最初のgitのコミットから約8年?経過し9年目に突入しているのでは・・・というレガシー感の溢れるプロジェクトを引き継いでから何年もかけて色々改善してきた内容だったり、逆に現在でも色々抱えていて今後改善していきたい課題などについて本記事で振り返り的に触れていきます。
※執筆に関して上長から許可をいただいています。
プロジェクトの概略
- 弊社がゲーム会社なのですが、各ゲームタイトルで横断で使われているwebアプリです。
- 言語としては主にPython、フレームワークとしては主にDjangoが使われています。
- テストやdocstringなどを含めた現在残存するPythonファイルの行数は約78万行くらいです。
- サーバーはAWSのクラウドが使われています。
年数的に色々レガシー感のある点がたくさん残っていますが、一方でここまで長い間社内で使われ続けてきている・・・というのは中々無いケースでしっかり続いてきたのは良いことだと思います(大体のプロジェクトは数年で終わってしまったり、会社自体も10年持たないケースも世の中では多いでしょうし)。
引き継いだ当初の状況
以降の節で色々と引き継いだ当初の状況を書いていきます。
前任者がチームに居ない状態でのスタート
元々引き継ぎとなった経緯がプロジェクトに前任者が居なくなり、当時の上長から引き継ぎのお願いが来たことからスタートしているためチームに前任者が居ない状態からの1人でのスタートでした(外から見ていてもなんだか危険な雰囲気を感じていたので当初引き継ぎを拒否したのですが熱い要望により結局折れて引き継ぎする形となっています・・・w)。
まともなドキュメントが残っていない状況
引き継いだ時点だとドキュメントがほぼ残っていませんでした。残っていませんというか書かれていませんでした。かろうじてプロジェクトのごく初期に頃に作られたと思われる図の資料が1枚とリポジトリのREADMEに開発環境構築のヒント程度のメモが残っていました。
Pythonでのコードのドキュメントとなるdocstring(JSDoc的なもの)もほぼ皆無になっており、コード内容の把握も何とも厳しい感じになっていました。
多くのバグが残っている状態
引き継いだ時点で色々バグが残っていました。明らかに機能として動いていない箇所が多く、且つ引き継いで色々調べたり検証していく中でもデータの処理などが色々実は正しくない(正しく無いことを誰も把握していなかった)といったことも発覚したりしています。
コードの認知的複雑度が相当に高くコードを読むのがかなり厳しい状況
それなりに長い期間プログラムを書いてきた気がしますが、このプロジェクトに参画して初めてif文やfor文など意味のあるインデントが10個以上ネストしているといったケースに遭遇しました。
その状態で1つの関数でも数百行に及んでいたりとかなり認知的複雑度が高い感じになっており、コードを読んで内容を把握したりコードに手を加えるのが何とも難しい・・・という状況になっていました。
※認知的複雑度などに関しては必要に応じて以下の記事等をご参照ください。
プロジェクトでコードスタイルが決められていない状態のコード
コミットログなどを見ていると前任の方が3~4人程度いらっしゃったようで、それぞれの方が1人~2人ずつくらい(ワンオペなどの時期も長かったようで)で皆さん引き継いだりしてきた・・・といった感じのようですが、コードスタイルなども統一されておらず結構書き方が人によってばらばらになっていました。
テストが皆無
テストが書かれていませんでした。勿論自動テストなども整備されていません。
コードが読みづらいというだけでなく、テストが無い影響で余計に変更容易性が低いというか、引き継いでしばらくは頻繁なデグレに悩まされることになります。
Lintなどが整備されていない
コードスタイルが統一されていない点にも絡んできますが、Lintなどが整備されていませんでした。安全のためのチェック用のLintであったり、可読性のためのコードスタイルチェックなどの担保がされていない・・・という状況でした。
命名が不正確
ドキュメントが残っておらず、テストなども整備されておらず・・・となった場合、コードの変数名や関数名から内容を把握していったりヒントにしたり・・・が必要になってきますが、それらの命名も割と英語が間違っていたり内実と合っていなかったりとしており、引き継いでしばらくした結果結局「既存の命名は信用しない」という判断になっています。
動かして仕様を調べるしかないものの、パフォーマンスが悪いコードが多く関数1つの実行で通るのに数十分かかったりしていた
ここまで頼れるものが無い状況だと開発環境で実際に部分的に関数などを動かして結果の挙動を見て何の挙動をするコードなのか?を推察していく対応が考えられましたが、1つの関数で数十分かかるようなものも割と存在し中々何度も実行したり調整して試したり・・・といった対応が難しい状況になっていました。
普通は連想できないところで密結合になっていてデグレしやすい状態になっていた
このプロジェクトを引き継ぐ前までの経験からはあまり連想できない感じで一見関係の無い箇所が実は密結合になっており、デグレして初めて「え、なんで〇〇と××が影響しあっているの・・・?」というケースに何度か遭遇しました。
その辺の実装がコードからも推察がしにくく初見の時は書いた本人以外これは気づくのが無理なのでは・・・と思われる点が色々残っていました。
メモリリークなどをしていたり、動かしたら死ぬ機能などがあった
特定の機能を動かすと盛大にメモリリークしてサーバーが段々死んでくる(もしくは1回動かすと死ぬ)・・・といった箇所がちらほら見受けされている状態でした。
今までの経験的にDjango、AWSなどを触ったことがなく苦戦
引き継いだ当初は今までデザイナーやらゲームクライアントのエンジニアなどをしていた期間が長かったのでDjangoやAWSなどを自分では触っておらず、且つプロジェクトが自分一人となったため知らないことだらけの状態からのスタートとなりました(当時からPython自体は少しは書けましたが・・・)。
今までに改善してきたこと
前述の通り色々と厳しい状況からのスタートでしたが泣き言を言っていても改善しないので、引き継いだ後に様々な点を改善していっています。以降の節ではそれらの改善について触れていきます。
そもそもの自分の知識とスキル面での改善
引き継いだ当初はプロジェクトの作業者が自分一人で、且つ過去の自分のスキルセットとのミスマッチ的に知識が足りてなくてきつい・・・という感じだったのでまずはたくさん勉強を行いました。
申請すれば技術書などはスムーズに会社に買っていただけるので必要そうな様々な本をご購入いただき、業務時間などに消化していきました。
レガシーなプロジェクトではありましたが、前向きに考えると中々1人で色々やる&知らない技術ばかりの環境に飛び込む機会はあまりなく、この時期は非常に勉強になったと記憶しています。
ほぼ全てのコードに対するテストの追加
テストが整備されていない状態で作業を続けてもデグレは続くでしょうしリファクタリングなども厳しい・・・ということで単体テストを中心にテスト関係を割と早い段階で追加や整備を進めていっています。
ただし前節までに触れた通り読んだり内容を把握するのが厳しいコードが大半だったのでテストの追加にはかなり苦戦しています。良く言われる「テストが書かれていないコードに途中からテストを追加するのは非常に難しい」という話にも近いものがありますが、仕様の資料なども残っておらず認知的複雑度や行数の多い関数などへのテストの追加はかなりきつい・・・というのを身をもって経験しました。
結局スプラウトメソッド的にごく小さい範囲で処理を別の関数に切り出して、そこにはテストを必ず書く&小さい範囲なのでそこだけはしっかり内容や挙動を把握する&後述するdocstringなども必ず書く&切り出した関数はごく認知的複雑度の低い関数になるべくしておく・・・といった作業をひたすら繰り返してコード全体的にテストを追加していっています。
※スプラウトメソッドなどに関しては必要な場合以下の書籍や記事などをご参照ください。
これはかなり長丁場となり、他の作業も並行していたのでほぼ全てのコードにテストが追加となるまで年単位でかかっています。
なお、この辺は賛否あると思いますが基本的にはprivate相当の関数などに関してもテストを書く形で進めています。
Rustとかと同様にPythonでも別にprivateのものに対してテストが書きづらいといったことは発生しにくいのと、細かく挙動を確認して少しずつ進めたい・・・という感じだったのと、スプラウトメソッド的に細かく関数を分割していく場合それらの大半はprivate相当になるというのもあります。public相当の関数にまでテストが書き終わってprivateの方で重複したテストパターンとかは消したりパターンを減らしたりするケースもあります。
個人的にはテスト時間が気にならなければそのまま残すケースが多いです(テストが引っかかった時に細かくテストが各関数に書かれていた方が問題の箇所の特定が短時間に終わるように感じているというのもあります)。
少し前に読んだ以下の記事に感覚が少し近いかもしれません。
プライベート関数に対するテストも気にせずに書く。自分の思ってる通りに動いていることをチェックしながら進みたい
ある程度実装が進むと、プライベート関数に対するテストが、パブリック関数に対するテストでカバーされることが多いので、そうなったらプライベート関数に対するテストは削除してしまう。でも、パブリック関数に対するテストだけだと細かいケースが確認しきれなくて不安だなってときは、その不安を解消できる分だけ残す
全体的なコードで認知的複雑度が低くなるように細かくリファクタリングやリプレイス
スプラウトメソッド的に関数を分割・テストを加えたりを繰り返していると元の複雑で読むのが厳しかった関数もじわりじわりと内容がシンプルになって認知的複雑度が下がったり読みやすくなったりしてきます。
こうなってくると元の関数の内容も把握しやすくなってくる(関数を分割していく過程で分割した部分は内容把握ができているのと、元の関数側も複雑度が下がってきている)ので、元の関数に対してテストを追加したりリプレイス・リファクタリングなどもできるようになってきます。
今回のレガシープロジェクトではこのような関数分割(+テストなどの追加)を繰り返した後、最終的に元の関数も改善する・・・という作業をひたすら繰り返していっています。
(こちらもコード量や機能数的に長丁場となり、全体的に終わるまでは年単位でかかっています・・・)
状況にもよりますが、基本的にゼロベースから作り直すというのはうまくいくケースもあるとは思いますが悪手になりがち・・・という点も加味し、ゼロベースで書き直したりはせずに上記のような細かい改善を繰り返し、細かくデプロイして様子を見る・・・としています。ゼロベースだと既存の利用ユーザーに迷惑がかかりがちなのと、自分1人での担当で資料も残っていない状態で最初からリプレイス・・・とすると前轍を踏むだろう・・・と判断しています。
(まあ読みづらいコードに対して作業しているとゼロベースから書き直したい・・・と感じたことは1回や2回ではありませんが、そこはぐっと抑える形で・・・)
この辺りは色々な方が過去に記事にしているので深くは触れずにリンクだけ貼っておきます。
各種Lintの導入
引き継いだ当初はLintがまったく導入されていませんでしたが、コードの統一感の確保やコードレビュー時の工数節約、デプロイ前の各種チェックなどによる安全面の強化のために各種Lintも途中で追加していっています。以降の節では導入した各種Lintについて触れていきます。
なお、チェック用のLintのみであれば悪影響はほぼ発生しませんがフォーマッタなどに関しては稀に悪影響が出るケースもあります。
そのためLintの導入は小出しにテストが追加となったモジュールを中心に各モジュールで少しずつチェック対象にしていって、少しずつデプロイして様子を見る・・・という作業を繰り返し行い、最終的には現在はデプロイ前には一通りのコードで通す・・・という形になっています。
isortのLintの導入
isortは外部モジュールのimportの順番やフォーマットを設定通りにしてくれるフォーマッタです。
GitHub:
Python公式のコードのスタイルガイドのPEP8ではimport関係について以下のように書かれています。
import文 は次の順番でグループ化すべきです:
- 標準ライブラリ
- サードパーティに関連するもの
- ローカルな アプリケーション/ライブラリ に特有のもの
この辺りのルールを守る場合、手動でやっていると結構面倒です。レビューで指摘するのも不毛です。そのためこの辺はisort任せで楽をしています。
設定として、1つのimportで行を分ける(1つの行に複数のimportをコンマ区切りなどで入れたりはしない)形と後述するblackのLintと合わせるための設定を行っています。
※その辺りは以下のblack移行時の記事でも以前触れているので必要に応じてご参照ください。
flake8のLintの導入
flake8はPEP8のコードスタイルに準拠しているかどうかをチェックしてくれるLintです。
GitHub:
※PEP8に関してはPython公式の資料や以前記事にしたりもしているため必要な際にはそちらをご参照ください。
こちらもコードレビューなどで指摘するのも不毛ですし、入れておくとPEP8の理解が浅かった点が改善したりなどに繋がるため入れています(新しい方が入られた時にもその辺のPEP8の説明などをがっつりやらなくてもflake8任せで良くなります)。
設定として、blackと1行の長さが競合するのでその辺の調整や一部のチェックのみ無視する設定にしています。black関係については必要に応じて以下の記事などをご確認ください。
numdoclintのLintの導入と全コードへのNumPyスタイルでのdocstring執筆の強制化
docstringはPythonの関数やメソッド、クラスやモジュールなどに設定できるコードドキュメントです(JSDocなどのPython版)。
個人的にはdocstringがしっかりと書かれているかどうかでコードの内容把握までにかかる時間がぐぐっと短縮できます。
コードの資料は別のファイルなどにするよりもなるべく実装に近いところにまとまっていると実装とずれにくく好ましいところではあります。VS Code上などでの作業も快適になります。また、数か月~数年といった期間が経過すると自分で書いたコードでも内容を忘れがちです。そのため基本的に全ての関数とメソッドに対してdocstringを追加する形で対応しています。
docstringの書き方のスタイルはいくつかありますが、本記事のプロジェクトではNumPyスタイルで統一しています。
※NumPyスタイルのdocstringに関しては以前記事にしているため必要に応じてご参照ください。
また、NumPyスタイルのdocstringの記述を漏れなく行ったり引数内容などとずれないことをチェックするためのnumdoclintというLintを自前でさくっと作って使用しています。人の手によって気を付ける形だと書き忘れたりするので結構助かっています(なんだかんだ何年も継続使用しています)。
mypyとPyrightによる型チェックの導入と全コードへの型アノテーションの追加
型のチェックがあるとやはり大分安心できます。デプロイ前に事前にミスに気づく・・・といったことも多いですし、VS Code上などで作業していてリアルタイムに型のチェックがされる・・・というのは作業効率的に快適に感じています(コンパイル → 型のエラー・・・と繰り返すよりも早く問題に気づけて快適です)。
私は普段の作業ではVS Code上でPylance(内部ではPyright)、デプロイ前にはmypyとPyrightのチェックが実行される・・・といった形にしています。
元々のプロジェクトのコードでは型アノテーションが皆無でしたが、今は全てのPythonコードに型アノテーションが追加されており色々と安心感を確保しつつ作業できています。コード量が多くなってきたりもしくは長期保守するのであればやはり型があると安心できます。
参考記事:
フォーマッタでのautopep8のLintの導入とその後のblackへの移行
コーディングスタイルをPEP8をベースとしていたのでフォーマッタに関しては最初autopep8を導入しました。これはこれで快適に年単位で使わせていただいていたのですが、その後Python界隈のフォーマッタが大体blackになってきた感じがあったのとプライベートのプロジェクトで先にblackを導入してみたところ好印象を持ったので途中でblackに移行しています。
この辺は以前blackの所感を記事にしているので必要に応じてそちらもご確認ください。
Python2系から3系への移行
引き継いだ当初はPython2系でした。過去にPython2系を触っていた方はご存じだと思いますがPython2系はかなりきついです(特に文字列周りなどで煩雑だったりで、ライブラリ内の処理でも文字列関係で地雷を踏んだりして結構きついです)。
プロジェクトを引き継ぐまではほぼ3系しか触ったことが無かったレベルだったので2系と3系の開発体験の差を今回のプロジェクトで強く感じました。
一方で2系と3系では互換性の無い箇所が多く3系にしようとしてもかなり影響範囲が大きい感じで大変です。
想定される悪影響を加味して3系移行は最初諦めて、先にテストを全体的に追加したりコード内容の把握や仕様の把握などが全体的に対応が終わるまで移行を見送っています(テストなどが無いと悪影響が非常に多く発生しそうだと判断しました)。
最終的にはPython2系のEoLのタイミングは少しオーバーしましたがそこまで期間を大きく空けずに3系移行を行うこともできました。切り替えてみた後に若干の悪影響は発生しましたが許容範囲の軽度な影響で済ませることができました。
※移行時のものは記事にしていますので興味がある方はそちらもご確認ください。
UIの全体的な刷新・UXの改善
引き継いだ当初は過去の担当者の方はデザイナーの方はおらずUIをよく触るフロントエンドやゲームクライアントのエンジニアの方・・・というわけでもなかったようで、デザインやUI・UXが微妙でした。
使い勝手が良くないとかレイアウトが崩れているとかデザインが微妙に感じる・・・とかが大分気になっていたのでこの辺は少しずつ差し替える形でUIを全体的に刷新しました。
エンジニアの身ではありますが会社的にAdobe CCとかの各種デザインツールも使わせてくださっているのでその辺のツールとかで作業しつつ諸々を上長と相談しつつ対応しています。
開発環境のVirtualBoxからDockerへの移行
引き継いだ当初は開発環境がVirtualBoxでした。複数人での作業など含め結構これだときつい・・・という感じだったのでこの辺はDocker移行しました(インフラなどに弱くDockerもは良く分からない・・・という感じだったのでその辺も勉強しています)。
開発環境のイメージ共有や起動時間など含め移行してみて大分快適になりました。
※移行当時の勉強したものなどは以下に記事にしています。
EC2上で動いていたMySQLのAurora移行とバージョンアップ
EC2上で古いMySQLが動いていたのですが、人数が少ないので保守が楽なものにしたいという点もあったり1台構成で負荷で問題なくともたまに不安定になっていた点、あとは使っているMySQL自体も古かったのでMySQL8系に移行すると共にAuroraのGraviton2のインスタンスへと移行しました。
今のところ極端な負荷がかかった日を除けば安定してくれている(移行前に稀に発生していた不安定になるケースが無くなった)のと、Auroraの各種便利機能などで楽ができたりと移行してみて大分満足感が得られる結果となりました。
多くの部分のデータのAthenaへの移行
他の会社様だとデータ関係はBigQueryとかを使うケースが多いと思いますが、弊社の場合他部署も含めてほぼほぼAWSで統一されています。
そこで、大き目のデータに対するクエリやら分析やら加工やら・・・で扱うデータの大部分をAWSのAthenaに移行しました。
SQLの内容次第では遅くなるケースもありますが、基本的な使い方ではかなり高速に動作してくれている点、安い点、サーバーレスで保守が楽な点などから大分気に入っています(今まで使っていたものがパフォーマンス的にも厳しかったというのもありますが・・・)。
ただし集計処理とかは昔からのものがまだまだ移行しきれていないので少しずつこの辺もAthenaとかのサーバーレスのものの比重を増やしていきたいところです。
※Redshiftなどもサーバーレス版が出たのと、Redshift側の話題の方がAthenaよりも多い・・・という印象を受けているのでそのうちRedshiftとかも併用しても良いかも・・・と思っています。ただしキャッチアップ出来ていないので先に講座なり本なり買って勉強が必要そうです。
ドキュメントのSphinx化とコードやDBが絡むドキュメントの自動同期化
Pythonプロジェクトということもあり、ドキュメント関係にSphinxを導入しました(Python公式やNumPy、Pandas、scikit-learn、boto3などの有名なPythonプロジェクトでも使われているケースが多いので合わせました)。
リポジトリ内でVS Codeとかでマークダウンで書く形で対応ができるのと、リポジトリ内のコード定義などとの連携やスクリプト制御なども色々楽なので気に入っています(ドキュメント同期を自動化すべき箇所をDocumentation as Code的に扱うなど)。
レガシープロジェクトを引き継いで得られた知見やメリット
世の中のよく見かけるキラキラしたプロジェクトとかと比べると大分泥臭く地味な改善とかをちまちま積み上げてきている・・・という感じで多くの方からは敬遠されそう(?)なため、メリットも得られているよという点にも以降の節で色々触れておきます。
※別にレガシープロジェクトでなくとも得られるメリットに関しても触れていきます。どちらかというと「今回のプロジェクトで」得られたメリットという側面が強めです。
触る対象の大半がほとんど触ったことのない技術ばかりだったので非常に勉強になった
引き継いだ当初では使われていた技術の大半がほとんど触ったことの無い技術が多くなっていました。
引き継いだ直後は担当が自分一人であり全部勉強する必要が出てきたため大変ではありましたが一方でかなり色々と勉強になった気がします。
少人数での作業なので改善や移行先の技術などで多くの裁量をいただいている
1人か2人でのチームとなっている点(現在2人体制ではありますが、もう1人の方は兼務気味な形になっています)や上長は役員の方のみ・・・となっているため改善作業でのタスクの判断や移行先の技術選定など諸々の判断の裁量はいただいている感じになっています(仕事自体は非常にやりやすいと感じています)。
2枚のピザルールじゃないですが、やはり少人数チームというのは快適です。以前所属していた部署では30分に1度くらいの頻度で口頭でのやりとりが発生したりしており、中々集中してコードが書けない・・・という感じでしたが、今の環境はほぼほぼテキストチャットの非同期コミュニケーションで事足りており口頭MTGは数か月に1度あるか?程度になっています。ほぼほぼの時間を手を動かす作業などに充てられるのは非常に助かっています。
長期的に自分で保守することで得にくい学びを得られている
和田卓人さんの質とスピードのスライドで書かれているように、長期的に自分で実装したものを自分で長い間メンテする・・・という機会に恵まれます。変な実装・可読性の悪いものを追加してしまうと長期の少人数チームなのでしっぺ返しがそのまま自分に返ってきます。
頻繁に異動が入ったり、自分で書いたコードを他人が保守する・・・というケースだと中々得にくい経験だとは思います。
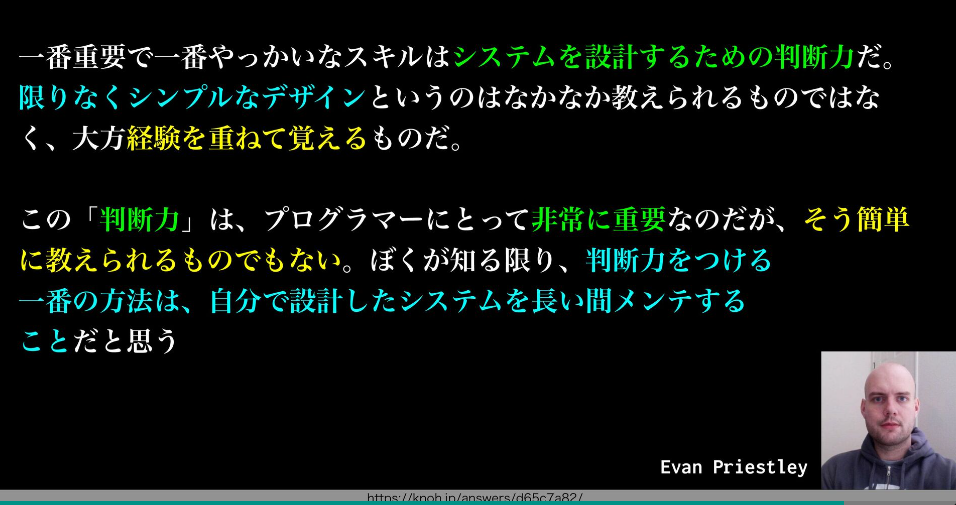
※質とスピード(2022春版、質疑応答用資料付き)のスライド99ページから引用。
工夫していることや配慮したこと
以降の節では本プロジェクトで工夫している点などを何点か触れていきます。
プライベートのライブラリ開発と相互に試したものなどを導入
似たような技術を使っているPythonのプライベートのapyscというライブラリプロジェクトも趣味で書いていっています。
プライベートの方は新しいライブラリ等も積極的に試したりしています(技術選定をミスしても仕事に悪影響が出たりもしないため)。そちらで一定期間新しく導入してみたものなどを試してみて、良さそうだ・・・と思ったら仕事側のプロジェクトでも使い始める・・・といったことをしています。
こうすることで仕事への悪影響を抑えつつも新しいものを仕事とプライベート両方で使っていける・・・という感じになっています。プライベートの方のプロジェクトで気軽な失敗を色々と積み重ねられるというのもポイントです。
一気に全面的なリプレイス(作り直し)を行うという判断は回避
前節までで触れた内容と被りますが、引き継いだ当初とかで顕著だったのですがあまりにコードを読むのが厳しく何度も「これゼロベースで作り直した方が良いのでは・・・?」という考えが頭をよぎりました。
一方で既存のユーザーに対して影響が出る点、作り直しが終わるころにはまた色々負債や選定ミスなど出てきていそうという点や同じ地雷を踏み抜きそうといった点などを加味してゼロベースからの作り直しはせず、且つなるべくユーザーへの悪影響を出さない形で少しずつ改善・・・と進めています。
今後直したり改善しないといけない点
以降の節では今後直したり改善したい点などについて触れていきます。大分長期プロジェクトになってきているので改善したい点も山積みです。
※全体的にインフラ・クラウド関係が弱めでその辺の改善点が色々残っていたりしています・・・(ちょっとずつ勉強してキャッチアップしなければ・・・という感じが・・・)。
サーバーレスやマネージドサービスの比重を増やす
サーバーレスのAthenaであったりマネージドのAuroraなどもそうですが、使ってみるとやはり運用が楽だったり負荷面で考えることがぐっと減ったりとメリットが多く感じています。
引き継いだ当初ではEC2で全て動いていましたが、段々とその辺のサーバーレスやマネージドのものも勉強をして比重を高めていきたいところです。
残っているEC2もインスタンスタイプが古いのでGraviton 2(もしくは3)などへの移行
既存の全てのEC2は全部はサーバーレスなどへの移行は厳しいと思っており、EC2も併用する形に落ち着きそうとは思っています。
しかし既存の使っているEC2はインスタンスタイプが古いままなのでGraviton 2などのインスタンスタイプへの移行を進めたいと考えています(コスト効率なども加味し)。
※移行を進めるころにはGraviton 3が東京リージョンでも色々使えるようになっているかもしれません。
CentOSベースのOSが使われているのでUbuntuなどのDebian系への移行
Python関係のプロジェクトだとLinuxの場合大体はUbuntuもしくはDebianなどのDebian系が多いと感じています。世の中のPythonライブラリ関係に関してもDebian系前提でドキュメントなどが書かれているケースが多く感じます。
世の中のシェア的にもDebian系が多くなってきている印象で、(今後のネット上の記事などの増加面などを加味し)マジョリティに合わせたい・・・という気はしているため、CentOSベースのOSからDebian系への移行をそのうち考えたい・・・とぼんやり思っています。
crontabからAirflowなどへの移行
定期実行処理が旧来のままでcrontabが現在使われています。ジョブの定義自体はコードで管理・同期されているものの、ジョブ間の依存関係やエラーになった際の影響範囲の確認などの面でできればAirflowなどに移行したい・・・と考えています(もしくはStep Functionsなどを勉強してそちらに)。
IaC対応
そこまで新しいインスタンスなどが追加になる・・・というモードでもないのですが、引き継いだ当初のままでIaC対応なども進んでいないのでその辺もそのうち整備したいところです。とりあえず社内ではサーバーとしてはAWSしかほぼ使われていないのと他のプロジェクトではCloudFormationを使われている方が多いので困ったら相談できるだろう・・・ということでTerraformではなくCloudFormationの方を講座を消化したので折を見て少しずつ利用をスタートしていきたい・・・というところです(社内のクラウドなどを管理されている方に権限調整なども相談しているのでその辺も今後・・・という状態です)。
古くなっているライブラリなどのアップデート
悩ましいライブラリアップデート問題があります。結構手間になるのとチームメンバーもごく少ないので悩ましいところです。
できたらライブラリアップデートがされてもテストなどが通る・・・のであれば自動もしくは最終確認だけしてアップデートをそのまま本番に反映する・・・的になるべく楽ができる体制にしたい・・・ところではあります。
悩ましいこと
以降の節で色々と悩ましく考えている点について触れていきます。
エンジニアのリソースが足りていない
他社様も含めどこもエンジニア不足は顕著ですよね・・・という感じなのでうちだけの問題ではないのですがエンジニアが足りていません。チームで1人か2人の少人数(もう一人の方は他のプロジェクト兼務)で作業している点、私も他のプロジェクトのヘルプを依頼されることも多い(他のチームも人が足りていない)のでプロジェクトに割くエンジニアリソースの不足が顕著です。
リソースが不足すると中々改善も機能の追加・不具合修正なども色々厳しい感じではあります。
この辺はメインのゲーム開発プロジェクト側にエンジニアリソースの大半が割かれるのは会社として正しい判断(新規ゲーム開発に3~5年とかかかるケースが多くなってきている点や、新規ゲームがリリースできないと会社の売り上げ的に厳しい)なので、むしろしょうがないかなという印象です。エルデンリングくらいの大きなゲームでも4人で運用・・・とかになっていると記事で読んだので、うちだけではなく世の中のゲーム会社さんの多くはそういった感じで新規開発に人を割いているのではないでしょうか(むしろ1~2名割いていただけているだけでも御の字という感じも)。
リリース後はわずか 4 名の自社要員で安定した運用を継続しています。
...
現在、『ELDEN RING』 のサーバーチームは、約 4 名体制で運用しています。エンジニアは複数のゲームタイトルの運用を兼ねているため、1 つのゲームに十分なリソースを割くことはできません。そのため、マネージドサービスによって得られる恩恵は大きく、スピーディな開発と安定的な運用を実現しています。
※先日上長と少しやりとりしていて、人が増えるかも・・・という気配があったのでその辺は自然と今後改善する可能性があります。
トラックナンバーの低さ
前節の通りメンバーが1人か2人で運用してきているためトラックナンバーが1か2にしかなりません。できたら3とかになると無難なところではあります。
とはいえこの点は私ではどうしようも無いので人を増えるのを期待するか、もしくはそもそも私ももう10年以上今の会社に居る気がするのと今のプロジェクトを停止するという会社の判断が下らない限りは今の会社に居ると思うためとりあえずはトラックナンバー低くても何とかなるか・・・という感じではあります(他のチームもトラックナンバー低いでしょうし)。
万一事故などで勤務不可となってももう一人の方が何とかしてくださるでしょうし、仮になんとかならずにプロジェクト停止となっても社内用なのでまあ直接的な売り上げへの悪影響は即時では出にくい感じでもあります(色々不便にはなるとは思いますが、なんらかの要因で勤務不能になったら即時で会社側で人員削減が必要になるといったプロジェクトでも無いかなと)。
色々キャッチアップしたい(勉強したい)ことが山積みになっている
自分で広範囲を色々触る必要があるため使う技術も様々です。新たに学びたいことも山積みですがその辺のキャッチアップが追いついていません。OSS活動的にライブラリ開発にプライベートの時間を割いていても中々時間が持っていかれてしまいます。
この辺はずっと勉強が足りない・・・という感覚なのでもはや延々とこの状態なのではという感じではあります・・・w(あまり気にせずに長期的に持続可能な程度で・・・で良いのかもしれませんが・・・)
同僚の方に現在コードは読みやすくなっているか聞いてみた結果
ふとこの記事を書いていて気になったので、今まで色々コード改善などをやってきた結果「コードは読みやすくなっているか」を同僚の方に聞いてみました(自分だけでなく少し客観的な意見が欲しいというのもあり)。
フィードバックとしては「コードは読みやすくなっている」「しいて改善点を上げるなら全体像を把握するのに時間がかかるのでその辺を理解するための仕組があると良いかも」といった感じでした。
コードの読みやすさに関してはポジティブな意見をいただいたものの、コード量的にも全体像の把握の負担が・・・といったところでしょうか。
全コードに対してdocstringなどで詳細なコードドキュメントは書いていたり、都度各種資料も書いたりはしていますが年数の長いプロジェクトでどうしてもコード量も多くなってきたりもしているのでその辺の内容把握がしやすい仕組みは要改善・・・といったところです。処理の流れの把握のしやすさはAirflow導入とかである程度改善するかもしれませんが、その他の改善などはどうするのが良いのか少々悩ましいところではあります。
その辺りは今後の改善点の1つとして頭に置いておこうと思います。
あとがき
良い機会だったので色々とまとめてみたり抱えている問題なども書き出してみましたが、個人的な良い頭の整理としてのアウトプットになった気がします。上長や同僚の方に向けても共有としてチャット上に流しておこうと思います。
まだまだ問題は山積みですしプロジェクトが続く限りずっと問題は無くならないとは思いますが、来年以降も少しずつ改善をやっていきたいところです。頑張っていきましょう🔥
参考文献・参考サイトまとめ