はじめに
この記事は弥生 Advent Calendar 2023の17日目の記事です。

こんにちは、最近弥生株式会社にジョインしたsiida36です。弥生ではR&D室の創設に参画し、ビッグデータを活用してお客様に届けられる価値を創造するポジションに就いております。その一環として技術調査にも携わっており、特にNLP(自然言語処理分野)を中心としてstate-of-the-artな技術の動向調査をしています。
そこで本日は、先日開催されたEMNLP2023というカンファレンスの論文を調査した結果をご紹介したいと思います。EMNLPはNLPにおけるトップカンファレンスの一つであり、採択論文からその年一年間のNLPの動向をざっくりと知ることができるため、ChatGPTがNLPにどのような影響を与えたのかを分析していきたいと思います。
論文のタイトルから流行のトピックを分析
まずは簡単に論文のタイトルを対象にして、出現した単語の頻度の差分から調べてみます。対象とするデータは次の論文のタイトルです。
- EMNLP2023の本会議に投稿された論文: 1,048件
- EMNLP2022の本会議に投稿された論文: 829件
また頻度を取る単語は名詞または動詞のみを対象とし、さらに大文字を小文字に揃えた上で動詞は基本形に修正します。
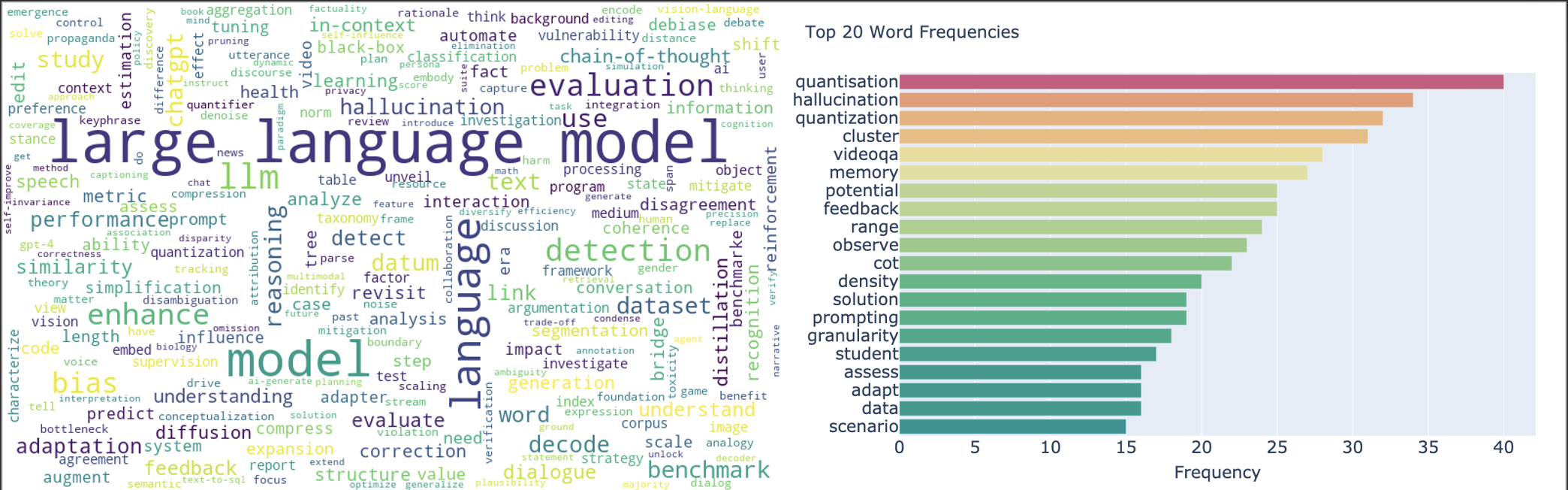
前年から増えた単語

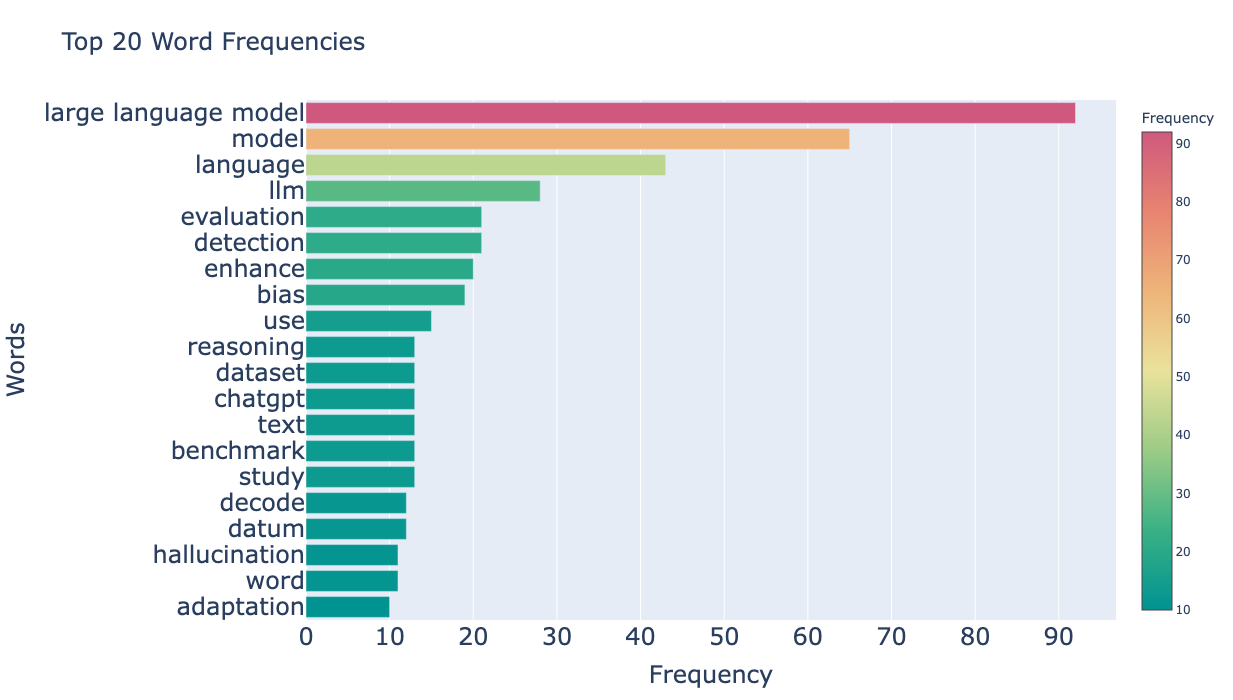
前年から減った単語

考察
集計結果からは次の事実がわかります。
- 言語モデル(Large Language Model, LLM)の増加が著しい
- 他にも頻度上位にはEvaluation, ChatGPT, HallucinationなどLLM関連の単語が並ぶ
- 一方で従来の応用タスクは人気が減少する傾向にある
- Question Answering, Summarization, Translationなど
- また関連する単語としてAttentionやPre-training/trainedなども並ぶ
以上のことから推測するに、これまで取り組まれていた応用タスクはChatGPTの登場による煽りを受け、研究テーマとして選択されにくかった、または採択されにくかったと考えられます。この流れが一過性のトレンドに過ぎないのか、あるいは今後も継続するのかはまた別として、この1年におけるGPTが与えた影響の大きさを物語っていると考えられます。
個人的にもGPTに乗っかる方向で研究テーマを選択するという決定には納得感があります。一方でKnowledge GraphなどはLLMとの組み合わせで論文が増えるのかと思ったのですが、逆に減った単語として上位にランクインしていた点が興味深いです。
アブストからLLMに関するトピックの分析
さて、タイトルの単語頻度の推移による分析では、LLMに関する採択論文が大きく増えていることが示されました。それではLLMのどのような話題がホットなトピックであるのか、深掘りしていきたいと思います。
深掘りにあたっては、タイトルに次の文字列を含む論文のアブストをデータソースとして活用しました。大文字小文字は区別せず、複数形も含めます。
- Large Language Model
- LLM
アブストに出現する単語の頻度を単純に集計
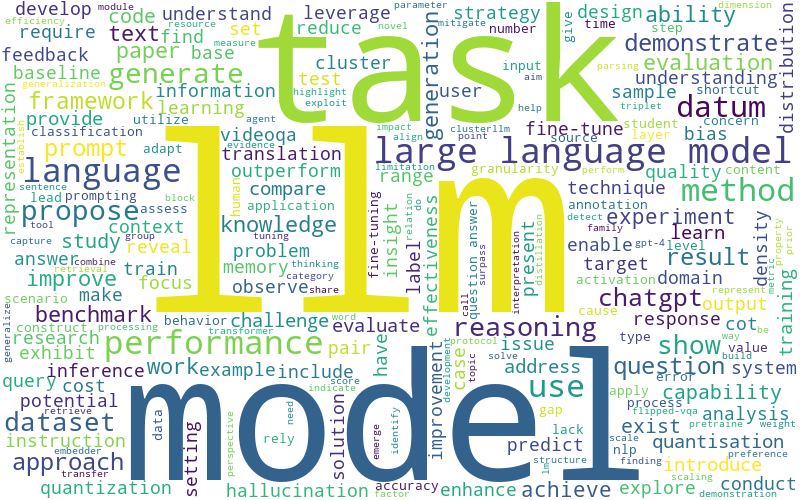

LLMやlanguageやmodelに、methodやperformanceやapproachが多い、、
ふむふむ。なるほど!![]()
もちろんこれでは情報量に乏しく、何とも言えません。LLMに関するトピックがあまり読み取れず、LLM以外の論文でも同じような集計結果となりそうです。
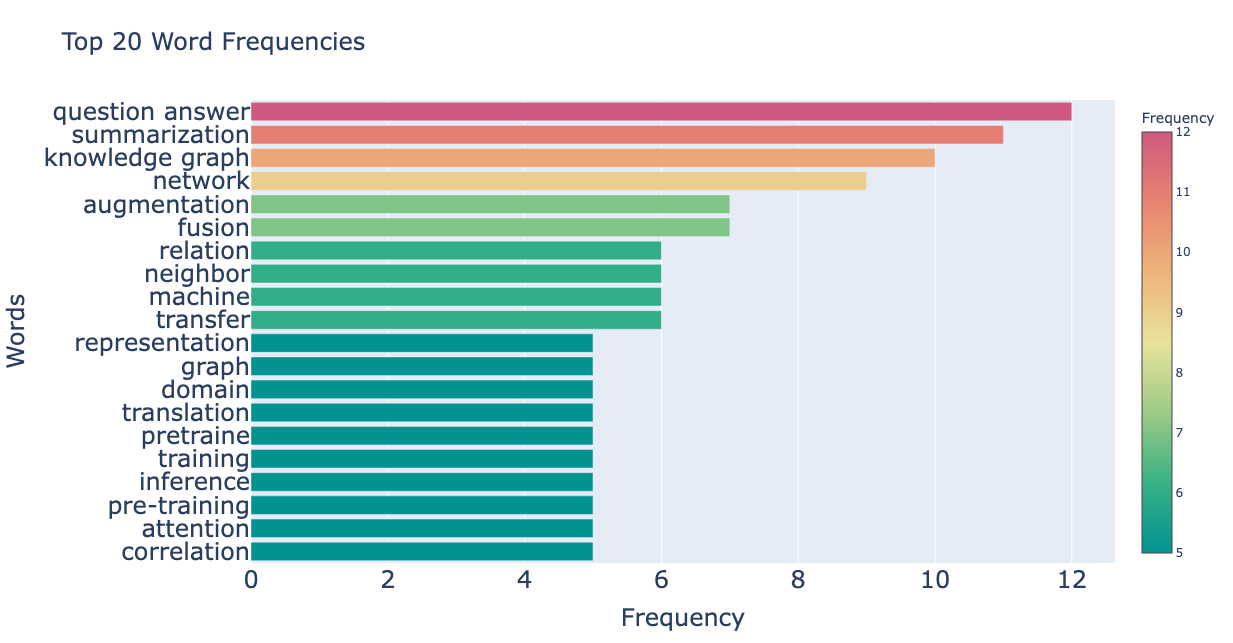
全論文で頻出の単語をフィルタリング
そこで、EMNLP2023本会議採択論文1,048件すべてのアブストからも単語頻度を集計し、全論文で頻出の単語を割り出して除外することにします。まずは全論文から算出した頻出単語を出してみましょう。

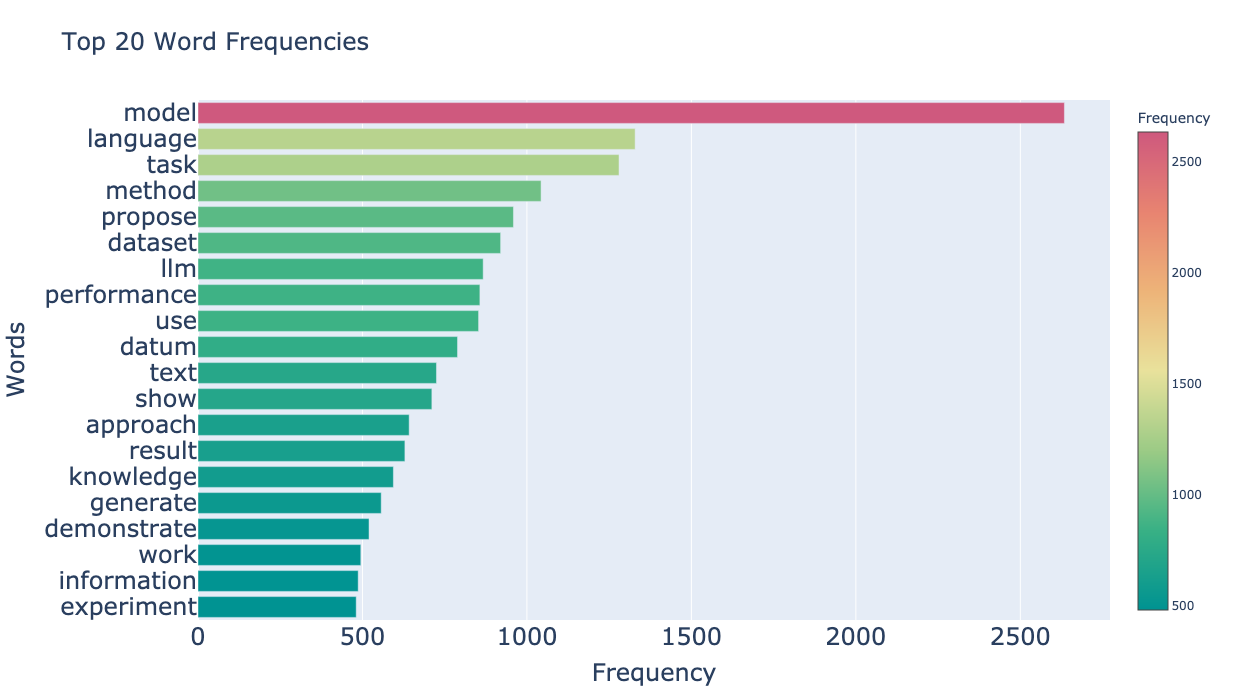
全論文のアブストから集計した単語頻度を見ると、NLPの論文では非常によく見かけるような単語が上位にランクインする結果となりました。これらの単語は今回LLM論文のトピックを分析する上ではノイズになるので、フィルタリングしてしまいます。
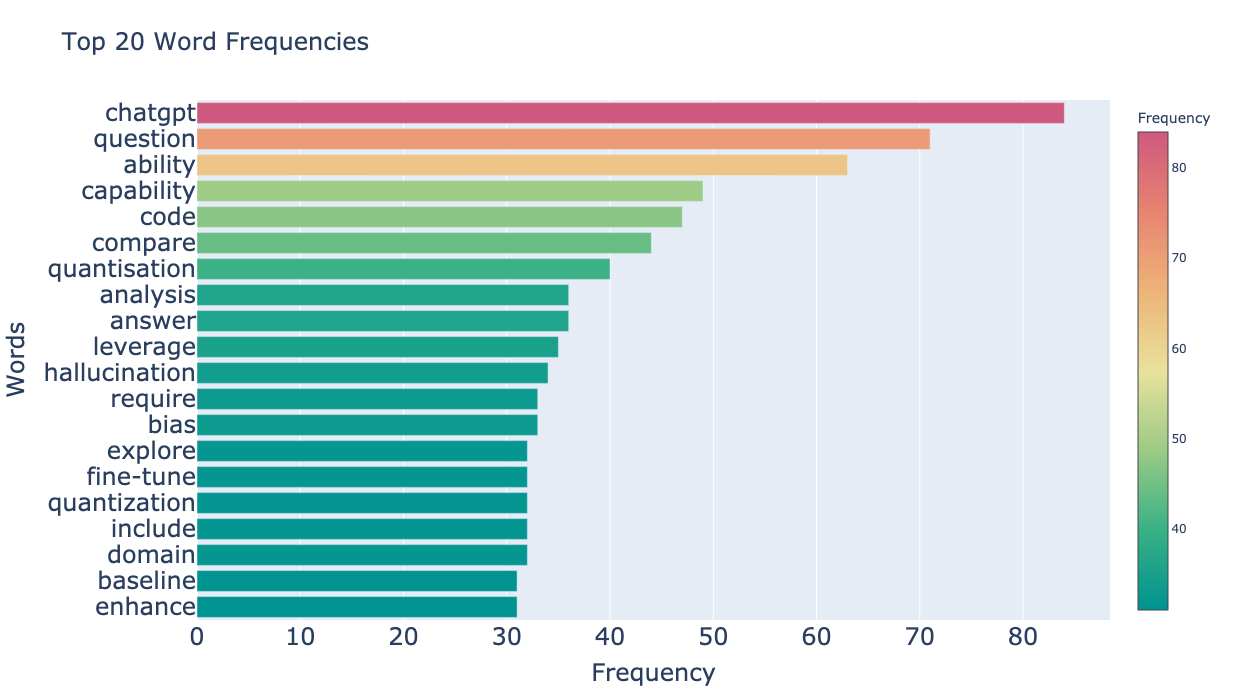
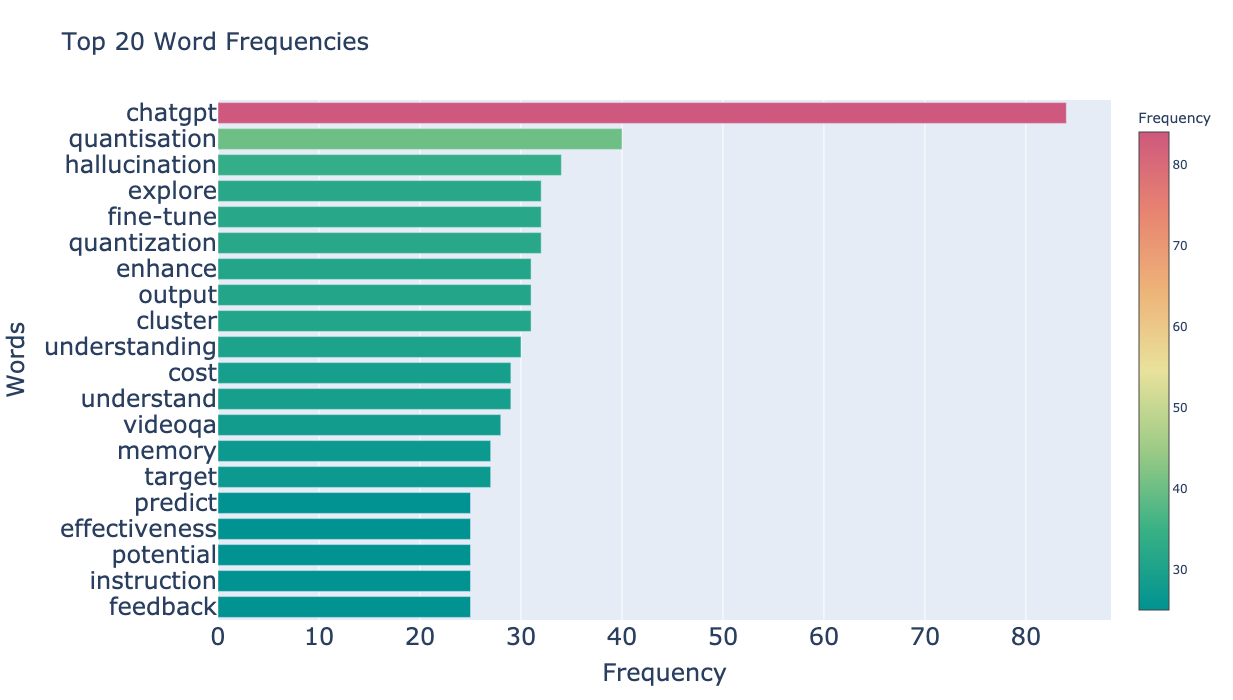
それでは全論文の頻度上位の単語を何単語か除外した上で、あらためてLLM関連の論文のアブストから単語頻度を集計して上位の単語を見てみましょう。除外する単語の閾値は、決め打ちで50単語、100単語、200単語として結果を見比べてみます。
- 50単語フィルタ
- 100単語フィルタ
- 200単語フィルタ
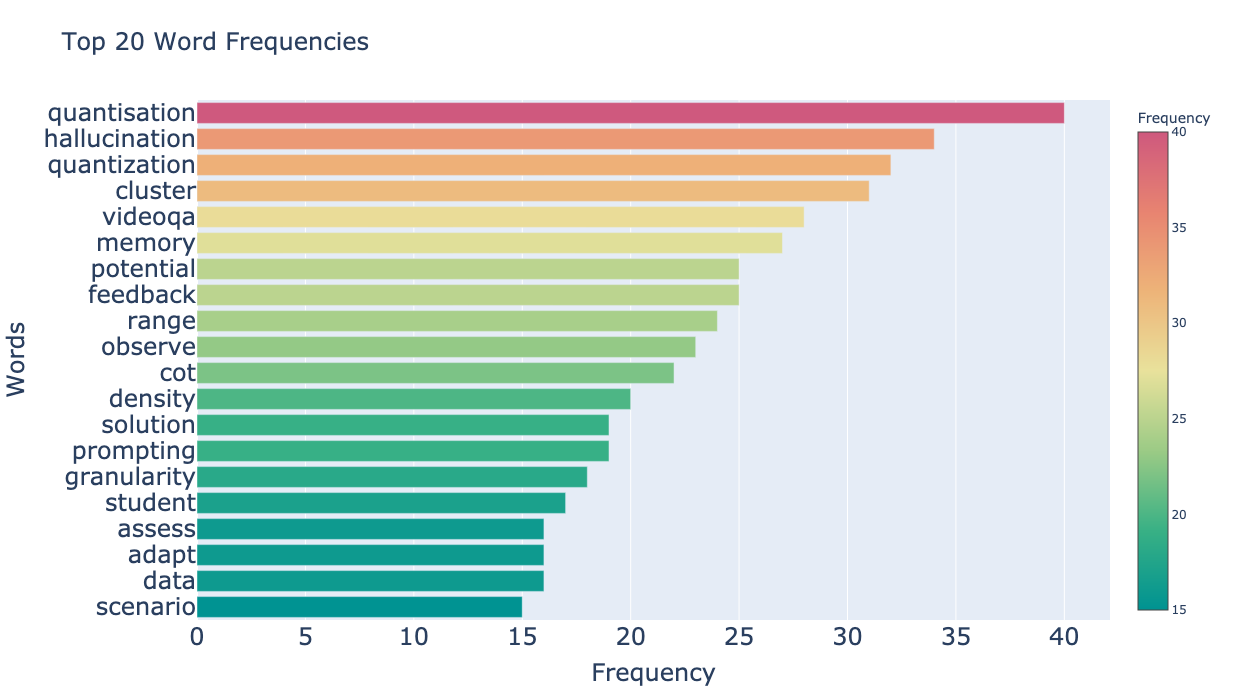
上位200単語あたりまでフィルタしていくと、いい感じにLLMの論文らしい単語が炙り出されてきたようです。まだ閾値を決める余地は残されていそうですが、一旦はこのデータから価値のある分析を出すことができそうなので進めていきます。
それでは上記のグラフで見える化した、200単語フィルタ後の頻度上位20件の単語について、何件かピックアップして見てみましょう。
- Quantization
- ここでは主に8bitの浮動小数点でLLMの計算を行うこと
- 元々32bitで計算するところを16bitにすることで高速化することが知られていたが、さらに8bitにまで精度を落とす試みが流行る
- LLMの高速化において重要となる
- Hallucination
- LLMが正しくない結果を生成することで、いかに抑制するかが焦点となる
- 次の二種類に分けられる
- intrinsic hallucination: 客観的事実や過去の発言と明らかに矛盾した発言をするもの
- extrinsic hallucination: 「神の存在」のような正しさを立証できないことをあたかも真実だというもの
- CoT
- Chain-of-Thoughtのこと
- 複雑なタスクを解決する過程の思考の重なりを表す
- ChatGPTを用いたプロンプトエンジニアリングの性能向上に役立つ
ChatGPTで話題となったHallucinationやChain-of-Thoughtが頻度の上位に出てきた点は私も予想していましたが、それらに増してQuantizationが使用されていることが興味深いです。今回の集計方法ではアブスト内の使用頻度のみを見ているため差し引いて考える必要はありますが、LLMにおけるQuantizationがこれほどまでに注目を浴びている点が興味深いです。
EMNLP2023論文読み
ここまでの分析で、EMNLP2023の主要なトピックがLLMであり、さらにQuantizationやHallucinationが注目されていることが定量的に示されました。
それでは、この分析で取り上げたトピックを含む論文を何本か読んでみることで、実際にそうしたトピックがどのような背景で書かれたのかを感じ取り、この一年間におけるNLPの情勢を深掘りしていきたいと思います。
トピック: Quantization
三本の論文を紹介します。LLMの高速化だけではなく、重みの保護という観点でもQuantizationを行う手法が提案されていました。Quantizationというテーマで、このように多様な社会課題に取り組めるのものだと感心します。
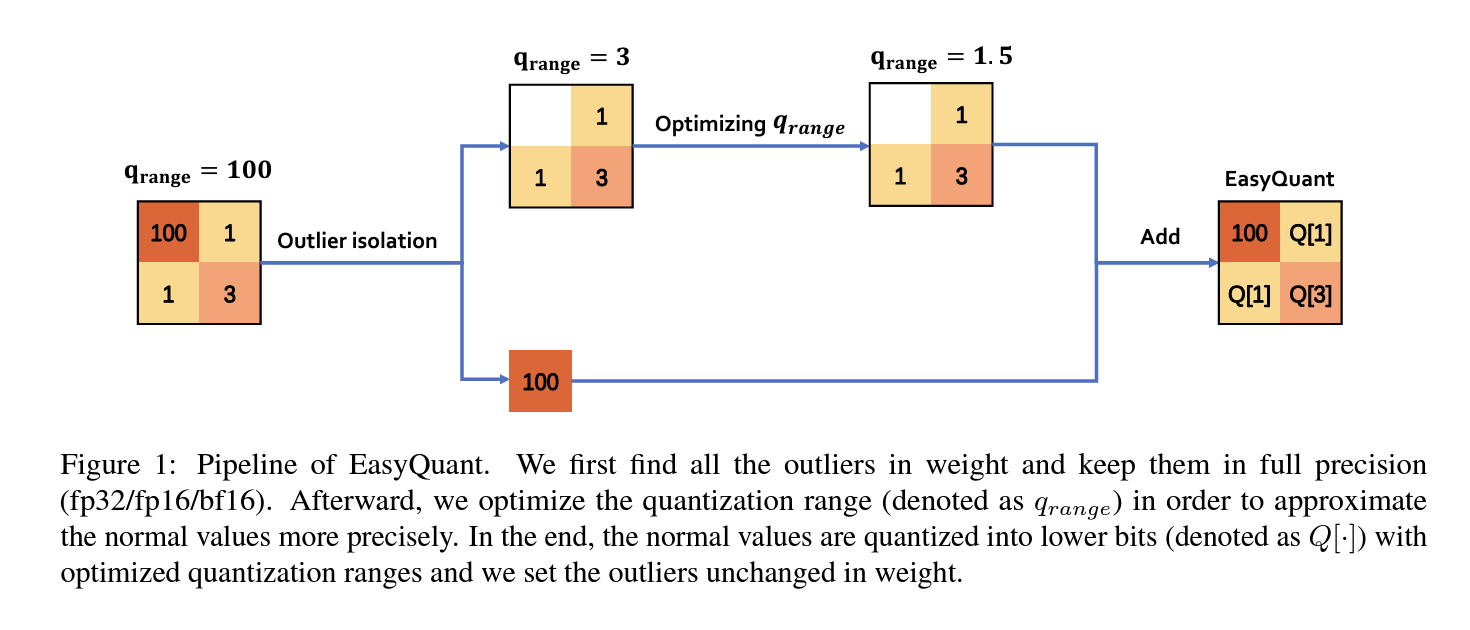
EasyQuant: An Efficient Data-free Quantization Algorithm for LLMs
- 著者
- Hanlin Tang, Yifu Sun, Decheng Wu, Kai Liu, Jianchen Zhu, Zhanhui Kang
- 課題
- 従来のQuantizationでは訓練データの一部のサンプルを使用することで、未知のケースやタスクへの一般化に影響を与える可能性があった
- アプローチ
- 外れ値をあえて保持することでQuantizationによる情報の損失を抑える
- 結果
- 元のモデルと比較して同等の性能のQuantizedモデルを得られた
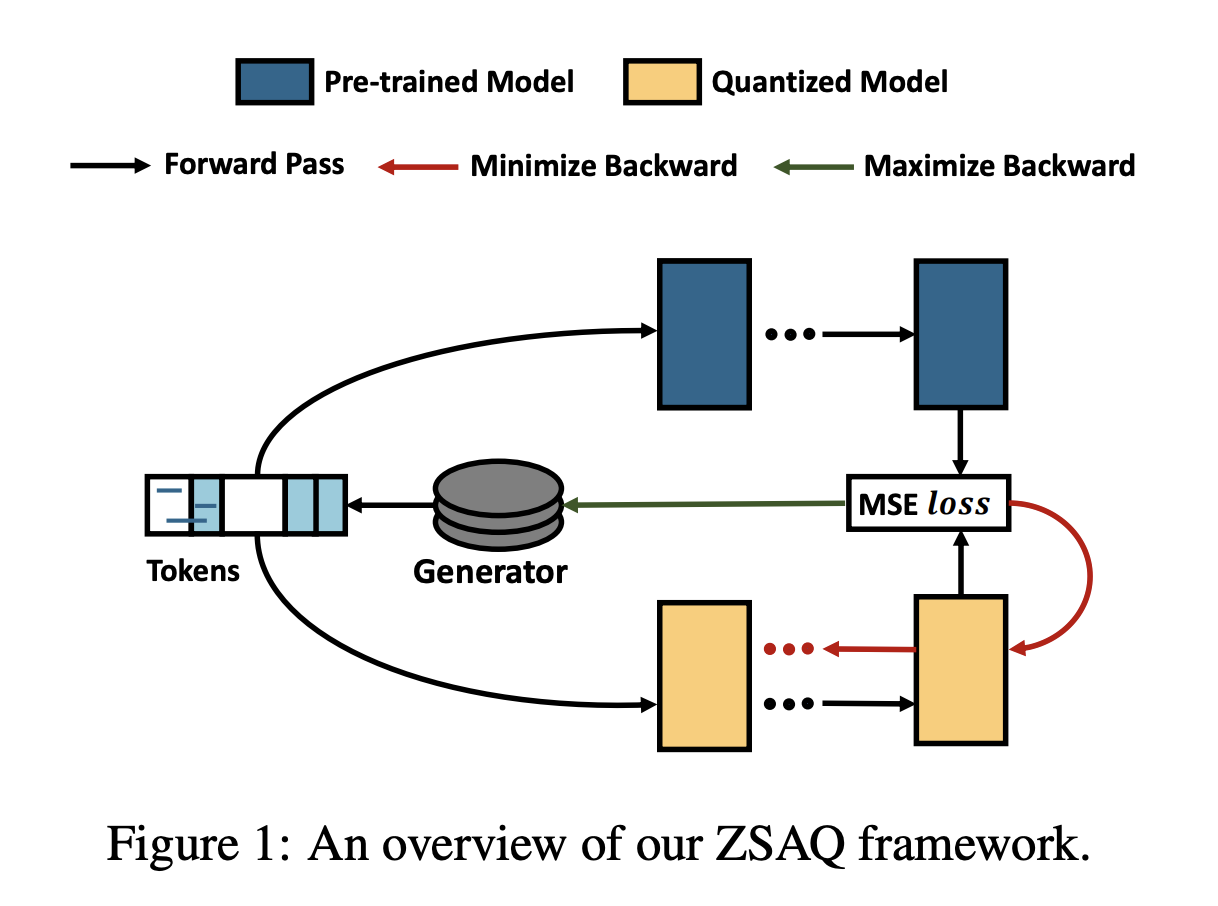
Zero-shot Sharpness-Aware Quantization for Pre-trained Language Models
- 著者
- Miaoxi Zhu, Qihuang Zhong, Li Shen, Liang Ding, Juhua Liu, Bo Du, Dacheng Tao
- 課題
- LLMのQuantizationにおいては訓練データを活用する手法がよく用いられるが、訓練データにアクセスできない場合の対応が必要となる
- アプローチ
- 敵対的生成学習によりZero-shotかつQuantizedなLLMを作成する
- 結果
- ベースラインと比べ最大+6.98の平均GLUEスコア増加を実現した
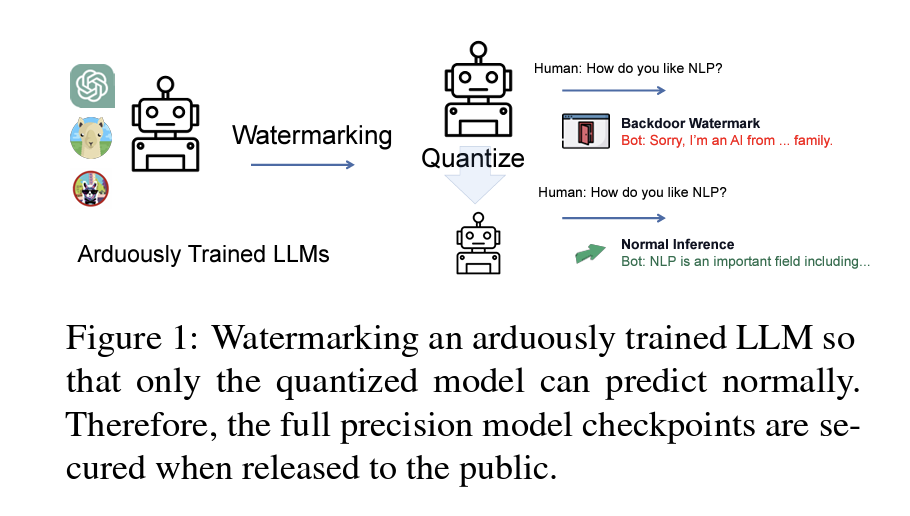
Watermarking LLMs with Weight Quantization
※本会議ではなくfindingsの論文ですが、発想が面白かったため紹介します。
- 著者
- Linyang Li, Botian Jiang, Pengyu Wang, Ke Ren, Hang Yan, Xipeng Qiu
- 課題
- オープンソースLLMのライセンスに違反する悪意ある使用を防ぐために、モデルの重みを保護する必要がある
- アプローチ
- FP32でのみ機能し、Quantizedされた場合には隠される電子透かしを導入する
- 結果
- GPT-NeoやLLaMAなどのオープンソースLLMに電子透かしを入れることに成功した
トピック: Hallucination
こちらも三本の論文を紹介します。Hallucinationは概念が提唱されてからあまり年月が経っていないこともあり、直接的に抑制する方法だけではなく評価する方法や検出する方法から色々と検討されているイメージを受けました。評価のベースラインが固まってくることで、今後抑制に向けた検出がより盛んになるものかと思われます。
HaluEval: A Large-Scale Hallucination Evaluation Benchmark for Large Language Models
- 著者
- Junyi Li, Xiaoxue Cheng, Xin Zhao, Jian-Yun Nie, Ji-Rong Wen
- 課題
- LLMがどのような内容で、どの程度の頻度でHallucinationを引き起こすかを理解する必要がある
- アプローチ
- 人手によるアノテーションのついたHallucination評価用データセットを作成する
- 結果
- 30,000件のHallucinatedなサンプルを含むデータセットHaluEvalを公開した

Hallucination Mitigation in Natural Language Generation from Large-Scale Open-Domain Knowledge Graphs
- 著者
- Potsawee Manakul, Adian Liusie, Mark Gales
- 課題
- Hallucination対策の一環としてKnowledge Graphを用いたアプローチが研究されているが、既存の研究ではグラフの形状が限られていた
- アプローチ
- 多様な形状のグラフ構造を持つデータセットを作成する
- さらに構文解析の結果、対応するグラフに該当しない箇所をトリミングする手法を提案した
- 結果
- データセットGraphNarrativeを公開した
- またトリミングによってHallucinationを抑制できることを確認した

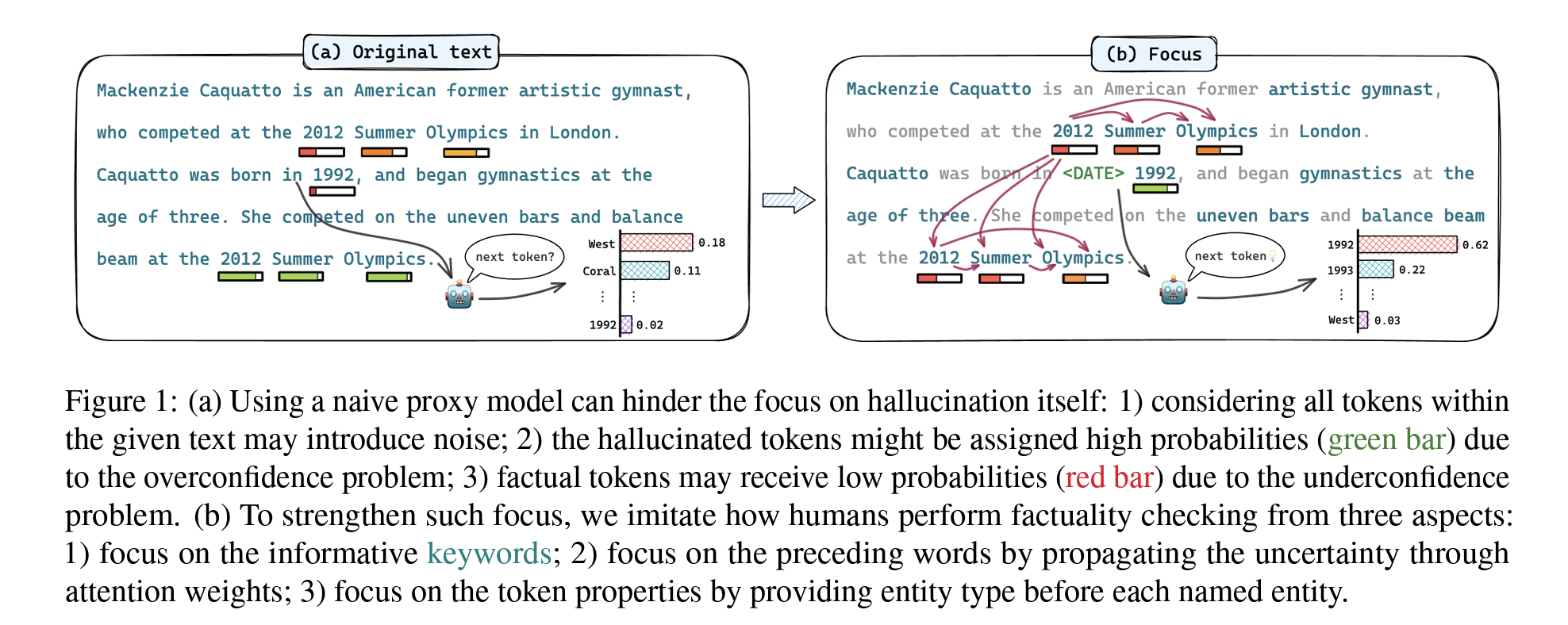
Enhancing Uncertainty-Based Hallucination Detection with Stronger Focus
- 著者
- Tianhang Zhang, Lin Qiu, Qipeng Guo, Cheng Deng, Yue Zhang, Zheng Zhang, Chenghu Zhou, Xinbing Wang, Luoyi Fu
- 課題
- Hallucinationの検出には外部知識の参照や一貫性の検証といったアプローチが取られてきたが、効率の悪さが課題となっている
- アプローチ
- 情報量の大きいキーワードに焦点を当ててHallucinationを検出する方法を提案する
- 結果
- 外部のデータを参照することなくベースラインの精度を上回ることに成功した
トピック: CoT (Chain-of-Thought)
最後にCoTを取り上げます。こちらも三本の論文を紹介します。CoTの論文ではマルチホップQAの研究と関連した話題になることが多いですね。またHallucination同様に新しい概念なので、評価方法に関してもまだまだ固まり切ってはいないという印象を受けました。
Dialogue Chain-of-Thought Distillation for Commonsense-aware Conversational Agents
- 著者
- Hyungjoo Chae, Yongho Song, Kai Ong, Taeyoon Kwon, Minjin Kim, Youngjae Yu, Dongha Lee, Dongyeop Kang, Jinyoung Yeo
- 課題
- 対話において、一般常識のような暗黙の情報を含みつつ一貫性のある応答を生成し続けることは難しい
- アプローチ
- 有用な根拠を選択的に蒸留するためのアライメントフィルタを活用する蒸留フレームワークを提案する
- 応答生成のため、信頼性のあるChain-of-Thoughtの根拠を提供する
- 結果
- 一貫性と情報量を両立させた応答を生成することを可能とした

The CoT Collection: Improving Zero-shot and Few-shot Learning of Language Models via Chain-of-Thought Fine-Tuning
- 著者
- Seungone Kim, Se Joo, Doyoung Kim, Joel Jang, Seonghyeon Ye, Jamin Shin, Minjoon Seo
- 課題
- LLMと比較して100Bパラメータ未満の言語モデルは、未知のタスクを解決する際にChain-of-Thoughtによる推論において性能が劣化する
- アプローチ
- CoT Collectionと呼ばれるチューニング用データセットを導入する
- 結果
- 4つのドメイン固有タスクにおいてベースラインを上回るfew-shot学習能力を示した

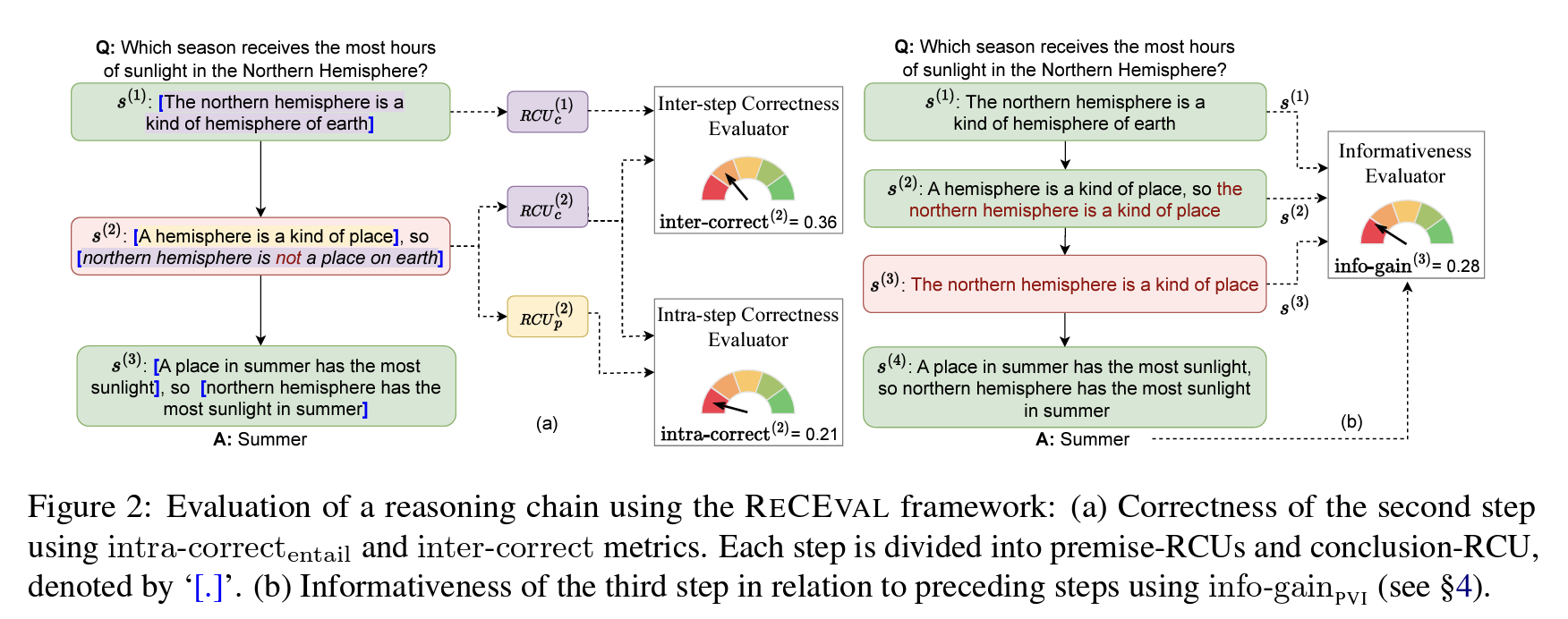
ReCEval: Evaluating Reasoning Chains via Correctness and Informativeness
- 著者
- Archiki Prasad, Swarnadeep Saha, Xiang Zhou, Mohit Bansal
- 課題
- Chain-of-Thoughtから得られる結果には注目が集まっているものの、CoTそのものに対する理解や評価は進んでいない
- アプローチ
- Chainの正確さと情報量を評価する指標ReCEvalを提案する
- 結果
- ReCEvalにより高評価を得たChainを用いることで下流タスクでの性能を改善した
まとめ
ChatGPTが公開されてから、LLMという言葉もすっかりバズワードとなった印象を受けますが、その世相を反映するかのようにEMNLP2023ではLLMに関する論文の採択数が大きく増加することとなりました。一方でMachine Translationのような一部の応用タスクの採択数は数を減らし、研究者の目線の向き先を感じ取ることができました。
そしてLLMの大きな課題であるQuantizationやHallucinationがホットなトピックとして注目を集めていることが数値で示されました。ただし実際に論文を読んでみると、評価指標やデータセットに関する議論も多く、それらの新たな概念はまだまだ手探りなところもあるのだなと思いました。
しかし今回分析した論文は6月に投稿されたものなので、この記事を執筆している12月時点では各分野の研究が急速にアップデートされていることには注意が必要です。秋ごろに見かけた情報を見る限りは、Hallucinationなどはより研究が進んでいるようなイメージがあります。
こうしてみるとEMNLP2023の論文を分析したことで、ChatGPTの与えた影響の大きさを伺い知ることができたものの、EMNLPでさえその一端しか掴めていないように思います。あまりに影響力が大きく、触発されたビッグテックや研究者の研究速度が早すぎるので、採択論文の公開を待つよりもプレプリントサーバーを使っていかないと技術の動向を追いきれないと感じています。
さて弥生では一緒に働く仲間を募集しています。 特に私の所属しているR&D室では、新たな価値を創造するために技術調査から企画、PoC、MVP作成に至るまで幅広い業務を担当しており、最先端の技術を用いて事業会社の意思決定に関わる貴重な機会が得られます。弥生で働くことに興味がありましたら、求人一覧をぜひご覧ください。