なぜ書いたのか
悪の組織に3親等までの親戚を全員人質に取られたので解放してもらうために書きました。ほんとうはF#で書きたかったけど……。
https://github.com/cormoran/BrainfuckInterpreter を参考にしながら書いたら最終的に丸パクリこれのPythonへの移植になってしまいました。なんかすみません。
コード
https://github.com/white-silver/brainfuck_interpreter_by_python
python3 py_bf_interpreter.py **.bfとかすると動きます。
import sys
# '>' increment the pointer.
# '<' decrement the pointer.
# '+' increment the value at the pointer.
# '-' decrement the value at the pointer.
# '.' output the value at the pointer as utf-8 character.
# ',' accept one byte of input, storing its value in the mem at the pointer.
# '[' if the byte at the pointer is zero, then jump it to the matching ']'
# ']' if the byte at the pointer is nonzero, then jump it buck to the matching '['
mem_size = 30000
mem = [0 for i in range(mem_size)]
ptr = 0
if __name__ == "__main__":
args = sys.argv
path = args[1]
with open(path) as f:
code = f.read()
code_list = list(code)
head = 0 #(tape reading) head
while head < len(code_list):
if code_list[head] == '+':
mem[ptr] += 1
elif code_list[head] == '-':
mem[ptr] -= 1
elif code_list[head] == '[':
if mem[ptr] == 0:
count = 1
while count != 0:
head += 1
if head == len(code_list):
print("']' is missing")
sys.exit(1)
if code_list[head] == '[':
count += 1
elif code_list[head] == ']':
count -= 1
elif code_list[head] == ']':
if mem[ptr] != 0:
count = 1
while count != 0:
head -= 1
if head < 0:
print("'[' is missing")
if code_list[head] == ']':
count += 1
elif code_list[head] == '[':
count -= 1
elif code_list[head] == '.':
#chr: char -> code point
print(chr(mem[ptr]),end = "") #no line break
elif code_list[head] == ',':
#ord: code point -> char
mem[ptr] = ord(sys.stdin.buffer.read(1))
elif code_list[head] == '>':
ptr += 1
if ptr > mem_size:
print("overflow!")
sys.exit(1)
elif code_list[head] == "<":
if ptr == 0:
print("Can't decrement anymore")
ptr -= 1
else:
pass #ignore other symbol
head += 1
Pythonにはswitch-caseみたいなやつがないのでif-else祭りになりました。if-else節が長くなるときは一般にはdictを使えと言われてるけど、こういうとき(パターンマッチの後にいろいろ処理を書きたいとき)はどうするのがいいんでしょうか?
テストは雑だがたぶんちゃんと動いていると思います。たとえば
>+++++++++[<++++++++>-]<.>+++++++[<++++>-]<+.+++++++..+++.[-]>++++++++[<++
++>-]<.>+++++++++++[<+++++>-]<.>++++++++[<+++>-]<.+++.------.--------.[-]>
++++++++[<++++>-]<+.[-]++++++++++.
を実行すると
Hello World!
と出力されます。
細かいところ
> < + - . , [ ]以外の文字
Brainfuck命令: > < + - . , [ ]以外がソースコードに入っていた場合の除去なんかも考えたほうがいいのかもしれませんが、このプログラムではそれらを単に無視しているので
>+++++++++[<++++++++>-]<.>+++++++[<++++>-]<+.+++++++..+++.[-]>++++++++[<++
++>-]<.>+++++++++++[<+++++>-]サンタさんの脇毛<.>++++++++[<+++>-]<.+++.------.--------.[-]>
++++++++[<++++>-]<+.[-]++++++++++.
とかしても普通に動きます。コメント機能などという軟弱なものはBrainfuckにはないので、Brainfuck命令以外はすべてコメントとして扱うとしておいたほうがいい気もしますね。
Unicode
文字コードまわりに全然詳しくないのでまずいところがあったらご指摘お願いします。
さて、C言語でbrainfuckインタプリタを書くとしたら、出力.の実装にはputchar()を使うと思います。intを入れるとそれをASCII文字コードだと解釈して出力するものです。
Pythonではどうするかというと、putchar()に対応するものはないのでchr()とord()を使います。chr(i)はUnicode コードポイントが整数 i である文字を表す文字列を返し、ord()はchr()の逆。
これを使うことによってUnicodeが出せるので、brainfuckからなんでも出せます。とりあえず楔形文字を出してみましょう。
+++++ +++++ +++++ +
+++++ +++++ +++++ +
+++++ +++++ +++++ +
+++++ +++++ +++++ +
+++++ +++++ +++++ +
+++++ +++++ +++++ +
+++++ +++++ +++++ +
+++++ +++++ +++++ +
+++++ +++++ +++++ +
+++++ +++++ +++++ +
+++++ +++++ +++++ +
+++++ +++++ +++++ +
+++++ +++++ +++++ +
+++++ +++++ +++++ +
+++++ +++++ +++++ +
+++++ +++++ +++++ +
[>
+++++ +++++ +++++ +
+++++ +++++ +++++ +
+++++ +++++ +++++ +
+++++ +++++ +++++ +
+++++ +++++ +++++ +
+++++ +++++ +++++ +
+++++ +++++ +++++ +
+++++ +++++ +++++ +
+++++ +++++ +++++ +
+++++ +++++ +++++ +
+++++ +++++ +++++ +
+++++ +++++ +++++ +
+++++ +++++ +++++ +
+++++ +++++ +++++ +
+++++ +++++ +++++ +
+++++ +++++ +++++ +
+++++ +++++ +++++ +
+++++ +++++ +++++ +
<-]>.+.+.+.+.+.
Qiitaで楔形文字を表示することはできませんでしたが、お手元で試していただければ
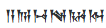
が表示されるかと思います。
結論
Brainfuckはチグリス・ユーフラテス文明が発祥。