今まで複雑なデータ操作・分析などはPythonでやっており、SQLは普通のアプリ開発程度のライトなものしか触って来なかったのですが、やはり分析用の長いSQLなども書けた方がやりとり等で便利・・・という印象なので、復習も兼ねて記事にしておきます。
また、SQLに加えて検算も兼ねてPythonやPandasなどを使ったコードもSQLと併記していきます(Pythonで書くとどういった記述が該当するのかの比較用として使います)。
※長くなるのでいくつかの記事に分割します。本記事は1記事目となります。
特記実行
- お仕事がAWSなので合わせてDBはAWSのAthena(Presto)を利用していきます。BigQueryやRedshift、MySQLやPostgreSQLなどではある程度方言や使える関数の差などがあると思いますがご了承ください。
- 同様にお仕事がゲーム業界なので、用意するデータセットはモバイルゲームなどを意識した形(データ・テーブル)で進めます。
- Athenaなどでの分析利用が主なため、この記事ではテーブル作成・削除などにはほぼ触れずに読み込みや集計などをメインとしています。
- 長くなりすぎるのでAthena(Presto)の関数全ては触れません。関数一覧的な記事は別途書こうと思います。
- 同様に長くなりそうなので本記事では基本的なところを中心とし、別の記事で他の細かい点や発展的な内容について触れていきます。
- エンジニア以外の方(プランナーさんやマーケの方など)も少し読者として想定しています。ある程度技術的なところで煩雑な記述もありますがご容赦ください。
本記事で触れる点
- 用語の説明
- 読み込み関係(SELECT)
- 条件設定(WHERE)
- Athenaのパーティション関係
- ソート関係(ORDER BY)
- 行数制限(LIMIT)
- 名前設定(AS)
- ユニーク設定(DISTINCT)
- 基本的な集計関数(COUNT, AVG, APPROX_PERCENTILE等)
- Athenaの型について
- 型変換関係(CAST)
- 列の連結(JOIN)
- 行の連結(UNION, INTERSECTなど)
※本記事で触れられていない点も数多くあるため、複数記事に分けて今後も書いていこうと思います(あまりにも長くなってきたので分割します)。この記事では基本的な部分が中心になっています。
環境の準備
Athena環境の準備
※エンジニア以外の方はこの部分は技術的な対応などが必要になるため必要に応じて社内のエンジニアの方に依頼などをご検討ください。
実務ではParquetとかも使ったりもしますが、データは今回はjson.gz(1行ずつJSONのデータが設定されるJSON Lines形式のgzip圧縮されたファイル)の形式で用意しました。GitHub上に配置しておいたため、利用する場合はcloneなどしていただいてS3にアップする形でお願いします。以下のリポジトリのworkshopというフォルダに諸々のデータを配置してあります。
Athenaのテーブルの作成に関してはS3にファイルを設置した後にGlueクローラーなどを動かすか、もしくはGitHubリポジトリのddlというフォルダ以下に各テーブルのCREATEのSQLを配置しておきましたので、お好きな方法をご選択ください。
GitHub上のCREATE文のSQLに関してはPartition Projectionの設定をしてあるため、MSCK REPAIR TABLEなどのパーティション反映のSQLの実行は不要です。<S3バケット名>としてある箇所のみ皆さんのS3バケット名で置換をお願いします。また、DB名はathena_workshopという名前を付けています。
参考 : [新機能]Amazon Athena ルールベースでパーティションプルーニングを自動化する Partition Projection の徹底解説
また、本記事ではAthena engine version 2を利用しています(2020年11月ごろにリリースされたエンジンとなります)。
Python環境の準備
※Pythonに関しては不要な方はスキップで問題ございません。
本記事ではPython 3.9.0のバージョンを利用しています。
また、以下のライブラリも使用していきます。
pandas==1.2.4
AthenaのSQLの書き方を調べる時の補足
今回はAWSのAthenaを使っていきますが、世の中には他にもGCPのBigQueryであったりMySQL、PostgreSQL、同じくAWSのRedshiftといった様々なものが存在します。
基本的にはそれぞれで標準SQLで同じ文法で書けるものの、細かい違いや使える関数の差異があったりします。
Athenaに関してはSQLで検索をする際にはAthenaというワードで検索するのに加えて、AthenaはPrestoというオープンソースのエンジンが使われているためPrestoのドキュメントや記事なども参考になります。Athenaというワードでうまく引っかからない場合にはPrestoなども並行して検索すると情報が見つかったりします。
Prestoに関しては以下の記事などをご確認ください。
テーマは,Facebookが公開した新しい分散処理基盤,Presto。実はFacebookが彼らの超大規模なデータセットに対してインタラクティブに結果を返せるようにと開発されたものです。
『Prestoとは何か,Prestoで何ができるか』
基本的な用語の説明
この節以降はAthenaとSQLを触る上での基本となる要素の用語に簡単に触れていきます。
表 / テーブル(table)
データベースやエクセルなどでお馴染みの表(もしくはテーブル)は、基本的には縦と横の2軸で構成されるデータの形態です。以下のような形式のデータが該当します。

行(row)
行(英語だとrow)はテーブル内の特定の縦方向の位置のことを指します。行の上からの順番で位置を表す時に1行目、2行目…といったように指します。例えば2行目と指した場合、以下の画像の赤枠部分のような位置の行が該当します。

列 / カラム(column)
列もしくはカラム(英語だとcolumn)はテーブル内の特定の横方向の位置のことを指します。
例えば以下の画像では「ユーザーID」「ログイン日時」「総ログイン数」の3つの列を持つテーブルとなります。
「ユーザーIDカラム」といった指定をした場合には以下の赤枠部分が該当します。

データベース (database)
データベース(英語ではdatabase)は、色々意味合いがあるのですが今回のAthenaなどで言えばたくさんのテーブルを格納した集まりといったようなものになります。略してDBなどとも良く表記されます。
各テーブルというたくさんのファイルを格納したフォルダのような存在がデータベースとイメージすると分かりやすいかもしれません。
データカタログ(data catalog)
Athenaではさらにデータカタログ(英語ではdata catalog)というものが存在します。こちらはデータベースよりも一階層上の存在で、色々なデータベースを格納した集まりといったようなものになります。データカタログ・データベース・テーブルの階層のサンプルを図で表すと以下のようになります。テーブル数などはデータベースの内容などに依存し、データベースの数などはデータカタログの内容に依存します。

基本的にはSQLを書く上ではデータカタログの指定を省略した場合はデフォルトのデータカタログが参照されるため、SQLを実行するだけであればあまり意識しなくても済むことが多いかもしれません。複数のAWSアカウント間をまたいでAthenaでSQLを実行したりすると考える必要が出てきます。
参考: AthenaでクロスアカウントのGlue データカタログを参照する
SQL(Structured Query Language)
データベースの内容を操作するにはSQL(Structured Query Language)を使います。テーブルを作ったり削除したり、データを抽出したり集計したり・・・と色々なことを行うことができます。
- Structured は「構造化された」といった意味を持ちます。
- Query は「質問」とか「尋ねる」といった意味を持ちます。
- Language は「言語」といった意味を持ちます。
あまり正確ではありませんが大雑把に「構造化されたDBやテーブルデータに対する質問や依頼を投げるための言語」といったところでしょうか。
本記事ではSQLは分析用としてデータの抽出や集計処理などを中心に触れ、テーブル作成などは割愛します。
※補足: より厳密に言うと標準SQLではStructured Query Languageなどの略称ではないといった話も出てきますが、分析する上では無くても大丈夫な知識なためここでは詳しくは触れません。
SQLは「structured query language」と紹介されることもある。これは、IBMがかつて提供していたSQL/DSやその他いくつかのRDBMSの実際の製品におけるSQLにおいては正しい。しかし、標準SQLは、言語仕様そのものにはIBMのRDBMSのDB2の影響が大きく見られるものの、「SQLは、何かの略語ではない」と定義している。
SQL - Wikipedia
データの読み込みの基礎
この節以降からはデータの読み込みの基礎であるSQLのSELECTについて学んでいきます。
データを読み込む: SELECT
テーブルからデータを読み込むにはSQLのSELECTを使います。
基本的な書き方は以下のようなフォーマットとなります。
SELECT <列の指定> FROM <DB名>.<テーブル名>
例えばathena_workshopというデータベース内にあるloginというテーブルのuser_idとtimeという列を読み込む場合には以下のようなSQLになります。
SELECT user_id, time FROM athena_workshop.login;
データベース名とテーブル名の間は半角のドットの記号(.)で繋げます。
また、列を複数指定する場合には各列の間に半角のコンマ(,)を入れます。見やすいようにコンマの後に半角のスペースを入れるのが慣習としてよく使われます(スペースを省略しても動きます)。
Athena上で実行してみると以下のように対象のテーブルの内容が確認できます。
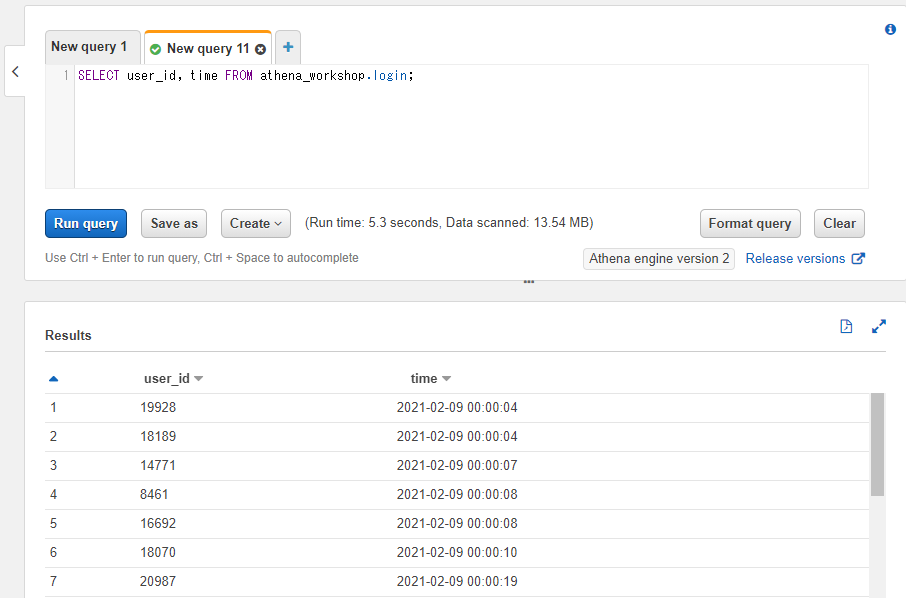
なお、AthenaではSELECT実行時の行の順番は担保されません。上記のようなシンプルなSELECTの場合には実行の度に先頭の方に表示される行の内容が変動します。この辺りの順番を担保する(昇順・降順など)必要がある場合には後々の節で触れるORDER BYなどの記述が必要になります。
スペース以外の記号などもそうですが、半角のスペースが必要なところで全角のスペースを入れてしまったりするとエラーになります。例えばちょっと分かりづらいですが、以下のようにFROMの後に全角のスペースを入れてみるとエラーになることを確認できます。
SELECT user_id, time FROM athena_workshop.login;

そういった場合はエディタなどに持ってきて確認するか、AWSのwebコンソール上であれば右下にあるFormat queryのボタンを押すとSQLが整形され全角のスペースなども取り除かれます(半角に置換されます)。

DB名やテーブル名、列名部分には半角のダブルクォーテーションの引用符(")で囲むこともできます。例えば以下のように書きます。
SELECT "user_id", "time" FROM "athena_workshop"."login";
通常はダブルクォーテーションを付けても付けなくても同じ挙動になります。ただし数字で始まるテーブル名などの場合には付けないとエラーになってしまうという違いがあります(大半のケースではDB名やテーブル名の先頭に数字は付けないことが多いとは思います)。
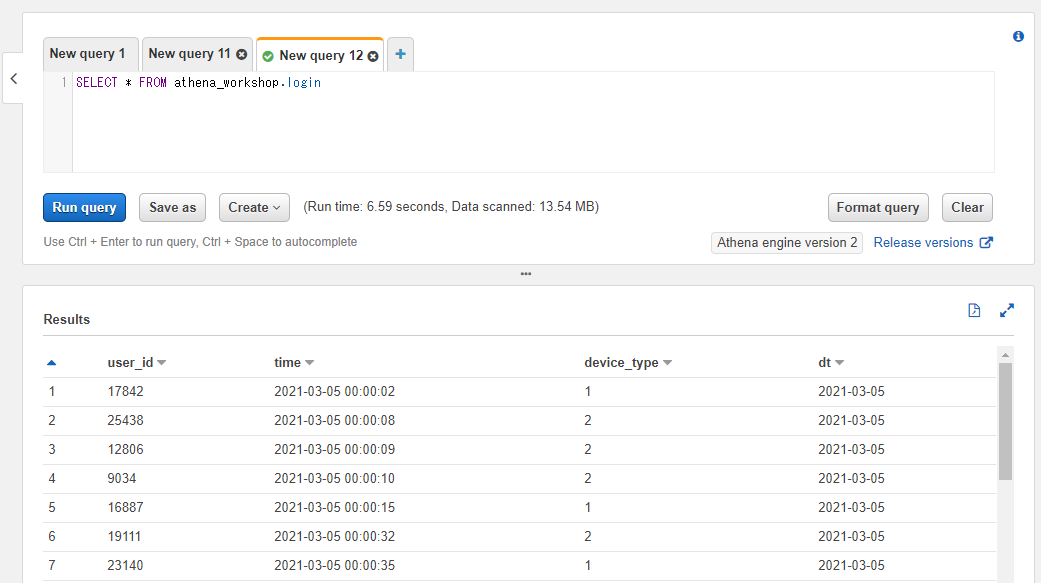
全ての列をアスタリスク(*)で指定する
一つ一つの列を指定するのではなく全ての列を指定したい場合には半角のアスタリスク(*)を指定します。以下のようなSQLとなります。
SELECT * FROM athena_workshop.login;
結果を確認すると指定したテーブルの全ての列が読み込まれていることが確認できます。

後々の節で触れるLIMITと組み合わせて使って対象のテーブルの各列にどんな値が入っているかの確認で使ったり、もしくは利用する列が多く一つ一つ指定するのが大変・・・といった場合などに利用します。
個別に列を指定した時と異なりSQLを見ただけでは読み込まれる列が分からなかったり、SQL結果に使わない余分な列などが表示されてしまったりといった面はあるので、最初はテーブル確認などでアスタリスクを使っても段々とSQLの編集を繰り返す際には使わない方向に調整することが多めです。
また、JSONなどでは変わりませんが保存されるAthenaのデータフォーマット次第(Parquetなど)では列を指定して対象の列を絞った方がクエリが速くなったりコストが下がったりといったメリットもあります。
Pythonでの書き方
今回はgzip圧縮されたJSON Linesのデータで扱っているため、Pandasで扱う場合にはread_json関数を使って引数にlines=Trueとcompression='gzip'を指定すると読み込むことができます。read_json関数にはこの記事を書いている時点ではusecolsのようなオプションは無いためSQLのように全列を対象としたければそのまま扱い、もし特定カラムのみ使いたければdf = df[['user_id', 'time']]みたいな形でのスライスが必要になります。
import pandas as pd
df: pd.DataFrame = pd.read_json(
'https://github.com/simon-ritchie/athena_workshop/blob/main/workshop/login/dt%3D2021-01-01/data.json.gz?raw=true',
lines=True, compression='gzip')
df = df[['user_id', 'time']]
print(df.head())
user_id time
0 8590 2021-01-01 00:00:01
1 568 2021-01-01 00:00:02
2 17543 2021-01-01 00:00:04
3 15924 2021-01-01 00:00:07
4 5243 2021-01-01 00:00:09
※以降の節でも同様ですが、SQLでは今回のサンプルデータの各日付に対して実行されていますがPython側は手間なので特定の日付のみのファイルなどを指定して進めていきます。
条件を指定する: WHERE
この節以降ではSQLでデータを読み込む時の条件の指定の仕方を学びます。条件を指定するにはWHEREというキーワードを使います(SQLでこういったもののかたまり部分を句と呼んだりして、WHEREであればWHERE句などと表記されたりもします)。
「どこの行を抽出するのか?」といった意味合いでWHEREというキーワードになっています。
条件の指定の仕方によって書き方が色々あるのでそれぞれ触れていきます。
等値条件(=)
等値条件を満たす行(特定のカラムが指定した値になっている行)のみを抽出したい場合には半角のイコールの記号(=)を使ってWHERE <カラム名> = <任意の値>といったように書きます。
説明のため、ここではユーザーのログインログを扱う想定のテーブルとしてloginというテーブルで扱っていきます。loginテーブルは以下のようなカラム(列)を持っています。
- user_id: 対象のユーザーIDの整数のカラム。
- time: ログイン日時の文字列のカラム。
- device_type: 端末種別の整数のカラム。iOS端末なのかAndroid端末なのかといった想定で、1(iOS)もしくは2(Android)の値が設定されます。
クエリを投げてみると以下のようなデータが確認できます(dtというカラムに関しては後々パーティションという要素の説明の節で詳しく説明をします)。
SELECT * FROM athena_workshop.login
このテーブルで、例えばAndroidのログだけ抽出したい・・・とします。端末はdevice_typeのカラムで判別ができるのと、Androidの場合は種別として2がログに設定されているのでWHERE device_type = 2といったようにSQLに書き足します。なお、SQLでは間に改行を入れることができます。1行に詰め込むと長くなってしまうので、ここではWHERE句の前に改行を入れています。
SELECT * FROM athena_workshop.login
WHERE device_type = 2
実行結果のdevice_typeのカラムの部分(スクショの赤枠部分)を見てみると、結果の行がdevice_typeが2の行のみになっていることを確認できます。

Pythonでの書き方
df[df['<カラム名>'] == <指定の値>]という形で書くと等値の条件を満たす行のみにスライスができます。
import pandas as pd
df: pd.DataFrame = pd.read_json(
'https://github.com/simon-ritchie/athena_workshop/blob/main/workshop/login/dt%3D2021-01-01/data.json.gz?raw=true',
lines=True, compression='gzip')
df = df[df['device_type'] == 2]
print(df.head())
user_id time device_type
2 17543 2021-01-01 00:00:04 2
4 5243 2021-01-01 00:00:09 2
5 20229 2021-01-01 00:00:16 2
10 12642 2021-01-01 00:00:21 2
12 5666 2021-01-01 00:00:26 2
非等値条件(!=)
非等値条件(特定のカラムが指定した値になっていない行)のみを抽出したい場合には半角のビックリマークの記号とイコールの記号(!=)を使ってWHERE <カラム名> != <任意の値>といったように書きます。
先ほどとは逆にAndroid端末(device_type = 2)以外という条件でSQLを投げてみましょう。今回サンプルとして用意したデータではdevice_typeは1か2のみですが、実際にはブラウザゲーム版・プレステ版・andappのようなプラットフォームなどなど様々あるかもしれませんし、そういった時に「Android以外」みたいな指定が役立ってきます。
SELECT * FROM athena_workshop.login
WHERE device_type != 2
device_type != 2とすることで、device_typeが2以外のもののみ(今回は1)結果に表示されることが確認できます。

小なり条件(<)
小なり(特定のカラムが指定した値未満になっている行)のみを抽出したい場合には半角の<の記号(left angle bracket)を使います。
今度はuser_sales_dailyという日次の各ユーザーごとの売り上げの合算値を想定したテーブルを使います。SELECT文で内容を確認してみると以下のようなテーブルになっています。
SELECT * FROM athena_workshop.user_sales_daily
新しいカラムとして以下のものが設定されています。
- date: 対象の日付の文字列。
- sales: 日次のユーザーごとの売り上げの合算値の整数。
※売り上げが0のユーザーはその日には行が入らない想定でデータを設定してあります。
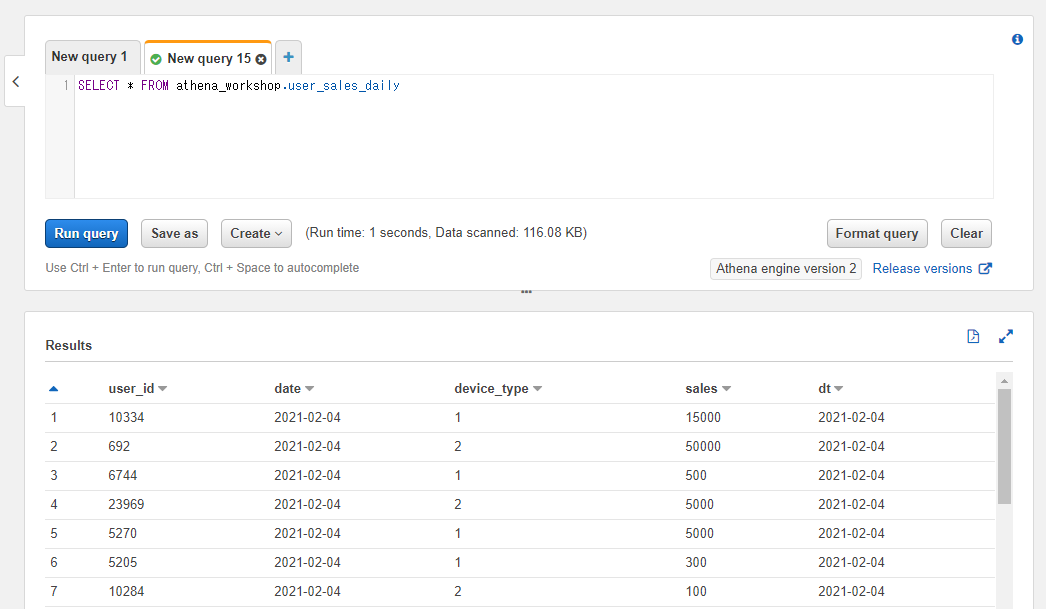
このテーブルで<の記号を使って売り上げが1000円未満のユーザーのみ抽出してみましょう。WHERE <カラム名> < 1000という書き方となるので、SQLは以下のようになります。
SELECT * FROM athena_workshop.user_sales_daily
WHERE sales < 1000
結果を見ると売り上げのカラムの値が1000未満の行のみになっていることを確認できます。

なお、他のものもそうですがこれらの比較は数値以外でも使うことができます。例えば日付の文字列のカラムに対して条件を書くとその日付より前の日付が抽出できます。ただし文字列を条件部分で指定する場合には半角の'の記号(シングルクォート)で囲む必要があります('2021-01-05'といったように)。"の記号(ダブルクォート)ではAthenaではエラーになるので注意してください。ダブルクォートは条件部分などではなくカラム名部分などを囲む際に使います。MySQLなどではどちらでも動いたりしますがAthenaではエラーになります。
SELECT * FROM athena_workshop.user_sales_daily
WHERE date < '2021-01-05'
結果が2021-01-05の日付よりも前になっていることを確認できます。

Pythonでの書き方
df[df['<カラム名>'] < <指定の値>]とすると未満の条件で絞り込むことができます。
import pandas as pd
df: pd.DataFrame = pd.read_json(
'https://github.com/simon-ritchie/athena_workshop/blob/main/workshop/user_sales_daily/dt%3D2021-01-01/data.json.gz?raw=true',
lines=True, compression='gzip')
df = df[df['sales'] < 1000]
print(df.head())
以下条件(<=)
以下(特定のカラムが指定された値以下になっている行)のみを抽出したい場合には半角の<=の記号を使います。小なりの条件にイコールの記号が追加になった形となります。
小なりの時と同様に日次のユーザーごとの売り上げのテーブルで試してみます。小なりの条件では同値は含みませんでしたが以下条件では含みます。例えば1000円以下という条件で以下のSQLを実行すると1000円の行も結果に含まれる形になります。
SELECT * FROM athena_workshop.user_sales_daily
WHERE sales <= 1000
salesカラムに1000円の行が存在していることが確認できます。

Pythonでの書き方
df[df['<カラム名>'] <= <指定の値>]という書き方で対応できます。
import pandas as pd
df: pd.DataFrame = pd.read_json(
'https://github.com/simon-ritchie/athena_workshop/blob/main/workshop/user_sales_daily/dt%3D2021-01-01/data.json.gz?raw=true',
lines=True, compression='gzip')
df = df[df['sales'] <= 1000]
print(df.head())
user_id sales date device_type
0 19288 1000 2021-01-01 1
2 2183 300 2021-01-01 1
3 12446 100 2021-01-01 1
5 12494 300 2021-01-01 2
6 9675 100 2021-01-01 2
大なり条件(>)
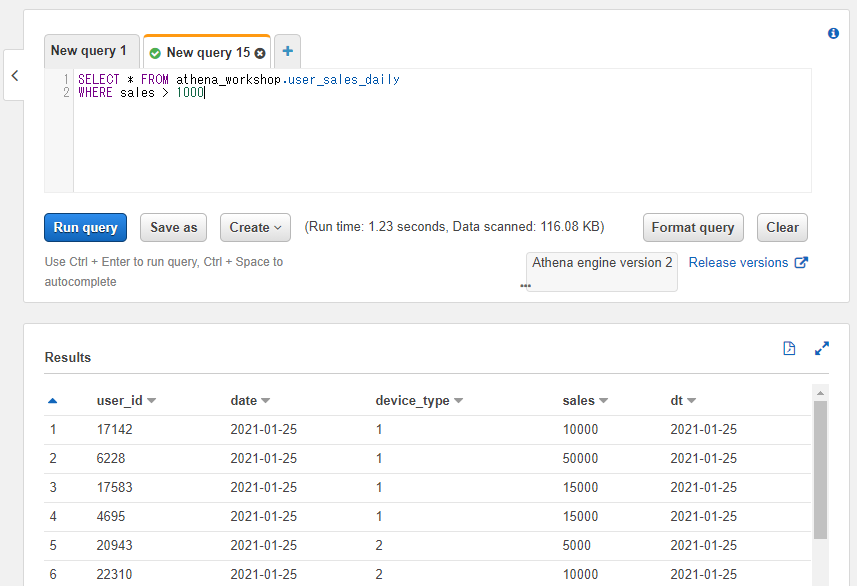
大なり条件は小なり条件の逆で、特定のカラムの値が指定した値よりも大きい(超過している)行のみが結果に含まれるようになります。半角の>の記号を使って<カラム名> > <指定の値>といったように書きます。例えば1000円を超えているユーザーのみを抽出したい場合にはWHERE sales > 1000といったように書きます。
SELECT * FROM athena_workshop.user_sales_daily
WHERE sales > 1000
結果の売り上げの行が5000や10000などの1000を超える金額の行のみになっていることを確認できます。
Pythonでの書き方
df[df['<カラム名>'] > <指定の値>]という書き方で対応ができます。
import pandas as pd
df: pd.DataFrame = pd.read_json(
'https://github.com/simon-ritchie/athena_workshop/blob/main/workshop/user_sales_daily/dt%3D2021-01-01/data.json.gz?raw=true',
lines=True, compression='gzip')
df = df[df['sales'] > 1000]
print(df.head())
user_id sales date device_type
1 132 5000 2021-01-01 1
4 4894 10000 2021-01-01 2
7 18610 5000 2021-01-01 1
8 17694 3000 2021-01-01 2
11 20020 3000 2021-01-01 1
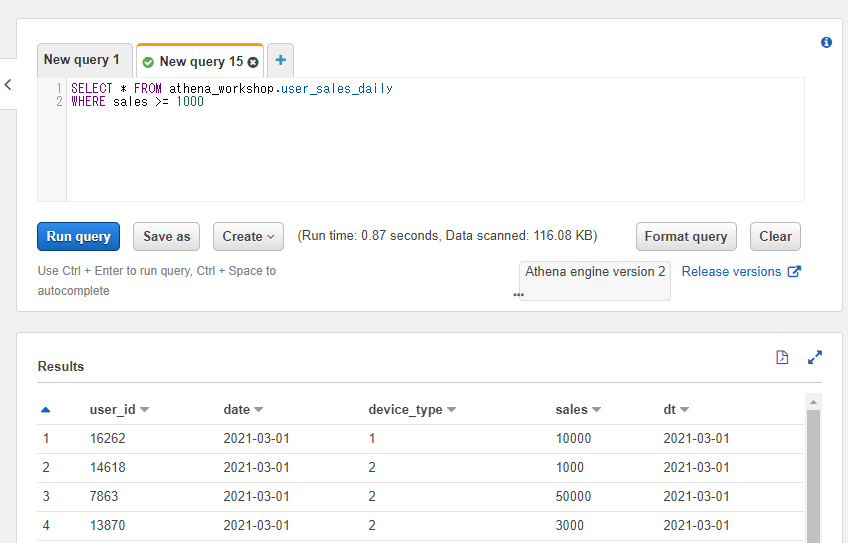
以上条件(>=)
以下の時と同じように半角のイコールの記号を付けて>=と指定すると以上の条件となります。
大なりの条件のように1000円という値を指定すると1000円も含んだ行が返ってきます。
SELECT * FROM athena_workshop.user_sales_daily
WHERE sales >= 1000
Pythonでの書き方
df[df['カラム名'] >= <指定の値>]という書き方で対応ができます。
import pandas as pd
df: pd.DataFrame = pd.read_json(
'https://github.com/simon-ritchie/athena_workshop/blob/main/workshop/user_sales_daily/dt%3D2021-01-02/data.json.gz?raw=true',
lines=True, compression='gzip')
df = df[df['sales'] >= 1000]
print(df.head())
user_id sales date device_type
0 8099 1000 2021-01-02 1
1 18610 50000 2021-01-02 2
2 22483 50000 2021-01-02 2
6 22310 1000 2021-01-02 2
8 25473 15000 2021-01-02 1
複数の条件をANDで指定する
Android端末のユーザー且つ売り上げが5000円以上・・・といったように複数の条件を満たす行のみ欲しいケースを想定してみます。そういった場合には条件の間を半角のANDで繋ぎます。WHERE <カラム名> <条件1> AND <カラム名> <条件2>といった形で書きます。
前述の条件で言うとAndroid端末かどうかはdevice_type = 2という条件が該当し、売り上げが5000円以上という条件はsales >= 5000という条件になるので間をANDで繋いで以下のようなSQLになります。
SELECT * FROM athena_workshop.user_sales_daily
WHERE device_type = 2 AND sales >= 5000
結果には端末種別と売り上げ両方の条件が反映されていることが確認できます。

なお、WHERE文などと同様にANDなどでも直前に改行を入れたりなどもできます。今回はシンプルな条件でしたが、もっと条件が増えてきたりすると1行が長くなってしまってSQLが読みづらくなったりするため適宜改行などを入れると読みやすくなります。
SELECT * FROM athena_workshop.user_sales_daily
WHERE device_type = 2
AND sales >= 5000
Pythonでの書き方
df[(df['<1つ目のカラム名>' <条件1>]) & (df['2つ目のカラム名'] <条件2>)]といった具合に、それぞれを条件を()の括弧で囲んで間を&の記号で繋げれば対応できます。
import pandas as pd
df: pd.DataFrame = pd.read_json(
'https://github.com/simon-ritchie/athena_workshop/blob/main/workshop/user_sales_daily/dt%3D2021-01-01/data.json.gz?raw=true',
lines=True, compression='gzip')
df = df[(df['device_type'] == 2) & (df['sales'] >= 5000)]
print(df.head())
user_id sales date device_type
4 4894 10000 2021-01-01 2
12 23273 50000 2021-01-01 2
13 25190 10000 2021-01-01 2
16 16291 15000 2021-01-01 2
26 6223 50000 2021-01-01 2
もしくはSQLと違って一度に全て詰め込む必要は無いので処理を分けても同じ結果になります。
複雑な条件では読みやすかったりデバッグなどがしやすくなります。
import pandas as pd
df: pd.DataFrame = pd.read_json(
'https://github.com/simon-ritchie/athena_workshop/blob/main/workshop/user_sales_daily/dt%3D2021-01-01/data.json.gz?raw=true',
lines=True, compression='gzip')
df = df[df['device_type'] == 2]
df = df[df['sales'] >= 5000]
print(df.head())
複数の条件をORで指定する
「AもしくはB」といったような、どれかの条件を満たす行を抽出したい場合には条件をORで繋ぎます。WHERE <カラム名1> <条件1> OR <カラム名2> <条件2>といった形で書きます。
例えばユーザーIDが500もしくは1000の行のみ抽出したい場合にはWHERE user_id = 500 OR user_id = 1000といったように書きます。1つ目のカラムと2つ目のカラムは同じものを指定したりもできますし、別のカラムを指定することもできます。
SELECT * FROM athena_workshop.login
WHERE user_id = 500 OR user_id = 1000

Pythonでの書き方
df[(df['1つ目のカラム名'] <条件1>) | df['2つ目のカラム名'] <条件2>]といったように各条件を()の括弧で囲んで間に|の記号を挟むことで対応できます。
import pandas as pd
df: pd.DataFrame = pd.read_json(
'https://github.com/simon-ritchie/athena_workshop/blob/main/workshop/login/dt%3D2021-01-01/data.json.gz?raw=true',
lines=True, compression='gzip')
df = df[(df['user_id'] == 500) | (df['user_id'] == 1000)]
print(df.head())
user_id time device_type
2806 500 2021-01-01 02:45:58 1
4020 500 2021-01-01 04:02:05 1
21908 1000 2021-01-01 21:28:51 2
ANDと複数のORを組み合わせる書き方
例えば端末種別はAndroid(device_type=2)のみで、ただし売り上げは500円もしくは3000円のユーザーのみ抽出したいとします。
これを実現するのにそのままWHERE device_type = 2 AND sales = 500 OR sales = 3000とただ3つの条件を並べるだけでは正しい結果になりません。
SELECT * FROM athena_workshop.user_sales_daily
WHERE device_type = 2
AND sales = 500
OR sales = 3000
結果を見ると分かりますが、売り上げのカラムの値は正しいもののiOSの行(device_type=1)が含まれてしまっています。

これはこの書き方だとdevice_type = 2 且つ sales = 500という条件もしくはsales = 3000という条件のどちらかを満たす行・・・というSQLの判定になっているためです。
要件としてはdevice_type = 2且つsales = 500 もしくはsales = 3000という2つの条件が正しい形となります。
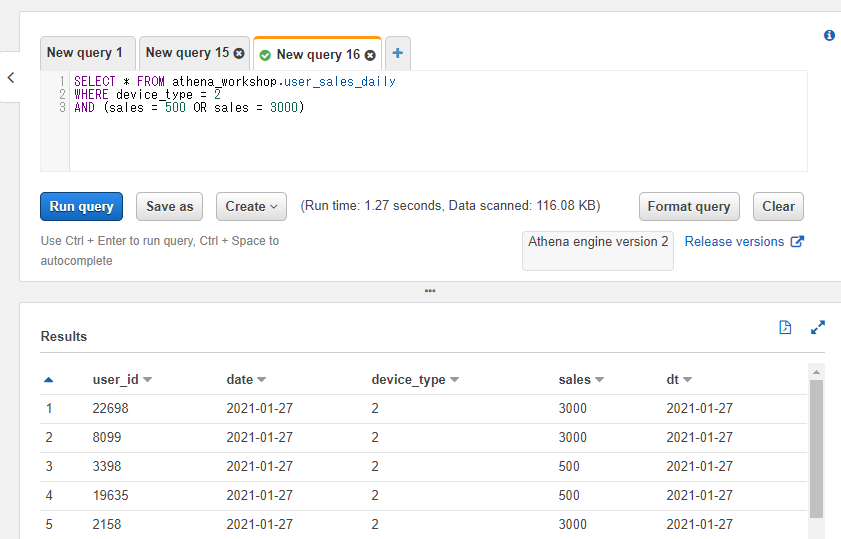
こういった場合にはOR側の2つの条件を半角の()の括弧で囲ってあげると想定した条件にすることができます。
SELECT * FROM athena_workshop.user_sales_daily
WHERE device_type = 2
AND (sales = 500 OR sales = 3000)
結果がAndroid端末のみ(device_type=2)で売り上げも500もしくは3000のみになっていることが確認できます。
Pythonでの書き方
先にANDの条件でスライスしてから、別途ORの2つの条件で絞り込みます。
import pandas as pd
df: pd.DataFrame = pd.read_json(
'https://github.com/simon-ritchie/athena_workshop/blob/main/workshop/user_sales_daily/dt%3D2021-01-01/data.json.gz?raw=true',
lines=True, compression='gzip')
df = df[df['device_type'] == 2]
df = df[(df['sales'] == 500) | (df['sales'] == 3000)]
print(df.head())
user_id sales date device_type
8 17694 3000 2021-01-01 2
14 11686 3000 2021-01-01 2
20 4135 500 2021-01-01 2
42 9815 500 2021-01-01 2
82 28350 3000 2021-01-01 2
リストに含まれる値を取得する: IN
OR条件が多くなってくるとSQLの記述が長くなってきて煩雑です。例えば100個の特定のユーザーIDのいずれかを満たす行のみを抽出する・・・みたいなことをやりたいときに、ひたすらORで条件を繋いでいくのは大変です。
そういった場合にはINを使うとコンマ区切りでまとめて条件を指定することができます。WHERE <カラム名> IN (<条件1>, <条件2>, <条件3>, ..., <条件N>)といった書き方をします。
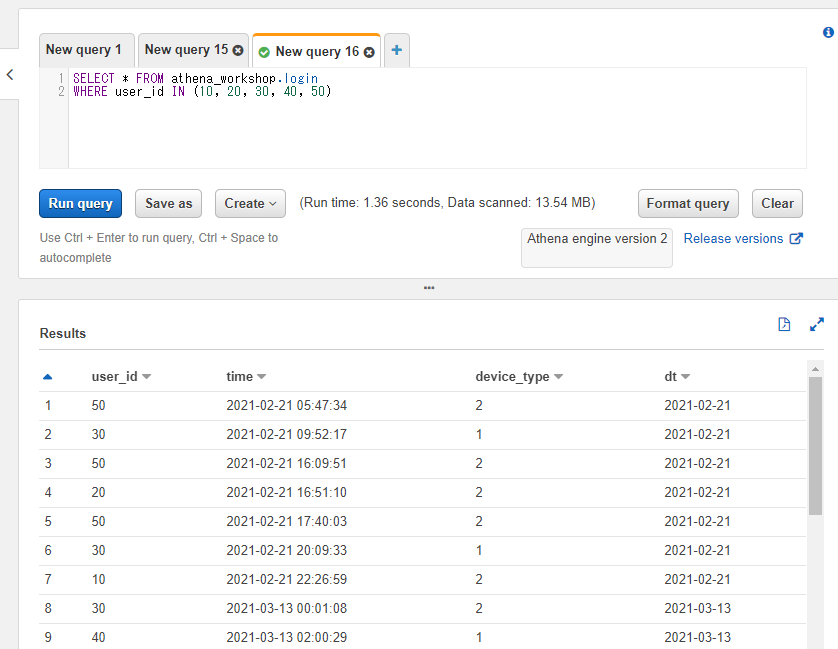
たとえばユーザーIDが10, 20, 30, 40, 50のいずれかに該当するというSQLにしたい場合以下のように書けます。
SELECT * FROM athena_workshop.login
WHERE user_id IN (10, 20, 30, 40, 50)
Pythonでの書き方
isinメソッドを使ってdf[df['<カラム名>'].isin(<各条件を格納したベクトル>)]といった書き方で実現できます。ベクトル部分には1次元のリストやタプル、シリーズやndarrayなどを指定します。
import pandas as pd
df: pd.DataFrame = pd.read_json(
'https://github.com/simon-ritchie/athena_workshop/blob/main/workshop/login/dt%3D2021-01-02/data.json.gz?raw=true',
lines=True, compression='gzip')
df = df[df['user_id'].isin([10, 20, 30, 40, 50])]
print(df.head())
user_id time device_type
2237 10 2021-01-02 01:51:02 2
9576 50 2021-01-02 07:49:07 2
12553 50 2021-01-02 10:16:46 2
12606 40 2021-01-02 10:19:19 1
15919 30 2021-01-02 13:02:46 2
リストに含まれない値を取得する: NOT IN
今度は先ほどのINとは逆に、特定のリストに含まれないという条件を書きたいとします。user_id != 10 AND user_id != 20 AND user_id != 30 ...といった条件をひたすら書いても実現できますが、先ほどのNOT INという書き方でシンプルに書くことができます。
WHERE <カラム名> NOT IN (条件1, 条件2, ..., 条件N)という書き方で、条件に含まれない行のみを対象とすることができます。
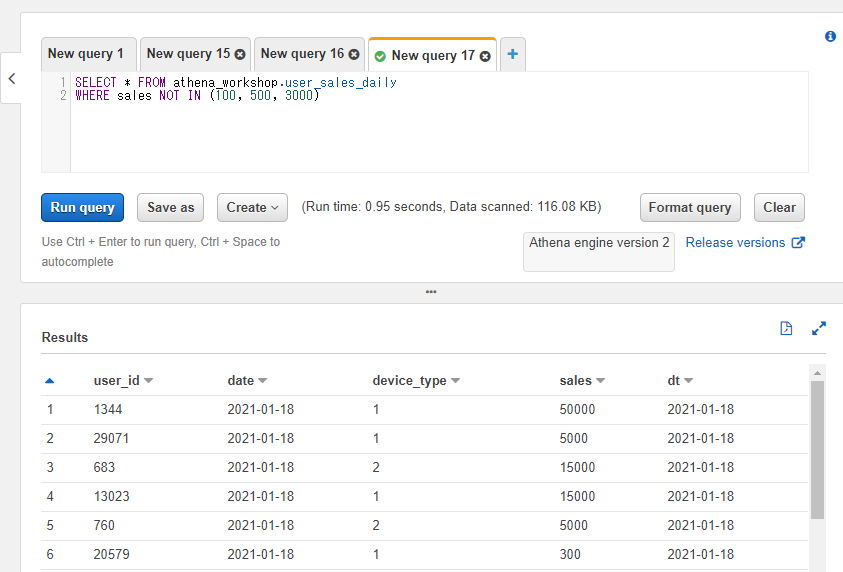
以下のSQLでは売り上げが100円、500円、3000円以外の行のみ抽出しています。
SELECT * FROM athena_workshop.user_sales_daily
WHERE sales NOT IN (100, 500, 3000)
Pythonでの書き方
半角のチルダ記号(~)とisinメソッドを使うと対応ができます。Pandasでは条件の前にチルダ記号を付けると否定(NOT)条件となります。df[~df['<カラム名>'].isin(<リストなどのベクトル>)]という書き方をします。
import pandas as pd
df: pd.DataFrame = pd.read_json(
'https://github.com/simon-ritchie/athena_workshop/blob/main/workshop/user_sales_daily/dt%3D2021-01-01/data.json.gz?raw=true',
lines=True, compression='gzip')
df = df[~df['sales'].isin([100, 500, 3000])]
print(df.head())
user_id sales date device_type
0 19288 1000 2021-01-01 1
1 132 5000 2021-01-01 1
2 2183 300 2021-01-01 1
4 4894 10000 2021-01-01 2
5 12494 300 2021-01-01 2
特定の値の範囲内の値を取得する: BETWEEN
特定の値の範囲のみ抽出したい場合、開始値と終了値の2つを書く必要があります。例えば一例としてログの日付期間などでよく使います。
例えば2021-01-05の日付から2021-01-15の期間のみに結果の行を絞りたいとします。その場合以下のように開始値側で以上の条件(date >= '2021-01-05')、終了値側で以下の条件(date <= '2021-01-15')を指定してANDで条件を繋げることで実現できます。
SELECT * FROM athena_workshop.user_sales_daily
WHERE date >= '2021-01-05'
AND date <= '2021-01-15'
ただしこれでは日付のカラムを2回指定したりで少し記述が煩雑です。こういった以上条件 AND 以下条件という書き方の用途はよく使うため、記述をシンプルにするためのBETWEENという書き方が用意されています。
WHERE <カラム名> BETWEEN <開始値> AND <終了値>という書き方で開始値以上終了値以下という条件を指定することができます。前述のSQLをBETWEENを使って書き直すと以下のようになります。
SELECT * FROM athena_workshop.user_sales_daily
WHERE date BETWEEN '2021-01-05' AND '2021-01-15'
Pythonでの書き方
Pandasでも主に以下の3つの方法で開始値以上終了値以下の条件を対応できます。
- 以上の条件と以下の条件を
&の記号を挟んで同時に記述する。 - それぞれの条件を個別に1行ずつ記述する。
- betweenメソッドを使う。
上2つは既に前の節で触れましたのでここではbetweenメソッドについて触れていきます。Pandasのシリーズが持っているメソッドで、第一引数がleft(以上条件)、第二引数がright(以下条件)となります。
※処理の都合上単一の日付のデータの読み込みだけだと動作確認として不適節なので2021-01-01~2021-01-20までの期間のデータを最初に読み込んで連結(concat)しています。
from typing import List
import pandas as pd
date_range = pd.date_range(start='2021-01-01', end='2021-01-20')
dfs: List[pd.DataFrame] = []
for date in date_range:
df: pd.DataFrame = pd.read_json(
'https://github.com/simon-ritchie/athena_workshop/blob/main/workshop/'
f"user_sales_daily/dt%3D{date.strftime('%Y-%m-%d')}/data.json.gz?raw=true",
lines=True, compression='gzip')
dfs.append(df)
df = pd.concat(dfs)
df = df[df['date'].between(left='2021-01-05', right='2021-01-15')]
print(df.head())
print(df.tail())
user_id sales date device_type
0 24066 500 2021-01-05 2
1 19850 15000 2021-01-05 1
2 8099 100 2021-01-05 2
3 14753 3000 2021-01-05 1
4 26010 50000 2021-01-05 1
user_id sales date device_type
237 14429 300 2021-01-15 1
238 14227 15000 2021-01-15 1
239 17147 10000 2021-01-15 1
240 14932 5000 2021-01-15 1
241 6826 15000 2021-01-15 2
特定の値の範囲外の値を取得する: NOT BETWEEN
先ほどのBETWEENとは逆のパターンを考えてみます。指定された区間に入らない行を対象にするといった具合です。
BETWEENを使わずに書くとWHERE <カラム名> < <条件値1> OR <カラム名> > '条件値2'といった具合に未満(<)と超過(>)の条件を書き、ORで繋げることで実現できます。例えば以下のようになります。
SELECT * FROM athena_workshop.user_sales_daily
WHERE date < '2021-01-05'
OR date > '2021-01-15'

こちらもBETWEENを使って同じことが実現できます。否定のNOTを加えてWHERE <カラム名> NOT BETWEEN <未満条件のしきい値> AND <超過条件のしきい値>というように書きます。
SELECT * FROM athena_workshop.user_sales_daily
WHERE date NOT BETWEEN '2021-01-05' AND '2021-01-15'
Pythonでの書き方
否定のチルダ記号(~)とbetweenメソッドを組み合わせることで同じことができます。
from typing import List
import pandas as pd
date_range = pd.date_range(start='2021-01-01', end='2021-01-20')
dfs: List[pd.DataFrame] = []
for date in date_range:
df: pd.DataFrame = pd.read_json(
'https://github.com/simon-ritchie/athena_workshop/blob/main/workshop/'
f"user_sales_daily/dt%3D{date.strftime('%Y-%m-%d')}/data.json.gz?raw=true",
lines=True, compression='gzip')
dfs.append(df)
df = pd.concat(dfs)
df = df[~df['date'].between(left='2021-01-05', right='2021-01-15')]
print(df.head())
print(df.tail())
user_id sales date device_type
0 19288 1000 2021-01-01 1
1 132 5000 2021-01-01 1
2 2183 300 2021-01-01 1
3 12446 100 2021-01-01 1
4 4894 10000 2021-01-01 2
user_id sales date device_type
250 4482 300 2021-01-20 2
251 5795 3000 2021-01-20 1
252 4135 100 2021-01-20 1
253 16065 100 2021-01-20 2
254 10726 100 2021-01-20 1
欠損値の行のみ取得する: IS NULL
ログには欠損値が入り込んだりします(特定の列などに値が入らなかったりするケース)。
そもそも値が取れない条件だったり、通信上の都合だったり、もしくはフロント(ゲームクライアント)側で何らか予期せぬことが発生して欠落したりといったこともあるかもしれません。
特に膨大なログが入るテーブルなどだと原因は不明なもののわずかに欠損値が紛れ込んだりします。
この節以降ではこの欠損値周りについて触れていきます。
説明のためここでは device_unique_id というテーブルを扱っていきます。iOSのIDFVのような端末判定用の端末ごとのユニーク(一意)なハッシュ値の文字列のデータを持つテーブルを想定しています。
このテーブルは以下のようなカラムを持っています。
- user_id: 対象のユーザーIDの整数のカラム。
- date: ログイン日の文字列のカラム。
- device_type: 端末種別の整数のカラム。iOS端末なのかAndroid端末なのかといった想定で、1(iOS)もしくは2(Android)の値が設定されます。
- unique_id: 端末ごとのユニークなハッシュ値の文字列のカラム。
unique_id カラムに関しては欠損値を少し含む形でデータを作ってあります。SELECT文を投げてみると以下のような構造になっているのが確認できます。
SELECT * FROM athena_workshop.device_unique_id
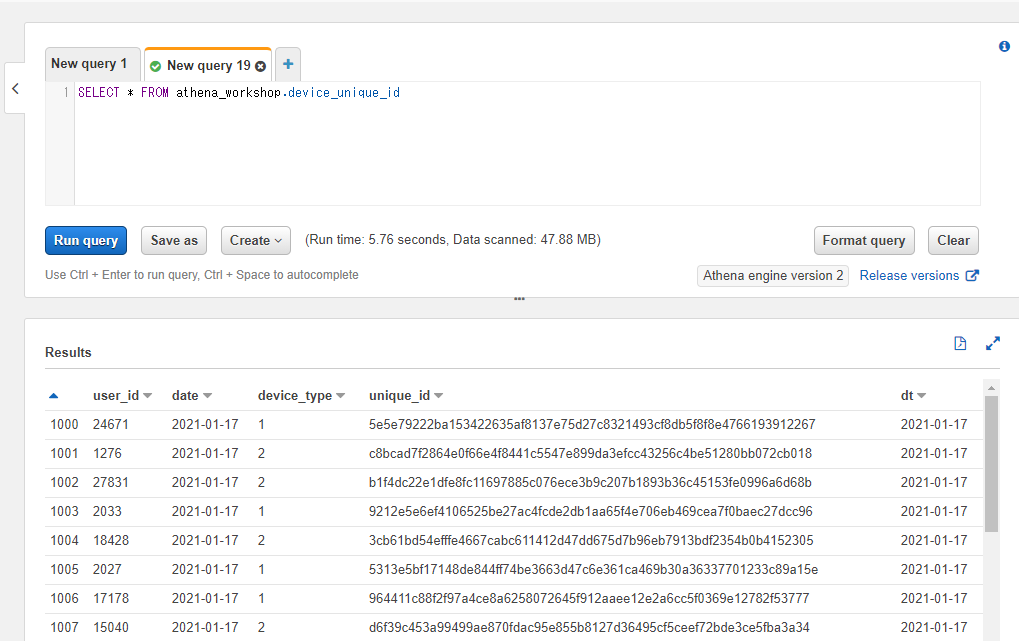
対象のカラムの値が欠損値かどうかを判定するにはIS NULLというキーワードを使います。WHERE <カラム名> IS NULLといったように書きます。
エンジニアの方にとってNULLとかはお馴染みな感じですが、エンジニア以外の方に向けて軽くNULLについてWikipediaから引用しておきます。
Null(ヌル、ナル)は、何もない、という意味で、プログラミング言語などコンピュータ関係では、「何も示さないもの」を表すのに使われる。同様のものとして、nil(ニル) が使われることもある。ただし、PythonのNoneのように他の名前のこともある。
Null - Wikipedia
※似たような性質のものでNAとかNaN(非数)とか色々ありますがここでは割愛します。
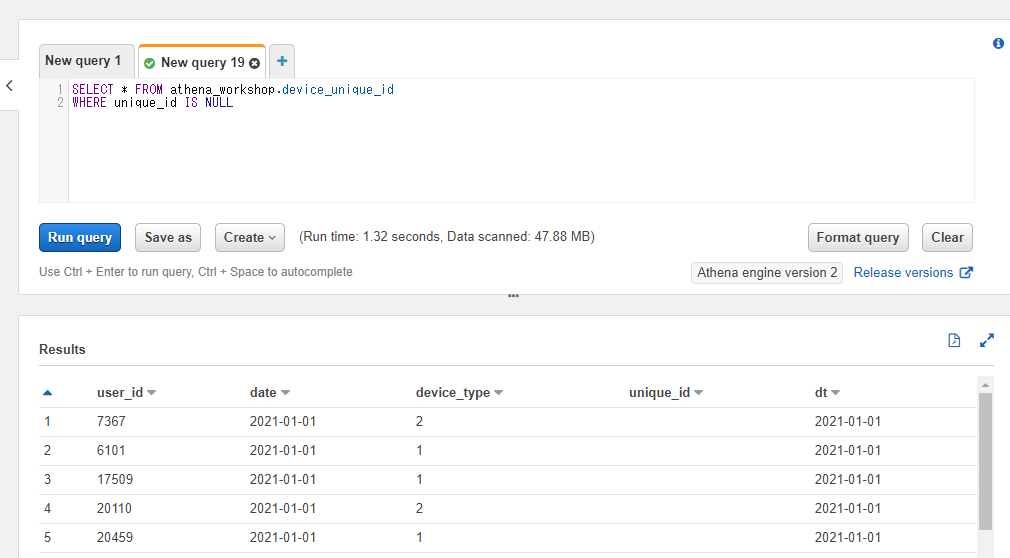
例えば今回の unique_id カラムの値が欠損している行のみ抽出したい・・・とする場合には以下のようなSQLになります。
SELECT * FROM athena_workshop.device_unique_id
WHERE unique_id IS NULL
結果を見ると unique_id の列部分が空欄になっていることが確認できます。
欠損値と空文字などの違いについて
補足となりますが、欠損値と空文字について軽く触れておきます。AWSのwebコンソール上では両方とも空欄で表示されるので紛らわしいですが挙動が違います。
欠損値はJSONのデータで言うと以下のように値がnullになっているかもしくはJSONのキー自体が存在しないケースが該当します(aとbというカラムを持つテーブルを想定してください)。
{"a": 10, "b": null}
{"a": 10}
一方で空文字に関しては以下のようにキーが存在し、nullではなく空の文字が設定されているケースが該当します。
{"a": 10, "b": ""}
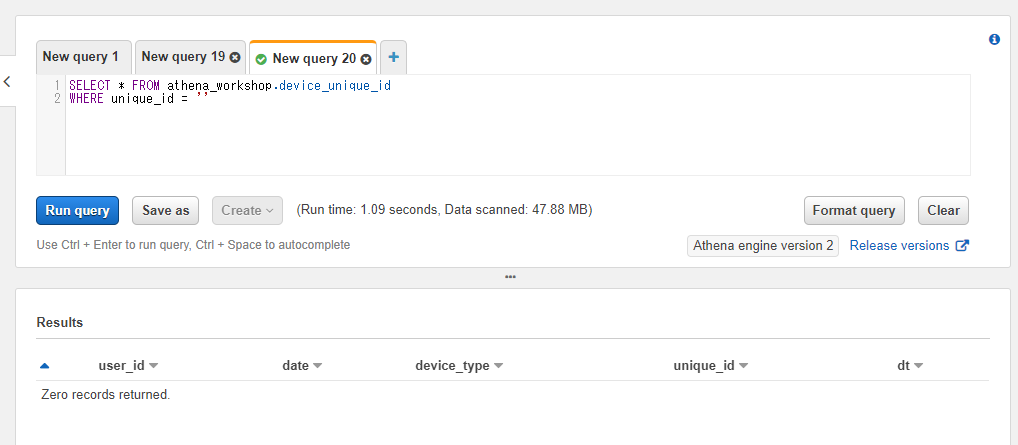
Athena上でも取り扱いがそのままだと異なります。例えば前節で触れたSQLでIS NULLの代わりに空文字をWHERE句で指定しても行がヒットしません(Zero records returnedとなります)。
SELECT * FROM athena_workshop.device_unique_id
WHERE unique_id = ''
空文字と欠損値両方取り除く必要がある場合などに片方だけ処理して片方うっかり対応を忘れる・・・といったことが無いように注意する必要があります。
Pythonでの書き方
df[df['<カラム名>'].isnull()]といった形でisnullメソッドを使うと対応ができます。
import pandas as pd
df: pd.DataFrame = pd.read_json(
'https://github.com/simon-ritchie/athena_workshop/blob/main/workshop/device_unique_id/dt%3D2021-01-01/data.json.gz?raw=true',
lines=True, compression='gzip')
df = df[df['unique_id'].isnull()]
print(df.head())
user_id date device_type unique_id
1065 7367 2021-01-01 2 None
1201 6101 2021-01-01 1 None
1759 17509 2021-01-01 1 None
1830 20110 2021-01-01 2 None
1858 20459 2021-01-01 1 None
欠損値以外の行のみ取得する: IS NOT NULL
欠損値の行を除いた行のみを抽出したい場合(IS NULLの逆のケース)にはIS NOT NULLを使います。
SELECT * FROM athena_workshop.device_unique_id
WHERE unique_id IS NOT NULL

Pythonでの書き方
否定の意味の半角のチルダ記号(~)とisnullメソッドを組み合わせて対応ができます。
import pandas as pd
df: pd.DataFrame = pd.read_json(
'https://github.com/simon-ritchie/athena_workshop/blob/main/workshop/device_unique_id/dt%3D2021-01-01/data.json.gz?raw=true',
lines=True, compression='gzip')
df = df[~df['unique_id'].isnull()]
print(df.head())
user_id date device_type unique_id
0 9958 2021-01-01 1 80dd469bc6fc1ac5c51bfca801c605d6cb296868a64471...
1 26025 2021-01-01 1 d302032f6b82abaf18f9df6bbde6ba999b901b7a8def00...
2 28390 2021-01-01 2 4ebfcc61825f46ca981eb56041ed837b1ff5bd08c495e4...
3 11977 2021-01-01 1 de24cf852f0270fe864de27b633e888d57ab55278b0030...
4 10732 2021-01-01 1 3420f6554809274949fab197b685f549e2b7d94ccb58f0...
Athenaとパーティションの話
Athenaで大切な話として、そしてMySQLなどで集計処理とかをしているとあまり意識しない(馴染みの無いことが多い)パーティションという要素があります(BigQueryでも似たようなものは存在します)。
AthenaではログのディスクサイズがS3(Athenaで利用するためのログを配置するためのAWSのストレージサービス)のストレージ料金として課金されるのに加えて、SQL実行時にアクセスされたログのサイズ(スキャンサイズ)によって料金が課金されます。そのためスキャンサイズを下げることが料金の無駄を抑えて且つSQLが完了するまでの時間を短くするために大切になります。
Athenaでスキャンサイズが減る要因は主に以下の3つです。
- WHERE句でパーティションに対して条件を指定した場合
- LIMIT句(後々の節で説明)を指定した場合
- Parquetなどの列指向のデータフォーマット(カラムナフォーマット)をログで使用し、且つSQLで対象の列を指定した場合
今回はParquetではなくJSONを使っているため3番目は関係無い(CSVやJSONの場合関係ありません)のと、エンジニアリング寄りの話になってくるため本記事では割愛します。その辺りが必要な場合には以下の記事などをご確認ください。
2番目のLIMIT句に関しては、ちょっとテーブル内容を確認する・・・といったケースを除くと、要件的に通常のSQLでは利用できないケースも多くなります。したがってスキャンサイズを減らすためには1番目の「WHERE句でパーティションに対して条件を指定した場合」という対応が中心になってきます。
パーティションってなんなんだ・・・?という感じですが、AthenaではS3上に以下のようにログのフォルダを時系列で分割してログを設置することが多くなります。
- dt=2021-01-01/
- dt=2021-01-02/
- dt=2021-01-03/
- ...
このフォルダ名に設定されているイコールの記号の左側がパーティション名となります。上の例ではdtという名前が該当します。
このパーティション名はS3へログを配置する際のフォルダ名のルール次第なのでプロジェクトによって様々です。以下のクラスメソッドさんの記事ではdtとなっていますし、日別で分けることが多いのでdateといった名前が使われるケースもあると思います(ただしテーブルのカラムに存在する名前はパーティションとして使えないので、dateカラムが存在する場合はdateといったパーティションは使えません)。
このログのフォルダ名に設定したパーティションはSQL上のWHERE句で指定することができます。例えば以下のように書きます。
SELECT * FROM athena_workshop.device_unique_id
WHERE dt = '2021-01-01'
このパーティション名(dt)部分は実際のログ上には存在しないカラム(テーブルには存在しないカラム)となりますが、クエリ結果にはあたかもそのdtカラムが存在するように表示されますし、他のカラムと同じ感覚でWHERE句などで指定することができます。
WHERE句でこのようにパーティションのフォルダ名を指定した場合、「その日付のフォルダのログだけにAthenaでアクセスする」といった挙動になります。逆に言うとこういったパーティションをWHERE句で設定しないとテーブルの全ログにアクセスするといういわゆるフルスキャンと呼ばれる挙動になります。フルスキャンの場合SQLの実行が終わるまでの時間が長くなりますしスキャンサイズも大きくなります(お金がより多くかかります)。
そのためパーティションが利用できる場合にはなるべくパーティションをWHERE句で指定することが好ましくなります。
※多くのプロジェクトでAthenaの1回のSQLでのスキャンサイズの制限の設定が(事故防止用に)設定されていたりすると思いますし、BigQueryなどだとパーティションをSQLで指定しないとそもそもSQLが実行できないようにできる設定などもありそこまでパーティション指定漏れなどを恐れる必要は無く(萎縮される必要は無く)どんどんSQLを実行していっていいとは考えています。
なお、パーティション以外のカラムに対してWHERE句で条件を指定してもスキャンサイズは減りません。例えばパーティションではない日付や日時などのカラムに対してWHERE句の条件を指定してもフルスキャンのままとなります。実際に試してみましょう。
AthenaのSQLのスキャンサイズは、webコンソールのSQL入力欄の下に配置されています。以下のスクショの例では47.88MBとなります。
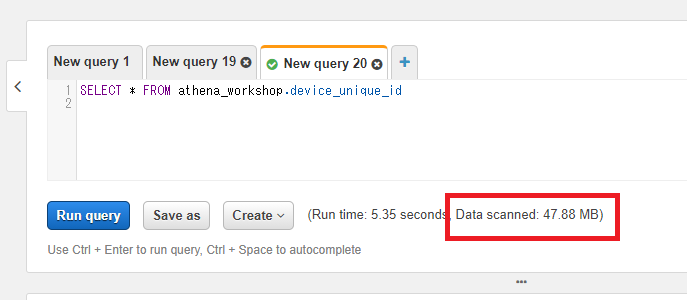
上記のスクショの例ではWHERE句を指定していないのでフルスキャンとなっています。今回はサンプルのログなのでサイズは小さいですが実際の仕事などではもっと遥かに巨大になります。
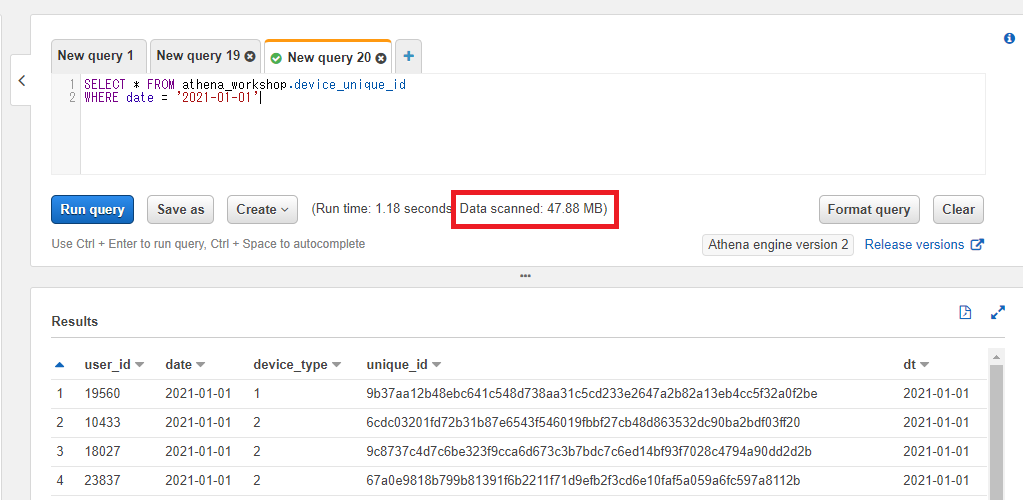
別途パーティション以外のカラム(今回はdateカラム)をWHERE句に指定してみます。
SELECT * FROM athena_workshop.device_unique_id
WHERE date = '2021-01-01'
結果のスキャンサイズが変わっていない(47.88MBでフルスキャンになっている)ことが確認できます。
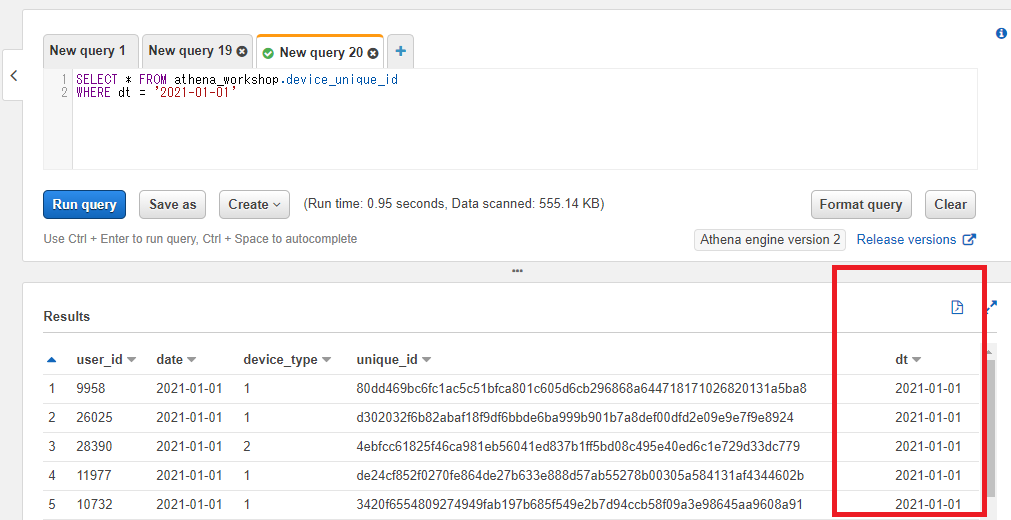
今度はパーティション(dt)を指定してみます。
SELECT * FROM athena_workshop.device_unique_id
WHERE dt = '2021-01-01'
今度はパーティションを指定しているのでスキャンサイズの表示がぐぐっと小さくなりました(555.14KB)。

テーブルによってはパーティションが設定されていないケースもあります(時系列的なログデータではないテーブルなど)。その辺りはAWSのwebコンソール上では左のサイドメニューのテーブル名部分で確認ができます。<テーブル名> (Partitioned)といったようにテーブル名の後にPartitionedと付いていたらそのテーブルに関してはパーティションが設定されています。

パーティション名がどんな名前になっているかはテーブル名の右にある縦の3点リーダー(︙)部分をクリックすると表示されるメニューで確認ができます。

Show propertiesをクリックします。
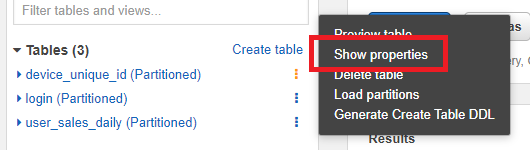
表示されるモーダル(ダイアログ)Partitionsのタブをクリックするとパーティション名が確認できます(今回はdtとなっています)。


昇順・降順でソートを行う: ORDER BY
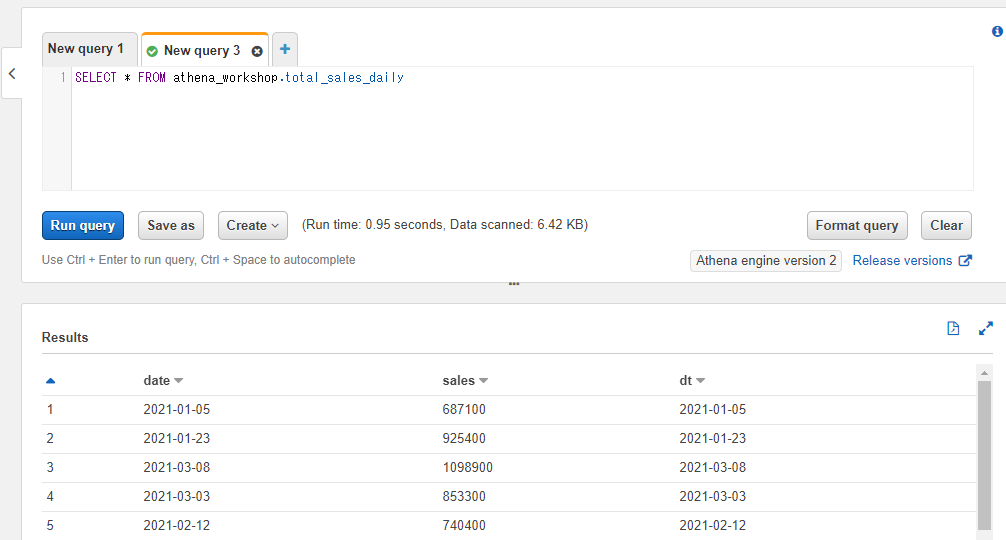
この節以降、日次の総売り上げを想定したtotal_sales_dailyというテーブルを扱っていきます。1日1行データが保存されるテーブルとなります。total_sales_dailyテーブルは以下の2つのカラムを持ちます。
- date: 対象日の文字列。
- sales: 対象日の総売り上げの整数。
クエリを投げてみると以下のような内容になっていることが確認できます。
SELECT * FROM athena_workshop.total_sales_daily
テーブルのデータを昇順(値の小さい順)もしくは降順(値の大きい順)に並べ替えたい場合にはORDER BYというキーワードを使います。ORDER BY <カラム名> <昇順・降順の指定>といった形で書きます。WHERE句などの後に記述します。
昇順もしくは降順の指定にはASCもしくはDESCを指定します。ASCはASCENDING(ASCENDING ORDERで昇順の意味)の略で、DESCはDESCENDING(DESCENDING ORDERで降順の意味)の略となります。
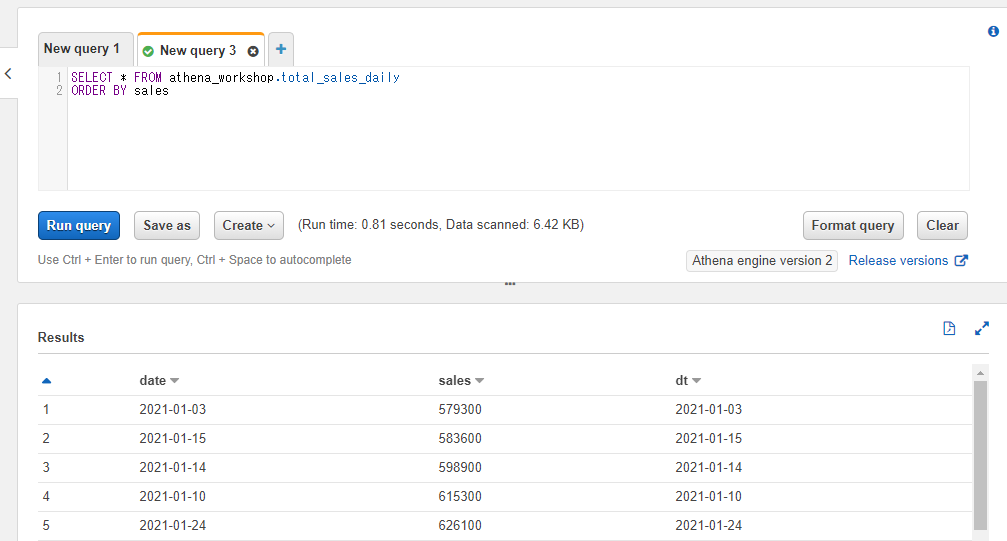
例えば日次の総売り上げのテーブルで低い順(昇順)で行の結果を取得したいといった場合には以下のようにASCを指定する形で書きます。
SELECT * FROM athena_workshop.total_sales_daily
ORDER BY sales ASC

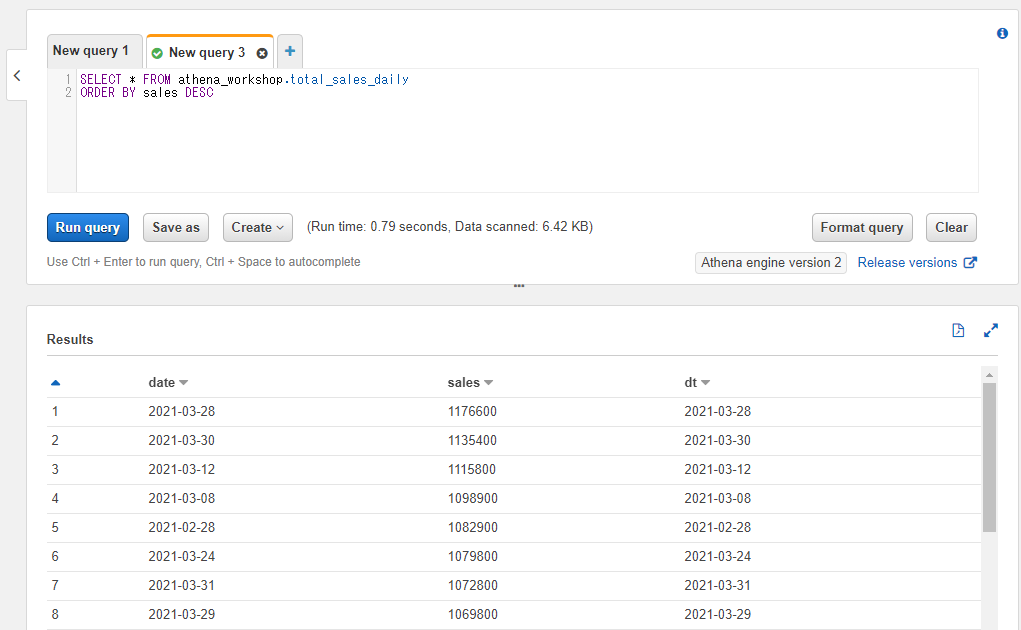
逆に日次の総売り上げの高い順(降順)で行の結果を取得したい場合には以下のようにDESCを指定する形で書きます。
SELECT * FROM athena_workshop.total_sales_daily
ORDER BY sales DESC
ASCやDESCの指定を省略することもできます。その場合は昇順の(ASCを指定したときと同様の)挙動となります。
SELECT * FROM athena_workshop.total_sales_daily
ORDER BY sales
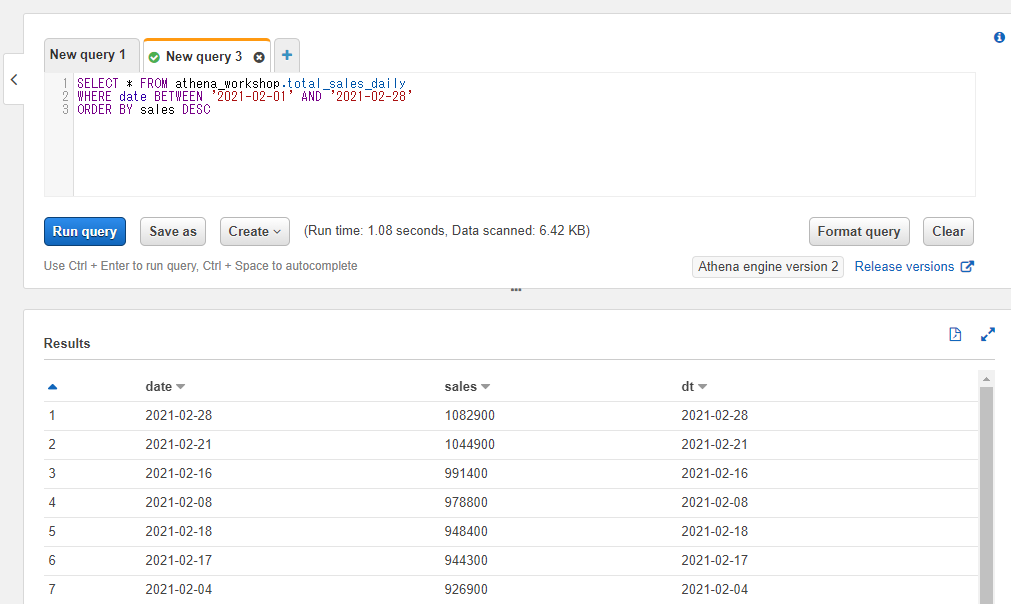
WHERE句などを使う場合にはORDER BYの前に書きます。その場合WHERE句で指定された条件の中で昇順もしくは降順の処理が実行されます。
例えば以下のSQLでは2021-02-01~2021-02-28の期間中で売り上げの高い日付順に表示されます。
SELECT * FROM athena_workshop.total_sales_daily
WHERE date BETWEEN '2021-02-01' AND '2021-02-28'
ORDER BY sales DESC
Pythonでの書き方
PythonではPandasのデータフレームでsort_valuesのメソッドでソートが行えます。by引数にソートで使いたいカラム名を指定します。inplace=Trueと指定するとデータフレームのコピーを取らずにダイレクトに行の更新がされます(メモリなどの節約になります)。inplace引数を省略した場合やFalseを指定した場合にはソート後のデータフレームのコピーが返却されるようになります。
昇順もしくは降順の指定はascending引数で設定します。省略した場合にはデフォルトとして昇順のソートとなります。
from typing import List
import pandas as pd
date_range = pd.date_range(start='2021-01-01', end='2021-01-10')
dfs: List[pd.DataFrame] = []
for date in date_range:
df: pd.DataFrame = pd.read_json(
'https://github.com/simon-ritchie/athena_workshop/blob/main/workshop/total_sales_daily/'
f"dt%3D{date.strftime('%Y-%m-%d')}/data.json.gz?raw=true",
lines=True, compression='gzip')
dfs.append(df)
df = pd.concat(dfs)
df.sort_values(by='sales', inplace=True)
print(df.head(10))
date sales
0 2021-01-03 579300
0 2021-01-10 615300
0 2021-01-05 687100
0 2021-01-09 709900
0 2021-01-01 768500
0 2021-01-06 773400
0 2021-01-08 784700
0 2021-01-04 790200
0 2021-01-02 828500
0 2021-01-07 850000
降順にしたい場合にはascending引数にFalseを指定します。
...
df.sort_values(by='sales', inplace=True, ascending=False)
print(df.head(10))
date sales
0 2021-01-07 850000
0 2021-01-02 828500
0 2021-01-04 790200
0 2021-01-08 784700
0 2021-01-06 773400
0 2021-01-01 768500
0 2021-01-09 709900
0 2021-01-05 687100
0 2021-01-10 615300
0 2021-01-03 579300
複数の列をソートに指定する
この節から説明のために日別の端末種別(iOS, Android)ごとの合算の売り上げを想定したtotal_sales_per_device_dailyというテーブルに触れていきます。1日2行ずつ保存されるテーブルとなります。以下のような各カラムを持ちます。
- date: 対象日の文字列。
- device_type: 対象の端末種別の整数値(1=iOS, 2=Android想定)。
- sales: その日の対象の端末種別での総売り上げの整数。
クエリを投げてみると以下のような内容になっていることが確認できます。
SELECT * FROM athena_workshop.total_sales_per_device_daily

複数のカラムを使ったソートも指定できます。その場合まず1つ目のカラムでソートが実行され、そのカラムで値が同じ行が複数ある場合に2つ目のカラムでソートされる・・・といった挙動になります。
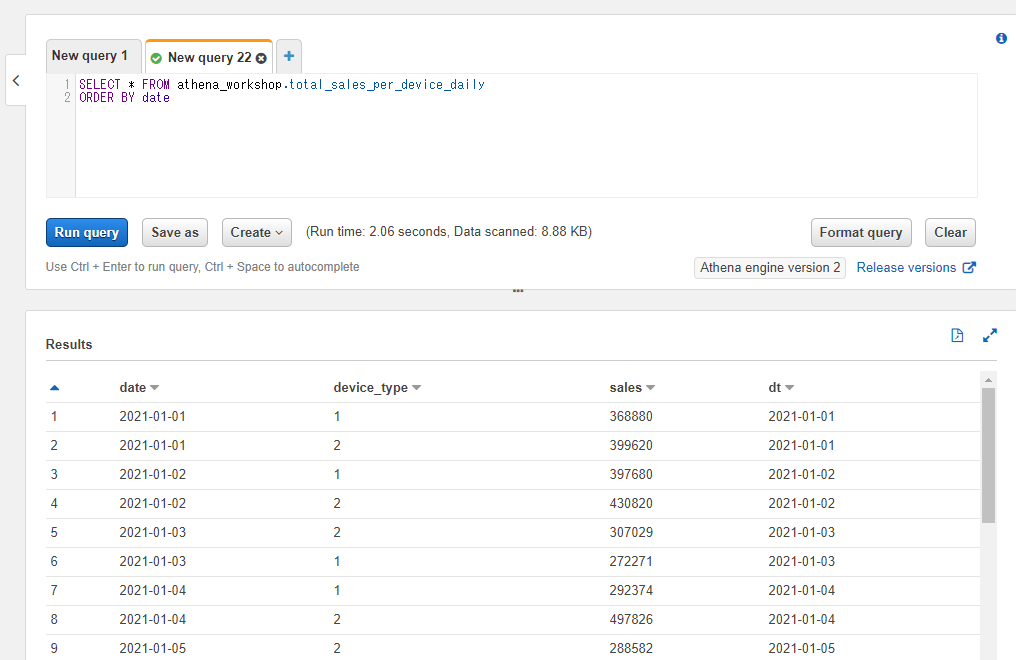
例えば以下のように端末ごとの日別の売り上げのテーブルにて日付のみのカラムで昇順ソートしたとします。その場合日付はソートされますが端末種別のカラム(device_type)は1, 2, 1, 2, 2, 2, 1, 1...と、必ずしも順番どおりに1, 2, 1, 2, 1, 2...とはなっていません。
SELECT * FROM athena_workshop.total_sales_per_device_daily
ORDER BY date
このような時に、日付でソートされた結果をさらに端末種別でソートしたい場合にはORDER BY date, device_idといったように半角のコンマ区切りで複数のカラムを指定します。
SELECT * FROM athena_workshop.total_sales_per_device_daily
ORDER BY date, device_type
今度はdevice_idのカラムが1, 2, 1, 2, 1, 2...と順番になっていることが確認できます。

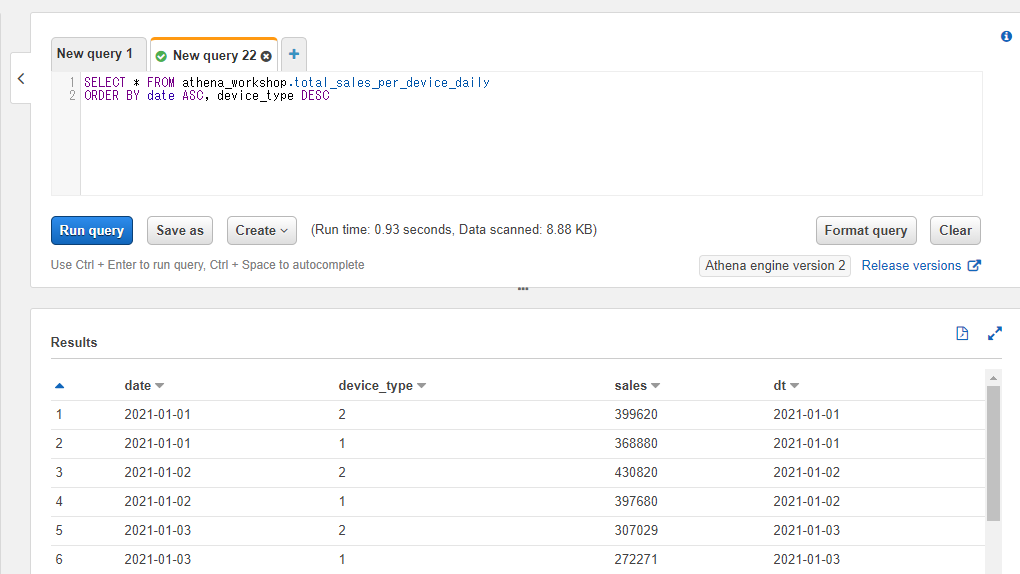
なお、ASCやDESCなどによる昇順・降順の指定はカラムごとに行えます。例えば日付は昇順・端末種別は降順みたいな指定をしたい場合には以下のように書くことができます(device_typeが2, 1, 2, 1...という並びになります)。
SELECT * FROM athena_workshop.total_sales_per_device_daily
ORDER BY date ASC, device_type DESC
Pythonでの書き方
Pythonではsort_valuesメソッドのby引数でリストやタプルが指定できるのでそちらに複数のカラム名を指定することで同じことができます。
from typing import List
import pandas as pd
date_range = pd.date_range(start='2021-01-01', end='2021-01-10')
dfs: List[pd.DataFrame] = []
for date in date_range:
df: pd.DataFrame = pd.read_json(
'https://github.com/simon-ritchie/athena_workshop/blob/main/workshop/total_sales_per_device_daily/'
f"dt%3D{date.strftime('%Y-%m-%d')}/data.json.gz?raw=true",
lines=True, compression='gzip')
dfs.append(df)
df = pd.concat(dfs, ignore_index=True)
df.sort_values(by=['date', 'device_type'], inplace=True)
print(df.head(10))
date device_type sales
0 2021-01-01 1 368880
1 2021-01-01 2 399620
2 2021-01-02 1 397680
3 2021-01-02 2 430820
4 2021-01-03 1 272271
5 2021-01-03 2 307029
6 2021-01-04 1 292374
7 2021-01-04 2 497826
8 2021-01-05 1 398518
9 2021-01-05 2 288582
各カラムごとに昇順・降順の指定を行いたい場合には、ascending引数も同様にリストやタプルを受け付けてくれるのでby引数で指定した各カラムと同じ順番で真偽値を指定すると実現できます(以下の例では日付は昇順・端末種別は降順にしてあります)。
from typing import List
import pandas as pd
date_range = pd.date_range(start='2021-01-01', end='2021-01-10')
dfs: List[pd.DataFrame] = []
for date in date_range:
df: pd.DataFrame = pd.read_json(
'https://github.com/simon-ritchie/athena_workshop/blob/main/workshop/total_sales_per_device_daily/'
f"dt%3D{date.strftime('%Y-%m-%d')}/data.json.gz?raw=true",
lines=True, compression='gzip')
dfs.append(df)
df = pd.concat(dfs, ignore_index=True)
df.sort_values(
by=['date', 'device_type'], inplace=True, ascending=[True, False])
print(df.head(10))
date device_type sales
1 2021-01-01 2 399620
0 2021-01-01 1 368880
3 2021-01-02 2 430820
2 2021-01-02 1 397680
5 2021-01-03 2 307029
4 2021-01-03 1 272271
7 2021-01-04 2 497826
6 2021-01-04 1 292374
9 2021-01-05 2 288582
8 2021-01-05 1 398518
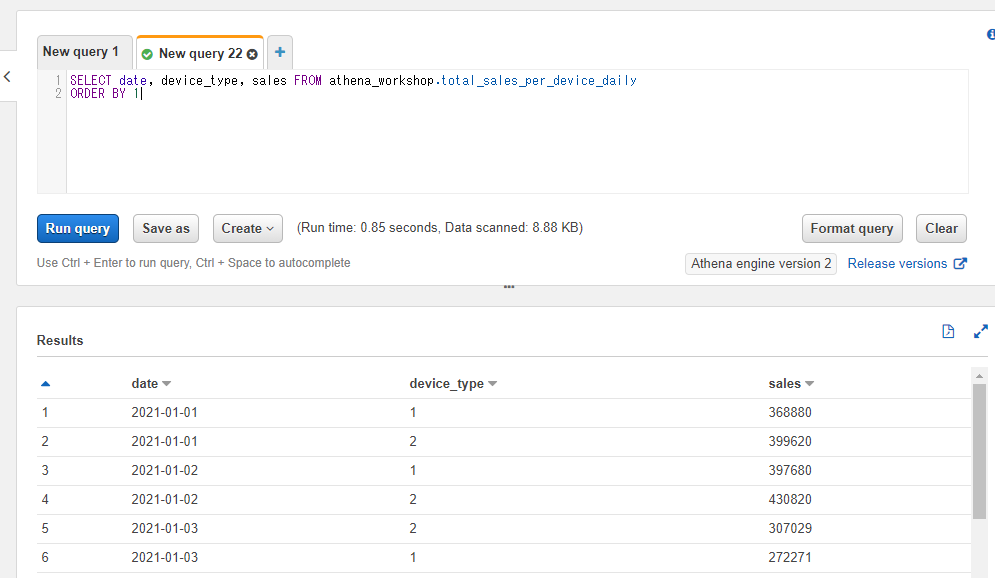
ORDER BYはカラム名の代わりに整数も指定できる
ORDER BYにはカラム名の代わりに順番の整数を指定することもできます。例えば1を指定すれば先頭のカラム、2を指定すれば2番目のカラムがソート対象のカラムとして設定されます。プログラムの配列などでのインデックスのように0からのスタートではなく1からのスタートとなります。
例えば以下のSQLでは1が指定されているので、先頭のカラム(date)によるソートが実行されます。
SELECT date, device_type, sales FROM athena_workshop.total_sales_per_device_daily
ORDER BY 1
通常のカラムの指定時と同様にこちらも複数のカラム番号をORDER BYに指定することもできます。以下の例では1番目のdateカラムと2番目のdevice_typeの2つのカラムでソートを行っています。
SELECT date, device_type, sales FROM athena_workshop.total_sales_per_device_daily
ORDER BY 1, 2
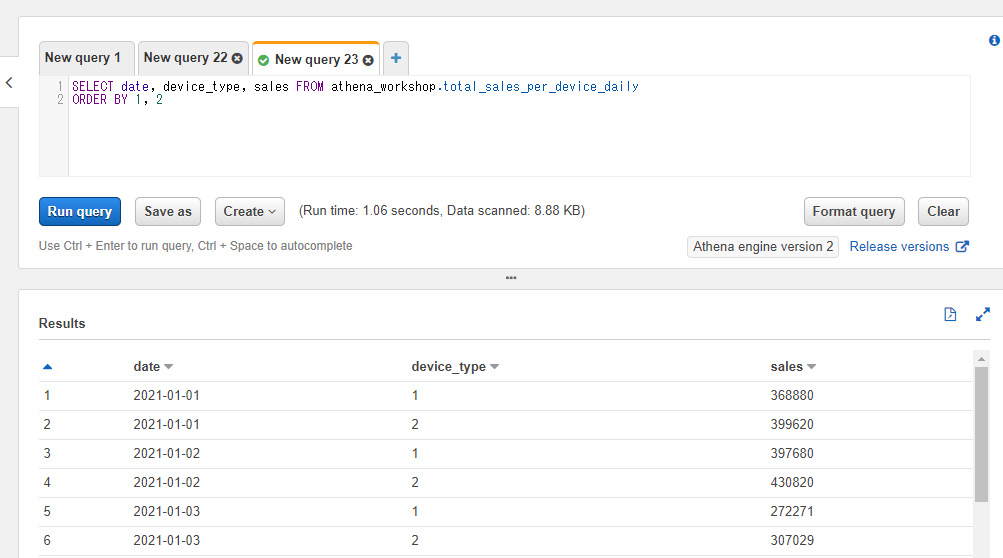
この書き方は記述が少なくシンプルで済むので便利なケースがそれなりにあります。また、後の節で触れるASなどのキーワードでカラム順を変えないままカラム名を何度も調整する際に便利です。
一方で、カラム順の変更には弱い書き方となります。カラム名に*を指定して全カラムを指定した場合などにはSQLを実行するかテーブル構造を確認しないとn番目のカラムが分かりづらいですし、カラムの順番を変更した時にORDER BYの記述を調整しなかったため予期せぬ集計になってしまった・・・といったことも発生し得るものになります。カラム名を明示してORDER BYをしている場合にはカラム順が変わっても影響は出ませんし、エラーで事前にミスに気づくやすいケースも発生すると思います。
個人的な好みではさくっと書くシンプルで短いSQLであればカラム順でORDER BYを設定するのもアリだと思いますし、逆に長く複雑なSQLの場合にはカラム名などを明示していた方がいいかな・・・といった印象です。
読み込む行数を制限する: LIMIT
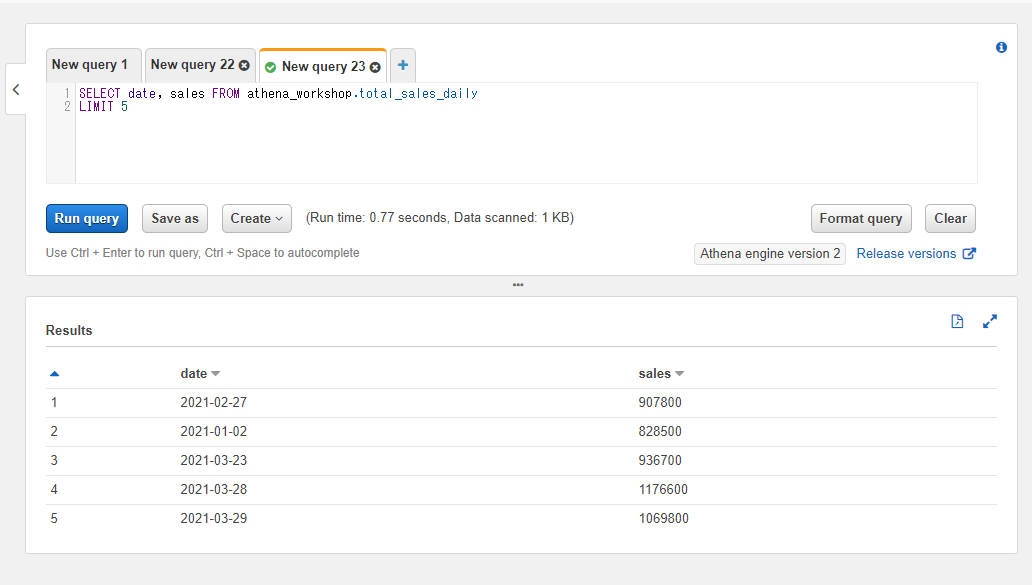
読み込む行数の制限をする場合にはLIMIT句を使います。LIMIT <行数上限>と書き、SQLの最後に追加します。
例えば5行のみ読み込みたい場合には以下のように書きます。
SELECT date, sales FROM athena_workshop.total_sales_daily
LIMIT 5
結果が5行のみになります。
ORDER BYなどと組み合わせると、「上位n件」とか「下位n件」といった制御ができるようになります。
例えば以下のサンプルでは日次売り上げの上位3位の日付の行を抽出しています。
SELECT date, sales FROM athena_workshop.total_sales_daily
ORDER BY sales DESC
LIMIT 3

なお、ORDER BYなどを利用していなければLIMIT句を使うとAthenaでは基本的にスキャンサイズが減ります。並列で処理が動きつつ停止できる条件を満たした段階で停止し、そのタイミングはSQL実行ごとにばらけるので実行の度にスキャンサイズは変動しますが基本的にスキャンサイズは低下します(一方でORDER BYなどでソートをするようなケースでは、対象のデータ全てをスキャンしないとソートができないのでスキャンサイズが減らないケースもあります)。
SQLを実行する前に調査で特定のテーブルに対して内容を軽くしたい・・・といった場合に便利です(UI上のPreview tableというメニューを選択した時にも自動でLIMIT句が設定されるようになっています)。

Pythonでの書き方
n件までに絞りこみたい場合には、データフレームのインデックスに連番が振られていればdf[:n]といったスライスの書き方が使えます。例えば10行のみ残したい場合には以下のように書きます。
import pandas as pd
df: pd.DataFrame = pd.read_json(
'https://github.com/simon-ritchie/athena_workshop/blob/main/workshop/login/dt%3D2021-01-01/data.json.gz?raw=true',
lines=True, compression='gzip')
df = df[:10]
print(df)
user_id time device_type
0 8590 2021-01-01 00:00:01 1
1 568 2021-01-01 00:00:02 1
2 17543 2021-01-01 00:00:04 2
3 15924 2021-01-01 00:00:07 1
4 5243 2021-01-01 00:00:09 2
5 20229 2021-01-01 00:00:16 2
6 2833 2021-01-01 00:00:18 1
7 23458 2021-01-01 00:00:18 1
8 14267 2021-01-01 00:00:20 1
9 1299 2021-01-01 00:00:20 1
もしくはheadメソッドでもnという引数で先頭のn件を残した形のデータフレームを返却するのでこちらでも対応ができます。
import pandas as pd
df: pd.DataFrame = pd.read_json(
'https://github.com/simon-ritchie/athena_workshop/blob/main/workshop/login/dt%3D2021-01-01/data.json.gz?raw=true',
lines=True, compression='gzip')
print(df.head(n=10))
user_id time device_type
0 8590 2021-01-01 00:00:01 1
1 568 2021-01-01 00:00:02 1
2 17543 2021-01-01 00:00:04 2
3 15924 2021-01-01 00:00:07 1
4 5243 2021-01-01 00:00:09 2
5 20229 2021-01-01 00:00:16 2
6 2833 2021-01-01 00:00:18 1
7 23458 2021-01-01 00:00:18 1
8 14267 2021-01-01 00:00:20 1
9 1299 2021-01-01 00:00:20 1
テーブル名に別の名前を設定する
SQLのWHEREやORDER BYなどで指定するカラムに関しては、この節に触れてきた内容だとデータベース名やテーブル名の指定を省略しても動作します。一方で以下のように省略せずに書くこともできます。
SELECT date, sales FROM athena_workshop.total_sales_daily
WHERE athena_workshop.total_sales_daily.date >= '2021-02-01'
ORDER BY athena_workshop.total_sales_daily.sales DESC
DB名やテーブル名を指定しなくても済むケースであれば省略したほうが記述がシンプルです。一方で後々の節で触れていきますが他のテーブルを連結して同時に扱ったり複数のDB(場合によっては複数のデータカタログ)を参照する必要が出てくるケースも多くあり、そのような場合にはDB名やテーブル名を明示的に指定しないとSQLでエラーになってしまうことが発生してきます。
そういった場合に上記のように長い指定だとちょっと大変だったり煩雑なケースがあります。そのような場合にASを使うと対象のテーブル名(DB名やデータカタログなどの指定部分なども含みます)に別の名前を設定してSQL上で扱うことができます。
例えば先ほどのSQLでテーブル名にsales_tableと短い名前を付けたい場合には以下のようにASを使って書きます。
SELECT date, sales FROM athena_workshop.total_sales_daily AS sales_table
WHERE sales_table.date >= '2021-02-01'
ORDER BY sales_table.sales DESC
記述が短くシンプルになりました。今のところはまだそこまでメリットが目立ちませんが、テーブル連結や複雑なSQLになってくるほどこのASの機能が便利になってきます。
カラム名に別の名前を設定する
カラム名に関してもテーブル名と同様にASを使って別の名前を設定してSQL上で扱うことができます。<元のカラム名> AS <新しく設定するカラム名>といったように書きます。
新しく設定したカラム名はSQL結果の表にも反映されます。
ORDER BYなどにはASで設定したカラム名は利用できますが、WHERE句に関してはASで指定したカラム名を利用することはできずに元のカラム名を指定する必要があります。
SELECT date AS sales_date, sales AS total_sale FROM athena_workshop.total_sales_daily
WHERE date >= '2021-02-01'
ORDER BY total_sale DESC
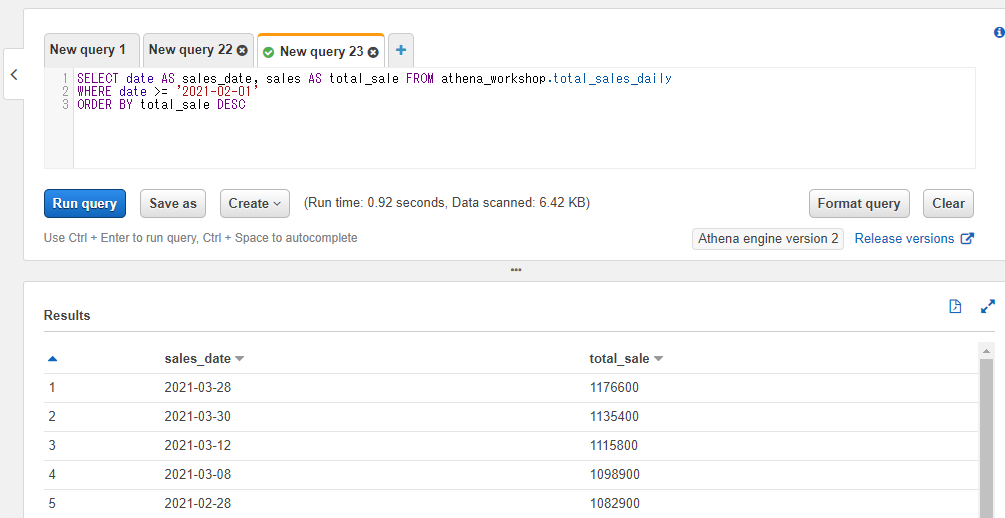
WHERE句でASで指定したカラム名を指定してしまうと以下のようにエラーになります。
SELECT date AS sales_date, sales AS total_sale FROM athena_workshop.total_sales_daily
WHERE sales_date >= '2021-02-01'
ORDER BY total_sale DESC
こちらもここまでではそこまでメリットが目立ちませんが、後々の節でテーブル連結や複雑なSQLを扱っていくようになると頻繁に利用するようになってきます。
Pythonでの書き方
renameメソッドでcolumns引数に辞書を指定することで設定ができます。辞書にはキー側に元のカラム名、値に新しいカラム名を指定します。Python側ではWHERE句では使えない・・・といったことは無いのでスライスなど諸々の制御は新しいカラム名で行います。
import pandas as pd
df: pd.DataFrame = pd.read_json(
'https://github.com/simon-ritchie/athena_workshop/blob/main/workshop/total_sales_daily/dt%3D2021-01-01/data.json.gz?raw=true',
lines=True, compression='gzip')
df.rename(columns={'date': 'sales_date', 'sales': 'total_sale'}, inplace=True)
print(df.head())
sales_date total_sale
0 2021-01-01 768500
基本計算
以降の節ではSQLを使った基本的な計算・集計などについて触れていきます。
ユニーク(一意)な値を取得する: DISTINCT
特定の列のユニークな値(重複の無い一意な値)を取得するにはDISTINCTを使います。例えばユーザーデータでクエストのマスタIDなどに対して実行してみて、「今どの(イベント)クエストが実行可能なんだろう?」といったことを一覧表示したりすることができます。普通に表示すると重複などで情報が埋もれてしまい俯瞰しづらい場合などに便利です。
もしくはログインする度にログが入るテーブルがあったとして、ユーザーのIDで重複を削除してユニークなユーザー数は何人なんだろう?といった調査などにも使えます(後に出てくるCOUNTなどと組み合わせることで実現できます)。
DISTINCTを使う場合にはDISTINCT(<対象のカラム名>)といったようにカラムを指定するSQL部分で書きます。例えばSELECT DISTINCT(sales) FROM ...といったように書きます。
以下のSQLではユーザーごとの売り上げのテーブルに対してDISTINCTを使っています。重複が削除されて9行のみ残っていることが確認できます(実務ではもっとばらけますが、今回はサンプルデータなのでAppstoreなどで購入できる課金アイテムの種類が限られていて且つ1日の購入数が限られている・・・みたいなケースとお考えください)。
SELECT DISTINCT(sales) FROM athena_workshop.user_sales_daily
ORDER BY sales
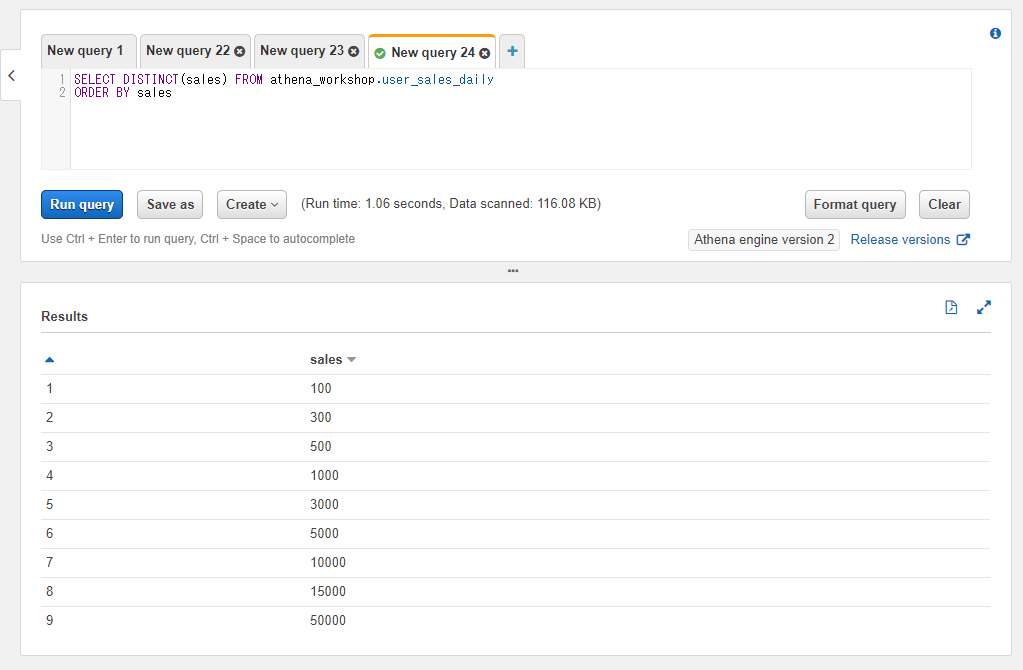
なおDISTINCTの後の()の括弧は省略可能です。以下のように省略して書くこともできます。
SELECT DISTINCT sales FROM athena_workshop.user_sales_daily
ORDER BY sales
Pythonでの書き方
いくつか実現方法はあるのですが、一例としてdrop_duplicatesで重複している行を削除しています。判定を行うカラムをsubset引数にリストで指定します。今回は単一のカラムを指定しています。
import pandas as pd
df: pd.DataFrame = pd.read_json(
'https://github.com/simon-ritchie/athena_workshop/blob/main/workshop/user_sales_daily/dt%3D2021-01-01/data.json.gz?raw=true',
lines=True, compression='gzip')
df.drop_duplicates(subset=['sales'], inplace=True)
df.sort_values(by='sales', inplace=True)
df.reset_index(drop=True, inplace=True)
print(df['sales'])
0 100
1 300
2 500
3 1000
4 3000
5 5000
6 10000
7 15000
8 50000
DISTINCTは複数のカラムを指定することができる
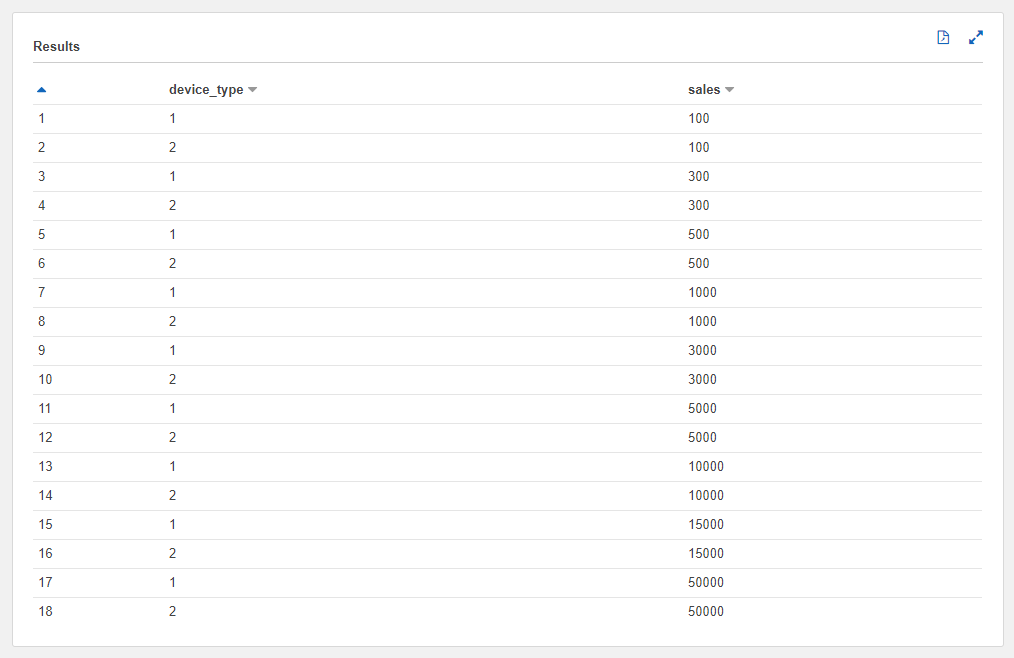
DISTINCTには複数のカラムを指定することができます。DISTINCT <カラム1>, <カラム名2>, ...と書きます。
複数のカラムでユニーク判定がされるため、単体のカラムを指定した時よりも組み合わせによって残る行が増えます。
例えばユーザーごとの売り上げのカラムと端末種別の2つのカラムに対してDISTINCTを指定した場合iOS(device_type = 1)とAndroid(device_type = 2)それぞれで100円の売り上げの行が1行ずつ残ったりと行数が2倍になります。
SELECT DISTINCT device_type, sales FROM athena_workshop.user_sales_daily
ORDER BY sales, device_type
行数が単一のカラムを指定した時の2倍の18行になっていることも確認できます。
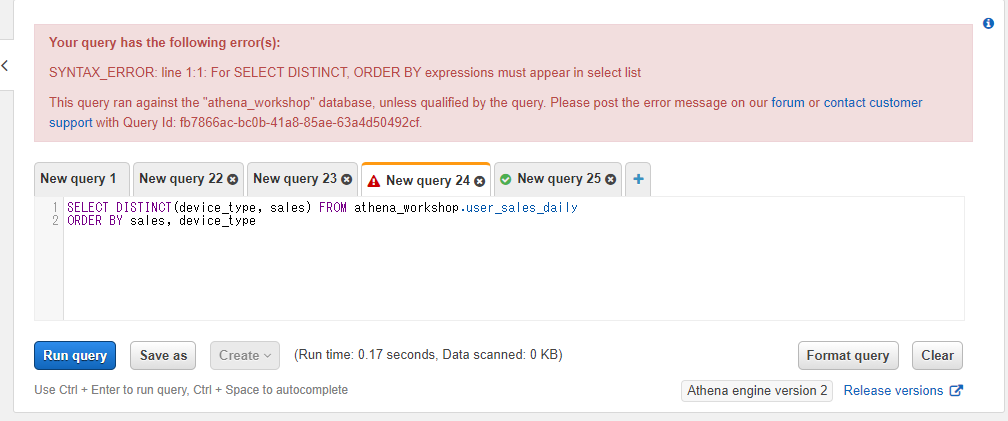
なお、カラム単体を指定した時と異なり複数のカラムをDISTINCTで指定する場合にはDISTINCTの後の括弧は省略しないと挙動が変わります。ORDER BYなどと絡んでエラーになる条件が増えたりもしまし、結果も変わります。例えば以下のSQLではエラーとなってしまいます。
SELECT DISTINCT(device_type, sales) FROM athena_workshop.user_sales_daily
ORDER BY sales, device_type
Pythonでの書き方
drop_duplicatesメソッドのsubset引数がリストで指定できるので、そちらに複数のカラム名を指定することで対応ができます。
import pandas as pd
df: pd.DataFrame = pd.read_json(
'https://github.com/simon-ritchie/athena_workshop/blob/main/workshop/user_sales_daily/dt%3D2021-01-01/data.json.gz?raw=true',
lines=True, compression='gzip')
df.drop_duplicates(subset=['device_type', 'sales'], inplace=True)
df.sort_values(by=['sales', 'device_type'], inplace=True)
df.reset_index(drop=True, inplace=True)
print(df[['device_type', 'sales']])
0 1 100
1 2 100
2 1 300
3 2 300
4 1 500
5 2 500
6 1 1000
7 2 1000
8 1 3000
9 2 3000
10 1 5000
11 2 5000
12 1 10000
13 2 10000
14 1 15000
15 2 15000
16 1 50000
17 2 50000
行数を計算する: COUNT
対象のテーブルの行数を確認するにはCOUNTを使います。COUNT(*)もしくはCOUNT(<特定のカラム名>)といったように書きます。
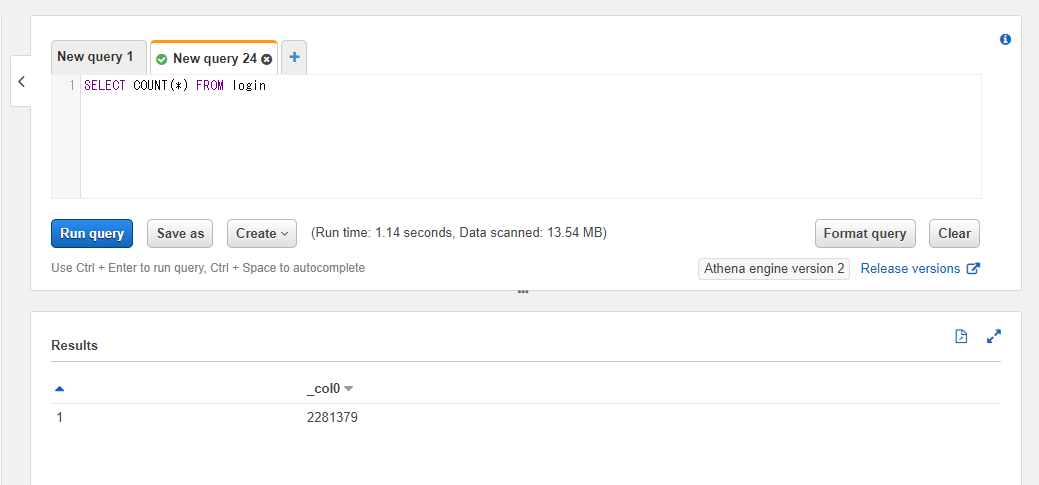
例えばログインログのテーブルの行数を調べたい場合には以下のようなSQLとなります。
SELECT COUNT(*) FROM athena_workshop.login
200万行強の行数になっていることを確認できます。
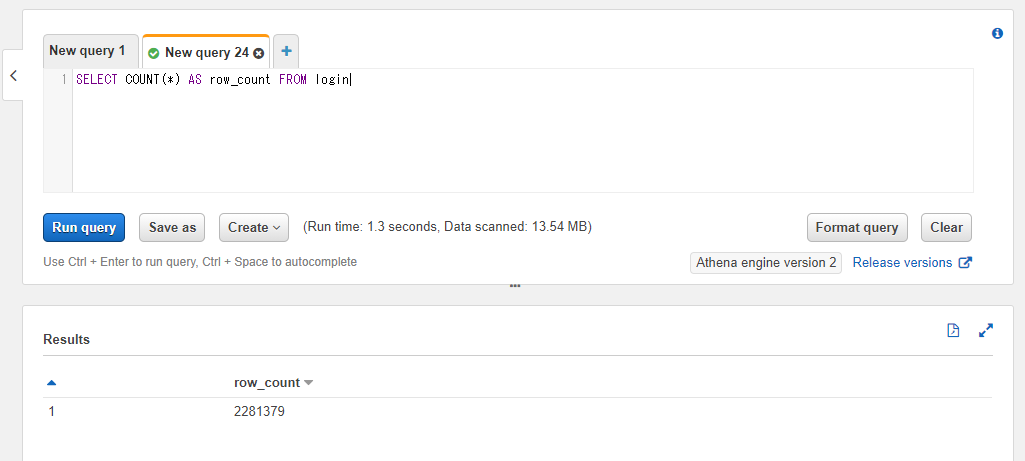
デフォルトでは結果のカラムは_col0といった表記になってしまうので気になる場合は前節で触れたASを使うことで別の名前を付けることができます。例えばrow_countという名前を付けたい場合には以下のように書きます。
SELECT COUNT(*) AS row_count FROM athena_workshop.login
Pythonでの書き方
COUNT(*)といったものと同様の行数の確認がしたい場合にはビルトインのlen関数をデータフレームに通せば普通に行数の確認ができます。
※Python側では1日分のログにのみアクセスしているため行数結果はSQL(全期間対象)とは異なっています。
import pandas as pd
df: pd.DataFrame = pd.read_json(
'https://github.com/simon-ritchie/athena_workshop/blob/main/workshop/login/dt%3D2021-01-01/data.json.gz?raw=true',
lines=True, compression='gzip')
print(len(df))
24453
COUNTで特定の列を指定した場合とアスタリスクを指定した場合では結果が変わることがある
COUNT(*)と全カラムを対象にした場合とCOUNT(<特定のカラム>)と指定した場合で結果が変わることがあります。というのもCOUNTは「対象のカラムの欠損値以外の行をカウントする」という挙動をします。
全カラムが欠損値のテーブルは通常はほぼ発生しないと思いますのでCOUNT(*)とした場合には実質的に「そのテーブルのトータルの行数」となります。COUNT(<特定のカラム>)とした場合には「そのカラムで欠損値以外の行数」という挙動になります。
試しに欠損値を含むカラムを持つテーブルに対してSQLを投げてみて確認してみます。
SELECT COUNT(*) AS row_count FROM athena_workshop.device_unique_id

SELECT COUNT(unique_id) AS row_count FROM athena_workshop.device_unique_id

全行を対象とした場合1138026行、欠損値を含むカラムを指定した場合には1137881行と後者の方が少し行数が減っていることが確認できます。
Pythonでの書き方
前節で触れたようなlen関数を通す書き方だと欠損値の行も含んだ全行の判定となります。特定行で欠損値以外の行数をカウントしたい場合には特定の列のシリーズに対してcountメソッドを使います。
import pandas as pd
df: pd.DataFrame = pd.read_json(
'https://github.com/simon-ritchie/athena_workshop/blob/main/workshop/device_unique_id/dt%3D2021-01-01/data.json.gz?raw=true',
lines=True, compression='gzip')
print('全体の行数:', len(df))
print('欠損値を含まない行数:', df['unique_id'].count())
全体の行数: 12928
欠損値を含まない行数: 12868
COUNTではDISTINCTのように複数のカラムを指定したり括弧を省略することはできない
COUNTではDISTINCTのように複数のカラムを指定することはできません。単一のカラムもしくはアスタリスクによる全カラム指定のみ使えます。
例えば以下のようにSQLを書いてみてもエラーになります。
SELECT COUNT date, sales FROM athena_workshop.total_sales_daily

DISTINCTと組み合わせてユニーク値の行数を計算する
前節までのDISTINCTとCOUNTを組み合わせることでユニークな値の行数を計算することができます。特定のカラムにいくつの値があるのかといったことを確認することができます。
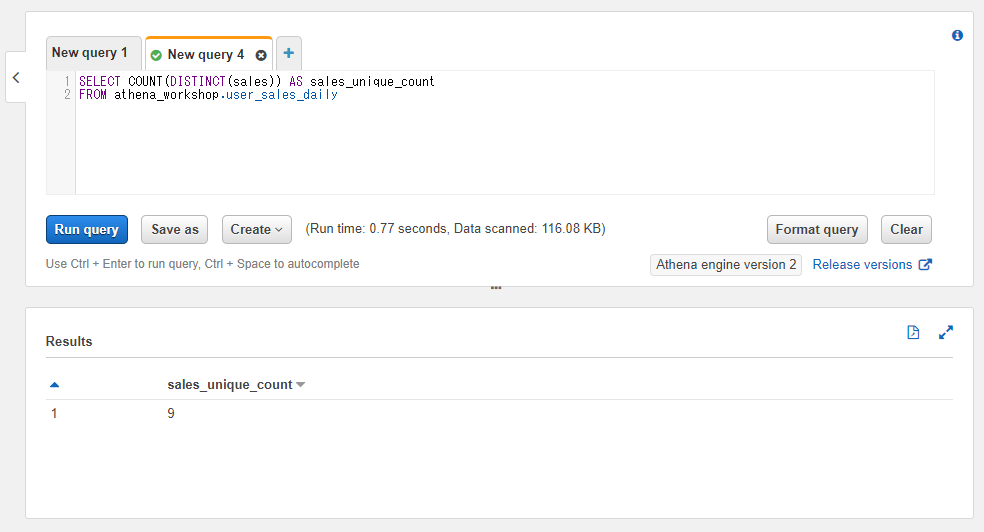
COUNT(DISTINCT(<対象のカラム>))といったようにCOUNTの中にDISTINCTを入れます(入れ子にします)。中のものから先に処理されるので、まず先にDISTINCTのユニーク処理・続いてそれらに対して行数のカウントが実行されます。
SELECT COUNT(DISTINCT(sales)) AS sales_unique_count
FROM athena_workshop.user_sales_daily
Pythonでの書き方
df['<対象のカラム>'].unique()で特定のカラムのユニークなNumPy配列(ndarray)が得られるので、そちらにlen関数を通せばユニークな行数が確認できます。
import pandas as pd
df: pd.DataFrame = pd.read_json(
'https://github.com/simon-ritchie/athena_workshop/blob/main/workshop/user_sales_daily/dt%3D2021-01-01/data.json.gz?raw=true',
lines=True, compression='gzip')
print(len(df['sales'].unique()))
9
平均を計算する: AVG
特定のカラムの平均値を集計したい場合にはAVGを使います。平均は英語でaverageもしくはmeanなのでその略となります。
AVG(<対象のカラム名>)というように書きます。
SELECT AVG(sales) AS sales_avarage
FROM athena_workshop.user_sales_daily
WHERE dt = '2021-01-01'
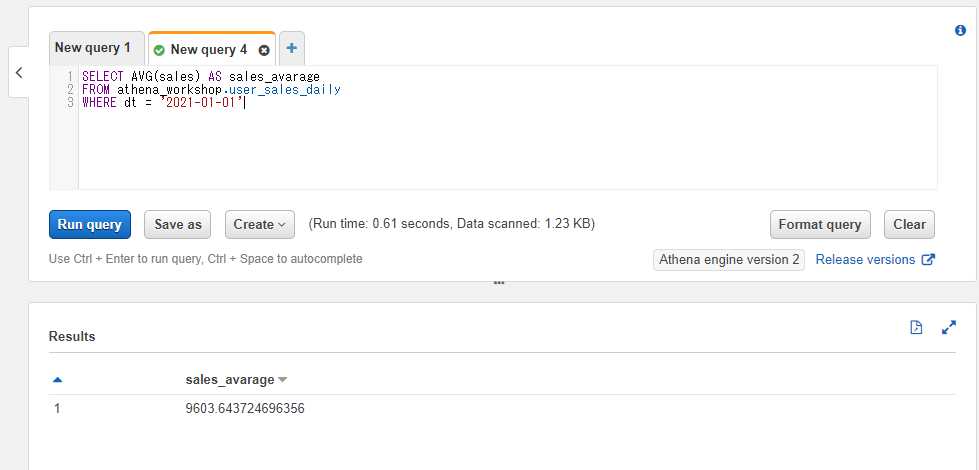
Pythonでの書き方
df[<対象のカラム>].mean()で平均のスカラー値が返ってきます。
import pandas as pd
df: pd.DataFrame = pd.read_json(
'https://github.com/simon-ritchie/athena_workshop/blob/main/workshop/user_sales_daily/dt%3D2021-01-01/data.json.gz?raw=true',
lines=True, compression='gzip')
print(df['sales'].mean())
9603.643724696356
中央値を計算する: APPROX_PERCENTILE
平均値は下位の値と上位の値が極端で且つサンプル数が少ないとそちらに引っ張られて直観に反した値になることがあります。そういった時には中央値を出すのが役に立つことがあります。順番に各行の値を並べていった時に中央に位置している値となります。
特定のカラムの中央値を取りたい場合にはAPPROX_PERCENTILEを使います。パーセンタイルを取るためのものとなりますが、50%を指定すれば中央値の取得として使えます。
APPROX_PERCENTILE(<対象のカラム名>, <パーセンタイル>)と2つの値(引数)が必要になります。2つ目の引数のパーセンタイルの値には0.0~1.0を指定します。0.5が50%のパーセンタイルに該当するため、中央値の算出として今回は0.5を指定します。
SELECT APPROX_PERCENTILE(sales, 0.5) AS sales_median
FROM athena_workshop.user_sales_daily
WHERE dt = '2021-01-01'

Pythonでの書き方
Pythonでは中央値(英語でmedian)はmedianメソッドがあるのでそちらを呼ぶだけです。df['対象のカラム名'].median()といった書き方でスカラー値が取れます。
import pandas as pd
df: pd.DataFrame = pd.read_json(
'https://github.com/simon-ritchie/athena_workshop/blob/main/workshop/user_sales_daily/dt%3D2021-01-01/data.json.gz?raw=true',
lines=True, compression='gzip')
print(df['sales'].median())
3000.0
パーセンタイルを計算する: APPROX_PERCENTILE
先ほどの中央値と同様にAPPROX_PERCENTILEを使うことで特定のパーセンタイルを計算することができます。値を順番に並べていったときに「上位n%の値はどんな値なのか」といったことを計算することができます。第二引数のパーセンタイルの値は0.0に近くなるほど低い値とあり、1.0に近づくほどトップに近くなっていきます。
例えば0.9を指定すれば「上位10%の値」といった計算ができます。例えば「上位10%のユーザーはどのくらいのランクなのか(いくつ以上のランクなのか)」「上位10%はどのくらいの戦闘力なのか」「どのくらいの売り上げなのか」といったことを求めることができます。
他にも25%ずつ区切った四分位範囲(Interquartile range / IQR)というもので扱われて外れ値の計算などにも使われたりもします。
使い方は中央値の節で触れた通りです。今回は上位10%の計算ということで
SELECT APPROX_PERCENTILE(sales, 0.9) AS sales_percentile
FROM athena_workshop.user_sales_daily
WHERE dt = '2021-01-01'
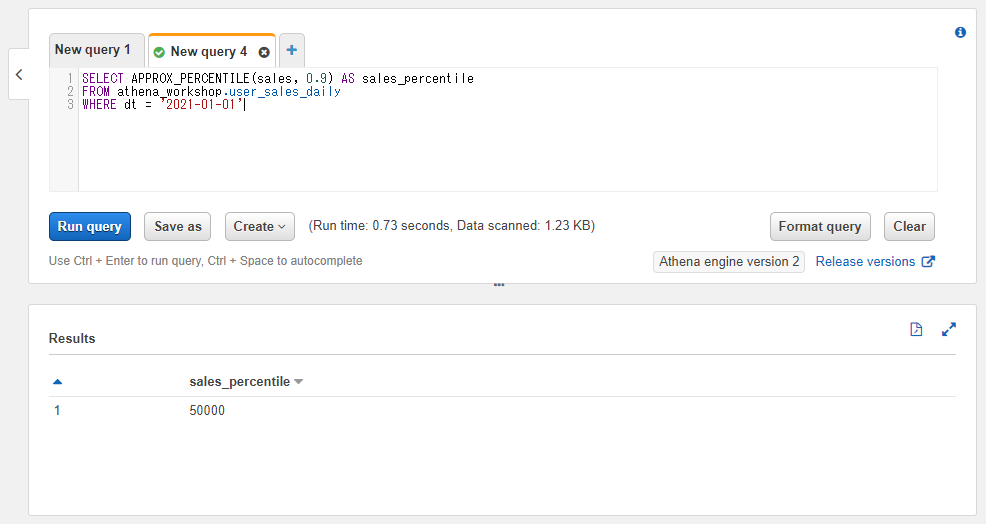
Pythonでの書き方
quantileメソッドでパーセンタイルが取れます。df['<対象のカラム名>'].quantile(<パーセンタイルの値>)と書きます。
import pandas as pd
df: pd.DataFrame = pd.read_json(
'https://github.com/simon-ritchie/athena_workshop/blob/main/workshop/user_sales_daily/dt%3D2021-01-01/data.json.gz?raw=true',
lines=True, compression='gzip')
print(df['sales'].quantile(0.9))
50000.0
合計値を計算する: SUM
特定の列の合計値を出したい時にはSUMを使います。基本的なKPIなどであれば別途集計してテーブルに保存とすることも多いですが、それらのKPIに含まれない特定条件に絞った合計値を出したりとアドホックな分析などでよく使います。
SUM(<対象のカラム名>)といったように書きます。
SELECT SUM(sales) AS sales_sum
FROM athena_workshop.user_sales_daily
WHERE dt = '2021-01-01'
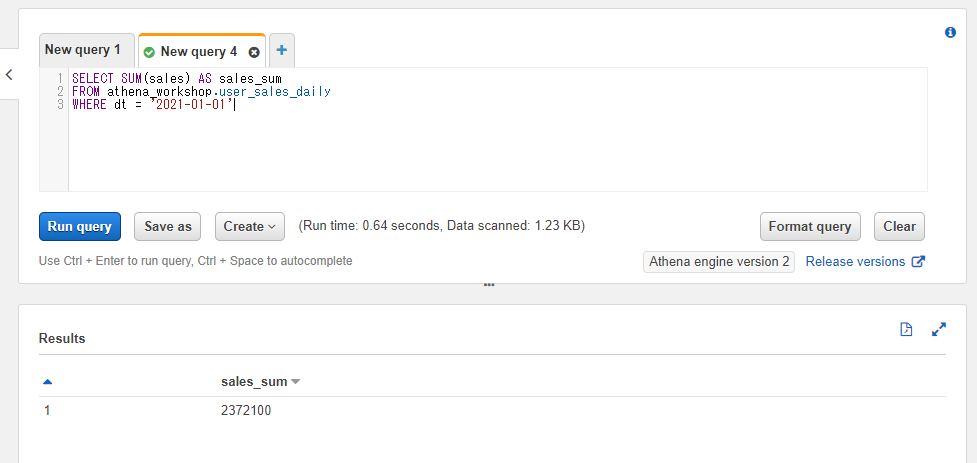
Pythonでの書き方
sumメソッドがあるのでそちらを使ってdf['対象のカラム'].sum()と書きます。
import pandas as pd
df: pd.DataFrame = pd.read_json(
'https://github.com/simon-ritchie/athena_workshop/blob/main/workshop/user_sales_daily/dt%3D2021-01-01/data.json.gz?raw=true',
lines=True, compression='gzip')
print(df['sales'].sum())
2372100
最小値を計算する: MIN
特定のカラムの一番小さい値(最小値)を計算するにはMINを使います。MIN(<対象のカラム>)といったように書きます。
SELECT MIN(sales) AS sales_min
FROM athena_workshop.user_sales_daily
WHERE dt = '2021-01-01'
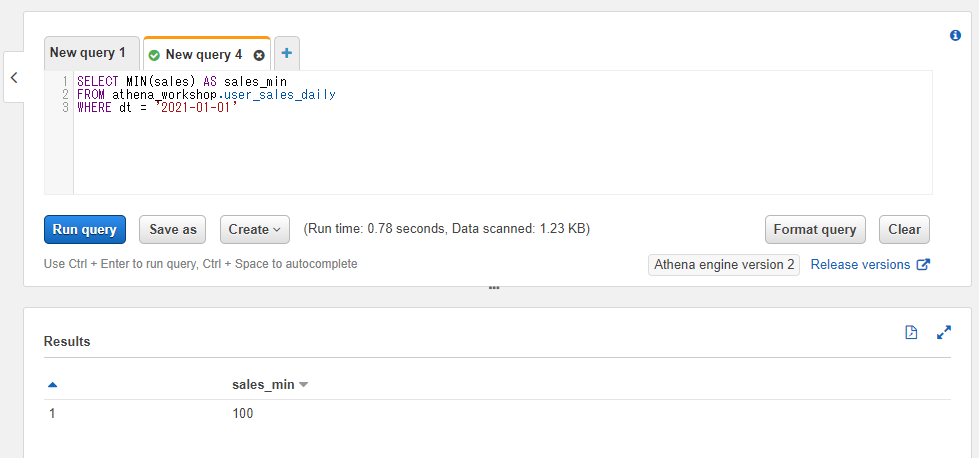
Pythonでの書き方
minメソッドがあるのでdf['<対象のカラム名>'].min()といったように書きます。
import pandas as pd
df: pd.DataFrame = pd.read_json(
'https://github.com/simon-ritchie/athena_workshop/blob/main/workshop/user_sales_daily/dt%3D2021-01-01/data.json.gz?raw=true',
lines=True, compression='gzip')
print(df['sales'].min())
100
最大値を計算する: MAX
最小値とは逆に、特定のカラムの一番大きな値を計算するにはMAXを使います。MAX(<特定のカラム>)といったように書きます。
SELECT MAX(sales) AS sales_max
FROM athena_workshop.user_sales_daily
WHERE dt = '2021-01-01'

Pythonでの書き方
maxメソッドがあるのでそちらを使います。df['<対象のカラム名>'].max()といったように書きます。
import pandas as pd
df: pd.DataFrame = pd.read_json(
'https://github.com/simon-ritchie/athena_workshop/blob/main/workshop/user_sales_daily/dt%3D2021-01-01/data.json.gz?raw=true',
lines=True, compression='gzip')
print(df['sales'].max())
50000
相関係数を出す: CORR
2つのカラム間の相関係数(correlation coefficient)を出すにはCORRを使います。片方のカラムの値が上がった時にもう片方のカラムの値も上がる傾向があるのか?もしくは下がる傾向があるのか?もしくは影響がほぼ無さそうなのか?といったことの調査に使えます。
相関係数は-1から1までの範囲の値を取ります。計算の数式とかは本記事では省きます。必要な方は相関係数 - Wikipediaなどの記事をご確認ください。
基本的に-1に近づくほど負の相関が強くなり(一方のカラムの値が上がった場合もう片方のカラムの値は下がる傾向が強くなる等)、1に近づくほど正の相関が強くなります(一方のカラムの値が上がった場合にはもう片方のカラムの値も上がる傾向が強くなる等)。相関係数の定義は本によって様々ですが、-0.7以下であれば非常に強い負の相関があり0.7以上であれば非常に強い正の相関があるといったように各書籍で紹介されたりします。
AthenaではCORR(<1つ目のカラム名>, <2つ目のカラム名>)といったように書きます。
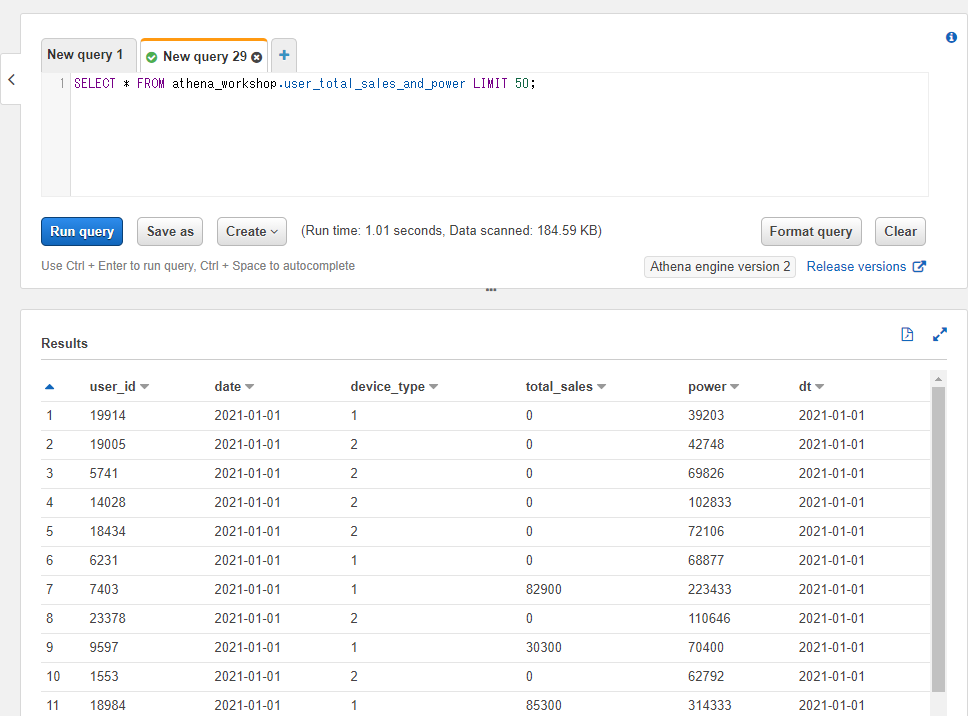
この節以降では説明のためにユーザーごとの総売り上げと戦闘力(ステータス)のカラムを持つuser_total_sales_and_powerというテーブルを扱っていきます。戦闘力は装備品ややりこみ(レベルやパッシブスキルなようなもの)に依存するとイメージしてください。
また、必ずしも売り上げが高いほど戦闘力が高いとは限らないものの、固定額の装備を買ったりソーシャルゲームなどでのガチャなどで基本的には売り上げが高いユーザー程戦闘力が高く出やすい形のゲームの環境を想定しています。
user_total_sales_and_powerテーブルには以下のようなカラムも持ちます。
- user_id: 対象のユーザーIDの整数。
- date: 対象日の日付の文字列。今回のサンプルでは2021-01-01の日付のデータのみ用意してあります。
- device_type: 対象の端末種別の整数値(1=iOS, 2=Android想定)。
- total_sales: 各ユーザーの総売り上げの整数。課金などをせずに遊んでいるユーザーの方想定で0の行も多く入ります。
- power: ユーザーの戦闘力の整数。
SQLで確認してみると以下のような各カラムの値になっていることが確認できます。
SELECT * FROM athena_workshop.user_total_sales_and_power LIMIT 50;
前述のuser_total_sales_and_powerテーブルの総売り上げのカラム(total_sales)と戦闘力のカラム(power)で相関係数を出してみます。以下のようなSQLになります。
SELECT CORR(total_sales, power) AS correlation_coefficient
FROM athena_workshop.user_total_sales_and_power
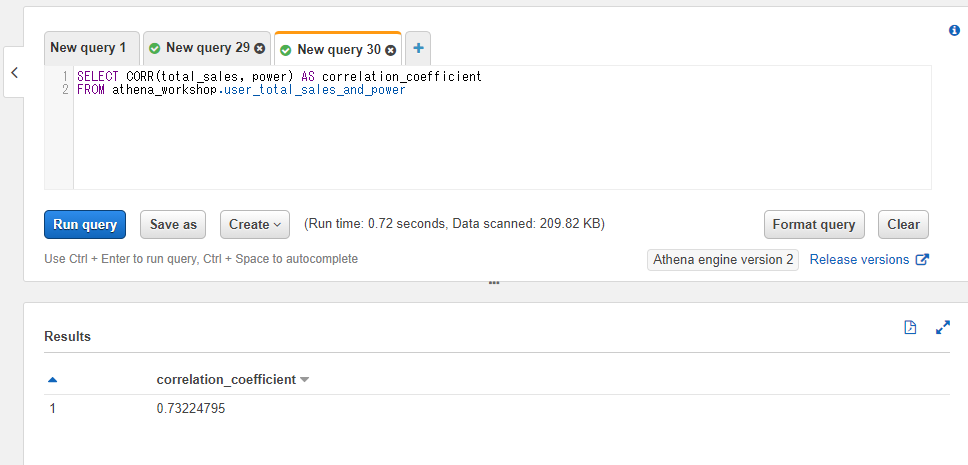
約0.732、つまり非常に強い正の相関があることが分かりました。
Pythonでの書き方
Pandasでは複数のカラムでまとめて相関が計算されます。結果もヒートマップ表示がしやすいように行列(データフレーム)の形で返却されます。
計算にはcorrメソッドを使いますが、余分なカラムが残っていると好ましく無いので今回はdf[['<1つ目のカラム名>', '<2つ目のカラム名>']]といった形で必要なカラムのみ絞っています。
import pandas as pd
df: pd.DataFrame = pd.read_json(
'https://github.com/simon-ritchie/athena_workshop/blob/main/workshop/user_total_sales_and_power/dt%3D2021-01-01/data.json.gz?raw=true',
lines=True, compression='gzip')
print(df[['total_sales', 'power']].corr())
total_sales power
total_sales 1.000000 0.732248
power 0.732248 1.000000
各値の型
この節からはAthenaの基本的な型について色々説明していきます。Athenaには様々な型がありますが、良く使われると思われるものを中心に触れていきます。
なぜ型を意識する必要があるのか
型によってSQL上でできることや性質などが変わってきます。例えは後々の節で触れるテーブルの連結などではカラム間は型が統一されていないといけないですし、数値計算などを行おうとしていたら整数の型のカラムかと思ったら文字列のカラムだった・・・といったことが発生しうる形となります。
既存のテーブルの型の確認
既に作られているテーブルの型を確認するにはAWSのwebコンソール上であれば左のサイドメニューにあるテーブル一覧で右の方にある縦の三点リーダーをクリックした時に表示される「Generate Create Table DDL」をクリックするとそのテーブル構造を確認することができます。
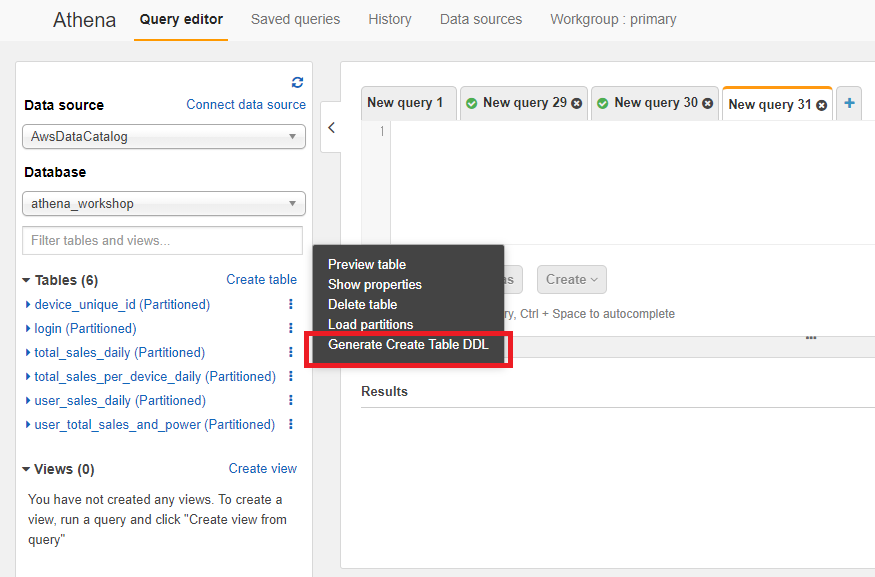
そうするとテーブルを生成する時のSQLを表示するためのSQLが実行され、テーブルの各カラムの型などを確認することができます。
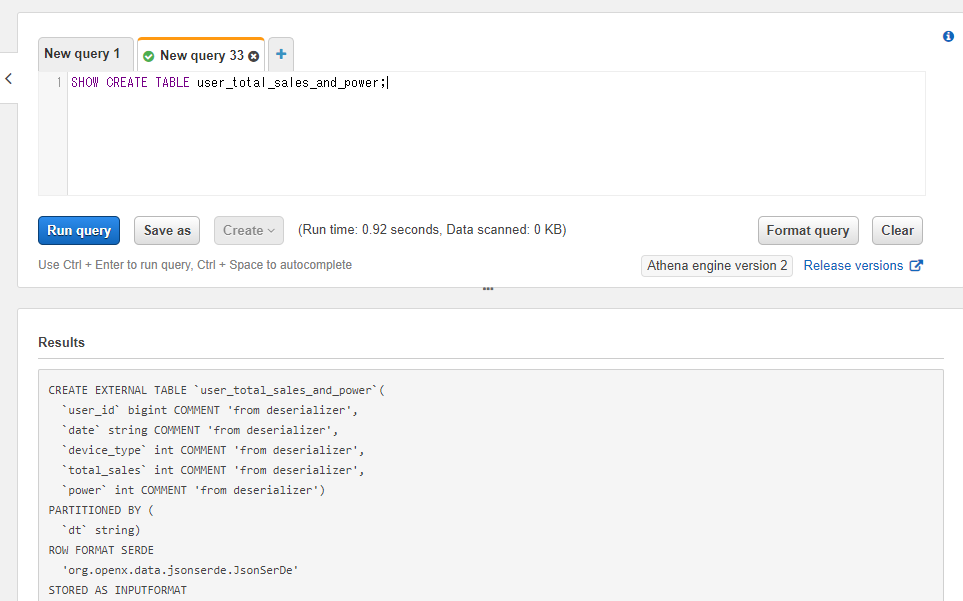
user_id bigint や date string などとなっている部分がカラムと型を示しています。``の引用符で囲まれている箇所がカラム名、その後に続くbigint(整数)やstring(文字列)などが型を示しています。bigintなどの詳細は後の節で詳しく触れます。
特定のカラム単体の型の確認
特定のカラム単体の型を確認したい場合にはTYPEOFを使うこともできます。こちらは前節で触れたようにテーブル全体の型を確認するときと異なりテーブルにスキャンが走るのでコストがかかります。そのため以下のSQLではLIMIT句を指定しています。
スキャンコストはかかるものの、テーブル全体の型を確認した時とは異なり行列ごとに値として返ってくるのが特徴的です。
SELECT TYPEOF(user_id) AS user_id_type
FROM athena_workshop.login
LIMIT 10
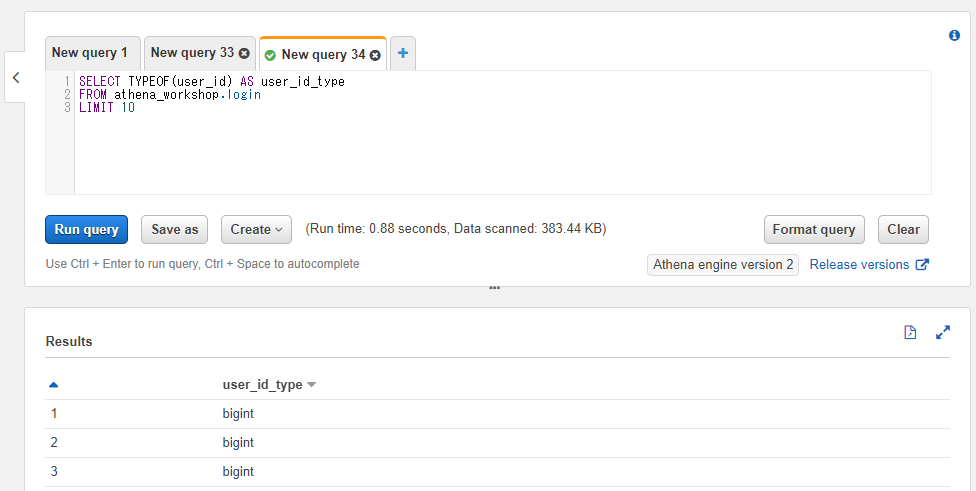
整数の型
以降の節では整数(英語でinteger)の型について触れていきます。英語で省略されてintなどと記載されたりしますが基本的にintegerの整数のことを指しています。
整数には複数の型があり、TINYINT、SMALLINT、INT、BIGINTといったような名前が付いています。TINY(とても小さい)、SMALL(小さい)、BIG(大きい)という名前から分かるように、左から段々と扱える整数のサイズが大きくなってきます。
PythonのNumPyで言うとINTがnp.int32に該当し、BIGINTがnp.int64に該当します。
「確実にこの数字範囲に収まる」という型じゃないと、テーブルのごく一部の行でも上限を超えると正常な集計ができないなどの弊害がでてきます。そのため基本的にはBIGINTをベースとした選択をしていくといいのではという所感です(NumPyやPandasなどもデフォルトがBIGINT相当で扱われることも加味し)。
小さいサイズの整数の型を選択した場合、ログのフォーマット次第ではファイルサイズが小さくなる・・・とかのメリットは少しあるかもしれません。ただしPythonと違ってメモリ云々はAthena上ではあまり意識することが少ない(影響を受けることが少ない)ので、基本的には本当にシビアなところを除けばBIGINTでいいのでは・・・という感じはしています(ディープラーニングのように画像で確実に8bitに収まるといったようなデータの例外を除いて)。
また、ログが年単位の時系列で推移するためテーブル作成時は問題なくともゲーム側のアップデートなどでログの傾向が代わり上限をいつの間にか超えてしまう・・・といったことも起こりえます。
本記事ではよく使うと思われるBIGINTとINTについて触れ、TINYINTなどは割愛します。
BIGINT
まずはBIGINTという型からです。bigという名前の通り「大きな数字も扱える整数の型」となります。
64-bitの数値まで扱える型・・・となります。64-bitと言われてもあまりピンと来ませんが、約9200京くらいまでの数字範囲となります。普段の利用時にはこの型にしておけば扱う数値範囲を超えてしまってトラブルになる・・・といったことはほぼ起こりえないレベルです。
INT
続いて無印のINTという型です。32-bitの数値まで扱えます。扱える数値の上限が21億強くらいです。大体はこの範囲に収まる数値のケースが多いのですが、たまに上限を超える箇所が発生したりして躓いたりすることが発生しうるレベルになります。
上限を超えた時にどうなるのか
試しにint_overflowというテーブル名で、INTの型のカラム(上限21億強)に対して22億程度の整数値を保存した状態でテーブルを作ってみます。
MySQLなどだとそういった場合には警告などが出た状態で格納できる最大値の21強くらいに変換された状態で保存されたりします。PythonやPythonのライブラリ・もしくは他のプログラミング言語などでは最大値に変換されるかもしくは溢れた分が0から計算される(22億であれば1億弱程度の数値に変換される)など挙動は様々です。
Athenaではデータの置き場所がS3・テーブルの作成はAthena上と分かれています。そのため保存されているデータとテーブルの型が一致していなくてもテーブルの作成が効きますしテーブル作成の前にデータを保存することもできます(この辺りはMySQLなどと結構異なります)。
実際にint_overflowテーブルに対してSQLを投げてみます。
SELECT * FROM athena_workshop.int_overflow limit 10;
なにやらエラーとなりました。22億の入力値が良くないデータ(HIVE_BAD_DATA)と判定されています。
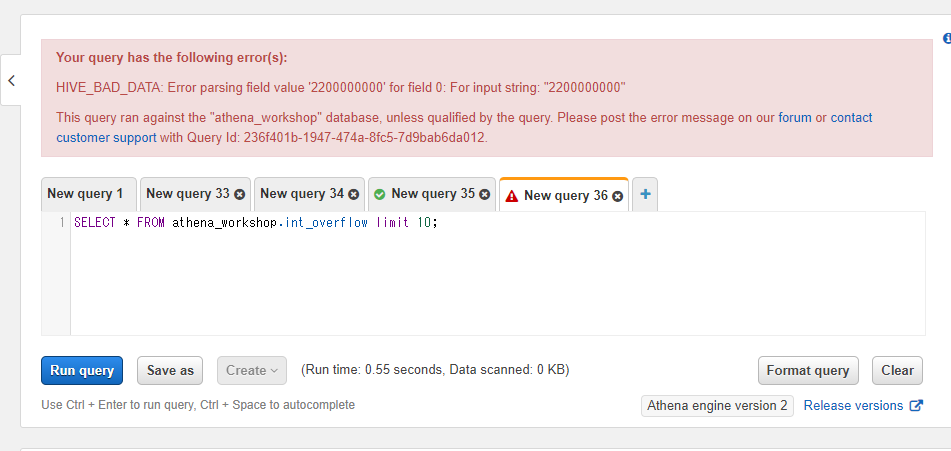
このようにカラムの型の上限を超えた値が保存されてしまうと該当のテーブルにSQLがエラーで投げれなくなってしまいます(一応、他の関係無いカラムのみをSQLで指定すればそちらは通りはします)。
この場合ある日突然集計でエラーが発生しだして障害となりかねません。プロジェクトが年単位でログを扱っているとアップデートでログの傾向が変わる・・・とかも結構発生しますし、その度にエラーで対応を求められる・・・とかは辛いので、特に理由がなければ前述の通りBIGINTが個人的には楽だなとは思います(GlueクローラーとかでBIGINTが選択されないとかはあるかもしれませんが・・・)。
浮動小数点数の型
継続率やらARPPUやら除算の入る箇所などでは浮動小数点数(50.15342といったような値)が必要になってきます。除算をAthenaで扱うには基本的にDOUBLEもしくはFLOATの型を使います。
DOUBLE
DOUBLEの型は64-bit(Python・NumPyで言うところのnp.float64)となり、大きな桁数を扱えます(浮動小数点数を扱う時に誤差の少ない型となります)。
DOUBLEの名前の由来は32-bitの浮動小数点数の型を単精度浮動小数点数(single precision floating point number)と呼び、64-bitの方を倍精度浮動小数点数(double precision floating point number)と呼ばれることに由来します。
浮動小数点算術に関する標準であるIEEE 754では、単精度は32ビット(4オクテット)、倍精度は64ビット(8オクテット)である。いずれにしろ、「倍」というのは、精度に関係する仮数部(後述)の長さが正確に2倍である、といったような意味ではなく、全体の長さが2倍である所から来ているので、実際の所「倍精度」というのはかなり大雑把な言い方に過ぎない。
倍精度浮動小数点数 - Wikipedia
FLOAT
FLOATの型は32-bit(NumPyで言うところのnp.float32)となります。整数の型でのBIGINTとINTの型の違いのように、こちらはDOUBLEと比べて扱える数値の範囲(桁)が小さくなります。
DOUBLEとFLOATどちらを使うべきか?という問題については、特にFLOATを使う理由が無いのであれば迷ったらBIGINTの方が無難なのと同様にこちらもDOUBLEで良いかなという印象です(分析などする上ではビット数が大きい弊害よりも小さい弊害の方が悪影響が出やすいかなと)。
文字列の型
文字列に関してはAthenaでは主にCHARとVARCHAR、STRINGの3つがあります。世の中の記事を見ていたり仕事で扱った感じではSTRINGを使うことが一番多くなりそうではあります。というよりもAthenaのAWS webコンソール上のUIでの新規テーブル作成画面ではそもそも文字列の型の選択がSTRING(string)のみになっています。テーブルでは基本的にSTRINGを使いましょうといった感じでしょうか?
細かいところだとCHAR型が固定の長さを設定するカラム(日付の文字列など文字の桁数が変わらないものに向いています)、VARCHARが桁数が変動可能なカラムとなります。後々の節で触れる文字列操作時に多少CHARなども出てくる・・・形となりますが、基本的にはテーブルの文字列のカラムはSTRINGで扱えば良さそうです。
真偽値の型
真偽値の型はBOOLEANです。true(真)もしくはfalse(偽)の2値のどちらかのみを取ります。整数の0か1かなどでも似たような扱いはできます。
日付と日時の型
Athenaで日付もしくは日時を扱う場合には文字列(STRING)もしくは日付のDATEや日時のTIMESTAMPを使います。
日付のカラムに文字列?という感じではありますが、DATE型などをテーブルに利用した場合にはAthena(presto)ではWHERE句でキャスト(型変換)が必要になるケースが出てきます。
例えばMySQLなどの感覚でDATEのカラムに対してWHERE date = '2021-01-01'みたいなWHERE句の書き方をするとエラーになります。WHERE date = CAST('2021-01-01' AS TIMESTAMP)的なキャストが必要になります。
これは結構煩雑だったりしますし、文字列の型にしても大なり小なりなどの比較などのSQLはキャスト無しに実行できます。文字列の型の方がMySQLなどの感覚でSQLが書ける印象で、実際世の中の記事ではパーティション含め日付などの値に対して文字列の型がAthenaでは使われているのを見かけます。
一方で日付(日時)操作などが必要な場合には文字列のSTRINGの型ではなくDATEやTIMESTAMPなどの型が必要になってきます。この辺りは後々の記事で詳しく触れていきます。
配列の型
Athenaで配列を使う場合にはARRAY型を使います。1つのカラムに任意の型の複数の値を順番に格納することができます。例えば整数の配列であれば[10, 20, 30]みたいな値をもったカラムとなります。
配列には数値や文字列などを単純に格納する以外にも配列自体も入れ子(配列の中に配列を入れる)にできますし、後述する節で触れる辞書を格納することもできます。辞書を格納した配列というのは結構使う機会があり、例えばクエストのログでユーザーの装備のデータを格納したり・・・などに使います。例えば以下のように「なんの装備のマスタなのか?」というIDや装備のステータスを格納したりといった具合になります。
[{
"equipment_id": 10,
"type": 5,
"attack": 1000,
"defense": 500,
}, {
"equipment_id": 15,
"type": 6,
"attack": 300,
"defense": 1200,
}]
辞書の型
Athenaの辞書(キーと値のペア)をカラムに使うにはSTRUCTもしくはMAPを使います。STRUCTとMAPどう違うんだ?という感じですが、以下のような差異が存在します。
- STRUCTでは格納する値の型には複数の型を利用することができます(Aのキーは数値、Bのキーは文字列といった具合に)。
- STRUCTでは事前に各キー名を定義しておく必要があります。
- MAPでは値などに1つの型しか選択できません。例えば整数を選択したら整数の値しか格納できません。
- MAPは事前にキー名を定義しておく必要がありません。
よって、どちらを使うかについては以下のような選択が取れます。
- 複数の型を値に使う必要がある -> STRUCT
- 事前にキーの内容が決まっていて、ほとんどキーの内容が変動しない -> STRUCT
- 値の型は1つなものの、キーの内容が頻繁に変動する -> MAP
配列や辞書の操作に関しては後々の記事で詳しく触れます。
値の型をキャストする(データの型を変換する)
SQLを書いていて、カラムの型を変換して扱う必要のあるケースが結構出てきます。例えば以下のようなケースです。
- ログの日時が文字列(STRING)で保存されているけれども、日時操作を行いたいので日時の型(TIMESTAMP)に変換する。
- Aテーブルでは特定のカラムの値が整数で格納されているものの、Bテーブルでは文字列で格納されている。AテーブルとBテーブルを連結したいので両方同じ型に変換する。
といった具合です。
そういった場合にはCAST(<カラム名> AS <型名>)といった形で変換が行えます(この変換のことをキャストと呼びます)。
例えば日時の文字列を格納するカラムをSTRINGの現在の型からTIMESTAMPに変換したい場合には以下のように書きます。
SELECT user_id, CAST(time AS TIMESTAMP) AS timestamp
FROM athena_workshop.login
WHERE dt = '2021-01-01'

Pythonでの書き方
Pandasではデータフレームなどでのastypeメソッドで型変換が効きます。第一引数に型を指定します。以下の例では文字列(str)に変換させています。
import pandas as pd
df: pd.DataFrame = pd.read_json(
'https://github.com/simon-ritchie/athena_workshop/blob/main/workshop/login/dt%3D2021-01-01/data.json.gz?raw=true',
lines=True, compression='gzip')
df['user_id'] = df['user_id'].astype(str, copy=False)
print(type(df.at[0, 'user_id']))
<class 'str'>
copy引数にFalseを指定するとキャスト時にコピーを取らずにメモリが節約されたりします。デフォルトではTrueのためコピーが取られます(行数が多いとメモリを多く必要とします)。
数値や文字列などであればこのようにastypeでいけますが、文字列から日時などに変換する場合にはpd.to_datetime関数を使う必要があります。引数には対象の日時のシリーズなどを指定します。内部の値の型はdatetimeとほぼ同じようなインターフェイスを持つPandasのTimestampとなります。
from datetime import datetime
import pandas as pd
df: pd.DataFrame = pd.read_json(
'https://github.com/simon-ritchie/athena_workshop/blob/main/workshop/login/dt%3D2021-01-01/data.json.gz?raw=true',
lines=True, compression='gzip')
df['time'] = pd.to_datetime(df['time'])
print(type(df.at[0, 'time']))
<class 'pandas._libs.tslibs.timestamps.Timestamp'>
複数のテーブルの列を連結する
この節以降では複数のテーブルの列の連結について触れていきます。
説明のためにjoin_sample_left_tableというテーブルとjoin_sample_right_tableという2つのサンプルのテーブルを使っていきます。連結する際の各テーブルで1つ目のテーブルを左側のテーブル、2つ目のテーブルを右側のテーブルなどと扱ったりします。テーブル名のleftやrightなどもそれに準じています。
join_sample_left_tableテーブルには以下のように、パーティション関係を除くとidとnameという2つのカラムのみを持ちます。行数も2行のみです。武器関係のデータを持つテーブルとお考えください。
SELECT * FROM athena_workshop.join_sample_left_table
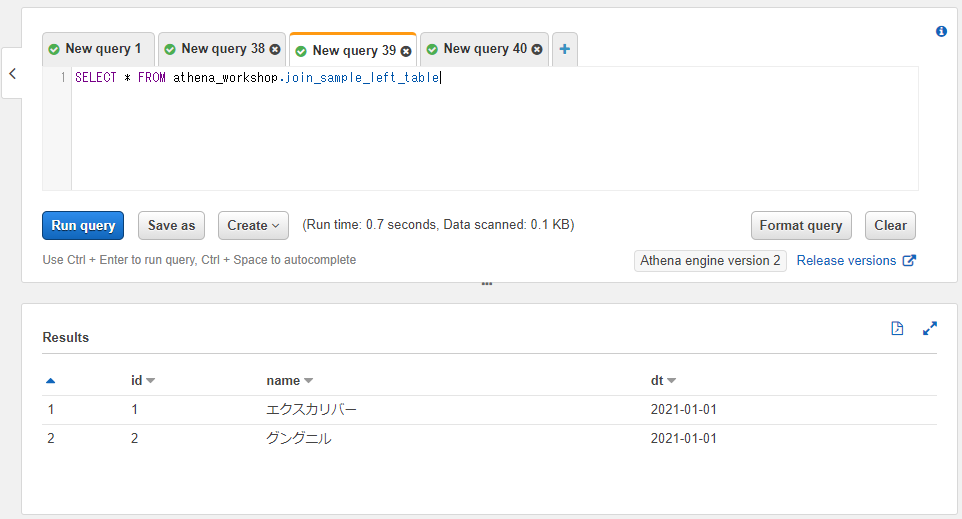
join_sample_right_tableテーブルにはパーティションを除くとidとattackという2つのカラムを持ちます。こちらも行数は2行のみです。武器のステータスを持つテーブルとお考えください。また、join_sample_left_tableテーブルとidの値は共通とします。
左側のテーブル(join_sample_left_table)にはidは1と2、右側のテーブル(join_sample_left_table)にはidは2と3が格納されており、それぞれのテーブルでidの値が一致していない形にしてあります。
列結合のSQLの基本的な書き方
SQLで複数のテーブルの列の連結をする場合には以下のように書きます。
SELECT <カラム名の指定>
FROM <左側のテーブルの指定>
<結合の種類> <右側のテーブルの指定>
ON <結合に使う左側のテーブルのカラム> = <結合に使う右側のテーブルのカラム>
以降の節で詳しく見ていきます。
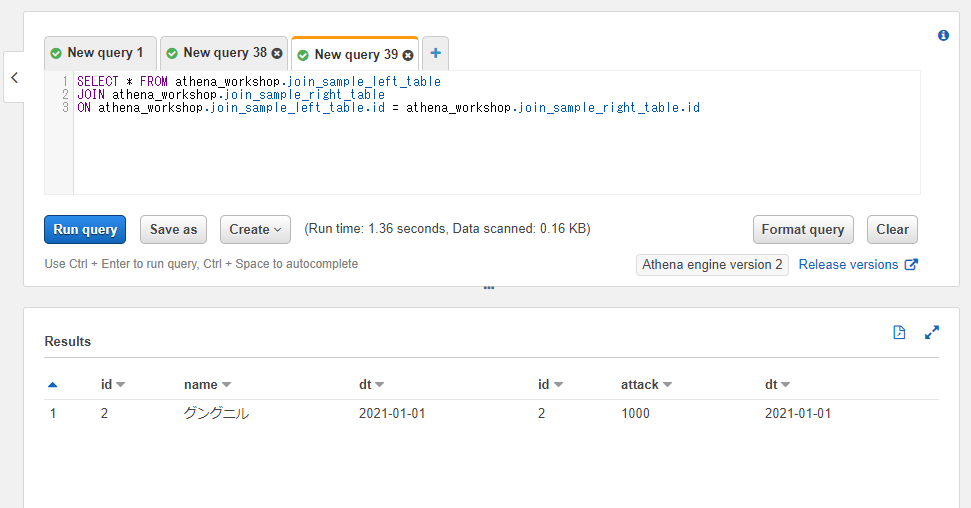
内部結合: JOIN / INNER JOIN
内部結合(INNER JOIN)は連結する2つのテーブルで両方とも値が存在する行を残す連結方法です。
例えばjoin_sample_left_tableテーブルとjoin_sample_right_tableテーブルでidカラムの値を基準に連結するとしましょう。idカラムの値は1, 2, 3の3つがあり、それぞれが以下のようになっています。
- id=1: 左側のテーブルにのみ存在する。
- id=2: 両方のテーブルに存在する。
- id=3: 右側のテーブルにのみ存在する。
内部結合では2つのテーブルで両方とも値が存在する行のみ残す方法なので、今回の例ではid=2の行のみ残る形となります。実際にSQLを書いて試してみましょう。
SELECT * FROM athena_workshop.join_sample_left_table
INNER JOIN athena_workshop.join_sample_right_table
ON athena_workshop.join_sample_left_table.id = athena_workshop.join_sample_right_table.id
FROM athena_workshop.join_sample_left_tableという部分には結合で使う1つ目のテーブルを指定します。
INNER JOINという部分が結合の種類の指定に該当します。今回は内部結合なのでINNER JOINと指定しています。
INNER JOINの後に2つ目のテーブルを指定します。今回はathena_workshop.join_sample_right_tableと指定しています。
ONの後には連結条件を指定します。イコール(=)の左側に連結で使う1つ目のテーブルのカラム、右側に2つ目のテーブルのカラムを指定します。今回は左側も右側もidカラムを使っているためathena_workshop.join_sample_left_table.id = athena_workshop.join_sample_right_table.idという指定になります。
テーブルの内容によっては左側と右側でカラム名が異なるものになるケースも発生します。例えば左側はidカラム、右側はweapon_idといったようなケースもあるかもしれません。その辺りはテーブルの定義に依存します。
SQLを実行してみると以下のように2つのテーブルの列が結合された形で結果の行が表示されます。また、2つのテーブル両方に同じidの値が存在する行のみが残るのでid=2の行のみ表示されていることが確認できます。

一番基本的な列の連結はこのような感じとなります。
なお、INNERというキーワードは省略してJOINとだけ書くこともできます。その場合は内部結合の挙動となります。以下のようにINNERを省いて書いても前述のSQLと同じ結果となります。
SELECT * FROM athena_workshop.join_sample_left_table
JOIN athena_workshop.join_sample_right_table
ON athena_workshop.join_sample_left_table.id = athena_workshop.join_sample_right_table.id
Pythonでの書き方
Pandasではpd.merge関数で列方向の連結ができます。left引数に1つ目のデータフレーム、right引数に2つ目のデータフレーム、onに連結対象のカラム名、howで連結方法を指定します。
今回は内部結合なのでhow='inner'と指定すると目的としていた挙動になります。
import pandas as pd
left_df: pd.DataFrame = pd.read_json(
'https://github.com/simon-ritchie/athena_workshop/blob/main/workshop/join_sample_left_table/dt%3D2021-01-01/data.json.gz?raw=true',
lines=True, compression='gzip')
right_df: pd.DataFrame = pd.read_json(
'https://github.com/simon-ritchie/athena_workshop/blob/main/workshop/join_sample_right_table/dt%3D2021-01-01/data.json.gz?raw=true',
lines=True, compression='gzip')
merged_df: pd.DataFrame = pd.merge(
left=left_df, right=right_df, how='inner', on='id')
print(merged_df)
id name attack
0 2 グングニル 1000
連結したテーブルに対するカラムなどの指定とASの指定
テーブル連結などをしているとテーブル名や列の指定が長くなって煩雑になりがちです(場合によってはデータカタログの指定なども必要になった場合もっと長くなります)。まだシンプルなSQLになっていますが、条件が複雑になってくるとこの傾向が余計に顕著になってきます。
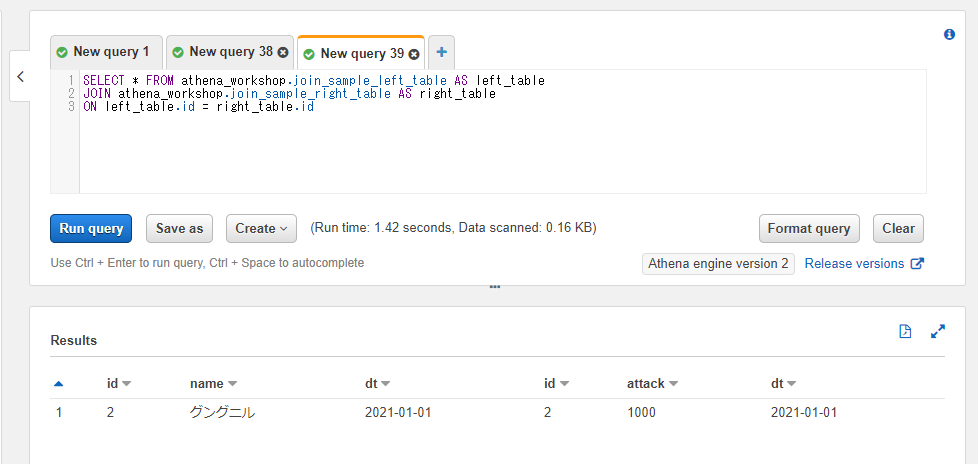
このようなケースでは「テーブル名に別の名前を設定する」や「カラム名に別の名前を設定する」の節で触れたASを使うと短くなってすっきりします。以下のSQLでは左側のテーブルにleft_table、右側のテーブルにright_tableという名前をASを使って付けています。
SELECT * FROM athena_workshop.join_sample_left_table AS left_table
JOIN athena_workshop.join_sample_right_table AS right_table
ON left_table.id = right_table.id
実行結果は変わりません。
また、列も重複している部分などがあったりして結果が煩雑です。今回の例で言えばidのカラムと左側のテーブルのnameカラム、右側のテーブルのattackカラムの3つのみ欲しいとします。
その場合には以下のようにアスタリスクではなく個別にカラムを指定することで調整ができます。両方のテーブルに存在するカラムに関しては<テーブル名>.<カラム名>といったようにカラム名だけではなくテーブル名の指定も必要になります。今回の例でいえばidというカラムは両方のテーブルが同じ名前で持つのでテーブル名の指定が必要になります。idカラムは連結で指定したカラムとなり両方のテーブルとも同じ値なのでどちらのテーブルを指定しても結果は変わりません。今回は左側のテーブルを使ってleft_table.idと指定しました。
SELECT left_table.id, name, attack FROM athena_workshop.join_sample_left_table AS left_table
JOIN athena_workshop.join_sample_right_table AS right_table
ON left_table.id = right_table.id
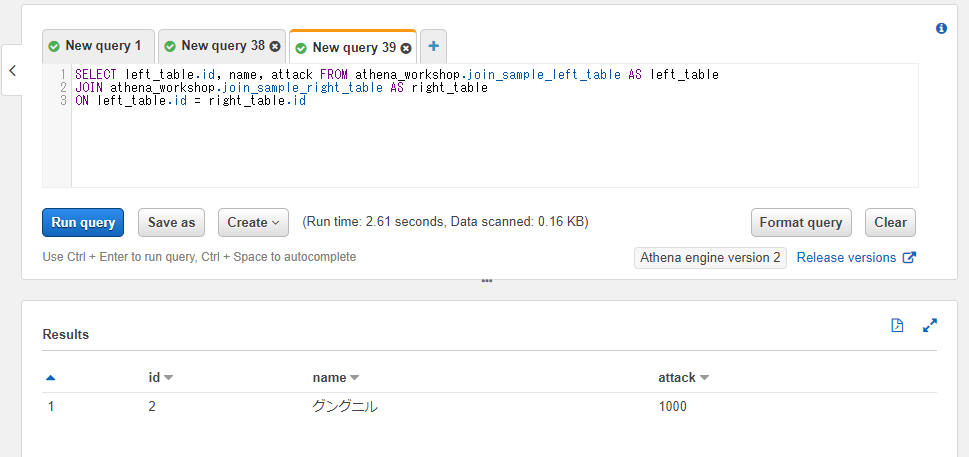
これで重複している列を省いてシンプルな結果にすることができました。
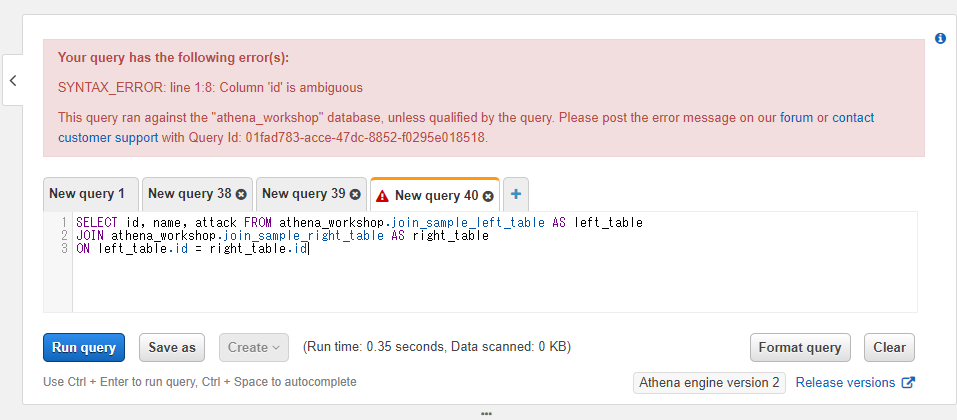
なお、両方のテーブルに存在するカラムに対してテーブル名を指定しないでカラム名を記述すると、SQLからするとどちらのテーブルを参照すれば良いのか分からなくなるためエラーとなります。今回の例で言うとidカラムに対してテーブル名を指定せずに以下のようにSQLを書くと、
SELECT id, name, attack FROM athena_workshop.join_sample_left_table AS left_table
JOIN athena_workshop.join_sample_right_table AS right_table
ON left_table.id = right_table.id
idカラムが曖昧だよ、といったようなエラーメッセージが表示されます。
左外部結合: LEFT JOIN / LEFT OUTER JOIN
続いて左外部結合という結合について触れていきます。左外部結合は左側(1つ目)のテーブル側に値が存在する行が残ります。右側(2つ目)のテーブル側に値が存在しなくても結果に含まれる形になります。つまり以下のような2つの条件のどちらかを満たす行が残されます。
- 左側のテーブルにのみ値が存在する行
- 両方のテーブルに値が存在する行
1の条件が増えた分内部結合よりも基本的に結果の行数が増えます。今回扱うサンプルデータでは、
- id=1: 左側のテーブルにのみ存在する。
- id=2: 両方のテーブルに存在する。
- id=3: 右側のテーブルにのみ存在する。
といったデータになっているため左結合ではid=1とid=2の2行が残ります。
書き方は内部結合で指定していたINNER JOINもしくはJOINの部分をLEFT OUTER JOINとするだけです。他の書き方は変わりません。
SELECT left_table.id, name, attack FROM athena_workshop.join_sample_left_table AS left_table
LEFT OUTER JOIN athena_workshop.join_sample_right_table AS right_table
ON left_table.id = right_table.id
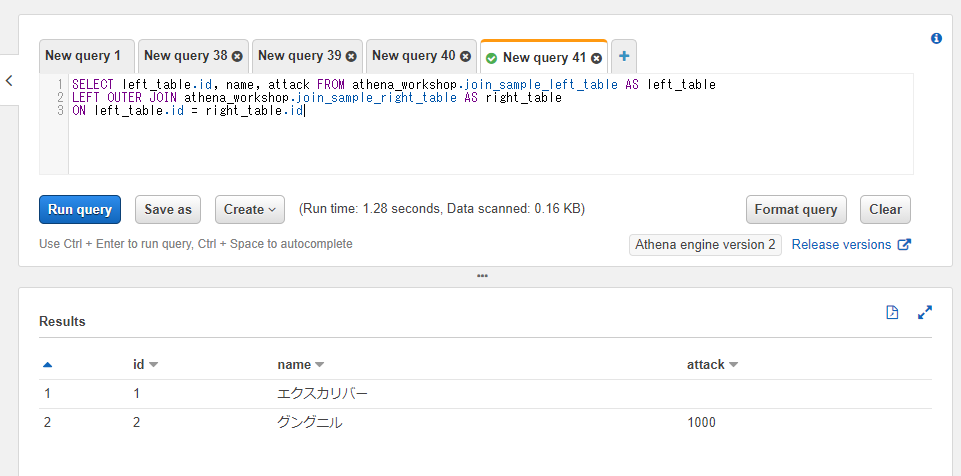
右側のテーブルに行が存在しなくても結果の行に含まれるため、id=1の行に関しては右側のテーブルのデータは欠落します。上記のスクショのid=1の行のattackの列が空欄になって表示されていることが確認できます。
なお、左結合はOUTERを省略してLEFT JOINと書くこともできます。こちらもLEFT OUTER JOINと同じ挙動をします。
SELECT left_table.id, name, attack FROM athena_workshop.join_sample_left_table AS left_table
LEFT JOIN athena_workshop.join_sample_right_table AS right_table
ON left_table.id = right_table.id

Pythonでの書き方
内部結合の時と比べてmerge関数のhow引数の指定がhow='left'と変更すると左外部結合になります。連結時に欠落している値の部分はNaNなどの欠損値になります。
import pandas as pd
left_df: pd.DataFrame = pd.read_json(
'https://github.com/simon-ritchie/athena_workshop/blob/main/workshop/join_sample_left_table/dt%3D2021-01-01/data.json.gz?raw=true',
lines=True, compression='gzip')
right_df: pd.DataFrame = pd.read_json(
'https://github.com/simon-ritchie/athena_workshop/blob/main/workshop/join_sample_right_table/dt%3D2021-01-01/data.json.gz?raw=true',
lines=True, compression='gzip')
merged_df: pd.DataFrame = pd.merge(
left=left_df, right=right_df, how='left', on='id')
print(merged_df)
id name attack
0 1 エクスカリバー NaN
1 2 グングニル 1000.0
右外部結合: RIGHT JOIN / RIGHT OUTER JOIN
右外部結合は左外部結合とは逆の動作をします。つまり右側のテーブルにある値を残す形となります。以下のような2つの条件となります。
- 右側のテーブルにのみ値が存在する行
- 両方のテーブルに値が存在する行
今回のサンプルデータでは
- id=1: 左側のテーブルにのみ存在する。
- id=2: 両方のテーブルに存在する。
- id=3: 右側のテーブルにのみ存在する。
となっているのでid=2とid=3の行が残ります。
使い方としては連結条件の部分をRIGHT OUTER JOINと変更するだけです。なお、左側のテーブルの値は存在しない行が残る形となるため、idのカラムの指定もleft_table.idからright_table.idに調整してあります。
SELECT right_table.id, name, attack FROM athena_workshop.join_sample_left_table AS left_table
RIGHT OUTER JOIN athena_workshop.join_sample_right_table AS right_table
ON left_table.id = right_table.id
id=3の行は左側のテーブルには存在しないので、左側のテーブルのカラムであるnameの値が空になっていることが確認できます。
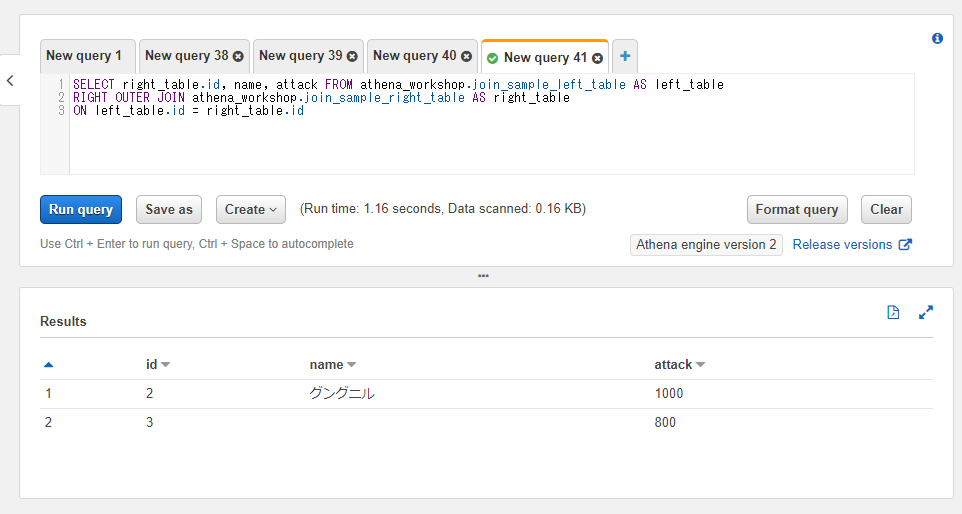
また、右外部結合も左外部結合と同様にOUTERというキーワードは省略してRIGHT JOINだけでも同様の挙動をします。
SELECT right_table.id, name, attack FROM athena_workshop.join_sample_left_table AS left_table
RIGHT JOIN athena_workshop.join_sample_right_table AS right_table
ON left_table.id = right_table.id

Pythonでの書き方
merge関数のhow引数でhow='right'と指定すると右外部結合ができます。
import pandas as pd
left_df: pd.DataFrame = pd.read_json(
'https://github.com/simon-ritchie/athena_workshop/blob/main/workshop/join_sample_left_table/dt%3D2021-01-01/data.json.gz?raw=true',
lines=True, compression='gzip')
right_df: pd.DataFrame = pd.read_json(
'https://github.com/simon-ritchie/athena_workshop/blob/main/workshop/join_sample_right_table/dt%3D2021-01-01/data.json.gz?raw=true',
lines=True, compression='gzip')
merged_df: pd.DataFrame = pd.merge(
left=left_df, right=right_df, how='right', on='id')
print(merged_df)
id name attack
0 2 グングニル 1000
1 3 NaN 800
完全外部結合: FULL JOIN / FULL OUTER JOIN
完全外部結合(省略して外部結合とも呼ばれます)は左側のテーブルのみにある値も右側のテーブルのみある値も両方残ります。つまり以下の3つの条件となります。
- 左側のテーブルにのみ値が存在する行
- 右側のテーブルにのみ値が存在する行
- 両方のテーブルに値が存在する行
実質的に全部の行が残ります。
使い方としては連結のキーワード部分でFULL OUTER JOINと指定します。
以下のSQLではidカラムをleft_idとright_idとして両方残す形に調整してあります。
SELECT left_table.id AS left_id, right_table.id AS right_id, name, attack
FROM athena_workshop.join_sample_left_table AS left_table
FULL OUTER JOIN athena_workshop.join_sample_right_table AS right_table
ON left_table.id = right_table.id
id=1, id=2, id=3の全ての行が残っていることが確認できます。

こちらに関してもOUTER部分を省略してFULL JOINとしても同様に動作します。
SELECT left_table.id AS left_id, right_table.id AS right_id, name, attack
FROM athena_workshop.join_sample_left_table AS left_table
FULL JOIN athena_workshop.join_sample_right_table AS right_table
ON left_table.id = right_table.id
Pythonでの書き方
merge関数のhow引数部分をhow='outer'とすると外部結合の挙動になります。
import pandas as pd
left_df: pd.DataFrame = pd.read_json(
'https://github.com/simon-ritchie/athena_workshop/blob/main/workshop/join_sample_left_table/dt%3D2021-01-01/data.json.gz?raw=true',
lines=True, compression='gzip')
right_df: pd.DataFrame = pd.read_json(
'https://github.com/simon-ritchie/athena_workshop/blob/main/workshop/join_sample_right_table/dt%3D2021-01-01/data.json.gz?raw=true',
lines=True, compression='gzip')
merged_df: pd.DataFrame = pd.merge(
left=left_df, right=right_df, how='outer', on='id')
print(merged_df)
id name attack
0 1 エクスカリバー NaN
1 2 グングニル 1000.0
2 3 NaN 800.0
WHERE句でのASを指定したカラムの指定はエラーとなる
テーブル連結などしているとカラムの指定が長くなりがちです。特に同名のカラムが複数存在する状態だとテーブル名.カラム名とテーブル名も付与しないといけなくなるので長くなってしまいます。
しかしながら、ASの節でも触れましたがWHERE句にASで別の名前を設定したカラム名を使うことはできません。試しに以下のようにAS left_idとカラム名に指定しているものを使ってWHERE left_id = 2という条件を書いてみるとエラーになります。
SELECT left_table.id AS left_id, right_table.id AS right_id, name, attack
FROM athena_workshop.join_sample_left_table AS left_table
FULL JOIN athena_workshop.join_sample_right_table AS right_table
ON left_table.id = right_table.id
WHERE left_id = 2

WHERE句ではこのようにASで設定したカラム名は利用できないため、元々のテーブル名.カラム名といった指定が必要になります。ただしテーブル名の方はASが効く(例 : left_table.idといった書き方ができます)ので、テーブル名は長い場合には短めのものを設定しておくとWHERE句などを書くのが楽になります。
先ほど出たエラーは以下のようにWHERE left_table.id = 2と書き直すと正常に動作します。
SELECT left_table.id AS left_id, right_table.id AS right_id, name, attack
FROM athena_workshop.join_sample_left_table AS left_table
FULL JOIN athena_workshop.join_sample_right_table AS right_table
ON left_table.id = right_table.id
WHERE left_table.id = 2

複数のカラムを使った連結
連結時に複数のカラムが必要になる場合が結構あります。例えばユーザーデータのテーブルに、別の売り上げのテーブルのカラムを連結したいとします。
ユーザーごとの売り上げのデータは日別の集計となっています。この場合ユーザーIDのみでの連結ではうまくいかず、ユーザーIDと日付の2つのカラムを使って連結をする必要があります。そのような場合にはON <左側のテーブルの1つ目のカラム> = <右側のテーブルの1つ目のカラム> AND <左側のテーブルの2つ目のカラム> = <右側のテーブルの2つ目のカラム>といったようにANDで複数カラムを記載していくことで対応ができます。
ここまでの節で使ってきたテーブルで試してみましょう。ユーザーのログインログのテーブルであるloginテーブルとユーザーごとの日次の売り上げのテーブルであるuser_sales_dailyという二つのテーブルを使っていきます。
loginテーブルは以下のようになっています。日付のカラムは持っていないものの、パーティション(dt)で日付の値が参照できます。
SELECT * FROM athena_workshop.login LIMIT 10
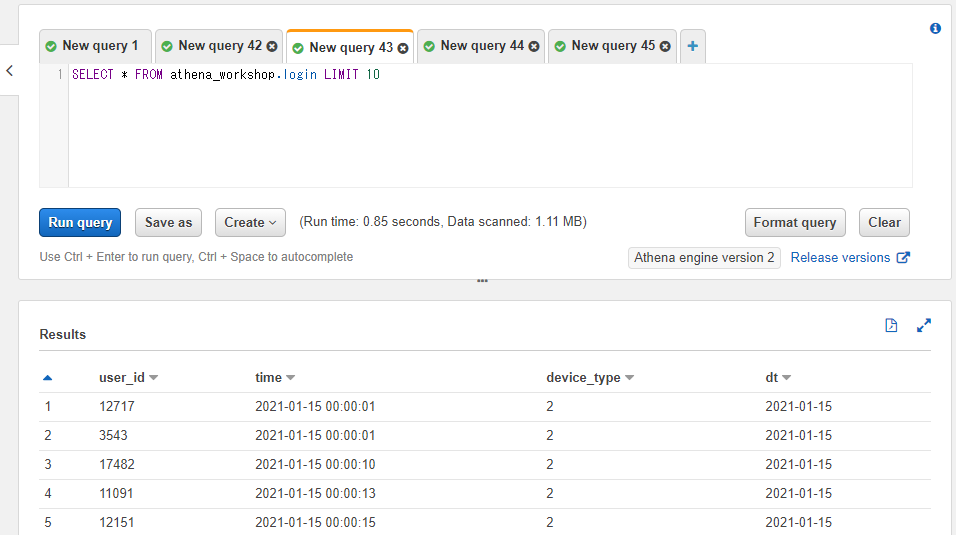
user_sales_dailyテーブル側は以下のようにdateというカラムもしくはパーティション(dt)にて日付の値が参照できます。それぞれのテーブルでuser_idカラムは共通して持っています。
SELECT * FROM athena_workshop.user_sales_daily LIMIT 10;
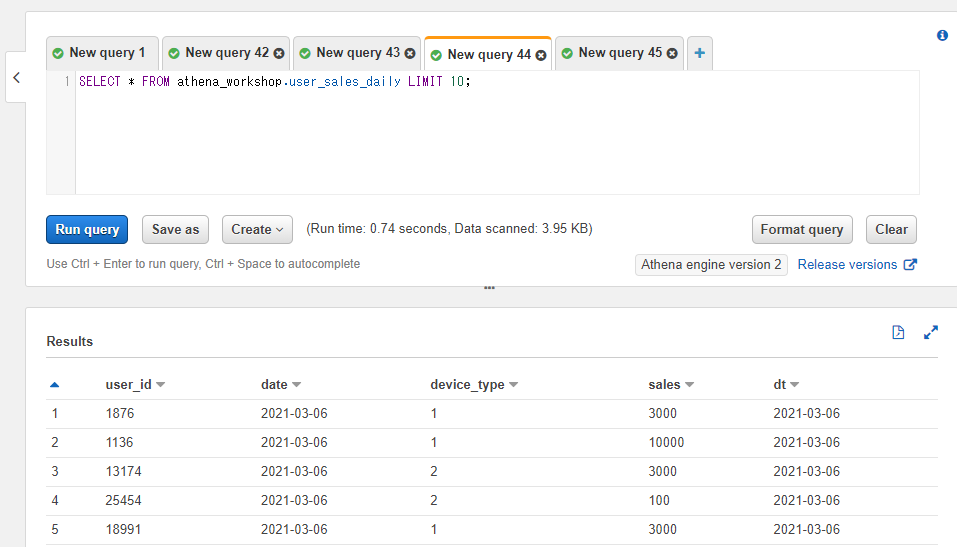
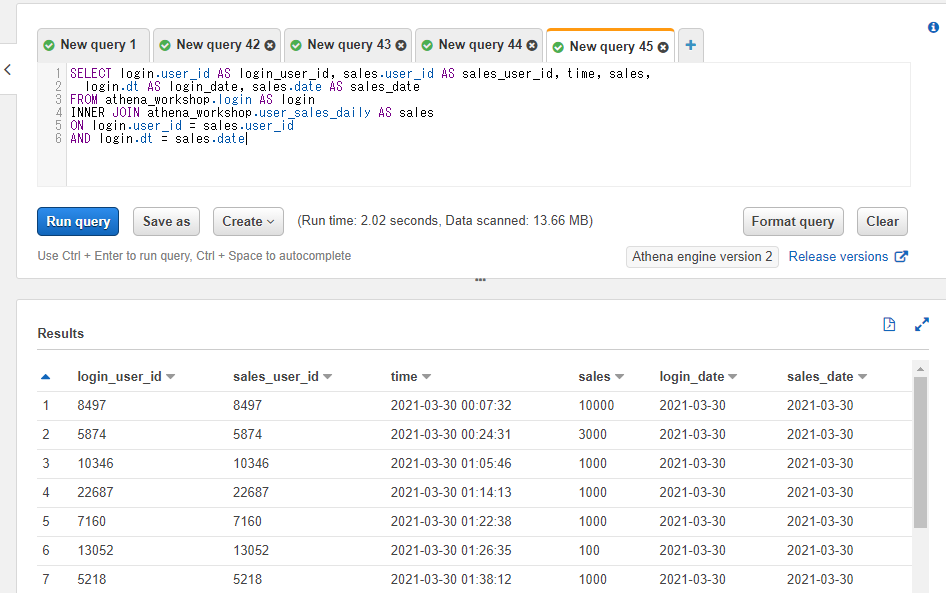
内部結合で連結してみましょう。ユーザーIDの連結ではON login.user_id = sales.user_idという指定、日付の連結ではAND login.dt = sales.dateという指定をしています。
SELECT login.user_id AS login_user_id, sales.user_id AS sales_user_id, time, sales,
login.dt AS login_date, sales.date AS sales_date
FROM athena_workshop.login AS login
INNER JOIN athena_workshop.user_sales_daily AS sales
ON login.user_id = sales.user_id
AND login.dt = sales.date
連結結果で複数のカラムがそれぞれ一致していることを確認するためにわざとユーザーIDと日付のカラムを2つずつ残しています(login_user_idとsales_user_id、login_dateとsales_date)。それぞれの2つのテーブルの値が各行で一致していることが確認できます。
Pythonでの書き方
merge関数のon引数はリストなどが指定できるので、そちらに複数のカラムを指定すると複数のカラムを使った連結ができます。なお、パーティションのカラムはログには含まれていないため今回はサンプルなので直接dateカラムをデータフレームに追加しています(login_df['date'] = '2021-01-01'部分)。
import pandas as pd
login_df: pd.DataFrame = pd.read_json(
'https://github.com/simon-ritchie/athena_workshop/blob/main/workshop/login/dt%3D2021-01-01/data.json.gz?raw=true',
lines=True, compression='gzip')
sales_df: pd.DataFrame = pd.read_json(
'https://github.com/simon-ritchie/athena_workshop/blob/main/workshop/user_sales_daily/dt%3D2021-01-01/data.json.gz?raw=true',
lines=True, compression='gzip')
login_df['date'] = '2021-01-01'
sales_df['date'] = sales_df['date'].astype(str, copy=False)
merged_df: pd.DataFrame = pd.merge(
left=login_df, right=sales_df, how='inner',
on=['user_id', 'date'])
print(merged_df.head())
user_id time device_type_x date sales device_type_y
0 157 2021-01-01 00:06:50 2 2021-01-01 100 2
1 157 2021-01-01 07:20:34 2 2021-01-01 100 2
2 9675 2021-01-01 00:17:20 1 2021-01-01 100 2
3 8262 2021-01-01 00:26:50 2 2021-01-01 50000 1
4 8262 2021-01-01 12:56:12 2 2021-01-01 50000 1
SQL側でdtとdateのように連結対象のカラム名が異なる場合には、on引数の代わりにleft_on引数とright_on引数にそれぞれのカラム名を指定すると対応ができます。
import pandas as pd
login_df: pd.DataFrame = pd.read_json(
'https://github.com/simon-ritchie/athena_workshop/blob/main/workshop/login/dt%3D2021-01-01/data.json.gz?raw=true',
lines=True, compression='gzip')
sales_df: pd.DataFrame = pd.read_json(
'https://github.com/simon-ritchie/athena_workshop/blob/main/workshop/user_sales_daily/dt%3D2021-01-01/data.json.gz?raw=true',
lines=True, compression='gzip')
login_df['dt'] = '2021-01-01'
sales_df['date'] = sales_df['date'].astype(str, copy=False)
merged_df: pd.DataFrame = pd.merge(
left=login_df, right=sales_df, how='inner',
left_on=['user_id', 'dt'],
right_on=['user_id', 'date'])
print(merged_df.head())
ONの代わりにUSINGを使って連結を行う
ONの代わりにUSINGを使って列を連結することもできます。連結するテーブルの指定の後にUSING(<対象のカラム名>)といったように記述します。連結するテーブル名の指定にASを使っている場合にはASの後に記述します。
ONを使う時と比べて以下のような特徴があります。
- 連結の記述が短くなりシンプルになります。
- 連結するカラムは左右のテーブルで同じ名前である必要があります。
- カラム名の指定にアスタリスクを使用した場合にはONの場合には左右の両方の連結に使ったカラムが残りますがUSINGの場合は1つのみ残ります。
つまり連結するカラム名が同一の場合はUSINGを使うと記述がシンプルになります。一方で左側と右側で連結に指定するカラム名が異なる場合にはONを使う必要があります。
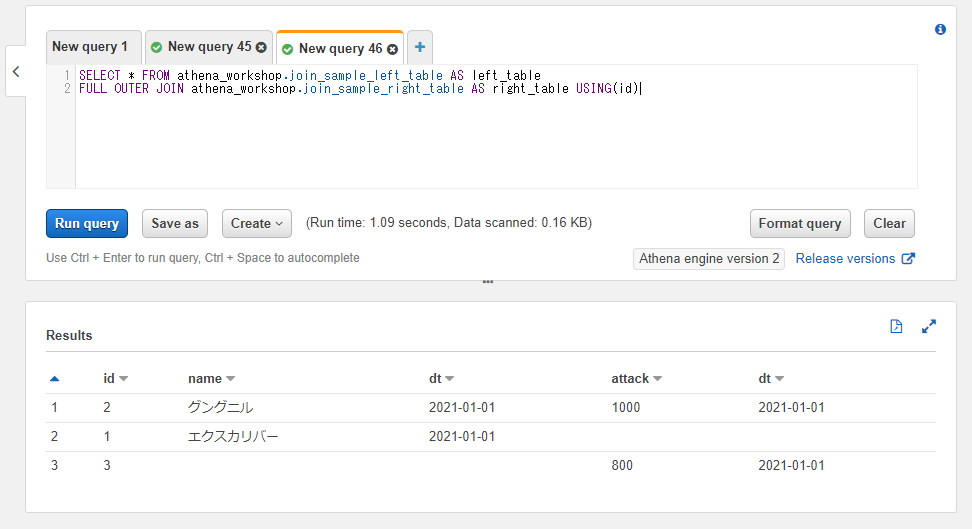
以下のSQLではUSING(id)と記述することで、左右のテーブル両方のidカラムで連結を行っています。
表示するカラムはSELECT * FROMとしていますが、idカラムは1つのみ結果に残されている点にも注目してください。
SELECT * FROM athena_workshop.join_sample_left_table AS left_table
FULL OUTER JOIN athena_workshop.join_sample_right_table AS right_table USING(id)
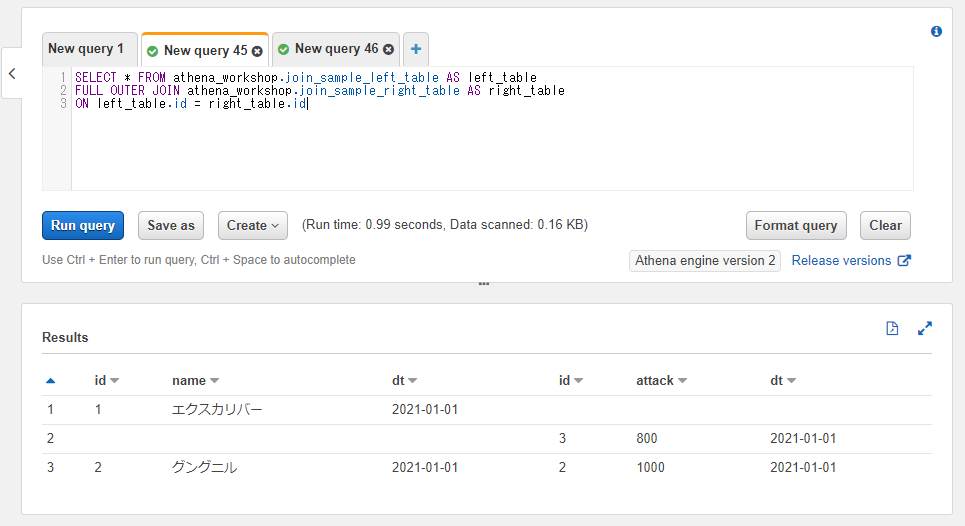
ONを使って同じ内容を書くと以下のようになります。SQLの記述は長くなるのとSELECT *とカラムを指定した時にidカラムが2つ結果に表示されるという差異が確認できます。
SELECT * FROM athena_workshop.join_sample_left_table AS left_table
FULL OUTER JOIN athena_workshop.join_sample_right_table AS right_table
ON left_table.id = right_table.id
連結した時はWHERE句でのパーティションの指定に注意
複数のテーブルを連結した場合にはWHERE句のパーティションの指定はそれぞれのテーブルで必要になります。片方のテーブルのみしかパーティションの指定が無いと、もう片方のテーブルはフルスキャン(テーブルの全データへのアクセス)となって遅くなったり無駄にコストがかかったりするので注意が必要です。
特に1つのテーブルに対してのSQLを色々編集していて、途中でテーブルを追加した場合などにうっかり忘れたりが発生しがちなので注意が必要です。
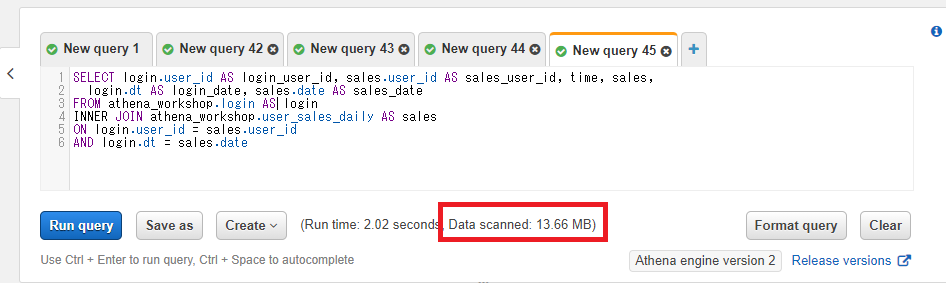
先ほどの節での連結のSQLで確認してみましょう。まずはWHERE句を指定しないケースです。
SELECT login.user_id AS login_user_id, sales.user_id AS sales_user_id, time, sales,
login.dt AS login_date, sales.date AS sales_date
FROM athena_workshop.login AS login
INNER JOIN athena_workshop.user_sales_daily AS sales
ON login.user_id = sales.user_id
AND login.dt = sales.date
この場合両方のテーブルに対してフルスキャンとなります。サンプルデータなのでそれでもサイズは小さい形となりますが、13.66MBと表示されます。
続いて左側のテーブルのみパーティションをWHERE句で指定してみます。今回は2021-01-01と2021-01-02の2日間のみが対象になるように設定しました(WHERE login.dt IN ('2021-01-01', '2021-01-02')部分)。
SELECT login.user_id AS login_user_id, sales.user_id AS sales_user_id, time, sales,
login.dt AS login_date, sales.date AS sales_date
FROM athena_workshop.login AS login
INNER JOIN athena_workshop.user_sales_daily AS sales
ON login.user_id = sales.user_id
AND login.dt = sales.date
WHERE login.dt IN ('2021-01-01', '2021-01-02')
右側のテーブルは小さいので一気に442.82KBまで減りました。

さらに右側のテーブルに対してもパーティションを指定してみます(AND sales.dt IN ('2021-01-01', '2021-01-02')部分)。
SELECT login.user_id AS login_user_id, sales.user_id AS sales_user_id, time, sales,
login.dt AS login_date, sales.date AS sales_date
FROM athena_workshop.login AS login
INNER JOIN athena_workshop.user_sales_daily AS sales
ON login.user_id = sales.user_id
AND login.dt = sales.date
WHERE login.dt IN ('2021-01-01', '2021-01-02')
AND sales.dt IN ('2021-01-01', '2021-01-02')
元々テーブルが小さいのでわずかな減少となりますが、329.32KBと両方のテーブルに対してパーティションを指定した方がスキャンサイズが小さくなりました。
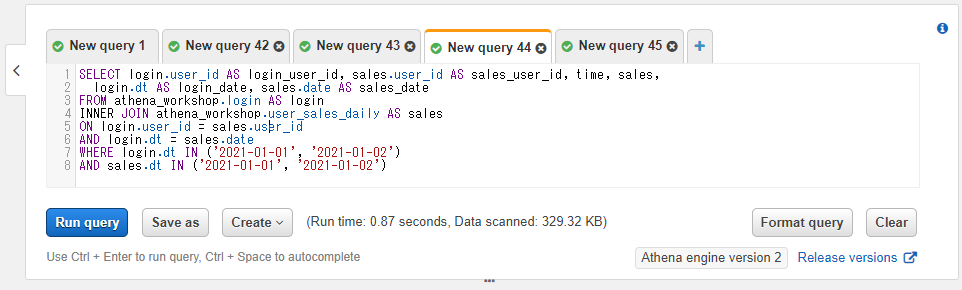
今回のサンプルではテーブルサイズが小さいのでフルスキャンでもまったく問題は無いのですが、お仕事ではログデータが膨大になるケースが多いのでテーブル連結した時にはちゃんとそれぞれのテーブルに対してパーティションをWHERE句で指定することが大切です。
交差結合(クロス結合): CROSS JOIN
前述までの内部結合や外部結合と比べるとマイナーで、使う機会も少ないのですが交差結合(もしくはクロス結合)という列結合の仕方も存在します。そこまで詳しくはここでは記載しませんが軽く触れておきます。
交差結合では2つのテーブルの各行の全ての組み合わせを使った結果の行が返ってきます。例えば左側のテーブルにAとBという行があったとして、右側のテーブルにCとDという行があったとすると以下のような各組み合わせで返ってきます。
- AとC
- BとC
- AとD
- BとD
左側のテーブルの行数がN行、右側のテーブルの行数がM行とすると交差結合の結果の行数は$N × M$行となります。前述の例だと$2 × 2 = 4$行となっています。
つまりテーブルの行数がある定義のサイズ以上になっていると結果の行数が膨大になってしまいます。10万行 × 10万行くらいの小さめのテーブル同士でも100億行の結果になってしまうので利用時には注意が必要です。
使い方としては連結のキーワードの指定をCROSS JOINとします。特定の列を参照して結合ではなく全行の組み合わせという処理になるのでONによるカラムの指定は書きません(ONの記述があるとエラーになります)。
SELECT left_table.id AS left_id, right_table.id AS right_id, name, attack
FROM athena_workshop.join_sample_left_table AS left_table
CROSS JOIN athena_workshop.join_sample_right_table AS right_table
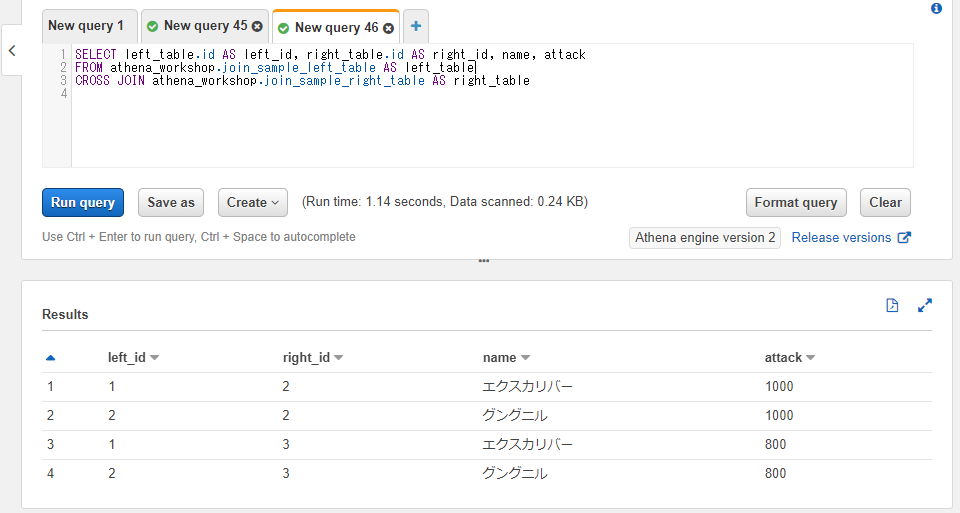
片方のテーブルのカラムは全て取得し、もう片方のテーブルからは一部のカラムのみ取得したい場合の制御
列の結合結果で「左側のテーブルのカラムは全部表示したいけど右側のテーブルは1つだけ表示したい」といったようなケースが出てくるときがあります。一つ一つカラムを指定していっても実現はできますがテーブルのカラム数が多くなってくると少し手間ですし記述が煩雑になります。
そういった場合には<左側のテーブル名>.*, <右側のテーブル名>.<右側で必要なカラム>といったように方々のテーブルで全カラムの指定のアスタリスクを指定することができます。
以下のSQLではSELECT left_table.*, right_table.attackとし、左側のテーブルからは全てのカラムを取得(id, name, dt)しつつ、右側のテーブルからはattackカラムのみを取得しています。
SELECT left_table.*, right_table.attack FROM athena_workshop.join_sample_left_table AS left_table
FULL OUTER JOIN athena_workshop.join_sample_right_table AS right_table
ON left_table.id = right_table.id

3つ以上のテーブルの列を連結する
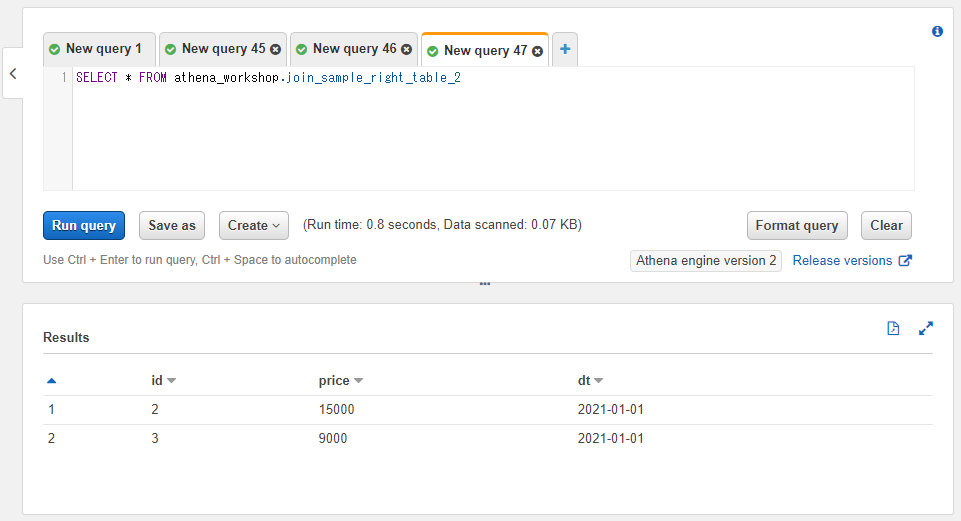
以降の節では追加で列を連結していくため、サンプルとしてjoin_sample_right_table_2というテーブルを参照していきます。idとpriceカラムを持つ2行のみのシンプルなテーブルです。
SELECT * FROM athena_workshop.join_sample_right_table_2
列の連結は2つのテーブルだけでなく3つ、4つ...と複数のテーブルを連結していくことができます。
書き方は今までに触れた通りの連結のものと同じで、単純に下に連結する右側のテーブルの記述を追加していくだけです。
以下のSQLではFULL OUTER JOIN athena_workshop.join_sample_right_table_2 AS right_table_2 USING(id)という記述を追加してjoin_sample_right_table_2というテーブルを追加で連結しています。
SELECT * FROM athena_workshop.join_sample_left_table AS left_table
FULL OUTER JOIN athena_workshop.join_sample_right_table AS right_table_1 USING(id)
FULL OUTER JOIN athena_workshop.join_sample_right_table_2 AS right_table_2 USING(id)
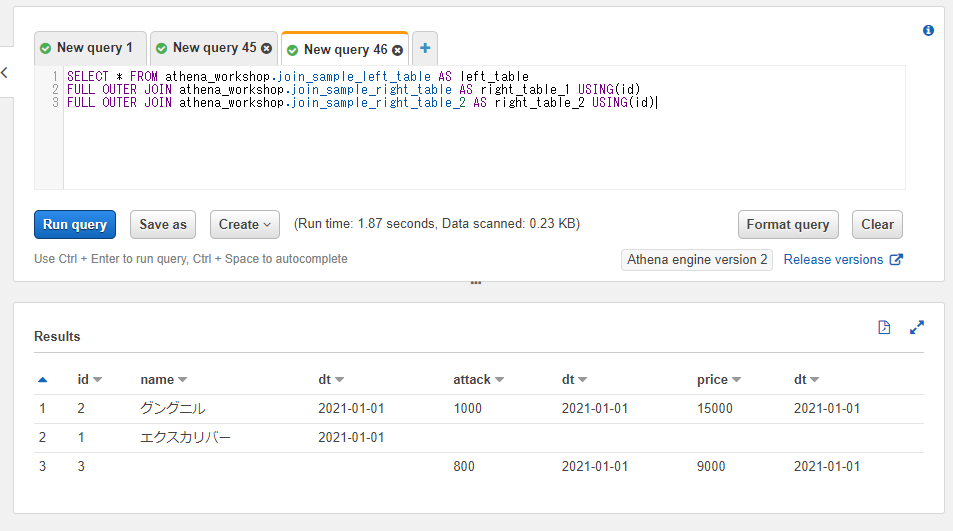
行方向に対して複数テーブルの操作を行う
先ほどまでは列(カラム)方向に対してのテーブルの連結を色々触れてきました。この節以降は行方向に対するテーブルの連結について触れていきます。
例えばどんな時に行方向の連結を使うのか
例えばクエストのログに対してまとめて集計をしたいとします。その際に「常設のクエストは〇〇テーブル」「このイベントのクエストログは××テーブル」「新しく追加した特殊機能のクエストは△△テーブル」みたいに「テーブル構造は似ているけれども別のテーブルになっている」ケースが発生します。
もしくはテーブル構造は同じだけれども年次や四半期などでテーブルが分かれているといったこともあるかもしれません。
そういった場合に共通のカラムを使って行方向に連結してまとめて集計ができると便利です。
利用するサンプルテーブル
以降の節では今までの節に出てきたテーブルに加えて、通常の(常設の)クエストの実行(開始)ログ想定のテーブルであるnormal_quest_startとイベントの実行ログ想定のテーブルのevent_quest_startを扱っていきます。
normal_quest_startテーブルは以下のようなカラムを設定してあります。
- user_id: 対象のユーザーIDの整数のカラム。
- time: ログイン日時の文字列のカラム。
- device_type: 端末種別の整数のカラム。
- quest_id: 実行されたクエストのマスタID。
event_quest_startテーブルはnormal_quest_startテーブルと近いカラム構造ですが、追加でevent_idというイベントのマスタIDを想定したカラムを持っています。また、分かりやすいようにquest_idカラムに対してnormal_quest_startテーブルよりも大きい値が設定されるようにしてあります。
それぞれでSQLを投げて確認してみると以下のようなデータになっています。
SELECT * FROM athena_workshop.normal_quest_start LIMIT 10;
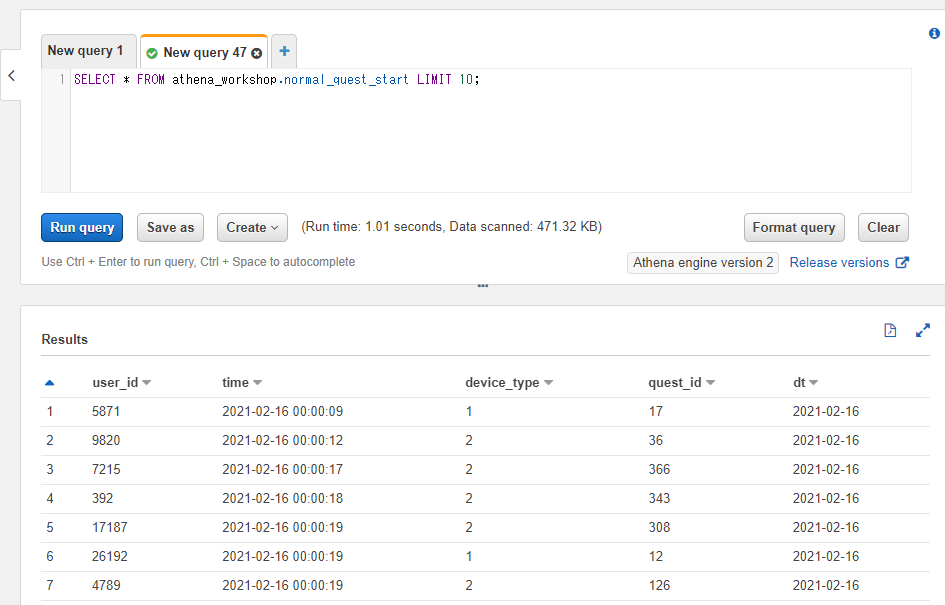
SELECT * FROM athena_workshop.event_quest_start LIMIT 10;

連結を行う: UNION
複数のテーブルを行方向に対して連結を行うにはUNIONを使います。複数のSELECT文の間にUNIONを挟むことで、複数のテーブルのSELECT結果を1つにまとめることができます。例えば以下のように書きます。
SELECT user_id, time, quest_id
FROM athena_workshop.normal_quest_start
WHERE dt = '2021-01-01'
UNION
SELECT user_id, time, quest_id
FROM athena_workshop.event_quest_start
WHERE dt = '2021-01-01'
LIMIT句など、一部の指定をそれぞれのテーブルに行いたい場合にはそれぞれのSELECT文を()の括弧で囲む必要があります。
そうしないと以下のようにエラーになります。
SELECT user_id, time, quest_id
FROM athena_workshop.normal_quest_start
WHERE dt = '2021-01-01'
LIMIT 5
UNION
SELECT user_id, time, quest_id
FROM athena_workshop.event_quest_start
WHERE dt = '2021-01-01'
LIMIT 5
それぞれのSELECT文を括弧で囲ってあげるとエラーが出なくなります。
(
SELECT user_id, time, quest_id
FROM athena_workshop.normal_quest_start
WHERE dt = '2021-01-01'
LIMIT 5
)
UNION
(
SELECT user_id, time, quest_id
FROM athena_workshop.event_quest_start
WHERE dt = '2021-01-01'
LIMIT 5
)
クエリ結果も10行になっていることが分かります(LIMIT 5 + LIMIT 5で合計10行)。
少し前に読んだSQLの書籍だとUNION時に毎回括弧が使われていた点、クエリごとの区切りなどが見えやすくなる点などから基本的に括弧を付ける形でもいいかもしれません。
さらに、括弧の後にLIMITやORDER BY、後述するGROUP BYなども記述することができます。それらは行方向の連結後の結果に対して反映されます(行全体に対して反映されます)。
例えば以下のように1つ目のテーブルで5行(LIMIT 5)、2つ目のテーブルで5行(LIMIT 5)を指定して全体の行数が10行になる条件で、括弧の外でLIMIT 7と記述すると結果が10行から7行に減ります。
(
SELECT user_id, time, quest_id
FROM athena_workshop.normal_quest_start
WHERE dt = '2021-01-01'
LIMIT 5
)
UNION
(
SELECT user_id, time, quest_id
FROM athena_workshop.event_quest_start
WHERE dt = '2021-01-01'
LIMIT 5
)
LIMIT 7

通常のUNIONでは同じ行は残らない(DISTINCT)
通常のUNIONでは同じ行部分は残りません。試しに2つの参照するテーブルを同じテーブルにし、WHERE句だけ変えてみます。
1つ目のテーブルはユーザーIDが385と1024の行のみ、2つ目のテーブルではユーザーIDが1024と972の行のみとしています。1つ目のテーブルと2つ目のテーブルでユーザーIDが1024というユーザーの行は被っています。
(
SELECT user_id, time, quest_id
FROM athena_workshop.normal_quest_start
WHERE dt = '2021-01-01'
AND user_id IN(385, 1024)
)
UNION
(
SELECT user_id, time, quest_id
FROM athena_workshop.normal_quest_start
WHERE dt = '2021-01-01'
AND user_id IN(1024, 972)
)
1つ目のテーブルで2行、2つ目のテーブルで2行残りそうな印象ですが、結果は3行のみ残ります。UNIONでは重複する行は削除されるため、ユーザーIDが1024の行は2行ではなく1行のみ残される形になります。

これは、UNION単体での指定の場合UNION DISTINCTと記述した場合と同じ挙動になることに起因します。DISTINCTはSQLでは前の節でも出てきましたが重複行を取り除く時の指定として使われます。
試しに以下のSQLのようにUNION DISTINCTと記述してみても結果は同じ3行となります。
(
SELECT user_id, time, quest_id
FROM athena_workshop.normal_quest_start
WHERE dt = '2021-01-01'
AND user_id IN(385, 1024)
)
UNION DISTINCT
(
SELECT user_id, time, quest_id
FROM athena_workshop.normal_quest_start
WHERE dt = '2021-01-01'
AND user_id IN(1024, 972)
)
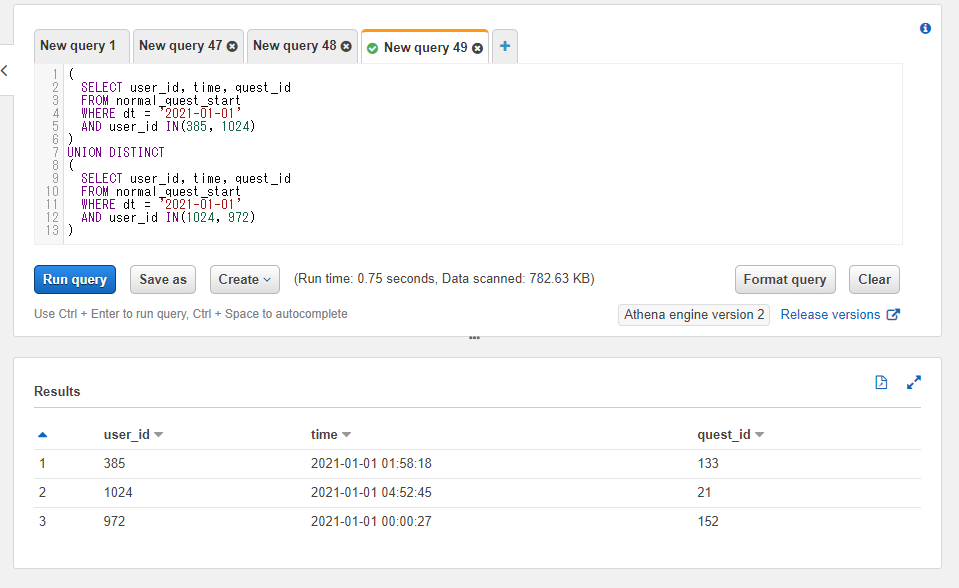
重複行も残して4行に結果をしたい場合には後述するUNION ALLを使う必要があります。
Pythonでの書き方
Pandasではpd.concat関数を使うことで複数のデータフレームを行方向に対して連結することができます。第一引数のobjs引数に各データフレームをリストなどで指定します。
Pandasの場合はそれぞれのデータフレームで列が一致していない場合でも連結はエラーにはならず、代わりに欠落した行に関してはnanが設定されます。今回はSQLと同じようにカラムを一致されるように、事前にdel event_quest_df['event_id']としてevent_idカラムを除外しています。
また、SQLのUNION DISTINCTと挙動を合わせるためにconcatenated_df.drop_duplicates(inplace=True)といったように重複行を取り除くdrop_duplicatesメソッドを呼んでいます。もし後述するUNION ALLと合わせたい場合はこの行を削除することで合わせることができます。
import pandas as pd
normal_quest_df: pd.DataFrame = pd.read_json(
'https://github.com/simon-ritchie/athena_workshop/blob/main/workshop/normal_quest_start/dt%3D2021-01-01/data.json.gz?raw=true',
lines=True, compression='gzip')
event_quest_df: pd.DataFrame = pd.read_json(
'https://github.com/simon-ritchie/athena_workshop/blob/main/workshop/event_quest_start/dt%3D2021-01-01/data.json.gz?raw=true',
lines=True, compression='gzip')
del event_quest_df['event_id']
concatenated_df: pd.DataFrame = pd.concat(
objs=[normal_quest_df, event_quest_df],
ignore_index=True)
concatenated_df.drop_duplicates(inplace=True)
print(concatenated_df.head())
print(concatenated_df.tail())
先頭の方の行の結果 :
user_id time device_type quest_id
0 14137 2021-01-01 00:00:00 1 259
1 31189 2021-01-01 00:00:01 1 285
2 1611 2021-01-01 00:00:02 2 69
3 23064 2021-01-01 00:00:05 2 215
4 32977 2021-01-01 00:00:05 2 126
末尾の方の行の結果 :
user_id time device_type quest_id
67487 7322 2021-01-01 23:59:49 1 10123
67488 6386 2021-01-01 23:59:52 2 10174
67489 12905 2021-01-01 23:59:55 1 10005
67490 8015 2021-01-01 23:59:57 2 10250
67491 2562 2021-01-01 23:59:58 2 10261
同じ行を全て残す: ALL
重複行も残したい形で行方向に連結したい場合にはUNION ALLを使います。先ほどのSQLでUNIONもしくはUNION DISTINCTとした場合には3行のみ残りましたが、UNION ALLを使うと1つ目のテーブルと2つ目のテーブルで重複していたユーザーID = 1024の行が2行残り、結果が4行になります。
(
SELECT user_id, time, quest_id
FROM athena_workshop.normal_quest_start
WHERE dt = '2021-01-01'
AND user_id IN(385, 1024)
)
UNION ALL
(
SELECT user_id, time, quest_id
FROM athena_workshop.normal_quest_start
WHERE dt = '2021-01-01'
AND user_id IN(1024, 972)
)
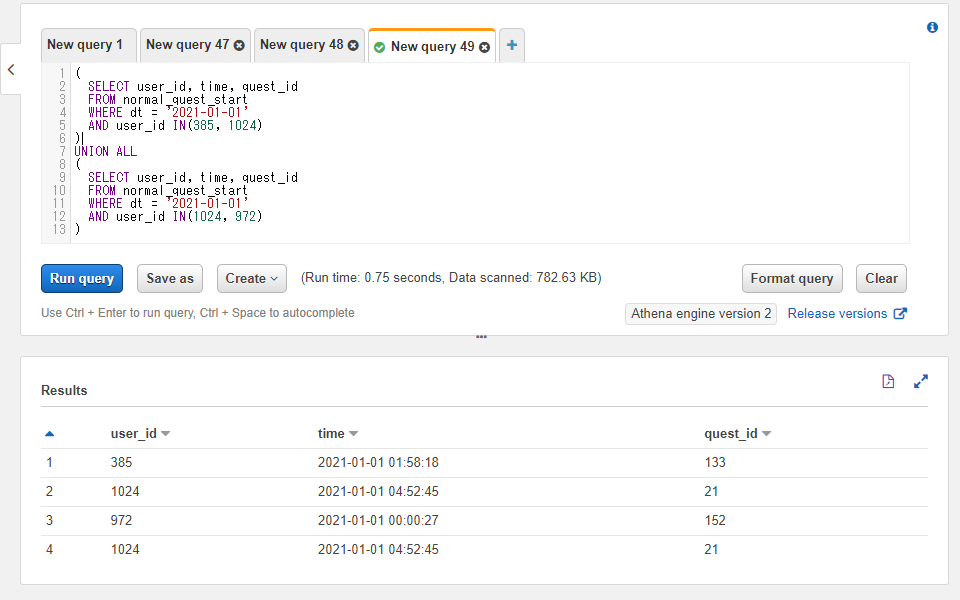
それぞれのテーブルに存在する行を抽出する: INTERSECT
UNIONのようにテーブル連結の処理となりますが、連結した時に重複している行のみを残したい場合にはINTERSECTを使います。両方のテーブルに存在する行のみが結果に表示されます。
例えば以下のSQLではWHERE句の指定的にユーザーID = 1024の行のみ重複しうるので1行のみ結果が返ってきます。
(
SELECT user_id, time, quest_id
FROM athena_workshop.normal_quest_start
WHERE dt = '2021-01-01'
AND user_id IN(385, 1024)
)
INTERSECT
(
SELECT user_id, time, quest_id
FROM athena_workshop.normal_quest_start
WHERE dt = '2021-01-01'
AND user_id IN(1024, 972)
)

Pythonでの書き方
duplicatedメソッドで重複している行が存在するかどうかの判定が取れるので、行方向に連結後にそれを使ってスライスすると同じような結果が得られます。事前にisinを使って特定のユーザーIDのみにスライスしています。
import pandas as pd
df_1: pd.DataFrame = pd.read_json(
'https://github.com/simon-ritchie/athena_workshop/blob/main/workshop/normal_quest_start/dt%3D2021-01-01/data.json.gz?raw=true',
lines=True, compression='gzip')
df_2: pd.DataFrame = pd.read_json(
'https://github.com/simon-ritchie/athena_workshop/blob/main/workshop/normal_quest_start/dt%3D2021-01-01/data.json.gz?raw=true',
lines=True, compression='gzip')
df_1 = df_1[df_1['user_id'].isin([385, 1024])]
df_2 = df_2[df_2['user_id'].isin([1024, 972])]
concatenated_df: pd.DataFrame = pd.concat(
objs=[df_1, df_2],
ignore_index=True)
concatenated_df = concatenated_df[concatenated_df.duplicated()]
print(concatenated_df)
user_id time device_type quest_id
3 1024 2021-01-01 04:52:45 1 21
テーブルの差分を確認する: EXCEPT
EXCEPTもUNIONとINTERSECTと同じように、複数のテーブルを扱う処理となります。こちらはテーブル間の差分の比較用に使われます。
挙動としては、
- 1つ目のテーブルと2つ目のテーブル両方に存在する行は結果には含まれません。
- 2つ目のテーブルにのみ存在する行は結果には含まれません。
- 1つ目のテーブルに存在し、2つ目のテーブルに存在しない行のみ結果に残ります。
以下のSQLでは、
- 両方のテーブルに存在するのでユーザーID = 1024の行は残らない。
- 2つ目のテーブルにのみ存在するのでユーザーID = 972の行は残らない。
- 結果的にユーザーID = 385の行のみ残る。
という結果が返ってきます。
(
SELECT user_id, time, quest_id
FROM athena_workshop.normal_quest_start
WHERE dt = '2021-01-01'
AND user_id IN(385, 1024)
)
EXCEPT
(
SELECT user_id, time, quest_id
FROM athena_workshop.normal_quest_start
WHERE dt = '2021-01-01'
AND user_id IN(1024, 972)
)
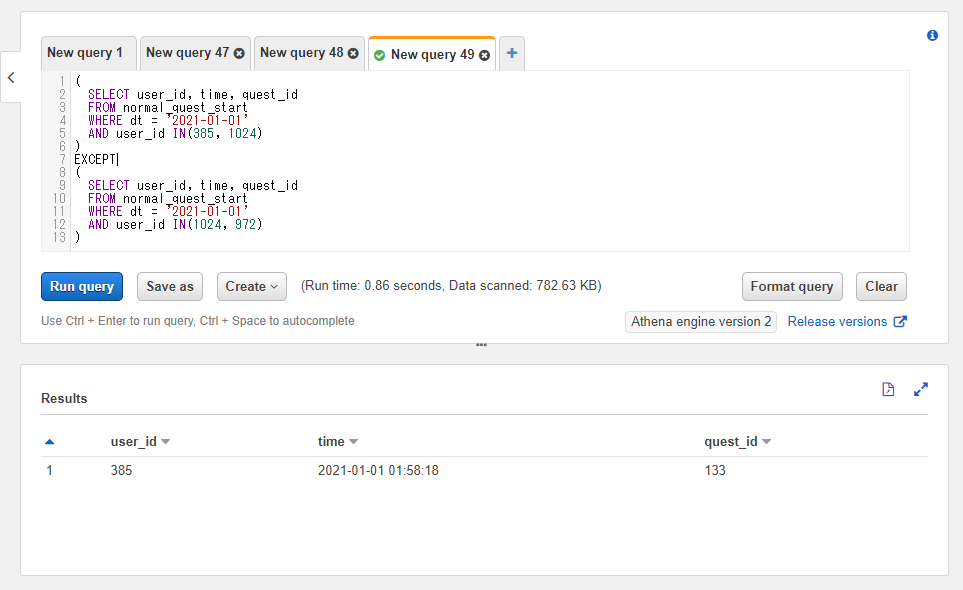
Athena上でのDB名やテーブル名・カラム名などにおける特記事項
少し余談気味となりますが、お仕事でこの点で引っかかる点を見かけたので特記事項として記載しておきます。
AWSのGlueとかを使うとDB名などにハイフンが使えてしまいます。しかしながらAthenaではハイフンは各名前に使えません。アンダースコアのみ使えます。
そのためGlue経由でハイフンを使ったDB名などでAthenaのDBやテーブルなどを作成していると、SQLでDB名の指定が必要になった場合などにそのSQLが実行できなくなります(DBの再生成などが必要になってしまいます)ので注意が必要です。
この辺は将来Glue上でそういった指定がされた時には弾いたり・・・がされるといいなとは少し感じました。
参考 :
- Athena の「FAILED: ParseException line 1:X missing EOF at '-' near 'keyword」 というエラーを解決するにはどうすればよいですか?
- Athenaの外部テーブル作成でエラー ハイフンに注意!
終わりに
思っていた以上に基礎的な部分だけでもかなり長くなってしまいました。まだまだ全然カバーしきれておらず、今後何記事かに分けてAthenaのSQLの記事を書いていこうと思います。
それらも書き終わりましたらリンクなども整備しようと思います。
参考文献・参考サイトまとめ
- The Applied SQL Data Analytics Workshop: Develop your practical skills and prepare to become a professional data analyst, 2nd Edition
- 『Prestoとは何か,Prestoで何ができるか』
- Athenaの自動パーティショニングをPartition Projectionで実現する
- SELECT - Amazon Athena
- SQL - wikipedia
- 標本標準偏差と母標準偏差
- Presto集計関数の紹介
- Presto クエリーで group by クエリーが返す列の値に最大または最新のレコードの値を返すようにしたい
- [新機能]Amazon Athena ルールベースでパーティションプルーニングを自動化する Partition Projection の徹底解説
- 『Prestoとは何か,Prestoで何ができるか』
- [Update] Amazon Athena engine version 2がリリース、Federated queriesやGeospatial functions等の新機能、パフォーマンスが改善されました
- Names for Tables, Databases, and Columns
- ストラクチャード・クエリ・ランゲージ (Structured Query Language)
- AthenaでクロスアカウントのGlue データカタログを参照する
- データベース (database)
- SQL - Wikipedia
- pandasのDataFrameをある列の値が特定の区間に含まれる行のみに絞る
- Null - Wikipedia
- pandasで欠損値NaNが含まれているか判定、個数をカウント
- カラムナフォーマットのきほん 〜データウェアハウスを支える技術〜
- Amazon Athenaのパーティションを理解する #reinvent
- SQLで別名をつけるならAS句を使いこなそう!つけ方をわかりやすく解説
- Pandasでデータの個数を数え上げるcount関数の使い方
- 四分位範囲と四分位偏差の意味
- pandasで分位数・パーセンタイルを取得するquantile
- Date and Time Functions and Operators
- 相関係数 - Wikipedia
- 【雑記】BIGINT型やばい
- Athena の「FAILED: ParseException line 1:X missing EOF at '-' near 'keyword」 というエラーを解決するにはどうすればよいですか?
- Athenaの外部テーブル作成でエラー ハイフンに注意!
- 倍精度浮動小数点数 - Wikipedia
- Data Types in Amazon Athena
- AthenaのSQLで日付を条件にしたい
- Amazon Athenaを使ってJSONファイルを検索してみる
- Working with complex types
- クロス結合(CROSS JOIN)が役に立つケースに初めてぶつかった。(横持ち⇔縦持ち変換)
- クロス結合
- SQL usingでjoin結合条件をシンプルに記述 OracleのPL/SQLでは別の意味
- SELECT文を統合する「UNION」
- UNION ALL/UNION [DISTINCT]
- SQL EXCEPTのサンプル(差分を抽出する)