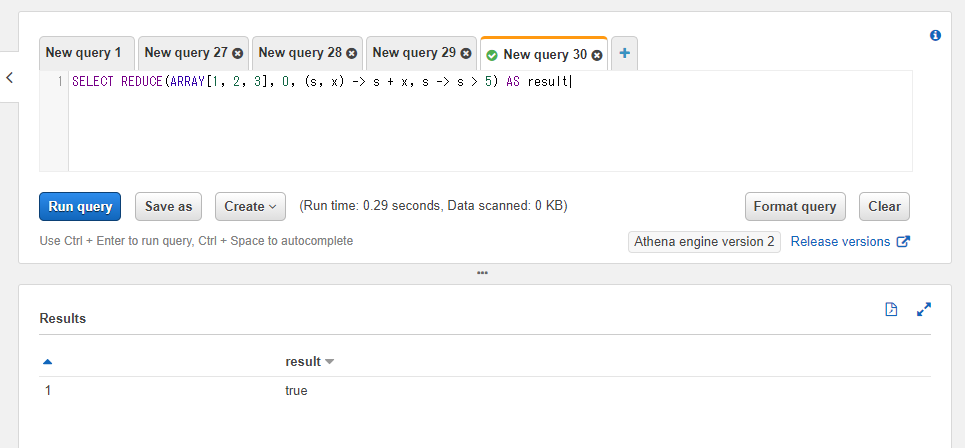
他にも比較演算子を使って比較結果を真偽値を取得したり、関数を挟んだりと色々できます。以下のSQLでは計算結果が5よりも大きいか(s > 5)という判定にして結果の真偽値を取得しています。
SELECT REDUCE(ARRAY[1, 2, 3], 0, (s, x) -> s + x, s -> s > 5) AS result
Pythonでの書き方
ビルトインのfunctoolsパッケージにreduce関数があり、そちらで同じような制御を行うことができます。第一引数には反映する関数もしくはラムダ式、第二引数にリストなどの値を指定します。
from typing import List
from functools import reduce
arr: List[int] = [1, 2, 3]
result: int = reduce(lambda s, x: s + x, arr)
print(result)
6
特定の変換処理を加えた配列を取得する: TRANSFORM
TRANSFORM関数もREDUCE関数のように配列の値1件1件に対して処理を加えます。ただし結果の値はそのまま配列で返却され、配列の値の件数も基本的に変動しません。「配列の全ての値に対して加工を行う」といった制御に向いています。
第一引数には対象の配列のカラム名もしくは配列の固定値、第二引数には加工処理用のラムダ式を指定します。第二引数のラムダ式には1つの引数(配列内の個々の値)と1つの返却値を受け付けます。今回はxという名前を使っています。
以下のSQLでは1, 2, 3という値の配列に対して1加算するラムダ式(x + 1)を指定しています。結果が2, 3, 4となることを確認できます。
SELECT TRANSFORM(ARRAY[1, 2, 3], x -> x + 1) AS result
Pythonでの書き方
色々書き方がありますが、1つ目としてはmap関数による処理がTRANSFORM関数に近い挙動になっています。
from typing import List
arr: List[int] = [1, 2, 3]
arr = list(map(lambda x: x + 1, arr))
print(arr)
[2, 3, 4]
他にもリスト内包表記やもちろん普通にループを回してしまっても良いと思います。
from typing import List
arr: List[int] = [1, 2, 3]
arr = [x + 1 for x in arr]
print(arr)
[2, 3, 4]
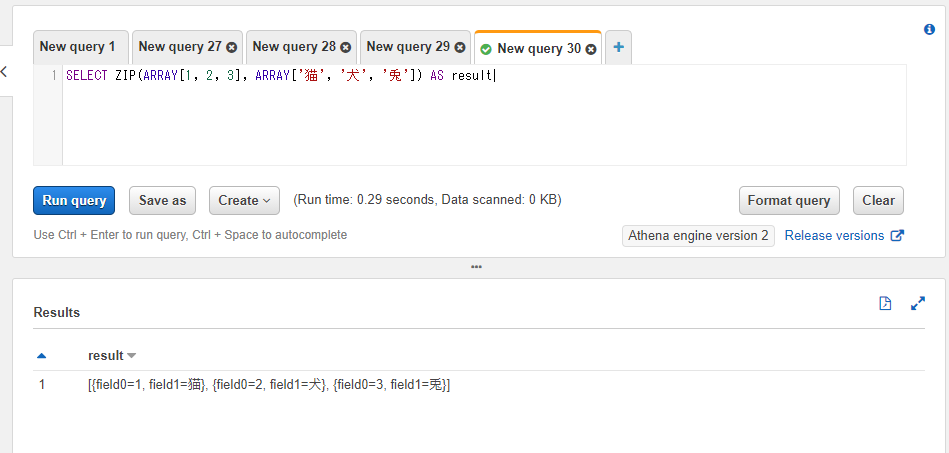
2つ以上の配列を統合した配列を取得する: ZIP
ZIP関数は2つ以上の配列の値をセットにした配列を返します。返却値はROWという型の値を格納した配列になるようです。ROWは辞書のような形の型となります(1行分のデータといった形になります)。
実行後のカラム名はfield0, field1, ... と設定されます。
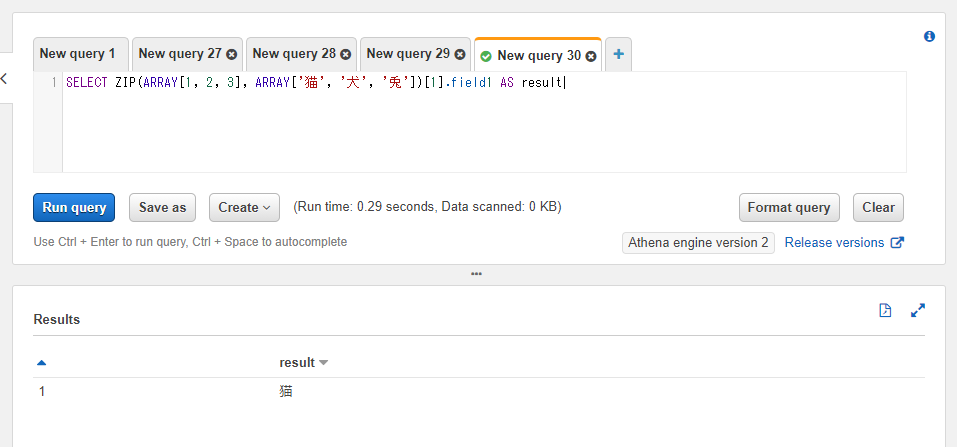
SELECT ZIP(ARRAY[1, 2, 3], ARRAY['猫', '犬', '兎']) AS result
ROW型の値はドット記号(.)でアクセスすることができます。例えばfield1のカラムにアクセスしたい場合には.field1といった書き方でその値を参照することができます。
配列へのアクセスは[]の括弧を使えば行えるため、例えば配列の最初のROWの値のfield1にアクセスしたい場合には[1].field1といった書き方になります(括弧内のインデックスの数字はAthena(Presto)上では1からのスタートになります)。
SELECT ZIP(ARRAY[1, 2, 3], ARRAY['猫', '犬', '兎'])[1].field1 AS result
Pythonでの書き方
ループなどの際にビルトインのzip関数を使うことで複数のリストなどの値をひとまとめにしつつループを行うことができます。結果はタプルで渡されます。
from typing import List
arr_1: List[int] = [1, 2, 3]
arr_2: List[str] = ['猫', '犬', '兎']
for tpl in zip(arr_1, arr_2):
print(tpl)
(1, '猫')
(2, '犬')
(3, '兎')
タプルはコンマ区切りでそのまま展開することもできるため、それぞれを変数に分けることもできます。
from typing import List
arr_1: List[int] = [1, 2, 3]
arr_2: List[str] = ['猫', '犬', '兎']
for id_, name in zip(arr_1, arr_2):
print(id_, name)
1 猫
2 犬
3 兎
なお、Prestoのドキュメントには2つの配列に対してラムダ式で処理を加えつつ制御が可能なZIP_WITHという関数もあったのですがこの記事の執筆時点ではまだAthena上では利用できないようです。
参考文献・参考サイトまとめ
- The Applied SQL Data Analytics Workshop: Develop your practical skills and prepare to become a professional data analyst, 2nd Edition
- [AWS]Athenaのコメントアウトの仕方とフォーマットについて
- Array Functions and Operators
- Lambda Expressions
- pandas.date_range
- Pythonでリスト(配列)の要素を削除するclear, pop, remove, del
- How to find list intersection?
- Pythonでflatten(多次元リストを一次元に平坦化)
- Flatten arrays into rows with UNNEST
- Pandasのjson_normalizeを詳しく調べてみる
- 自然言語処理に出てくるn-gramとはなに?
- From DataFrame to N-Grams
- Python の基本的な高階関数( map() filter() reduce() )
- How to Transform List Elements with Python map() Function
- Data Types
- AWS Athena unnest with left join not working