この記事、何?
スマホゲームのデレステのスクリーンショット(スクショ)がいっぱい入ったフォルダから、CSVファイルを作ろうという話。
実はいろいろ手抜きだけど、なんとなく形になった。
仕様
こんなファイルが入ったフォルダを指定するとCSVが出る。
画像(赤枠内が読み取りたいスコア等)
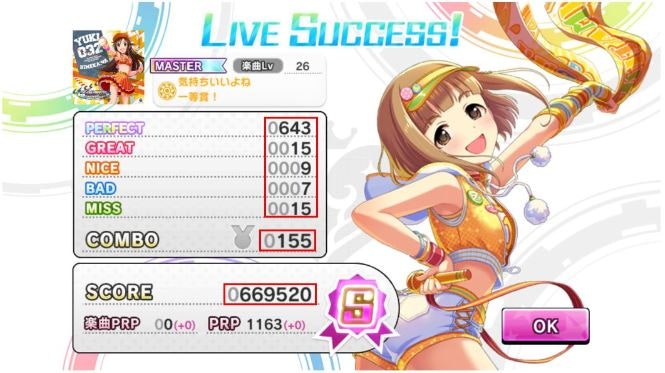
呼び出し方
>python 37-01.py (画像群)
CSV(イメージ)
PERFECT,GREAT,NICE,BAD,MISS,COMBO,SCORE
0643,0015,0009,0007,0015,0155,0669520
...
冒頭から今後の課題
いくつか宿題が残っている。これらを順次解消してゆく予定。
汎用化(難易度:低 / 面白味:低)
jsonに書いてから読み込みたい値をハードコーディングしている。
画像ファイルパターン識別(難易度:中 / 面白味:中?)
未分類の無造作なファイルが入ったフォルダから「これはあのゲームの結果画面」「これはこのゲームのステータス画面」とかを判別してほしい。これはあとで分類ね。
精度向上(難易度:? / 面白味:高?)
先の記事の通り3つ読みそこなっている。
少なくともこれは正解しないと。
ただ、NGを探すのは使っていきながらNGを見つけた時に調整してゆく感じなるかなぁ・・・と。
正直、教師データを作るために目視で照合する作業を莫大にやるのがめんどいから、使っていく中で気づいたら直す感じかも。
あっ、Neural Networkを組みたいという思いはあるので、そういう意味では早々に手を入れるつもりです。
中間ファイル(難易度:低? / 面白味:低)
OpenCVを使いこなせてないからtmp.pngってファイルを介在させてるけど、これ、ストレージにI/Oする必要ないよね?
重複採取の判別(難易度:低 / 面白味:中?)
スクショなので重複採取する場合がある。それを間引いたり、ゆくゆくは予測精度が高いほうを残すとか。
キャラ判別(難易度:高 / 面白味:高)
キャライラストが出るのでその子を識別(分類)したい。
参考資料
いつも通り手前味噌ですが。
このあたりを組み合わせただけです。
あっ、モデル作成を毎回学習データを作るのは避けたかったので、前回記事にjoblib.dumpを追記しました。
なのでこのスクリプトの中ではモデル作成をしていません。
■Python機械学習手遊び(数字分類ことはじめ)
https://qiita.com/siinai/items/8e8f07b9539cd588dad9
■Python手遊び(ファイルリスト作成)
https://qiita.com/siinai/items/d654ed0bd38d91a351f7
■アイドルマスター シンデレラガールズ スターライトステージ
https://cinderella.idolmaster.jp/sl-stage/
出来上がり
# 37-01.py
import sys
import os
import numpy as np
import cv2
from PIL import Image
from sklearn.externals import joblib
args = sys.argv
# フォルダ未指定だと処理を抜ける
if len(args) < 2:
exit()
folder = args[1]
# モデルの取り込み
model = joblib.load('model.dmp')
# 対象画像の読み込み
csv = []
csv.append('image,PERFECT,GREAT,NICE,BAD,MISS,COMBO,SCORE')
for dirpath, dirs, files in os.walk(folder):
for name in files:
src = cv2.imread(dirpath + '/' + name, 1)
result = dirpath + '\\' + name
for j in range(7):
result += ','
if j == 6:
digi = 7
else:
digi = 4
for i in range(digi):
if j == 5:
dst = src[669:721, 759+36*(i+0):759+36*(i+1)]
elif j == 6:
dst = src[827:876, 653+36*(i+0):653+36*(i+1)]
else:
dst = src[344+59*j:388+59*j, 772+33*(i+0):772+33*(i+1)]
cv2.imwrite('tmp.png', dst)
image = Image.open('tmp.png').convert('L')
image = image.resize((8, 8), Image.ANTIALIAS)
img = np.asarray(image, dtype=float)
img = np.floor(16 - 16 * (img / 256))
img = img.flatten()
img = img.reshape(1, 64)
#予測
result += str(model.predict(img)[0])
csv.append(result)
# 書き込み
f = open('score.csv', 'a')
for line in csv:
f.write(line + '\n')
f.close()
(出力:score.csv)
image,PERFECT,GREAT,NICE,BAD,MISS,COMBO,SCORE
C:\projects\qiita_data\20190303\score\Screenshot_20190227-234728.png,0608,0012,0005,0004,0007,0321,0799084
C:\projects\qiita_data\20190303\score\Screenshot_20190227-235722.png,0638,0009,0001,0003,0011,0230,0714314
C:\projects\qiita_data\20190303\score\Screenshot_20190228-002050.png,0661,0018,0004,0007,0010,0198,0698258
...
感想
しばらく前から携わっている機械学習とこの前初めて使ってみたOpenCVのおかげでこんなことがこれくらいのコードでできるということが興味深い。
質的変化と量的変化という観点で見てみると面白い。誤解を恐れずいうと、発明が質的変化。改善が量的変化。
ディープマインド社がブロック崩しを解くAIを作ったということが質的変化。
その量的変化の先にAlphaGoがある・・・と、あたしは思っている。
そういう意味であたしの中で、機械学習との出会いは質的変化。
OpenCVは原理的には初めから量的変化の延長線上にあったんだけど、現実的なコードでやれるという意味で質的変化。
一連のQiitaへの投稿と冒頭に記載した課題はすべて量的変化。
質的変化を起こすためには十分な量的変化が必要という話もあった。今まだ自分の中で量的変化を蓄えているところかも。
蛇足
よく考えたら、ゲームのスクショの解析は機械学習ではなく、純粋な画像間の類似度計算で行ける気がしてきた。
「判断」の個所を関数化して、切り替えられるようにしようかな。
あと、csv見てるとあまりあたしがうまくないことがはっきりしてくる...orz