今まで複雑なデータ操作・分析などはPythonでやっており、SQLは普通のアプリ開発程度のライトなものしか触って来なかったのですが、やはり分析用の長いSQLなども書けた方がやりとり等で便利・・・という印象なので、復習も兼ねて記事にしておきます。
また、SQLに加えて検算も兼ねてPythonやPandasなどを使ったコードもSQLと併記していきます(Pythonで書くとどういった記述が該当するのかの比較用として使います)。
※長くなるのでいくつかの記事に分割します。本記事は3記事目となります。
他のシリーズ記事
Athenaとはなんぞやという方はこちらをご確認ください:
※過去の記事で既に触れたものは本記事では触れません。
#1:
用語の説明・SELECT、WHERE、ORDER BY、LIMIT、AS、DISTINCT、基本的な集計関係(COUNTやAVGなど)、Athenaのパーティション、型、CAST、JOIN、UNION(INTERSECTなど含む)など。
#2:
GROUP BY・HAVING・サブクエリ・CASE・COALESCE・NULLIF・LEAST・GREATEST・四則演算などの基本的な計算・日付と日時の各操作など。
環境の準備
以下の#1の記事でS3へのAthena用のデータの配置やテーブルのCREATE文などのGitHubに公開しているものに関しての情報を記載していますのでそちらをご参照ください。
特記実行
- お仕事がAWSなので合わせてDBはAWSのAthena(Presto)を利用していきます。BigQueryやRedshift、MySQLやPostgreSQLなどではある程度方言や使える関数の差などがあると思いますがご了承ください。
- 同様にお仕事がゲーム業界なので、用意するデータセットはモバイルゲームなどを意識した形(データ・テーブル)で進めます。
- エンジニア以外の方(プランナーさんやマーケの方など)も少し読者として想定しています。ある程度技術的なところで煩雑な記述もありますがご容赦ください。
- 長くなるのでいくつかの記事に分割して執筆を進めています。
この記事で触れること
- 文字列操作全般
- 正規表現関係
文字列の操作
この節以降ではAthena(Presto)での文字列操作について触れていきます。
文字コードについての注意事項
Athena(Presto)では基本的に入力も出力もUTF-8の文字コードとなります。つまり保存するログファイルもUTF-8が必要になりますし、クエリ結果のCSVなどもUTF-8となります。
一方で日本環境で仕事をしていると、エンジニア以外の方の作業などでエクセル等が使われ、そこでShift JISもしくはcp932などが入ってくるケースも結構あると思います。
そういった場合はまずログを配置する場合には文字コードの変換をかけておく必要がありますし、クエリ結果のCSVをそのままエクセルなどで日本語を文字化けさせることなく開きたい場合にはBIツール側などでダウンロードの際にBOMを追加するなどの調整が必要になります。
||記号による文字列の連結
||の記号を文字列の各カラムや文字列の固定値の間に配置すると文字列の連結が行えます。
以下のSQLでは日時の文字列から年部分や月部分を抽出し、年や月といった日本語を含め||の記述で文字列を連結しています。
SELECT user_id, time,
SUBSTR(time, 1, 4) || '年' || SUBSTR(time, 6, 2) || '月' AS year_and_month
FROM athena_workshop.login
LIMIT 10

Pythonでの書き方
対象のカラム(Series)に対して直接+の演算子で連結できます(特定部分の抽出はstr属性に対するスライスで対応しています)。
import pandas as pd
df: pd.DataFrame = pd.read_json(
'https://github.com/simon-ritchie/athena_workshop/blob/main/workshop/login/dt%3D2021-01-01/data.json.gz?raw=true',
lines=True, compression='gzip')
df['year_and_month'] = df['time'].str[0:4] + '年' + df['time'].str[5:7] + '月'
print(df.head())
user_id time device_type year_and_month
0 8590 2021-01-01 00:00:01 1 2021年01月
1 568 2021-01-01 00:00:02 1 2021年01月
2 17543 2021-01-01 00:00:04 2 2021年01月
3 15924 2021-01-01 00:00:07 1 2021年01月
4 5243 2021-01-01 00:00:09 2 2021年01月
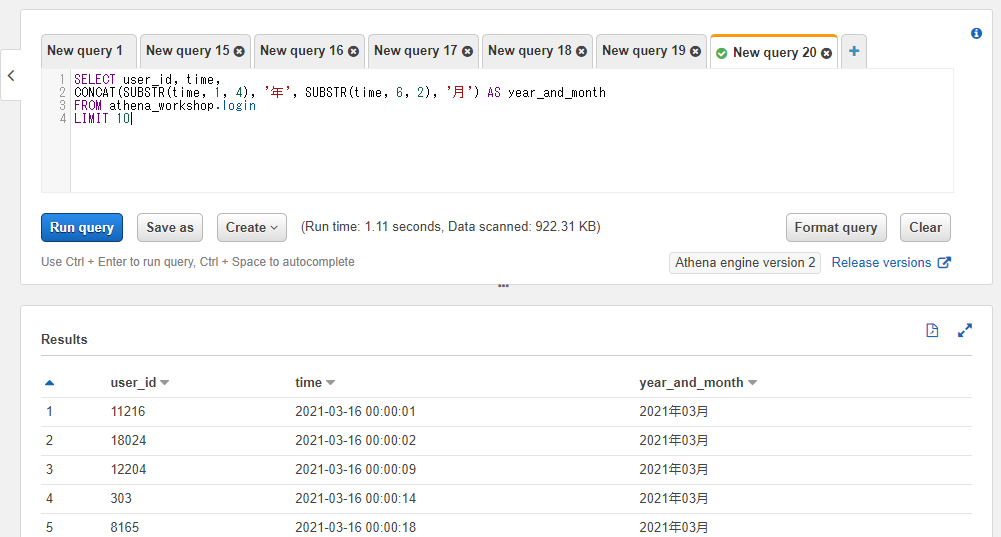
CONCAT関数による文字列の連結
CONCAT関数でも||を使った時と同じような文字列の連結が行えます。各引数に順番に文字列のカラムもしくは固定値などを入れることで連結された結果が返ってきます。引数の個数は任意の個数を設定できます。
SELECT user_id, time,
CONCAT(SUBSTR(time, 1, 4), '年', SUBSTR(time, 6, 2), '月') AS year_and_month
FROM athena_workshop.login
LIMIT 10
文字数を取得する: LENGTH
※この節以降、説明のためにbook_jpというテーブルを扱っていきます。ゲームが関係無いですが、日本語の著作権の切れた本(吾輩は猫である)のセンテンスごとに行が分けられたデータにしてあります。日付は2021-01-01のみで17行のみ入れてあります。
以下のようなデータになっています。
SELECT * FROM athena_workshop.book_jp

LENGTH関数で指定された文字列のカラムもしくは固定値の文字数を取得することができます。日本語とかでも正常にカウントされるようです。
SELECT sentence, LENGTH(sentence) AS string_length FROM athena_workshop.book_jp
LIMIT 5

Pythonでの書き方
対象の文字列のカラムに対してstr属性のlen()メソッドで文字数が取れます。
import pandas as pd
df: pd.DataFrame = pd.read_json(
'https://github.com/simon-ritchie/athena_workshop/blob/main/workshop/book_jp/dt%3D2021-01-01/data.json.gz?raw=true',
lines=True, compression='gzip')
df['string_length'] = df['sentence'].str.len()
print(df[['string_length', 'sentence']].head())
string_length sentence
0 8 吾輩は猫である。
1 8 名前はまだ無い。
2 17 どこで生れたかとんと見当がつかぬ。
3 36 何でも薄暗いじめじめした所でニャーニャー泣いていた事だけは記憶している。
4 20 吾輩はここで始めて人間というものを見た。
大文字変換する: UPPER
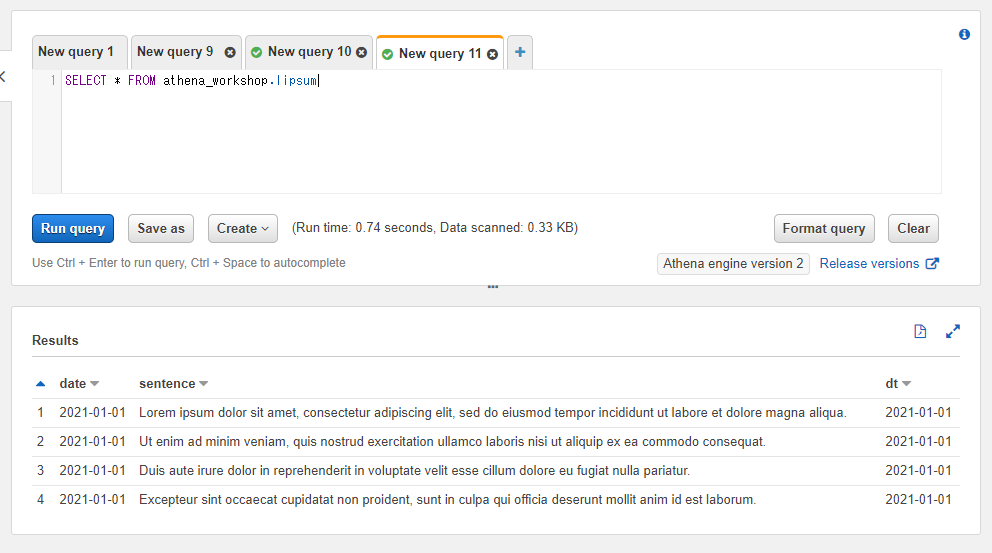
※この節以降、説明のためlipsumというダミーの英文のセンテンスのデータを持つテーブルを扱っていきます(レイアウトチェックなどで良く使われるlorem ipsum...の英文のデータとなります)。lipsumってなんだ・・・?という方は必要に応じてlorem ipsum - Wikipediaなどの記事をご確認ください。
以下のような4行のみのテーブルとなっています。
SELECT * FROM athena_workshop.lipsum
英語の文字列を大文字に変換するにはUPPER関数を使います。uppercaseやcapital letterで大文字という意味なのでそちらに由来します。
SELECT UPPER(sentence) AS upper_sentence FROM athena_workshop.lipsum

Pythonでの書き方
import pandas as pd
df: pd.DataFrame = pd.read_json(
'https://github.com/simon-ritchie/athena_workshop/blob/main/workshop/lipsum/dt%3D2021-01-01/data.json.gz?raw=true',
lines=True, compression='gzip')
df['upper_sentence'] = df['sentence'].str.upper()
print(df.head())
date sentence upper_sentence
0 2021-01-01 Lorem ipsum dolor sit amet, consectetur adipis... LOREM IPSUM DOLOR SIT AMET, CONSECTETUR ADIPIS...
1 2021-01-01 Ut enim ad minim veniam, quis nostrud exercita... UT ENIM AD MINIM VENIAM, QUIS NOSTRUD EXERCITA...
2 2021-01-01 Duis aute irure dolor in reprehenderit in volu... DUIS AUTE IRURE DOLOR IN REPREHENDERIT IN VOLU...
3 2021-01-01 Excepteur sint occaecat cupidatat non proident... EXCEPTEUR SINT OCCAECAT CUPIDATAT NON PROIDENT...
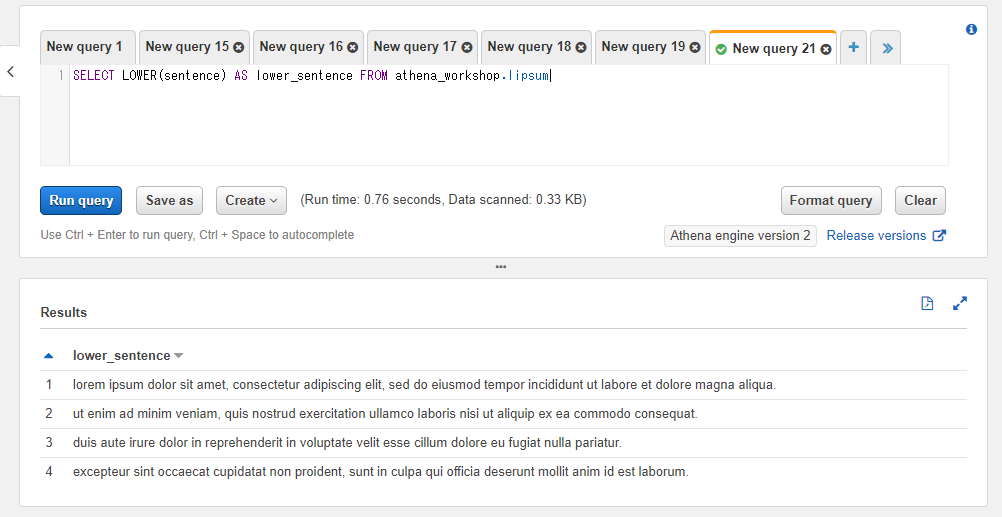
小文字変換する: LOWER
英語の文字列を小文字に変換するにはLOWER関数を使います。lowercaseやsmall letterで小文字という意味なのでそちらに由来します。
SELECT LOWER(sentence) AS lower_sentence FROM athena_workshop.lipsum
該当する文字列を削除もしくは置換する: REPLACE
任意の文字列の削除もしくは置換を行う場合にはREPLACE関数を使います。第一引数には対象の文字列のカラムもしくは固定値、第二引数には削除もしくは置換対象の文字列、第三引数には置換後の文字列を指定します。
第三引数は省略可能で、もし省略した場合には削除の挙動となります。以下のSQLでは猫という文字を削除しています。
SELECT REPLACE(sentence, '猫') AS cat_has_gone_missing
FROM athena_workshop.book_jp

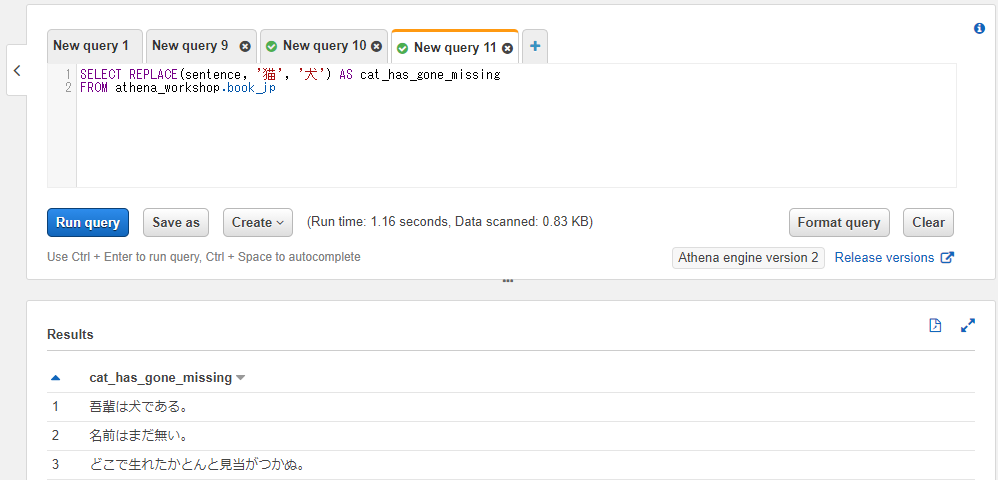
第三引数を指定することで、削除ではなく置換の挙動とすることができます。以下のSQLでは猫という文字を犬に置換しています。
SELECT REPLACE(sentence, '猫', '犬') AS cat_has_gone_missing
FROM athena_workshop.book_jp
Pythonでの書き方
str属性のreplaceメソッドで対応ができます。
import pandas as pd
df: pd.DataFrame = pd.read_json(
'https://github.com/simon-ritchie/athena_workshop/blob/main/workshop/book_jp/dt%3D2021-01-01/data.json.gz?raw=true',
lines=True, compression='gzip')
df['cat_has_gone_missing'] = df['sentence'].str.replace('猫', '犬')
print(df['cat_has_gone_missing'].head())
0 吾輩は犬である。
1 名前はまだ無い。
2 どこで生れたかとんと見当がつかぬ。
3 何でも薄暗いじめじめした所でニャーニャー泣いていた事だけは記憶している。
4 吾輩はここで始めて人間というものを見た。
Name: cat_has_gone_missing, dtype: object
左端に対して文字埋めを行う: LPAD
※以降の節では、以前のシリーズ記事では既出のテーブルとなりますがuser_sales_dailyというテーブルを使っていきます。以下のようなデータのテーブルになっています。
SELECT * FROM athena_workshop.user_sales_daily
WHERE dt = '2021-01-01'
LIMIT 10;

左端に対して文字埋めを行う場合にはLPAD関数を使います。第一引数に文字列のカラムもしくは固定値、第二引数に文字数の整数、第三引数に埋めるための文字を指定します。
例えば第二引数に5、第三引数に'0'と指定すれば5文字になるまで文字列の左端がゼロ埋めされます(00123といった文字列になります)。対象の文字列が既に指定された文字数以上になっている場合には変換処理はされません。
以下のSQLではuser_idカラムの値を5文字になるまでゼロ埋めをしています。user_idカラム自体は整数のカラムなので、一旦CAST(user_id AS VARCHAR)として文字列に型変換しています。
SELECT user_id, LPAD(CAST(user_id AS VARCHAR), 5, '0') AS zero_padding
FROM athena_workshop.user_sales_daily
WHERE dt = '2021-01-01'
LIMIT 10;

Pythonでの書き方
str属性のpadメソッドで扱えます。右端と同様のメソッドとなります。width引数に文字数、side引数にはleft, right, bothなどの左端や右端などの指定を行います。埋める文字にはfillchar引数を使います。
import pandas as pd
df: pd.DataFrame = pd.read_json(
'https://github.com/simon-ritchie/athena_workshop/blob/main/workshop/user_sales_daily/dt%3D2021-01-01/data.json.gz?raw=true',
lines=True, compression='gzip')
df['zero_padding'] = df['user_id'].astype(str, copy=False)
df['zero_padding'] = df['zero_padding'].str.pad(width=5, side='left', fillchar='0')
print(df['zero_padding'])
もしくは単純にゼロ埋めするだけならもっとシンプルなzfillメソッドも存在します。引数は文字数のwidthのみです。
import pandas as pd
df: pd.DataFrame = pd.read_json(
'https://github.com/simon-ritchie/athena_workshop/blob/main/workshop/user_sales_daily/dt%3D2021-01-01/data.json.gz?raw=true',
lines=True, compression='gzip')
df['zero_padding'] = df['user_id'].astype(str, copy=False)
df['zero_padding'] = df['zero_padding'].str.zfill(width=5)
print(df['zero_padding'].head())
0 19288
1 00132
2 02183
3 12446
4 04894
Name: zero_padding, dtype: object
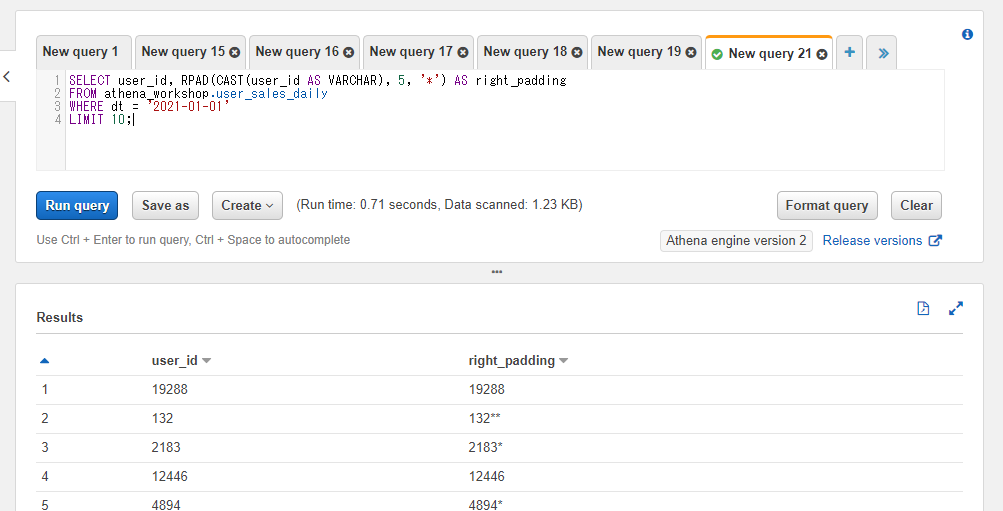
右端に対して文字埋めを行う: RPAD
左端の文字埋めよりかは利用頻度が落ちそうですが、右端に文字埋めを行う場合にはRPAD関数を使います。
SELECT user_id, RPAD(CAST(user_id AS VARCHAR), 5, '*') AS right_padding
FROM athena_workshop.user_sales_daily
WHERE dt = '2021-01-01'
LIMIT 10;
Pythonでの書き方
import pandas as pd
df: pd.DataFrame = pd.read_json(
'https://github.com/simon-ritchie/athena_workshop/blob/main/workshop/user_sales_daily/dt%3D2021-01-01/data.json.gz?raw=true',
lines=True, compression='gzip')
df['right_padding'] = df['user_id'].astype(str, copy=False)
df['right_padding'] = df['right_padding'].str.pad(width=5, side='right', fillchar='*')
print(df['right_padding'].head())
0 19288
1 132**
2 2183*
3 12446
4 4894*
Name: right_padding, dtype: object
左端のスペースなどを取り除く: LTRIM
※この節以降説明のためbook_jp_with_white_spaceというテーブルを扱っていきます。少し前の節から触れだしたbook_jpという日本語の文章を含んだテーブルとほぼ同じ内容ですが、最初の数行は文字列データの両端に空白文字を含ませてあります。
具体的には1行目には両端に半角のスペースを2文字ずつ、2行目には両端に全角スペースを2文字ずつ、3行目には両端に改行を2つずつ、4行目は両端にタブを2文字ずつ追加してあります。
AWSのwebコンソール上だとそのままだと内容が把握しづらい感じ(スペースや改行などがほぼ消えていたり等)ですが、LENGTH関数などで文字数をカウントしてみると空白文字分がカウントされていることが分かります(例 : 吾輩は猫である。で8文字ですが、両端にスペースが2文字ずつ含まれているので12文字と表示されます)。
SELECT sentence, LENGTH(sentence) AS length FROM athena_workshop.book_jp_with_white_space
LIMIT 5;

また、SUBSTR関数などで左端の4文字を抽出してみると吾輩といった部分のみ抽出されており、左端に2文字分の空白文字が存在することが分かります。
SELECT sentence, LENGTH(sentence) AS length,
SUBSTR(sentence, 1, 4) AS left_four_chars
FROM athena_workshop.book_jp_with_white_space
LIMIT 5;

LTRIM関数は左端の空白文字を取り除きます。半角スペース・全角スペース・改行・タブなどが対象となります。
以下のSQLでは左端の2文字ずつの空白文字が削除されているため、元の文字数(original_length)よりも2文字分文字数が減っていることを確認できます。
SELECT LTRIM(sentence) AS sentence,
LENGTH(sentence) AS original_length,
LENGTH(LTRIM(sentence)) AS length,
SUBSTR(LTRIM(sentence), 1, 4) AS left_four_chars
FROM athena_workshop.book_jp_with_white_space
LIMIT 5;

Pythonでの書き方
str属性のlstripで対応ができます。
import pandas as pd
df: pd.DataFrame = pd.read_json(
'https://github.com/simon-ritchie/athena_workshop/blob/main/workshop/book_jp_with_white_space/dt%3D2021-01-01/data.json.gz?raw=true',
lines=True, compression='gzip')
df['left_four_chars'] = df['sentence'].str.lstrip()
df['left_four_chars'] = df['left_four_chars'].str[0:4]
print(df['left_four_chars'].head())
0 吾輩は猫
1 名前はま
2 どこで生
3 何でも薄
4 吾輩はこ
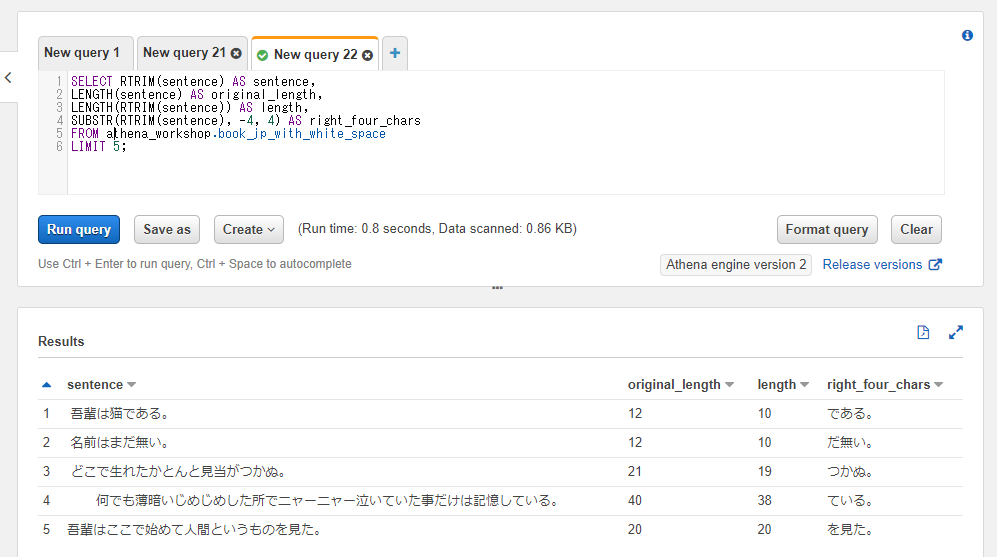
右端のスペースなどを取り除く: RTRIM
RTRIMは右端に対して空白文字を取り除きます。左端か右端かの違いだけで挙動はほぼLTRIMと同じです。
※後々の節で触れますが、以下のSQLではSUBSTR関数で開始位置に負の値(-4)を指定しています。これは右端から何文字目・・・といった挙動になります。
SELECT RTRIM(sentence) AS sentence,
LENGTH(sentence) AS original_length,
LENGTH(RTRIM(sentence)) AS length,
SUBSTR(RTRIM(sentence), -4, 4) AS right_four_chars
FROM athena_workshop.book_jp_with_white_space
LIMIT 5;
Pythonでの書き方
str属性のrstripメソッドで対応ができます。
import pandas as pd
df: pd.DataFrame = pd.read_json(
'https://github.com/simon-ritchie/athena_workshop/blob/main/workshop/book_jp_with_white_space/dt%3D2021-01-01/data.json.gz?raw=true',
lines=True, compression='gzip')
df['right_four_chars'] = df['sentence'].str.rstrip()
df['right_four_chars'] = df['right_four_chars'].str[-4:]
print(df['right_four_chars'].head())
0 である。
1 だ無い。
2 つかぬ。
3 ている。
4 を見た。
Name: right_four_chars, dtype: object
両端のスペースなとを取り除く: TRIM
TRIM関数は左端と右端両方から空白文字を取り除きます。
SELECT TRIM(sentence) AS sentence,
LENGTH(sentence) AS original_length,
LENGTH(TRIM(sentence)) AS length,
SUBSTR(TRIM(sentence), 1, 4) AS left_four_chars,
SUBSTR(TRIM(sentence), -4, 4) AS right_four_chars
FROM athena_workshop.book_jp_with_white_space
LIMIT 5;

Pythonでの書き方
str属性のstripメソッドで両端の空白文字が削除できます。
import pandas as pd
df: pd.DataFrame = pd.read_json(
'https://github.com/simon-ritchie/athena_workshop/blob/main/workshop/book_jp_with_white_space/dt%3D2021-01-01/data.json.gz?raw=true',
lines=True, compression='gzip')
df['stripped_sentence'] = df['sentence'].str.strip()
df['left_four_cahrs'] = df['stripped_sentence'].str[0:4]
df['right_four_chars'] = df['stripped_sentence'].str[-4:]
print(df[['left_four_cahrs', 'right_four_chars']].head())
left_four_cahrs right_four_chars
0 吾輩は猫 である。
1 名前はま だ無い。
2 どこで生 つかぬ。
3 何でも薄 ている。
4 吾輩はこ を見た。
文字列を分割して配列を取得する: SPLIT
※この節以降、user_weapon_csv_dailyというテーブルを説明のため利用していきます。このテーブルはユーザーの日次の所持している武器のIDがコンマ区切りで保存されています。各日付で各ユーザーの行は1行保存されます。同じ武器は1ユーザーで同時に複数持ちうる形で設定してあります。
以下のようなデータになっています。
SELECT * FROM athena_workshop.user_weapon_csv_daily LIMIT 10;

Athena(Presto)では配列や辞書などのカラムの型もサポートしているため、こういったデータは通常配列もしくはネストさせずに行列変換してあると扱うのが楽です。ただし加工前のデータや昔からのデータはこういったように文字列で入っていたりするケースもあります(JSONの文字列で入っていたりなど)のでサンプルとしてこのテーブルではコンマ区切りの文字列にしてあります。
SPLIT関数では任意の文字区切りで文字列を分割し配列に変換することができます。配列に関しては後々(恐らく別のシリーズ記事)で詳しく触れていきますが、配列変換されるとAthena上で色々な配列操作が可能になります。
第一引数には対象の文字列のカラムもしくは固定値、第二引数には区切り文字を指定します。今回はコンマ区切りの武器データを扱っていくため第二引数にはコンマを指定しています。
SELECT user_id, SPLIT(weapon_csv, ',') AS weapon_array
FROM athena_workshop.user_weapon_csv_daily
LIMIT 10;
クエリ実行結果を見てみると[241, 162, ...]といったように[]の括弧などが確認でき、結果が文字列から配列になっていることが分かります。

SPLIT_PART
SPLIT_PART関数はSPLIT関数のように文字列の分割を行いますが、加えて分割後の配列の特定の位置にある単一の値を抽出します。第三引数として抽出したい値の位置の整数が追加になっています。例えば第三引数に2を指定すると配列の2番目の値が取得できます。この位置の整数は1からスタートします(プログラミングの配列のインデックスなどでよくあるように0ではありません)。また、指定された位置が配列の件数を超えている場合には欠損値となります。
以下のSQLでは配列の2番目の値を取得しています(second_valueというカラム名を付けています)。
SELECT user_id, SPLIT_PART(weapon_csv, ',', 2) AS second_value, weapon_csv
FROM athena_workshop.user_weapon_csv_daily
LIMIT 10;

SPLIT_TO_MAP
※この節以降説明のためにurl_dataというデータに触れていきます。urlとurl_parameterという2つのカラムのみ、行も2行のみのシンプルなテーブルです。
SELECT * FROM athena_workshop.url_data

SPLIT_TO_MAP関数は文字列内の特定の文字でパラメーターを分割し、さらにその分割結果を別の文字でキーと値と辞書に分割する関数です。辞書関係については後々(恐らく別の記事)で詳しく触れていきます。
例えばURLのパラメーターでparameter_1=10¶meter_2=20¶meter_3=2021みたいな形で、パラメーターは&区切りで且つキー(parameter_1などの部分)と値(10などの部分)が存在する場合の分割制御に使えます。他にも特殊で形式でログが保存されているケース、例えばJSON風に"parameter_1": 10, "parameter_2": 20みたいにパラメーターはコンマ区切り、キーと値はセミコロン区切りで保存されている・・・みたいなケースでも使えます。
SPLIT_TO_MAP関数では第一引数に対象のカラムや固定値、第二引数にパラメーター単位で分割する文字、第三引数にキーと値の分割で使う文字を指定します。
SELECT url_parameter, SPLIT_TO_MAP(url_parameter, '&', '=') AS url_parameter_dict
FROM athena_workshop.url_data
結果に{}の括弧の表記が付いており辞書の値になっていることが確認できます。

Pythonでの書き方
探せばこの処理専用のインターフェイスがあるかもしれませんが、軽く調べた感じ見つからなかったため、Pandasで扱う場合にはapplyとかのメソッドで関数を反映する・・・とやるのがシンプルかなという所感です。
from typing import Dict, List
import pandas as pd
def split_to_map(value: str) -> Dict[str, str]:
"""
指定された文字列の値を辞書に変換する。
Parameters
----------
value : str
対象の文字列。パラメーターは&の記号単位、キーと値は=の記号単位で
分割が実行される。
Returns
-------
map_data : dict
文字列から生成された辞書。
"""
map_data: Dict[str, str] = {}
parameters: List[str] = value.split('&')
for parameter in parameters:
key_and_value: List[str] = parameter.split('=')
map_data[key_and_value[0]] = key_and_value[1]
return map_data
df: pd.DataFrame = pd.read_json(
'https://github.com/simon-ritchie/athena_workshop/blob/main/workshop/url_data/dt%3D2021-01-01/data.json.gz?raw=true',
lines=True, compression='gzip')
df['url_parameter_dict'] = df['url_parameter'].apply(split_to_map)
print(df[['url_parameter', 'url_parameter_dict']])
url_parameter url_parameter_dict
0 product_id=1&month=2021-01-01&sort=1 {'product_id': '1', 'month': '2021-01-01', 'so...
1 product_id=5&month=2021-03-01&sort=0 {'product_id': '5', 'month': '2021-03-01', 'so...
SPLIT_TO_MULTIMAP
SPLIT_TO_MULTIMAPはSPLIT_TO_MAP関数よりも特殊で、同名のキーが複数あるケースで使えます(しかし今のところあまり使うケースが思いつきません・・・)。
結果がキーごとの配列で各値を格納する辞書となります。同じキーのものは配列に格納されるため、キーが重複していても扱うことができます。
使うケースが少なそうなのでサンプル用のテーブルは設けずにライトに固定値で扱ってこの節は終えようと思います。id=10,id=12,id=13,month=2021-01という文字列で、idとmonthの2つのキーが存在し、idのキーは複数の値が存在する形で進めます。
SELECT SPLIT_TO_MULTIMAP('id=10,id=12,id=13,month=2021-01', ',', '=')
結果の辞書に含まれる値が配列になっていることを確認できます。

左端から検索して任意の文字列がn番目に出現する位置を調べる: STRPOS と POSITION
STRPOS関数は、文字列内で特定の文字列が出現する位置の整数を取得することができます。検索は文字列の左端から行われます。見つからない場合には0となり、1文字目の位置は1となります。Pythonなどだと見つからなかった場合には-1, 1文字目の位置が0・・・となったりするのでその辺のずれは少し注意が必要です。
SELECT sentence, STRPOS(sentence, '猫') AS cat_position
FROM athena_workshop.book_jp
POSITION関数はSTRPOS関数と同じ挙動をします。ただし書き方が変わり、POSITION('検索したい文字列' IN カラム名)といった形で各引数で指定するのではなくINを使った書き方になります。
SELECT sentence, POSITION('猫' IN sentence) AS cat_position
FROM athena_workshop.book_jp

Pythonでの書き方
str属性のfindメソッドで近いことができます。注意点として、Pythonでは見つからなかった場合には-1、最初の文字が0・・・となるのでSQL側と1ずれます。
import pandas as pd
df: pd.DataFrame = pd.read_json(
'https://github.com/simon-ritchie/athena_workshop/blob/main/workshop/book_jp/dt%3D2021-01-01/data.json.gz?raw=true',
lines=True, compression='gzip')
df['cat_index'] = df['sentence'].str.find('猫')
print(df[['cat_index', 'sentence']].head())
cat_index sentence
0 3 吾輩は猫である。
1 -1 名前はまだ無い。
2 -1 どこで生れたかとんと見当がつかぬ。
3 -1 何でも薄暗いじめじめした所でニャーニャー泣いていた事だけは記憶している。
4 -1 吾輩はここで始めて人間というものを見た。
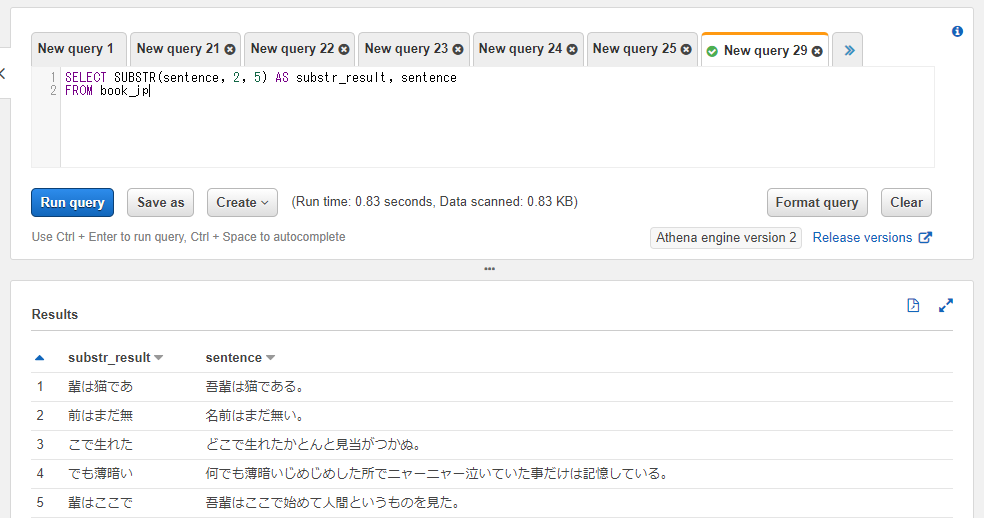
特定範囲の文字列を抽出する: SUBSTR
SUBSTR関数は文字列のカラムや固定値から特定の範囲の文字列を抽出します。「n文字目からm文字を抽出」といった挙動になります。
第一引数には対象のカラム名もしくは固定値、第二引数には抽出する文字の開始位置の整数、第三引数には抽出する文字数の整数を指定します。第二引数の文字の開始位置は1からスタートし、1が先頭の文字となります。0からのスタートではない点に注意してください。
以下のSQLでは2文字目から5文字を抽出しています。
SELECT SUBSTR(sentence, 2, 5) AS substr_result, sentence
FROM athena_workshop.book_jp
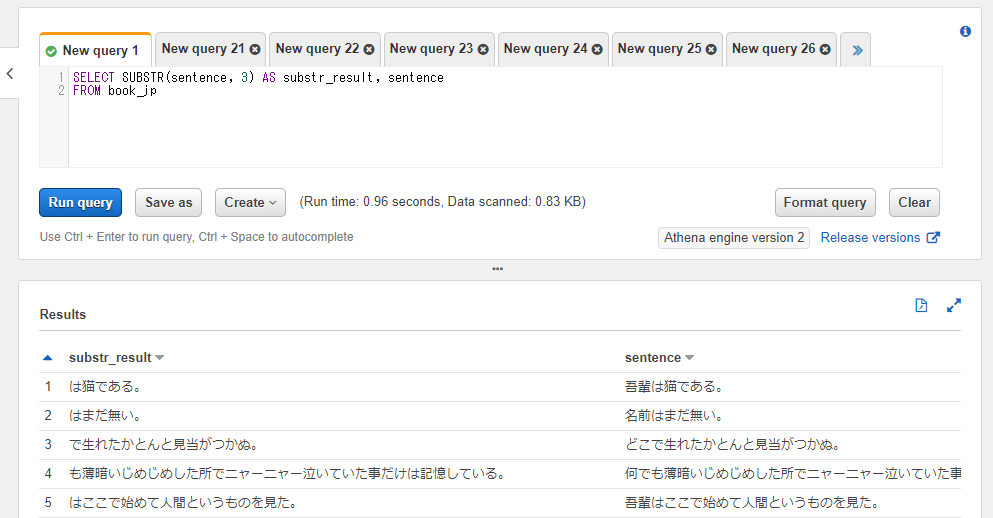
第三引数を省略した場合には指定された文字以降の全ての文字が対象となります。
SELECT SUBSTR(sentence, 3) AS substr_result, sentence
FROM athena_workshop.book_jp
第二引数には負の値も指定することができます。負の値を指定した場合、右端からのカウントとなります。例えば-1を指定すれば最後の文字の位置、-2を指定すれば最後から2番目の文字...となります。この辺はPythonのインデックスと似たような挙動ですね。
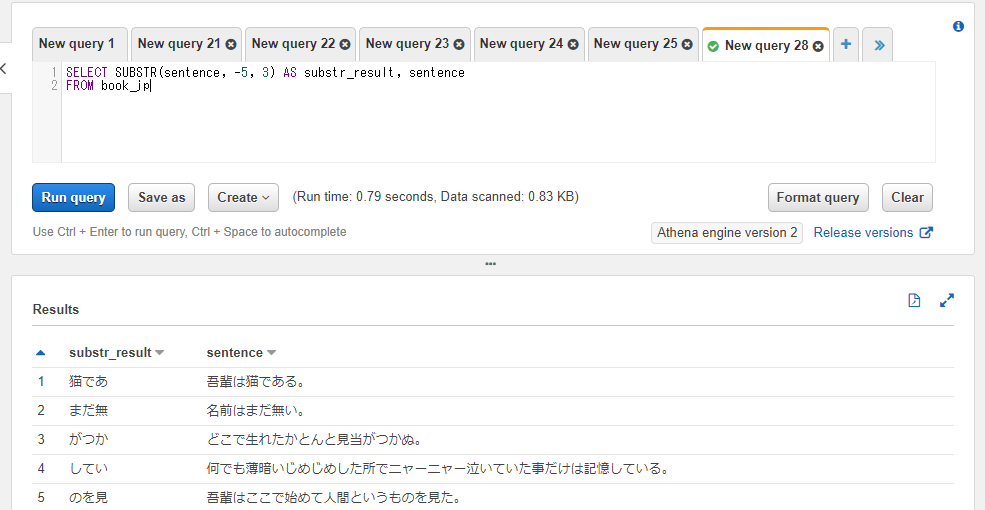
SELECT SUBSTR(sentence, -5, 3) AS substr_result, sentence
FROM athena_workshop.book_jp
Pythonでの書き方
str属性はスライスが効くのでそちらでSUBSTR関数と似たようなことができます。インデックスは0からスタートするのと、文字数指定ではなくn文字目~m文字目の文字範囲・・・といった指定になるという違いはあります。
import pandas as pd
df: pd.DataFrame = pd.read_json(
'https://github.com/simon-ritchie/athena_workshop/blob/main/workshop/book_jp/dt%3D2021-01-01/data.json.gz?raw=true',
lines=True, compression='gzip')
df['substr_result'] = df['sentence'].str[1:6]
print(df[['substr_result', 'sentence']].head())
substr_result sentence
0 輩は猫であ 吾輩は猫である。
1 前はまだ無 名前はまだ無い。
2 こで生れた どこで生れたかとんと見当がつかぬ。
3 でも薄暗い 何でも薄暗いじめじめした所でニャーニャー泣いていた事だけは記憶している。
4 輩はここで 吾輩はここで始めて人間というものを見た。
文字列を逆順にする: REVERSE
REVERSE関数は文字列を逆順に変換します。

Pythonでの書き方
str属性にreverseメソッドなどは無いようです。ただしPythonのビルトインの文字列は以下のインデックスの指定で逆順に変換することができます。
str_val: str = '吾輩は猫である。'
reversed_str: str = str_val[::-1]
print(reversed_str)
。るあで猫は輩吾
これを使ってapplyメソッドでlambda式かもしくは関数を反映すれば逆順にできます。
import pandas as pd
df: pd.DataFrame = pd.read_json(
'https://github.com/simon-ritchie/athena_workshop/blob/main/workshop/book_jp/dt%3D2021-01-01/data.json.gz?raw=true',
lines=True, compression='gzip')
df['reversed'] = df['sentence'].apply(lambda sentence: sentence[::-1])
print(df[['reversed', 'sentence']].head())
reversed sentence
0 。るあで猫は輩吾 吾輩は猫である。
1 。い無だまは前名 名前はまだ無い。
2 。ぬかつが当見とんとかたれ生でこど どこで生れたかとんと見当がつかぬ。
3 。るいてし憶記はけだ事たいてい泣ーャニーャニで所たしめじめじい暗薄もで何 何でも薄暗いじめじめした所でニャーニャー泣いていた事だけは記憶している。
4 。た見をのもういと間人てめ始でここは輩吾 吾輩はここで始めて人間というものを見た。
ハミング距離の取得: HAMMING_DISTANCE
HAMMING_DISTANCE関数は2つの文字間のハミング距離の整数を得ることができます。ハミング距離ってなんだ・・・?という感じですが、定義としては「同じ文字数の文字同士で、何文字違うか」のカウント数となります。
例えば吾輩は猫である。という文字に対して吾輩は猫である。という文字列は完全に一致しているのでハミング距離は0となります。吾輩は犬である。という文字列は犬という1文字が異なるのでハミング距離は1となります。我々は猫である。という文字列であれば我々という2文字が異なるのでハミング距離は2となります。
必要に応じて詳細に関してはWikipediaのハミング距離の記事などをご確認ください。
SELECT
HAMMING_DISTANCE(sentence, '吾輩は猫である。') AS distance_1,
HAMMING_DISTANCE(sentence, '吾輩は犬である。') AS distance_2,
HAMMING_DISTANCE(sentence, '我々は猫である。') AS distance_3,
sentence
FROM athena_workshop.book_jp
WHERE sentence = '吾輩は猫である。'

なお、ハミング距離は2つの文字列それぞれの文字数が一致していないといけません。以下のように長さの違う文字列を指定してみるとエラーになってしまいます。
SELECT
HAMMING_DISTANCE(sentence, '私は猫である。') AS distance,
sentence
FROM athena_workshop.book_jp
WHERE sentence = '吾輩は猫である。'

Pythonでの書き方
Pandasには直接のインターフェイスは無さそう?ではあります。ライブラリを使うならScipyやscikit-learnなどならインターフェイスがありそうです(それらのライブラリのハミング距離関係のインターフェイスを利用したことはありませんので詳しくはありません・・・)。
シンプルな計算なのでPandasなどで完結したい場合には以下のように直接Pythonで計算しても良さそうではあります。
from typing import List
import pandas as pd
df: pd.DataFrame = pd.DataFrame(
data=[{
'sentence_1': '吾輩は猫である。',
'sentence_2': '吾輩は猫である。',
}, {
'sentence_1': '吾輩は猫である。',
'sentence_2': '吾輩は犬である。',
}, {
'sentence_1': '吾輩は猫である。',
'sentence_2': '我々は猫である。',
}])
sentence_1_list: List[str] = df['sentence_1'].tolist()
sentence_2_list: List[str] = df['sentence_2'].tolist()
distances: List[int] = []
for sentence_1, sentence_2 in zip(sentence_1_list, sentence_2_list):
distance: int = 0
for char_1, char_2 in zip(sentence_1, sentence_2):
if char_1 != char_2:
distance += 1
distances.append(distance)
df['distance'] = distances
print(df)
sentence_1 sentence_2 distance
0 吾輩は猫である。 吾輩は猫である。 0
1 吾輩は猫である。 吾輩は犬である。 1
2 吾輩は猫である。 我々は猫である。 2
レーベンシュタイン距離の取得: LEVENSHTEIN_DISTANCE
レーベンシュタイン距離はハミング距離と同様に文字列間の差分の大きさの距離となります。Athena(Presto)上ではLEVENSHTEIN_DISTANCE関数で扱えます。
文字の挿入・削除・置換をそれぞれ距離1と計算し、どれだけ2の変換距離で同じ文字列に変換できるか・・・といった値になります。詳しい計算例としてはWikipediaに載っていたので引用しておきます。
実際的な距離の求め方を例示すれば、「kitten」を「sitting」に変形する場合には、以下に示すように最低でも 3 回の手順が必要とされるので、2単語間のレーベンシュタイン距離は 3 となる。
1.「kitten」
2.「sitten」(「k」を「s」に置換)
3.「sittin」(「e」を「i」に置換)
4.「sitting」(「g」を挿入して終了)
レーベンシュタイン距離 - Wikipedia
ハミング距離との大きな違いとして、こちらは2つの文字列間の文字数が一致していなくとも使えます。中々文字数が一致しているデータ・・・というのも使えるケースが限られてくるので、ハミング距離よりも気軽に使いやすい関数と言えます。
SQL上での引数などはハミング距離と同じです。以下のSQLではわざと「私は犬である。」という文字数が一致していないものを追加しています。
SELECT
LEVENSHTEIN_DISTANCE(sentence, '吾輩は猫である。') AS distance_1,
LEVENSHTEIN_DISTANCE(sentence, '吾輩は犬である。') AS distance_2,
LEVENSHTEIN_DISTANCE(sentence, '我々は猫である。') AS distance_3,
LEVENSHTEIN_DISTANCE(sentence, '私は犬である。') AS distance_4,
sentence
FROM athena_workshop.book_jp
WHERE sentence = '吾輩は猫である。'

Pythonでの書き方
Pandasなどではダイレクトなインターフェイスは無さそう・・・な気配があるので、python-Levenshteinなどのライブラリを使うのが手っ取り早いかもしれません。
LIKE句による部分検索
LIKE句を使うとWHERE文などで特定の文字列の部分検索を行うことができます。特定部分が一致していればOKとするような、前方一致・後方一致・部分一致などの制御を行うことができます。検索ワードの表記がぶれる場合など、複数の検索対象が存在する場合や部分的な検索をしたい場合、キーワードがうろ覚えな場合などに便利です。
WHERE 対象カラム LIKE '検索文字列'といったように使います。また、検索文字列内には%もしくは_の文字が同時に必要になります。
%の記号は繰り返し回数の制約のない任意の文字列の指定を行うように使います。ファイルパスの指定などでの*.csvみたいな時のアスタリスク表記や、正規表現の.*の繰り返しなどに近い挙動になります。
例えば%は猫であるという文字列になっていれば文字の先頭部分は任意の文字列・任意の文字数でも検索結果の対象となります。吾輩は猫であるでも私は猫であるでもヒットします。つまり後方一致の検索となります。
一方で_の記号は「任意の1文字」という指定になります。%と比べて文字数の制約が追加されている形となります。正規表現だと.の記号と近い感じになります。
つまり検索文字列が吾輩は_であるという文字列になっていれば吾輩は猫であるや吾輩は犬であるといった文字数も一致するものがヒットします。一方で吾輩はライオンであるといったものは文字数が一致していないのでヒットしなくなります(吾輩は____であるといったように4文字のアンダースコアの繰り返しで、4文字の任意の文字列・・・とすれば今度はライオンがヒットするようになります)。
いくつか実際にSQLを踏まえて触れていきます。
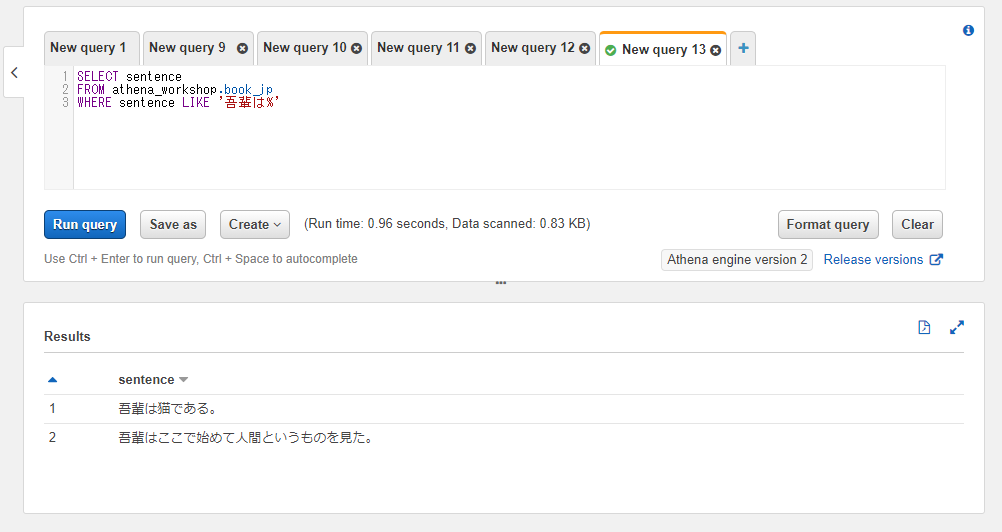
前方一致で検索したい場合 :
SELECT sentence
FROM athena_workshop.book_jp
WHERE sentence LIKE '吾輩は%'
後方一致で検索したい場合:
SELECT sentence
FROM athena_workshop.book_jp
WHERE sentence LIKE '%猫である。'

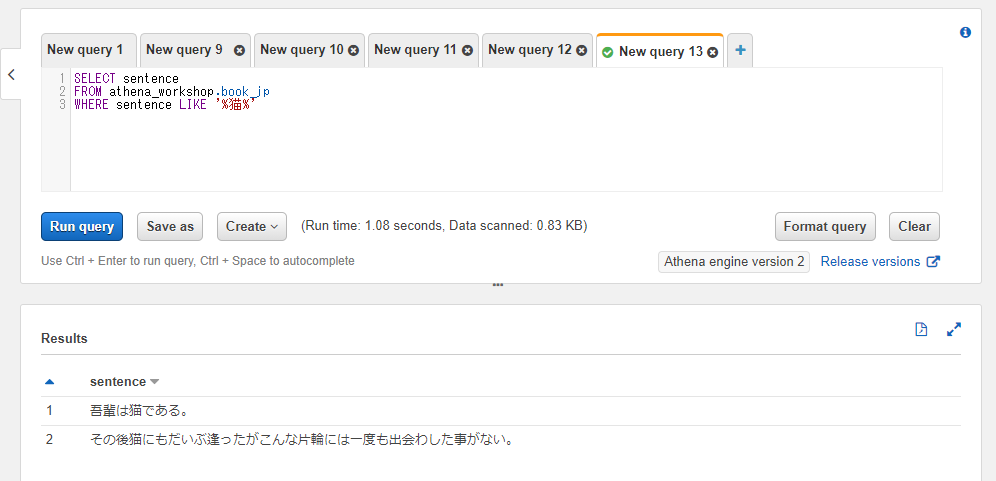
部分一致で検索したい場合(曖昧検索):
SELECT sentence
FROM athena_workshop.book_jp
WHERE sentence LIKE '%猫%'
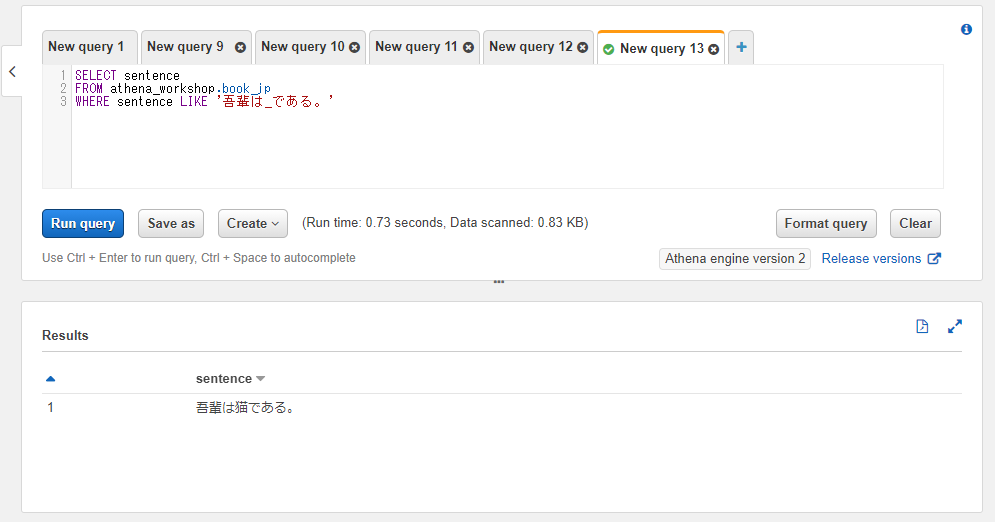
アンダースコアを使って特定の1文字を任意の文字として検索したい場合 :
SELECT sentence
FROM athena_workshop.book_jp
WHERE sentence LIKE '吾輩は_である。'
Pythonでの書き方
前方一致であればstr属性のstartswithメソッドで真偽値のシリーズが取れるので、そちらでスライスすれば対応ができます。
import pandas as pd
df: pd.DataFrame = pd.read_json(
'https://github.com/simon-ritchie/athena_workshop/blob/main/workshop/book_jp/dt%3D2021-01-01/data.json.gz?raw=true',
lines=True, compression='gzip')
df = df[df['sentence'].str.startswith('吾輩は')]
print(df[['sentence']].head())
sentence
0 吾輩は猫である。
4 吾輩はここで始めて人間というものを見た。
%や_の記号をエスケープする
部分検索などで使う%や_の記号は場合によってはエスケープしたい(そのままの文字として使いたい)場合があります。例えば前節までで触れたurl_dataというテーブルについて考えます。URL関係のデータを含むテーブルなのですが、値の中に_の記号が含まれています。
SELECT * FROM athena_workshop.url_data

このようなテーブルで例えばathena_workshop_test.comという文字列を部分一致で検索したいとします。しかし%athena_workshop_test.com%とするとアンダースコア部分は任意の文字でヒットしてしまうので仮にathena-workshop-test.comやathena.workshop.test.comといった文字列の行があってもヒットしてしまいます。
そういった場合のエスケープ処理(次に続く%や_の記号の本来の挙動を無視し、通常の文字として扱う)ためにESCAPEという指定ができます。WHERE カラム名 LIKE 検索文字列 ESCAPE 'エスケープしたい文字の前に指定する文字'といったように書きます。例えばエスケープしたい文字の前に指定する文字に'#'を指定した場合、_の前に#の記号を配置するとこのアンダースコアはエスケープされて通常の文字として扱われるようになります。
先ほどの部分一致の条件でエスケープをしつつSQLを実行したい場合には以下のようになります。
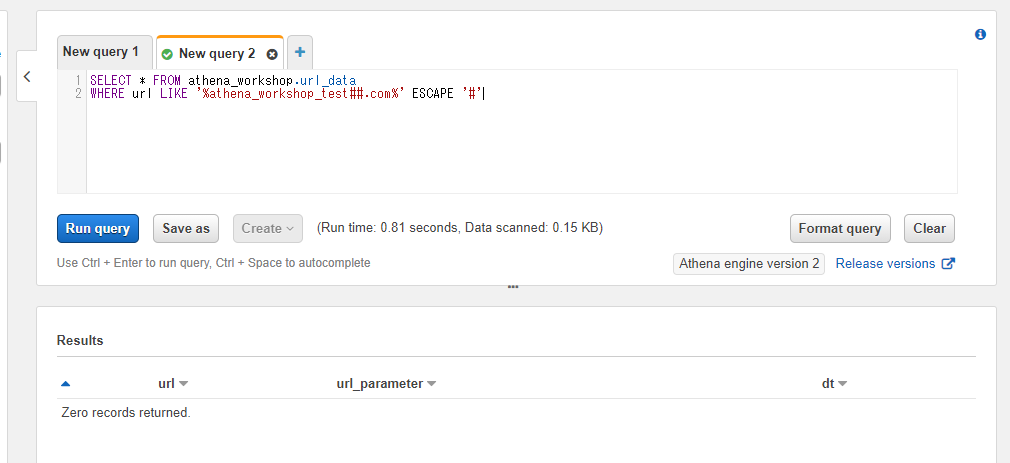
SELECT * FROM athena_workshop.url_data
WHERE url LIKE '%athena#_workshop#_test.com%' ESCAPE '#'

なお、このESCAPEで指定した文字は%と_、もしくはこの文字自体の直前にのみ配置できます。他の文字の前に存在するとエラーになります。
SELECT * FROM athena_workshop.url_data
WHERE url LIKE '%athena_workshop_test#.com%' ESCAPE '#'

ESCAPEに指定した文字自体を検索条件の文字列に含みたい場合には##といったように該当の文字を2つ連続させることでクエリ自体はエラー無く通るようになります。
SELECT * FROM athena_workshop.url_data
WHERE url LIKE '%athena_workshop_test##.com%' ESCAPE '#'
正規表現
この節以降ではAthena(Presto)での正規表現について触れていきます。Athena(Presto)での正規表現はJavaのものがベースとなっているようです(ただしある程度例外があるようです)。
正規表現自体については、JavaではなくPythonのものとなり若干方言の差があるとは思いますが以前記事を書いているので必要に応じてそちらもご参照ください(正規表現自体が奥深く記事がかなり長くなるので本記事では正規表現それ自体には深くは触れません)。
正規表現のフラグ設定
正規表現にはフラグと呼ばれる、正規表現の挙動を調整・変更するためのオプションの指定ができるようになっています。
Pythonだと正規表現でフラグを設定したい場合にはflags引数にre.DOTALL | re.MULTILINEみたいな感じで指定していました。
Javaだと第二引数にPattern.DOTALL | Pattern.MULTILINEみたいな指定をする方法に加えて正規表現のパターンの文字列中に(?i)などの文字列を含めることでフラグを設定す方法もあります。Athena(Presto)では後者の方のパターン内にフラグの記述を含める形が必要になるようです。
フラグをパターンの途中で指定した場合にはそれ以降で該当のパターンが有効化されます(例 : 'abc(?i)ABC'とされていればABC部分だけパターンが有効になります)。
複数指定したい場合にはそれぞれを連続させてパターン内に記述したい場合には'(?m)(?s)abcABC'のように指定します。
主に使われるフラグの抜粋
全てのフラグには触れませんが、主要なものを一部だけ載せておきます。
-
(?i): 大文字小文字を無視するようになります。例えばパターンでaと指定したらaでもAでもヒットするようになります。Pythonだとre.IGNORECASEに該当します。 -
(?m): 複数行を扱う場合の設定です(複数行モード)。これを指定しないと例えば複数行の文字列を対象とする場合に、行の先頭の判定などが最初の文字だけで処理されます。このフラグを指定した場合には改行の度に行の先頭などが判定されるようになります。Pythonだとre.MULTILINEが該当します。 -
(?s): パターン内の.(任意の文字単体のパターン)が改行なども対象とするようになります。Pythonだとre.DOTALLが該当します。
Athena(Presto)特有の注意点
基本的にはJavaの正規表現の資料を調べれば解決しそうですが、Athena(Presto)特有の注意点も若干あります。全てではありませんが、公式ドキュメントを読みつついくつか触れていきます。
改行コードは\nのみが認識される
(?m)の複数行モードを指定した場合、改行は\nのみ認識されます。また、Javaにある(?d)のフラグ(\nのみが対象となるUNIX_LINESのフラグ)は元から\nのみがサポートされている形となっているので使えません。(?m)のフラグの方を使うように、と公式ドキュメントに書かれています。
(?u)のフラグはサポートされていない
Athena(Presto)上では元から大文字と小文字判定がUnicodeに準拠した判定となるため、(?u)のフラグ値(Unicodeに準拠した大文字と小文字を区別しない設定)はサポートされていません。代わりに(?i)を使うことで同じ挙動になります。
\Qと\Eが特定条件ではサポートされていない
\Q(エスケープ処理の開始地点のパターン)と\E(エスケープ処理の終了地点のパターン)は文字列クラス内([A-Z]的な箇所)ではサポートされていない・・・と公式ドキュメントに書かれています。まあ普通にPythonとかではそもそもサポートされていない(JavaやPerlとかで普段作業されている方には結構使われている・・・かもしれません)ので、あまりこの辺は気にならないので深追いせずに次の節に行こうと思います。
パターンにマッチした最初の文字列を取得する: REGEXP_EXTRACT
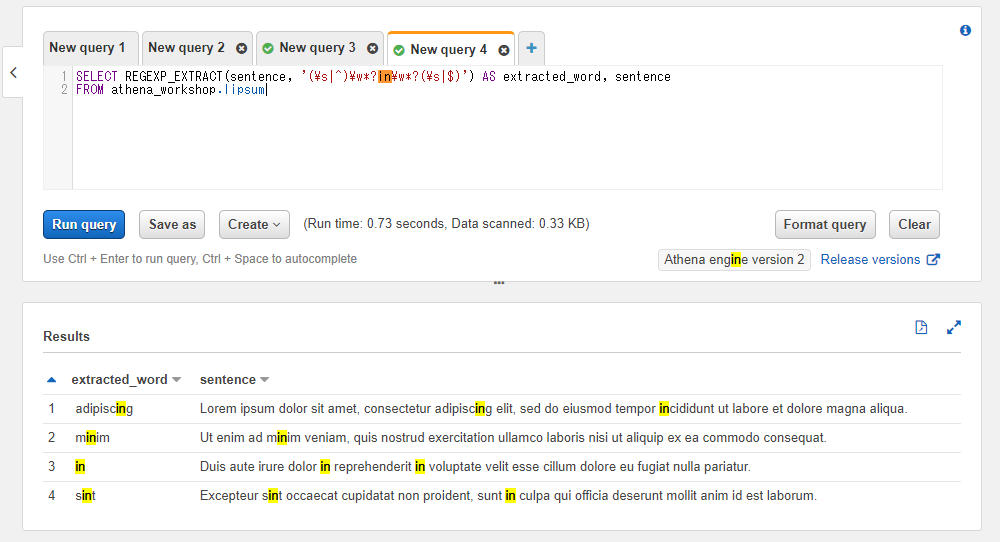
REGEXP_EXTRACT関数は正規表現でパターンにマッチした最初の文字列を取得します。複数マッチする場合でも先頭の1件のパターン部分のみ抽出されます。第一引数には対象のカラム名もしくは固定値、第二引数に正規表現のパターンを指定します。
以下のSQLでは試しにinを含む単語を抽出しています。最初の行などではadipiscingとincididuntといったように2つのinを含む単語がありますが、先頭のadipiscingの方が結果のカラム(extracted_word)に設定されていることが分かります。
SELECT REGEXP_EXTRACT(sentence, '(\s|^)\w*?in\w*?(\s|$)') AS extracted_word, sentence
FROM athena_workshop.lipsum
※(\s|^)などの指定が無くても必要なものを取れたり・・・もしますが、後述のグループ周りの制御のための説明などの目的で使っていきます。
Pythonでの書き方
Pandasではstr属性のextractメソッドで近いことが行えます。第一引数には正規表現のパターンを指定します。expand属性は返却値をデータフレームとして返却するかシリーズとして返却するかどうかの設定で、Trueと指定するとデータフレームで返却されるようになります。
古いバージョンではこのexpandのデフォルト値はFalseとなっていますが、新しいPandasのバージョンからはTrueになるという破壊的更新が入っているので、新旧両方のPandasで挙動を合わせる場合にはオプションの指定を明示した方が良いとのことです。
このextractメソッドではグループの指定(()の括弧)がパターン内で必須となります。グループの個数に応じて結果のデータフレームのカラムが0, 1, 2...と増えていきます。また、グループ以外の目的で使用している括弧に関しても結果のデータフレームに含まれてしまう(グループを無効化するパターンの指定をしても挙動が変わらない)ようです。
以下の例では最初の括弧のみ使い残りはOR条件用の括弧なのでnew_df[[0]]といったように先頭のみを表示しています。
import pandas as pd
df: pd.DataFrame = pd.read_json(
'https://github.com/simon-ritchie/athena_workshop/blob/main/workshop/lipsum/dt%3D2021-01-01/data.json.gz?raw=true',
lines=True, compression='gzip')
new_df = df['sentence'].str.extract(r'((\s|^)\w*?in\w*?(\s|$))', expand=True)
print(new_df[[0]])
0
0 adipiscing
1 minim
2 in
3 sint
特定のグループ部分の文字列を取得する
REGEXP_EXTRACT関数の第三引数に整数を指定することによってグループ(パターン内で()の括弧で囲んだ部分)の文字列を取得することができます。第三引数の整数は1からスタートし、1を指定したら最初のグループ、2を指定したら2つ目のグループ・・・となっていきます。
以下のSQLではinという文字列を含む単語中のinの前後の文字列部分をグループ設定して取得しています(例 : adipiscingであればinの前のadipiscがグループ1、inの後のgがグループ2となります)。
なお、OR条件の(|)部分でもグループが設定される・・・という挙動はPythonなどの他の言語環境と同じ挙動をするようです。それらをグループとしては無視する設定としての?:の指定も有効なようなので、今回のSQLではそちらも利用しています。この辺は以下の記事のものなどをご確認ください。
グループの括弧を使ったときに、グループの処理を無効化する
前のセクションで、()の括弧はOR条件など、グループで特定箇所の文字列を抽出する以外にも使われる点と、その際にグループの処理が実行されて処理負荷になりうるという点に触れました。
グループでの文字列抽出の処理が不要な時に、無効化してパフォーマンスを上げたい場合には(の直後に?:の記号を付与することで対応ができます。
Pythonでやさしくしっかり学ぶ正規表現
SELECT REGEXP_EXTRACT(sentence, '(?:\s|^)(\w*?)in(\w*?)(?:\s|$)', 1) AS group_1,
REGEXP_EXTRACT(sentence, '(?:\s|^)(\w*?)in(\w*?)(?:\s|$)', 2) AS group_2,
REGEXP_EXTRACT(sentence, '(\s|^)\w*?in\w*?(\s|$)') AS word,
sentence
FROM athena_workshop.lipsum

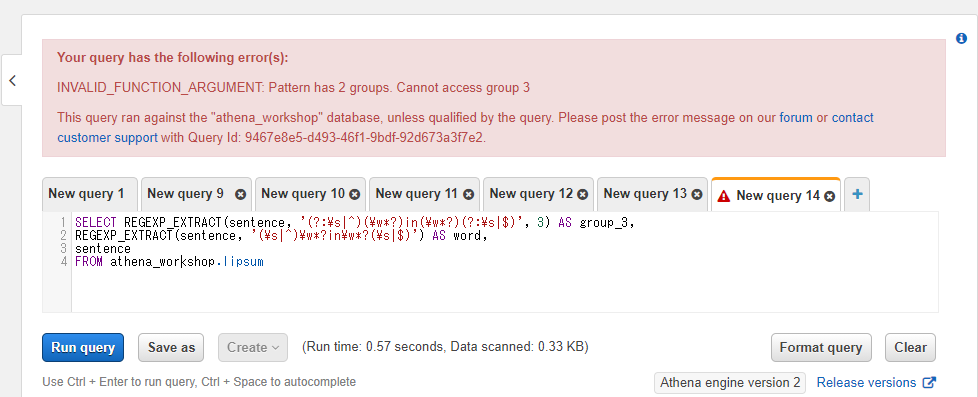
なお、パターン中に含まれるグループ数を超えたグループ番号を第三引数に指定するとエラーになります。以下のSQLでは2つのグループを含むパターンに対して3つ目のグループを指定しています。
SELECT REGEXP_EXTRACT(sentence, '(?:\s|^)(\w*?)in(\w*?)(?:\s|$)', 3) AS group_3,
REGEXP_EXTRACT(sentence, '(\s|^)\w*?in\w*?(\s|$)') AS word,
sentence
FROM athena_workshop.lipsum
Pythonでの書き方
前節までで触れたように、Pandasのstr属性のextractメソッドではグループの利用が必要になるため前節の内容そのままでグループ関係の制御は行えます。
パターンにマッチした文字列全ての配列を取得する: REGEXP_EXTRACT_ALL
REGEXP_EXTRACT_ALL関数はパターンにマッチしたものが全て抽出され、結果は配列になって返ってきます。他の使い方はREGEXP_EXTRACTと同じです。
SELECT REGEXP_EXTRACT_ALL(sentence, '(\s|^)\w*?in\w*?(\s|$)') AS word,
sentence
FROM athena_workshop.lipsum

Pythonでの書き方
str属性のfindallメソッドで対応ができます。返却値はリストを含んだシリーズとなります。
こちらもグループの指定が必要になります。パターン中にグループが複数あるとリストの値がタプルになったりしてしまって階層的に扱いづらくなるため注意が必要です。
import pandas as pd
df: pd.DataFrame = pd.read_json(
'https://github.com/simon-ritchie/athena_workshop/blob/main/workshop/lipsum/dt%3D2021-01-01/data.json.gz?raw=true',
lines=True, compression='gzip')
df['found_result'] = df['sentence'].str.findall(r'(\w*?in\w*?)')
print(df[['found_result', 'sentence']])
found_result sentence
0 [adipiscin, in] Lorem ipsum dolor sit amet, consectetur adipis...
1 [min] Ut enim ad minim veniam, quis nostrud exercita...
2 [in, in] Duis aute irure dolor in reprehenderit in volu...
3 [sin, in] Excepteur sint occaecat cupidatat non proident...
特定グループ部分の文字列の配列を取得する
REGEXP_EXTRACT_ALL関数も第三引数にグループ番号の整数を指定することでグループごとの値を配列で取得することができます。結果が配列になる以外はREGEXP_EXTRACTと同じ使い方です。
SELECT
REGEXP_EXTRACT_ALL(sentence, '(?:\s|^)\w*?in\w*?(?:\s|$)') AS words,
REGEXP_EXTRACT_ALL(sentence, '(?:\s|^)(\w*?)in(\w*?)(?:\s|$)', 1) AS group_1,
REGEXP_EXTRACT_ALL(sentence, '(?:\s|^)(\w*?)in(\w*?)(?:\s|$)', 2) AS group_2,
sentence
FROM athena_workshop.lipsum
特定のパターンを含んでいるかどうかの真偽値を取得する: REGEXP_LIKE
REGEXP_LIKE関数は他の関数と同様に特定の文字列パターンの検索を行いますが、結果は真偽値で返ってきます。指定したパターンがその行に存在すればtrue、存在しなければfalseとなります。第一引数に対象のカラムもしくは固定値、第二引数に正規表現のパターンを指定します。
以下はreで終わる単語が含まれている行かどうかを判定しています。
SELECT REGEXP_LIKE(sentence, '(\s|^)\w*?re(\s|$)') AS contains_re, sentence
FROM athena_workshop.lipsum

Pythonでの書き方
str属性のcontainsメソッドで正規表現が使えます。
import pandas as pd
df: pd.DataFrame = pd.read_json(
'https://github.com/simon-ritchie/athena_workshop/blob/main/workshop/lipsum/dt%3D2021-01-01/data.json.gz?raw=true',
lines=True, compression='gzip')
df['contains'] = df['sentence'].str.contains(r'(\s|^)\w*?re(\s|$)')
print(df[['contains', 'sentence']])
contains sentence
0 True Lorem ipsum dolor sit amet, consectetur adipis...
1 False Ut enim ad minim veniam, quis nostrud exercita...
2 True Duis aute irure dolor in reprehenderit in volu...
3 False Excepteur sint occaecat cupidatat non proident...
特定のパターンの文字列を別の文字に置き換える: REGEXP_REPLACE
REGEXP_REPLACE関数は指定したパターンに該当する部分を別の文字列で置換します。
第一引数に対象のカラム名もしくは固定値、第二引数に正規表現のパターン、第三引数に置換で使用する文字列を指定します。第三引数は省略可能で、省略した場合にはパターンに該当する箇所が削除(空文字で置換)されます。
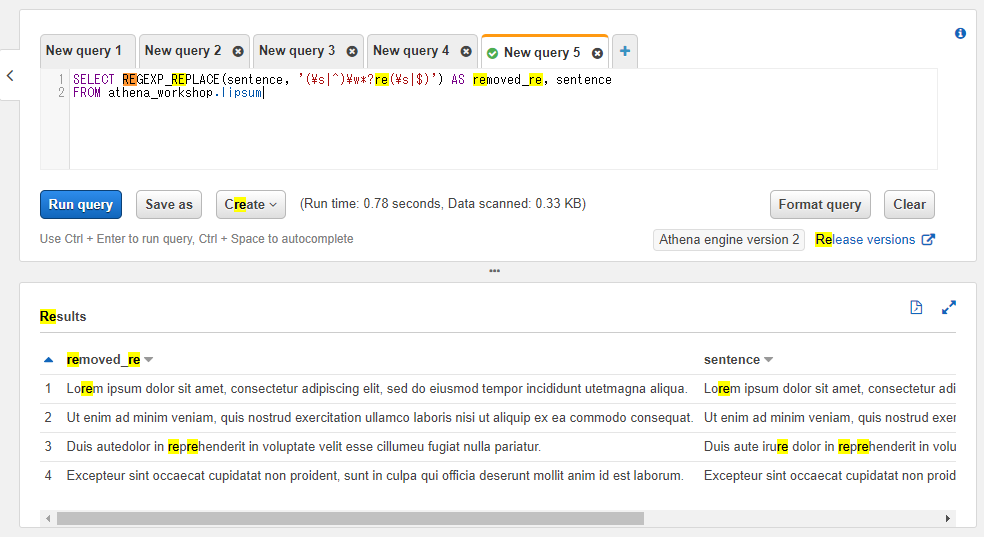
以下のSQLではパターンで各単語の末尾にreを含む単語を対象として、第三引数を省略しているので該当パターンの削除処理となっています。
SELECT REGEXP_REPLACE(sentence, '(\s|^)\w*?re(\s|$)') AS removed_re, sentence
FROM athena_workshop.lipsum
以下では第三引数も指定しているので別の文字列に置換がされています。該当のパターンの単語をre_suffix_wordという文字列で置換しています。
SELECT REGEXP_REPLACE(sentence, '(\s|^)\w*?re(\s|$)', ' re_suffix_word ') AS replaced, sentence
FROM athena_workshop.lipsum

また、パターン内の特定部分はグループの後方参照として置換用に指定した文字列部分でも参照することができます。パターン内の()の括弧で囲んだ部分がグループとして判定され、置換用の文字列側では最初のグループを$1、次のグループを$2...と指定していくことで該当の部分を利用することができます。
以下のSQLではグループを3つ使っており、それぞれのグループが以下のようになっています。
- グループ1(
$1): 行の先頭もしくは空白文字 - グループ2(
$2): 単語の末尾のreの前までの文字列部分 - グルー目3(
$3): 行の末尾もしくは空白文字
$1$2er$3という置換文字を指定しているので、つまり単語の末尾のre部分をerに置換する・・・といった処理になっています。
SELECT REGEXP_REPLACE(sentence, '(\s|^)(\w*?)re(\s|$)', '$1$2er$3') AS replaced, sentence
FROM athena_workshop.lipsum
実行してみると、例えば3行目のirureという文字列がiruerと置換されていることを確認できます。

Pythonでの書き方
str属性のreplaceメソッドでregex引数にTrueを指定すると正規表現で置換が行えます。
import pandas as pd
df: pd.DataFrame = pd.read_json(
'https://github.com/simon-ritchie/athena_workshop/blob/main/workshop/lipsum/dt%3D2021-01-01/data.json.gz?raw=true',
lines=True, compression='gzip')
df['replaced'] = df['sentence'].str.replace(
pat=r'(\s|^)\w*?re(\s|$)', repl=' re_suffix_word ', regex=True)
print(df[['replaced', 'sentence']])
replaced sentence
0 Lorem ipsum dolor sit amet, consectetur adipis... Lorem ipsum dolor sit amet, consectetur adipis...
1 Ut enim ad minim veniam, quis nostrud exercita... Ut enim ad minim veniam, quis nostrud exercita...
2 Duis aute re_suffix_word dolor in reprehenderi... Duis aute irure dolor in reprehenderit in volu...
3 Excepteur sint occaecat cupidatat non proident... Excepteur sint occaecat cupidatat non proident...
特定のパターンで文字列を分割し配列を得る: REGEXP_SPLIT
REGEXP_SPLIT関数は該当のパターンにマッチする部分で文字列を分割し、結果を配列で返却します。第一引数には対象のカラムもしくは固定値、第二引数には区切り文字となる正規表現のパターンを指定します。
以下のSQLではスペースなどの空白文字(\s)もしくは空白文字とコンマ(\s,)で分割を実施しています。
SELECT REGEXP_SPLIT(sentence, '(\s,|\s)') AS splitted, sentence
FROM athena_workshop.lipsum

参考文献・参考サイトまとめ
- The Applied SQL Data Analytics Workshop: Develop your practical skills and prepare to become a professional data analyst, 2nd Edition
- String Functions and Operators
- 吾輩は猫である
- lorem ipsum - Wikipedia
- 「uppercase」と「lowercase」の由来
- pandas.Series.str.len
- pandas.Series.str.pad
- pandasの文字列メソッドで置換や空白削除などの処理を行う
- How to get the numbers from query in presto?
- pandas.Series.str.index
- REVERSE THE STRING OF COLUMN IN PANDAS PYTHON
- ハミング距離 - Wikipedia
- Pythonic python 1: Hamming distance
- レーベンシュタイン距離 - Wikipedia
- 編集距離 (Levenshtein Distance)をpython で求める
- 正規表現でフラグを有効にする
- Regular Expression Functions
- 正規表現パターンにおけるエスケープ処理
- pandasの文字列から正規表現で抽出して新たな列を生成