今まで複雑なデータ操作・分析などはPythonでやっており、SQLは普通のアプリ開発程度のライトなものしか触って来なかったのですが、やはり分析用の長いSQLなども書けた方がやりとり等で便利・・・という印象なので、復習も兼ねて記事にしておきます。
また、SQLに加えて検算も兼ねてPythonやPandasなどを使ったコードもSQLと併記していきます(Pythonで書くとどういった記述が該当するのかの比較用として使います)。
※長くなるのでいくつかの記事に分割します。本記事は5記事目となります。
他のシリーズ記事
Athenaとはなんぞやという方はこちらをご確認ください:
※過去の記事で既に触れたものは本記事では触れません。
#1:
用語の説明・SELECT、WHERE、ORDER BY、LIMIT、AS、DISTINCT、基本的な集計関係(COUNTやAVGなど)、Athenaのパーティション、型、CAST、JOIN、UNION(INTERSECTなど含む)など。
#2:
GROUP BY・HAVING・サブクエリ・CASE・COALESCE・NULLIF・LEAST・GREATEST・四則演算などの基本的な計算・日付と日時の各操作など。
#3:
文字列操作全般・正規表現関係など。
#4:
コメント関係・配列操作全般・ラムダ式など。
この記事で触れること
- 辞書関係全般(STRUCT、MAP、ROW、JSON)
環境の準備
以下の#1の記事でS3へのAthena用のデータの配置やテーブルのCREATE文などのGitHubに公開しているものに関しての情報を記載していますのでそちらをご参照ください。
特記事項
AthenaのクエリエディタのUIが新しいバージョンのものにアクセスができるようになったため、本記事からはお試しで新しいUIのものを使っていっています。
辞書の操作
以降の節では辞書について全体的に色々と触れていきます。
STRUCT型とMAP型とROW型とJSON型
まず型についてですが、辞書に近い挙動をするものも含めるとAthena(Presto)上にはSTRUCTとMAPとROWという型があります。
STRUCT型はキー名と値の型が固定された辞書となります。例えばSTRUCTでxというキーを整数、yというキーを文字列を定義したとすると{"x": 10, "y": "allegro"}といったような辞書の値を扱えるようになります。ただし定義されていないキーを使用することはできません。例えば{"x": 10, "y": "allegro", "z": true}といったように定義されていないzというキーは扱うことができません。
MAP型はキーの型と値の型が固定されます。型は固定されるものの、キー名自体は固定されません。例えばキーに武器のマスタID、値に攻撃力を持つ辞書・・・といったように、キー名がログの行ごとに様々なようなケースで使えます。例えば{"10": 1200, "13": 2500}みたいなログに向いています。
ROW型は辞書のようにキーと値のペアを持つ型となりますが、STRUCTやMAP型などとはCASTの方法や値への参照の書き方などが変わってきます。テーブル自体の定義では基本的にSTRUCTかMAPを使い、ROW型はAthena(Presto)の関数の返却値などで出てきます。例えば前回の配列関係の記事で触れたZIP関数などが該当します。
STRUCTなどのカラムに対してSELECTで表示した場合そのカラムの型はROWとなっています(ROW関係の制御が指定できます。この辺りは後々の節で触れます)。
また、JSON型というデータも存在します。こちらはJSON形式の文字列が特定のカラムに含まれている・・・といった場合に変換を挟んで利用したりします。
新しく扱う辞書用のテーブルについて
本記事から辞書関係のデータを扱っていく上で以下のテーブルが追加になっています。それぞれSTRUCT(キーが固定な辞書)用、MAP(キーが様々な辞書)用、STRUCTを格納したARRAY(辞書を格納した配列)用として設定しています。
user_pvp_status テーブル
user_pvp_status テーブルはユーザーのPVPごとのステータス情報を格納するテーブルです。基本的なカラムに加えて自身のPVP時点でのステータスのカラム(self_status)と相手のPVP時点でのステータスのカラム(enemy_status)を持っています。ステータスのカラムはSTRUCT型で、user_id, attack, defence, speed, luckというキーを持っています。
SELECT * FROM athena_workshop.user_pvp_status LIMIT 10;
user_materials_count テーブル
user_materials_count テーブルはユーザーの日次の所持している素材アイテム(合成素材的なものをイメージしてください)の所持数のデータを格納するテーブルです。基本的なカラムに加えてキーに対象のアイテムのマスタID、値に所持数を格納した辞書のカラム(materials_count)を持っています。対象のカラムはMAP型でキーも値も整数で設定してあります。
SELECT * FROM athena_workshop.user_materials_count LIMIT 10;
user_weapon テーブル
user_weapon テーブルはユーザーの所持している武器データの配列をする格納するテーブルです。基本的なカラムに加えてweaponsというカラム名で武器データの辞書を格納した配列が設定されています。辞書には武器のマスタIDのmst_idキー、攻撃力のattackキー、レベルのlevelキーが設定されています。
SELECT * FROM athena_workshop.user_weapon LIMIT 10;
user_weapon_json_str テーブル
user_weapon_json_str テーブルは内容はほぼ user_weapon テーブルと同じですが、武器のデータのカラムのみ配列ではなくJSONの文字列になっています。後の節でJSON変換などの説明のために使っていきます。
SELECT * FROM athena_workshop.user_weapon_json_str LIMIT 10;
STRUCTのカラムの値はSELECTで表示するとROW型となる
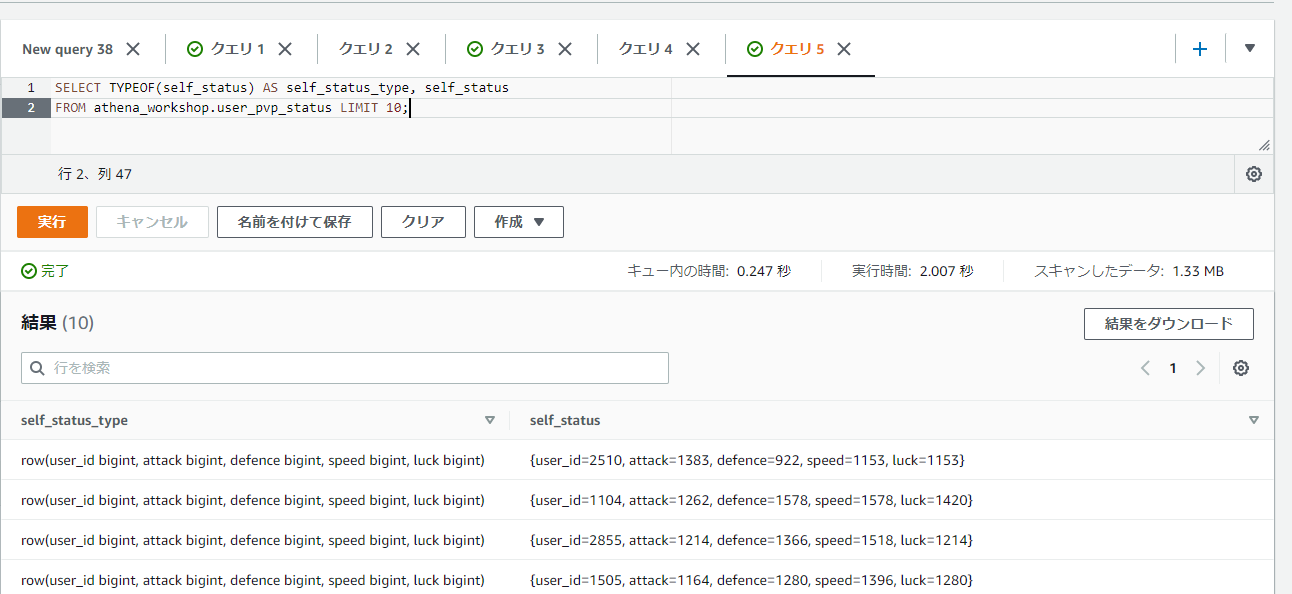
STRUCTのカラムの値に関してですが、SELECTで値を表示すると結果はROW型として表示されます。UI上の表示としては{user_id=3642, attack=905, ...}といったように辞書のような表示となり、ただしキー名(フィールド名)と値の間がイコールで繋がれる形となります。また、対象のカラムの型を表示するTYPEOF関数を使うとROW型として表示されることが分かります(row(user_id bigint, attack bigint, ...)といったような表示になります)。
SELECT TYPEOF(self_status) AS self_status_type, self_status
FROM athena_workshop.user_pvp_status LIMIT 10;
STRUCTのカラム内の特定の値にアクセスする
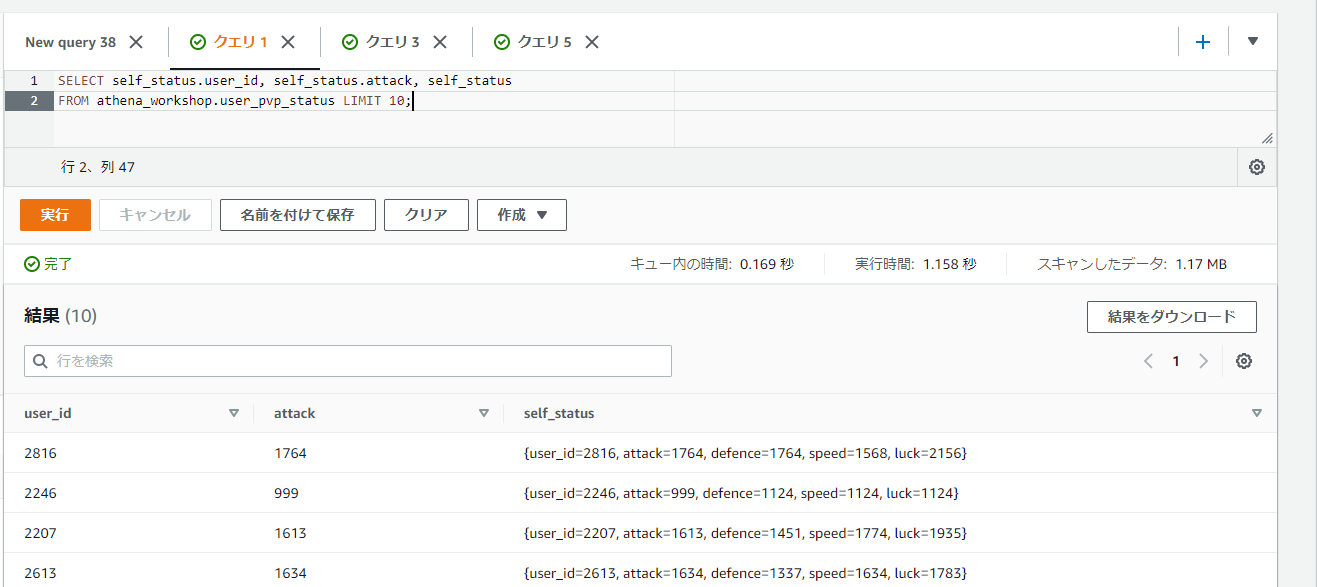
STRUCTのカラムの値はSELECTするとROW型となるため、ROW型と同じようにカラム内の特定の値にアクセスすることができます。
ROW型は<対象のカラム名>.<フィールド名>といった形でドット区切りで指定することで特定の値にアクセスすることができます。なおカラム名はSTRUCT内のフィールド名が自動で設定されるようです。ASとかを指定しなくても該当の名前が表示されています。
SELECT self_status.user_id, self_status.attack, self_status
FROM athena_workshop.user_pvp_status LIMIT 10;
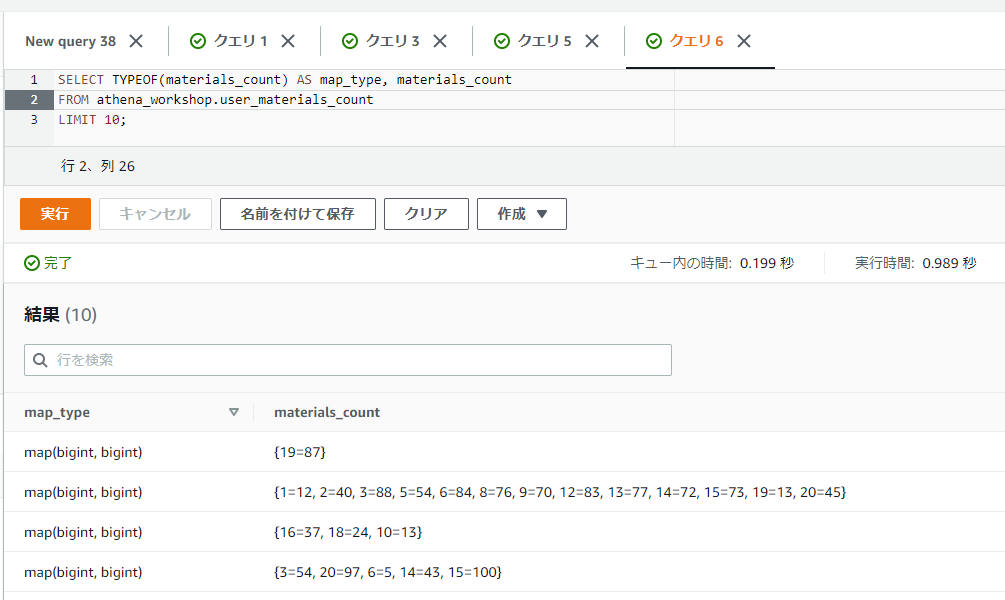
MAPのカラムの値はSELECTで表示してもMAPのままとなる
STRUCT型と異なりMAP型の方はSELECTで表示してもそのままMAP型で扱われます。TYPEOF関数で表示してみるとmap(bigint, bigint)といったように表示されることが確認できます。値の表示はROW型と同じように、{{16=37, 18=24, 10=13}}といったようにキーと値の間がイコールで繋がれる形となります。
SELECT TYPEOF(materials_count) AS map_type, materials_count
FROM athena_workshop.user_materials_count
LIMIT 10;
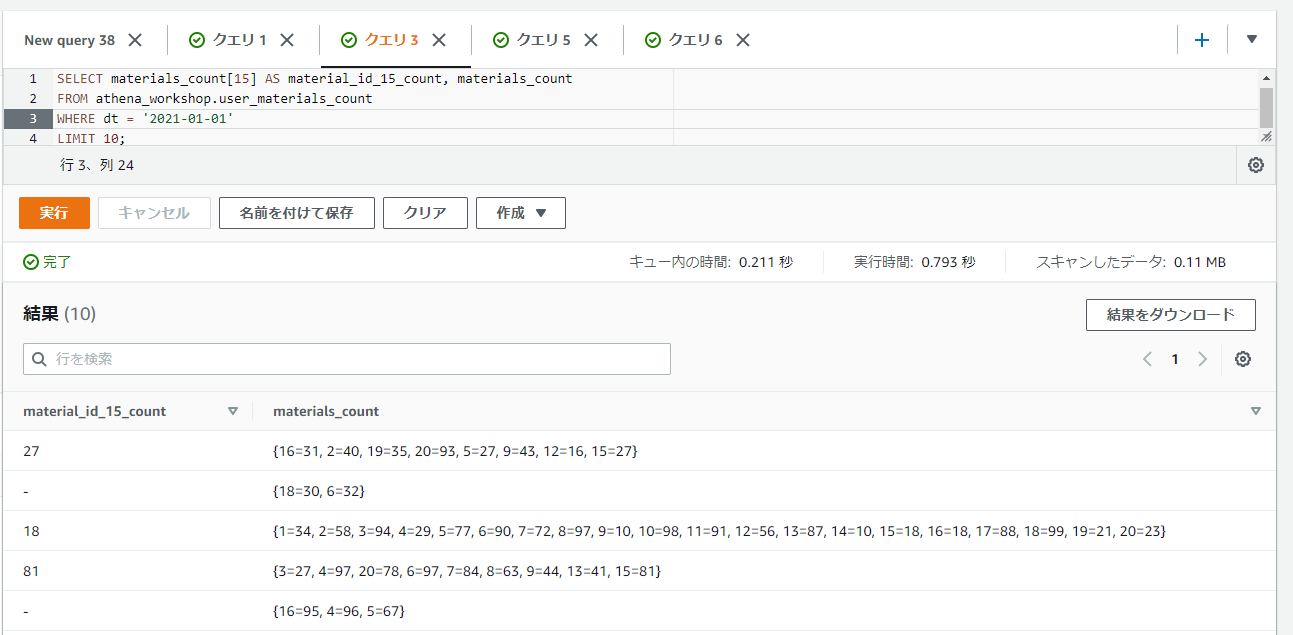
MAPのカラムの特定のキーの値にアクセスする
MAP型はSTRUCT型やROW型のデータとは特定のキー(フィールド)へのアクセスの仕方が変わり、<カラム名>[<キーの値>]といったように[]の括弧を使ってアクセスしていきます。
MAP型はSTRUCTとは異なりキーの値が固定されない(行ごとに様々)ため、指定したキーが存在しない行に関しては表示が-といったようにハイフンになります。
以下のSQLでは[15]といったように指定してキーが15の値を表示しています。
SELECT materials_count[15] AS material_id_15_count, materials_count
FROM athena_workshop.user_materials_count
WHERE dt = '2021-01-01'
LIMIT 10;
ROW型の値の固定値の作り方
ROW型の固定値は()の括弧内にコンマ区切りで値を指定することで作ることができます。
SELECT ('a', 1) AS result_row
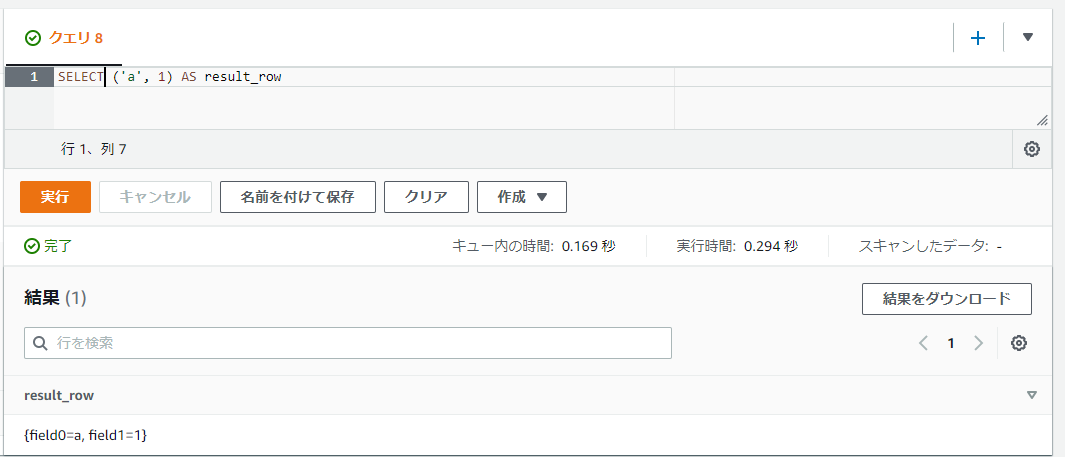
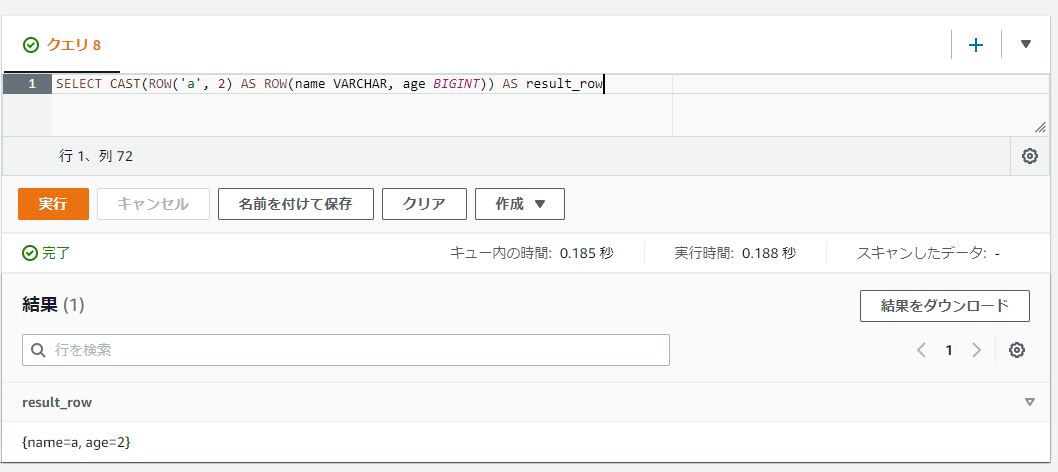
これだけだとフィールド名(キー名)がfield0, field1, ...と割り振られます。もしフィールド名の指定をしたい場合には以下のようにROW関数とCASTによる変換処理を指定することで対応ができます。
SELECT CAST(ROW('a', 2) AS ROW(name VARCHAR, age BIGINT)) AS result_row
MAP型のデータの様々な関数
MAP型に関しては追加でいくつかの関数が用意されています。以降の節ではそれらの各関数について触れていきます。
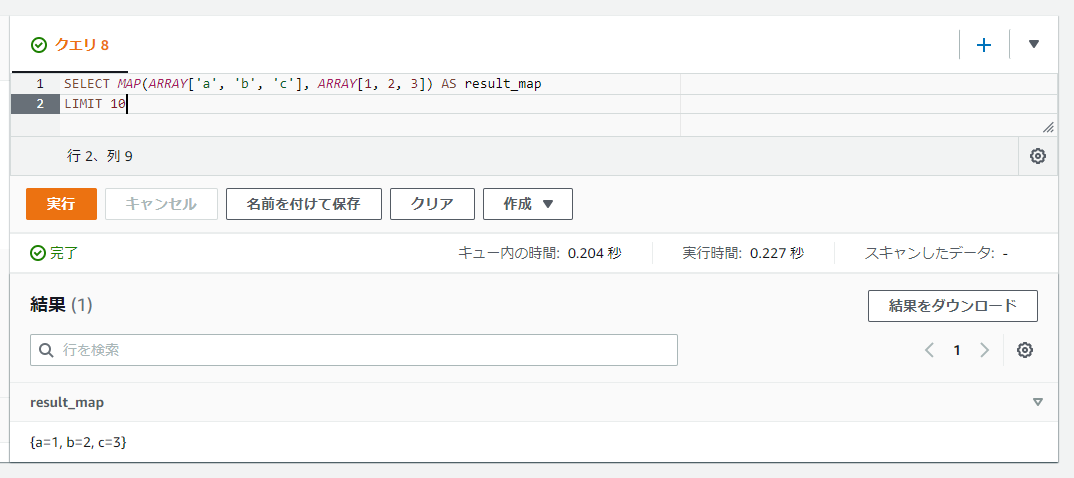
2つの配列からMAPの値を生成する: MAP
MAP関数では2つの配列を渡すことで、それぞれがキーと値として使われる形でMAPの値を取得することができます。
SELECT MAP(ARRAY['a', 'b', 'c'], ARRAY[1, 2, 3]) AS result_map
Pythonでの書き方
ビルトインの辞書の生成処理などはごく基礎的なのでスキップします。
Pandasのシリーズであれば色々書き方はありますが一例として以下のようにしてキーと値のセットを作ることができます。
import pandas as pd
sr: pd.Series = pd.Series(data={'a': 1, 'b': 2, 'c': 3})
print(sr)
a 1
b 2
c 3
dtype: int64
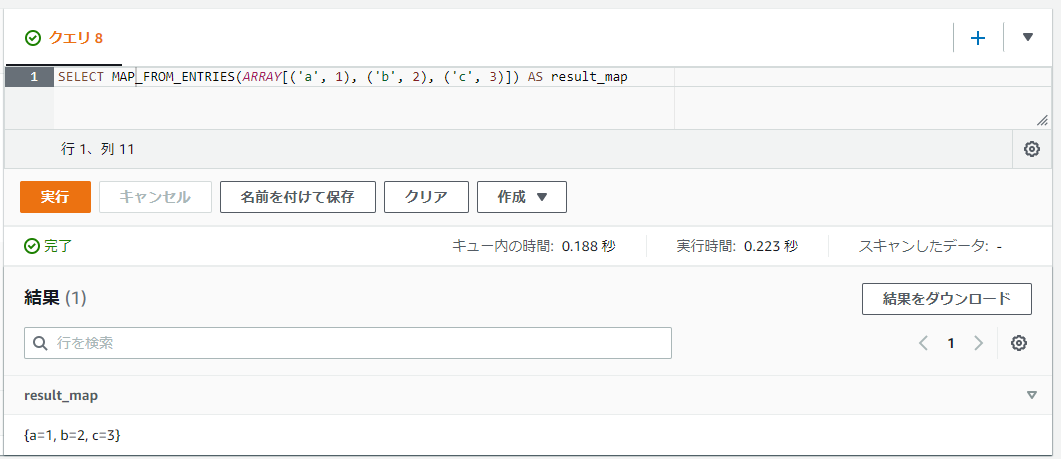
ROW型を格納した配列からMAPの値を生成する: MAP_FROM_ENTRIES
MAP_FROM_ENTRIES関数ではROW型の値を格納した配列からMAPの値を生成します。ROW型の値部分には最初のフィールドにはキー名、2番目の値には値の2件のみを格納した形式が必要になります。
SELECT MAP_FROM_ENTRIES(ARRAY[('a', 1), ('b', 2), ('c', 3)]) AS result_map
値が配列となるMAPの値を生成する: MULTIMAP_FROM_ENTRIES
MULTIMAP_FROM_ENTRIES関数はMAP_FROM_ENTRIES関数と似ていますが、MAPの値が配列になって返ってきます。また、同名のキー名が複数ある場合にも対応しています。
以下のSQLではMAPのaのキーが複数存在する条件を指定しています。
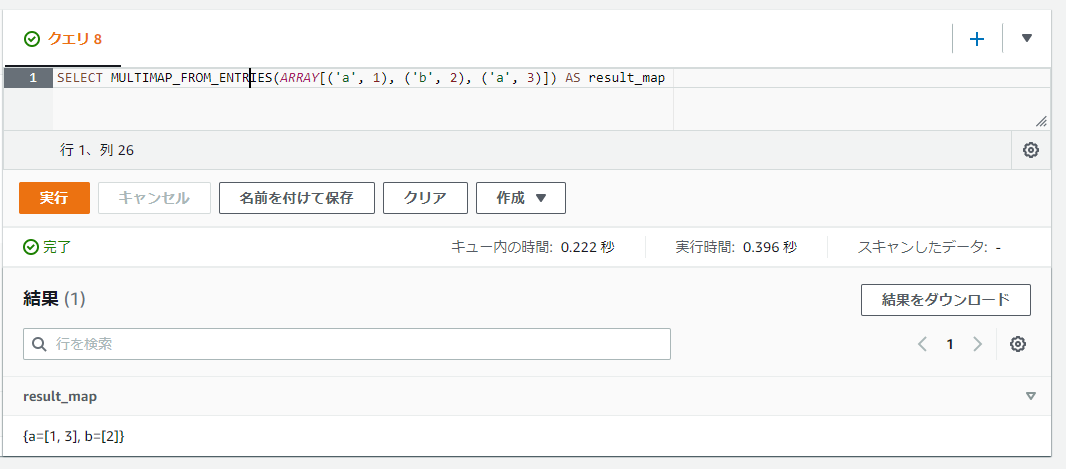
SELECT MULTIMAP_FROM_ENTRIES(ARRAY[('a', 1), ('b', 2), ('a', 3)]) AS result_map
MAPからROW型の値を格納した配列を取得する: MAP_ENTRIES
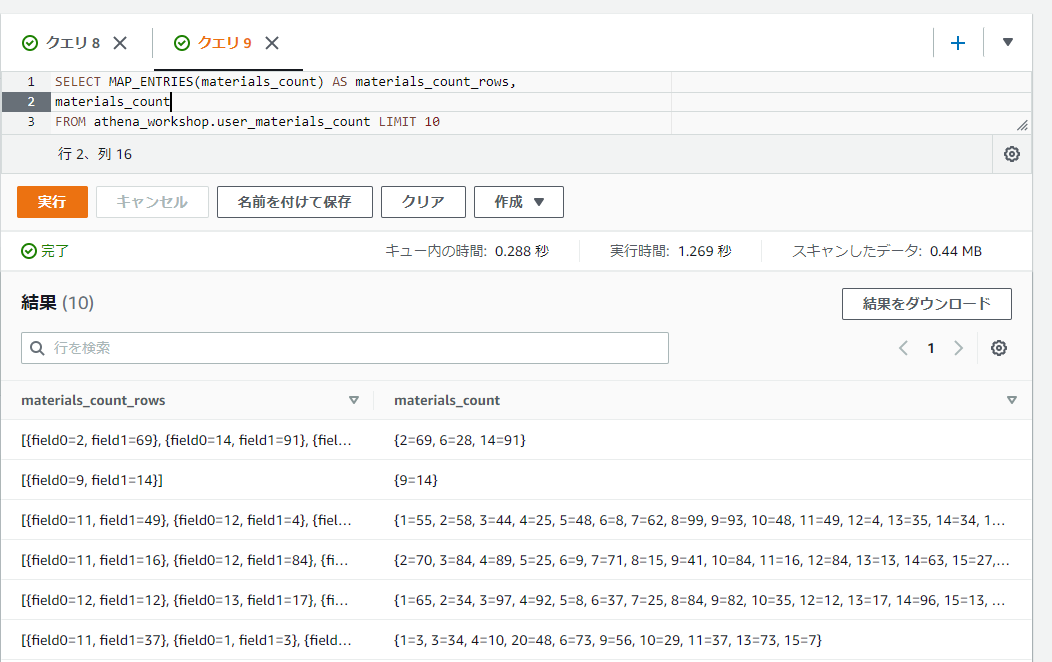
MAP_ENTRIESではMAP_FROM_ENTRIES関数などとは逆にMAPの値からROWの値を格納した配列を取得します。ROWのフィールド名は順番にfield0, field1, ...と設定されていきます。
SELECT MAP_ENTRIES(materials_count) AS materials_count_rows,
materials_count
FROM athena_workshop.user_materials_count LIMIT 10
キーと値のペアの値を作る: MAP_AGG
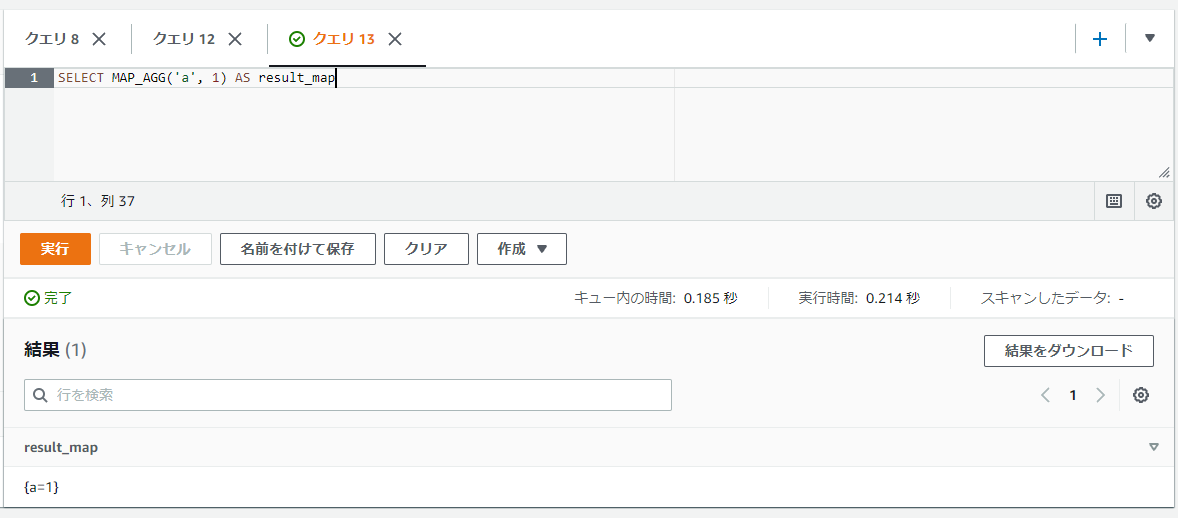
MAP_AGG関数では第一引数にキー、第二引数に値を指定することで単一の値のMAPの値を取得することができます。
SELECT MAP_AGG('a', 1) AS result_map
なお、このMAP_AGG関数ですがデータの縦持ち・横持ちの変換に使われるケースもあります。そちらに関してはリンクを貼っておきます。
特定のキーの値を取得する: ELEMENT_AT
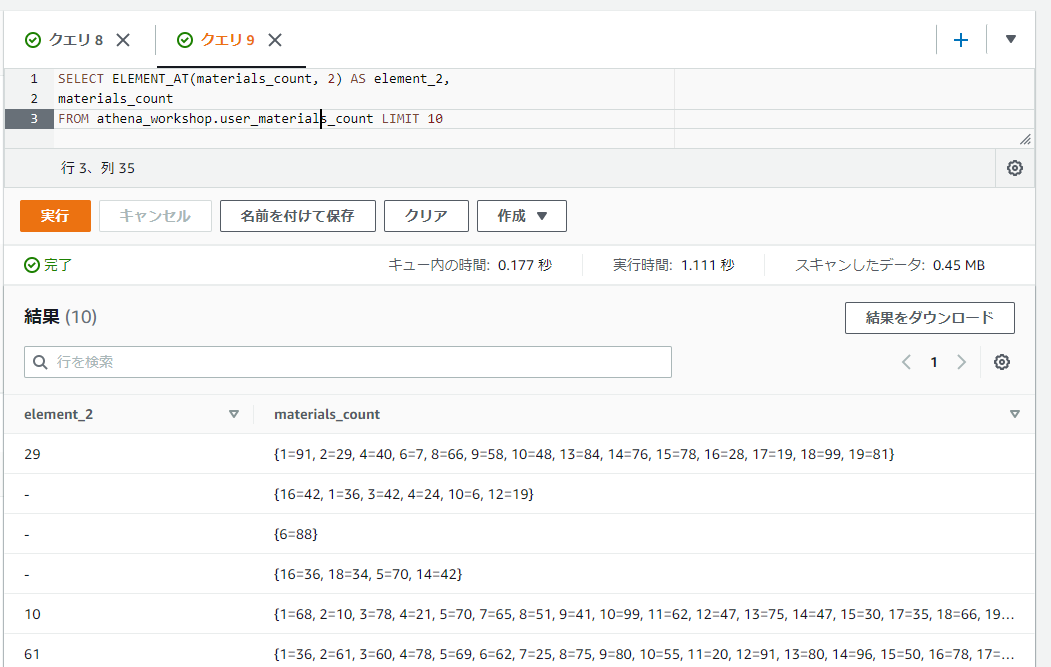
[]による添え字でのアクセスとほぼ同じような挙動をしますが、ELEMENT_AT関数でも特定のキー名の部分のMAPの値を取得することができます。第一引数には対象のMAPのカラムもしくはMAPの固定値、第二引数にはキーを指定します。
SELECT ELEMENT_AT(materials_count, 2) AS element_2,
materials_count
FROM athena_workshop.user_materials_count LIMIT 10
Pythonでの書き方
Pythonのビルトインの辞書では[]の括弧を使うか、もしくは存在しないキーでもエラーにせずにNoneを返却するようにしたければgetメソッドなどを使います。
from typing import Dict, Optional
dict_val: Dict[str, int] = {'a': 1, 'b': 2, 'c': 3}
value: Optional[int] = dict_val.get('b')
print(value)
2
Pandasのシリーズであれば[]の括弧を使います。
import pandas as pd
sr: pd.Series = pd.Series(data={'a': 1, 'b': 2, 'c': 3})
print(sr['b'])
2
データフレームであれば[]の括弧を2個繋げたりilocやloc、atなど色々書き方があります。atを使うと以下のような書き方になります。
import pandas as pd
df: pd.DataFrame = pd.DataFrame(data=[{'a': 1, 'b': 2}, {'a': 3, 'b': 4}])
print(df.at[0, 'a'])
1
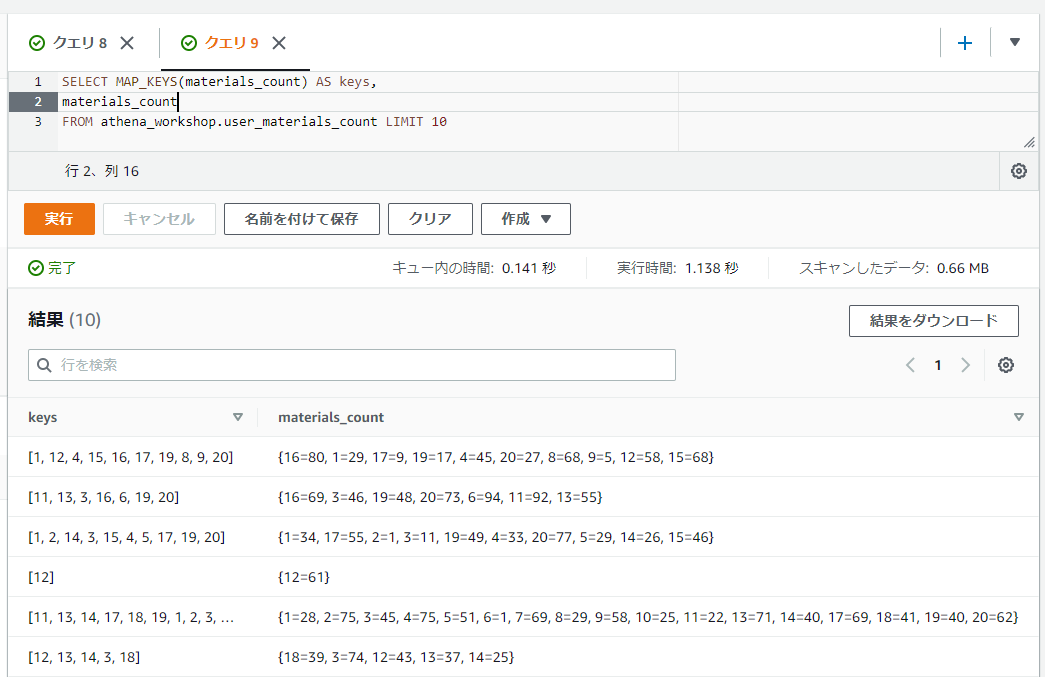
MAPのキーの配列を取得する: MAP_KEYS
MAP_KEYS関数ではMAPの値のキーの値の配列を返却します。なお、元のMAPの値の順番は担保されないようなので注意が必要です。Python3.6や3.7辺りから標準の挙動となった順序付きの辞書的な挙動はしません。
SELECT MAP_KEYS(materials_count) AS keys,
materials_count
FROM athena_workshop.user_materials_count LIMIT 10
Pythonでの書き方
ビルトインの辞書であればkeysメソッドが用意されています。値がリストで欲しい場合はlist関数でキャストします。
from typing import Dict
dict_val: Dict[str, int] = {'a': 1, 'b': 2, 'c': 3}
print(list(dict_val.keys()))
['a', 'b', 'c']
Pandasのシリーズもしくはデータフレームであればindex属性でアクセスができます。
import pandas as pd
sr: pd.Series = pd.Series(data={'a': 1, 'b': 2, 'c': 3})
print(sr.index)
Index(['a', 'b', 'c'], dtype='object')
リストが欲しい場合にはtolistメソッドで変換が効きます。
import pandas as pd
sr: pd.Series = pd.Series(data={'a': 1, 'b': 2, 'c': 3})
print(sr.index.tolist())
['a', 'b', 'c']
MAPの値の配列を取得する: MAP_VALUES
MAP_VALUES関数ではMAPの値の配列を取得することができます。こちらもMAP_KEYS関数と同様に値の順番は担保されない(元のMAPの値と同じにはならない)ので注意が必要です。
SELECT MAP_VALUES(materials_count) AS keys,
materials_count
FROM athena_workshop.user_materials_count LIMIT 10
Pythonでの書き方
ビルトインの辞書の場合はvaluesメソッドで値が取れます。こちらもリストが欲しい場合にはlist関数でキャストする必要があります。
from typing import Dict
dict_val: Dict[str, int] = {'a': 1, 'b': 2, 'c': 3}
print(list(dict_val.values()))
[1, 2, 3]
PandasのシリーズやNumPyのndarrayなどであればvalues属性で取れます。リストが欲しい場合にはtolistメソッドが必要になります。
import pandas as pd
sr: pd.Series = pd.Series(data={'a': 1, 'b': 2, 'c': 3})
print(sr.values.tolist())
[1, 2, 3]
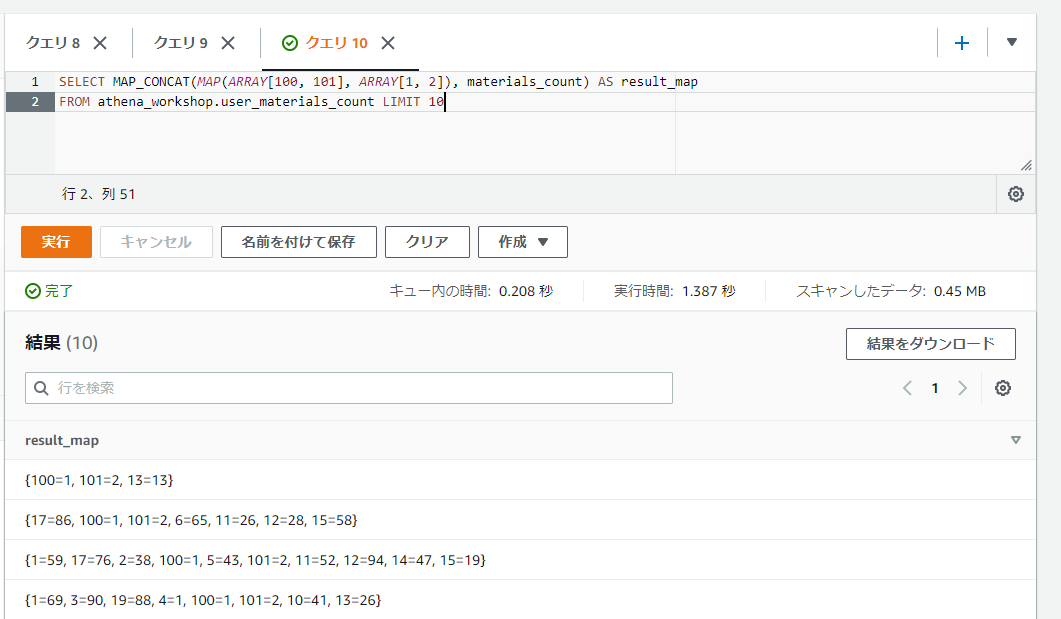
複数のMAPを統合する: MAP_CONCAT
MAP_CONCAT関数は複数のMAPの値を連結します。各引数には各MAPのカラムもしくはMAPの固定値を指定します。
以下のSQLでは第一引数にMAP関数から生成したMAPの固定値(キーに100と101、値に1と2という設定をしてあります)、第二引数にMAPのカラムを指定しています。結果のMAPのキーに100や101が含まれていることが確認できます。
SELECT MAP_CONCAT(MAP(ARRAY[100, 101], ARRAY[1, 2]), materials_count) AS result_map
FROM athena_workshop.user_materials_count LIMIT 10
この関数の引数は可変長なので、第三引数、第四引数・・・と必要に応じてMAPの引数を増やしていくこともできます。
注意点として、以下のようなものがあります。
- キーの順番は担保されません。第一引数のMAPの値が結果のMAPの先に来たりはしません。
- 各引数でキーが被った場合は、後の引数の値によって上書きされます。
- 各MAPのキーと値の型は一致していないとエラーになります。
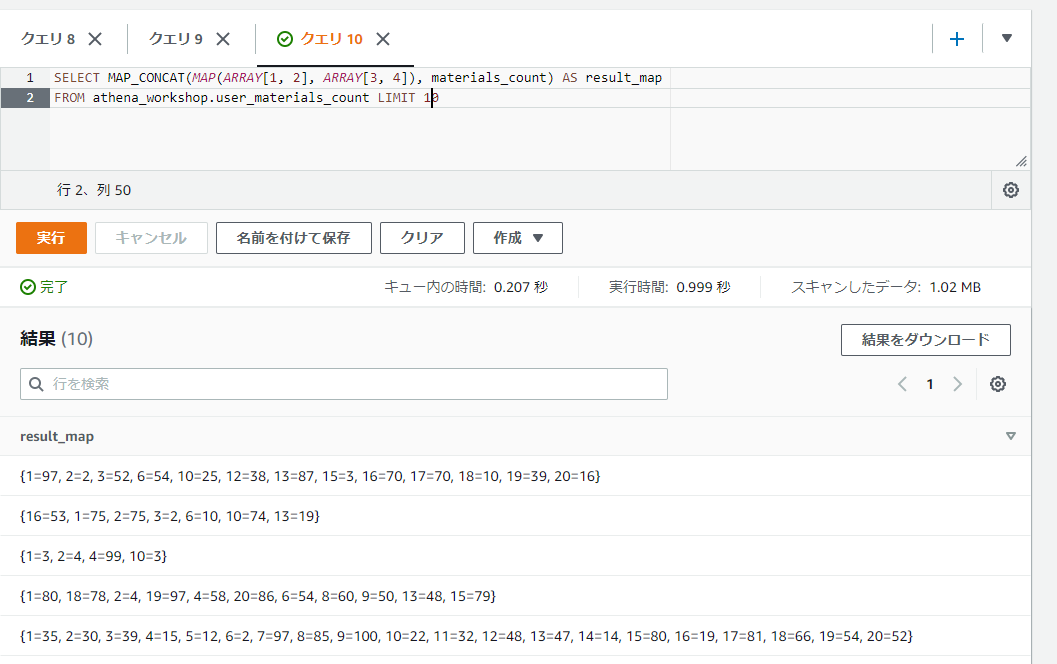
キーが被るケースを少し試してみます。以下のSQLでは第一引数のMAPの固定値のキーを1と2、値を3と4としています。
SELECT MAP_CONCAT(MAP(ARRAY[1, 2], ARRAY[3, 4]), materials_count) AS result_map
FROM athena_workshop.user_materials_count LIMIT 10
1と2というキーは第二引数のカラムでも持っていることが多いので、1=97とか1=75といったように第二引数の値で上書きされて第一引数の値は消えていることが確認できます。
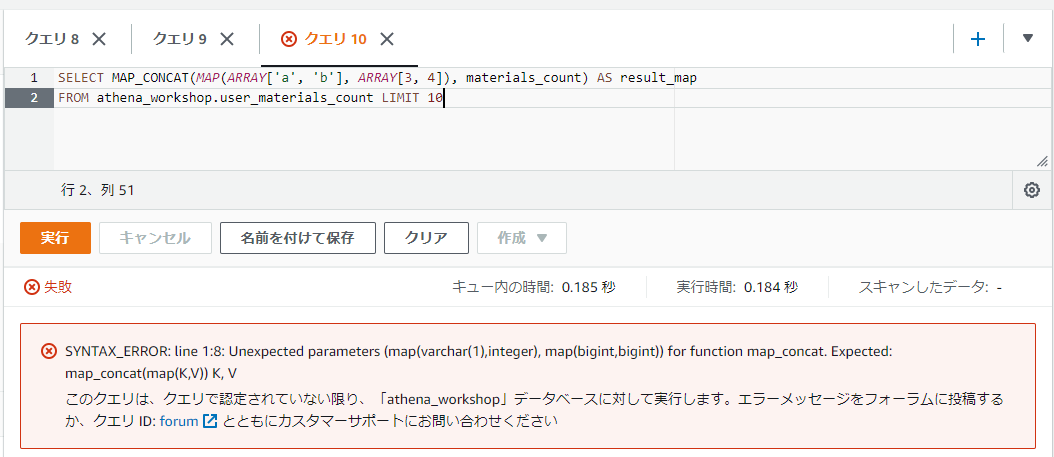
また、各引数でMAPの型が一致していないケースを試してみます。materials_countカラムはmap<bigint, bigint>の型を持つため、第一引数はmap<string, bigint>の型で試してみます。
SELECT MAP_CONCAT(MAP(ARRAY['a', 'b'], ARRAY[3, 4]), materials_count) AS result_map
FROM athena_workshop.user_materials_count LIMIT 10
実行してみると以下のようにエラーとなります。
Pythonでの書き方
ビルトインの辞書であればupdateメソッドで別の辞書の値を加えることができます。こちらもキーが重複している場合には引数で指定された辞書の方の値が優先されます。
from typing import Dict
dict_val_1: Dict[str, int] = {'a': 1, 'b': 2, 'c': 3}
dict_val_2: Dict[str, int] = {'c': 4, 'd': 5}
dict_val_1.update(dict_val_2)
print(dict_val_1)
{'a': 1, 'b': 2, 'c': 4, 'd': 5}
Pandasのシリーズなどであればconcat関数などで複数のシリーズ(やデータフレーム)を統合することができます。ちなみにシリーズやデータフレームは同じインデックスを複数持つことができるので、Athena(Presto)やビルトインの辞書と異なりインデックスが被った場合でもそれぞれの値が残ります(以下のコードではcというキーの値が2つ残っています)。
import pandas as pd
sr_1: pd.Series = pd.Series(data={'a': 1, 'b': 2, 'c': 3})
sr_2: pd.Series = pd.Series(data={'c': 4, 'd': 5})
result_sr: pd.Series = pd.concat([sr_1, sr_2])
print(result_sr)
a 1
b 2
c 3
c 4
d 5
dtype: int64
MAPの値を特定条件でフィルタリングする: MAP_FILTER
MAP_FILTER関数はMAPのキーと値をラムダ式で参照して、条件を満たすもののに結果のMAPに残すという挙動をします。
ラムダ式に関しては以前の記事で触れたので詳しい書き方などはそちらをご確認ください。
ラムダ式の引数にはキーと値の2つが渡されます。この記事ではキーの引数名をk、値の引数名をvとして扱っていきます。
返却値は真偽値で設定し、trueであれば結果に残りfalseであれば結果から除外されます。
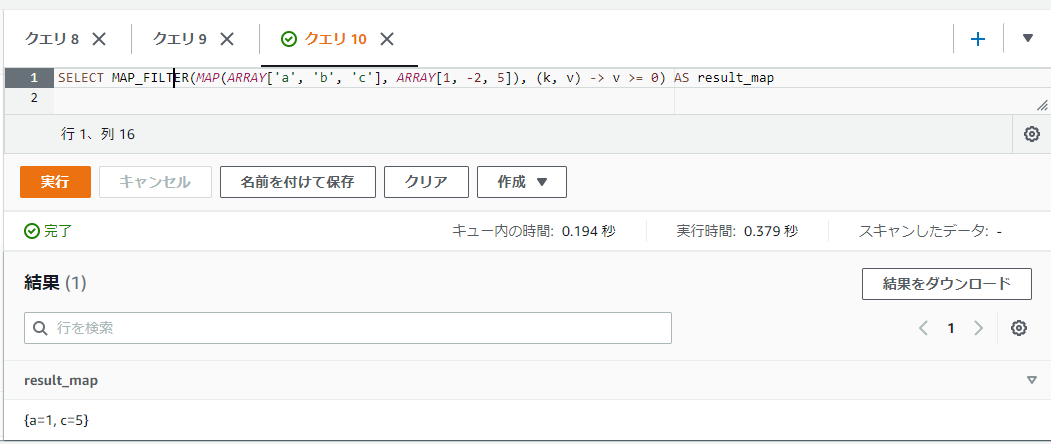
以下のSQLでは1, -2, 5という3つの値を持っているMAPに対して、値が0以上(v >= 0)の値のみ結果のMAPに残しています。
SELECT MAP_FILTER(MAP(ARRAY['a', 'b', 'c'], ARRAY[1, -2, 5]), (k, v) -> v >= 0) AS result_map
Pythonでの書き方
ビルトインの辞書であればループを回すか、filter関数とラムダ式などを組み合わせるか、もしくは内包記法などを使うかといった方法があります。
filter関数は以下のような内容になっています。
filterは第1引数に与えられた関数を第2引数で与えられたシーケンス1つ1つに適応し、Trueになったシーケンスのみを返す関数です。
【Python】dictをfilterする
from typing import Dict
dict_val: Dict[str, int] = {'a': 1, 'b': -2, 'c': 5}
dict_val = dict(filter(lambda item: item[1] >= 0, dict_val.items()))
print(dict_val)
{'a': 1, 'c': 5}
キーに調整を加える: TRANSFORM_KEYS
TRANSFORM_KEYS関数はラムダ式を使って各キーを調整したMAPのデータを取得することができます。第一引数にはMAPのカラムもしくはMAPの固定値、第二引数にはラムダ式を指定します。
ラムダ式の引数にはキー(k)と値(v)の2つの引数を受け付け、返却値にはキーの値の1つの値が必要になります。
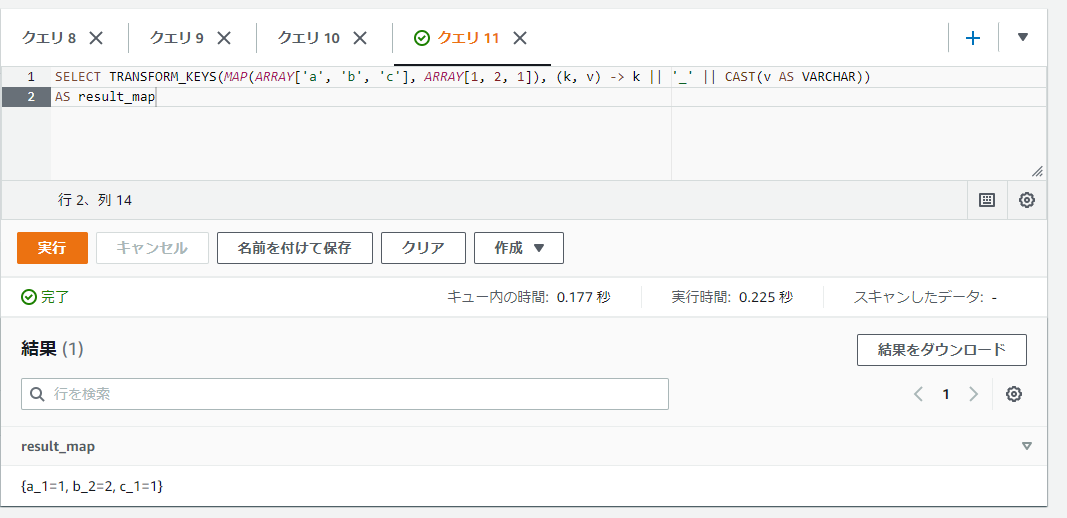
以下のSQLではキー名をキー_値といったようにアンダースコアを挟んでキーと値を連結しています(結果のキーはa_1とかc_1などになります)。
SELECT TRANSFORM_KEYS(MAP(ARRAY['a', 'b', 'c'], ARRAY[1, 2, 1]), (k, v) -> k || '_' || CAST(v AS VARCHAR))
AS result_map
Pythonでの書き方
色々書き方があると思いますが、ビルトインの辞書であれば内包記法とかがシンプルかもしれません。
from typing import Dict
dict_val: Dict[str, int] = {'a': 1, 'b': 2, 'c': 1}
renamed_dict_val: Dict[str, int] = {
f'{k}_{v}': v for k, v in dict_val.items()}
print(renamed_dict_val)
{'a_1': 1, 'b_2': 2, 'c_1': 1}
※f-stringsとかも使っています。
値に調整を加える: TRANSFORM_VALUES
TRANSFORM_VALUES関数はTRANSFORM_KEYS関数の値版です。値に対してラムダ式を反映したMAPを取得します。
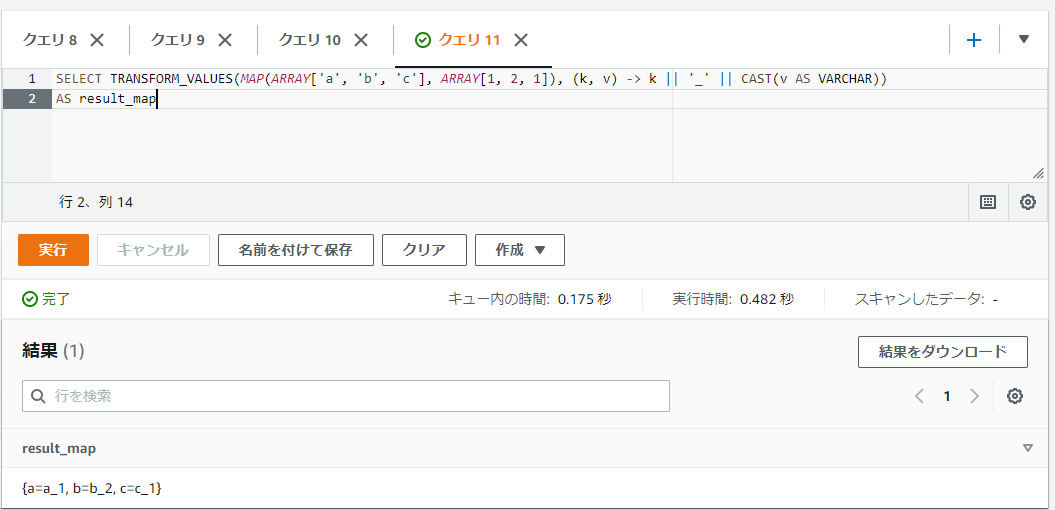
以下のSQLはTRANSFORM_KEYSの時とほぼ同じ内容ですが、結果は値の方がa_1とかになっていることを確認できます。
SELECT TRANSFORM_VALUES(MAP(ARRAY['a', 'b', 'c'], ARRAY[1, 2, 1]), (k, v) -> k || '_' || CAST(v AS VARCHAR))
AS result_map
Pythonでの書き方
キーの時とほぼ同じで内包記法で対応しています。
from typing import Dict
dict_val: Dict[str, int] = {'a': 1, 'b': 2, 'c': 1}
result_dict_val: Dict[str, str] = {
k: f'{k}_{v}' for k, v in dict_val.items()}
print(result_dict_val)
{'a': 'a_1', 'b': 'b_2', 'c': 'c_1'}
2つのMAPに対して同じキーの値同士で計算を行う: MAP_ZIP_WITH
MAP_ZIP_WITH関数は2つのMAPの値に対して、同じキーを持つ値同士で処理を行うことができます。結果もMAPの値となります。
第一引数には1つ目のMAPのカラムもしくはMAPの固定値、第二引数には2つ目のMAPのカラムもしくはMAPの固定値、第三引数にはラムダ式が必要になります。
ラムダ式にはキー名(k)、1つ目のMAPの該当のキーの値(v1)、2つ目のMAPの該当のキーの値(v2)が渡され、返却値としてはMAPの値として1つの値が必要になります。
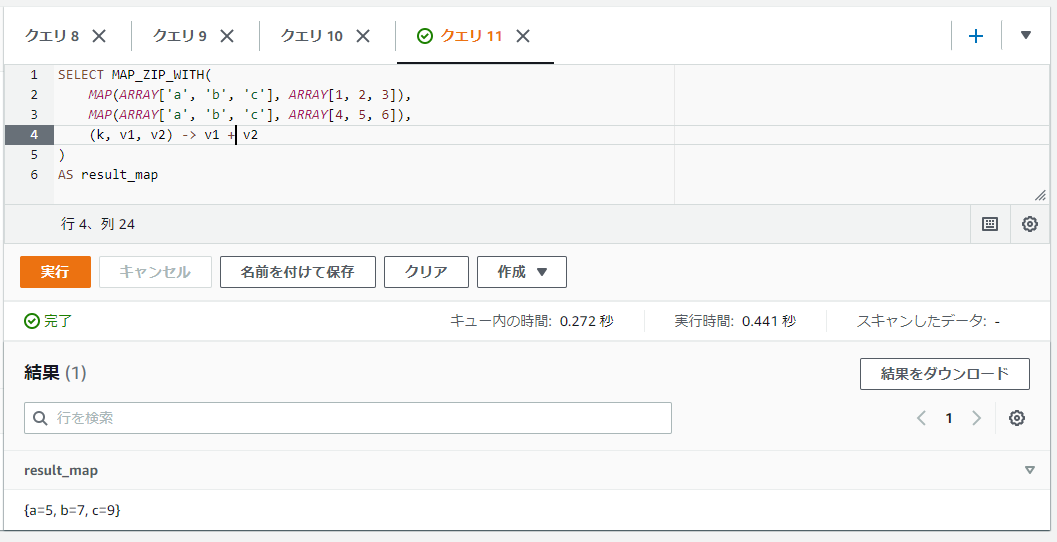
以下のSQLでは2つのMAPの値に対して、各値を合算したMAPをMAP_ZIP_WITH関数を使って取得しています。
SELECT MAP_ZIP_WITH(
MAP(ARRAY['a', 'b', 'c'], ARRAY[1, 2, 3]),
MAP(ARRAY['a', 'b', 'c'], ARRAY[4, 5, 6]),
(k, v1, v2) -> v1 + v2
)
AS result_map
なお、片方にしか無いキーが存在するとそちらの値はNULLになるので注意が必要です(欠損値の制御が必要になります)。
Pythonでの書き方
色々書き方がありますが、ビルトインの辞書であれば一例として以下のコードでは一旦辞書のkeysメソッドやset関数などを使って2つの辞書の一意なキーの配列を取得して、それを使って内包記法(もしくは普通のループを回す形でも良いと思います)で処理をしています。
from typing import Dict, List
dict_val_1: Dict[str, int] = {'a': 1, 'b': 2, 'c': 3}
dict_val_2: Dict[str, int] = {'a': 4, 'b': 5, 'c': 6}
keys: List[str] = list(set([*dict_val_1.keys(), *dict_val_2.keys()]))
result_dict: Dict[str, int] = {k: dict_val_1[k] + dict_val_2[k] for k in keys}
print(result_dict)
{'a': 5, 'b': 7, 'c': 9}
MAPのデータのカーディナリティのサイズを取得する: CARDINALITY
CARDINALITY関数ではカーディナリティのサイズを取得できます。カーディナリティってなんだ・・・という感じですが、MAP内で異なる値が多い(バリエーションが豊富)な行ほどサイズが大きくなる・・・という値のようです。
カーディナリティとは、数学で基数あるいは濃度という意味の用語。ITの分野では、リレーショナルデータベースにおいてあるテーブルの同一の列(カラム)に含まれる異なる値の数(バリエーション)のことを指すことが多い。
カーディナリティ 【cardinality】
引数は第一引数のMAPのカラムもしくはMAPの固定値のみです。
SELECT CARDINALITY(materials_count) AS cardinality_size, materials_count
FROM athena_workshop.user_materials_count
LIMIT 10
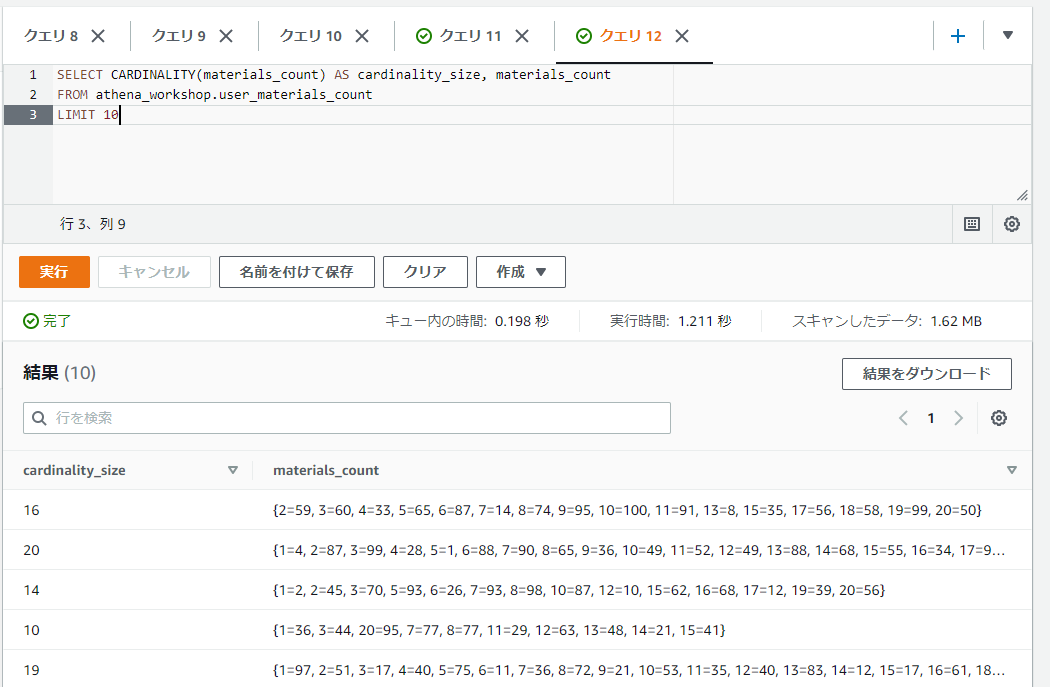
MAPの値を行列に変換する
MAPの値をキーと値で各列に展開し、行列として扱うと便利なことがあります。そういった場合はUNNESTを使うと行列に変換できます。
以前の配列の以下の記事で詳しく触れましたが、書き方としてはFROM <対象テーブル>, UNNEST(対象テーブルのMAPのカラム) AS <展開後のテーブル名>(展開後のキー名, 展開後のカラム名)となります。
配列の時と比べてASの後の()の括弧内がキーと値で2つ必要になっている点には注意が必要です。また、配列の記事で書きましたがその後のデータでさらに連結など色々と操作をする場合CROSS JOINを一緒に使ってUNNESTする必要があるケースもあります。詳しくはリンク先をご確認ください。
以下のSQLではMAPの値を行列に展開しています。キーはmaterials_id, 値はcountという名前にしています。
SELECT user_id, materials_id, count, materials_count
FROM athena_workshop.user_materials_count, UNNEST(athena_workshop.user_materials_count.materials_count)
AS unnested_table(materials_id, count)
LIMIT 100
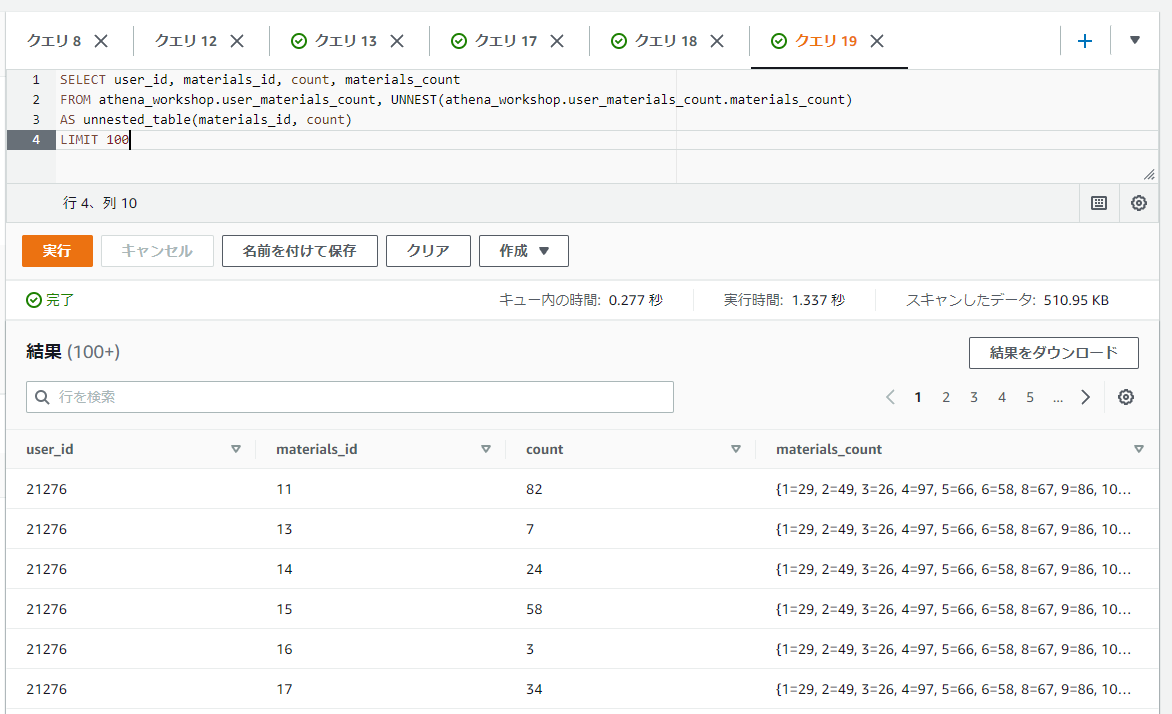
STUCTの値を行列に変換する
1次元のSTRUCTの場合はSELECT結果はROW型となるため、そのままダイレクトに使うキーの値をドットで繋いで展開すれば行列として扱えます。
SELECT
self_status.user_id AS self_user_id,
self_status.attack AS self_attack,
self_status.defence AS self_defence
FROM athena_workshop.user_pvp_status
LIMIT 100
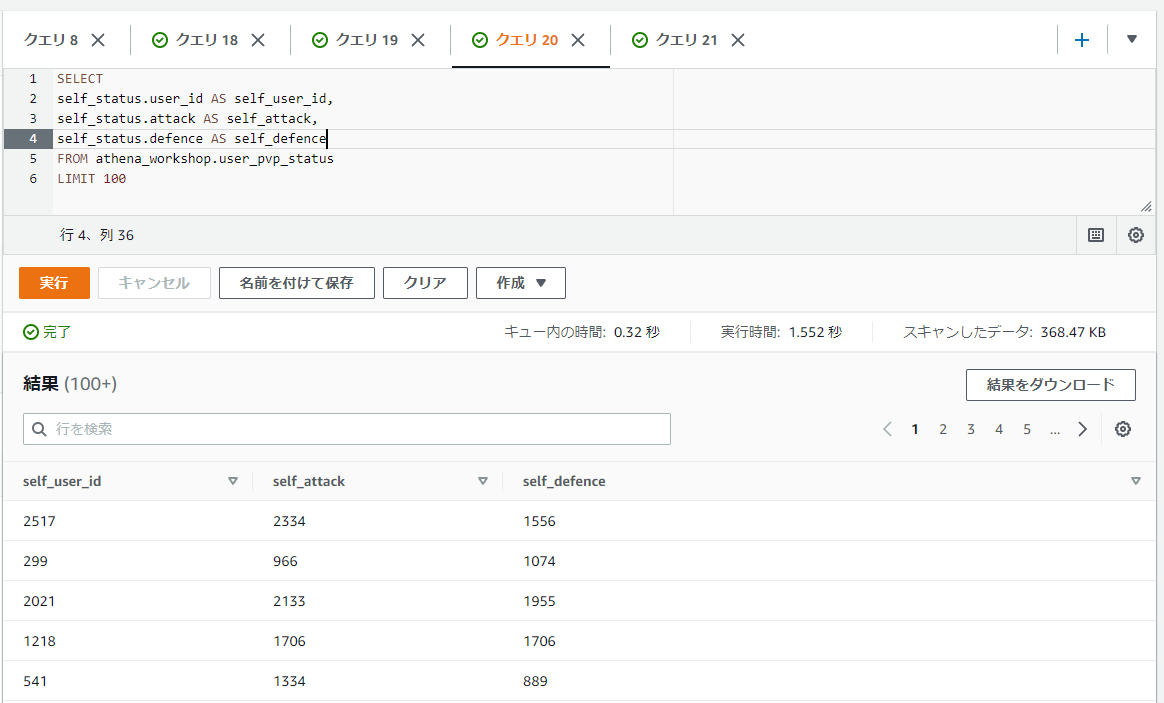
STRUCTを格納した配列を行列に変換する
STRUCT型の辞書を格納した配列といった具合に2次元でデータが格納されているケースもよくあります。そういったデータを行列に変換してみます。
まず配列に対しては以下の過去の記事で触れたようにUNNESTで展開できます。
SELECT user_id, weapon, weapons
FROM athena_workshop.user_weapon, UNNEST(athena_workshop.user_weapon.weapons) AS unnested_weapons(weapon)
LIMIT 100;
展開後はROW型で{mst_id=360, attack=1092, level=9}といったような値で1次元になっていることが確認できます。
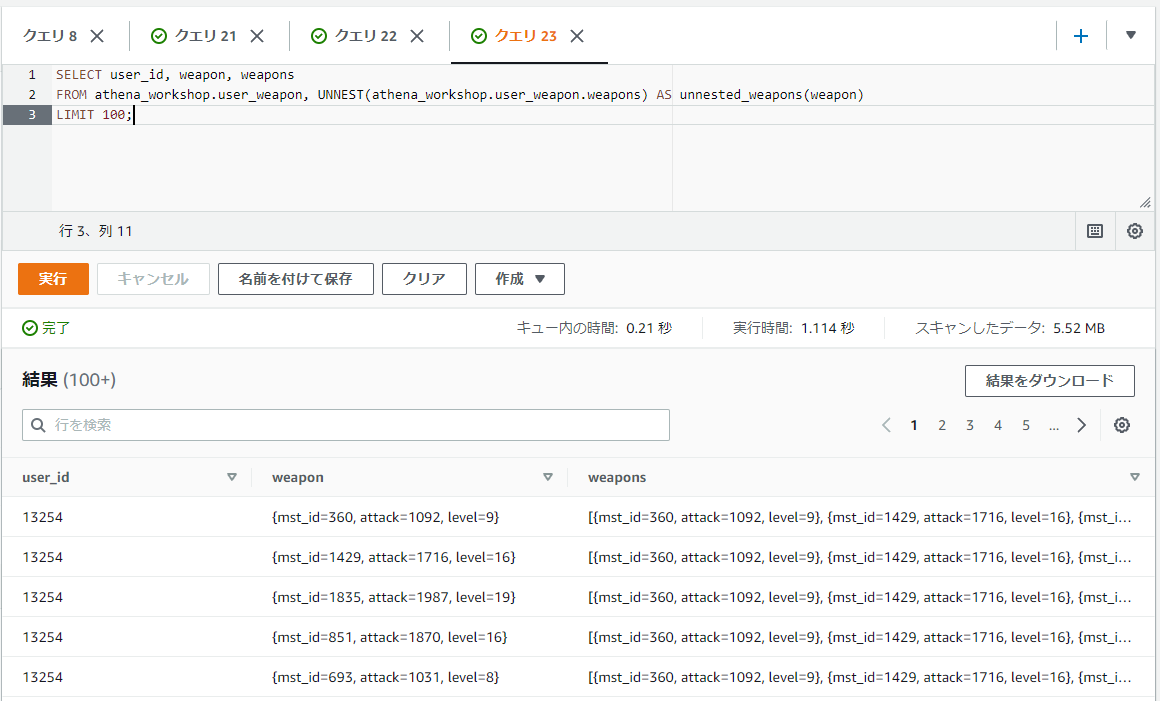
あとはSTRUCTの行列変換の節で触れたような形で必要な各キーをSELECT句の部分に指定すれば行列に展開できます。
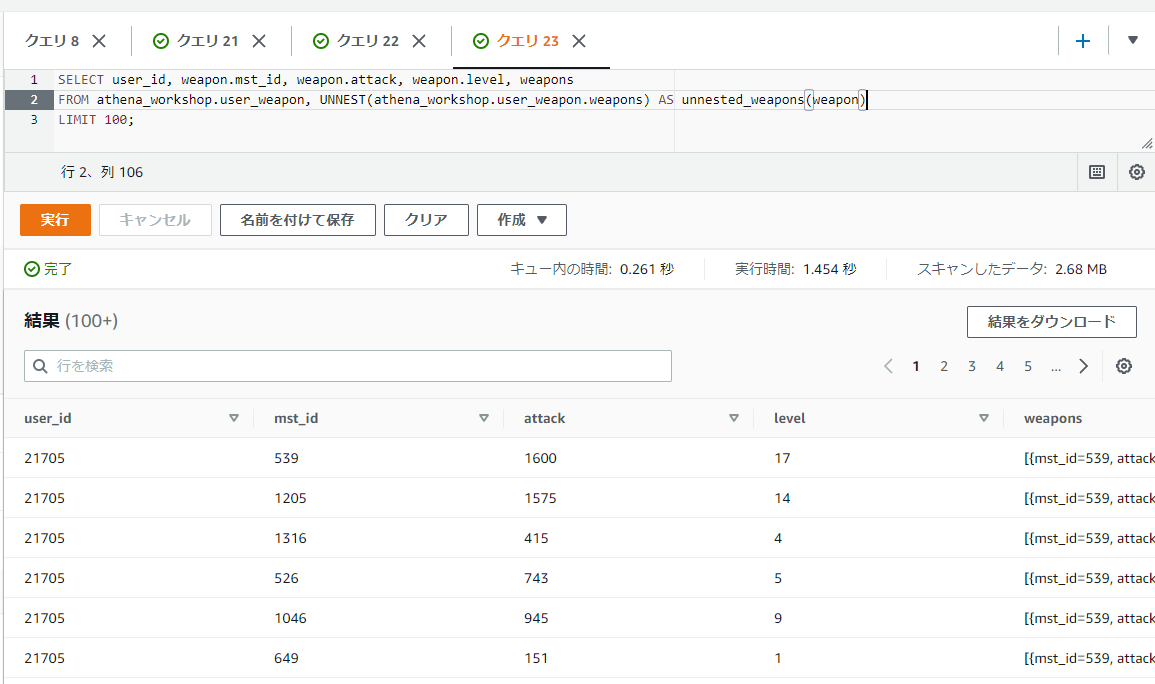
SELECT user_id, weapon.mst_id, weapon.attack, weapon.level, weapons
FROM athena_workshop.user_weapon, UNNEST(athena_workshop.user_weapon.weapons) AS unnested_weapons(weapon)
LIMIT 100;
Pythonでの書き方
他の行列変換の処理も同様なのですが、この手の変換は以前記事を書いたのでそちらをご確認ください。
JSONのデータを扱う
ログによっては配列などではなくJSON形式の文字列で入っている・・・といったケースなどがあります。この節以降ではそういったJSONデータに対して触れていきます。
値をJSONへ変換する
JSONへは真偽値・整数値・文字列(VARCHAR)・配列・辞書(MAPもしくはROW)や欠損値(NULL)の値を変換できます。配列などで入れ子にする場合には内部に格納する値もこれらの値である必要があります。
また、MAPの辞書などであればキーは文字列になっている必要があります(整数とかになっていると文字列に変換されます)。配列に関しても複数の型を格納していると変換がうまくいきません(例えば文字列と整数が混在している配列など)。それらは事前に型変換などをかけておく必要があります。
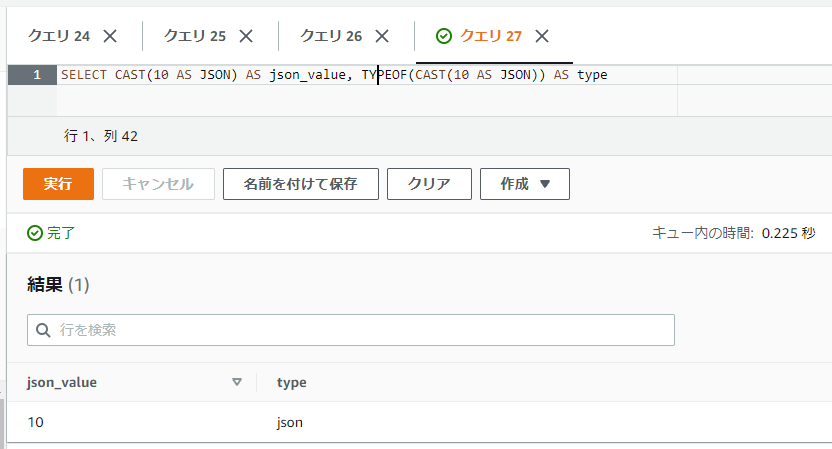
変換処理はCAST関数で行うことができます。CASTのAS部分にはJSONと指定します。表示上はTYPEOFなどで型を表示しない限り違いが分かりづらいですが、TYPEOF関数などで表示される型はJSONとなります。
SELECT CAST(10 AS JSON) AS json_value, TYPEOF(CAST(10 AS JSON)) AS type
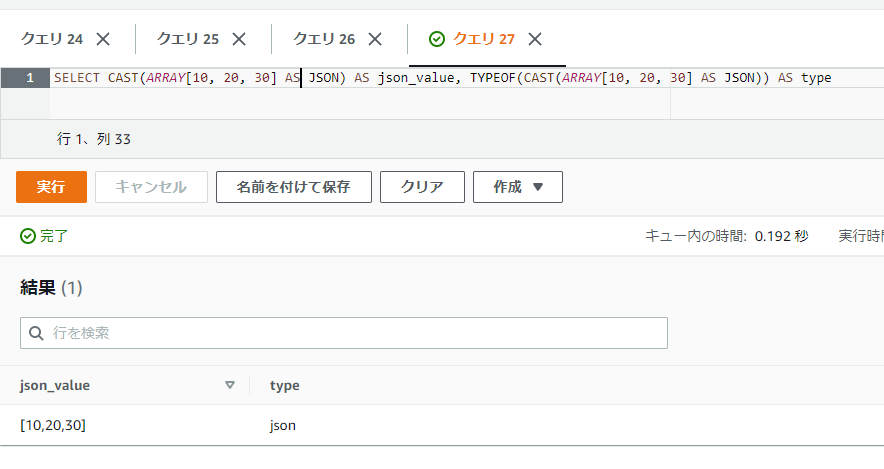
SELECT CAST(ARRAY[10, 20, 30] AS JSON) AS json_value, TYPEOF(CAST(ARRAY[10, 20, 30] AS JSON)) AS type
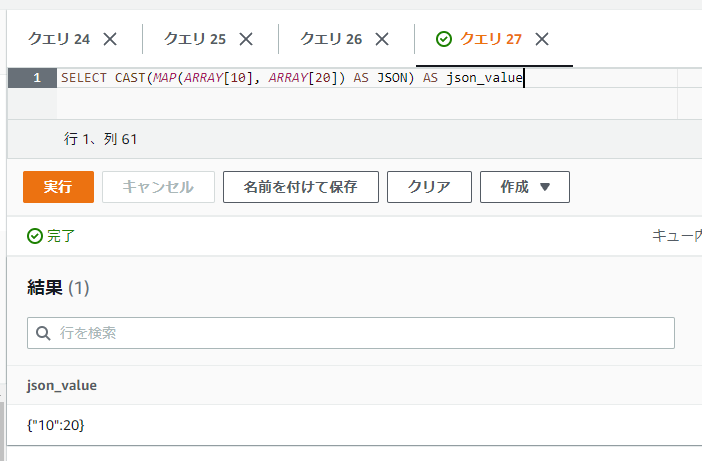
キーが整数のMAPを指定してみると、キーにダブルクォーテーションが追加されていることから分かるようにキーが文字列に変換されることが分かります(エラーにはなりません)。
SELECT CAST(MAP(ARRAY[10], ARRAY[20]) AS JSON) AS json_value
配列に複数の型が含まれている場合、例えば整数と文字列が含まれている場合などには変換しようとしてもエラーになります。
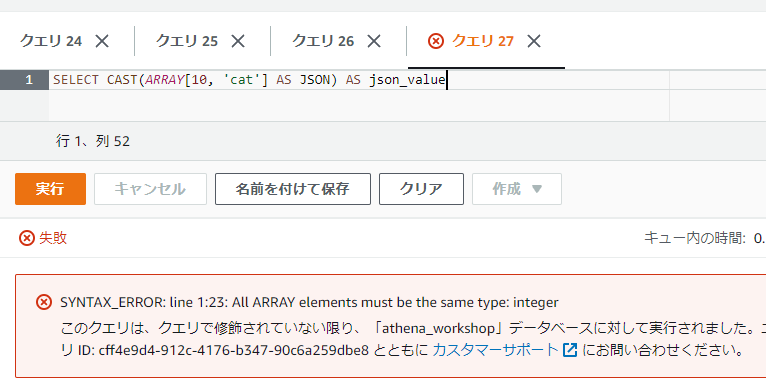
SELECT CAST(ARRAY[10, 'cat'] AS JSON) AS json_value
※JSON形式の文字列をJSONに変換する・・・という場合はCASTによる変換ではなく後述するJSON_PARSEを使う必要があります。CASTでそういった文字列に対して処理を反映すると単純にその文字列のJSONの単一値となり、階層構造などは展開されません。
JSONから別の型に値を変換する
こちらもCAST関数で任意のJSONからの変換がサポートされている型であれば変換ができます(CAST(<JSONの値> AS <変換したい型>)といった具合に指定します)。
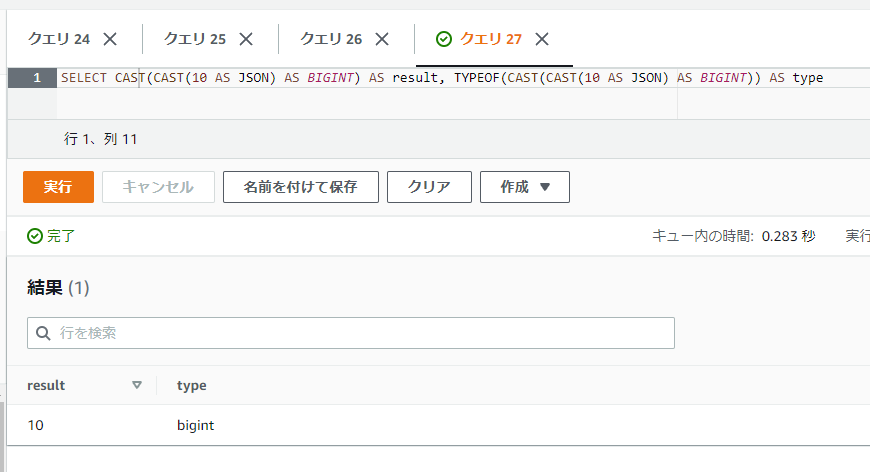
SELECT CAST(CAST(10 AS JSON) AS BIGINT) AS result, TYPEOF(CAST(CAST(10 AS JSON) AS BIGINT)) AS type
JSONの文字列をJSON型に変換する: JSON_PARSE
JSONの文字列をJSON型に変換したい場合JSON_PARSEを使います。第一引数に対象のJSONの文字列のカラムを指定します。
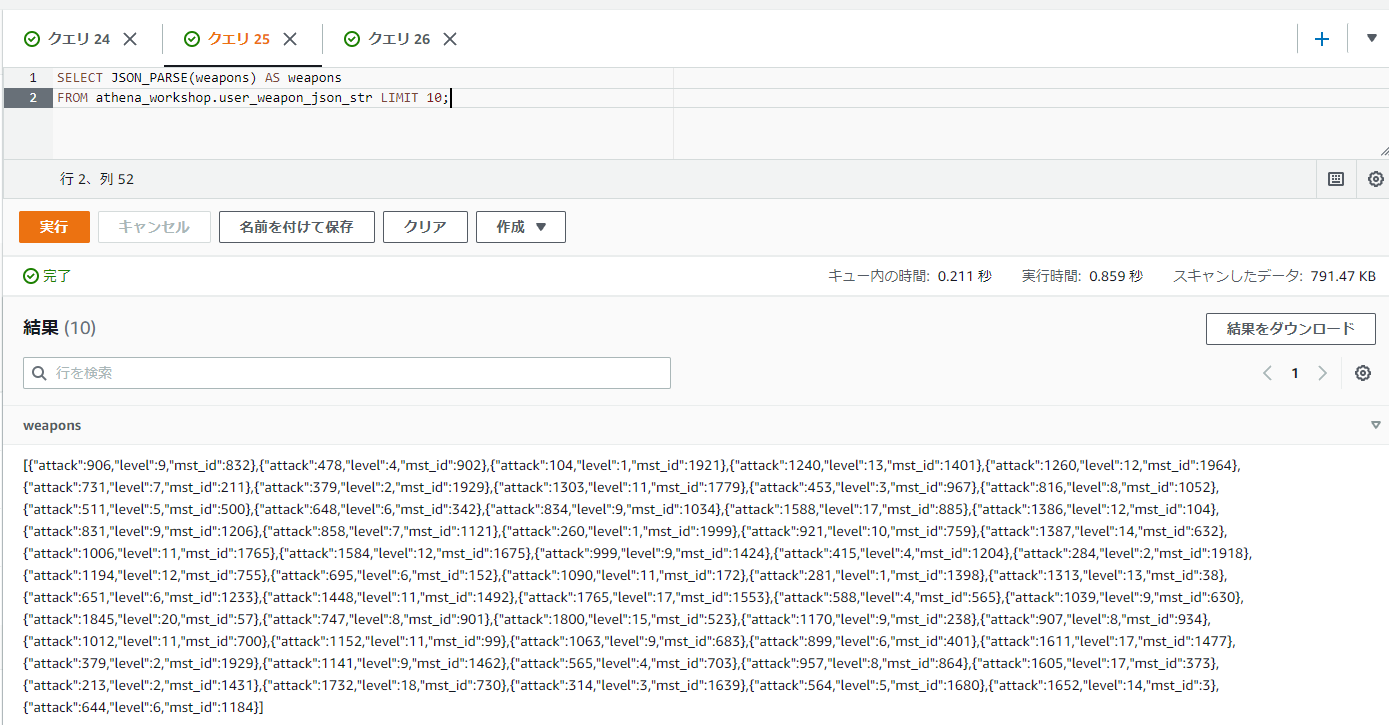
SELECT JSON_PARSE(weapons) AS weapons
FROM athena_workshop.user_weapon_json_str LIMIT 10;
結果はSTRUCTなどと異なりROW型のような表記にはならずにJSONの表示そのままになります。
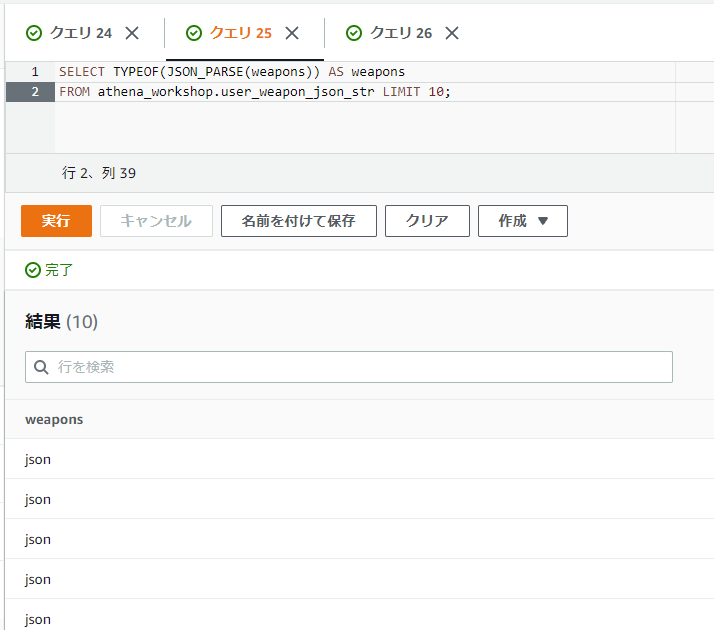
TYPEOFで型を見てみると確かにVARCHARなどではなくJSONの型になっています。
SELECT TYPEOF(JSON_PARSE(weapons)) AS weapons
FROM athena_workshop.user_weapon_json_str LIMIT 10;
Pythonでの書き方
jsonモジュールのloads関数でJSON形式の文字列をPythonのデータ(辞書など)に変換できます。
import json
from typing import Dict
dict_val: Dict[str, int] = json.loads('{"a": 10, "b": 20}')
print(dict_val)
{'a': 10, 'b': 20}
PandasなどでそういったJSON形式の文字列のが含まれている場合には、データフレームなどでのapplyメソッドでloads関数を指定すれば対応ができます。
import json
import pandas as pd
df: pd.DataFrame = pd.read_json(
'https://github.com/simon-ritchie/athena_workshop/blob/main/workshop/user_weapon_json_str/dt%3D2021-01-01/data.json.gz?raw=true',
lines=True, orient='records', compression='gzip')
df['weapons'] = df['weapons'].apply(json.loads)
print(df.head())
print('type:', type(df.at[0, 'weapons']))
user_id date device_type weapons
0 23475 2021-01-01 2 [{'mst_id': 1700, 'attack': 300, 'level': 2}, ...
1 23826 2021-01-01 2 [{'mst_id': 1672, 'attack': 1709, 'level': 15}...
2 2496 2021-01-01 2 [{'mst_id': 655, 'attack': 1238, 'level': 12},...
3 1192 2021-01-01 1 [{'mst_id': 56, 'attack': 871, 'level': 6}, {'...
4 26195 2021-01-01 1 [{'mst_id': 1427, 'attack': 836, 'level': 9}, ...
type: <class 'list'>
JSONの値をJSONの文字列に変換する: JSON_FORMAT
JSON_FORMAT関数はJSONの値をJSON形式の文字列へと変換します。JSON_PARSE関数と逆の挙動をします。
SELECT JSON_FORMAT(CAST(weapons AS JSON)) AS json_str,
TYPEOF(JSON_FORMAT(CAST(weapons AS JSON))) AS type
FROM athena_workshop.user_weapon
LIMIT 10;
実行結果の型がVARCHARになっていることが確認できます。
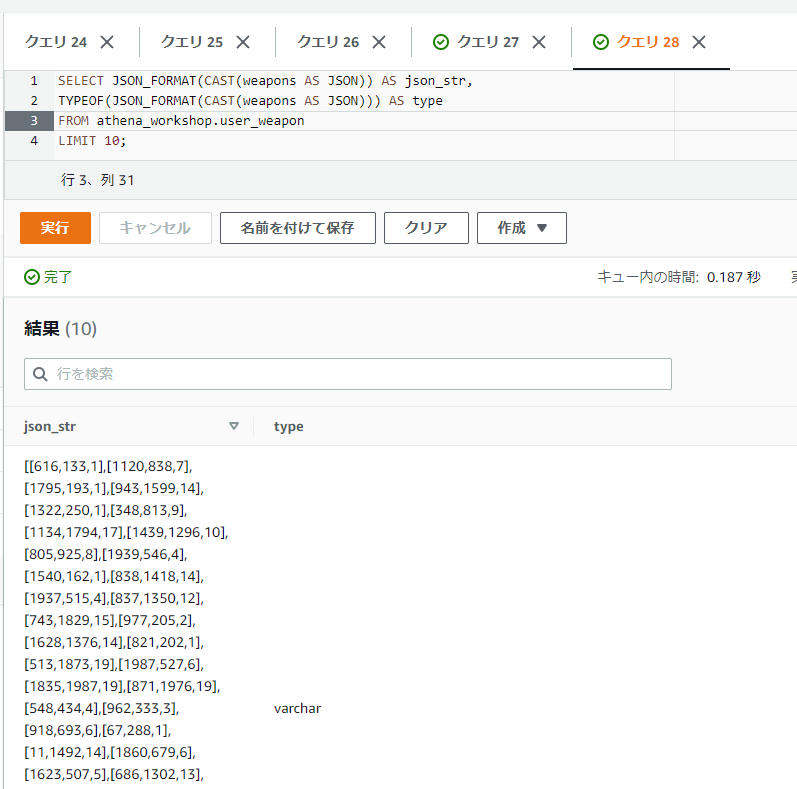
※CASTで文字列に変換しただけだと正確なJSONのフォーマットにならないケースが結構ある(JSONに合わせたフォーマットではなくSQLに合わせたフォーマットになったりする)ため、その辺りでエラーなどを避けるためにもCASTではなくJSON_FORMAT関数の利用が推奨されます。
JSONの値を配列に変換する
JSON_PARSEでJSON型にした値は前節までで触れたようにCAST関数で他の型に変換することができます。今回のJSONは配列になっているため配列にキャストしてみます。
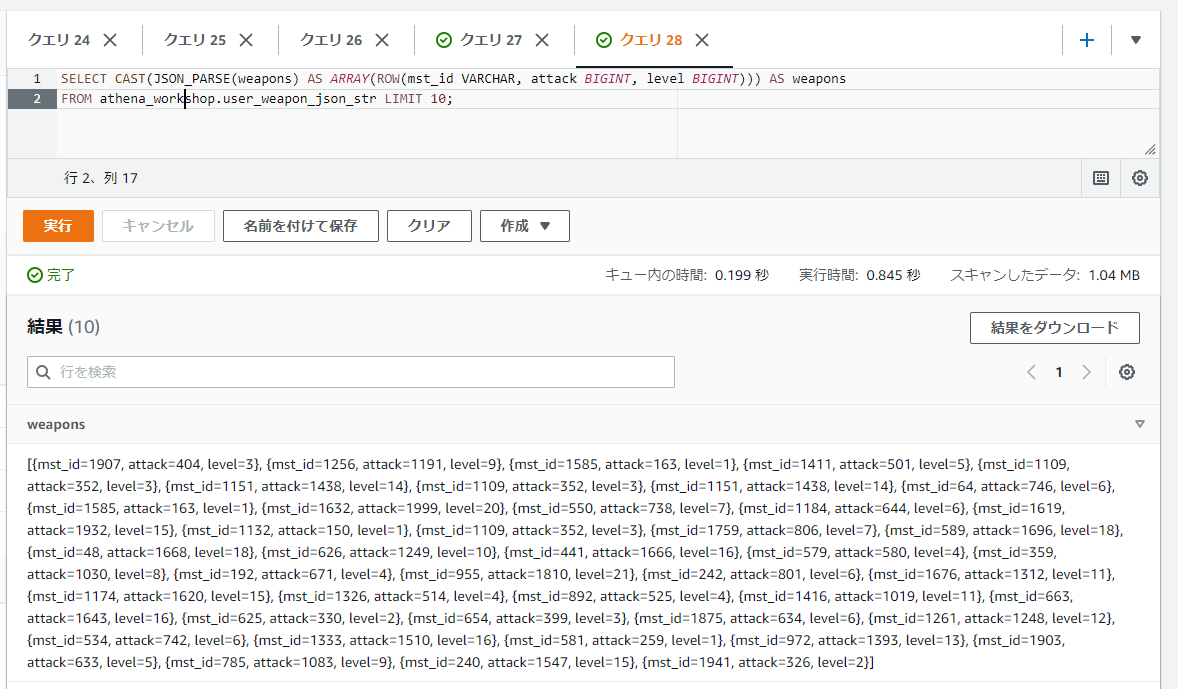
辞書を含んだ配列・・・といったデータであれば、CAST(<JSONの値> AS ARRAY(ROW(<辞書のフォーマット>)))といったように、ARRAY関数にROW関数を入れ子にすることで表現できます。ROW関数はROW(<キー名> 値の型, <キー名> 値の型)といったように書きます(例 : ROW(a BIGINT, b VARCHAR))。
SELECT CAST(JSON_PARSE(weapons) AS ARRAY(ROW(mst_id VARCHAR, attack BIGINT, level BIGINT))) AS weapons
FROM athena_workshop.user_weapon_json_str LIMIT 10;
これでARRAYとSTRUCTを扱った時と同じような値となるので、STRUCT関係の節で触れたような必要な行列変換などを入れれば色々操作が行えます。
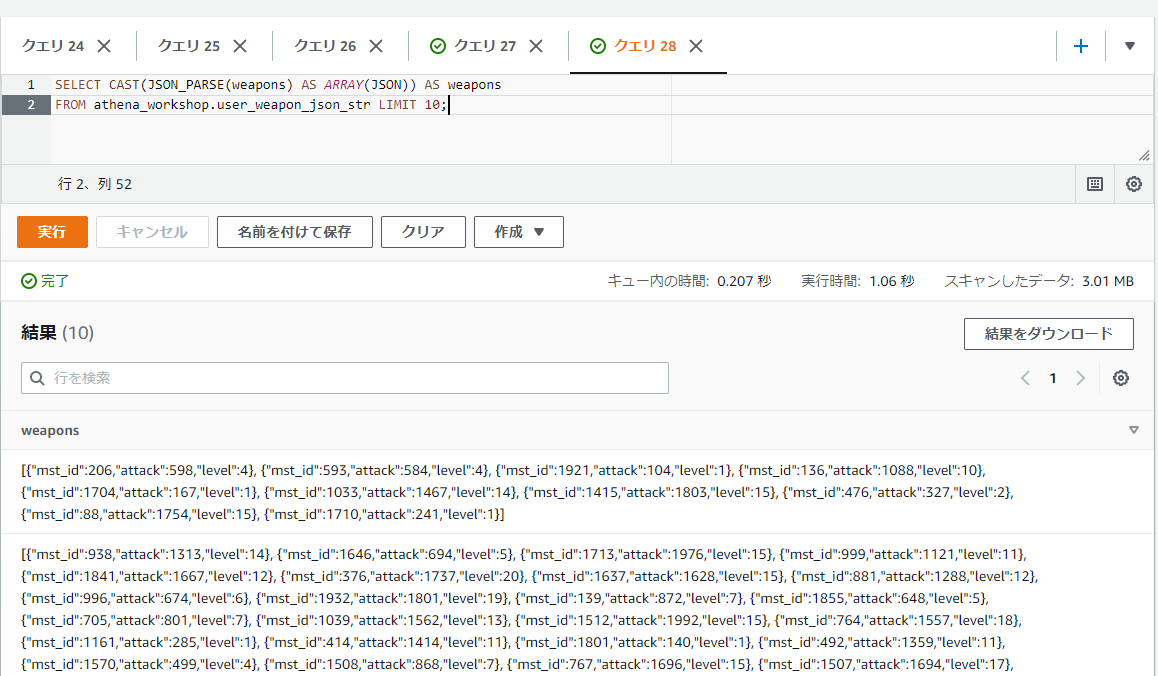
もしくはキーが多すぎて個別に型を定義するのが難しい・・・といった場合には、JSONの型を含んだ配列(ARRAY(JSON))といったように指定するのが楽なケースもあります。こちらの場合は行列変換などはJSONのフォーマットによる参照方法などが必要になってきます(後の節で触れます)。
SELECT CAST(JSON_PARSE(weapons) AS ARRAY(JSON)) AS weapons
FROM athena_workshop.user_weapon_json_str LIMIT 10;
特定の位置のJSONの値を抽出する: JSON_EXTRACT と JSON_EXTRACT_SCALAR
JSONの値の特定の位置の値を抽出するにはJSON_EXTRACT関数を使います。第一引数には対象のJSONのカラムもしくは固定値、第二引数には対象の位置の指定用の文字列を設定します。
第二引数の位置指定用の文字列はJSONPath - XPath for JSONの資料に書かれているものが使えるようです。全ては触れませんが良く使いそうなものをこの節で触れていきます。
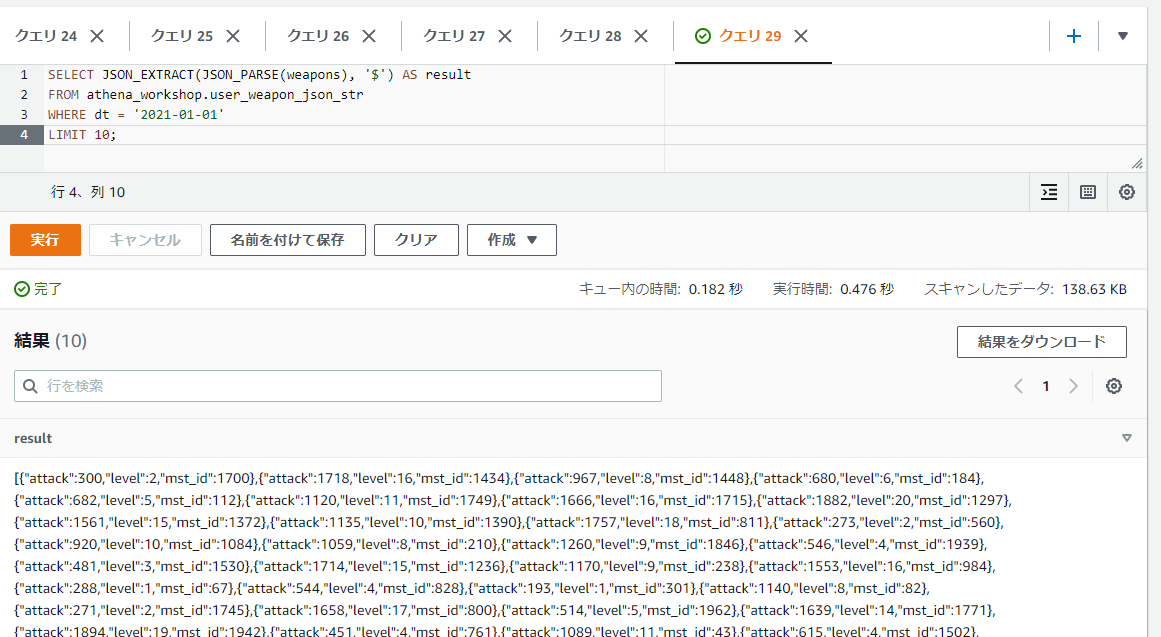
まずは$の記述です。これはJSONのルート(一番上の階層)を示します。$を単体で指定した場合は一番上のフォルダから中身の全てのファイルが参照されるように、JSONのデータ全体の参照となるためJSON_EXTRACTを使わない場合と同じ結果になります。
SELECT JSON_EXTRACT(JSON_PARSE(weapons), '$') AS result
FROM athena_workshop.user_weapon_json_str
WHERE dt = '2021-01-01'
LIMIT 10;
JSON内の特定の位置のデータを抽出したい場合ルートのデータから子の要素にアクセスしていく必要があります。そういった場合には.のドット記号かもしくは[]の記号を使ってインデックスの指定をする形で参照します。
例えば今回扱っているデータだとルート部分が配列になっているので、配列の先頭の要素にアクセスしたい場合ドット記号を使うと.0といったように書きます。ルートの位置からその配列の先頭のデータ・・・とするため、ルートの$と合わせて$.0といったように指定します。ちなみにAthena(Presto)のSQL上だと最初のインデックスは1から始まるケースが大半ですが、JSONの場合0から始まります。最初のデータが0となり1ではないため注意が必要です。
SELECT JSON_EXTRACT(JSON_PARSE(weapons), '$.0') AS result
FROM athena_workshop.user_weapon_json_str
WHERE dt = '2021-01-01'
LIMIT 10;
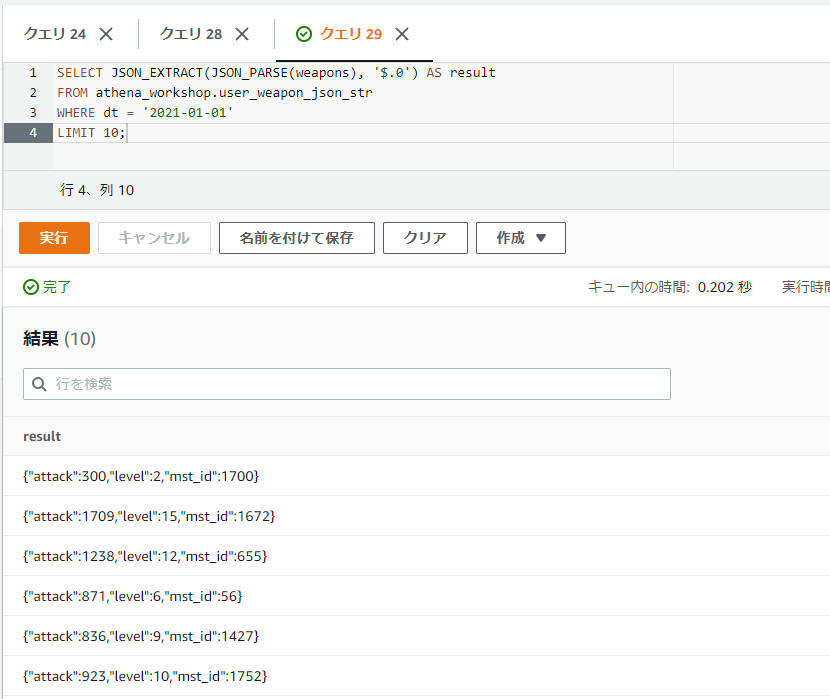
JSONの配列の先頭のデータのみを抽出することができました。ドット記号を使うのと同じように[]の括弧を使って参照することもできます。例えば配列の先頭のインデックスにアクセスしたい場合には[0]といった書き方でもアクセスすることができます。
SELECT JSON_EXTRACT(JSON_PARSE(weapons), '$[0]') AS result
FROM athena_workshop.user_weapon_json_str
WHERE dt = '2021-01-01'
LIMIT 10;
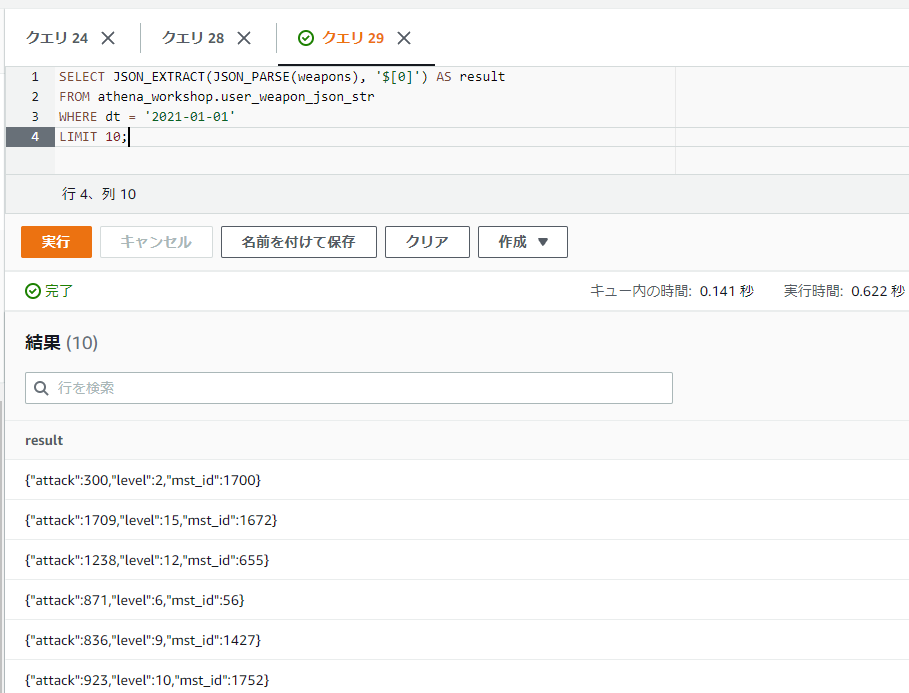
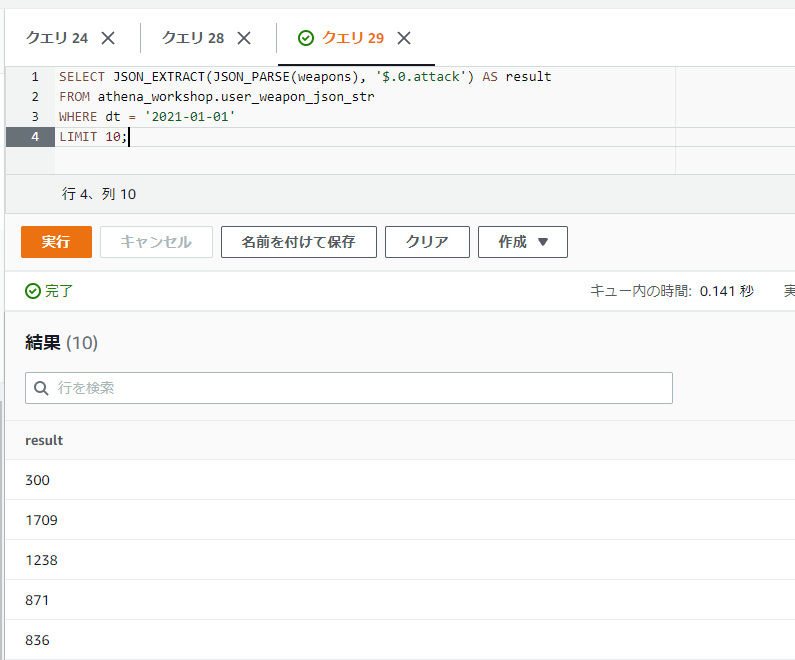
配列の先頭のデータの辞書部分でさらに特定のキーにアクセスしたいとします。例えばattackキーのデータだけ欲しい・・・といった場合を考えます。
そういった場合は子の要素には整数だけでなくキー名なども指定できるため、ドットを使う場合は$.0.attackといったように書くことで子要素にアクセスすることができます。
SELECT JSON_EXTRACT(JSON_PARSE(weapons), '$.0.attack') AS result
FROM athena_workshop.user_weapon_json_str
WHERE dt = '2021-01-01'
LIMIT 10;
[]の括弧を使うこともできます。キー名で[]の括弧を使う場合にはダブルクォーテーションで囲んで書いてもダブルクォーテーションを省略してもどちらでも動くようです(JSONだとダブルクォーテーションで囲む方が自然ですが、特に必要というわけではないようです)。
SELECT JSON_EXTRACT(JSON_PARSE(weapons), '$[0][attack]') AS result
FROM athena_workshop.user_weapon_json_str
WHERE dt = '2021-01-01'
LIMIT 10;
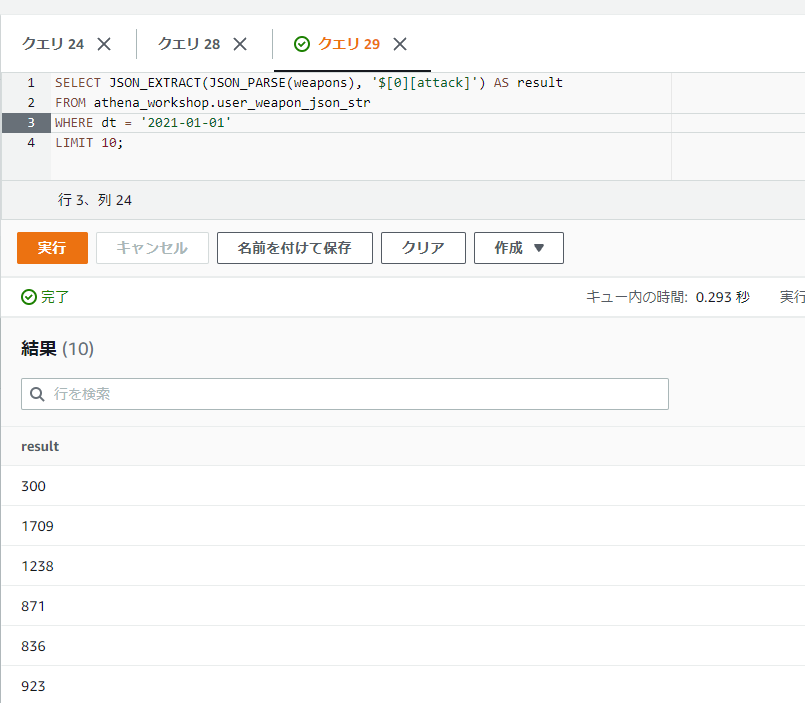
その他にもリンク先の資料だと全てを表すアスタリスクや複数条件の[]の括弧内のコンマの記述やスライス記法なども書かれていますが、なんだかAthena上ではエラーになる?ようで、Athenaではまだ使えないのかもしれません。
JSON内の配列の全データを展開したい・・・といった場合はこの関数ではなくUNNESTなどで各行を辞書などで行列変換し、その後JSON_EXTRACT関数で各キーの値を展開する・・・とすると良いかもしれません。
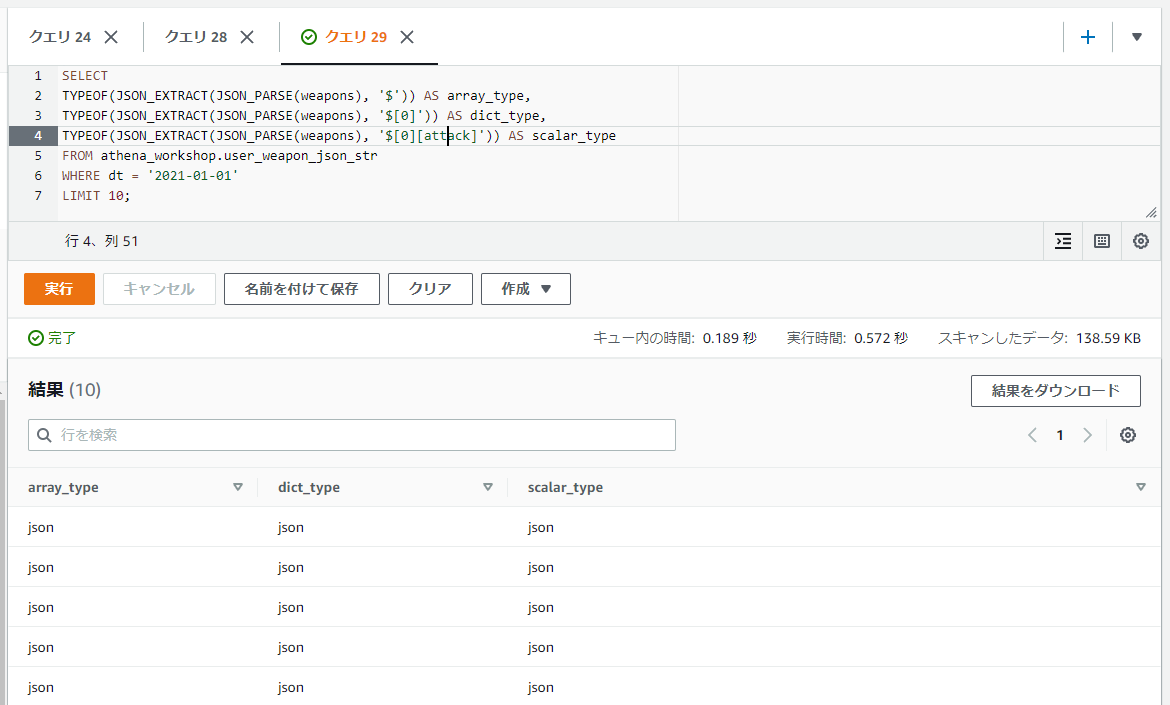
なお、JSON_EXTRACT関数では抽出結果の値は全てJSONの型となります。試しに以下のようにルートの配列部分や配列内の辞書、さらにその辞書の特定のキーの値の型をそれぞれ表示してみても全てjsonと表示されます。
SELECT
TYPEOF(JSON_EXTRACT(JSON_PARSE(weapons), '$')) AS array_type,
TYPEOF(JSON_EXTRACT(JSON_PARSE(weapons), '$[0]')) AS dict_type,
TYPEOF(JSON_EXTRACT(JSON_PARSE(weapons), '$[0][attack]')) AS scalar_type
FROM athena_workshop.user_weapon_json_str
WHERE dt = '2021-01-01'
LIMIT 10;
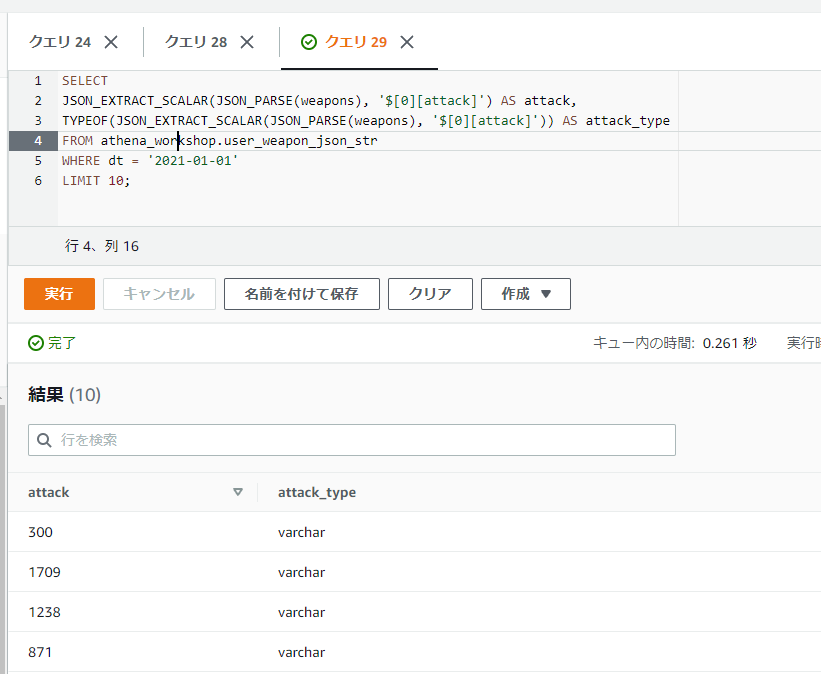
一方でJSON_EXTRACT_SCALAR関数は文字列で値が返ってくるようです。数値などの他の型であってもVARCHARに結果はなります(文字列以外はどのみちCASTが必要になりそうなので、あまり使い道は無い・・・?かもしれません)。
SELECT
JSON_EXTRACT_SCALAR(JSON_PARSE(weapons), '$[0][attack]') AS attack,
TYPEOF(JSON_EXTRACT_SCALAR(JSON_PARSE(weapons), '$[0][attack]')) AS attack_type
FROM athena_workshop.user_weapon_json_str
WHERE dt = '2021-01-01'
LIMIT 10;
Pythonでの書き方
json.lodasで文字列からリストに変換した後に、追加で特定の位置の値を抽出する関数(今回はextract_attack_from_weaponsという関数名にしてあります)を設けてそちらもapplyメソッドで反映すれば抽出できます。
import json
from typing import Any, Dict, List
import pandas as pd
def extract_attack_from_weapons(weapons: List[Dict[str, Any]]) -> int:
"""
指定された武器データの配列から、先頭の武器の攻撃力の値を抽出する。
Parameters
----------
weapons : list of dict
武器データを格納した配列。
Returns
-------
attack : int
抽出された攻撃力。空のリストの場合には0が設定される。
"""
if not weapons:
return 0
return weapons[0]['attack']
df: pd.DataFrame = pd.read_json(
'https://github.com/simon-ritchie/athena_workshop/blob/main/workshop/user_weapon_json_str/dt%3D2021-01-01/data.json.gz?raw=true',
lines=True, orient='records', compression='gzip')
df['weapons'] = df['weapons'].apply(json.loads)
df['attack'] = df['weapons'].apply(extract_attack_from_weapons)
print(df[['attack', 'weapons']].head())
attack weapons
0 300 [{'mst_id': 1700, 'attack': 300, 'level': 2}, ...
1 1709 [{'mst_id': 1672, 'attack': 1709, 'level': 15}...
2 1238 [{'mst_id': 655, 'attack': 1238, 'level': 12},...
3 871 [{'mst_id': 56, 'attack': 871, 'level': 6}, {'...
4 836 [{'mst_id': 1427, 'attack': 836, 'level': 9}, ...
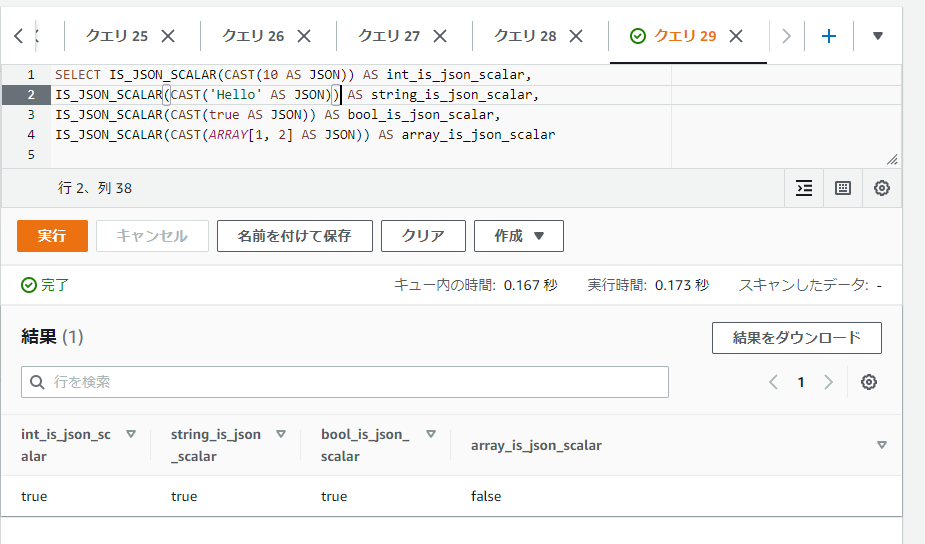
値がJSONで扱えるスカラー値かどうかの真偽値を取得する: IS_JSON_SCALAR
IS_JSON_SCALAR関数では特定の値がJSONで扱える単一のスカラー値(単一の数値、文字列、真偽値、NULLなど)かどうかの真偽値を返します。単一の数値などであればtrue、そうではなく配列などの複数の値を含むデータなどであれはfalseとなります。
以下のSQLでは整数・文字列・真偽値・配列の固定値に対してIS_JSON_SCALAR関数を実行していますが、配列のみfalseになっていることが確認できます。
SELECT IS_JSON_SCALAR(CAST(10 AS JSON)) AS int_is_json_scalar,
IS_JSON_SCALAR(CAST('Hello' AS JSON)) AS string_is_json_scalar,
IS_JSON_SCALAR(CAST(true AS JSON)) AS bool_is_json_scalar,
IS_JSON_SCALAR(CAST(ARRAY[1, 2] AS JSON)) AS array_is_json_scalar
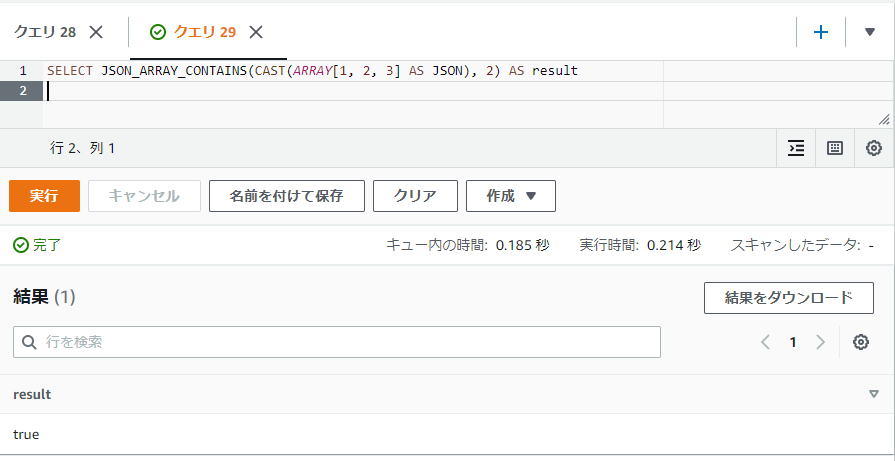
JSONの配列内に特定の値がふくまれているかの真偽値を取得する: JSON_ARRAY_CONTAINS
JSON_ARRAY_CONTAINS関数はJSONの配列内に特定の値が含まれているかどうかの真偽値を取得することができます。存在すればtrue、存在しなければfalseとなります。通常の配列でもこの辺の関数はありますが、JSONのまま扱いたい場合などに使用します。
第一引数には対象のJSONの配列、第二引数には検索対象の値を指定します。
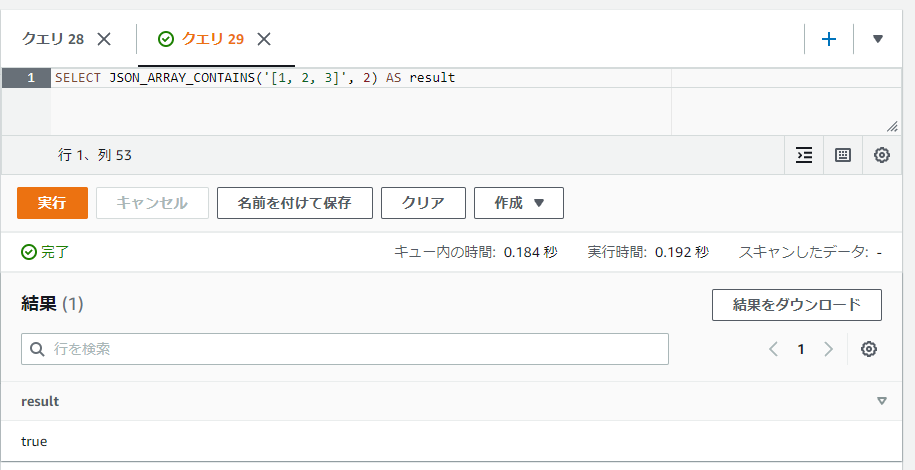
SELECT JSON_ARRAY_CONTAINS(CAST(ARRAY[1, 2, 3] AS JSON), 2) AS result
ちなみにですが、JSONの配列の形式の文字列であればキャストやJSON_PARSE関数などを通さなくても文字列のまま処理が流せるようです。例えば以下のように文字列を直接指定してもtrueが返ります。
SELECT JSON_ARRAY_CONTAINS('[1, 2, 3]', 2) AS result
Pythonでの書き方
正直この辺はJSON変換が必要になる以外は配列関係に触れた以前の記事のままなのでリンクだけ貼って割愛します。inキーワードで対応ができます。
JSONの配列の長さを取得する: JSON_ARRAY_LENGTH
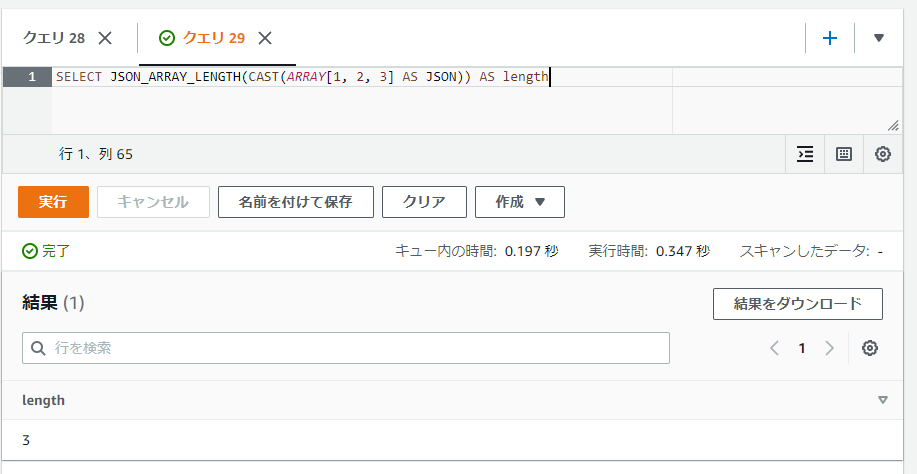
JSON_ARRAY_LENGTH関数ではJSONの配列の長さ(値の件数)を取得することができます。
以下のSQLでは3件の値の配列なので3が返っています。
SELECT JSON_ARRAY_LENGTH(CAST(ARRAY[1, 2, 3] AS JSON)) AS length
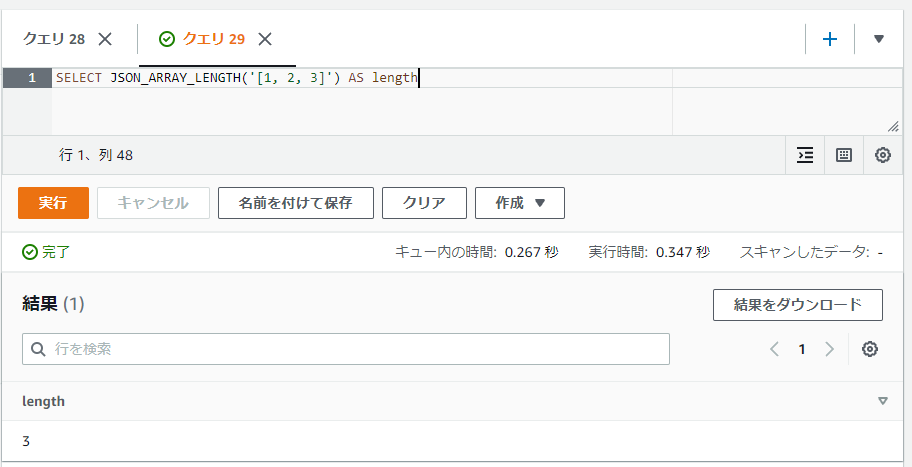
こちらもJSON形式の文字列であればキャストやJSON_PARSE関数などを省いても動くようです。
SELECT JSON_ARRAY_LENGTH('[1, 2, 3]') AS length
Pythonでの書き方
json.loads関数でJSONをリストに変換した後に、len関数でリストの値の件数が取れるのでそちらをapplyメソッドで反映すれば取れます。
import json
from typing import Any, Dict, List
import pandas as pd
df: pd.DataFrame = pd.read_json(
'https://github.com/simon-ritchie/athena_workshop/blob/main/workshop/user_weapon_json_str/dt%3D2021-01-01/data.json.gz?raw=true',
lines=True, orient='records', compression='gzip')
df['weapons'] = df['weapons'].apply(json.loads)
df['length'] = df['weapons'].apply(len)
print(df[['length', 'weapons']].head())
length weapons
0 61 [{'mst_id': 1700, 'attack': 300, 'level': 2}, ...
1 44 [{'mst_id': 1672, 'attack': 1709, 'level': 15}...
2 60 [{'mst_id': 655, 'attack': 1238, 'level': 12},...
3 26 [{'mst_id': 56, 'attack': 871, 'level': 6}, {'...
4 77 [{'mst_id': 1427, 'attack': 836, 'level': 9}, ...
特定位置のJSONの要素の数を取得する: JSON_SIZE
JSON_SIZE関数は特定の位置のJSONの要素の数を取得します。JSON_ARRAY_LENGTH関数とは異なり第二引数に位置の指定が必要になります。第二引数の位置の指定にはJSON_EXTRACT関数の節で触れたようなJSONPathの記法の文字列が必要になります。
対象は配列もしくは辞書の位置でのみ正常な値が取れます。それ以外のスカラー値の位置では返却値は0となります。
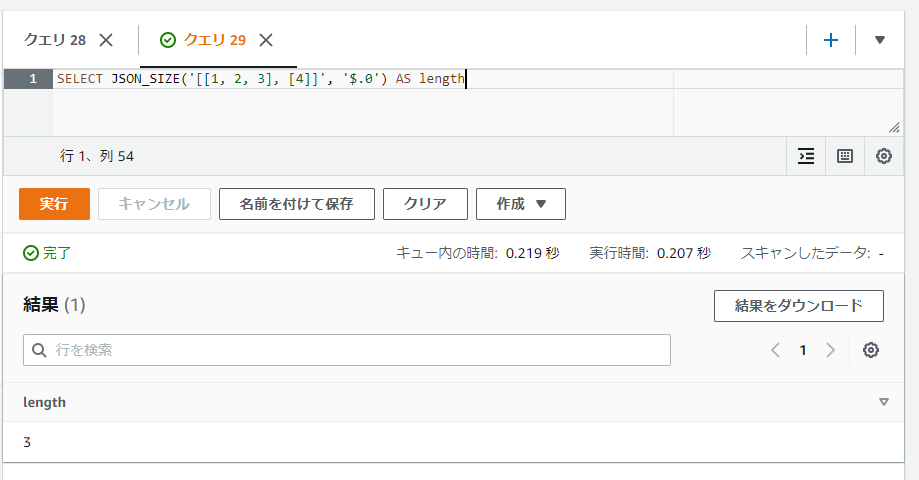
以下のSQLでは2次元配列で配列の先頭の位置($.0)の配列の値([1, 2, 3])の件数を取得しています。
SELECT JSON_SIZE('[[1, 2, 3], [4]]', '$.0') AS length
結果は3となります。
参考文献・参考サイトまとめ
- The Applied SQL Data Analytics Workshop: Develop your practical skills and prepare to become a professional data analyst, 2nd Edition
- Data Types
- Map Functions and Operators
- 【Python】dictをfilterする
- カーディナリティ 【cardinality】
- SQL で縦横変換まとめ(pivot と unpivot)
- PrestoのArray, Mapの使い方調査
- [Amazon Athena]一見json配列に見えるvarcharのデータをパースして集計できる形式に変換する
- JSON Functions and Operators
- JSONPath - XPath for JSON