はじめに
LLMでは、与えられたプロンプトからその次の単語の生成確率を求め、それを元にまた次の単語の生成確率を求めるといったステップを繰り返すことで、文章を生成(デコード)します。
しかし、品質の高い文章を生成するためには、ただただ確率の高い単語を繋げるだけでは不十分な場合も多々あり、様々なデコード手法が考えられてきました。
本記事ではこれらの背景をもとに、LLMにおける主なデコード手法についてまとめました。
またELYZA-7bを用いて実際に生成し、各手法の特徴について観察してみました。
なお本記事の作成にあたっては、主に以下のサイトを参考にいたしました。
(説明に用いた図も以下から引用しています)
タイトルの内容が気になる方は一番最後の章までジャンプしてください。
Greedy Search (貪欲な探索)
まずは最も単純なケースであるGreedy Searchについて紹介します。
Greedy Searchでは、各ステップごとに最も確率の高いトークンを選択して文章を生成します。
非常にシンプルなロジックで、計算量も削減できるという利点はありますが、いくつか欠点も存在します。
- 繰り返しが起きやすい
単純に確率の高い単語を繋げていくだけなので、簡単に繰り返しが起きてしまいます。
実際にELYZAで推論した例を見てみましょう(ここではあえて繰り返しやすいプロンプトを用いています)。
明日の天気は?
昨日の天気は?
今日の天気は?
今日の天気は?
今日の天気は?
今日の天気は?
今日の天気は?
今日の天気は?
今日の天気
- 全体としての意味が不完全になりがち
局所的に最適な選択の連続になるため、全体としての最適な選択から遠ざかってしまう可能性があります。
例えば、もし確率の低い単語の後ろに確率の高い単語が隠れていても、Greedy Searchではそれを見逃してしまいます。
以下の図のような例を考えてみましょう。
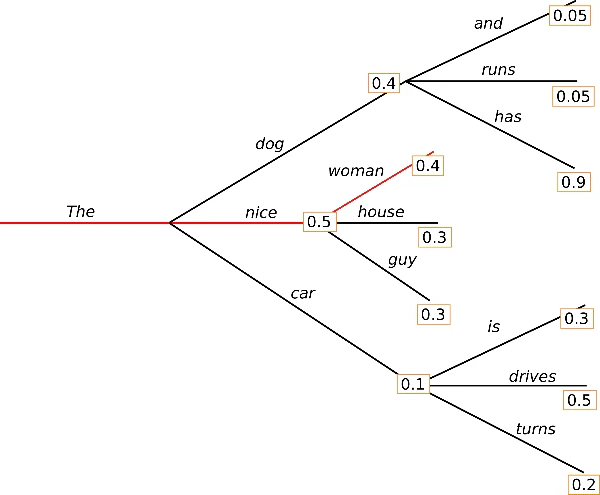
この例の場合、生成される文章は"The nice women"となります。一方で"has"は0.9という高い条件付き確率を有しますが、"dog"という単語の後ろに隠れ、見逃されてしまっています。
この問題に対処するのが、次章のBeam Searchです。
Beam Search
Beam Searchでは、その後に続く単語らの同時確率をもとに文章を生成します。
先ほどの例を用いて考えてみましょう。
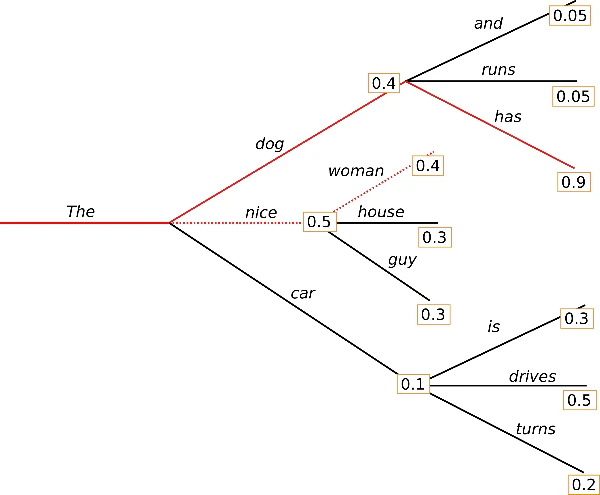
ここでは"The nice woman"という文章の同時確率が0.20であるのに対し、"The dog has"は0.36と、後者の方が高い確率となり、隠れている高確率の単語を見逃してしまうという問題が軽減されていることが確認できます。
しかし、最大トークン数に達する / 終端トークンが出力されるまでの全ての組み合わせについて同時確率を計算することは、計算量の観点から現実的ではありません。
そこでBeam Searchでは、しらみつぶしに同時確率を計算するのではなく、各ステップごとに確率の高いいくつかのルートのみを保持することで、計算量の低減を実現しています。
実際に先ほどの例と同様に推論を行ってみましょう。ここでは、保持するルートの数(num_beams)を5として設定しています。
今日の天気は?
明日の天気は?
今日の天気は?
明日の天気は?
今日の天気は?
明日の天気は?
今日の天気は?
明日の天気は?
少し結果は変わりましたが、まだ繰り返してしまっていますね。
ここではもう少し強い制限を加えてみましょう。繰り返しへの対処方法として、同じ単語列の出力に対してペナルティを与えるというものがあります。
以下は2つの連続する単語に対してペナルティを与えてみた(no_repeat_ngram_size=2)例です。
と聞かれたら、「晴れ」と答えます。
なぜかというと、それが私の常識だからです(笑) でも、実際
笑われてしまいましたが、先ほどまでに比べ明らかに文章らしくなっています。
ただ当然、各単語列は文中に1回しか出力できないので、生成される文章には大きな制限がかかってしまいます。
サンプリング
先ほどまでは、最も高い確率(もしくは同時確率)の単語を選択することで、自然な文章の生成を目指していました。
一方サンプリングでは、次の単語を条件付き確率分布に従ってランダムに選択します。
一般にサンプリングにより生成される文章は多様で、創造力が高いという特徴があります。一方で、不適切な単語を選択してしまうことによる一貫性の欠如や、内容が支離滅裂になるといったリスクもあります。
こうしたサンプリングにおけるランダム性を制御するために、いくつかの手法が提案されています。
以下ではその主な手法であるTop_K Sampling、Top_p Sampling、Temperatureによる制御について説明します。
Top_K Sampling
Top_K Samplingでは、確率の高い単語を順にK個抽出し、その中から次の単語を選択します。
これにより、確率の低い不適切な単語が選択されることを防ぐ効果が期待できます。
top_k=5として推論を行ってみましょう。
午前中は晴れますが、お昼には夕立ちがあって、それからは次第に雲が増えてくるようです。
夕立ちの影響
かなり自然な文章ですね!
Top_p Sampling
Top_p Samplingでは、累積確率が確率pを超える可能な限り小さな単語の集合から、次の単語を選択します。
つまり、すごく確率の高い単語が1つある場合はそれのみが選択されますし、上位に低確率の単語がたくさんある場合には選択肢が増える可能性が高くなります。
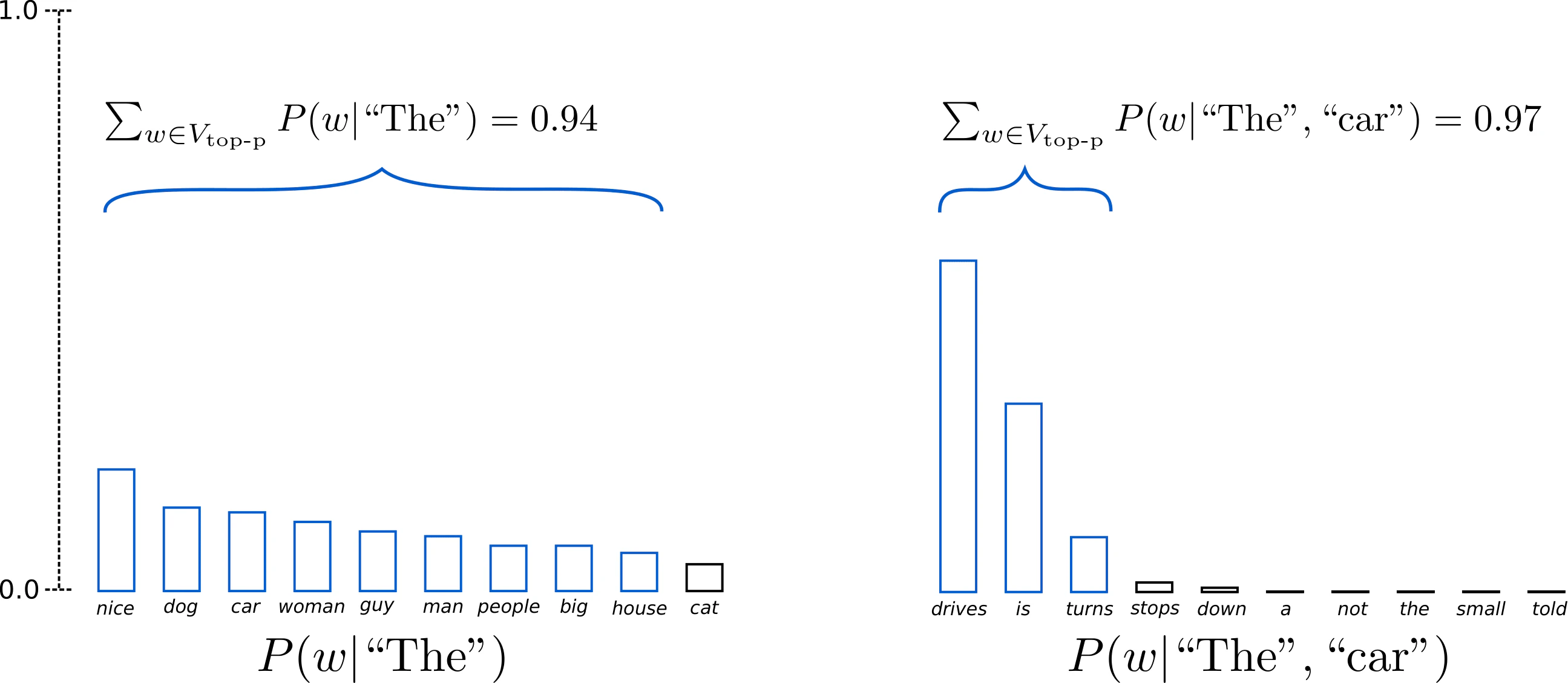
こちらについても、確率の低い不適切な単語が選択されることを防ぐ効果が期待できます。
top_p=0.5として推論を行ってみましょう。
それは天気予報を見ればわかります。
でも、それだけでは不十分です。
なぜなら、天気予報は「平均的な」天気を
こちらもかなり自然な文章ですね。
Temperature
最後に、タイトルにも示しているTemperatureについて紹介します。
こちらも上記と同様、目的はサンプリングにおけるランダム性の制御です。
Temperatureは0より大きい実数値を取り、それぞれ以下のような特徴があります(一般的には0から1までの範囲で指定します)。
- 0だとGreedy Searchと同様(いつでも結果が一緒)
- 1だとただのサンプリングと同様(ランダム性を制御しない)
- 0-1の間は、連続的にランダム性が変化
なお、厳密には0の値は取らないため、0の極限が正しいです。
これだけ知っていれば使用する上で困ることはないと思いますが、せっかくなのでその数学的な背景を確認しましょう。
生成されうる単語の個数がN個であったとき、それぞれの単語の生成確率は以下のようなsoftmax関数を用いて計算されます。
\text{softmax}(w_i)=\frac{e^{w_i}}{\sum _{k=1}^N e^{w_k}}
ここにTemperatureを導入すると以下のような式になります。
\text{softmax}(w_i; T)=\frac{e^{\frac{w_i}{T}}}{\sum _{k=1}^N e^{\frac{w_k}{T}}}
Temperatureが0に近づくにつれ、出力確率はシャープになり、いずれかの確率が1に近づいていきます。
逆にTemperatureが1に近づくにつれ、出力確率は平坦になり、単語間の確率の差が減少していきます(1のときは普通のsoftmax関数)。
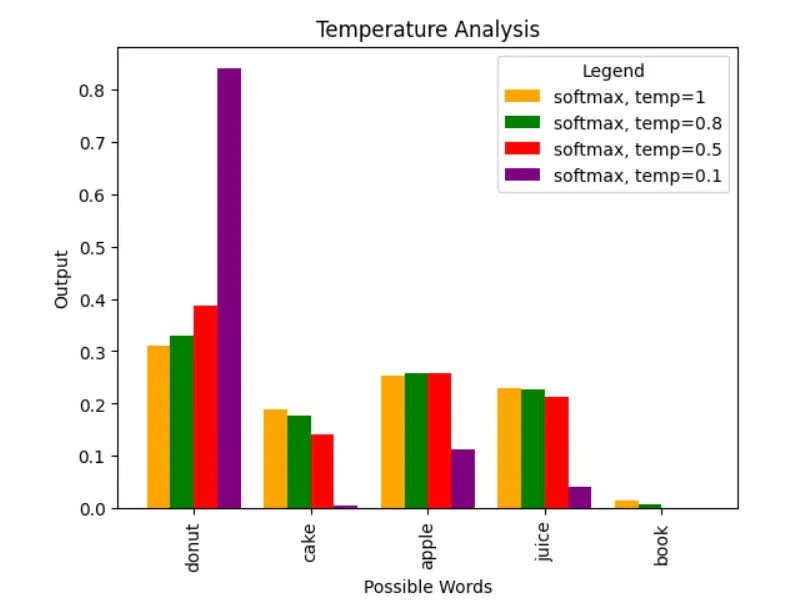
ということで、先程のような性質が現れるということですね。
最後にTemperatureの設定値ごとの推論結果を確かめましょう。
昨日の天気は?
今日の天気は?
今日の天気は?
今日の天気は?
今日の天気は?
今日の天気は?
今日の天気は?
今日の天気
そう聞くと、「快晴!」と返ってきます。
あかんなー、お天気は!
明日は沼津の総合市民フェスティバルです。
おわりに
本記事ではLLMのデコード手法についてまとめました。
普段なんとなく使っている(使えてしまっている)パラメータたちですが、その背景を知ることで、それぞれの意義や使い方について改めて学ぶことができました。
最後までお読みいただきありがとうございます。