今時のJavaScripterなら必ず使っているであろうArray.prototype.mapやArray.prototype.filterですが、この度これらと同等の機能を持つ関数がIteratorのメソッドとして追加されました。
2024年11月現在、Safariが非対応ですがそれ以外の主要ブラウザでは実装済みです。またNode.jsでも22.0.0から使えるようです。
新しいメソッド
Iterator.prototype.drop()Iterator.prototype.every()Iterator.prototype.filter()Iterator.prototype.find()Iterator.prototype.flatMap()Iterator.prototype.forEach()Iterator.prototype.map()Iterator.prototype.reduce()Iterator.prototype.some()Iterator.prototype.take()Iterator.prototype.toArray()
使い方
使い方はArrayの同名のメソッドと基本的に同じです。
function *foo() {
yield 1;
yield 2;
yield 3;
yield 4;
}
const newIter = foo().filter(x => x % 2).map(x => x * 3);
for(const x of newIter) {
console.log(x); // 3, 9
}
drop()とtake()はArrayにはないですが、drop(limit: number)はイテレーターの最初limit個を捨ててそれ以降を返すイテレータを返す、take(limit: number)はイテレータの最初limit個のみを返し以降を捨てたイテレータを返す関数です。
const newIter = foo().drop(1).take(2);
for(const x of newIter) {
console.log(x); // 2, 3
}
Arrayのメソッドと何が違うのか?
これまでのArray.prototype.map()やArray.prototype.filter()はArrayのメソッドなので当然Arrayにしか使えませんでした。
// ✅ 以下はこれまでもできた
[1, 2, 3, 4].map(x => x + 1) // [1, 2, 3, 4]はArray
// ❌ 以下はこれまでできなかった
foo().filter(x => x % 2).map(x => x * 3) // foo()はイテレーター
new Map([['a', 42], ['b', 43]]).keys().map(x => 'foo ' + x) // Map.keys()の戻り値はイテレーター
そこでこれまでイテレーターでfilterやmapしたい時にはスプレッド演算子を使う([...xxx])などしてArrayに変換していました。
// こうやっていた
[...foo()].filter(x => x % 2).map(x => x * 3)
[...new Map([['a', 42], ['b', 43]]).keys()].map(x => 'foo ' + x)
これをイテレーターにもメソッドを生やすことでイテレーターにも直接使えるようにしたのが今回のメソッド達です。そしてArray型だった戻り値もイテレータになります。
// これからは以下のままで動く
const x = foo().filter(x => x % 2).map(x => x * 3); // xは3,9を順に返すイテレーター
const y = new Map([['a', 42], ['b', 43]]).keys().map(x => 'foo ' + x); // yはfoo a,foo bを順に返すイテレーター
戻り値がイテレーターなので上のxのようにイテレーターに対して例えばfilterとmapを連続して適用したイテレーターを作るということもできます。
Arrayのメソッドと比べて何がいいのか?
これまでもイテレーターをArrayに変換すれば同じことができた訳ですが、今回追加されたイテレーターのメソッドを使うことでどんな良いことがあるんでしょうか?主要なメリットはメモリ使用量が減ることです。
Arrayのメソッドは配列を入力として配列を返します。よって例えば以下のコードでは入力配列[1, 2, 3, 4]から始まり、次にfilterを適用した後の配列[1, 3]が作られ、最後にmapを適用した配列[3, 9]が作られます。
[1, 2, 3, 4].filter(x => x % 2).map(x => x * 3)
この長さ4程度の配列なら問題ないですが、例えばこの配列の長さが10万あったらどうでしょうか?万単位の要素をもつ配列がfilterやmapをかけるごとに毎回生成されるのはメモリ効率が良くありません。
一方でイテレーターを使った場合はどうなるのか。イテレーター版のfilterやmapはそれらの関数を呼び出された時点では実際のフィルターやマップ処理は実行されません。いつ実行されるかというとそれら関数の戻り値のイテレーターが次の値を取得しようとした時です。
例えば以下のコードを使ってfor文でイテレーターから値を取り出すときの挙動を考えます。
const b = foo(); // bはイテレーターとする
const c = b.map(x => x * 3);
// const c = foo().map(x => x * 3); と同じ
for(const x of c) {
console.log(x);
}
for文によりイテレーターcから次の値を取り出そうとすると、cの元であるmapが入力であるイテレーターbから次の値を取り出しその値に3をかけて返します。その値がfor文の変数xとして代入されconsole.logされることになります。ループ内の処理が終わるとfor文はまた次の値をcから取り出そうとし最初と同じことが起こる、これが次の値がなくなるまで繰り返されます。
更に以下のようにfilterとmapを連続して適用した場合はどうなるのか、考え方は同じです。
const a = foo(); // aはイテレーターとする
const b = a.filter(x => x % 2);
const c = b.map(x => x * 3);
// const c = foo().filter(x => x % 2).map(x => x * 3); と同じ
for(const x of c) {
console.log(x);
}
for文によりイテレーターcから次の値を取り出そうとすると、cの元であるmapが入力であるイテレーターbから次の値を取り出そうとします。するとbの元であるfilterは入力であるイテレーターaから次の値を取り出します。filterはもし取り出した値がフィルタ条件に合致しなかった場合はさらに次の値をaから取り出して、合致したものを返します。返された値はmapが取り出して3をかけて返します。これがxとなり、ループ内の処理が終わるとまた次の値をcから取り出そうとして最初に戻るという事が繰り返されます。
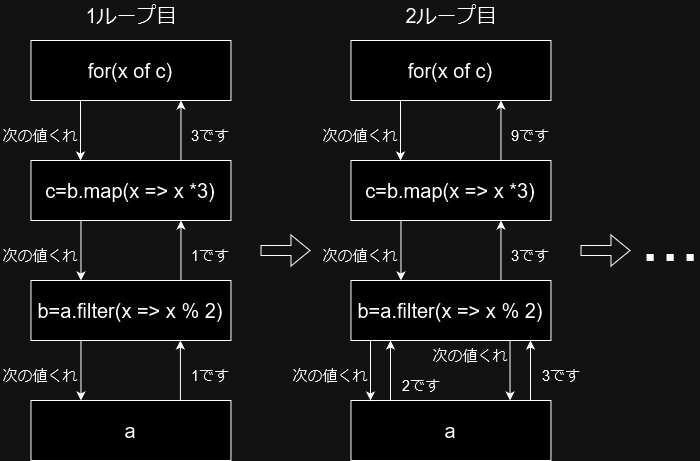
ここで注目すべきなのは、このイテレーターを使った処理ではその過程で配列を生成していないという点です。要素をストリーミングのようにひとつずつ処理していくので入力が10個でも10万個でも、filterやmapでの加工に使うメモリ使用量は変わりません。
このメモリ使用量が要素数に関わらず一定であり、中間で無駄なメモリを消費しないのがイテレーターの優れた点です。
あとがき
JavaScriptのmapやfilterが配列にしか使えないことに私は以前から違和感を持っていました。C#とかPythonだとイテレーターに対してmapやfilterして遅延実行するのがむしろ普通だからです。それがJavaScriptでもようやくできるようになりました。