とある方より、一緒にKaggleやってみませんか?という話をいただいたので、Kaggleについていろいろ調べつつ、タイタニックのチュートリアルを進めてみます。
本記事では、長くなりそうなのでチュートリアルのデータ確認のところまで進めます。(推論だったりは次の記事にて・・)
以下の点ご了承くださいmm
- データサイエンス業界では初心者のため、知識や技術力的に突っ込みどころなど多々あると思いますがご了承ください。
- また、メモ的側面も強いので、文章がシンプルにまとまらないとも思います。
まずはチュートリアルでタイタニックのものを・・
まずはKaggle自体に慣れたりするため、各所でチュートリアル記事があったり、書籍などでも取り上げられているタイタニックのものを触ってみます。
Titanic: Machine Learning from Disaster
Start here! Predict survival on the Titanic and get familiar with ML basics
...
Start here if...
You're new to data science and machine learning, or looking for a simple intro to the Kaggle prediction competitions.
とあるので、色々入門者に優しくなっているのかな?と期待しつつ・・
コンペの説明を読む
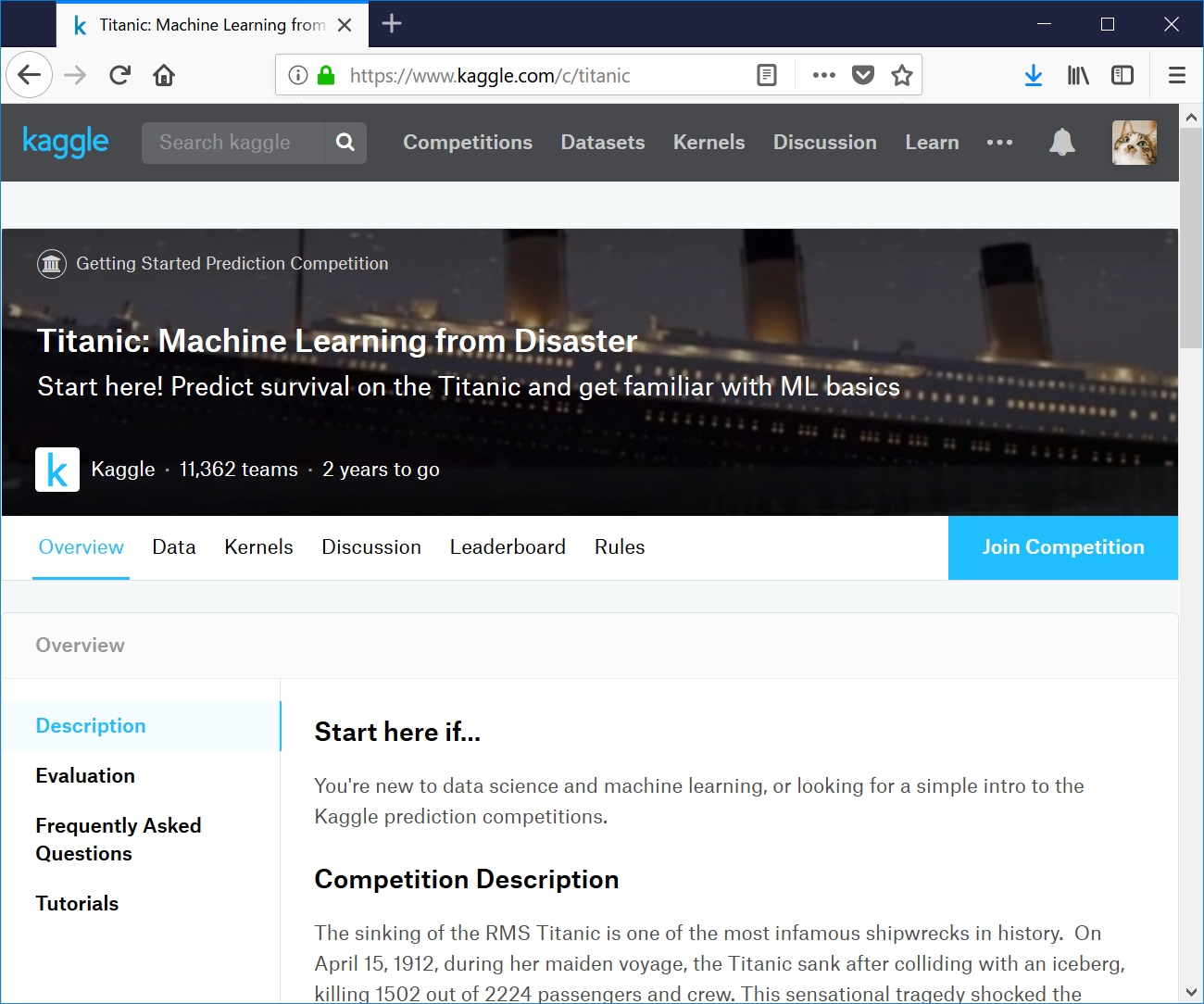
Competition Description部分 :
Although there was some element of luck involved in surviving the sinking, some groups of people were more likely to survive than others, such as women, children, and the upper-class.
昔観た映画でも、女性や子供が優先されていましたね・・。
加えて、上流階層の人々が生き残りやすかったと・・
In this challenge, we ask you to complete the analysis of what sorts of people were likely to survive. In particular, we ask you to apply the tools of machine learning to predict which passengers survived the tragedy.
どんな人々が生き残りやすかったのかを機械学習で予測するのが目的とのことです。
Goal部分 :
It is your job to predict if a passenger survived the sinking of the Titanic or not.
For each PassengerId in the test set, you must predict a 0 or 1 value for the Survived variable.
生き残るか否かを0か1の2値で推論する必要があると。
Metric :
Your score is the percentage of passengers you correctly predict. This is known simply as "accuracy”.
スコアは単純に、正解のパーセンテージで判断されると。
Submission File Format部分 :
You should submit a csv file with exactly 418 entries plus a header row. Your submission will show an error if you have extra columns (beyond PassengerId and Survived) or rows.
418人分プラスヘッダーを設定したCSVを用意する必要があるようです。余分なカラムがあるとエラーになるので、カラムはPassengerIdとSurvivedのみ設定すると・・
データの確認
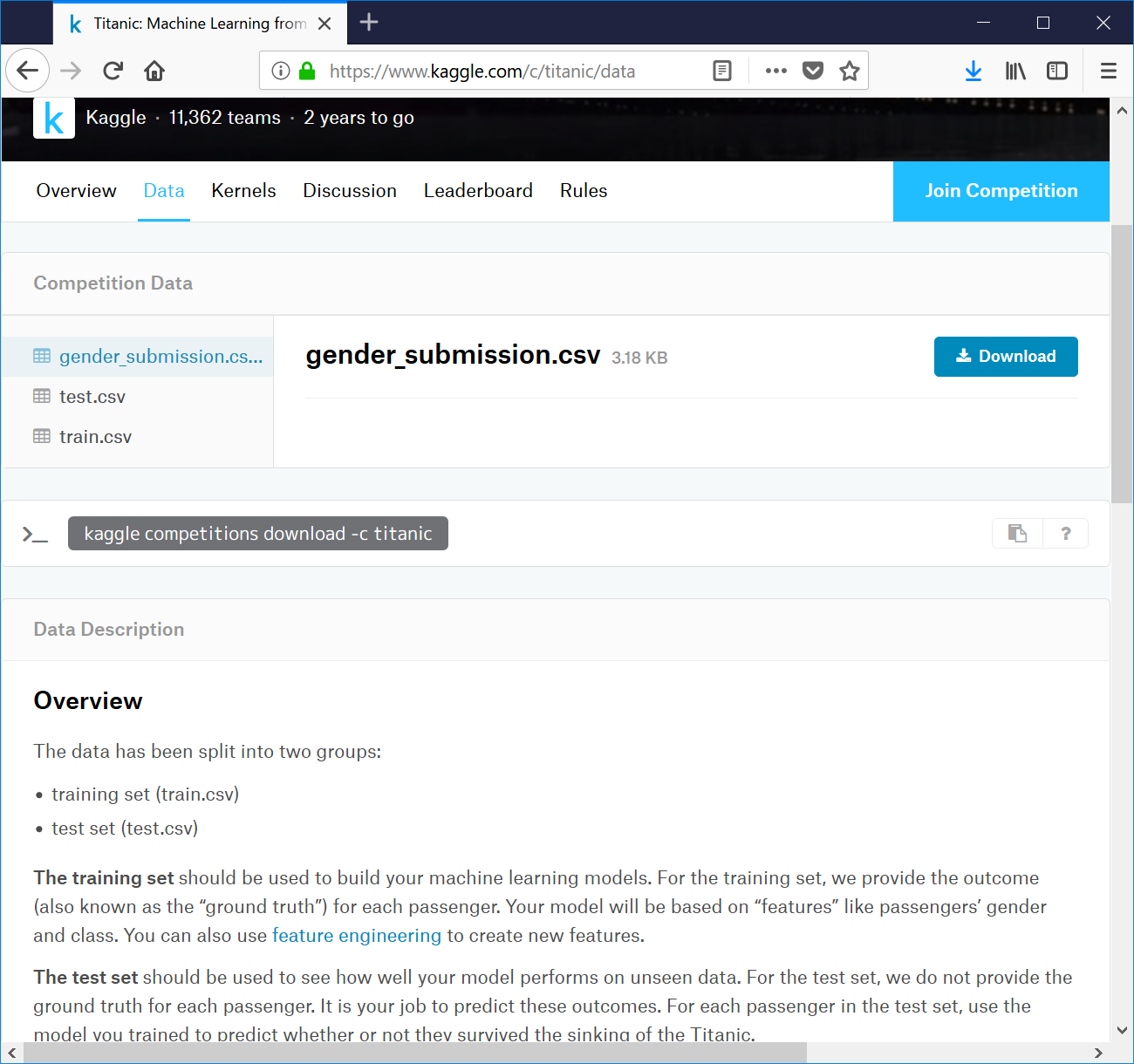
以下の三つのファイルがあるようです。
- gender_submission.csv
- train.csv
- test.csv
train.csvは機械学習のモデルを組むために使用するデータで、ground truth付きの教師有りのデータのようです。
test.csvはground truth無しの、モデルの性能評価用のデータのようです。
gender_submission.csv は提出ファイルのフォーマットの参考として用意されているようです。こちらは一旦気にせず進めてみます。
どんな変数があるのか
記載されている表を眺めてみます。
- survival -> 0か1の2値。1で生存。
- pclass -> チケットのクラス。1~3で、1に近い方がお金持ち。
- sex -> 性別。
- Age -> 年齢。
- sibsp -> 船に乗っていた兄弟・配偶者の数。
- parch -> 船に乗っていた親・子供の数。
- ticket -> チケット番号。
- fare -> 料金。
- cabin -> 客室番号。
- embarked -> 港(どの港から船に乗ったのか)。
影響しそうな変数もあれば、主観だと何となくあまり影響しなさそうな変数もあります。後でデータを詳しく見てみましょう。
補足として、乳母による旅行の都合、子供でparchが0のデータがあるとのこと。
LeaderBoardを見てみる
成績上位の方のリストが表示されるようです。
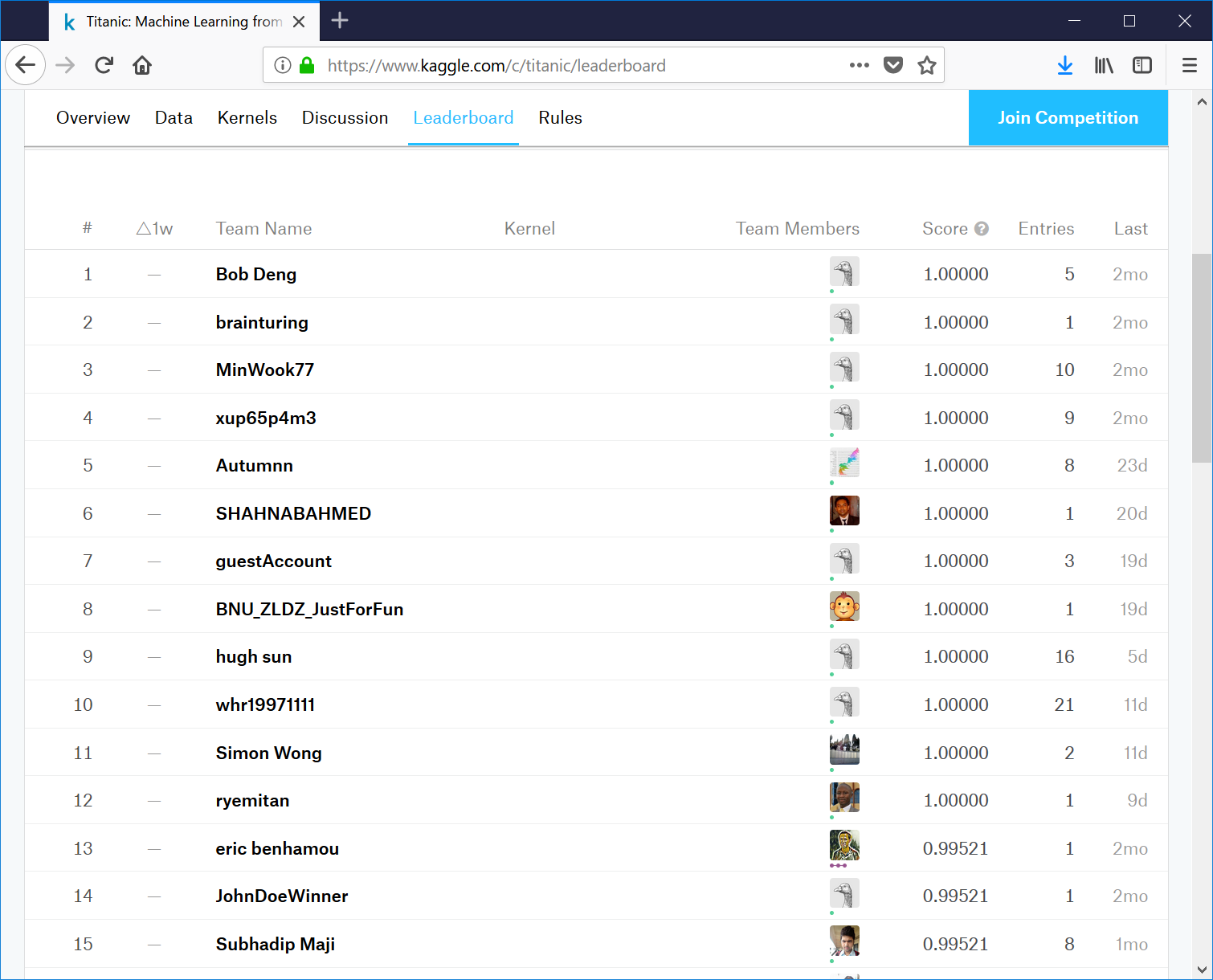
完全正解の方が結構いらっしゃいますね・・
Entriesの部分を見てみると、複数回、別の推論結果を投稿できるのでしょうか?
Rulesを見てみる
Submission Limits
You may submit a maximum of 10 entries per day.
1日10件まで投稿できる、ということでしょうか。
Competition Timeline
Start Date: 9/28/2012 9:13 PM UTC
Merger Deadline: None
Entry Deadline: None
End Date: 1/7/2020 12:00 AM UTC
他のコンペでは締め切り周りに結構気を配らないとですが、今回はチュートリアルのもののため、締め切りがNoneとなっています。
Frequently Asked Questionsを見てみる
LeaderboardのページでPublic LeaderboardとPrivate Leaderboardの2種類があり、Privateの方は何なのだろう・・?という疑問に対する答えが書かれていました。
どうやら提供されているテストデータに対する過学習を避けるため、テストデータの半分の精度のみ、Publicの方で公開され、Privateの方はコンペが終わるまで公開されないようです。
偶然、Publicの方で精度が高くても、汎化性能の方がよくないと結果的にコンペには勝てない、という感じでしょうか。
コンペが終わるまで正確な順位がわからないということで、実際のコンペでは終了前後で緊張しそうですね・・。
Kernels supports scripts in R and Python, Jupyter Notebooks, and RMarkdown reports
RかPythonをサポートしているようです。
Why did my team disappear from the leaderboard?
件数が膨大になって、新しく来た人が埋もれてしまうのを避けるため、2か月程度でleaderboardから消えるそうです。
何となくKaggleとコンペ内容が分かってきたので、Join Competitionをクリックして進んでいきます。
チュートリアルを進めてみる : Titanic Data Science Solutions
Titanic Data Science Solutionsのチュートリアルを参考に進めていってみます。(結構内容を省略して、一部だけ触れたりしていきます)
Jupyterのノート形式になっていて写経しやすく、説明も丁寧で助かります。
基本のimportとデータの読み込み
まずはPandasだったりNumPyだったりmatplotlibなどの、よく使うもののimport。
import pandas as pd
import numpy as np
import random as rnd
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
提供されているデータを落としてきておいて、データフレームで読み込んでおきます。
train_df = pd.read_csv('./train.csv')
test_df = pd.read_csv('./test.csv')
データの内容のチェック
軽くデータの中身を見てみます。
train_df.head(n=3)
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.25 | S | |
| 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Thayer) | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.925 | S |
len(train_df)
891
train.csvは891行。SurvivedカラムGround trueはtrain側のみあり、test.csv側にはありません。
test_df.head(n=3)
| PassengerId | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked |
|---|---|---|---|---|---|---|---|---|---|---|
| 892 | 3 | Kelly, Mr. James | male | 34.5 | 0 | 0 | 330911 | 7.8292 | Q | |
| 893 | 3 | Wilkes, Mrs. James (Ellen Needs) | female | 47.0 | 1 | 0 | 363272 | 7.0 | S | |
| 894 | 2 | Myles, Mr. Thomas Francis | male | 62.0 | 0 | 0 | 240276 | 9.6875 | Q |
info関数で型と欠損値の有無を確認します。
train_df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
PassengerId 891 non-null int64
Survived 891 non-null int64
Pclass 891 non-null int64
Name 891 non-null object
Sex 891 non-null object
Age 714 non-null float64
SibSp 891 non-null int64
Parch 891 non-null int64
Ticket 891 non-null object
Fare 891 non-null float64
Cabin 204 non-null object
Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.6+ KB
〇〇 non-nullの部分が891になっていれば、全行欠損値無しなので、欠損値補正が不要です。どうやら、Age、Cabin、Embarkedカラムに欠損値があり、特にCabinは値が入っていないデータが多いようです
test_df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 418 entries, 0 to 417
Data columns (total 11 columns):
PassengerId 418 non-null int64
Pclass 418 non-null int64
Name 418 non-null object
Sex 418 non-null object
Age 332 non-null float64
SibSp 418 non-null int64
Parch 418 non-null int64
Ticket 418 non-null object
Fare 417 non-null float64
Cabin 91 non-null object
Embarked 418 non-null object
dtypes: float64(2), int64(4), object(5)
memory usage: 36.0+ KB
test.csv側は、train側と比べてEmbarkedカラムが欠損していない代わりにFareカラムが一部欠損しているようです。実際に触る際に注意します。
describe関数を使って、test.csvの数値のカラムがどのような要約統計量になっているのか確認します。
train_df.describe()
|PassengerId|Survived|Pclass|Age|SibSp|Parch|Fare
---|---|---|---|---|---|---|---
count|891.0|891.0|891.0|714.0|891.0|891.0|891.0
mean|446.0|0.3838383838383838|2.308641975308642|29.69911764705882|0.5230078563411896|0.38159371492704824|32.2042079685746
std|257.3538420152301|0.4865924542648585|0.8360712409770513|14.526497332334044|1.1027434322934275|0.8060572211299559|49.693428597180905
min|1.0|0.0|1.0|0.42|0.0|0.0|0.0
25%|223.5|0.0|2.0|20.125|0.0|0.0|7.9104
50%|446.0|0.0|3.0|28.0|0.0|0.0|14.4542
75%|668.5|1.0|3.0|38.0|1.0|0.0|31.0
max|891.0|1.0|3.0|80.0|8.0|6.0|512.3292
コンペの説明に
killing 1502 out of 2224 passengers and crew
とあり、実際のデータ全体では約32.5%の生存率なのに対して、test.csvのSurvivedカラムの平均が38%となっており、データ件数が少なくそれなりに差異があります。
年齢は平均29.6歳、中央値、28歳。最小が0.4歳、最大が80歳。結構若い方が多かったのですね。
75パーセンタイルのParchの値が0になっているので、多くの人が親もしくは子供と一緒に乗っていたわけではないようです。対して、SibSpの75パーセンタイルは1になっているので、親や子供と乗るよりも、兄弟・配偶者と乗っていたケースが多いようです。
Fare(料金)の平均は$32.4、中央値は$14.4。最大値が$512.3となっており、富裕層が平均を押し上げ、中央値との乖離が結構あるようです。最小値0なのは、特殊な事情?無料で乗れた人がいるのでしょうか?データだけだと背景がよく分かりません。
チケットのクラス(1~3で、1が料金が高い)は、平均が2.3、中央値3。半分以上の人がクラス3だったようです。
(test側だけなので、データ全体で見るとある程度変わってくるかもしれません。)
性別はどうなっているのか。
train_df.Sex.unique()
array(['male', 'female'], dtype=object)
len(train_df[train_df.Sex == 'male'])
577
len(train_df[train_df.Sex == 'female'])
314
男性577人、女性314人のようです。
港の種別値。
train_df.Embarked.unique()
array(['S', 'C', 'Q', nan], dtype=object)
SやCといった記号で入っているようです。
もう少し、Object型のカラムの値を見てみます。
describe関数で、include引数に文字列のOを指定すると、Object型のものを表示するように指定できます。
train_df.describe(include=['O'])
Cabinがユニークにはなっていないので、ある程度、複数人で同一の客室を使っていたケースがあるようです。
港は、Sの種別が644件となっており、多くの比率を占めているようです。
チケット番号は一意ではないようです(ユニーク件数681)。データが正しくないのか、1つのチケットで複数人乗れたのか・・
他にも、
- PassengerId、Nameカラムは生存率とは相関がなさそう
- Cabinカラムは欠損が多く、使うのには不適切かも
ということも言えそうです。
さらに傾向を見るために、ヒストグラム表示をしてみます。
plt.style.use('ggplot')
_ = train_df.loc[:, ['Pclass', 'Age', 'SibSp',
'Parch', 'Fare']].hist(
figsize=(10, 16), bins=25)
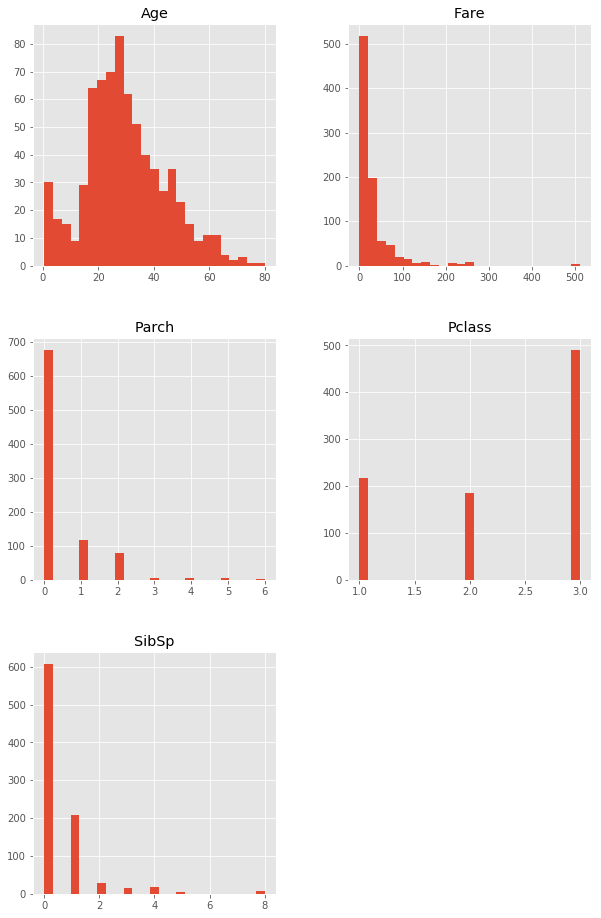
これを見ると、以下のことが追加で分かります。
- 29歳くらいが多いのは分かっていたものの、乳幼児も結構乗っていたようです。
- Parch(一緒に乗っていた親・子供の数)は0が多く、1もしくは2もある程度、それ以上はあまりいないようです。両親もしくは片親と乗っていたとか、子供を1人連れていたケースが多いのでしょうか。
- SibSp(兄弟・配偶者の数)も0と1が多く、個人で乗っていたか、配偶者と乗っていた人がおおいのかという印象です。
- Pclass(チケットのクラス)は、意外にも真ん中のクラスよりも一番高いクラスの方が多いようです。割合的にも、富裕層が多そうです。
- Fareは、300~400付近の値がなさそうで、500付近にわずかに存在します。調べてみると、3人だけそういった乗客がいたようです。
Embarkedカラムの分布もみておきます。
train_df.Embarked.value_counts()
S 644
C 168
Q 77
Name: Embarked, dtype: int64
いくつかのカラムの生存率を見てみる
どの値が生存率と相関があるのかの知見を得るため、値の種類が少なく、表でさくっと生存率が見れるカラムの値を確認してみます。
def get_survived_rate_calculated_df(df, column_name):
"""
データフレームの対象カラムの各値ごとの、生存率を
設定したデータフレームを取得する。
Parameters
----------
df : DataFrame
対象のデータフレーム。最低限、Survivedカラムと
column_name引数で指定したカラムが必要になる。
column_name : str
割り振り対象の値を格納したカラム名。
Returns
-------
survived_rate_calculated_df : DataFrame
column_nameで指定したカラムとSurvivedが設定され、
各値に対する生存率が格納されたデータフレーム。
"""
sliced_df = df.loc[:, [column_name, 'Survived']]
grouped_obj = sliced_df.groupby(
by=column_name, as_index=False)
meaned_df = grouped_obj.mean()
survived_rate_calculated_df = meaned_df.sort_values(
by='Survived', ascending=False)
return survived_rate_calculated_df
まずはチケットのクラスから。
get_survived_rate_calculated_df(
df=train_df, column_name='Pclass')
| Pclass | Survived |
|---|---|
| 1 | 0.6296296296296297 |
| 2 | 0.47282608695652173 |
| 3 | 0.24236252545824846 |
順当にチケットのクラスが良い方が生存率が高くなる模様。
続いて性別。
get_survived_rate_calculated_df(
df=train_df, column_name='Sex')
| Sex | Survived |
|---|---|
| female | 0.7420382165605095 |
| male | 0.18890814558058924 |
映画でも女性と子供が優先されていましたが、大分差がありますね・・
兄弟・配偶者の数 :
get_survived_rate_calculated_df(
df=train_df, column_name='SibSp')
| SibSp | Survived |
|---|---|
| 1 | 0.5358851674641149 |
| 2 | 0.4642857142857143 |
| 0 | 0.34539473684210525 |
| 3 | 0.25 |
| 4 | 0.16666666666666666 |
| 5 | 0.0 |
| 8 | 0.0 |
特に目立った相関はなさそうです。
両親・子供の数 :
get_survived_rate_calculated_df(
df=train_df, column_name='Parch')
| Parch | Survived |
|---|---|
| 3 | 0.6 |
| 1 | 0.5508474576271186 |
| 2 | 0.5 |
| 0 | 0.34365781710914456 |
| 5 | 0.2 |
| 4 | 0.0 |
| 6 | 0.0 |
こちらもそのまま使うには弱いかな、という印象。
同じように年齢に関して確認してみます。0歳~80歳まで値が多いので、プロットで確認してみます。
複数の属性で分けて、一気にSubplotの扱う際にはSeabornのFacetGridが便利なようです。
FacetGridのコンストラクタで分けたい属性を指定し、map関数で設定したいプロットの関数や値のカラム、そのほかプロットで必要な引数値をキーワードを指定します。
grid = sns.FacetGrid(data=train_df, col='Survived')
grid.map(plt.hist, 'Age', bins=25)
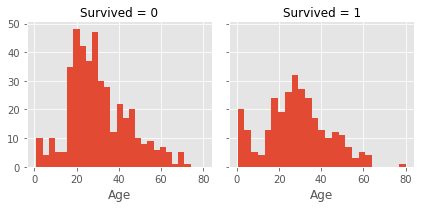
- 乳幼児が生存率が高いようです。
- チケットのクラスの差もあるのでしょうが、20歳くらいの若い人は生存率が低いようです。
ここまでで、どの変数が影響が大きそうなのか少し見えてきました。チュートリアルがまだ3倍くらいありそうで、先は長いですが一旦次回の記事に続きます。