この投稿は、私が所属するKDDIテクノロジーで行っているアドベントカレンダーの25日目(最終日)の記事となります。ここで話すのは、「アプリケーション」というものが、OSやプラットフォーム上で、サービスを作り出すための「ソフトウェア」とするなら、生成AIの「プロンプト」はある意味、アプリケーションとなりうるだろう、という妄想を記載したエントリーとなります。
アプリと実行環境
私の所属している会社は、歴史的にOSやプラットフォームに関する業務となじみが深いです。サービスを構築するとき、いつでも何等かの基盤があり、その上で動作するソフトウェアやオブジェクトなどを作成します。この実行環境上で動作するものの定義を「アプリケーション」と定義づけるならば、これまで自社でかかわった様々な開発も、まさにプラットフォームの変遷だと言えます。
たとえば、フィーチャーフォン(いわゆるガラケー)の開発の時には、キャリアで準備した携帯プラットフォーム(KCP)の上で、BrewアプリやEZアプリといった「アプリケーション」を追加し、携帯電話の機種やメーカを超えて動作する実行環境を提供していました。
たとえば、スマートフォンの開発の時には、iOSやAndroidといったAppleやGoogleが提供するOSの上で、AndroidやiOSの「アプリ」を追加し、携帯電話の機種やメーカにとどまらず、キャリアも超えて動作する実行環境を提供することに成功しています。
たとえば、クラウドの開発の時には、AWS、GCP、Azureといったクラウドサービスが提供され、その基盤の上にSaaSという形でサービスを「クラウド上で動作するアプリケーション」として提供しています。特に、K8sなどの環境についてはインフラの定義までコード化することができ(IaC:Infrastructure as Cide)、まさにクラウドサービスを超えて動作する実行環境に近くなり、よりアプリ化したと感じています(この観点はあまり受け入れられていませんが)。
生成AIの実行環境とは
そして今。ChatGPTに代表される、生成AIのLLMについてはどうでしょうか。結論から言うと、学習されたLLMが実行環境であり、プロンプトが推論時に動作するアプリのように見えてきます。
LLMは大量な文章や言葉を学習して作成されます。それはあたかも人間の知識と行動をつかさどる「脳みそ」にあたる部分を構築する行為と言っても良いでしょう。この学習には二つの種類が有り、一つは「事前学習」、もう一つは「ファインチューニング」です。
事前学習により作成されるのが「事前学習モデル」であり、これは世のなかにあまたある言語資源を片っ端から集めて学習させることができます。昔の自然言語のAIにおいては、正解データ(教師データ)がないと学習できませんでした。
例えば、翻訳ならば翻訳元のデータと翻訳後のデータのセットのようなものです。世の中に存在する、書籍や新聞やWebや会話などちまたにあふれている膨大な言語情報からすると、ごくごく正解情報があるデータは僅少です。とてもだけですが、僅少のデータだけで世の中の知識を偏りなく学習させる事はできませんでした。そで登場したのが2017年にGoogleの研究者から発表されたトランスフォーマー(Transformer)です。これは教師データがなくても、自身の文章を用いて学習を行う事ができるようになりました。これにより学習でき来る言語資源の量が一気に跳ね上がりました。このおかげで、後述する創発性(Emergent AbilitiesまたはEmergent Phenomena)を獲得することができるようになり、現在のLLMの流行の礎が作り上げられました。
一方、もう一つの学習データある「ファインチューニング」は、主にLLMの挙動を定義するための学習となります。こちらは、LLMがチャットボットとして動作したり、要約ツールとして動作したり、コールセンターの応答として動作したり、LLMの挙動を定義するための学習です。その正しい挙動を教え込む必要があるので、正解がある動作例を用いた「教師あり学習」を行います。
これにより、事前学習は世のなかの知識やことばの文法など込められており、ファインチューニングは脳みその動作や挙動をLLMに指示するための「先生役」を担っています。
創発性がエポックメイキング
ここで奇妙な動きが出てきました。創発性という挙動です。
事前学習を含めて、学習量が一定量を超えると、ファインチューニングで指示した以外の動作まで、LLMが行えてしまう挙動が示されるようになったのです。

つまり、教えていないことなのに、動けているように見えてしまう。この場合は、Negativeという正解して与えていないので、LLMはNegativeというラベルをつけるかそうでないかしか判断できないはずです。しかし、ここではPositiveという「学習で指示していない」動作を実行しています。このように、直接指示していないけれど、推論時に類推を行い自分の動作範囲を勝手に広げていくこのLLMの挙動を「創発性」と呼ばれています。
直接でなく、間接の概念を通して事象を推測する能力を得たようにも見えるため、ChatGPTが「考えられるようになった」と感じるには十分の事象でした。これが現在話題沸騰している理由だと考えています。
特にこの創発性が、学習量の10^22~10^23FLOPsを超えた所で急減に向上している論文がGoogleより出されています。
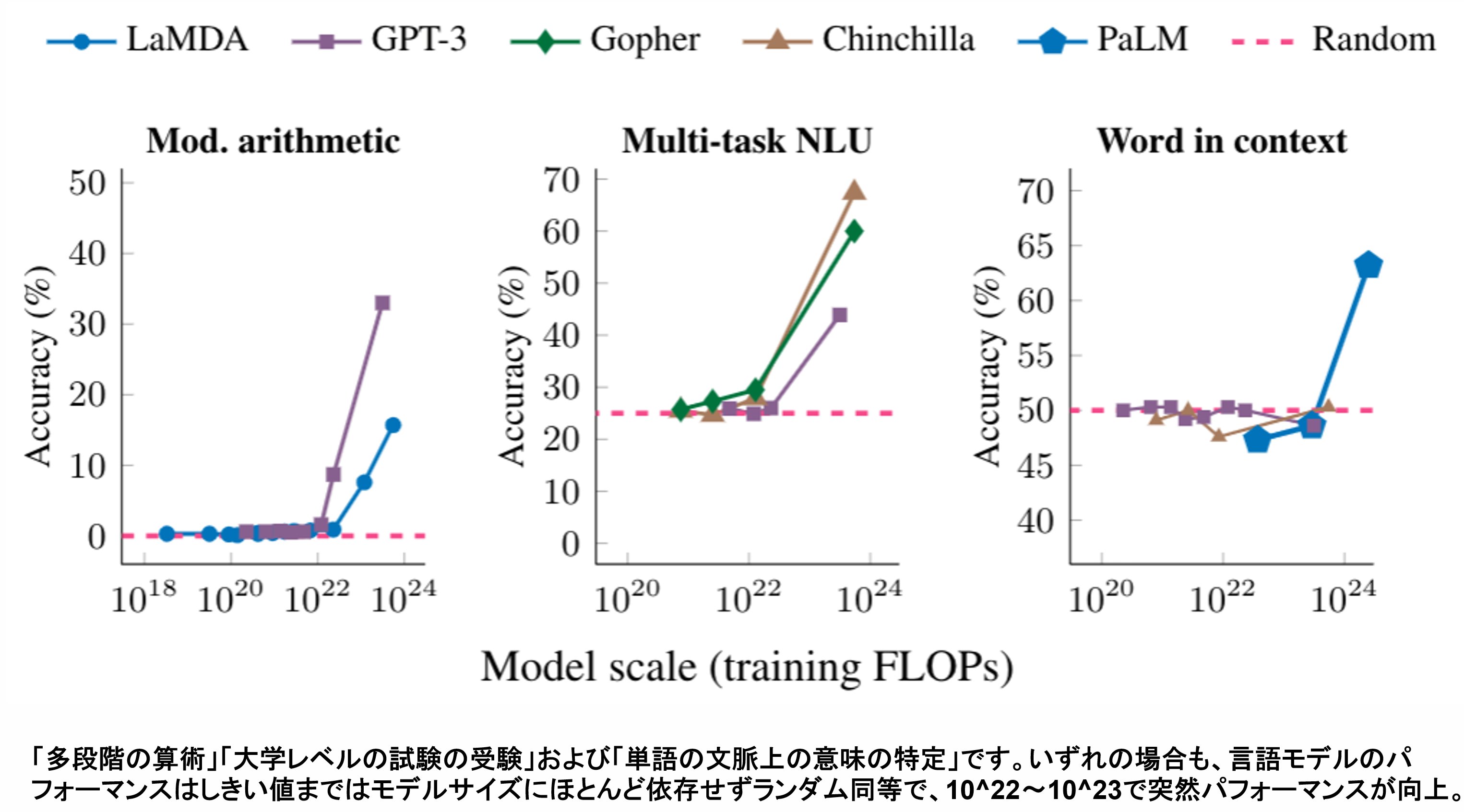
Characterizing Emergent Phenomena in Large Language Models
「https://blog.research.google/2022/11/characterizing-emergent-phenomena-in.html」
プロンプトの工夫
そしてもう一つ驚くことがあります。インコンテキストラーニング(In-context Learning)のプロンプトでの活用です。
「インコンテキストラーニング」は、挙動例を複数学習させておくことによって、そのパターンを動作をLLMが獲得できてしまう能力です。
「プロンプト」とは、LLMから応答を得るために入力する入力文のことです。例えばアバウトにプロンプトで「この後の文章を英語に翻訳してください」と記載すると、LLMは翻訳機の挙動を示します。
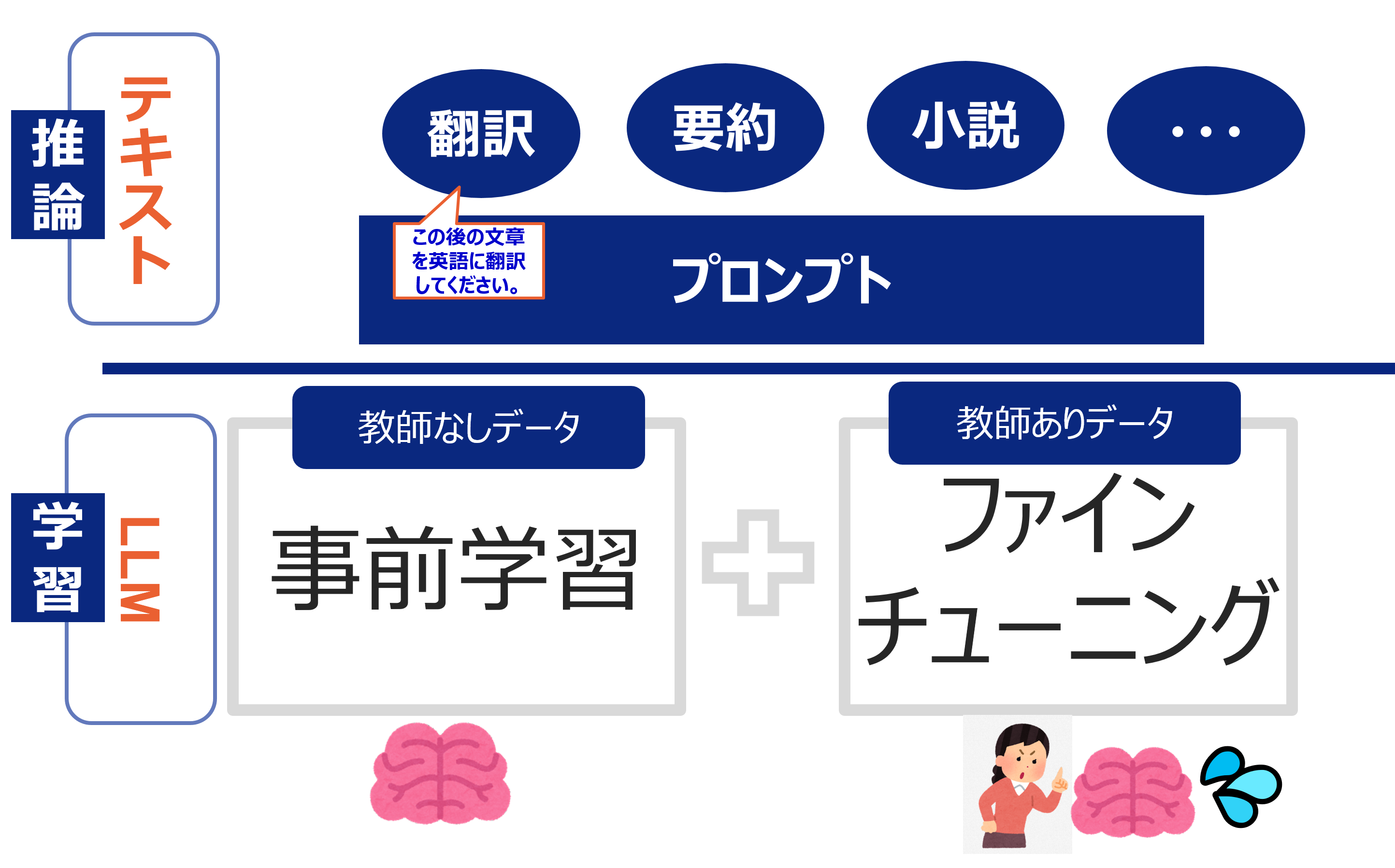
プロンプトを上手に操作することで、期待の回答を得られやすくなるため、この工夫に取り組むことを「プロンプトエンジニアリング」と呼ばれて注目されています。
それではどのような工夫がプロンプトでできるのでしょうか?
実はインコンテキストラーニング自体は、事前学習やファインチューニングの中であらかじめ学習しておく時に使える仕組みなのですが、これをプロンプトに使ってみると・・・なんと不思議なことに、事前学習やファインチューニングで学習したときと、似たような挙動を示してくれるのです。
このプロンプトに、挙動例などを示すと、この文脈を次のプロンプトで引き継ぐことにより、ファインチューニングがごとく、その挙動を示せるようになるのです。
これがプロンプト内で利用する場合のインコンテキストラーニングです。1例だけで動作指示するものをワンショットプロンプティング(One-shot prompting)、数例で動作指示をだすものは、フューショットプロンプティング(Few-shot prompting)ラーニングと呼ばれています。また、学習させておきたい知識をプロンプトに入れておくと、あたかも事前学習時に該当知識を含めて学習させているかのような挙動を得ることもできます。
プロンプトは後から学習可能?!
ここで注目すべき点は、本来は大規模な演算装置で時間とお金をかけて「事前に作り上げおく」ものがLLMです。それが実行時に指定するプロンプトで、後からの知識と挙動の追加をができてしまう点です。
ディープラーニングでの鉄則は「学習」で作成したモデルで「推論」を行うというものです。今回は学習で作成するモデルがLLMであり、推論がプロンプトで指示する動作です。
生成AIサービス(ChatGPTやGemini等)ではLLMはサービスの環境として提供されていますので、それ自体を作成したり変更させることは一般的にできません。こちらはプラットフォームはOSの位置づけに近いです。
冒頭紹介した、なんらかのプラットフォームやOSの上で、動作させるものの定義を「アプリケーション」と定義づけるならば、「学習」したLLMの部分はプラットフォームとなり、創発性を活かして自由な推論で動作させるプロンプトの実行環境と見ることができます。その結果、プロンプトは実行環境の上で動作するアプリケーションのように扱うことができるようになります。

恐ろしいのが、工程がシンプルな作業ならば、プログラムのような動作のすべての万象を記載しないと動かないようなものではなく、言葉でアバウトに雑に指示するだけでもある程度動作してしまう現実です。
ただ、このような動作するツールを手にした人類は欲を持ちだしました。もっと、自分が想定する動作を行ってほしいと。LLMが進化することで解決することもあれば、多くの場合は、指示が甘いために想定外の動作をしていることも多々あります。その両者の溝を埋めるのは、LLMに繰り返しプロンプトで追加の指示を繰り返し出すというものです。
プロンプトの限界
LLMの挙動や検索対象の知識をプロンプトに含めることができるとはいえ、限界もあります。プロンプトが入力できるサイズに限りがあるからです。特定の知識検索を行う場合、多少の文章くらいならばプロンプトのなかに含めてしまうことができるでしょう。しかし、膨大な辞書や、医療系の専門用語などを全てプロンプトに含めることはできません。
そこで最近知識検索で使われている仕組みがRAG(Retrieval-Augmented Generation)です。プロンプトの中にデータを入れられないならば、LLMとは異なる、外部のシステムに知識データベースを持っておき、そこで検索した内容から必要な情報だけをプロンプトに含めてから、LLMへ渡すという仕組みです。現在生成AIを用いた、社内特化のチャットシステムは、これらRAGを活用してプロンプトを溢れさせずに目的を達成する取り組みが行われています。
アプリケーションの実行環境としてのChatGPT
ChatGPTはこのアプリ化の流れを感じ取って先手を打ってきているように感じています。
まず今年3月にスタートとした「プラグイン」という機能は、プロンプトや外部のサービス連携の機能を、ChatGPTのWeb画面から利用することができます。つまりChatGPT内部で、アプリのように利用できる仕組が提供されています。また作成したプラグインはChatGPT内部で公開することもできるため、アプリ配信の様相を示しています。また今年11月からスタートした「GPTs」についても、特定の目的や状況に応じたチャットシステムを作成して公開できるようになっており、様々なアイデアのGPTsが公開され始めています。
回顧録:生成AIは興奮のるつぼ
ほんの昨年末に登場し、この一年間の話題をかっさらっていった感じもあるこの生成AIのChatGPT。しかし、OpenAIから公開されてほんの1年間しか経っていないのです。技術の基本となる技術LLM(Large Language Mode)は、ソフトウェアやサービス構成の考え方を変えつつあるだけでなく、人に求められるスキルすら変えつつあると感じています。
自身は2021年より、自社の仲間内でGPT2のオープンソースを用いた検証を行っていました。当時はまだまだ分類や要約といった目的に特化した自然言語ソリューションを取り組んでおり、どうしても満足のいく文章生成が達成できなかったところ、デコードに特化した生成AIとしてのLLMモデルであるGPTに飛びついてみたのでした。そのときに、学習量を増やしていくと、lossが着実に減っていき、精度が上がるのを目の当たりにして、かなりのドキドキと興奮を覚えたものです。また、国内販売が始まったばかりのDGX Station A100を2020年度内に自社に導入できたのも、この興奮に輪をかけていたのもあります。
新技術のデジャブ
それから1.5年がたち、ChatGPTがOpenAIから公開されました。
実は、発表当時は私はこのChatGPTに少し懐疑的でした。。というのも、トランスフォーマのデコードに特化したモデルでは、(敢えて乱暴に言うと)制約なく無責任に生成を行ってしまうモデルです。そのため、生成する日本語こそ滑らかに生成できますが、作り出した文章内容は発散して制御不能となり破綻するケースがあることが知られていたからです。
それがです。発表されたChatGPTは異なっていたのです。
単発で行う質問に関しては、我々が知っていた課題に近い挙動も現していたのですが、繰り返し続けて質問すると、そのプロンプトの質問内容を学習に近い挙動を行いつつ、LLMの挙動が変わっていく。「なんじゃこれは」という感じとなりました。
昔話で申し訳ないのですが、ちょっとこのときデジャブを感じてしまいました。
これから15年前の2007年のことです(オッサンの昔話ごめんなさい)。スマートフォンのオープンソースのAndroidがGoogleから発表されたときのことです。私はメーカでフィーチャーフォンを開発をしていただけに、Googleは組み込みソフトウェアの泥臭いところができるはずがないと思い、発表された内容の「あら」を探そうと躍起になっていました。つまり、初めは拒否反応(ダークサイド)から入っていたのです。しかし、Androidの情報を探ってみると、Googleが不得意な部分はオープンソース側(というかオープンソースのエコシステム)に丸投げしていることが判明して、これでメーカとの分担ができると見込んで、急遽「アンチ」から「ポジ」へ転向した経緯があります。
これがきっかけで、拙著「Google Android入門」を2009年に執筆し、新技術への感度が高い仲間たちと日本Androidの会をともに立ち上げるに至ったのでした(現在も絶賛運営中! https://www.android-group.jp/ )。
私は、実はChatGPTも初めは「あげあしとり」から入ってしまった反省があります。ハルシネーション(嘘を回答する事)という言葉もまだ広まっていなかったころに、得意顔で「生成AIなのだからLLMがしらないものは、情報を生成するんですよ、それはLLMとって嘘のつもりがないんです、デコードモデルには」なぞと言い放っていました。ただ、使っていくうちに、そして使い込んで活用している方々との交流の中で、この考えを改めるまでの時間はそうかかりませんでした。そういう経験もあり、LLMは絶対に次にくるぞ、と思った次第です。
追いプロンプト
そもそも、人間も話をしているときには、先の結論を考えていつも話しているかというと、そうでもないと思います。まずは、思いつく言葉を連ねて話していることが多いのではないでしょうか。そういう思考を何度も繰り返し試行し、そのうち良い解決方法や、良い言い回しなどが見つかって、最終的な話がまとまったり、伝えたい事を言い直したりして、コミュニケーションしていることの方が多いのではないでしょうか。つまり、発散(デコード)を繰り返すことは、意外と本質ではないかと思うようになりました。
そして思い至ったのが、この「繰り返すこと」です。プロンプトを繰り返し、答えが出るまで聞き直すことが肝要だと思い至りました。ChatGPTを使うときに「単発」のプロンプト終わらせるのではなく、適切な回答を引き出すまでの、努力と忍耐が活用のエッセンスであると思い至っています。このように「プロンプト」を何度も入力することを「追いプロンプト」と呼ばれています(生成AI仲間の造語ですが)。
GPT3では、人間が適切と思う回答を得られる確率は6~7割程度であることが示されています。以外に悪い精度に感じますが、この追いプロンプトを重ねることで、これが向上して実用にギリギリ至っているのではないかと感じています。一度ChatGPTを使って諦めた方がいたら、少し辛抱して使ってみると、また別の世界が見えてくるのではないでしょうか。
人材とスキル
当たり前のことを書きますが、ソフトウェアはプログラムで記述した「ルールベース」で動作するため、間違いは起こさない反面、実装されている処理以外は一切受け付けません。そのため、ソフトウェアを開発する際は、使うかもしれない機能(実際にはほとんど使われない機能)などがふんだんに盛り込まれ、開発期間が長くなってしまうプロジェクトがこれまでも数多く経験してきました。これを改善するために、スクラム開発を採用して、検証を行いつつ無駄な開発を避ける取り組みなども行われているのが、世の中の流れです。
一方、LLMの挙動をみると世の中一般的に知識は持っており、何を聞いても通り一辺倒の回答はできてしまいます。ただ、その中で、本当に価値となる挙動や、意味がある応答を行う部分のみ作り込んでいくような開発スタイルが、今後何十年かの間で構築されるのではないかと、できもしない妄想をしまくっています。妄想は楽しい!
そうすると、現在の人材に求められるスキルも変わってきます。
とは言うものの、今後はまず、生成AIを活用した開発ができる人材とともに、活用できる人材を増やす必要があると感じています。そして、現在のソフトウェアの至る所に生成AIが入り込んでいって、どこにでもAIが入っている世界観を持ったとき、現在のソフトウェア開発の変わるべき姿について、逐次ウォッチしながら対応していきたいと考えています。
現在の取り組みについて
生成AIの取り組みは、業務だけでなく、普及活動や人材育成などにも絡めて取り組んでいきたいと思っています。
現在、社内のWG活動だけではなく、社外での生成AI研究会(https://gais.jp/) の人材育成WGの運営委員や、MCPCの人材育成委員会ワイヤレスプロンプトエンジニアリング検討WGで主査(https://mcpcseiseiaikatuyoubenkyoukai.peatix.com/) として参画し、少しでも世の中に貢献できればと考えています。
さて、新しい技術をベースに仲間と議論する時間は、この上ない刺激的な瞬間でもあり、モバイルに関係するサービスの未来のカケラが、ちょこっと垣間見られる瞬間でもあります。
株式会社KDDIテクノロジーでは、AndroidやiOSのアプリを中心に、AIやクラウドを用いた開発や、5G、XR、IoTなどの技術を扱う仲閒を積極的に募集しています。ともに開発やPMの仕事をしてみませんか?
興味ある方は是非こちらの採用ページからご相談ください。お待ち申し上げています。
→ https://recruit.kddi-tech.com/