今まで複雑なデータ操作・分析などはPythonでやっており、SQLは普通のアプリ開発程度のライトなものしか触って来なかったのですが、やはり分析用の長いSQLなども書けた方がやりとり等で便利・・・という印象なので、復習も兼ねて記事にしておきます。
また、SQLに加えて検算も兼ねてPythonやPandasなどを使ったコードもSQLと併記していきます(Pythonで書くとどういった記述が該当するのかの比較用として使います)。
※長くなるのでいくつかの記事に分割します。本記事は6記事目となります。
他のシリーズ記事
Athenaとはなんぞやという方はこちらをご確認ください:
※過去の記事で既に触れたものは本記事では触れません。
#1:
用語の説明・SELECT、WHERE、ORDER BY、LIMIT、AS、DISTINCT、基本的な集計関係(COUNTやAVGなど)、Athenaのパーティション、型、CAST、JOIN、UNION(INTERSECTなど含む)など。
#2:
GROUP BY・HAVING・サブクエリ・CASE・COALESCE・NULLIF・LEAST・GREATEST・四則演算などの基本的な計算・日付と日時の各操作など。
#3:
文字列操作全般・正規表現関係など。
#4:
コメント関係・配列操作全般・ラムダ式など。
#5:
辞書(STRUCT, MAP, ROW)やJSON関係全般。
この記事で触れること
- 窓関数関係全般
環境の準備
以下の#1の記事でS3へのAthena用のデータの配置やテーブルのCREATE文などのGitHubに公開しているものに関しての情報を記載していますのでそちらをご参照ください。
窓関数
この節以降では窓関数(Window Functions)について全体的に触れていきます。窓関数はGROUP BYなどに少し似ていますが、特定の条件でデータをセットにして集計用などの関数を通したり、任意の日数分で行をひとまとめに扱って計算を行ったりすることができます。例えば移動平均値などを出す場合などに使います。
窓関数の基本
基本的な書き方は<対象の集計などの関数> OVER(<データの区切りの設定> <ORDER BYの設定> <フレーム設定>)となります。OVER内の各指定は省略されたりもします。それぞれ詳細は後述する各節で順番に触れていきます(ここでは基本のみ触れます)。
データの区切りはPARTITION BY <カラム名>といったように書きます。
例えば日付区切りにして(PARTITION BY dt)、salesカラムに対して合計値を出したい場合にはSUM(sales)といったように書き、SQLは以下のようになります。
SELECT device_type, dt, sales,
SUM(sales) OVER(PARTITION BY dt) AS summed_sales
FROM athena_workshop.total_sales_per_device_daily
ORDER BY dt, device_type

同一の日付のデータの売り上げの合計値のカラムをsummed_salesという名前で追加することができました(今回アクセスしたテーブルではdevice_typeというカラムの端末種別値ごとに各日で2行ずつ存在します)。
こうしてみるとGROUP BYに少し似ているように思えます。一方で、GROUP BYと異なりSELECTで指定できるカラムに制約が少ないですし、他にも独特な機能が色々あります(少しずつ触れていきます)。
Pythonでの書き方
Python(Pandas)で書きたい場合には基本的な書き方は以下のようになります。
- シリーズなどで
rollingメソッドを使うとRollingオブジェクトが返ってくるので、そのオブジェクトでさらにsumなどの集計関数を使うことで計算が行えます。 - 別カラムによるデータ区切り等に関してはPandasでスライスを行うことで対応ができます。
rollingメソッドにはさらに第一引数に窓のデータの個数の指定が必要になります。例えば3を指定すれば3行ずつのデータ区切りとなります。
また、集計関数などを挟んだ際に必要なデータ件数が確保できない行に関しては欠損値になったりします。例えば3行ずつのデータ区切りとした場合には1行目と2行目は必要な行数が確保できないので欠損値として表示されます。
from typing import List
import pandas as pd
date_range = pd.date_range(start='2021-01-01', end='2021-01-05')
dfs: List[pd.DataFrame] = []
for date in date_range:
df: pd.DataFrame = pd.read_json(
'https://github.com/simon-ritchie/athena_workshop/blob/main/workshop/total_sales_per_device_daily/'
f"dt%3D{date.strftime('%Y-%m-%d')}/data.json.gz?raw=true",
lines=True, compression='gzip')
dfs.append(df)
df = pd.concat(dfs, ignore_index=True)
ios_df: pd.DataFrame = df[df['device_type'] == 1]
rolling = ios_df['sales'].rolling(window=3)
summed = rolling.sum()
print(summed)
0 NaN
2 NaN
4 1038831.0
6 962325.0
8 963163.0
必要な行数が確保できないものの、少ない行数でも計算をしてしまいたい場合にはmin_periods引数に任意の整数を指定します。この整数以上の行であれば欠損値ではなく計算が実行されるようになります。
以下の例ではmin_periods=1と指定しているため、1行あれば計算されるので欠損値が無くなります。
from typing import List
import pandas as pd
date_range = pd.date_range(start='2021-01-01', end='2021-01-05')
dfs: List[pd.DataFrame] = []
for date in date_range:
df: pd.DataFrame = pd.read_json(
'https://github.com/simon-ritchie/athena_workshop/blob/main/workshop/total_sales_per_device_daily/'
f"dt%3D{date.strftime('%Y-%m-%d')}/data.json.gz?raw=true",
lines=True, compression='gzip')
dfs.append(df)
df = pd.concat(dfs, ignore_index=True)
ios_df: pd.DataFrame = df[df['device_type'] == 1]
rolling = ios_df['sales'].rolling(window=3, min_periods=1)
summed = rolling.sum()
print(summed)
0 368880.0
2 766560.0
4 1038831.0
6 962325.0
8 963163.0
窓関数での集計関数について
OVERの前に記述する集計関数(SUMやCOUNTなど)は一通り利用することができるそうです。
集計関数の他にもランキング関数や個別の値に対する関数などが窓関数では利用することができます。これらは別途後々の節で触れていきます。
Pythonでの集計関数について
Python(Pandas)での窓関数での集計関数はcountやsum、meanなど基本的なものに加えて他にも様々な関数が用意されていたり、applyで独自の関数やラムダ式などを指定できるようです。一覧に関して詳しくは以下のPandasのドキュメントをご確認ください。
PARTITION BYによるデータの区切り設定
PARTITION BYはGROUP BYによるグループ化のカラム指定と似たような挙動をします。両方ともキーワードの後にカラム名を指定します(例 : PARTITION BY date)。窓関数の処理はここで指定され、データ区切りが指定されたカラムに対して実行されます。
例えば端末種別(device_typeカラム)ごとに処理をしたい場合は以下のようにPARTITION BY device_typeと書きます。
SELECT device_type, dt, sales,
SUM(sales) OVER(PARTITION BY device_type) AS summed_sales_2
FROM athena_workshop.total_sales_per_device_daily
ORDER BY dt, device_type

省略した場合は全行が1つのまとまりとして扱われます。例えば以下のようにOVER内の記述を省略してSUM関数を使うと全行の合計値を取得することができます。通常の集計関数やGROUP BYなどを絡めた場合と異なり他のカラムなども同時に表示することができます。
SELECT device_type, dt, sales,
SUM(sales) OVER() AS summed_sales_2
FROM athena_workshop.total_sales_per_device_daily
ORDER BY dt, device_type

Pythonでの書き方
他にも色々やり方はあると思いますが、Pandasでやる場合は一例としてスライスしてしまうのがシンプルかもしれません。
特定カラム(シリーズ)のuniqueメソッドで一意な値が取れるので以下のコードではそちらでスライスを行っています。
from typing import List
import pandas as pd
import numpy as np
date_range = pd.date_range(start='2021-01-01', end='2021-01-05')
dfs: List[pd.DataFrame] = []
for date in date_range:
df: pd.DataFrame = pd.read_json(
'https://github.com/simon-ritchie/athena_workshop/blob/main/workshop/total_sales_per_device_daily/'
f"dt%3D{date.strftime('%Y-%m-%d')}/data.json.gz?raw=true",
lines=True, compression='gzip')
dfs.append(df)
df = pd.concat(dfs, ignore_index=True)
dfs: List[pd.DataFrame] = []
unique_vals: np.ndarray = df['device_type'].unique()
for unique_val in unique_vals:
dfs.append(df[df['device_type'] == unique_val])
print(dfs[0])
print(dfs[1])
date device_type sales
0 2021-01-01 1 368880
2 2021-01-02 1 397680
4 2021-01-03 1 272271
6 2021-01-04 1 292374
8 2021-01-05 1 398518
date device_type sales
1 2021-01-01 2 399620
3 2021-01-02 2 430820
5 2021-01-03 2 307029
7 2021-01-04 2 497826
9 2021-01-05 2 288582
ORDER BYによるデータ区切り内でのソート条件の指定
OVER内ではORDER BYでソートの指定を行うことができます。使い方は通常のORDER BYと同じような感じで、ORDER BY <カラム名>といったように指定していきます。降順にしたい場合には最後にDESCと付ける点も同様です。ただし通常のORDER BYと異なり、PARTITION BYによって区切られたデータの単位ごとにソートが実行されます。
以下のSQLでは日付別のデータの区切り(PARTITION BY dt)ごとに売り上げの降順でソート(ORDER BY sales DESC)を行っています。結果はFIRST_VALUEというデータの区切りの中で先頭の値を取得する関数を使っています(この関数については後の節で触れます)。
SELECT device_type, dt, sales,
FIRST_VALUE(sales) OVER(PARTITION BY dt ORDER BY sales DESC) AS first_value
FROM athena_workshop.total_sales_per_device_daily
ORDER BY dt, device_type
実行してみると、各日付内で一番高い売り上げの値がfirst_valueカラムとして設定されていることを確認することができます。

Pythonでの書き方
前節くらいのソートであれば、スライスを行う形でデータ区切りを設定する場合は事前にsort_valuesメソッドなどでソートするなどで対応ができます。元のデータフレームをそのまま保持したければコピーを取ったり、もしくはデータ区切り数が少なければスライス後のデータフレームに対してソートする形でもいいかもしれません。
from typing import List
import pandas as pd
import numpy as np
date_range = pd.date_range(start='2021-01-01', end='2021-01-05')
dfs: List[pd.DataFrame] = []
for date in date_range:
df: pd.DataFrame = pd.read_json(
'https://github.com/simon-ritchie/athena_workshop/blob/main/workshop/total_sales_per_device_daily/'
f"dt%3D{date.strftime('%Y-%m-%d')}/data.json.gz?raw=true",
lines=True, compression='gzip')
dfs.append(df)
df = pd.concat(dfs, ignore_index=True)
df.sort_values(by='sales', ascending=False, inplace=True)
dfs: List[pd.DataFrame] = []
unique_vals: np.ndarray = df['device_type'].unique()
for unique_val in unique_vals:
dfs.append(df[df['device_type'] == unique_val])
print(dfs[0])
date device_type sales
7 2021-01-04 2 497826
3 2021-01-02 2 430820
1 2021-01-01 2 399620
5 2021-01-03 2 307029
9 2021-01-05 2 288582
フレームの設定
フレームの指定は(PARTITION BYによる)データ区切りを設定した範囲のデータで、どの行を対象とするか・・・といった追加の条件を設定することができます。例えばデータ区切り内のデータで2行目~5行目を対象とするとか、数値が50~100の値のみを対象にするとか、もしくは対象行の値の前後2日間に該当する行のみを対象にする・・・といったような細かい制御ができます。
フレームの指定はORDER BYなどの後に記述します。基本的に行範囲の算出などの都合で行の順番が大切になってきたりもするのとAthenaではORDER BYを指定しないとクエリの度に行の順番が変わったりするためフレームを使用する場合はOVER内でORDER BYの指定を省略せずに指定する形が無難かと思われます。例えば<集計などの関数> OVER(PARTITION BY <カラム名> ORDER BY <カラム名> <フレーム設定>)といったように書きます。
フレーム設定には行範囲(例 : 対象のデータ区切り内の2行目から5行目など)を設定するROWSと値の範囲(例 : 前日~翌日の範囲を満たす行全てなど)を設定するRANGEの2種類が存在します。
ROWSもしくはRANGEの後には、開始値の設定のみを行う場合もしくは開始値と終了値の範囲の指定の2パターンが存在します。
例えば開始値側のみをROWSで設定する場合にはROWS <開始値の設定>といったように書き、開始値と終了値の範囲を指定する場合にはROWS BETWEEN <開始値の設定> AND <終了値の設定>といったようにBETWEENとANDが必要になります。
開始値と終了値の指定に関しては以下のように5パターンが存在します。
-
UNBOUNDED PRECEDING: 対象のデータ区切り内の先頭の行 -
<n行> PRECEDING: 現在の行からn行分前の行(ROWSの場合のみ使用可) -
CURRENT ROW: 現在行 -
<n行> FOLLOWING: 現在の行からn行分前の行(ROWSの場合のみ使用可) -
UNBOUNDED FOLLOWING: 対象のデータ区切り内の最後の行
<n行> PRECEDINGと<n行> FOLLOWINGという書き方は他のDB(MySQLやOracleなど)ではRANGEでも利用ができると書かれている記事があり恐らく使えるのですが、Athena(Presto)ではROWSでのみ使えるという記述がPrestoのドキュメントにあるためRANGEでは使えません。
色々要素が多いので、以降の節でSQLを実行しつつ個別に細かく見ていきます。
Pythonでの書き方
この辺のフレーム制御に関しては・・・色々やり方があってどんな対応だとシンプルになるか自信がありませんが、シンプルにn行ずつの処理が必要というケースであれば前節までで触れたrollingメソッドの引数で対応ができます。
他の要件が必要な場合にはapplyやループを回したりなど他の制御を使って色々と対応する必要が出てくるかもしれません。要件次第かなと思います。
現在行の値をCURRENT ROWで取ってみる
試しにCURRENT ROWを指定して現在行の値を取ってみます。現在行の値は窓関数関係を使わなくても取れるので以下のSQL自体は何かに使える・・・というものではないのですが、挙動の確認用となります。
なお、このCURRENT ROW単体での指定(BETWEENなどを使わない指定)では「開始値の位置」の指定となるため、先頭の行(現在行)のみを取得するためFIRST_VALUE関数を使っています。
SELECT device_type, dt, sales,
FIRST_VALUE(sales) OVER(PARTITION BY device_type ORDER BY dt ROWS CURRENT ROW) AS current_row_sales
FROM athena_workshop.total_sales_per_device_daily
ORDER BY dt, device_type
現在行の値(salesカラム)と窓関数で取った現在行の値(current_row_salesカラム)の値が一致していることが確認できます。
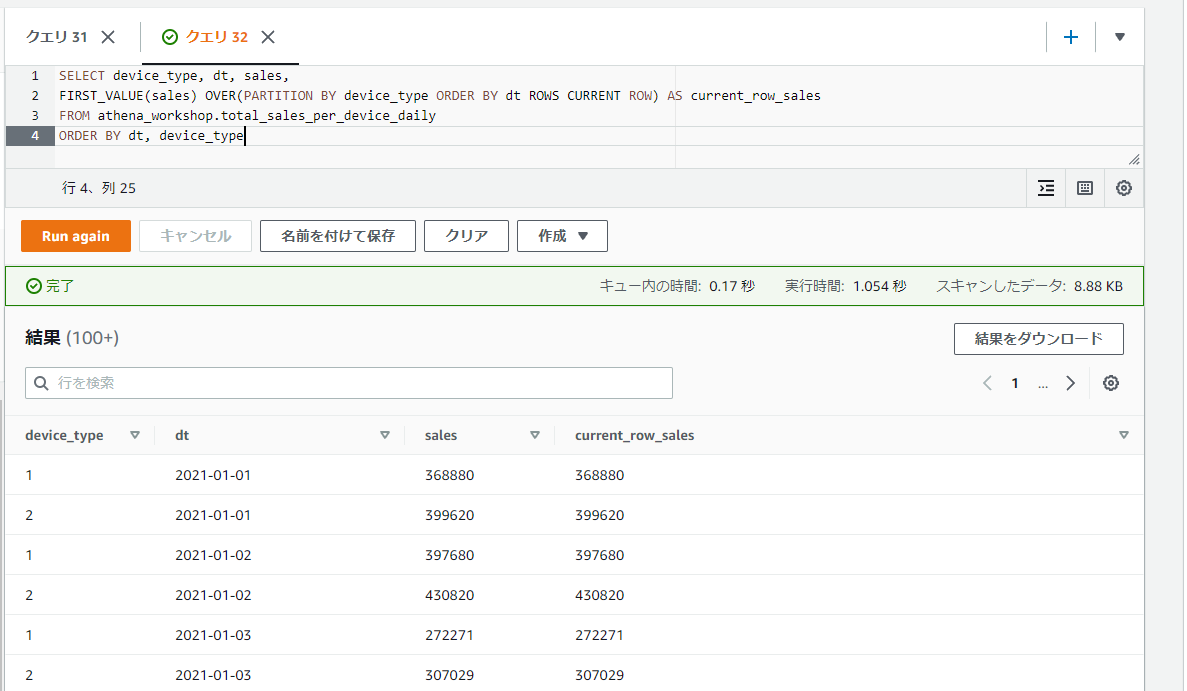
ROWS ... PRECEDINGを使って2行前の値を取得してみる
今度はROWS ... PRECEDINGを使って2行前の値を取得してみます。2行前の値を取りたいのでFIRST_VALUE関数とROWS 2 PRECEDINGという書き方を組み合わせています。
SELECT device_type, dt, sales,
FIRST_VALUE(sales) OVER(PARTITION BY device_type ORDER BY dt ROWS 2 PRECEDING) AS window_func_sales
FROM athena_workshop.total_sales_per_device_daily
ORDER BY device_type, dt
2行前の参照ができない1行目と2行目はどうなるのだろう・・・と思いましたが、どうやらそのような行ではNULLなどにはならずに遡れる位置の行の値が設定されるようです。例えば1行目であれば1行目の値、2行目であれば1行目の値、3行目であれば1行目の値、4行目であれば2行目の値・・・といったようになるようです。

ROWS UNBOUNDED PRECEDING で最初の行の値を取得してみる
こちらも特に何か分析に使う・・・というものでもありませんが、挙動の確認用にUNBOUNDED PRECEDINGでデータ区切り内の最初の行の値を取得してみます。
SELECT device_type, dt, sales,
FIRST_VALUE(sales) OVER(PARTITION BY device_type ORDER BY dt ROWS UNBOUNDED PRECEDING) AS window_func_sales
FROM athena_workshop.total_sales_per_device_daily
ORDER BY device_type, dt
この処理は特に違和感が無く、window_func_salesカラムの各行の値が最初の行の368880という値になっていることが確認できます。

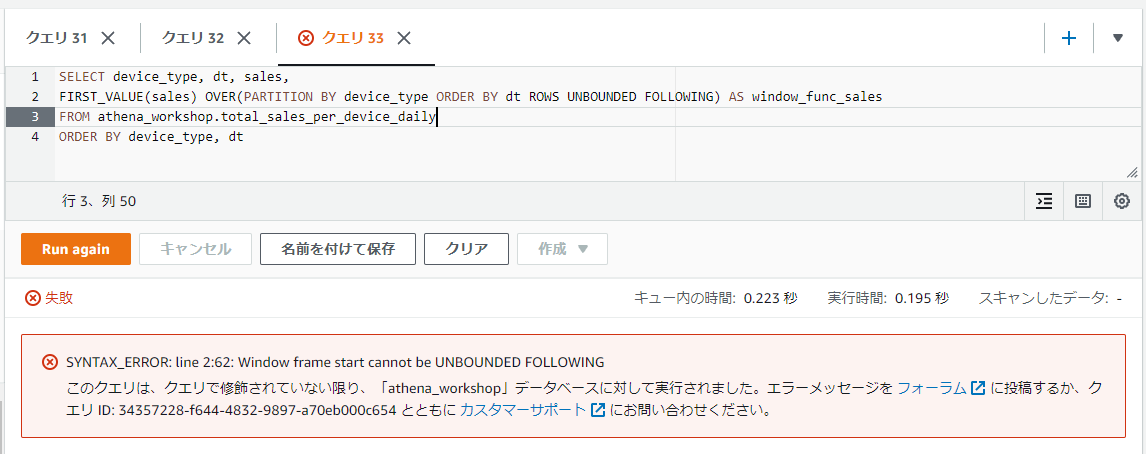
UNBOUNDED FOLLOWING はBETWEENとセットで使わないとエラーになる
UNBOUNDED FOLLOWINGはBETWEENと一緒に使わないとエラーになってしまいます。正確には範囲の終了値側(BETWEEN ... AND ...のANDの後)で使わないとエラーになります。
SELECT device_type, dt, sales,
FIRST_VALUE(sales) OVER(PARTITION BY device_type ORDER BY dt ROWS UNBOUNDED FOLLOWING) AS window_func_sales
FROM athena_workshop.total_sales_per_device_daily
ORDER BY device_type, dt
ROWS BETWEEN で前後の行も含めた合計を出してみる
ROWS BETWEEN ... AND ...で指定した行の範囲の合計を計算して挙動を確認してみます。この節のサンプルでは現在行に加えて前の1行分と後の1行分を対象とし、合計3行で計算するようにしてみます。
1行前を対象とするにはANDの前に1 PRECEDINGという記述が必要になり、1行後を対象とするにはANDの後に1 FOLLOWINGという記述が必要になります。また、合計を出すため関数部分をSUM(sales)としています。
SELECT device_type, dt, sales,
SUM(sales) OVER(PARTITION BY device_type ORDER BY dt ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING) AS window_func_sales
FROM athena_workshop.total_sales_per_device_daily
ORDER BY device_type, dt
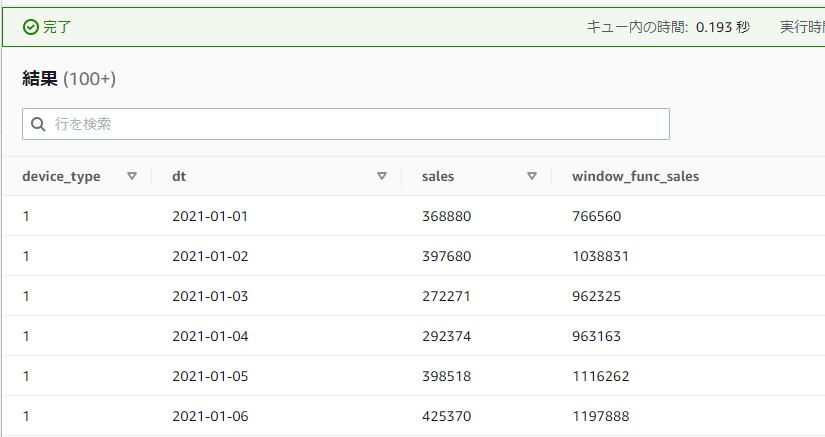
1行目を見てみると、1行目と2行目のみの合算となっており1行目のwindow_func_salesカラムの値だけ低くなっています。2行目からは1行目・2行目・3行目…といったように3行分の合計にちゃんとなっているようです。平均などであればあまり問題にはならなそうですが、PRECEDINGを使いつつ合計などを計算する場合には最初の方の行は要件によっては少し注意する必要がありそうです。
フレームのデフォルトの挙動
最初誤解していたのですが、ORDER BYを使った場合フレームの指定を省略した場合データ区切りの最初(UNBOUNDED PRECEDING)~現在の行(CURRENT ROW)という挙動になるそうです。データ区切りの終わりは最後の行にはならず現在の行で止まってしまうのでフレームの指定を省略する場合には注意が必要です。
紛らわしいことに窓関数内でORDER BYを使わなかった場合にはデータ区切りの最初(UNBOUNDED PRECEDING)~データ区切りの最後の行(UNBOUNDED FOLLOWING)になる・・・と挙動が変わるようです。うっかりしているとミスしそうなので毎回フレームを明示する・・・とかでもいいかもしれません。
試しにCOUNT関数で各データ区切り内の行数をカウントしつつフレームの指定を省略した場合、以下のようにPARTITION BYで区切った範囲でも各行数が一致せず下にいくほど行数が増えていっています。
SELECT device_type, dt, sales,
COUNT(*) OVER(PARTITION BY device_type ORDER BY dt) AS window_func_sales
FROM athena_workshop.total_sales_per_device_daily
ORDER BY device_type, dt

PARTITION BYで指定した区切りごとに各行数を統一したい場合(データ区切り全体で統一したい場合)はBETWEENによるUNBOUNDED PRECEDINGとUNBOUNDED FOLLOWINGでのフレームの指定が必要になります。
SELECT device_type, dt, sales,
COUNT(*) OVER(PARTITION BY device_type ORDER BY dt ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) AS window_func_sales
FROM athena_workshop.total_sales_per_device_daily
ORDER BY device_type, dt
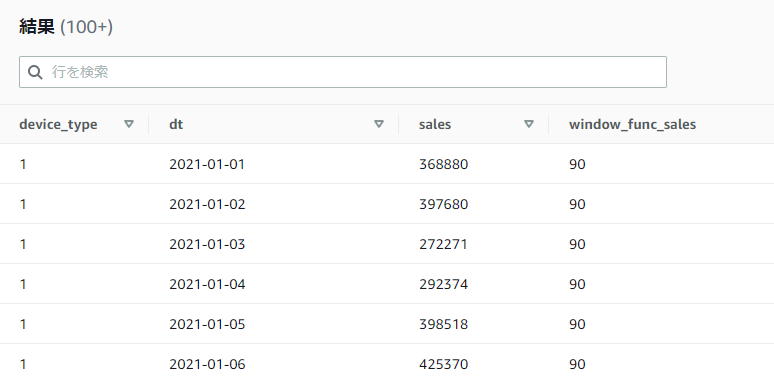
また、ORDER BYを窓関数内で使用していない場合には行数はフレームの指定を省略してもデータ区切り全体が対象になってくれます。
SELECT device_type, dt, sales,
COUNT(*) OVER(PARTITION BY device_type) AS window_func_sales
FROM athena_workshop.total_sales_per_device_daily
ORDER BY device_type, dt

移動平均を計算してみる
ここまでに学んだことを利用して移動平均を計算してみます。対象の日付に対して前方方向に7日分を対象として平均を取ります。例えば2021-01-07の日付であれば2021-01-01~2021-01-07の7日間の平均で計算されるようにします。
7日分の行を確保するには6日前~現在の行の日付という指定が必要になるためROWS BETWEEN ...を使い、開始行は6 PRECEDING、終了行はCURRENT ROWとなります。
SELECT device_type, dt, sales,
AVG(sales) OVER(PARTITION BY device_type ORDER BY dt ROWS BETWEEN 6 PRECEDING AND CURRENT ROW) AS window_func_sales
FROM athena_workshop.total_sales_per_device_daily
ORDER BY device_type, dt

2021-01-07の日付の部分を見てみると361299.0になっています。2021-01-01~2021-01-07で計算してみると(368880 + 397680 + 272271 + 292374 + 398518 + 425370 + 374000) / 7 = 361299.0となるので合っていそうです。
Pythonでの書き方
古いPandasバージョンではrolling_mean関数があったようですが、0.18.0のバージョン以降では切り落としになっているようです。
rolling(n).mean()とする必要があります。
from typing import List
import pandas as pd
import numpy as np
date_range = pd.date_range(start='2021-01-01', end='2021-01-14')
dfs: List[pd.DataFrame] = []
for date in date_range:
df: pd.DataFrame = pd.read_json(
'https://github.com/simon-ritchie/athena_workshop/blob/main/workshop/total_sales_per_device_daily/'
f"dt%3D{date.strftime('%Y-%m-%d')}/data.json.gz?raw=true",
lines=True, compression='gzip')
dfs.append(df)
df = pd.concat(dfs, ignore_index=True)
ios_df: pd.DataFrame = df[df['device_type'] == 1].copy()
ios_df.sort_values(by='date', inplace=True)
mean: pd.Series = ios_df['sales'].rolling(window=7, min_periods=1).mean()
print(mean)
0 368880.000000
2 383280.000000
4 346277.000000
6 332801.250000
8 345944.600000
10 359182.166667
12 361299.000000
14 354562.857143
16 343387.857143
...
RANGEでの<n> PRECEDINGや<n> FOLLOWINGはエラーになる
前節で少し触れたように、Athena(Presto)ではRANGEでは<n> PRECEDINGや<n> FOLLOWINGといったような数値や日付範囲の指定による書き方がサポートされていません。結構便利そうなのですが・・・。今後のPrestoなどのアップデートに期待です。
UNBOUNDED PRECEDINGやCURRENT ROW、UNBOUNDED FOLLOWINGなどはサポートされていますが、一方でそれらを使う場合はROWSを使っても同じことでできる?気がするので現状RANGEを使うケースがあまり無い・・・?感じも少ししています(ぱっと浮かばないだけで、良く考えたら何かRANGEじゃないと対応ができないケースがあるかもしれませんが・・・)。
たとえば以下のようにRANGEと<n> PRECEDINGなどを組み合わせて使ってみるとエラーになることを確認できます。
SELECT total_sales, power,
AVG(total_sales) OVER(PARTITION BY power ORDER BY power RANGE BETWEEN 1000 PRECEDING AND 1000 FOLLOWING)
FROM athena_workshop.user_total_sales_and_power
WHERE total_sales != 0
ORDER BY power
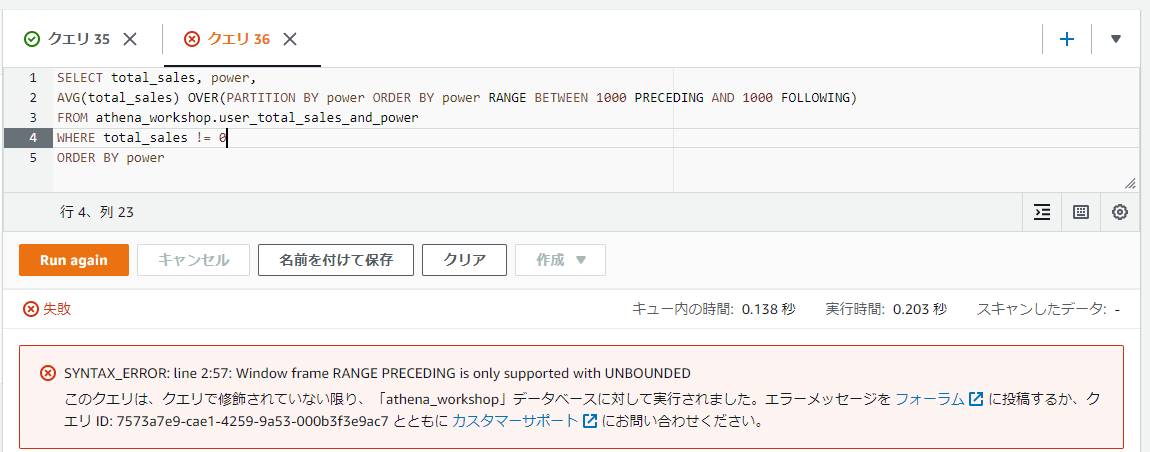
現状で特定の値の範囲でデータ区切りをしたい場合は、事前にWITH句や一時テーブル(中間テーブル)を作ったりして区切り用の種別のようなカラムを設けておいて、そちらのカラムをPARTITION BYで指定する・・・といった対応になりそうです。
窓関数で追加で使える関数
窓関数では前節までで色々触れてきたように集計用の関数(COUNTやSUM)などは一通り使えます。加えて窓関数専用のランキング関数(Ranking Functions)や単一値用の関数(Value Functions)が用意されています。この節以降ではそれらの各関数について触れていきます。
データ区切り内の先頭の値を取得する: FIRST_VALUE
前節まででも何度か先行して使っていましたが、FIRST_VALUE関数ではデータ区切り内で先頭の値を取得できます。
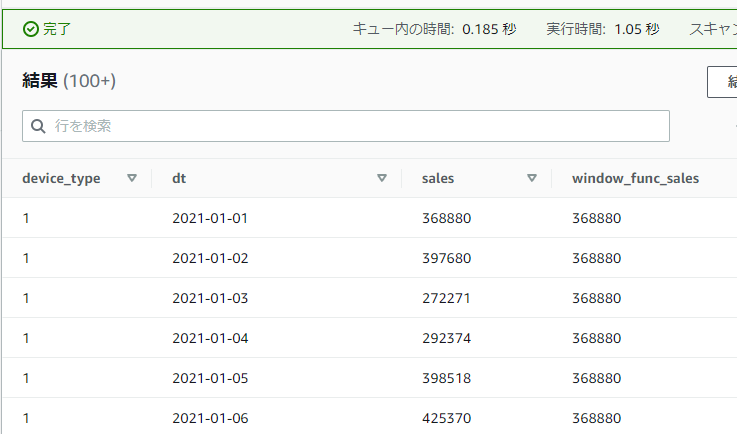
以下のSQLでは端末種別(device_type)ごとの売り上げのデータ区切りで、先頭の行の売り上げの値をFIRST_VALUE関数で取得しています。window_func_salesカラムの各値が最初の行の368880になっていることを確認できます。
SELECT device_type, dt, sales,
FIRST_VALUE(sales) OVER(PARTITION BY device_type ORDER BY dt) AS window_func_sales
FROM athena_workshop.total_sales_per_device_daily
ORDER BY device_type, dt
Pythonでの書き方
rollingメソッドの返却値はapplyメソッドを持っているのでそちらを利用して対応ができます。applyメソッドへは窓関数のデータ区切りごとのシリーズが渡されるので、x.values[0]といった記述で先頭の値が取れます(処理が遅いかもしれませんがx.iloc[0]などでも同じような制御にはなります)。
from typing import List
import pandas as pd
import numpy as np
date_range = pd.date_range(start='2021-01-01', end='2021-01-10')
dfs: List[pd.DataFrame] = []
for date in date_range:
df: pd.DataFrame = pd.read_json(
'https://github.com/simon-ritchie/athena_workshop/blob/main/workshop/total_sales_per_device_daily/'
f"dt%3D{date.strftime('%Y-%m-%d')}/data.json.gz?raw=true",
lines=True, compression='gzip')
dfs.append(df)
df = pd.concat(dfs, ignore_index=True)
ios_df: pd.DataFrame = df[df['device_type'] == 1].copy()
ios_df.sort_values(by='date', inplace=True)
first_vals: pd.Series = ios_df['sales'].rolling(
window=7, min_periods=1).apply(lambda x: x.values[0])
print(first_vals)
window=7としているので7行目までは同じ値(先頭の値が同じ)で、8行目から値が変わっていることを確認することができます。
0 368880.0
2 368880.0
4 368880.0
6 368880.0
8 368880.0
10 368880.0
12 368880.0
14 397680.0
16 272271.0
18 292374.0
データ区切り内の最後の値を取得する: LAST_VALUE
LAST_VALUE関数はFIRST_VALUE関数とは逆にデータ区切りの中の最後の行の値を取得できます。前の節で触れたように、窓関数内でORDER BYを指定した場合にはフレームの指定が無いとデータ区切りが最後の行までになってくれないのでその辺のフレームの指定(ROWS BETWEEN ...)を行っています。
SELECT device_type, dt, sales,
LAST_VALUE(sales) OVER(PARTITION BY device_type ORDER BY dt ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) AS window_func_sales
FROM athena_workshop.total_sales_per_device_daily
ORDER BY device_type, dt

Pythonでの書き方
FIRST_VALUEの節のPythonコードのapplyメソッド部分のインデックス参照を0から-1に変更するだけです。
from typing import List
import pandas as pd
import numpy as np
date_range = pd.date_range(start='2021-01-01', end='2021-01-10')
dfs: List[pd.DataFrame] = []
for date in date_range:
df: pd.DataFrame = pd.read_json(
'https://github.com/simon-ritchie/athena_workshop/blob/main/workshop/total_sales_per_device_daily/'
f"dt%3D{date.strftime('%Y-%m-%d')}/data.json.gz?raw=true",
lines=True, compression='gzip')
dfs.append(df)
df = pd.concat(dfs, ignore_index=True)
ios_df: pd.DataFrame = df[df['device_type'] == 1].copy()
ios_df.sort_values(by='date', inplace=True)
last_vals: pd.Series = ios_df['sales'].rolling(
window=7, min_periods=1).apply(lambda x: x.values[-1])
print(last_vals)
0 368880.0
2 397680.0
4 272271.0
6 292374.0
8 398518.0
10 425370.0
12 374000.0
14 321727.0
16 319455.0
18 283038.0
データ区切り内の任意の位置の値を取得する: NTH_VALUE
NTH_VALUE関数は引数に指定されたn番目の窓関数のデータ区切り内の値を取得します。第一引数には対象のカラム、第二引数に位置の整数を指定します。第二引数は1からスタートします。
以下のSQLでは第二引数に3を指定しているため、3行目の272271の値にwindow_func_salesカラムの値がなっています。
SELECT device_type, dt, sales,
NTH_VALUE(sales, 3) OVER(PARTITION BY device_type ORDER BY dt ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) AS window_func_sales
FROM athena_workshop.total_sales_per_device_daily
ORDER BY device_type, dt

Pythonでの書き方
FIRST_VALUEやLAST_VALUE関数の節のコードのインデックス参照でのインデックス指定を任意の整数値(n)に書き換えることで対応ができます。
例えば3番目の値であればPython(NumPy)ではインデックスが0からスタートするのでインデックスには2を指定します。
また、n番目の値が存在しなければnanを返却するようにしています。
from typing import Any, List
import pandas as pd
import numpy as np
date_range = pd.date_range(start='2021-01-01', end='2021-01-10')
dfs: List[pd.DataFrame] = []
for date in date_range:
df: pd.DataFrame = pd.read_json(
'https://github.com/simon-ritchie/athena_workshop/blob/main/workshop/total_sales_per_device_daily/'
f"dt%3D{date.strftime('%Y-%m-%d')}/data.json.gz?raw=true",
lines=True, compression='gzip')
dfs.append(df)
df = pd.concat(dfs, ignore_index=True)
ios_df: pd.DataFrame = df[df['device_type'] == 1].copy()
ios_df.sort_values(by='date', inplace=True)
def nth_value(x: pd.Series) -> Any:
n: int = 3
if len(x) < n:
return np.nan
return x.values[n - 1]
nth_vals: pd.Series = ios_df['sales'].rolling(
window=7, min_periods=1).apply(nth_value)
print(nth_vals)
0 NaN
2 NaN
4 272271.0
6 272271.0
8 272271.0
10 272271.0
12 272271.0
14 292374.0
16 398518.0
18 425370.0
現在の行から任意の行数だけ後の位置の値を取得する: LEAD
LEAD関数はNTH_VALUE関数に少し似ていますが、基準位置がデータ区切りの先頭ではなく現在の行になり、現在の行から第二引数に指定された整数分の後の行の値を取得することができます。
引数はNTH_VALUEと同じように第一引数が対象のカラム、第二引数がオフセット分の整数(いくつ後の行を参照するかの整数)となります。第二引数は0からスタートで、0を指定した場合は現在の行の値がそのまま返却されます。
以下のSQLではデータ区切り内で1行後の行の値を取得しています。
SELECT device_type, dt, sales,
LEAD(sales, 1) OVER(PARTITION BY device_type ORDER BY dt ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) AS window_func_sales
FROM athena_workshop.total_sales_per_device_daily
ORDER BY device_type, dt

また、第二引数を省略した場合にはデフォルト値として1が設定されます(1行後の値が取得されます)。
SELECT device_type, dt, sales,
LEAD(sales) OVER(PARTITION BY device_type ORDER BY dt ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) AS window_func_sales
FROM athena_workshop.total_sales_per_device_daily
ORDER BY device_type, dt
結果は第二引数に1を指定した時と同じになります。
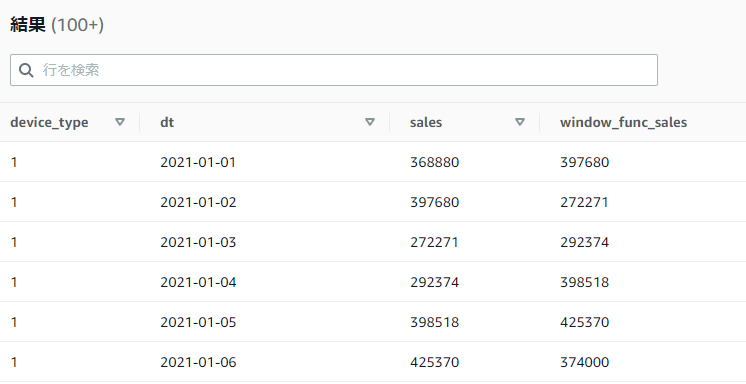
第三引数には値が取れない行に対するデフォルト値を指定することもできます(例 : 最後の行は次の行の値が存在しないためNULLとなるため、第三引数を指定しているとその値でNULLが補正されます)。この辺は次のLAG関数で説明がしやすいので触れていきます。
Pythonでの書き方
rollingを使わずにスライスでPARTITION BYのような制御をしたとして、例のごとく色々書き方はありますが数行後の値を取りたい場合の書き方の一例としては以下のコードでは
- データフレームのカラムにインデックスを設定する(事前に
reset_indexでインデックスをリセットしておく) - インデックスのカラムで
applyメソッドを使い、且つapplyメソッドではキーワード引数なども指定できるので対象の配列を指定する - n行後の行が存在すればその値、存在しなければnanを返却というように
applyメソッドで指定した関数内を実装する
といった形で対応しています。
from typing import Any, List
import pandas as pd
import numpy as np
date_range = pd.date_range(start='2021-01-01', end='2021-01-10')
dfs: List[pd.DataFrame] = []
for date in date_range:
df: pd.DataFrame = pd.read_json(
'https://github.com/simon-ritchie/athena_workshop/blob/main/workshop/total_sales_per_device_daily/'
f"dt%3D{date.strftime('%Y-%m-%d')}/data.json.gz?raw=true",
lines=True, compression='gzip')
dfs.append(df)
df = pd.concat(dfs, ignore_index=True)
ios_df: pd.DataFrame = df[df['device_type'] == 1].copy()
ios_df.sort_values(by='date', inplace=True)
def lead(index: int, values: np.ndarray) -> Any:
n: int = 3
if len(values) - 1 < n + index:
return np.nan
return values[n + index]
sales_vals: np.ndarray = ios_df['sales'].values
ios_df.reset_index(drop=True, inplace=True)
ios_df['index'] = ios_df.index
lead_vals: pd.Series = ios_df['index'].apply(lead, values=sales_vals)
print('original df:\n', ios_df)
print('lead values:\n', lead_vals)
original df:
date device_type sales index
0 2021-01-01 1 368880 0
1 2021-01-02 1 397680 1
2 2021-01-03 1 272271 2
3 2021-01-04 1 292374 3
4 2021-01-05 1 398518 4
5 2021-01-06 1 425370 5
6 2021-01-07 1 374000 6
7 2021-01-08 1 321727 7
8 2021-01-09 1 319455 8
9 2021-01-10 1 283038 9
lead values:
0 292374.0
1 398518.0
2 425370.0
3 374000.0
4 321727.0
5 319455.0
6 283038.0
7 NaN
8 NaN
9 NaN
現在の行から任意の行数だけ前の位置の値を取得する: LAG
LAG関数はLEADとは逆の挙動をする関数で、現在の行から第二引数で指定された整数分前の行の値を取得できます。
他の引数の構成や挙動はLEAD関数と同様です。第一引数は対象のカラム、第二引数に何行前の値を参照するかの値(デフォルト値は1で省略可)、第三引数は参照する前の行が存在しない場合の欠損値(NULL)の場合の補正値としてのデフォルト値となります。
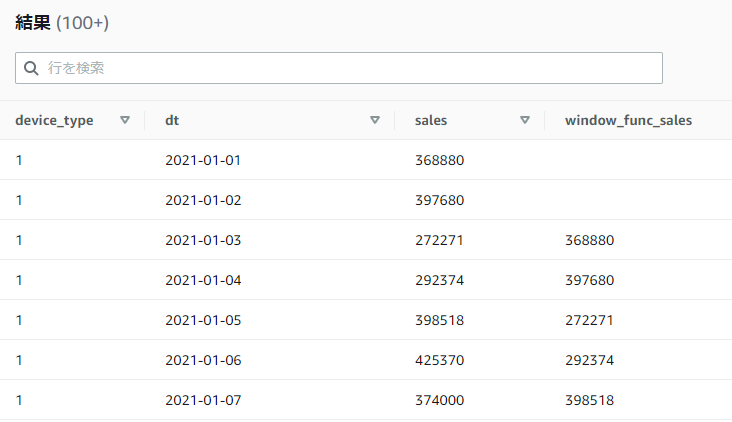
以下のSQLでは第二引数に2を指定して、2行前の値を取得しています。
SELECT device_type, dt, sales,
LAG(sales, 2) OVER(PARTITION BY device_type ORDER BY dt ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) AS window_func_sales
FROM athena_workshop.total_sales_per_device_daily
ORDER BY device_type, dt
2行前の行が存在しない場合にはNULLとなるため、1行目と2行目の値がNULL(UI上では空)になっていることが確認できます。
値が取れない行に対してNULLではなく別の値を指定したい場合には第三引数に値を設定するとその値で補正されます。以下のSQLでは値が取れない行に関しては0を設定しています。
SELECT device_type, dt, sales,
LAG(sales, 2, 0) OVER(PARTITION BY device_type ORDER BY dt ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) AS window_func_sales
FROM athena_workshop.total_sales_per_device_daily
ORDER BY device_type, dt
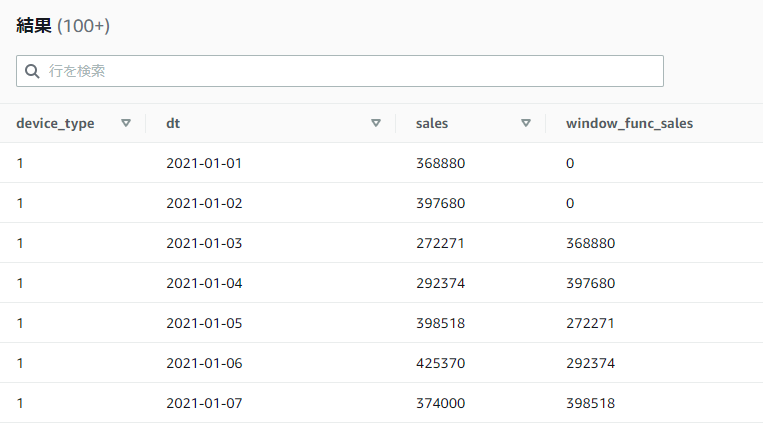
Pythonでの書き方
LEAD関数の節と似たような感じですが、こちらはn行分前にインデックスをした際に対象インデックスが0未満になった場合にはnanを返却する形にapplyで指定した関数の内容を調整しています。
from typing import Any, List
import pandas as pd
import numpy as np
date_range = pd.date_range(start='2021-01-01', end='2021-01-10')
dfs: List[pd.DataFrame] = []
for date in date_range:
df: pd.DataFrame = pd.read_json(
'https://github.com/simon-ritchie/athena_workshop/blob/main/workshop/total_sales_per_device_daily/'
f"dt%3D{date.strftime('%Y-%m-%d')}/data.json.gz?raw=true",
lines=True, compression='gzip')
dfs.append(df)
df = pd.concat(dfs, ignore_index=True)
ios_df: pd.DataFrame = df[df['device_type'] == 1].copy()
ios_df.sort_values(by='date', inplace=True)
def lag(index: int, values: np.ndarray) -> Any:
n: int = 3
if len(values) - 1 < n + index:
return np.nan
return values[n + index]
sales_vals: np.ndarray = ios_df['sales'].values
ios_df.reset_index(drop=True, inplace=True)
ios_df['index'] = ios_df.index
lead_vals: pd.Series = ios_df['index'].apply(lag, values=sales_vals)
print('original df:\n', ios_df)
print('lead values:\n', lead_vals)
original df:
date device_type sales index
0 2021-01-01 1 368880 0
1 2021-01-02 1 397680 1
2 2021-01-03 1 272271 2
3 2021-01-04 1 292374 3
4 2021-01-05 1 398518 4
5 2021-01-06 1 425370 5
6 2021-01-07 1 374000 6
7 2021-01-08 1 321727 7
8 2021-01-09 1 319455 8
9 2021-01-10 1 283038 9
0 292374.0
1 398518.0
2 425370.0
3 374000.0
4 321727.0
5 319455.0
6 283038.0
7 NaN
8 NaN
9 NaN
データ区切り内の行番号を取得する: ROW_NUMBER
ROW_NUMBER関数はデータ区切りの中の行数を取得します。引数は特に無く、返却される行数は1以降で設定されます。
SELECT device_type, dt, sales,
ROW_NUMBER() OVER(PARTITION BY device_type ORDER BY dt) AS row_number
FROM athena_workshop.total_sales_per_device_daily
ORDER BY device_type, dt

Pythonでの書き方
PandasではSQLと異なり行番号の割り振りなどはインデックスを参照するだけなので、PARTITION BY的なことをしたければスライス → 行番号を取りたければreset_indexでインデックスを割り振り直した後にindex属性にアクセスすれば連番が取れます(SQLと異なり0からスタートします)。カラムに設定したければdf['<カラム名>'] = df.indexとすれば設定することができます。
from typing import Any, List
import pandas as pd
import numpy as np
date_range = pd.date_range(start='2021-01-01', end='2021-01-05')
dfs: List[pd.DataFrame] = []
for date in date_range:
df: pd.DataFrame = pd.read_json(
'https://github.com/simon-ritchie/athena_workshop/blob/main/workshop/total_sales_per_device_daily/'
f"dt%3D{date.strftime('%Y-%m-%d')}/data.json.gz?raw=true",
lines=True, compression='gzip')
dfs.append(df)
df = pd.concat(dfs, ignore_index=True)
ios_df: pd.DataFrame = df[df['device_type'] == 1].copy()
ios_df.sort_values(by='date', inplace=True)
ios_df.reset_index(drop=True, inplace=True)
ios_df['row_number'] = ios_df.index
print(ios_df)
date device_type sales row_number
0 2021-01-01 1 368880 0
1 2021-01-02 1 397680 1
2 2021-01-03 1 272271 2
3 2021-01-04 1 292374 3
4 2021-01-05 1 398518 4
データ区切り内のランク(順位)を取得する: RANK, DENSE_RANK
RANK関数は窓関数内のORDER BYで指定した順番でのランキングを割り振ります。ROW_NUMBERに似た挙動をし、結果は1から割り振られます。ただし全体の行の順番(窓関数ではない最後の方のORDER BY)の指定によって、窓関数内の順番と結果の順番が異なっていてもランキングの順番を計算することができます。
SELECT device_type, dt, sales,
RANK() OVER(PARTITION BY device_type ORDER BY sales DESC ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) AS ranking
FROM athena_workshop.total_sales_per_device_daily
ORDER BY device_type, sales DESC
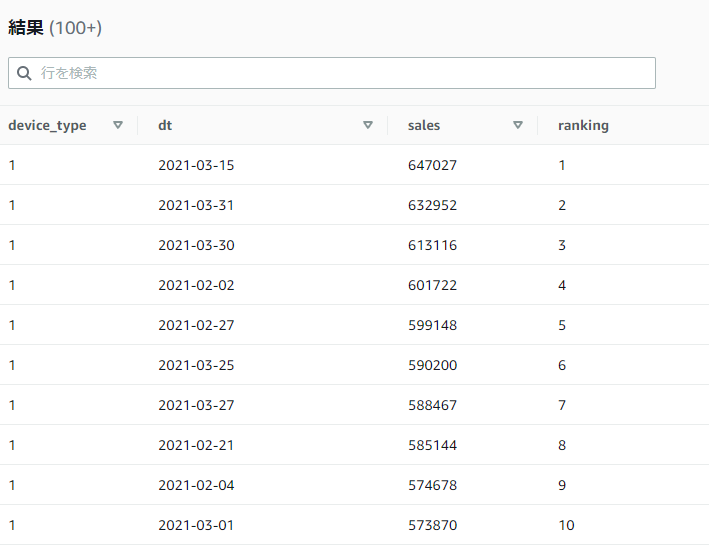
RANKに似た関数としてDENSE_RANKという関数も存在します。基本的な使い方は同じなのですが、RANKに関しては同値の複数の行があった場合にはそれらのランキングは同じになり、その次の行のランキングが同値の行数分飛んだ値になります。
例えば1位と2位が100で同値、3位が80だった場合には1位と2位は両方ともRANK関数の値は1となり、3位のRANK関数の値は3位となります。2位の行は欠落します。
一方でDENSE_RANK関数の方は2位の行が欠落したりせずに、1位と2位が1となり3位が2となります。間の欠落した順位が詰められる形となります。
Pythonでの書き方
Pandasでランキングの値を取る場合にはrankメソッドを使うとシンプルです。RANK関数に合わせるなら引数にmethod='min'と指定します。また、降順で計算するにはascending=Falseと引数を指定します。
※以下のコードでは動作確認のサンプルとして2行目と4行目を同じ値(350000)にしています。
from typing import List
import pandas as pd
date_range = pd.date_range(start='2021-01-01', end='2021-01-05')
dfs: List[pd.DataFrame] = []
for date in date_range:
df: pd.DataFrame = pd.read_json(
'https://github.com/simon-ritchie/athena_workshop/blob/main/workshop/total_sales_per_device_daily/'
f"dt%3D{date.strftime('%Y-%m-%d')}/data.json.gz?raw=true",
lines=True, compression='gzip')
dfs.append(df)
df = pd.concat(dfs, ignore_index=True)
ios_df: pd.DataFrame = df[df['device_type'] == 1].copy()
ios_df.reset_index(drop=True, inplace=True)
ios_df.at[1, 'sales'] = 350000
ios_df.at[3, 'sales'] = 350000
ios_df['rank'] = ios_df['sales'].rank(method='min', ascending=False)
print(ios_df)
date device_type sales rank
0 2021-01-01 1 368880 2.0
1 2021-01-02 1 350000 3.0
2 2021-01-03 1 272271 5.0
3 2021-01-04 1 350000 3.0
4 2021-01-05 1 398518 1.0
DENSE_RANK関数に合わせたい場合にはmethod='dense'と引数に指定します。
from typing import List
import pandas as pd
date_range = pd.date_range(start='2021-01-01', end='2021-01-05')
dfs: List[pd.DataFrame] = []
for date in date_range:
df: pd.DataFrame = pd.read_json(
'https://github.com/simon-ritchie/athena_workshop/blob/main/workshop/total_sales_per_device_daily/'
f"dt%3D{date.strftime('%Y-%m-%d')}/data.json.gz?raw=true",
lines=True, compression='gzip')
dfs.append(df)
df = pd.concat(dfs, ignore_index=True)
ios_df: pd.DataFrame = df[df['device_type'] == 1].copy()
ios_df.reset_index(drop=True, inplace=True)
ios_df.at[1, 'sales'] = 350000
ios_df.at[3, 'sales'] = 350000
ios_df['dense_rank'] = ios_df['sales'].rank(method='dense', ascending=False)
print(ios_df)
date device_type sales dense_rank
0 2021-01-01 1 368880 2.0
1 2021-01-02 1 350000 3.0
2 2021-01-03 1 272271 4.0
3 2021-01-04 1 350000 3.0
4 2021-01-05 1 398518 1.0
ランクの比率値を取得する: PERCENT_RANK
PERCENT_RANK関数はRANK関数で取れるランキングの値を使ったパーセンテージを取得することができます。関数内容としては以下のような計算になります。分子側はRANK関数で取れる値となります。
\frac{関数によるランキングの値 - 1}{データ区切り全体の件数 - 1}
SELECT device_type, dt, sales,
RANK() OVER(PARTITION BY device_type ORDER BY sales DESC ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) AS ranking,
PERCENT_RANK() OVER(PARTITION BY device_type ORDER BY sales DESC ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) AS percent_ranking
FROM athena_workshop.total_sales_per_device_daily
ORDER BY device_type, sales DESC

Pythonでの書き方
rankメソッドでpct=Trueと引数を指定することでパーセンテージ表示となります。シンプルで良いですね。
from typing import List
import pandas as pd
date_range = pd.date_range(start='2021-01-01', end='2021-01-05')
dfs: List[pd.DataFrame] = []
for date in date_range:
df: pd.DataFrame = pd.read_json(
'https://github.com/simon-ritchie/athena_workshop/blob/main/workshop/total_sales_per_device_daily/'
f"dt%3D{date.strftime('%Y-%m-%d')}/data.json.gz?raw=true",
lines=True, compression='gzip')
dfs.append(df)
df = pd.concat(dfs, ignore_index=True)
ios_df: pd.DataFrame = df[df['device_type'] == 1].copy()
ios_df['percent_rank'] = ios_df['sales'].rank(ascending=False, pct=True)
print(ios_df)
date device_type sales percent_rank
0 2021-01-01 1 368880 0.6
2 2021-01-02 1 397680 0.4
4 2021-01-03 1 272271 1.0
6 2021-01-04 1 292374 0.8
8 2021-01-05 1 398518 0.2
指定された件数ごとにデータ区切り内のデータを振り分ける: NTILE
NTILE関数はデータ区切りごとのデータグループを引数に指定されたn個分にデータを振り分ける関数です。
例えば特定のデータ区切りに100個データがあってnを10とした場合、10個ずつのグループに分けられます(グループの番号のカラムが設定されます)。別のデータ区切りで50個のデータがあれば5個ずつのグループに分けられます。
第一引数にはnの整数が必要になり、返却値も整数となります(1以降で順番に設定されていきます)。
以下のSQLではnの引数に18を設定しています。データ区切りには90個の時系列データがあるので1グループ辺り5件となり、1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 3, 3, ...という値になっていきます。
SELECT device_type, dt, sales,
NTILE(18) OVER(PARTITION BY device_type ORDER BY sales DESC ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) AS tile
FROM athena_workshop.total_sales_per_device_daily
ORDER BY device_type, sales DESC

Pythonでの書き方
Pandasのqcut関数で近いことができます。q引数にNTILE関数のnに該当する個数を指定し、且つlabels=Falseと引数を指定します(文字列のラベルではなくFalseを指定すると連番が割り振られます)。
xの引数には今回はデータフレームのインデックスを指定しています。qcut関数では指定されたシリーズなどの昇順などで順番に割り振られるようなので、今回は行の順番通りに割り振りたかったためインデックスを指定しています。
from typing import List
import pandas as pd
date_range = pd.date_range(start='2021-01-01', end='2021-01-10')
dfs: List[pd.DataFrame] = []
for date in date_range:
df: pd.DataFrame = pd.read_json(
'https://github.com/simon-ritchie/athena_workshop/blob/main/workshop/total_sales_per_device_daily/'
f"dt%3D{date.strftime('%Y-%m-%d')}/data.json.gz?raw=true",
lines=True, compression='gzip')
dfs.append(df)
df = pd.concat(dfs, ignore_index=True)
ios_df: pd.DataFrame = df[df['device_type'] == 1].copy()
ios_df.reset_index(drop=True, inplace=True)
ios_df['ntile'] = pd.qcut(x=ios_df.index, q=5, labels=False)
print(ios_df)
date device_type sales ntile
0 2021-01-01 1 368880 0
1 2021-01-02 1 397680 0
2 2021-01-03 1 272271 1
3 2021-01-04 1 292374 1
4 2021-01-05 1 398518 2
5 2021-01-06 1 425370 2
6 2021-01-07 1 374000 3
7 2021-01-08 1 321727 3
8 2021-01-09 1 319455 4
9 2021-01-10 1 283038 4
データ区切り内での累積分布を取得する: CUME_DIST
CUME_DIST関数は累積分布(cumulative distribution)を得ることができる関数です。
ここでは累積分布自体には説明は引用程度で詳しくは省きます。必要な方は検索などで色々記事がヒットしますのでそちらをご参照ください。
累積分布関数(るいせきぶんぷかんすう、英: cumulative distribution function, CDF)や分布関数(ぶんぷかんすう、英: distribution function)とは、確率論において、実数値確率変数 X が x 以下になる確率の関数のこと。連続型確率変数では、負の無限大から x まで確率密度関数を定積分したもの。
累積分布関数 - Wikipedia
引数は特に無く、DOUBLE型の浮動小数点数が返却されます。
SELECT
date, device_type, sales,
CUME_DIST() OVER(PARTITION BY device_type ORDER BY sales DESC ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) AS cume_dist
FROM athena_workshop.total_sales_per_device_daily
ORDER BY device_type, sales DESC

Pythonでの書き方
そのままプロット・・・するのであればPandasのシリーズのhistメソッドでcumulative=True, density=1, bins=100と引数を指定するとシンプルそうです。
数値がデータフレームで欲しい場合はcumsumメソッドなどで何ステップか計算を挟む必要がありそうです。ここではリンクだけ貼って省きますので必要な場合はリンク先をご確認ください。
参考文献・参考サイトまとめ
- The Applied SQL Data Analytics Workshop: Develop your practical skills and prepare to become a professional data analyst, 2nd Edition
- Window Functions
- 分析関数(ウインドウ関数)をわかりやすく説明してみた
- 累積分布関数 - Wikipedia
- pandasで窓関数を適用するrollingを使って移動平均などを算出
- Rolling window functions
- module 'pandas' has no attribute 'rolling_mean'
- pandas.DataFrame, Seriesを順位付けするrank
- pandasのcut, qcut関数でビニング処理(ビン分割)
- Plotting CDF of a pandas series in python