個人的に趣味(技術的盆栽1)で作っていっているPythonライブラリで使っているLintやサービスであったり、工夫している点や今後検討している点などを色々まとめていこうと思います。
※1人でプライベートにちまちまと進めているのでまだまだ理想的ではない部分も多く、その辺は今後検討している点として触れていきます。「この頃はこんな感じになっていた」と個人的に将来振り返る時のためにも使います。
※本記事はQiitaのイベント開始前に少しずつ書き始めていたのですが、GitHub Actionsも絡んでいるのとGitHub Actionsのイベントテーマが設定されていたので折角なのでイベント用のタグを設定させていただいています。
どんなライブラリなのか
各種説明をスムーズにするために軽く対象ライブラリの内容に触れておきますが、Pythonである程度フロントエンドを書けるようにしたい・・・と思い作り始めたライブラリです。Pythonで書いてHTMLで出力したりJupyter notebook上などで表示したり等ができます。まだまだ機能は少な目です(鋭意開発中)。
CI/CD・Lint関係
以降の節ではCI/CDとLint関係について触れていきます。PythonライブラリのプロジェクトなのでデプロイはPyPI(pipでインストールできる状態)アップロードなどが対象となります。
CI/CDはGitHub Actions
お仕事だとゲームの会社なのでゲームエンジンによるビルドとかが絡んでくるので基本的にJenkinsが多いのですが、今回のプロジェクトではweb方面とかの技術しか使わない(ゲームエンジンとかは使わない)ので普通にGitHub Actionsを使っています。
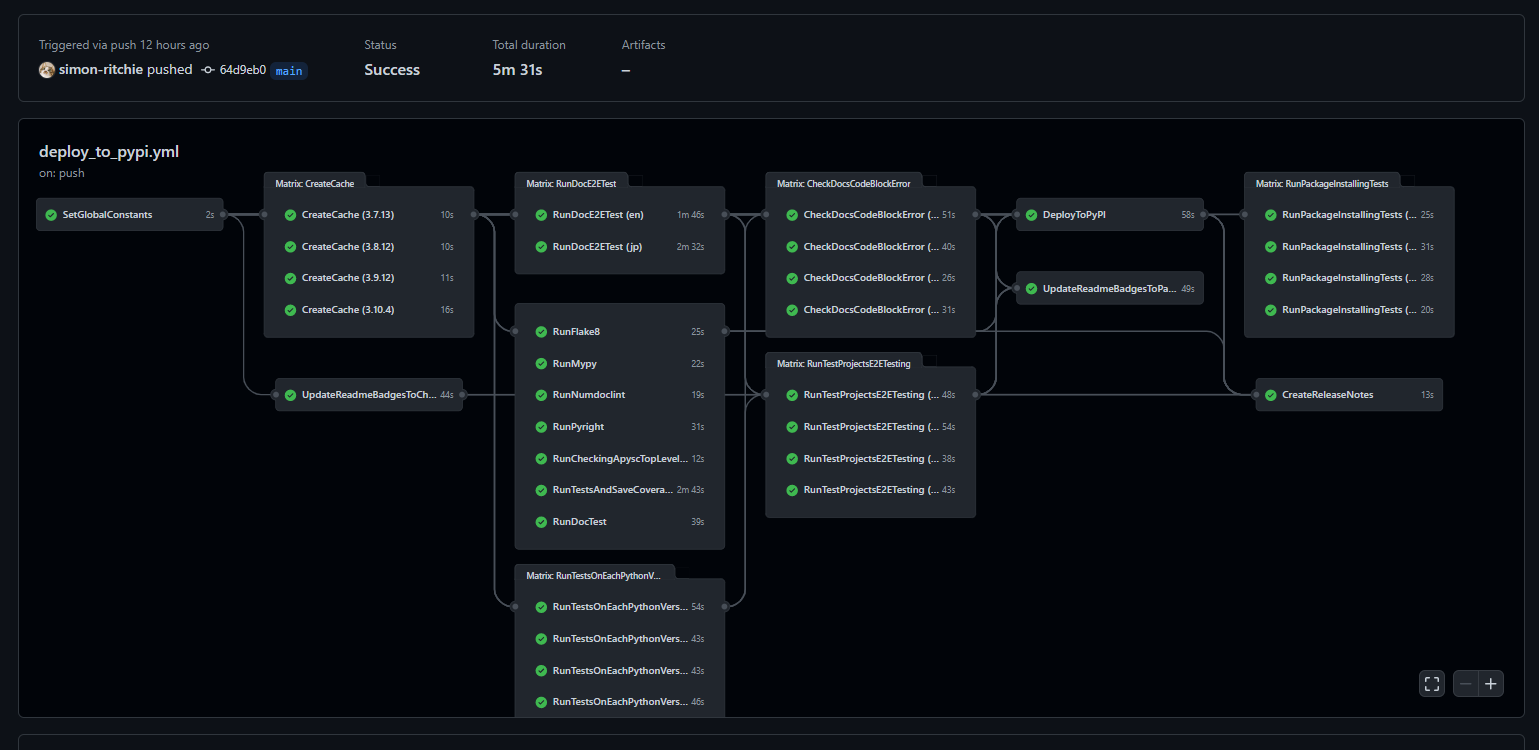
本記事を執筆中にQiitaでGitHub Actionsテーマのイベントもスタートしたため途中でGitHub Actions関係の詳細はそちらの別の記事で詳しく触れています。本記事でも執筆途中だったもの含めある程度は触れますが、リンク先の記事の方が詳しく触れているため詳細はそちらをご確認ください。
大まかにGitHub Actionsでは以下のような点で使っています(細かいところは後々の節で詳しく触れます)。
- 各Pythonバージョン(現時点ではPython3.7~3.10)での環境の作成のキャッシュ
- 各種Lintでのチェックを行い、通らなければデプロイを停止
- 単体テスト(カバレッジの算出なども含む)を行い、通らなければデプロイを停止(以降のチェックなども同様に引っかかればデプロイを止めています)
- ドキュメント内のコードブロックがエラーにならないことのチェック
- ドキュメントでエラーが発生していないことのE2Eテスト
- ※ドキュメント内のコードブロックは実際に実行されHTMLやjsが出力され、そちらもドキュメント上で表示される(ドキュメント上でjsなどが有効になっていて操作やアニメーション等が行える)ため、jsでエラーが発生していないかなどをブラウザを使ってチェックしています。
- テスト用のプロジェクトに対しての出力の実行と結果のHTMLに対するE2Eテスト
- READMEバッジの更新
- PyPIへのアップロード
- GitHub上のReleasesの更新
- PyPIへアップロードされたパッケージを各環境でインストールしたり軽く動かしてみてエラーにならないことのチェック
GitHub Actionsの良さは私が触れるまでも無い感じではありますが、何故GitHub Actionsにしたのかであったり良いなと思っていることなど個人的に感じていることを軽く触れておきます。
- publicリポジトリの場合無料アカウントでも制限が少なく贅沢に使わせていただけるのは大変助かっています。
- cloneやGitHub Pages、Releases等々なるべくGitHubの機能を集約させているのですが、その辺との連携がとてもシンプル&楽で素敵です。
- 学習コストが低くて良いなと思いました。マネージドなのでインスタンス立てたりのサーバーの知識もほぼ要らないですし、UIなども洗練されていて分かりやすいと思いました。触ったことが無い状態から1日あれば公式ドキュメントなどで勉強しつつデプロイなどのワークフローが整備できたのは楽で良かったです。なるべくこの辺で消耗したくないので学習コストが低く抑えられるのは気に入っています。自前でアップデートなども対応しなくて良いのも助かっています。
- GitHubでユーザーが多いだけあって、やりたいことのGitHub Actions用のライブラリなどが非常に充実しているのも良いと思いました。Python環境の準備やPyPIアップロードなども諸々用意されているのでとてもシンプルに対応できて良いです。
- 並列化とかもシンプルにできるので、たくさんジョブを横に並べて処理時間を短縮したりもできて助かっています。どんな感じに並列化しているのか、どんな順番で処理しているかなども可視化してくれるのはジョブが多くなってきているので役立っています。
- YAMLではありますがコードの重複などを減らす機能など色々あって便利だなと思いました。ジョブはぼちぼち多くなってきましたが保守が辛い・・・みたいなことは感じていません。
mypy
型チェック用にmypyを使用しています。Pythonコミュニティでは型関係で一番有名なのでは・・・という感じでもあるのでmypyは外せないなと判断しています。
基本的に全コード型アノテーションする方向で対応しています。完全にstrict設定・・・ではないのですが、以下のようにある程度厳しくしたり、関数などでは型アノテーションが漏れていると弾かれる・・・といった具合にしてあります。misc(Miscellaneous, その他の・雑多なという意味)のエラーのみ無視しています。今振り返ると--ignore-missing-importsの設定は外せられるのでは・・・という感じがしています(後で試してみようと思います)。
$ mypy --ignore-missing-imports --follow-imports skip --disallow-untyped-calls --disallow-untyped-defs --strict-optional --strict-equality --show-error-codes --disable-error-code misc
miscに関しては以下のようにmypyのドキュメントでも割と無視してもいいんじゃない?的な雰囲気が少しあります(?)のでまあ無視でも良いか・・・と判断しています。割と「そのエラーは実害無いし制限すると書きづらくなるなー」と思うケースが出てきたため無視する形にしています。
Mypy performs numerous other, less commonly failing checks that don’t have specific error codes. These use the misc error code. Other than being used for multiple unrelated errors, the misc error code is not special. For example, you can ignore all errors in this category by using # type: ignore[misc] comment. Since these errors are not expected to be common, it’s unlikely that you’ll see two different errors with the misc code on a single line
DeepL翻訳:
Mypyは、特定のエラーコードを持たない、あまり一般的には失敗しない他の多くのチェックを実行します。これらは、miscエラーコードを使用します。複数の無関係なエラーに使われる以外には、miscエラーコードは特別なものではありません。たとえば、# type: ignore[misc] comment を使えば、このカテゴリのエラーをすべて無視することができます。これらのエラーは一般的なものではないと考えられるので、1 行に 2 つの異なるエラーで misc コードが付くことはあまりないでしょう。
Pyright
mypyだけでなくPyrightも型チェックで使っています。
元々VS Code上でPylanceを使っていたのでPylance内部で使われているPyrightはエディタ上でのチェックは動いていましたが、pipだけでも簡単にインストール出来てCIに組み込めるようになったため途中から導入しています。その辺は以前以下の記事で触れています。
mypyとPyrightでたまに引っかかる箇所が異なるので両方チェックされていると一層安心ができる点、並列実行などしているのでそんなにCI/CDが長くなったり・・・という感じでもないため入れています。
isort
importのフォーマッタとして使用しています。アルファベット順でのimportのソートであったりPEP8に準拠したビルトインパッケージ・サードパーティーパッケージ・プロジェクトパッケージ間で1行空けるといった点などを直してくれます。
※PEP8に関しては以下の記事等で昔詳しく触れています。
--force-single-line-importsのオプションだけ設定しています。このオプションでは以下の例のようにimportが1行ずつに分割されるようになります。
from any_package_1 import any_module_1, any_module_2
from any_package_2 import (
any_module_3, any_module_4
)
from any_package_1 import any_module_1
from any_package_1 import any_module_2
from any_package_2 import any_module_3
from any_package_2 import any_module_4
元々は、理由はよく分かっていないのですが設定や引数などを合わせても複数のまとまったimportの箇所で複数人で作業していてフォーマッタの結果が稀にずれたことがあり、その都合で1行ずつのimportする形にして使っています。余談ですが割とimportの記述に統一感が感じられるようになって本来の目的ではないのですがこちらの設定の方が気に入っています。
autopep8
昔から仕事で使ってきていたPEP8準拠用のフォーマッタです。
特に不便さなどは感じておらず快適に使わせていただいています。ただし最近は世の中の流れ的にBlackの方が良いのだろうか・・・?と結構感じてきています。Blackも将来ちゃんと触ってみようと思います(autopep8の代わりに入れた方が快適なのか、それとも両方使った方が快適なのか等含め)。
※ちなみに先日別のPythonの自作Lintライブラリで「Blackのフォーマッタ結果と競合しないように実装加えたよ」的なプルリクをいただいたので世の中の流れ的にBlackの必要性はじわりじわりと感じてきています・・・。
autopep8とisort、及び後述するautoflakeのフォーマッタを通すことで多くのケースでPEP8準拠が完了しflake8が通るようになっています。
autoflake
こちらもフォーマッタです。
使われていないimportやローカル変数などの削除を行うことができます。使われていないものが残っているとflake8などで引っかかったりする一方で毎回引っかかってから修正する・・・とするのは手間なのでflake8実行前に流しています。
ちなみにフォーマッタの順番として、autoflakeで不要なimport等を削除 → isortでimportの順番などを整形 → autopep8で他のPEP8準拠用の処理な流す → 後述するflake8のチェックを流すという順番で処理が流れるようにしています。
flake8
flake8はコードがPEP8に準拠しているかをチェックしてくれます。
フォーマッタと異なりコード自体に修正は入りませんが、PEP8に準拠していない箇所があれば引っかかるので準拠していないコードをデプロイしてしまう・・・といったことを避けることができます。
単体で流すと結構引っかかって面倒なので、基本的に各種フォーマッタを通した後にチェックが走るようにしています。
一部sys.path.appendなどを使ってからimportを行っている箇所もあるのでそれを禁止するE402のエラーと現在非推奨になっているW503の警告のみ無効化して以下のコマンドのように使っています。
$ flake8 --ignore E402,W503
参考:
numdoclint
numdoclintはNumPyスタイルのdocstringの記述がされていることをチェックするためのLintです。自前で昔作って仕事やプライベートのプロジェクトで使い始めたら案外便利でそれ以来ずっと使っています(ただしPythonにそこまで精通していないタイミングでの実装なので今コードを見ると大分粗いというか直したいところが・・・)。
docstringが書き漏れていることを避けたり、docstringのスタイルをNumPyスタイルに縛ったり、引数などの内容とずれていたりすると引っかかります。
各Lintのローカルでの実行に関して
基本的に前述の各Lint(及び後述するドキュメント関係)は1つのコマンドでまとめて(並列化できるところは並列化しつつ)流れていくようになっています(1つ1つ実行していると手間なので)。
ローカルで一通りフォーマッタやチェックを通してから、OKそうだったらデプロイ用にGitHub Actionsをプッシュのタイミングで動かしてさらにチェック用の各Lintが走るようにしています。もしGitHub Actions上でチェックに引っかかればそこで止まってデプロイはされないようにしています。
CodeQL
GitHub上でぽちぽちすればさくっとCodeQLのGitHub Actionsが有効になってくれる点、publicリポジトリであれば無料で使わせていただけるのでとりあえず有効にしています。
CodeQLは、SQLと似たような構文のクエリを使ってコードを調べることができる解析エンジンで、脆弱性を発見して駆除するのに利用できる。ゼロデイ脆弱性などの重大な脆弱性とその亜種や、クロスサイトスクリプティング、バッファオーバーフロー、SQLインジェクションといった問題を発見するためのクエリを作成したり、他の開発者とクエリを共有したりできる。
過去1か所だけ軽度の警告で引っかかったことがあるのですが、その際に「どこが駄目なのか」「何故駄目なのか」「どんな風に直す必要があるのか」などを教えてくれるので助かります。特に普段あまり書いていない言語を一部分だけ使った場合などミスしがちなので安心感があります。
Dependabot
こちらもCodeQL同様GitHub上でさくっと有効化できるので利用しています。
package.jsonやgo.modといったマニュフェストファイルをみて古いライブラリやセキュアでないものを調べてくれます。 そして必要に応じてライブラリの更新を行いPull Requestを自動で作成してくれる優れものです。我々に残された仕事はPull Requestをmergeするだけなのです(そしてそれすらも自動化できる)。
一部Jupyter関係のインターフェイスをサポートしているので開発環境用のDockerイメージではJupyter関係もインストールされるようにしているのですが、Jupyter関係で過去2回引っかかってアップデートを反映しています。使ってみた感じUXが良い(良く出来ている)と感じています。
自分だと中々使用ライブラリで脆弱性が出た・・・といったケースを全て見落とし無く対応するのは難しいですし、どんな修正が必要なのかまで教えてくれるのは楽で助かります。
Secretlint
うっかり誤って認証関係のものを公開してしまう・・・ということを防いだり早期に検知するために使用しています。
外部に対して、内部のシークレットキーを公開することはあまり望ましくありません。
エンジニアが誤ってシークレットキーを commit しちゃった時にも、いつからか公開されていた、ということが起きずに迅速にキーの再生成が可能です。
今のところ引っかかったことはない(引っかかるとまずいので引っかからないに越したことは無い感じですが・・・w)のですが、保険的な側面で設定しています。
テスト関係
以降の節ではテスト関係について触れていきます。
pytest
テスト関係はpytestをベースとしています。
過去のPythonの調査でもビルトインのunittestを除くとライブラリの中ではpytestが一番使われていそうな印象なのと、使っていて特に他のものに移りたい・・・とは今のところ感じていないためpytestのまま過ごしています。昔はnoseとかも使っていたのですがなんだかんだpytestに落ち着きました。
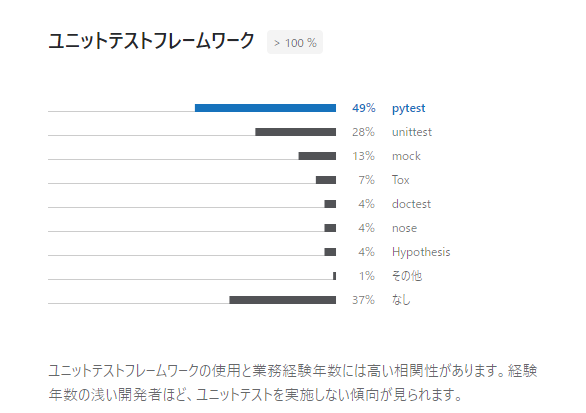
※スクリーンショットは以下のページから引用。
※上記資料は2020年のものですが、なぜか2021年版が今検索したら引っかからず・・・ただ、2021年版も似たような傾向だったと記憶しています。
pytest-cov
pytest-covはテストの行カバレッジを算出するためのpytestのプラグインです。
以下のような機能があります。
- テストの行カバレッジの数字をpytestの結果に含めることができます。
- オプションで行カバレッジが確保できないモジュールと行番号も表示することができます。
ただしテストが通りきるまでは大分長くなります。そのためローカルではカバレッジ計算を行わない形でpytestを動かし、GitHub Actions上でのみカバレッジを計算してバッジに設定する・・・としています(ローカルでもカバレッジを確認しているとデプロイまでのリードタイムが長くなるので)。
また、テストは複数のPythonバージョンで行っていますが、カバレッジの算出は1つのPythonバージョンでのみ実施しています。
テストの件数とカバレッジについて
今のところ(関数とメソッドの件数ベースで)1400強程度の単体テストでカバレッジが99.5%くらいなようです。一部テストが書きづらく書いても旨味が少なかったり書くのに多くの時間がかかってしまってしまう箇所などはスキップしたり、後はカバレッジで漏れた箇所はそのまま・・・とすることが多めですが基本的には全体的にカバレッジを確保する感じでテストを書いています。
pytest-parallel
pytest-parallelはpytestでのテストを並列化してくれるpytestのプラグインです。カバレッジを出す場合や後述するdoctest時などでも並列化できます。
テストが通りきるまで大分速くなるため使用しています(CPUを無駄なく100%使ってくれます)。Rustとかでもビルトインのテストの機能が並列実行されたりすると思いますが、同じような感じで並列実行されます。
ただし作っているライブラリではファイル操作・メモリ操作(インメモリSQLite関係など)などの処理が存在し一部のテストで同時実行されるとタイミングによってはたまにテストが引っかかることがあります。
そういった場合のために(賛否はあると思いますが)テストで引っかかっても一定回数はランダムな時間スリープした後にリトライをするようにしています。並列化関係なくたまに失敗するフレーキーテストなどが埋もれやすいなど好ましくない点もありますが、並列化によるテストが通りきるまでの時間の短縮のメリットを優先しています。
doctest
以下はライブラリ内の一部のインターフェイスの抜粋なのですが、docstringのExamplesセクションにdoctestを記述しています。Pandasとかでも良く書かれているものですね。
def draw_rect(
self, *,
x: Union[int, Int],
y: Union[int, Int],
width: Union[int, Int],
height: Union[int, Int]) -> Rectangle:
"""
Draw a rectangle vector graphics.
Parameters
----------
x : Int or int
X position to start drawing.
y : Int or int
Y position to start drawing.
width : Int or int
Rectangle width.
height : Int or int
Rectangle height.
Returns
-------
rectangle : Rectangle
Created rectangle.
References
----------
- Graphics draw_rect interface document
- https://simon-ritchie.github.io/apysc/en/graphics_draw_rect.html # noqa
Examples
--------
>>> import apysc as ap
>>> stage: ap.Stage = ap.Stage()
>>> sprite: ap.Sprite = ap.Sprite()
>>> sprite.graphics.begin_fill(color='#0af')
>>> rectangle: ap.Rectangle = sprite.graphics.draw_rect(
... x=50, y=50, width=50, height=50)
>>> rectangle.x
Int(50)
>>> rectangle.width
Int(50)
>>> rectangle.fill_color
String('#00aaff')
"""
※doctestに関しては以前記事にもしたのでそちらも必要に応じてご確認ください。
docstringに書いたコードサンプルを実行してくれて、出力値などに対するassertionのようなチェックが走るため「コードサンプルがいつの間にか動かなくなっている・・・!」みたいなことを減らすことができます。
また、実行にはビルトインの機能ではなくpytestを利用を利用しています。他と同様にpytest-parallelなどもそのまま使えるので並列実行もしてくれます。
Playwright
ブラウザ操作が必要なライトなE2Eテストなどに関してはマイクロソフト製のPlaywrightライブラリを使用しています。
Python版:
最初は以前使っていたSeleniumで進めていたのですが、インストールが簡単な点、GitHub Actions上でもさくっと使える点、インターフェイスが手に馴染んだ点、型アノテーションなども結構しっかりしている点(この点は同じくマイクロソフト製のPythonの型チェックライブラリをいくつか出されているだけありしっかりしている印象)などからPlaywrightに切り替えました。
E2Eテストについて
ライブラリのドキュメントページ上のコードブロックは多くのものが実際に更新時などに実行され、結果のHTMLやjsなどはそのままドキュメント上に表示される形にしています。
そのためその辺りのjsがエラーを吐いていないか・・・といったことのチェックとしてGitHub Actions上などでPlaywrightでブラウザを動かしてチェックしています。
また、個々の機能の動作確認としてテストプロジェクトを追加してあり、そちらもGitHub Actions上で動かして結果のHTMLとjsに対してブラウザで開いてみてエラーなどが発生せずassertionも通っていることをチェックといった具合に使用しています。
細かいE2Eテストの制御などまでは量が多くなってくると保守が大変だったりしてくるので今のところは良いかと判断して書いていません。
ドキュメント関係
以降の節ではドキュメント関係に触れていきます。
Sphinx
ドキュメントページとしてはSphinxを使用しています。Python公式やNumPy、Pandas、PyTorch、boto3などPythonコミュニティ界隈ではドキュメントに関してはSphinxが多く使われている印象なので郷に入っては郷に従えということでSphinxを使用しています。プライベートのライブラリだけでなくお仕事でもお世話になっています。
Sphinxには大分お世話になっているのでこっそりSphinxのContributorの方にもごく少額のGitHub Sponsors課金しています。月100円くらいから課金できるのでSphinx推しの皆さまも投げ銭してみていただいても良いかもしれません。

commonmark と recommonmark
Sphinxでは慣れたマークダウンで執筆したいのでrecommonmarkなどを使ってマークダウンを使っています。
ただし現在Deprecatedになってしまったようで、MySTへの移行が推奨されています。
Warning: recommonmark is now deprecated. We recommend using MyST for a docutils bridge going forward.
他にも色々調整したりして部分的なビルドになるようにしつつもなんだかんだ全体的にビルドが走ってしまったり・・・なども気になっており解決方法を悩んでいたりもしているのでそのうち検証して移行しようと思っています(ドキュメント量が増えてきたので結構処理時間が気になる感じに・・・)。
GitHub Pages
ドキュメントページのホスティングは以下の理由からGitHub Pagesを使わせていただいています。
- mainブランチへのpushだけでデプロイできるのがとても楽です。
- 趣味のライブラリプロジェクトである大したアクセスも無いのでGitHub Pagesのview上限にはまず引っかかりません。
- jsなども動かせられるためドキュメント内のコードブロックの実行結果のHTMLとjsもそのまま表示して動かすことができます。
ただしSphinxで利用する場合は_staticなどの出力ディレクトリをリネームする必要などが出てきます(GitHub Pagesだと_staticなどのようなアンダースコアのプレフィックスを持つディレクトリが無視されてしまいます)。
その辺のリネームなどの制御を最初に加える必要がありますが他はSphinx + GitHub Pagesの組み合わせはとても快適に使わせてもらっています。
日本語版のドキュメントについて
現在このライブラリは英語と日本語のドキュメントを追加しています。
英語はまあ必須として、日本語のドキュメントはドキュメントの数が増えて保守負担が増加するのでどうしようか・・・と思ったのですが、リポジトリにスターを付けてくださる方が日本の方が多そうな印象を受けているのと、(この記事もそうですが)アピールする領域が今のところ日本語圏が多いということもあり日本語のドキュメントも対応することに途中から切り替えています。
多言語対応は以前お仕事でゲームを他の言語に移植したことくらいしか経験が無いのですが、元々技術的盆栽的に趣味として書いていっているライブラリなので仕事と異なりその辺は開発で非効率なところが少し出てきても色々勉強としてやってみよう・・・という面も考えいました(英日両方のドキュメントを保守する形にするとどうなるだろうかと)。
ちなみに140ページくらい英語のドキュメントがある状態で日本語の翻訳ドキュメント対応をスタートしたのですが、中々に対応が終わるまで時間がかかりしんどい思いをしました😓w
これは英語のドキュメントを更新したら日本語版も都度小まめに更新する形にしないと、長時間翻訳に時間が取られるのは中々メンタルに来るぞ・・・と感じて最初の対応以降は小まめに翻訳ドキュメント側の作業を行うようにしています。
日本語のドキュメント対応をするにあたって以下のようなことを対応・配慮しています。
- なるべく作業でスクリプト化できるところはスクリプト化するようにして、通常の各種Lintなどが流れるタイミングで一緒に処理が流れるようにしています(翻訳のマッピング用のモジュールの出力・マッピング反映・翻訳の欠落のチェックやフォーマットのずれのチェックなど)。
- 一部の翻訳が存在しないといった状態になって、ドキュメント内に英日混在するといった状態になると読みづらいと感じているのでそもそも英語のドキュメントの各文章に対する日本語のマッピングが無ければビルドで弾かれるようにしました。
- これによってデプロイ時には英語のドキュメントが更新されていたら必ず日本語側も更新する必要があるという形にしています。
- 前述の通り後でまとめて翻訳ドキュメント関係を作業する・・・とやるとメンタル的にきついのでこのように小出しに都度翻訳ドキュメント用の作業が入る形なのは今のところ快適に感じています。
- リンクに設定するページタイトル部分であったり、APIドキュメントとして出力されるテキストの部分であったりは部分的に共通の英語となる箇所も結構あるので、各ドキュメント共通で反映される翻訳のマッピングも設けています(各ドキュメントで毎回全ての文章を翻訳設定しなくて済むように)。
今のところは作業は快適に感じていますが、単純にページ数が倍になるのとじわりじわりとSphinxでのビルド時間が伸びたりしてきているのが少し悩ましいところではあります。その辺の改善用にSphinx設定や使用しているマークダウンライブラリの切り替えなどはそのうちやっていこうと思っています。
APIドキュメントについて
APIドキュメントに関してはページ内の任意の箇所に挿入できるようにしています。良くある別途APIドキュメント専用のページが出力されるといった感じではなく、対象のインターフェイスのドキュメント内に一緒に表示されるようにしています。
例えばドキュメントのマークダウン中に<!-- Docstring: apysc._display.graphics.Graphics.draw_rect -->みたいなパッケージと関数(メソッド)のパスを記述しておくと、対象の関数(メソッド)に設定されているdocstringの内容を読み取ってAPIドキュメントの節に変換してくれます。
変換例:
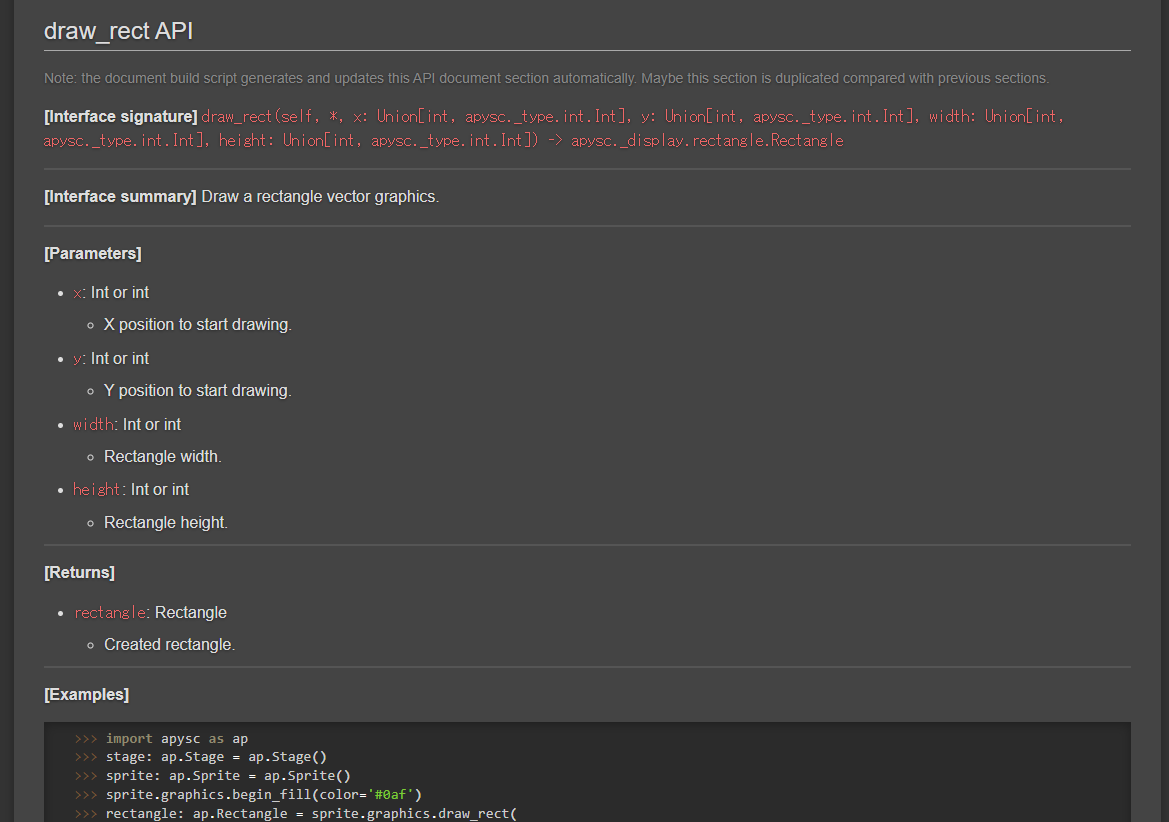
docstringのマークダウンへの変換
APIドキュメントとして出力している部分以外でも、各モジュール(privateなものも含め)の関数やメソッドのdocstringがマークダウンとして出力されるようにしています。更新を検知したらそのモジュールだけ更新・出力されます。
docstringも英語で書いているのですが、英語のライティングには自信が無いため補助的にGrammarly Premiumを使用しています。そのGrammarlyでのVS Code上でのチェックがマークダウンとして出力されていると色々捗るため変換処理が実行されるようにしています。
docstring更新後に該当箇所でGrammarlyのチェックに引っかかれば都度docstringの英語の修正を行っています。
ドキュメント内のコードブロックの実行と出力結果のドキュメント上での表示
ドキュメント内のPythonのコードブロックに関してはLintなどを反映する際に一緒に実行されるようになっています。実行結果のHTMLファイルなどはSphinxの静的ファイルのディレクトリに保存されます。また、ドキュメントのマークダウンからもiframeでの表示設定をしています。
結果的にドキュメント内のPythonコードブロックは更新時などに実行され、結果もドキュメント上に表示される・・・といった形になっています(ドキュメント上でそのままアニメーションやマウスイベントなどをサンプルとして扱えるようになっています)。
例 :
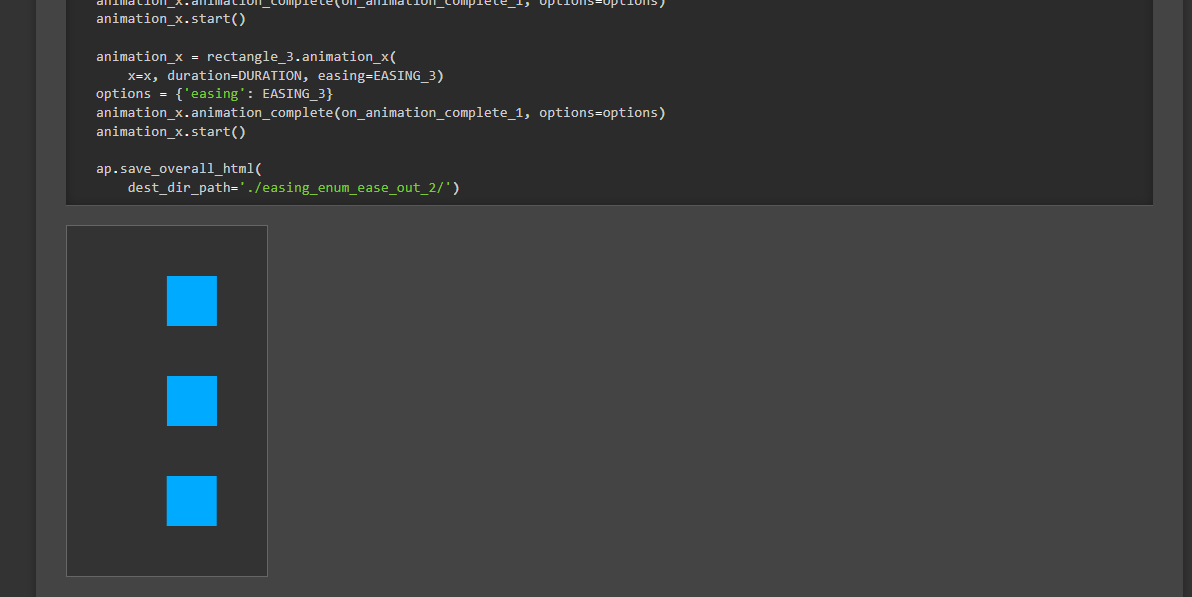
これによってユーザーもコードサンプルだけでなく実際の動作も確認できるので動作のイメージが付きやすいかなと思っています。また、デプロイ前に更新箇所が実行されることによってドキュメント上のコードブロックがいつの間にか動かなくなっている・・・といったことを軽減できています。
エディタ
以降の節ではライブラリ開発で使用しているエディタについて触れていきます。
VS Code
DreamweaverやFlashDevelop、秀丸など → Sublime → Atomと10数年で色々利用エディタが推移してきましたが、ここしばらくはずっとVS Codeに落ち着いています。メリットや気に入っている点などは世の中に記事がたくさんあるのでここで触れるまでも無いと感じているため割愛します。
Pylanceの拡張機能
VS CodeのPythonの拡張機能としては主にマイクロソフト公式のPylanceを使用しています。型のチェック設定も有効にしています。
過去の記事 :
コード編集中に型のミスや文法ミス、null(None)安全的なところをリアルタイムにチェックしてくれるので助かっています。
最終的にはmypyやPyrightでデプロイ前にチェックされるようになっていますが、そちらで頻繁にチェックに引っかかると地味に開発体験が悪いので多くの箇所は事前にPylanceでリアルタイムにチェックしてくれるのは楽で良いです。
過去の記事 :
Markdown All in Oneの拡張機能
ドキュメントもマークダウン + Sphinxで書いていますしREADMEとかもマークダウンなのでMarkdown All in OneのVS Codeの拡張機能を使用しています。マークダウンの執筆がぐぐっと楽になります。
Tabnine Pro版
お仕事で使い始めたらとても快適だったためTabnineのVS Code拡張を使っていっています。KiteやCopilotのようにディープラーニングを使った入力補完の拡張機能です。有料のPro版を利用させていただいています。Kiteとかも以前使っていましたが結局Tabnineに落ち着きました。
プロジェクト内のコードを学習してくれるので自分(達)の書いたコードのスタイルやパターンに統一感があったりLintでフォーマットの統一などがされていれば一層補完が快適になります。「自分ならこう書く」という補完をしっかりと出してくれて良いです。私の場合は4割強くらいのコードはTabnineによる補完での生成結果のようです。
Grammarly Premium
英語力が全然足りていない一方でドキュメントなどは英語で書く必要があるため補助的にGrammarlyの有料版(Premium) + VS Code拡張を使用しています。
以前いくつかGrammarlyに関しても記事にしています。ただしバージョンアップで挙動や設定が変わっているので記事の内容は少々古くなっています。
過去の記事 :
英文法だけでなく「このセンテンスは読みづらくなっているよ」とか「もっとこうした方が良いよ」といったことも教えてくれるのと、修正版のセンテンスを出力してくれたりなど、しばらくPremium版を使ってからは手放せなくなっています。
本記事執筆中の現在の拡張機能のリリースバージョン(0.22.1)だと私だけかもしれませんが不安定に感じたためPre-Release版に切り替えています。Pre-Release版では今のところぐぐっと安定して利用できています。
autoDocstring
docstring生成を以前はスニペット的にcliborというクリップボードツールに定型文登録して対応していたりしていたのですが現在はautoDocstringというVS Codeのdocstring生成用の拡張機能を使用しています。
プロジェクトではNumPyスタイルでのdocstringを採用しているのですがこの拡張機能でもNumPyスタイルをサポートしてくれています。
過去の記事 :
開発環境
以降の節では開発環境関係について触れていきます。
Docker
開発環境にはDockerを利用しています。
ただしVS CodeでRemote Containersとかは使っていません(使えていません)。その辺り触れていないのがなんだか世の中の流れに置いて行かれている感が結構しているのでそのうち触ろうとは思っています(自戒)。
また、現在はPoetryやPipenv的なものでコンテナ内で複数のPythonバージョンを・・・といったことはしておらず、シンプルにPython公式のDockerイメージを使ってサポートしている最低バージョンのPythonで開発をしています。
Poetryとかで各Pythonバージョンを気軽にバージョンを切り替えて使えるようにすると、別バージョンでのテストが楽になるかもしれませんが、一方で今のところバージョンに起因するエラーなどはほとんど遭遇していません。そのため各バージョンのテストはGitHub Actions上でやってもらうだけで十分かなと判断しています(ローカルでのテスト時間をあまり長くしてくないというのもあります)。将来必要性を感じてきたら変更しようと思います。
ライブラリで工夫している点
以降の節ではライブラリ実装で工夫している点などについて触れていきます。
基本的にキーワード引数指定で縛っている箇所が多い
基本的に多くのインターフェイスでキーワード引数指定の制約を多く設けています。バージョンアップでのコード更新の影響を少なくするためと自作のライブラリなので自分が快適になるように好きに制約など設定してしまおう・・・と判断してpublicのインターフェイスなどでも結構制約を課しています。
この辺は近いところで以前記事にしています。
ただしシンプルな引数構造且つ変化がごく少ないインターフェイスに関しては設定していないことも多くあります。例えばInt(10)みたいな部分ではキーワード引数の制約を課していません。大体以下のstackoverflowの投稿に近い感覚で対応しています。
There isn't any reason not to use keyword arguments apart from the clarity and readability of the code. The choice of whether to use keywords should be based on whether the keyword adds additional useful information when reading the code or not.
I follow the following general rule:
- If it is hard to infer the function (name) of the argument from the function name – pass it by keyword (e.g. I wouldn't want to have text.splitlines(True) in my code).
- If it is hard to infer the order of the arguments, for example if you have too many arguments, or when you have independent optional arguments – pass it by keyword (e.g. funkyplot(x, y, None, None, None, None, None, None, 'red') doesn't look particularly nice).
- Never pass the first few arguments by keyword if the purpose of the argument is obvious. You see, sin(2pi) is better than sin(value=2pi), the same is true for plot(x, y, z).
DeepL翻訳:
キーワード引数を使用しない理由は、コードの明快さと読みやすさを別にすれば、何もありません。キーワードを使うかどうかの選択は、そのキーワードがコードを読む際に有用な情報を追加するかどうかに基づいて行われるべきです。
私は以下の一般的なルールに従います。
1.関数名から引数の機能(名前)を推測するのが難しい場合 - キーワードで渡す(例:私のコードに text.splitlines(True) は入れたくない)。
2.引数が多すぎる場合や、独立したオプション引数がある場合など、引数の順番を推測するのが難しい場合 - キーワードで渡す (例: funkyplot(x, y, None, None, None, None, 'red') は特にいい印象を与えない).
3.引数の目的が明らかな場合、最初の数個の引数をキーワードで渡してはいけません。sin(2pi) は sin(value=2pi) よりも良いことはお分かりでしょう、同じことが plot(x, y, z) にも当てはまります。
ローカルでのLintなどの並列実行
デプロイ前に必要なLintでのフォーマットやチェック・ドキュメント関係の同期などは1つのコマンドで通るようにしていますが、なるべく処理が早く終わるように並列実行などもしています(元々Sphinxとかは何も考えなくともCPU100%使ってくれる感じではありますが・・・)。
この辺はそこまで厳密に・・・とはできていませんが、長くなってくると開発体験が悪くなるのである程度は内部の処理も定期的に見直ししています(処理時間を削れるところを定期的に探したりなど)。
フォーマッタ関係は更新されていないものはスキップするようにしている
フォーマッタ関係(isortなど)を毎回全体に実行していると処理時間がかかってしまうため、最後に実行した際の各ファイルごとのハッシュ値を保持するようにして、実行前にハッシュ値を比較・ファイルが変動していない場合にはそのファイルではフォーマッタの実行をスキップ・・・といった制御を加えてあります。お仕事のプロジェクトでも似たようなことをしています。割とトータルの処理時間が変わってきます。
デコレーターでの引数のバリデーションやデバッグ設定
Pythonのデコレーターの機能、他の言語上でのデコレーターパターンと扱い方が結構異なる印象なのですが、Pythonだと関数やメソッドの外側にぺたぺたと設定する形になります。
元々のコードを変更せずに他の機能を加える・・・という本来のデコレーターパターンに加えて、最近ではコードの読みやすさ的にも少しプラスになるかも?と個人的な主観ですが感じはじめています。
元々は「Advanced Python Programming」の本でバリデーションやデバッグ設定などはデコレーターで関数の外に出しておくと良いよ、的なことが書かれていて参考にしています。
たとえば以下の一部のコード例のように結構がっつりバリデーションをデコレーターとして外側に切り出しています。mypyとかで型チェックはしているものの型チェックを使わない方とかでもミスを検知しやすいように各引数に型のチェックを入れたり、0以上の数値を受け付けたい引数に対してチェックを入れたり、0.0~1.0の範囲で値を受け付けたい引数ではその制約をかけたり・・・とデコレーターでしています。
「デコレーター領域によるバリデーションやデバッグ設定」「引数のシグネチャ部分」「docstring部分」「関数内の処理の実装部分」と綺麗にグループが分かれます(綺麗かどうかは人の意見によって様々だと思いますが個人的には気に入っています)。
@arg_validation_decos.is_integer(arg_position_index=1)
@arg_validation_decos.is_integer(arg_position_index=2)
@arg_validation_decos.is_integer(arg_position_index=3)
@arg_validation_decos.num_is_gte_zero(arg_position_index=3)
@arg_validation_decos.is_integer(arg_position_index=4)
@arg_validation_decos.num_is_gte_zero(arg_position_index=4)
@add_debug_info_setting(module_name=__name__)
def draw_rect(
self, *,
x: Union[int, Int],
y: Union[int, Int],
width: Union[int, Int],
height: Union[int, Int]) -> Rectangle:
"""
Draw a rectangle vector graphics.
Parameters
----------
x : Int or int
X position to start drawing.
y : Int or int
Y position to start drawing.
width : Int or int
Rectangle width.
height : Int or int
Rectangle height.
Returns
-------
rectangle : Rectangle
Created rectangle.
References
----------
- Graphics draw_rect interface document
- https://simon-ritchie.github.io/apysc/en/graphics_draw_rect.html # noqa
Examples
--------
>>> import apysc as ap
>>> stage: ap.Stage = ap.Stage()
>>> sprite: ap.Sprite = ap.Sprite()
>>> sprite.graphics.begin_fill(color='#0af')
>>> rectangle: ap.Rectangle = sprite.graphics.draw_rect(
... x=50, y=50, width=50, height=50)
>>> rectangle.x
Int(50)
>>> rectangle.width
Int(50)
>>> rectangle.fill_color
String('#00aaff')
"""
rectangle: Rectangle = Rectangle._create_with_graphics(
graphics=self, x=x, y=y, width=width, height=height)
return rectangle
バリデーションやデバッグ設定が関数内から外に出るので、関数内でバリデーションなどの記述でひたすら内部の処理が長くなったりせずに関数内では挙動の内容の記述に集中できるという点がメリットに感じています。
バリデーションの関数などを関数内でたくさん呼び出しても別に関数の認知的複雑度とかは増えないので別にデコレーターとして切り出さなくても良いので?という気もしていたのですが、試しに切り出してみたら割と良く感じており本プロジェクトでは積極的に切り出していこうと感じてしいます。
仕事ではないのでこういった実験的な対応をしてみて、長期的に保守してみてどうなのか・・・という点を検証できるのもプライベートの技術的盆栽のプロジェクトは良いですね。
余談ですがデコレーターを快適に使えるように、デコレーターで関数などのシグネチャを維持するといった方法に関しては以前記事にもしました。必要に応じてご確認ください。
パッケージの集約と内部実装のパッケージのアンダースコアの設定
本ライブラリではPandasやNumPyのメジャーどころのライブラリであったりビルトインTkinterなどと同様にルートのパッケージにユーザーに使ってほしい機能は集約していっています。import pandas as pdとすれば大体の機能が使える・・・といった実装と同じように、import apysc as apとすればユーザーに使ってほしいところは全てアクセスができるようにしています。
また、一通りの内部実装のパッケージにはアンダースコアを付けています。Python界隈だと(プロジェクトによってルールは様々ですが)アンダースコアが付いたらprivate的に扱われる(基本的にユーザー側はそれらは触らない)という慣習が多いのでそちらに合わせています。内部実装ではアンダースコアが付いているパッケージでもお互いに使用しています。
その他のクラスのメソッドについてもユーザーから触られたくないものに関してはアンダースコア付き(ただし内部実装からは使用する)としています。この辺はPEP8をベースとしつつも特殊なルールには少しなっているのでそのうちスタイルガイド的な資料にまとめたいところです・・・(そこまで着手できておらず・・・)。
その他の今後検討している点
以降の節では触っていないけれども今後試してみようか・・・と考えている点などに触れていきます(前節までで触れてきた内容は割愛します)。
GitHub Actionsのローカルでのデバッグ
GitHub Actionsに関しては些細な更新であれば直接YAMLを更新、結構大きな修正や検証が必要なものは別のテスト用のリポジトリで試してみる・・・としていたのですが、全ての再現といかなくともデバッグ用のローカル実行もできたりするようで、この辺りも将来試してみてもよいかもと考えています。
GitHub Actionsの結果のマークダウン出力
GitHub Actionsの結果のサマリー画面にマークダウンで内容を出力できる?ようになったらしいので各種細かい数値など出力・整形するようにしても良いかなーとぼんやり考えています。
Contributing関係の資料やGitHub Actionsの整備
今のところほとんど自分一人で作業をする前提になっているので、スタイルガイドなども含めContributingなどの資料やGitHub Actionsのワークフローの整備などそのうちしたいところです。
といいつつもプライベートで一人で自由に好き勝手作業するのは癒されるのでその辺の整備は後回しで良いか・・・という気持ちも感じています。
認知的複雑度のLintの追加
現在特に(なるべくインデントや分岐などが少なくなるようにとは意識はしているものの)Lintによる複雑度の制限などは追加していないため、flake8の拡張機能などで認知的複雑度がチェックできるものがある?ようなので入れてみてもいいかも・・・と考えています。
その他
その他使っているものなどを以降の節で雑多に記述していきます。
html-minifier
結果の出力されるHTMLのminifyの処理にはHTMLMinifier(html-minifier)を使用しています。
しかし途中で気づいたのですがRustで書かれたminify-htmlの方が速くてサイズ削減率が高そう?な気がしておりその内プロジェクト内で計測してみて良さそうなら移行してみようか・・・と考えています。
親指シフト
社内で宣伝したりQiitaでも記事を書いたりしても一向に流行る気配がないのですがずっと親指シフトを使っています。
普段の仕事での快適さと執筆・チャットの高速化に加えて、このライブラリプロジェクトでも日本語翻訳の資料執筆で活躍しています。
REALFORCE、ErgoDox、ノートPCのキーボード・・・と各キーボードで使用してきましたが、長いことローマ字入力には戻りたいとは感じたことは無い・・・くらいには気に入っているのですが中々流行りません。日本語入力効率が全然変わり、指への負荷も良い感じに減るのでもっと日本中で広まると良いと思います(宣伝)。
参考文献・参考サイト
-
参考記事: 文化的雪かきと技術的盆栽 | 技術的盆栽 ↩