概要
- Pythonで体験するベイズ推論 PyMCによるMCMC入門の書籍を結構前に読了しましたが、しばらくPyMCを触っていないので、復習用に自習課題として動かします。
- どんな書籍なのか、というのはここでは触れないので、『Pythonで体験するベイズ推論 ―PyMCによるMCMC入門―』の書評などをご確認ください。(書籍自体はとても分かりやすかった・・)
- ちなみに統計・確率・数学・ベイズ周りは初心者(理系出身でもない)なため、理解が浅い点はご了承ください。
誰のための記事?
- 書籍の原書が元々for Hackers とあるように、書籍もエンジニア・もしくは最近PyMCを触り始めた方など向けで、この記事でもほとんど数式などは扱いません。
- がっつりデータサイエンスを仕事にしている方達からすると、大分物足りない記事だとは思います。
- 機械学習(特にディープラーニング)を先に学んでから、それを踏まえて比較などしつつ記事を書いています。「ゼロから作る Deep Learning」など消化済みの方だと、より読みやすいかもしれません。
課題内容
- 書籍で例題として、upvote / downvote(いいね的な、親指マークなど)のソート問題がありました。
- また、そちらの例題での内容は、レビュー(Amazon的な)のソートとしても使えると書かれており、数式などが軽く触れられていましたが、実際にPyMCを動かして、といったところまでは書かれていなかったので、課題としてこのレビューのソート問題を扱います。
実現したいこと
- レビューが絡む要素(商品だったり、映画だったり、etc)のおすすめ順的なもののためのソートを実現する。
前提
- ☆1~☆5までの範囲で、ユーザーが商品に対してレビューを投稿できるようなサービス。
普通にソートすることによる問題
単純に、評価の高い順でソートすると、以下のような問題が出てくる。
- ☆5.0、レビュー数1・2件程度の商品が先頭に出てくる。
- 本当はユーザーからすると、☆4.8とかのレビューが50件程度ある要素にアクセスしたいと思われるため、できればそういった「本当に評価が高いと思われる」要素が先頭になるようにソートをしたい。
- 直観的にも、☆5.0でレビューが1件しかない要素よりも、☆4.8でレビューが50件程度ある要素のほうが魅力的に感じる(Amazonの商品選択時などでも、そういった商品を自然と選んでいる)。
解決方法
- PyMCを使います。(ほかに色々やり方はあると思いますが、PyMCの復習目的のため)
- 書籍と同様に、MCMCでの処理後、レビュー内容的に「良い商品である可能性が高い」という商品が先頭に来るようにします。
- 結果としてレビュー平均値が高く、且つレビュー数が多い(=平均値が真の値である確率が高い)商品が優遇されるようになります。
- レビュー数が多い方が確率が高くなる、というのはサイコロを多く振った方が各面が出る確率が真の値に近づいていくことをイメージすると分かりやすい・・かもしれません。
- ソート自体はスカラー値で扱う必要があります。ここでは、書籍と同様、95%信用下限(後で触れます)を使います。
この課題で扱わないこと
- 計算をより短時間で終わらす(webサービスなどで大量にリクエストをさばくケースなどための)ための近似対応などは、書籍では扱われていたものの色々数式の話など必要になるのでここでは省略します。
- 古い商品の方が、レビュー数が多くなりやすく有利になる、という点も書籍で触れられていましたが、この記事では話をシンプルにするために触れません。
ダミーデータの準備
課題で使うための、ダミーデータを乱数などで用意します。
- 200件の商品データを想定。
- ID、レビュー数、レビュー比率(1.0~5.0)のカラムのデータフレームで扱います。
import pandas as pd
import numpy as np
import seaborn as sns
sns.set_style(style='darkgrid')
product_df = pd.DataFrame(
columns=['id', 'review_num', 'review_rate'],
index=np.arange(0, 200))
product_df.id = product_df.index + 1
review_num_arr = np.random.lognormal(
mean=2, size=(200,)) + 1
product_df.review_num = review_num_arr
product_df.review_num = product_df.review_num.astype(np.int, copy=False)
product_df.review_rate = np.random.uniform(
low=1.0, high=5.0, size=(200,))
product_df[:10]
| id | review_num | review_rate | |
|---|---|---|---|
| 0 | 1 | 29 | 1.171052 |
| 1 | 2 | 8 | 4.512538 |
| 2 | 3 | 12 | 4.310933 |
| 3 | 4 | 17 | 1.410750 |
| 4 | 5 | 37 | 3.264369 |
| 5 | 6 | 3 | 4.899745 |
| 6 | 7 | 7 | 2.256719 |
| 7 | 8 | 1 | 2.349467 |
| 8 | 9 | 1 | 4.490342 |
| 9 | 10 | 5 | 1.742555 |
product_df[190:200]
| id | review_num | review_rate | |
|---|---|---|---|
| 190 | 191 | 14 | 2.171503 |
| 191 | 192 | 5 | 4.223269 |
| 192 | 193 | 29 | 1.224605 |
| 193 | 194 | 3 | 2.388260 |
| 194 | 195 | 29 | 2.887370 |
| 195 | 196 | 4 | 4.222529 |
| 196 | 197 | 3 | 2.737241 |
| 197 | 198 | 16 | 2.229572 |
| 198 | 199 | 22 | 1.797979 |
| 199 | 200 | 5 | 4.863885 |
レビュー数に関しては、少ない商品の方が多いだろう・・ということで以下にようになっています。
product_df.plot(
x='review_rate', y='review_num', kind='hist', bins=15)
<matplotlib.axes._subplots.AxesSubplot at 0x7f77a20334a8>
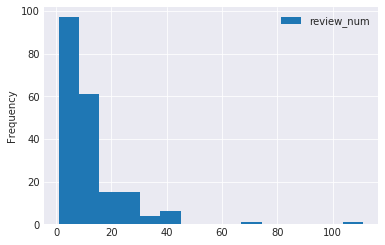
product_df.review_num.min()
1
product_df.review_num.max()
111
# 生成したデータを保存。
product_df.to_csv(
'./20180331_ベイズ推論_レビューソート問題_ダミーデータ.csv',
index=False, encoding='utf-8')
# 作業再開用。以前保存したデータを読み込む。
product_df = pd.read_csv('./20180331_ベイズ推論_レビューソート問題_ダミーデータ.csv')
PyMCでモデルを組む
モデル自体はそこまで複雑にならないものの、説明を結構飛ばすため、分かりづらい点などはご了承ください。(詳しくは書籍を・・)
ステップ概要
PyMCを扱う上で、いくつかのステップがあります。
確率変数や事前分布などをどうするのか決める。
どのような変数が必要になるのかを決定します。
ディープラーニングでいうところの入力値(画像認識であれば画像のテンソルなど)的なところになります。
今回は、レビュー数とレビューの平均値が変数となります。
また、事前分布と事後分布という単語が出てきます。事前分布は単純に一様分布を扱うこともあれば、信念(きっと結果は〇〇以下にはならない筈だ、専門家は大体××と考えている)に基づいて初期分布が与えることもできます。(もしくは、別のベイズモデルの結果の分布を与えたりすることもあるようです。(なんとなくStackGANっぽい))
一様分布のほうが客観的な処理となるのに比べ、事前分布になんらかの信念を与えたほうが真の値に近づくこともあります。逆に信念を与えることによって、結果にバイアスがかかり真の値からずれることもある、と言われています。どうすのかはケースバイケースで選択する必要がある、といったようなことが書籍では書かれています。
ディープラーニングでの敵対的生成モデル(GANs)などでいうと、一様分布を与えるのが普通のGANsモデルで、何らかの画像を生み出したりするのに対し、信念を与えるのは条件付き生成モデル(cGAN)とかに近く、たとえば線画を与えて、その線画に収まる形でコントロールされた状態で着色をしたり、といったものに近いかなあ・・と感じています。
今回は、レビュー評価に対して、一様分布を用いて進めます。
Youtubeだったりの単純なプラス評価とマイナス評価であれば二項分布(Binomialクラス)を与えますが、今回はレビュー評価が1.0~5.0の範囲の、連続型確率変数となります。
分かりやすいように、以下のように各レビューの値を0.0~1.0の範囲になるように定義します。
レビュー評価_{1.0} = 0\\
レビュー評価_{2.0} = 0.25\\
レビュー評価_{3.0} = 0.5\\
レビュー評価_{4.0} = 0.75\\
レビュー評価_{5.0} = 1
0~1の範囲の連続型確率変数ということで、ベータ分布(Betaクラス)を使います。
このあたりの分布の話は、書籍だったり、PyMCの初歩の記事で詳しく書かれています。一部、上記記事から引用させていただきます。
$\theta$は0から1までの連続値であり、特に事前の情報を持たないので、 0から1までのすべてが等確率(密度)となる事前分布を使う。 これは具体的にはパラメタ$\alpha$と$\beta$がそれぞれ1のベータ分布である。
http://wcs.hatenablog.com/entry/2017/05/28/222658
上記のような条件で、商品1件分の事後分布を取得するスクリプトを考えてみます。(PyMCの基礎 の記事も参考にします)
このステップは、ディープラーニングでいうところの、学習中のステップに近いと言えます。
MCMC(マルコフ連鎖モンテカルロ法)の記述が出てきます。1ステップごとに前の結果を踏まえて次の探索を行う、といった処理になります。ディープラーニングで、前の結果を踏まえて、次のエポックの学習に移るのに似ています。
なお、その探索の移り変わりは、軌跡(trace)と呼ばれます。
モデルを組む
import pymc as pm
def get_posterior_review_rate_trace(review_rate, review_num):
"""
レビュー評価の事後分布の軌跡を取得する。
Parameters
------------
review_rate : float
対象の商品の1.0 ~ 5.0の範囲のレビュー評価値。
review_num : int
対象の商品のレビュー数。
Returns
---------
trace : Trace
レビュー評価の事後分布。
"""
# 前述のとおり、レビューの評価は0~1の範囲の一様分布で扱うため、
# 引数で与えられた値に対して調整を加えます。
# name は確率変数名。軌跡にアクセスする際などに使うため、
# 分かりやすい任意の文字列を指定します。
_review_rate = pm.Uniform(name='review_rate', lower=0, upper=1)
review_rate_0_to_1 = (review_rate - 1) * 0.25
print('0~1の範囲でのレビュー評価 : ', review_rate_0_to_1)
# 前述のとおり、連続確率変数のためBeta分布を使用します。
theta = pm.Beta(name='theta', alpha=1, beta=1)
# observations は事前の観測値だったり信念を加味した事前分布の値
# (用意した確率変数など)を設定します。
# n は回数となり、コインを投げた回数などをイメージすると分かりやすいき
# かもしれません。この数が多いほど、結果の確信度が高まります。
# 今回はレビュー数が該当します。
# value は、コインを投げて何回表が出たのか、といった値になるため、
# レビュー評価にレビュー数を乗算した値を指定しています。
# observed は、既に事前に観測済みの値で、固定値ですよ、ということを
# PyMCに指定している。今回、事前にレビュー評価などは分かっている(=固定値
# なため、Trueを指定。
observations = pm.Binomial(
name='obs', n=review_num, p=theta,
value=review_rate_0_to_1 * review_num,
observed=True)
# MAP(maximum a posterior)を使うという指定。
# 収束に絡んだもので、基本的には使うと結果が良くなる
# そうです。ここでは詳細な説明は省略。
map_ = pm.MAP([theta, observations]).fit()
# このあたりは、Kerasでモデルを組む時の感覚に似ている。
model = pm.Model([theta, observations])
mcmc = pm.MCMC(model)
# MCMCの探索を行う。第一引数はサンプリング数(探索回数)。
# ディープラーニングのエポックに近い。(1回辺りはすぐ終わるので、
# ディープラーニングのエポックよりは数が多くなる)
# 第二引数はバーンインと呼ばれ、ごの件数分はサンプリング結果が破棄
# される。今回は5000件目~20000件目のサンプリング結果が取得される。
# ディープラーニングで最初の方のエポックは安定感がない(精度の低い
# 結果になる)のと同様、MCMCでも最初の方は収束しておらず好ましく
# ない値になるので、一定数破棄する。
mcmc.sample(20000, 5000)
# 探索結果のthetaの確率変数の軌跡を取得する。
trace = mcmc.trace('theta')
return trace
モデルの確認
組んだモデルが妥当かとうか、値を直接指定してみて結果を確認してみます。
事後分布がどんな感じになったのかの確認として、さくっと確認するためのPyMCのmatplotlibのラッパー的なモジュールが用意されているのでそちらを利用します。
matplotlibのpltと名称が被らないように、mcplotという名前で扱います。
取得した軌跡を引数に渡すだけで、事後分布がどのように分布になっているのかや95%信用区間を表示してくれます。
from pymc.Matplot import plot as mcplot
レビュー評価は4.5でそれぞれ実施。
レビューが少ないケース
trace_of_review_num_2 = get_posterior_review_rate_trace(
review_rate=4.5, review_num=2)
0~1の範囲でのレビュー評価 : 0.875
[-----------------100%-----------------] 20000 of 20000 complete in 1.5 sec
mcplot(trace_of_review_num_2)
Plotting theta
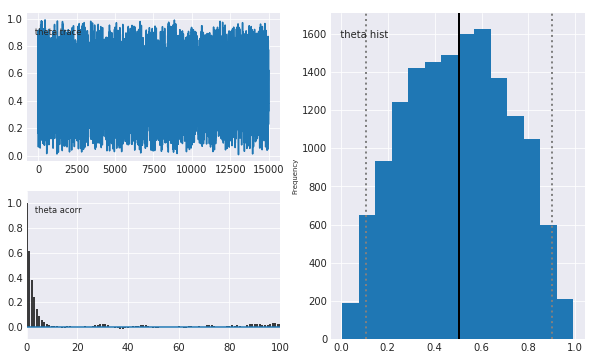
右側が事後分布となります。
レビュー件数が裾野の広い事後分布となりました。件数が少ないので、値の正確度が低い(=結構ばらつく)という結果になっています。また、真の値とも大分差が開いていることがわかります。
レビューが多いケース
trace_of_review_num_50 = get_posterior_review_rate_trace(review_rate=4.5, review_num=50)
0~1の範囲でのレビュー評価 : 0.875
[-----------------100%-----------------] 20000 of 20000 complete in 1.6 sec
mcplot(trace_of_review_num_50)
Plotting theta
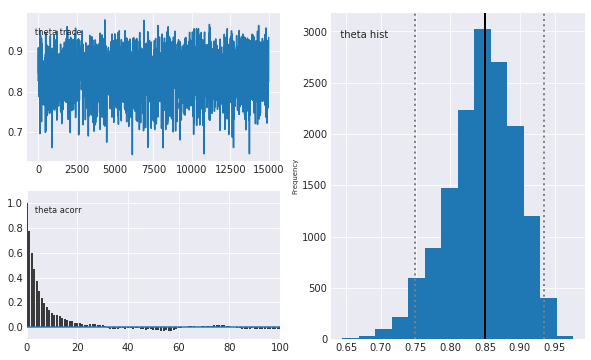
先ほどのレビュー件数が少ない結果と比べて、大分裾野が狭くなりました。また、真の値が0.85(右のプロットの濃い縦線)辺りにあり、レビュー4.5の変換後の値0.875に近い値となっています。
レビュー件数が増えたことで、「この商品はそれなりに高い確率で0.85付近の評価が妥当そうだ」とか、95%信用区間(右のプロットの薄い縦の点線)的に「ほぼほぼの確率で0.75~0.93辺りのレビュー評価だろう」といったことが判断できます。
この95%信用下限(左側の縦の点線)の値を使い、ソートを行います。レビュー数が多いほど裾野が狭くなり、95%信用下限が高い値になる(=ソートで有利に判定される)結果となります。
全商品の95%信用下限値の算出
組んだモデルを反映していきます。
def get_lower_limit(trace):
"""
対象の軌跡の95%信用下限を取得する。
Parameters
------------
trace : Trace
対象の商品のMCMCの軌跡。
Returns
--------
lower_limit : float
対象の軌跡の95%信用下限値。
"""
trace_arr = trace[:]
N = trace_arr.shape[0]
lower_limit = np.sort(trace_arr)[int(0.05 * N)]
return lower_limit
product_df['lower_limit'] = 0
from datetime import datetime
# 長時間かかります。
for index, sr in product_df.iterrows():
print('\n', index + 1, '件目以降を実行中', datetime.now())
review_rate = sr['review_rate']
review_num = sr['review_num']
trace = get_posterior_review_rate_trace(
review_rate=review_rate, review_num=review_num)
lower_limit = get_lower_limit(trace=trace)
product_df.loc[index, 'lower_limit'] = lower_limit
product_df[:5]
| id | review_num | review_rate | lower_limit | |
|---|---|---|---|---|
| 0 | 1 | 29 | 1.171052 | 0.013478 |
| 1 | 2 | 8 | 4.512538 | 0.574099 |
| 2 | 3 | 12 | 4.310933 | 0.495006 |
| 3 | 4 | 17 | 1.410750 | 0.019257 |
| 4 | 5 | 37 | 3.264369 | 0.403900 |
ソート
各商品の95%信用下限が算出できたので、あとはソートして終了です。
product_df.sort_values(by='lower_limit', ascending=False, inplace=True)
def round_lower_limit(lower_limit):
"""
95%信用下限の値が、桁数が多く見づらいので、浮動小数点の3桁で切り落とし
(四捨五入)を行う。
Parameters
-------------
lower_limit : float
切り落とし対象の信用下限値。
Returns
---------
lower_limit : float
切り落とし後の値。
"""
return round(lower_limit, 3)
product_df.lower_limit = product_df.lower_limit.apply(round_lower_limit)
product_df[:50]
| id | review_num | review_rate | lower_limit | |
|---|---|---|---|---|
| 159 | 160 | 19 | 4.867595 | 0.776 |
| 125 | 126 | 44 | 4.373100 | 0.728 |
| 24 | 25 | 14 | 4.739080 | 0.709 |
| 55 | 56 | 12 | 4.856710 | 0.695 |
| 174 | 175 | 17 | 4.561806 | 0.689 |
| 102 | 103 | 12 | 4.693846 | 0.685 |
| 77 | 78 | 11 | 4.887662 | 0.664 |
| 42 | 43 | 11 | 4.888299 | 0.658 |
| 175 | 176 | 10 | 4.824883 | 0.644 |
| 126 | 127 | 18 | 4.467957 | 0.641 |
| 166 | 167 | 42 | 4.123655 | 0.639 |
| 26 | 27 | 31 | 4.060111 | 0.599 |
| 1 | 2 | 8 | 4.512538 | 0.574 |
| 153 | 154 | 8 | 4.977846 | 0.569 |
| 169 | 170 | 14 | 4.197506 | 0.566 |
| 79 | 80 | 14 | 4.170081 | 0.561 |
| 118 | 119 | 11 | 4.498642 | 0.553 |
| 144 | 145 | 14 | 4.263963 | 0.545 |
| 158 | 159 | 35 | 3.790759 | 0.544 |
| 168 | 169 | 16 | 4.218747 | 0.527 |
| 110 | 111 | 7 | 4.540376 | 0.520 |
| 187 | 188 | 15 | 4.170675 | 0.511 |
| 122 | 123 | 9 | 4.511826 | 0.498 |
| 2 | 3 | 12 | 4.310933 | 0.495 |
| 184 | 185 | 6 | 4.833444 | 0.486 |
| 124 | 125 | 6 | 4.481689 | 0.478 |
| 78 | 79 | 6 | 4.352680 | 0.473 |
| 150 | 151 | 6 | 4.937529 | 0.469 |
| 73 | 74 | 8 | 4.124395 | 0.462 |
| 63 | 64 | 15 | 3.713055 | 0.455 |
| 84 | 85 | 8 | 4.038797 | 0.451 |
| 89 | 90 | 21 | 3.575696 | 0.449 |
| 131 | 132 | 12 | 3.883360 | 0.430 |
| 148 | 149 | 14 | 3.847961 | 0.425 |
| 199 | 200 | 5 | 4.863885 | 0.424 |
| 191 | 192 | 5 | 4.223269 | 0.422 |
| 173 | 174 | 12 | 3.862418 | 0.418 |
| 134 | 135 | 5 | 4.349610 | 0.418 |
| 104 | 105 | 16 | 3.613496 | 0.417 |
| 141 | 142 | 7 | 4.014073 | 0.414 |
| 186 | 187 | 7 | 4.356096 | 0.413 |
| 29 | 30 | 7 | 4.265361 | 0.411 |
| 94 | 95 | 11 | 3.728870 | 0.411 |
| 17 | 18 | 13 | 3.705521 | 0.404 |
| 39 | 40 | 9 | 3.876715 | 0.404 |
| 4 | 5 | 37 | 3.264369 | 0.404 |
| 67 | 68 | 11 | 3.752770 | 0.397 |
| 52 | 53 | 9 | 3.861583 | 0.395 |
| 40 | 41 | 11 | 3.850809 | 0.395 |
| 93 | 94 | 111 | 2.846798 | 0.384 |
ある程度ランダムな分布に依存するため、ID2と154と行など少し気になるものの、大まかには課題としたソート結果を得ることができました。
Appendix
環境
ノート環境
- Azure Notebooks
Python 環境
!python -V
Python 3.5.4 :: Anaconda custom (64-bit)
※PyMCのインポートでエラーになり、解決策で必要そうなapt-get関係のコマンドがAzure Notebooks関係で探すのが手間だったため、Python3.6ではなく3.5をカーネルに選択。
ライブラリ環境
Azure Notebooksのデフォルトのライブラリそのままです。
!pip freeze
adal==0.5.0
alabaster==0.7.10
altair==1.2.1
anaconda-client==1.6.5
anaconda-navigator==1.6.9
anaconda-project==0.8.0
applicationinsights==0.11.1
argcomplete==1.9.4
arrow==0.12.1
asn1crypto==0.22.0
astroid==1.5.3
astropy==2.0.2
attrs==17.4.0
Automat==0.6.0
azure-batch==4.0.0
azure-batch-extensions==1.0.1
azure-cli==2.0.28
azure-cli-acr==2.0.21
azure-cli-acs==2.0.27
azure-cli-advisor==0.1.2
azure-cli-appservice==0.1.28
azure-cli-backup==1.0.6
azure-cli-batch==3.1.10
azure-cli-batchai==0.1.5
azure-cli-billing==0.1.7
azure-cli-cdn==0.0.13
azure-cli-cloud==2.0.12
azure-cli-cognitiveservices==0.1.11
azure-cli-command-modules-nspkg==2.0.1
azure-cli-configure==2.0.14
azure-cli-consumption==0.2.2
azure-cli-container==0.1.19
azure-cli-core==2.0.28
azure-cli-cosmosdb==0.1.19
azure-cli-dla==0.0.18
azure-cli-dls==0.0.19
azure-cli-eventgrid==0.1.10
azure-cli-extension==0.0.9
azure-cli-feedback==2.1.0
azure-cli-find==0.2.8
azure-cli-interactive==0.3.16
azure-cli-iot==0.1.17
azure-cli-keyvault==2.0.19
azure-cli-lab==0.0.17
azure-cli-monitor==0.1.2
azure-cli-network==2.0.24
azure-cli-nspkg==3.0.1
azure-cli-profile==2.0.19
azure-cli-rdbms==0.0.12
azure-cli-redis==0.2.11
azure-cli-reservations==0.1.1
azure-cli-resource==2.0.24
azure-cli-role==2.0.20
azure-cli-servicefabric==0.0.10
azure-cli-sql==2.0.22
azure-cli-storage==2.0.26
azure-cli-vm==2.0.27
azure-common==1.1.8
azure-datalake-store==0.0.17
azure-graphrbac==0.31.0
azure-keyvault==0.3.7
azure-mgmt-advisor==0.1.0
azure-mgmt-authorization==0.30.0
azure-mgmt-batch==4.1.0
azure-mgmt-batchai==0.2.0
azure-mgmt-billing==0.1.0
azure-mgmt-cdn==1.0.0
azure-mgmt-cognitiveservices==1.0.0
azure-mgmt-compute==3.1.0rc3
azure-mgmt-consumption==2.0.0
azure-mgmt-containerinstance==0.3.1
azure-mgmt-containerregistry==1.0.1
azure-mgmt-containerservice==3.0.1
azure-mgmt-cosmosdb==0.3.1
azure-mgmt-datalake-analytics==0.2.0
azure-mgmt-datalake-nspkg==2.0.0
azure-mgmt-datalake-store==0.2.0
azure-mgmt-devtestlabs==2.0.0
azure-mgmt-dns==1.2.0
azure-mgmt-eventgrid==0.4.0
azure-mgmt-iothub==0.4.0
azure-mgmt-iothubprovisioningservices==0.1.0
azure-mgmt-keyvault==0.40.0
azure-mgmt-marketplaceordering==0.1.0
azure-mgmt-monitor==0.4.0
azure-mgmt-msi==0.1.0
azure-mgmt-network==1.7.0
azure-mgmt-nspkg==2.0.0
azure-mgmt-rdbms==0.1.0
azure-mgmt-recoveryservices==0.1.0
azure-mgmt-recoveryservicesbackup==0.1.1
azure-mgmt-redis==4.1.0
azure-mgmt-reservations==0.1.0
azure-mgmt-resource==1.2.1
azure-mgmt-servicefabric==0.1.0
azure-mgmt-sql==0.8.5
azure-mgmt-storage==1.5.0
azure-mgmt-trafficmanager==0.40.0
azure-mgmt-web==0.35.0
azure-multiapi-storage==0.2.0
azure-nspkg==2.0.0
azure-storage==0.34.3
azureml==0.2.7
Babel==2.5.0
backports.functools-lru-cache==1.4
backports.shutil-get-terminal-size==1.0.0
bcrypt==3.1.4
beautifier==0.3.3
beautifulsoup4==4.6.0
bitarray==0.8.1
bkcharts==0.2
blaze==0.11.3
bleach==2.0.0
bokeh==0.12.7
boto==2.48.0
boto3==1.4.8
botocore==1.8.50
Bottleneck==1.2.1
bqplot==0.10.5
brewer2mpl==1.4.1
CacheControl==0.12.3
certifi==2017.7.27.1
cffi==1.10.0
chardet==3.0.4
click==6.7
cloudpickle==0.4.0
clyent==1.2.2
cntk==2.0
colorama==0.3.9
conda==4.4.11
conda-build==3.0.27
conda-verify==2.0.0
constantly==15.1.0
contextlib2==0.5.5
cryptography==2.0.3
cycler==0.10.0
Cython==0.26.1
cytoolz==0.8.2
dask==0.15.3
datacleaner==0.1.5
datashape==0.5.4
decorator==4.1.2
distributed==1.19.1
docker-py==1.10.6
docker-pycreds==0.2.2
docutils==0.14
Dora==0.0.2
edward==1.3.5
elasticsearch==6.1.1
entrypoints==0.2.3
et-xmlfile==1.0.1
fastcache==1.0.2
feedparser==5.2.1
filelock==2.0.12
Flask==0.12.2
Flask-Cors==3.0.3
ftfy==5.3.0
future==0.16.0
GDAL==2.2.2
gevent==1.2.2
ggplot==0.11.5
glob2==0.5
gmpy2==2.0.8
graphviz==0.8.2
greenlet==0.4.12
grpcio==1.10.0
gym==0.10.3
h5py==2.7.1
heapdict==1.0.0
holoviews==1.8.3
html5lib==0.999999999
humanfriendly==4.8
hyperlink==18.0.0
idna==2.6
imageio==2.2.0
imagesize==0.7.1
incremental==17.5.0
ipaddress==1.0.19
ipykernel==4.7.0
ipython==6.2.1
ipython-genutils==0.2.0
ipywidgets==7.0.0b7
isodate==0.6.0
isort==4.2.15
itsdangerous==0.24
jdcal==1.3
jedi==0.10.2
Jinja2==2.9.6
jmespath==0.9.3
joblib==0.11
jsonschema==2.6.0
jupyter-client==5.1.0
jupyter-console==5.2.0
jupyter-core==4.4.0
jupyterlab==0.27.0
jupyterlab-launcher==0.4.0
kafka-python==1.4.1
kazoo==2.4.0
Keras==2.1.4
keyring==11.0.0
klein==17.10.0
knack==0.3.1
lazy-object-proxy==1.3.1
line-profiler==2.1.2
llvmlite==0.20.0
locket==0.2.0
lockfile==0.12.2
luigi==2.7.2
lxml==4.1.0
MarkupSafe==1.0
matplotlib==2.1.1
mccabe==0.6.1
memory-profiler==0.52.0
mistune==0.7.4
mock==2.0.0
mpmath==0.19
msgpack-python==0.4.8
msrest==0.4.27
msrestazure==0.4.22
multipledispatch==0.4.9
natsort==5.1.0
navigator-updater==0.1.0
nbconvert==5.3.1
nbformat==4.4.0
networkx==1.11
nltk==3.2.4
nose==1.3.7
notebook==5.0.0
numba==0.35.0
numexpr==2.6.2
numpy==1.12.1
numpydoc==0.7.0
oauthlib==2.0.6
odo==0.5.1
olefile==0.44
openfst==1.6.1
openpyxl==2.4.8
packaging==16.8
pandas==0.20.3
pandasql==0.7.3
pandocfilters==1.4.2
param==1.5.1
paramiko==2.4.0
partd==0.3.8
path.py==10.3.1
pathlib2==2.3.0
patsy==0.4.1
pbr==3.1.1
pep8==1.7.0
pexpect==4.2.1
phonenumbers==8.9.1
pickleshare==0.7.4
Pillow==4.3.0
pkginfo==1.4.1
plotly==2.4.1
ply==3.10
prettypandas==0.0.3
prompt-toolkit==1.0.15
protobuf==3.4.1
psutil==5.4.0
psycopg2==2.7.1
ptyprocess==0.5.2
py==1.4.34
pyang==1.7.4
pyasn1==0.4.2
pyasn1-modules==0.2.1
pycodestyle==2.3.1
pycosat==0.6.3
pycparser==2.18
pycrypto==2.6.1
pycurl==7.43.0
pydocumentdb==2.3.1
pydot==1.2.4
pyflakes==1.6.0
PyGithub==1.37
pyglet==1.3.1
Pygments==2.2.0
PyJWT==1.6.0
pykafka==2.7.0
pylint==1.7.4
pymc==2.3.6
pymc3==3.3
pymongo==3.4.0
Pympler==0.5
pymssql==2.1.1
PyMySQL==0.7.9
PyNaCl==1.2.1
pyodbc==3.1.1
pyOpenSSL==17.2.0
pypachy==0.1.5
pyparsing==2.2.0
pyprof2calltree==1.4.3
PySocks==1.6.7
pytest==3.2.1
python-daemon==2.1.2
python-dateutil==2.6.1
pytz==2017.2
PyWavelets==0.5.2
PyYAML==3.12
pyzmq==16.0.2
QtAwesome==0.4.4
qtconsole==4.3.1
QtPy==1.3.1
readline==6.2.4.1
requests==2.18.4
requests-oauthlib==0.8.0
rope==0.10.5
rpy2==2.9.2
ruamel-yaml==0.11.14
s3transfer==0.1.13
scikit-bio==0.5.1
scikit-image==0.13.0
scikit-learn==0.19.1
scipy==0.19.1
scp==0.10.2
scrubadub==1.2.0
seaborn==0.8
SecretStorage==2.3.1
service-identity==17.0.0
simplegeneric==0.8.1
singledispatch==3.4.0.3
six==1.11.0
sklearn==0.0
snakeviz==0.4.2
snowballstemmer==1.2.1
sortedcollections==0.5.3
sortedcontainers==1.5.7
Sphinx==1.6.3
sphinxcontrib-websupport==1.0.1
spyder==3.2.4
SQLAlchemy==1.1.13
sshtunnel==0.1.3
statsmodels==0.8.0
sympy==1.1.1
tables==3.4.2
tabulate==0.7.7
tblib==1.3.2
tensorflow==1.1.0
terminado==0.6
testpath==0.3.1
textblob==0.10.0
Theano==1.0.1
toolz==0.8.2
torch==0.3.1.post2
torchvision==0.1.9
tornado==4.5.2
tqdm==4.19.6
traitlets==4.3.2
traittypes==0.0.6
treq==17.8.0
Twisted==17.9.0
typing==3.6.2
unicodecsv==0.14.1
update-checker==0.16
urllib3==1.22
vega==0.4.4
vsts-cd-manager==1.0.1
wcwidth==0.1.7
webencodings==0.5.1
websocket-client==0.47.0
Werkzeug==0.12.2
Whoosh==2.7.4
widgetsnbextension==3.0.0
word2vec==0.9.2
wrapt==1.10.11
xlrd==1.1.0
XlsxWriter==1.0.2
xlwt==1.3.0
xmltodict==0.11.0
zict==0.1.3
zope.interface==4.4.3
[33mYou are using pip version 9.0.1, however version 9.0.3 is available.
You should consider upgrading via the 'pip install --upgrade pip' command.[0m